23种计模式之Python/Go实现
目录
- 设计模式
- what?
- why?
- 设计模式:设计模式也衍生出了很多的新的种类,不局限于这23种
- 创建类设计模式(5种)
- 结构类设计模式(7种)
- 行为类设计模式(11种)
- 六大设计原则
- 开闭原则
- 里氏替换原则
- 依赖倒置原则
- 接口隔离原则
- 迪米特法则(最少知识原则)
- 单一职责原则
- 设计原则与设计模式
- 创建类设计模式与设计原则
- 结构类设计模式与设计原则
- 行为类设计模式与设计原则
- 创建类设计模式(5种)
- 单例模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 工厂模式&简单工厂模式,抽象工厂模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 建造者模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 原型模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 结构类设计模式(7种)
- 代理模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 装饰器模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 适配器模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 门面模式/外观模式/Facade Pattern
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 组合模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 享元模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 桥接模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 行为类设计模式(11种)
- 策略模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 责任链模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 命令模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 中介者模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 模板模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 迭代器模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 访问者模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 观察者模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 解释器模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 备忘录模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
- 状态模式
- 使用场景
- 优缺点
- 代码实现
- python代码
- go代码
设计模式
what?
设计模式是面对各种问题进行提炼和抽象而形成的解决方案。
这些设计方案是前人不断试验,考虑了封装性、复用性、效率、可修改、可移植等各种因素的高度总结。
它不限于一种特定的语言,它是一种解决问题的思想和方法。
why?
由于高级语言的出现,让机器读懂你的意图已经不是最主要的“矛盾”,而让人读懂你的意图才是最重要。按照设计模式编写的代码,其可读性也会大大提升,利于团队项目的继承和扩展。
