NLP_Bag-Of-Words(词袋模型)
文章目录
- 词袋模型
- 用词袋模型计算文本相似度
- 1.构建实验语料库
- 2.给句子分词
- 3.创建词汇表
- 4.生成词袋表示
- 5.计算余弦相似度
- 6.可视化余弦相似度
- 词袋模型小结
词袋模型
词袋模型是一种简单的文本表示方法,也是自然语言处理的一个经典模型。它将文本中的词看作一个个独立的个体,不考虑它们在句子中的顺序,只关心每个词出现的频次,如下图所示
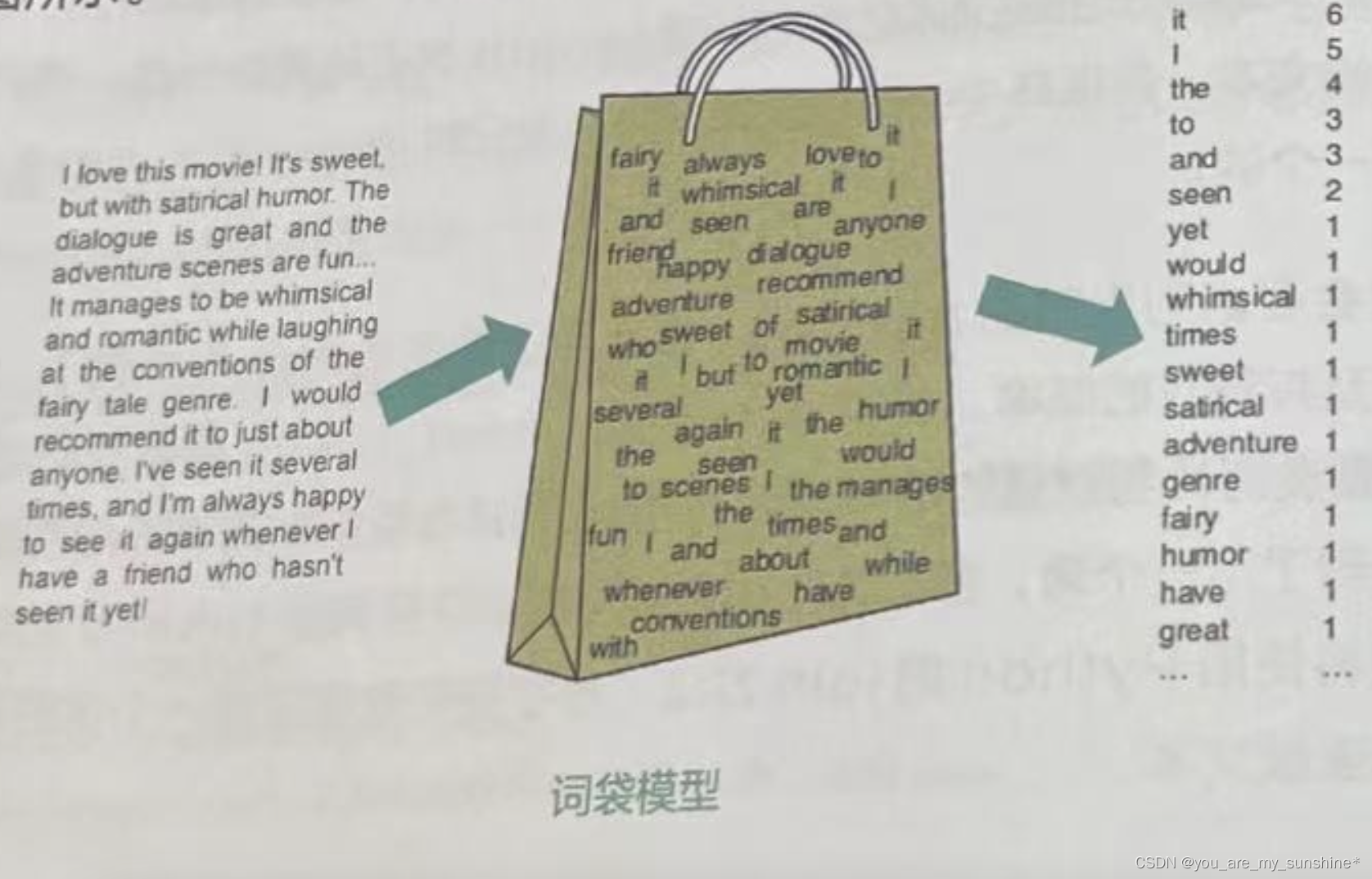
用词袋模型计算文本相似度
1.构建实验语料库
# 构建一个数据集
corpus = ["我特别特别喜欢看电影","这部电影真的是很好看的电影","今天天气真好是难得的好天气","我今天去看了一部电影","电影院的电影都很好看"]
2.给句子分词
# 对句子进行分词
import jieba # 导入 jieba 包
# 使用 jieba.cut 进行分词,并将结果转换为列表,存储在 corpus_tokenized 中
corpus_tokenized = [list(jieba.cut(sentence)) for sentence in corpus]
3.创建词汇表
# 创建词汇表
word_dict = {} # 初始化词汇表
# 遍历分词后的语料库
for sentence in corpus_tokenized:for word in sentence:# 如果词汇表中没有该词,则将其添加到词汇表中if word not in word_dict:word_dict[word] = len(word_dict) # 分配当前词汇表索引
print(" 词汇表:", word_dict) # 打印词汇表

4.生成词袋表示
# 根据词汇表将句子转换为词袋表示
bow_vectors = [] # 初始化词袋表示
# 遍历分词后的语料库
for sentence in corpus_tokenized:# 初始化一个全 0 向量,其长度等于词汇表大小sentence_vector = [0] * len(word_dict)for word in sentence:# 将对应词的索引位置加 1,表示该词在当前句子中出现了一次sentence_vector[word_dict[word]] += 1# 将当前句子的词袋向量添加到向量列表中bow_vectors.append(sentence_vector)
print(" 词袋表示:", bow_vectors) # 打印词袋表示

5.计算余弦相似度
计算余弦相似度(Cosine Similarity),衡量两个文本向量的相似性。
余弦相似度可用来衡量两个向量的相似程度。它的值在-1到1之间,值越接近1,表示两个向量越相似;值越接近-1,表示两个向量越不相似;当值接近0时,表示两个向量之间没有明显的相似性。

余弦相似度和向量距离(Vector Distance)都可以衡量两个向量之间的相似性。余弦相似度关注向量之间的角度,而不是它们之间的距离,其取值范围在-1(完全相反)到1(完全相同)之间。向量距离关注向量之间的实际距离,通常使用欧几里得距离(Euclidean Distance)来计算。两个向量越接近,它们的距离越小。
如果要衡量两个向量的相似性,而不关心它们的大小,那么余弦相似度会更合适。因此,余弦相似度通常用于衡量文本、图像等高维数据的相似性,因为在这些场景下,关注向量的方向关系通常比关注距离更有意义。而在一些需要计算实际距离的应用场景,如聚类分析、推荐系统等,向量距离会更合适。
# 导入 numpy 库,用于计算余弦相似度
import numpy as np
# 定义余弦相似度函数
def cosine_similarity(vec1, vec2):dot_product = np.dot(vec1, vec2) # 计算向量 vec1 和 vec2 的点积norm_a = np.linalg.norm(vec1) # 计算向量 vec1 的范数norm_b = np.linalg.norm(vec2) # 计算向量 vec2 的范数 return dot_product / (norm_a * norm_b) # 返回余弦相似度
# 初始化一个全 0 矩阵,用于存储余弦相似度
similarity_matrix = np.zeros((len(corpus), len(corpus)))
# 计算每两个句子之间的余弦相似度
for i in range(len(corpus)):for j in range(len(corpus)):similarity_matrix[i][j] = cosine_similarity(bow_vectors[i], bow_vectors[j])
6.可视化余弦相似度
# 导入 matplotlib 库,用于可视化余弦相似度矩阵
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib.font_manager import FontProperties
font = FontProperties(fname='SimHei.ttf', size = 15)#plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式
#plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式
#plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
fig, ax = plt.subplots() # 创建一个绘图对象