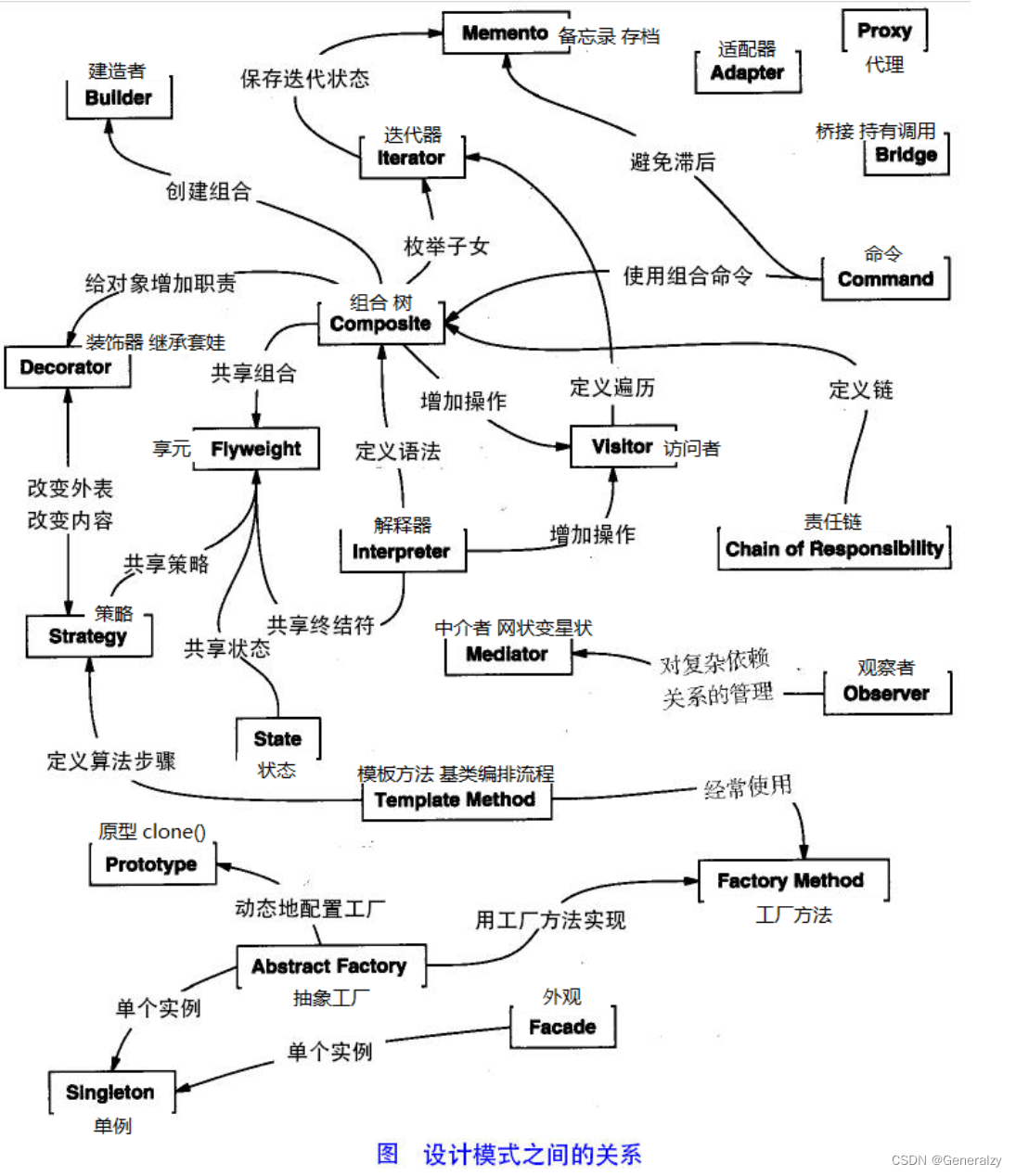
设计模式:设计模式也衍生出了很多的新的种类,不局限于这23种
设计模式可以分为三个大类:创建类设计模式、结构类设计模式、行为类设计模式
下面用一个图片来整体描述一下设计模式之间的关系:
创建类设计模式(5种)
单例模式、工厂模式(简单工厂模式、抽象工厂模式)、建造者模式、原型模式
结构类设计模式(7种)
代理模式、装饰器模式、适配器模式、门面模式、组合模式、享元模式、桥梁模式
行为类设计模式(11种)
策略模式、责任链模式、命令模式、中介者模式、模板模式、迭代器模式、访问者模式、观察者模式、解释器模式、备忘录模式、状态模式
六大设计原则
设计模式与设计原则,基本符合规则与原则的关系,设计模式是一个个具体问题的解决方案,设计原则则反映了这些设计模式的指导思想;同时,设计原则可衍生出的设计模式也不仅限于上述介绍到了23种设计模式,任何一种针对特定业务场景中的解决方法,虽然找不到对应的设计模式与之匹配,但若符合设计原则,也可以认为是一种全新的设计模式。从这个意义上来说,设计模式是程序设计方法的形,而设计原则是程序设计方法的神。
开闭原则
开闭原则英文原名为Open Closed Principle,简称OCP原则。其含义为:一个软件实体,如类、模块、函数等,应该对扩展开放,对修改关闭。
开闭原则是非常基础的一个原则,也有人把开闭原则称为“原则的原则”。模块分原子模块,低层模块,高层模块,业务层可以认为是最高层次的模块。
对扩展开放,意味着模块的行为是可以扩展的,当高层模块需求改变时,可以对低层模块进行扩展,使其具有满足高层模块的新功能;对修改关闭,即对低层模块行为进行扩展时,不必改动模块的源代码。最理想的情况是,业务变动时,仅修改业务代码,不修改依赖的模块(类、函数等)代码,通过扩展依赖的模块单元来实现业务变化。
举例说明:假设一个原始基类水果类,苹果类是它的派生类,苹果中包含水果的各种属性,如形状、颜色等;另有两个类,农民类和花园类,最高层次(业务层次)为农民在花园种苹果。如果此时,农民决定不种苹果了,改种梨,符合OCP原则的设计应该为基于水果类构建一个新的类,即梨类(对扩展开放),而并不应该去修改苹果类,使它成为一个梨类(对修改关闭)。修改应仅在最高层,即业务层中进行。
里氏替换原则
里氏替换原则英文原名为Liskov Substitution Principle,简称LSP原则。它是面向对象设计的最为基本原则之一。 里氏替换原则的含义为:任何基类可以出现的地方,子类一定可以出现。 LSP是继承复用的基石,只有当子类可以替换掉基类,软件单位的功能不受到影响时,基类才能真正被复用,子类也能够在基类的基础上增加新的行为。
举例说明:对于一个鸟类,可以衍生出麻雀、喜鹊、布谷等子类,这些子类都可继承鸟类的鸣叫、飞行、吃食等接口。而对于一个鸡类,虽然它在生物学上属于鸟类,但它不会飞,那么符合LSP设计原则的情况下,鸡就不应该是鸟的一个子类:在鸟类调用飞行接口的地方,鸡类并不能出现。如果鸡类要使用鸟类的接口,应该使用关联关系,而不是继承关系。
依赖倒置原则
依赖倒置原则英文原名为Dependence Inversion Principle,简称DIP原则。它的含义为:高层模块不应该依赖于低层模块,两者都应该依赖其抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
将每个不可细分的逻辑叫作原子逻辑,原子逻辑组装,形成低层模块,低层模块组装形成高层模块。依赖倒置原则的含义为,高层模块和低层模块都应该由各自的抽象模块派生而来,同时接口设计应该依赖于抽象,而非具体模块。
举例说明:司机与汽车是依赖的关系,司机可以有实习司机类、老司机类等派生;汽车可以有轿车、SUV、卡车等派生类。如果司机中设计一个接口drive,汽车是其参数,符合DIP设计原则的参数,应该是在基类司机类中,将基类汽车类作为参数,而司机的派生类中,drive的参数同样应该为基类汽车类,而不应该是汽车类的任一个派生类。如果规定实习司机只能开轿车等业务逻辑,应该在其接口中进行判断,而不应该将参数替换成子类轿车。