# 使用 matshow 函数绘制余弦相似度矩阵,颜色使用蓝色调
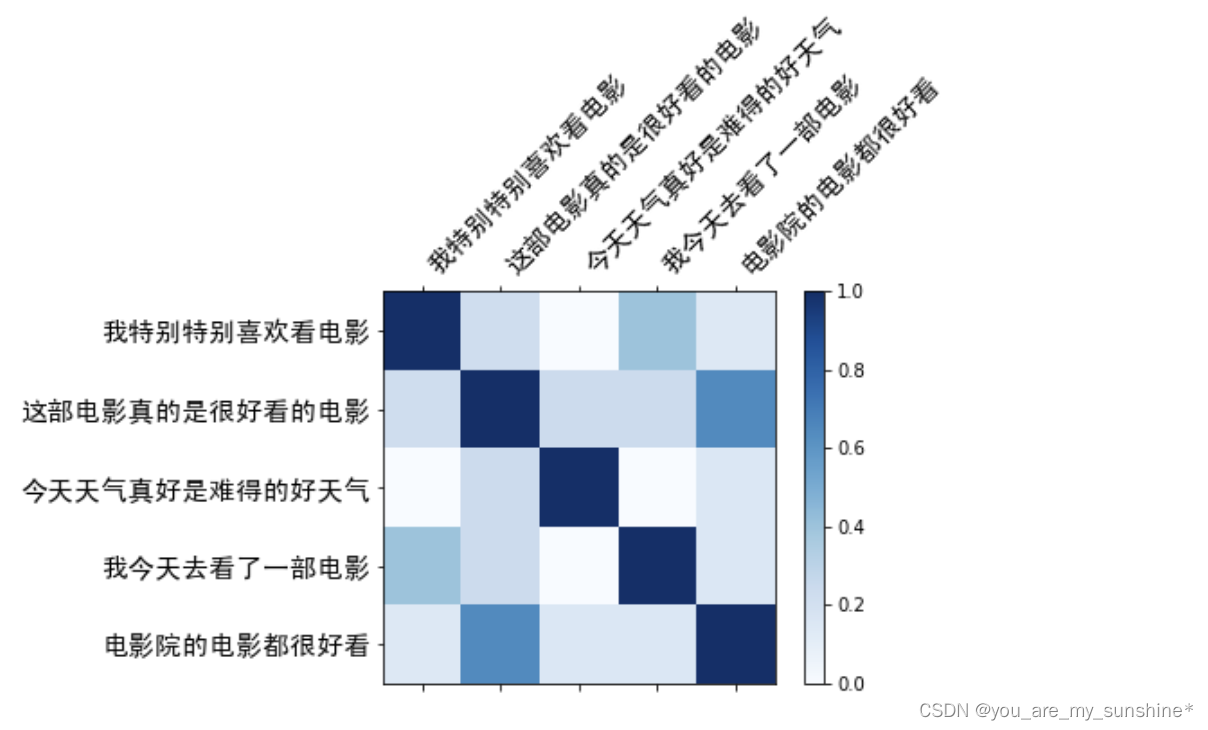
cax = ax.matshow(similarity_matrix, cmap=plt.cm.Blues)
fig.colorbar(cax) # 条形图颜色映射
ax.set_xticks(range(len(corpus))) # x 轴刻度
ax.set_yticks(range(len(corpus))) # y 轴刻度
ax.set_xticklabels(corpus, rotation=45, ha='left', FontProperties = font) # 刻度标签
ax.set_yticklabels(corpus, FontProperties = font) # 刻度标签为原始句子
plt.show() # 显示图形
词袋模型小结
Bag-of-Words则是一种用于文本表示的技术,它将文本看作由单词构成的无序集合,通过统计单词在文本中出现的频次来表示文本。因此,Bag-of-Words主要用于文本分类、情感分析、信息检索等自然语言处理任务中。
- (1) Bag-of-Words是基于词频将文本表示为一个向量,其中每个维度对应词汇表中的一个单词,其值为该单词在文本中出现的次数。
- (2) Bag-of-Words忽略了文本中的词序信息,只关注词频。这使得词袋模型在某些任务中表现出色,如主题建模和文本分类,但在需要捕捉词序信息的任务中表现较差,如机器翻译和命名实体识别。
- (3)Bag-of-Words 可能会导致高维稀疏表示,因为文本向量的长度取决于词汇表的大小。为解决这个问题,可以使用降维技术,如主成分分析(Principal Component Analysis,PCA)或潜在语义分析(Latent Semantic Analysis,LSA)。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…
相关文章:
NLP_Bag-Of-Words(词袋模型)
文章目录 词袋模型用词袋模型计算文本相似度1.构建实验语料库2.给句子分词3.创建词汇表4.生成词袋表示5.计算余弦相似度6.可视化余弦相似度 词袋模型小结 词袋模型 词袋模型是一种简单的文本表示方法,也是自然语言处理的一个经典模型。它将文本中的词看作一个个独立…...
C语言rand随机数知识解析和猜数字小游戏
rand随机数 rand C语言中提供了一个可以随机生成一个随机数的函数:rand() 函数原型: int rand(void);rand函数返回的值的区间是:0~RAND_MAX(32767)之间。大部分编译器都是32767。 #include<stdlib.h> int ma…...

django中的缓存功能
一:介绍 Django中的缓存功能是一个重要的性能优化手段,它可以将某些耗时的操作(如数据库查询、复杂的计算等)的结果存储起来,以便在后续的请求中直接使用这些缓存的结果,而不是重新执行耗时的操作。Django…...
三、搜索与图论
DFS 排列数字 #include<iostream> using namespace std; const int N 10; int a[N], b[N]; int n;void dfs(int u){if(u > n){for(int i 1; i < n; i)cout<<a[i]<<" ";cout<<endl;return;}for(int i 1; i < n; i){if(!b[i]){b[…...
【翻译】Processing安卓模式的安装使用及打包发布(内含中文版截图)
原文链接在下面的每一章的最前面。 原文有三篇,译者不知道贴哪篇了,这篇干脆标了原创。。 译者声明:本文原文来自于GNU协议支持下的项目,具备开源二改授权,可翻译后公开。 文章目录 Install(安装࿰…...