接口隔离原则
接口隔离原则英文原名为Interface Segregation Principle,简称ISP原则。其含义为:类间的依赖关系不应该建立一个大的接口,而应该建立其最小的接口,即客户端不应该依赖那些它不需要的接口。这里的接口的概念是非常重要的。从逻辑上来讲,这里的接口可以指一些属性和方法的集合;从业务上来讲,接口就可以指特定业务下的接口(如函数,URL调用等)。接口应该尽量小,同时仅留给客户端必要的接口,弃用没有必要的接口。
举例说明:如果要根据具体的数据,生成饼图、直方图、表格,这个类该如何设计?如果将生成饼图、直方图、表格等“接口”(这里的接口就是“操作”的集合的概念),写在一个类中,是不符合接口隔离原则的。符合ISP原则的设计应该是设计三个类,每个类分别实现饼图、直方图、表格的绘制。
接口隔离原则和单一职责原则一样,涉及到粒度的问题,解决粒度大小,同样依赖于具体的业务场景,需要读者根据实践去权衡。
迪米特法则(最少知识原则)
迪米特法则(Law of Demeter)也叫最少知识原则,英文Least Knowledge Principle,简称LKP原则。其含义为:一个对象应该对其它对象有最少的了解。
举例说明:一个公司有多个部门,每个部门有多个员工,如果公司CEO要下发通知给每个员工,是调用接口直接通知所有员工么?其实不然,CEO只需和它的“朋友”类部门Leader交流就好,部门Leader再下发通知信息即可。而CEO类不需要与员工进行“交流”。
迪米特法则要求对象应该仅对自己的朋友类交流,而不应该对非朋友类交流。那什么才是朋友类呢?一般来说,朋友类具有以下特征:
1)当前对象本身(self);
2)以参量形式传入到当前对象方法中的对象;
3)当前对象的实例变量直接引用的对象;
4)当前对象的实例变量如果是一个聚集,那么聚集中的元素也都是朋友;
5)当前对象所创建的对象。
单一职责原则
单一职责原则英文原名为Single Responsibility Principle,简称SRP原则。其含义为:应该有且仅有一个原因引起类的变更。
举例说明:一个视频播放系统,一个客户端类有两个功能接口,即视频播放接口和音频播放接口。虽然这样的设计很常见,但却不满足单一职责原则的。原因是,如果对视频播放有变更需求或者对音频播放有修改需求,都会变更视频客户端的类结构。符合单一原则的设计是,将视频播放单元和音频播放单元各建一个类,播放客户端继承两个类,构成客户端。
单一职责原则的最大难点在于职责的划分,试想,以上划分是否是符合单一职责了?既是,也不是。试想,如果将视频传输和音频传输的协议信息和数据信息区分开,为符合这种粒度的单一职责原则就必须要有协议传输类和数据传输类的划分。如果接着细分,可能一个简单的小模块,都要设计非常多的类。因此,单一职责原则粒度的选择,应该根据业务流程和人员分工来进行考虑。一些基本的划分,似乎已经成了行业规范性的内容,比如,业务逻辑与用户信息管理的划分等。
设计原则与设计模式
创建类设计模式与设计原则
工厂模式:工厂方法模式是一种解耦结构,工厂类只需要知道抽象产品类,符合最少知识原则(迪米特法则);同时符合依赖倒置原则和里氏替换原则;
抽象工厂模式:抽象工厂模式具有工厂模式的优点,但同时,如果产品族要扩展,工厂类也要修改,违反了开闭原则;
模板模式:优秀的扩展能力符合开闭原则。
结构类设计模式与设计原则
代理模式:代理模式在业务逻辑中将对主体对象的操作进行封装,合适的应用会符合开闭原则和单一职责原则;事实上,几乎带有解耦作用的结构类设计模式都多少符合些开闭原则;
门面模式:门面模式不符合开闭原则,有时不符合单一职责原则,如若不注意,也会触碰接口隔离原则;
组合模式:符合开闭原则,但由于一般在拼接树时使用实现类,故不符合依赖倒置原则;
桥梁模式:桥梁模式堪称依赖倒置原则的典范,同时也符合开闭原则。
行为类设计模式与设计原则
策略模式:符合开闭原则,但高层模块调用时,不符合迪米特法则。行为类设计模式多少会符合些单一职责原则,典型的如观察者模式、中介者模式、访问者模式等;
责任链模式:符合单一职责原则和迪米特法则;
命令模式:符合开闭原则。
在不同的业务逻辑中,不同的设计模式也会显示出不同的设计原则特点,从这个意义上来说,设计模式是设计原则的体现,但体现不是固定的,是根据业务而有所不同的。
创建类设计模式(5种)
单例模式
单例模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
单例模式是一种创建型设计模式,它确保一个类只有一个实例,并提供了一个全局访问点来访问该实例。
注意:
- 单例类只能有一个实例。
- 单例类必须自己创建自己的唯一实例。
- 单例类必须给所有其他对象提供这一实例。
使用场景
意图:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
主要解决:一个全局使用的类频繁地创建与销毁。
何时使用:当您想控制实例数目,节省系统资源的时候。
如何解决:判断系统是否已经有这个单例,如果有则返回,如果没有则创建。
关键代码:构造函数是私有的。
应用实例:
- 一个班级只有一个班主任。
- Windows 是多进程多线程的,在操作一个文件的时候,就不可避免地出现多个进程或线程同时操作一个文件的现象,所以所有文件的处理必须通过唯一的实例来进行。
- 一些设备管理器常常设计为单例模式,比如一个电脑有两台打印机,在输出的时候就要处理不能两台打印机打印同一个文件。
- 要求生产唯一序列号。
- WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
- 创建的一个对象需要消耗的资源过多,比如 I/O 与数据库的连接等。
优缺点
优点:
- 在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例(比如管理学院首页页面缓存)。
- 避免对资源的多重占用(比如写文件操作)。
缺点:
- 没有接口,不能继承,与单一职责原则冲突,一个类应该只关心内部逻辑,而不关心外面怎么样来实例化。
- 单例模式是并发协作软件模块中需要最先完成的,因而其不利于测试;
- 单例模式在某种情况下会导致“资源瓶颈”。
代码实现

以实现一个日志handle为例,
python代码
# logger.py
from threading import Lock
from typing import Selfmutex = Lock()class Logger:@classmethoddef get_logger(cls) -> Self:if not hasattr(cls, "__single__"):# 加锁实例化一次with mutex:if not hasattr(cls, "__single__"):cls.__single__ = Logger()# 实例化后返回return cls.__single__# main.py
from logger import Logger
from concurrent.futures import ThreadPoolExecutordef test():logger = Logger.get_logger()print(hex(id(logger)))if __name__ == '__main__':with ThreadPoolExecutor() as pool:for _ in range(10):pool.submit(test)
执行结果:
0x1364a000b10
0x1364a000b10
0x1364a000b10
0x1364a000b10
0x1364a000b100x1364a000b100x1364a000b10
0x1364a000b100x1364a000b10
0x1364a000b10
go代码
golang提供了sync.Once,使得开发者可以更容易的写出单例代码:
// logger.go
package mainimport ("sync"
)var (once = new(sync.Once)
)var L *Loggertype Logger struct {
}func getLogger() *Logger {once.Do(func() {L = new(Logger)})return L