MATLAB图像处理——边缘检测及图像分割算法
1.检测图像中的线段 clear clc Iimread(1.jpg);%读入图像 Irgb2gray(I); %转换为灰度图像 h1[-1, -1. -1; 2, 2, 2; -1, -1, -1]; %模板 h2[-1, -1, 2; -1, 2, -1; 2, -1, -1]; h3[-1, 2, -1; -1, 2, -1; -1, 2, -1]; h4[2, -1, -1; -1, 2, -1; -1, -1, 2]; J1imfilter(I, h1)…...

探索设计模式:原型模式深入解析
探索设计模式:原型模式深入解析 设计模式是软件开发中用于解决常见问题的标准解决方案。它们不仅能提高代码的可维护性和可复用性,还能让其他开发者更容易理解你的设计决策。今天,我们将聚焦于创建型模式之一的原型模式(Prototyp…...

IAR报错解决:Fatal Error[Pe1696]: cannot open source file “zcl_ha.h“
报错信息 Fatal Error[Pe1696]: cannot open source file "zcl_ha.h" K:\Z-Stack 3.0.2\Projects\zstack\Practice\SampleSwitch\Source\zcl_samplesw_data.c 51 意思是找不到zcl_ha.h文件 找不到的理由可能是我把例程复制了一份到别的文件目录下,少复制…...
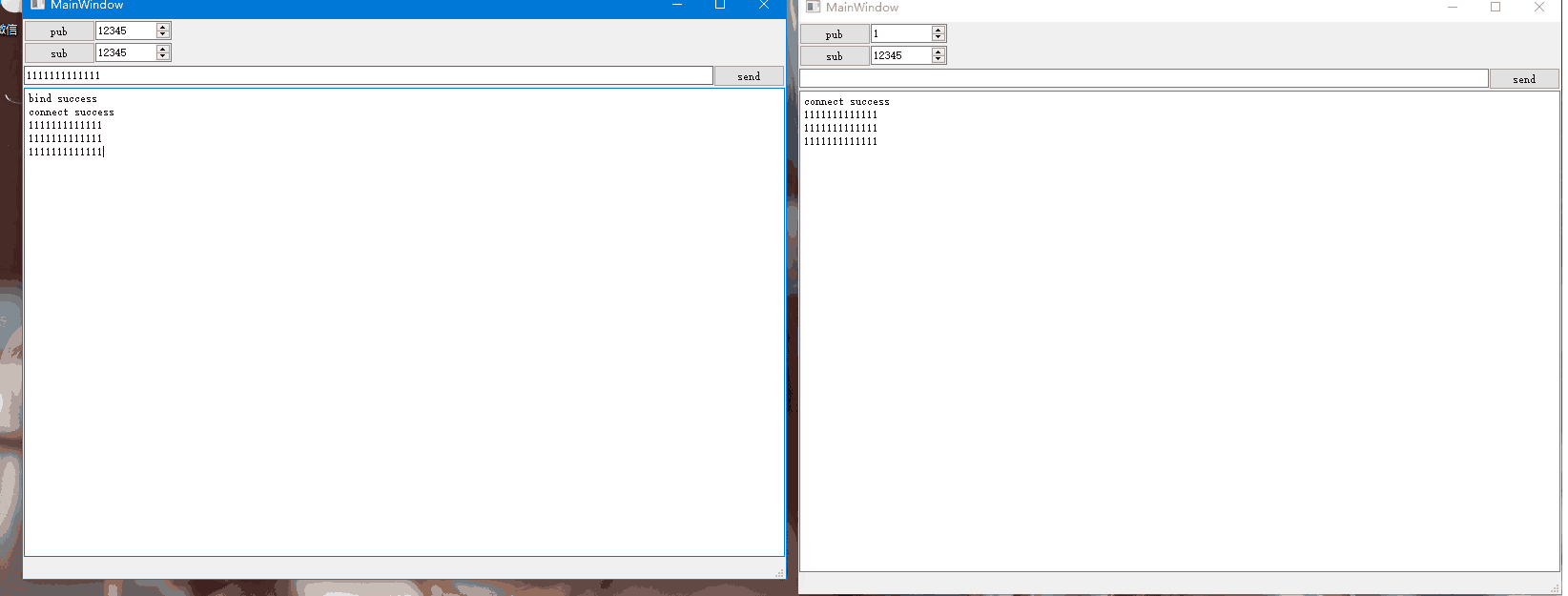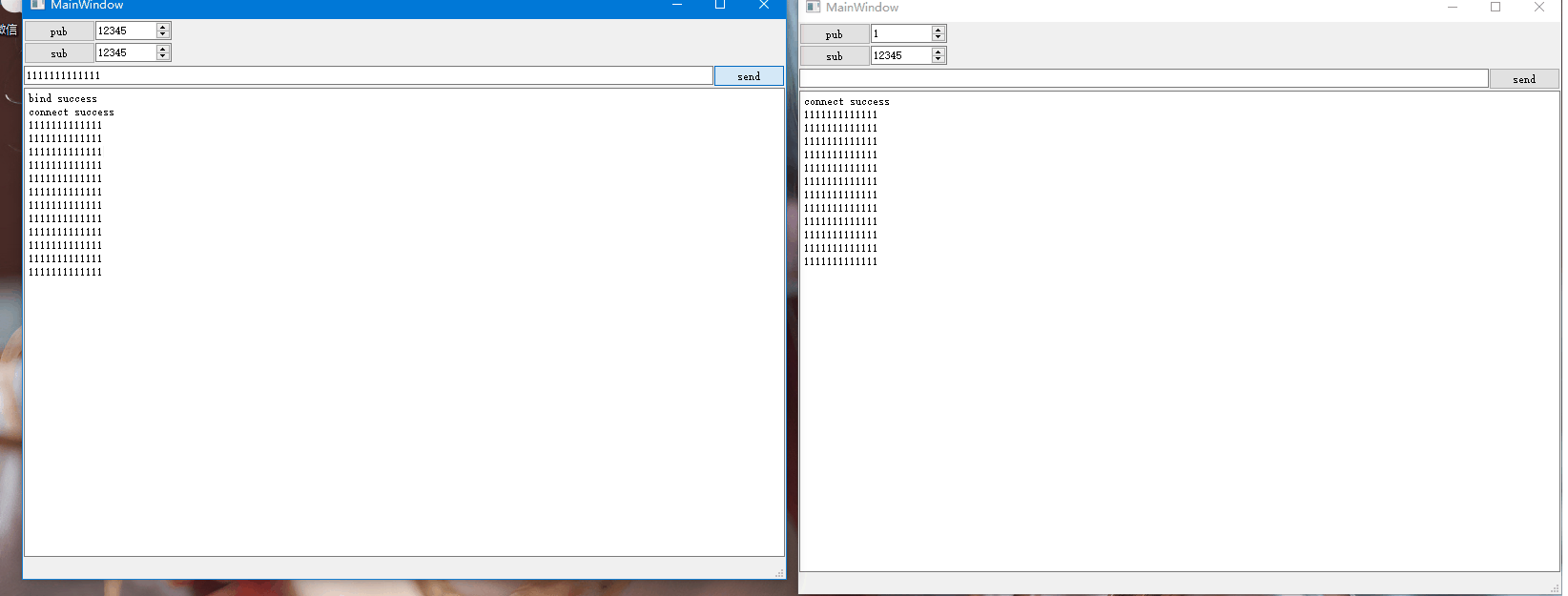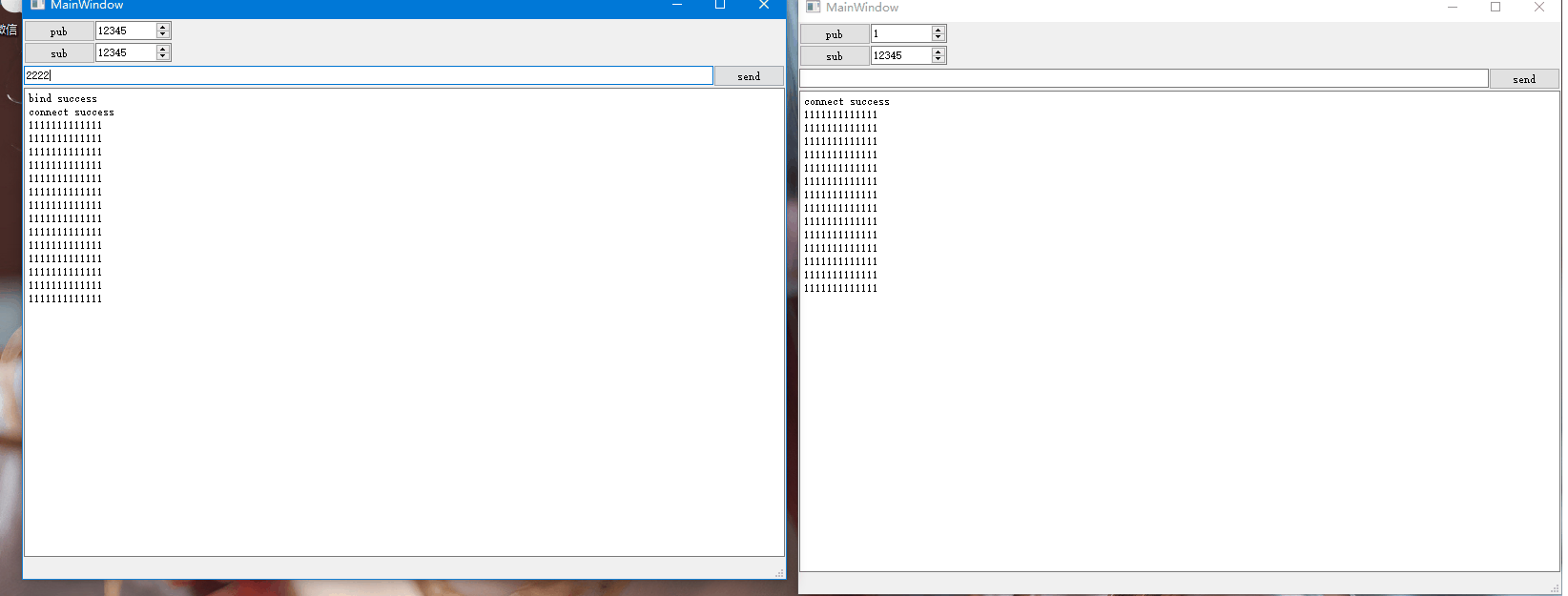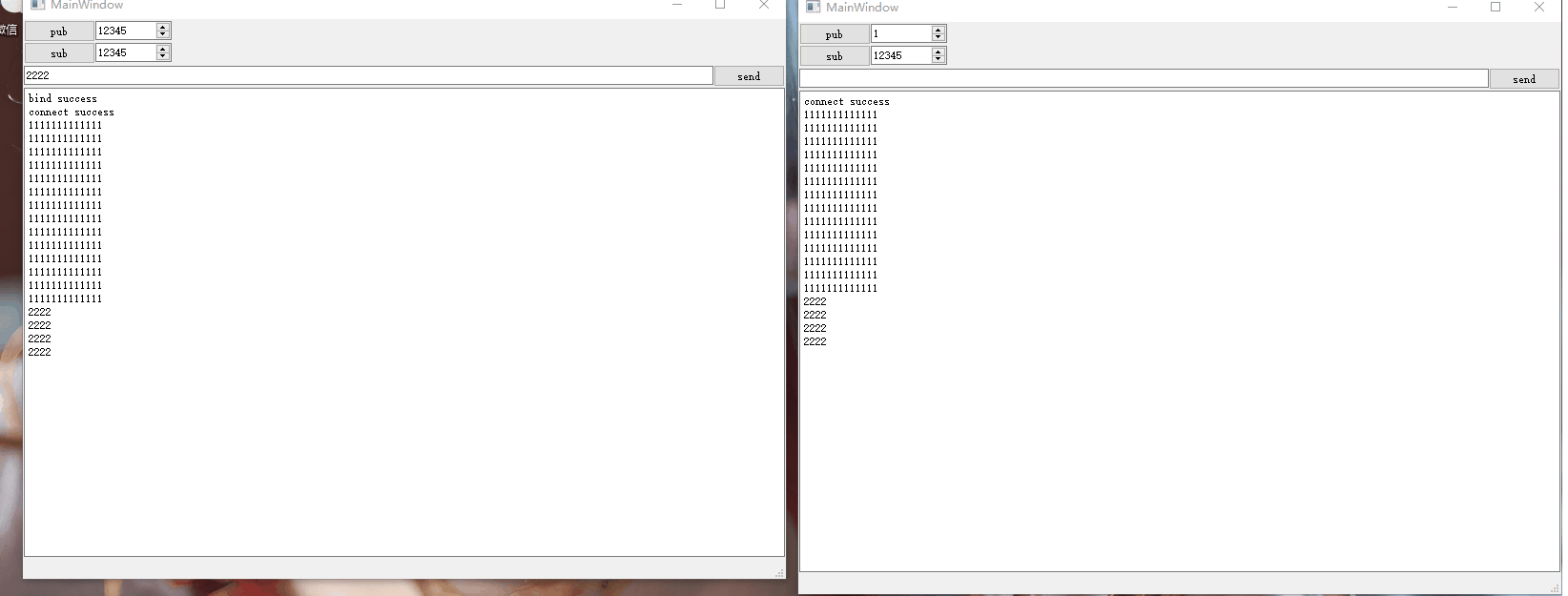
Qt网络编程-ZMQ的使用
不同主机或者相同主机中不同进程之间可以借助网络通信相互进行数据交互,网络通信实现了进程之间的通信。比如两个进程之间需要借助UDP进行单播通信,则双方需要知道对方的IP和端口,假设两者不在同一主机中,如下示意图: …...

如何清理Docker占用的磁盘空间?
在Docker中,随着时间的推移,占用的磁盘空间可能会不断增加。为了保持系统的稳定性和性能,定期清理Docker占用的磁盘空间非常重要。下面将介绍一些清理Docker磁盘空间的方法。 一、清理无用的容器 有时候,我们可能会运行一些临时…...

从零开始学HCIA之NAT基本工作原理
1、NAT设计之初的目的是解决IP地址不足的问题,慢慢地其作用发展到隐藏内部地址、实现服务器负载均衡、完成端口地址转换等功能。 2、NAT完成将IP报文报头中的IP地址转换为另一个IP地址的过程,主要用于实现内部网络访问外部网络的功能。 3、NAT功能一般…...

Day40- 动态规划part08
一、单词拆分 题目一:139. 单词拆分 139. 单词拆分 给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。 注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以…...

论文笔记:相似感知的多模态假新闻检测
整理了RecSys2020 Progressive Layered Extraction : A Novel Multi-Task Learning Model for Personalized Recommendations)论文的阅读笔记 背景模型实验 论文地址:SAFE 背景 在此之前,对利用新闻文章中文本信息和视觉信息之间的关系(相似…...

5G技术对物联网的影响
随着数字化转型的加速,5G技术作为通信领域的一次重大革新,正在对物联网(IoT)产生深远的影响。对于刚入行的朋友们来说,理解5G技术及其对物联网应用的意义,是把握行业发展趋势的关键。 让我们简单了解什么是…...
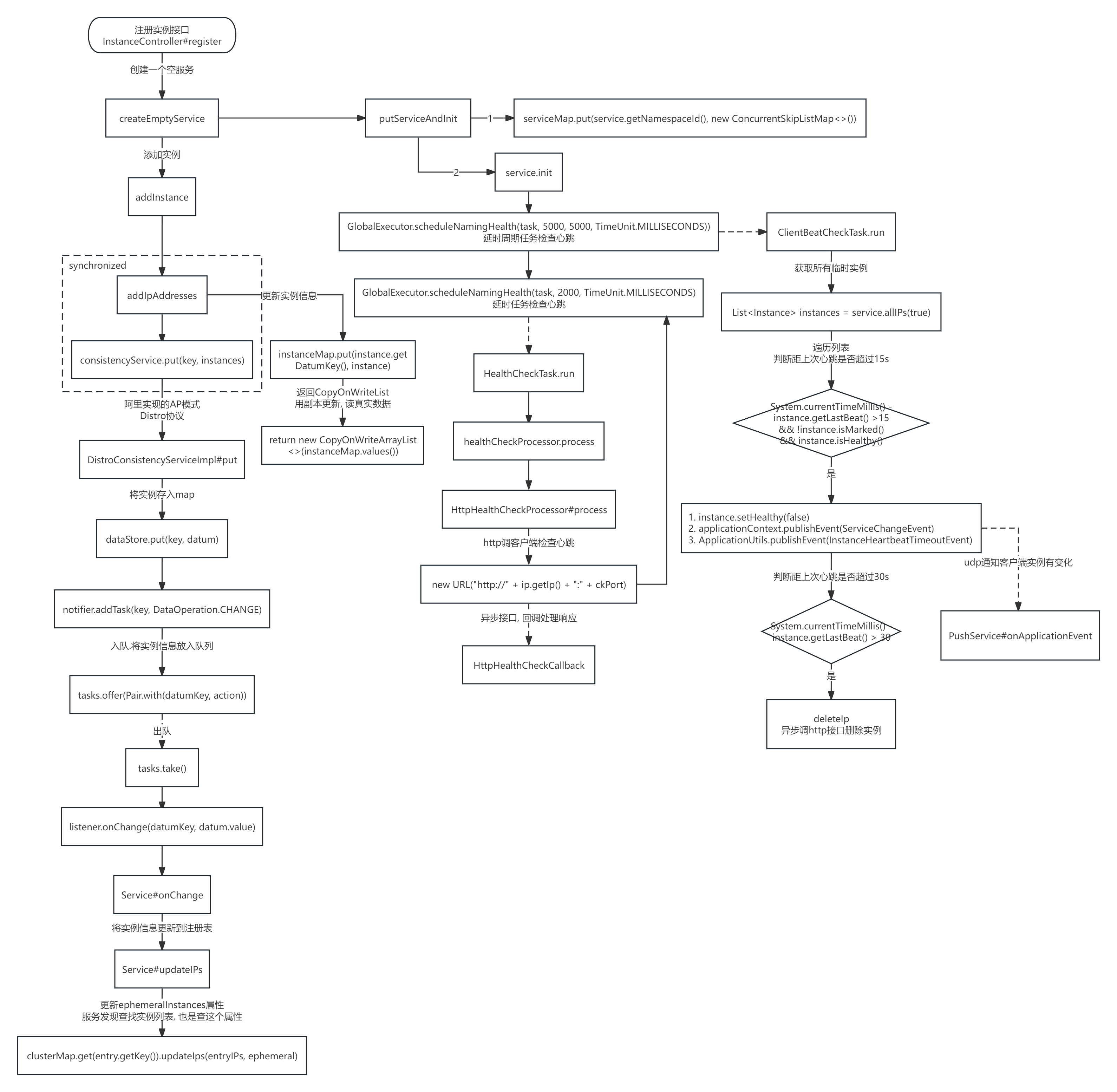
Nacos1.X源码解读(待完善)
目录 下载源码 注册服务 客户端注册流程 注册接口API 服务端处理注册请求 设计亮点 服务端流程图 下载源码 1. 克隆git地址到本地 # 下载nacos源码 git clone https://github.com/alibaba/nacos.git 2. 切换分支到1.4.7, maven编译(3.5.1) 3. 找到启动类com.alibaba.na…...

算法之双指针系列1
目录 一:双指针的介绍 1:快慢指针 2:对撞指针 二:对撞指针例题讲述 一:双指针的介绍 在做题中常用两种指针,分别为对撞指针与快慢指针。 1:快慢指针 简称为龟兔赛跑算法,它的基…...

苍穹外卖面试题
8. 如何理解分组校验 很多情况下,我们会将校验规则写到实体类中的属性上,而这个实体类有可能作为不同功能方法的参数使用,而不同的功能对象参数对象中属性的要求是不一样的。比如我们在新增和修改一个用户对象时,都会接收User对象…...
【Qt 学习之路】在 Qt 使用 ZeroMQ
文章目录 1、概述2、ZeroMQ介绍2.1、ZeroMQ 是什么2.2、ZeroMQ 主线程与I/O线程2.3、ZeroMQ 4种模型2.4、ZeroMQ 相关地址 3、Qt 使用 ZeroMQ3.1、下载 ZeroMQ3.2、添加 ZeroMQ 库3.3、使用 ZeroMQ3.4、相关 ZeroMQ 案例 1、概述 今天是大年初一,先给大家拜个年&am…...

CI/CD到底是啥?持续集成/持续部署概念解释
前言 大家好,我是chowley,日常工作中,我每天都在接触CI/CD,今天就给出我心中的答案。 在现代软件开发中,持续集成(Continuous Integration,CI)和持续部署(Continuous D…...
)
golang常用库之-disintegration/imaging图片操作(生成缩略图)
文章目录 golang常用库之什么是imaging库导入和使用生成缩略图 golang常用库之 什么是imaging库 官网:https://github.com/disintegration/imaging imaging 是一个 Go 语言的图像处理库,它提供了一组功能丰富的函数和方法,用于进行各种图像…...

终极硬件调优指南:如何用UXTU免费解锁电脑隐藏性能
终极硬件调优指南:如何用UXTU免费解锁电脑隐藏性能 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility 还在为电脑性能…...

英雄联盟智能助手Seraphine:如何用3个核心功能提升你的排位胜率
英雄联盟智能助手Seraphine:如何用3个核心功能提升你的排位胜率 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否曾在英雄联盟排位赛中因为BP阶段手忙脚乱而错失先机?是否因为不了…...

终极英雄联盟工具箱:5个核心功能快速提升你的游戏体验
终极英雄联盟工具箱:5个核心功能快速提升你的游戏体验 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款专为英雄…...

别再只盯着NXP和Impinj了!盘点5款国产超高频RFID芯片的‘独门绝技’
国产超高频RFID芯片的五大技术突围路径 在供应链安全与核心技术自主可控的背景下,国产超高频RFID芯片正从"能用"向"好用"快速演进。不同于早期简单模仿进口芯片的方案,如今头部厂商已形成独特的技术路线——有的在抗金属性能上实现突…...
)
环境科学家都在偷偷用的NotebookLM技巧(2024中科院实测TOP5插件清单)
更多请点击: https://codechina.net 第一章:NotebookLM在环境科学研究中的范式变革 传统环境科学研究长期受限于多源异构数据整合困难、跨学科知识理解门槛高、因果推断缺乏可解释性支持等瓶颈。NotebookLM 作为基于用户自有文档构建的语义增强型AI协作…...

3步实现微信聊天记录永久备份:WeChatExporter完整解决方案
3步实现微信聊天记录永久备份:WeChatExporter完整解决方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因手机丢失或系统更新而永远丢失珍贵的微信…...

5分钟快速上手:Proxmark3GUI图形界面终极指南
5分钟快速上手:Proxmark3GUI图形界面终极指南 【免费下载链接】Proxmark3GUI A cross-platform GUI for Proxmark3 client | 为PM3设计的跨平台图形界面 项目地址: https://gitcode.com/gh_mirrors/pr/Proxmark3GUI 对于RFID技术初学者来说,Proxm…...
)
用Logisim从零搭建MIPS CPU:我的计组课设通关实录(附完整电路文件)
从零构建MIPS CPU:一位计算机系学生的Logisim实战指南 1. 为什么选择Logisim搭建MIPS CPU 作为一名计算机专业的学生,第一次接触计算机组成原理课程设计时,面对"用Logisim搭建MIPS CPU"这个任务,我既兴奋又忐忑。兴奋的…...

联想拯救者工具箱:开源替代方案实现笔记本性能优化与硬件控制
联想拯救者工具箱:开源替代方案实现笔记本性能优化与硬件控制 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 联…...

对比直接使用厂商 API 通过 Taotoken 聚合调用的账单清晰度差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 与通过 Taotoken 聚合调用的账单清晰度差异 在集成多个大语言模型到业务中时,开发者通常会面临一…...