}// main.go
package mainimport ("fmt""sync"
)func Task() {l := getLogger()fmt.Printf("%p \n", l)
}func main() {wg := new(sync.WaitGroup)wg.Add(10)for i := 0; i < 10; i++ {go func() {defer wg.Done()Task()}()}wg.Wait()
}
执行结果:
0x5da5c0
0x5da5c0
0x5da5c0
0x5da5c0
0x5da5c0
0x5da5c0
0x5da5c0
0x5da5c0
0x5da5c0
0x5da5c0
工厂模式&简单工厂模式,抽象工厂模式
工厂模式(Factory Pattern)是 Java 中最常用的设计模式之一,这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
工厂模式提供了一种创建对象的方式,而无需指定要创建的具体类。
工厂模式属于创建型模式,它在创建对象时提供了一种封装机制,将实际创建对象的代码与使用代码分离。
使用场景
意图:定义一个创建对象的接口,让其子类自己决定实例化哪一个工厂类,工厂模式使其创建过程延迟到子类进行。
主要解决:主要解决接口选择的问题。
何时使用:我们明确地计划不同条件下创建不同实例时。
如何解决:让其子类实现工厂接口,返回的也是一个抽象的产品。
关键代码:创建过程在其子类执行。
应用实例:
- 您需要一辆汽车,可以直接从工厂里面提货,而不用去管这辆汽车是怎么做出来的,以及这个汽车里面的具体实现。
- 在 Hibernate 中,如果需要更换数据库,工厂模式同样发挥了作用。只需简单地更改方言(Dialect)和数据库驱动(Driver),就能够实现对不同数据库的切换。
- 日志记录器:记录可能记录到本地硬盘、系统事件、远程服务器等,用户可以选择记录日志到什么地方。
- 数据库访问,当用户不知道最后系统采用哪一类数据库,以及数据库可能有变化时。
- 设计一个连接服务器的框架,需要三个协议,“POP3”、“IMAP”、“HTTP”,可以把这三个作为产品类,共同实现一个接口。
注意事项:作为一种创建类模式,在任何需要生成复杂对象的地方,都可以使用工厂方法模式。有一点需要注意的地方就是复杂对象适合使用工厂模式,而简单对象,特别是只需要通过 new 就可以完成创建的对象,无需使用工厂模式。如果使用工厂模式,就需要引入一个工厂类,会增加系统的复杂度。
工厂模式包含以下几个核心角色:
- 抽象产品(Abstract Product):定义了产品的共同接口或抽象类。它可以是具体产品类的父类或接口,规定了产品对象的共同方法。
- 具体产品(Concrete Product):实现了抽象产品接口,定义了具体产品的特定行为和属性。
- 抽象工厂(Abstract Factory):声明了创建产品的抽象方法,可以是接口或抽象类。它可以有多个方法用于创建不同类型的产品。
- 具体工厂(Concrete Factory):实现了抽象工厂接口,负责实际创建具体产品的对象。
优缺点
优点:
- 一个调用者想创建一个对象,只要知道其名称就可以了。
- 扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
- 屏蔽产品的具体实现,调用者只关心产品的接口。
- 工厂模式巨有非常好的封装性,代码结构清晰;在抽象工厂模式中,其结构还可以随着需要进行更深或者更浅的抽象层级调整,非常灵活;
- 屏蔽产品类,使产品的被使用业务场景和产品的功能细节可以分而开发进行,是比较典型的解耦框架。
缺点:
- 每次增加一个产品时,都需要增加一个具体类和对象实现工厂,使得系统中类的个数成倍增加,在一定程度上增加了系统的复杂度,同时也增加了系统具体类的依赖,这并不是什么好事。
- 工厂模式相对于直接生成实例过程要复杂一些,所以,在小项目中,可以不使用工厂模式;
- 抽象工厂模式中,产品类的扩展比较麻烦。毕竟,每一个工厂对应每一类产品,产品扩展,就意味着相应的抽象工厂也要扩展
代码实现
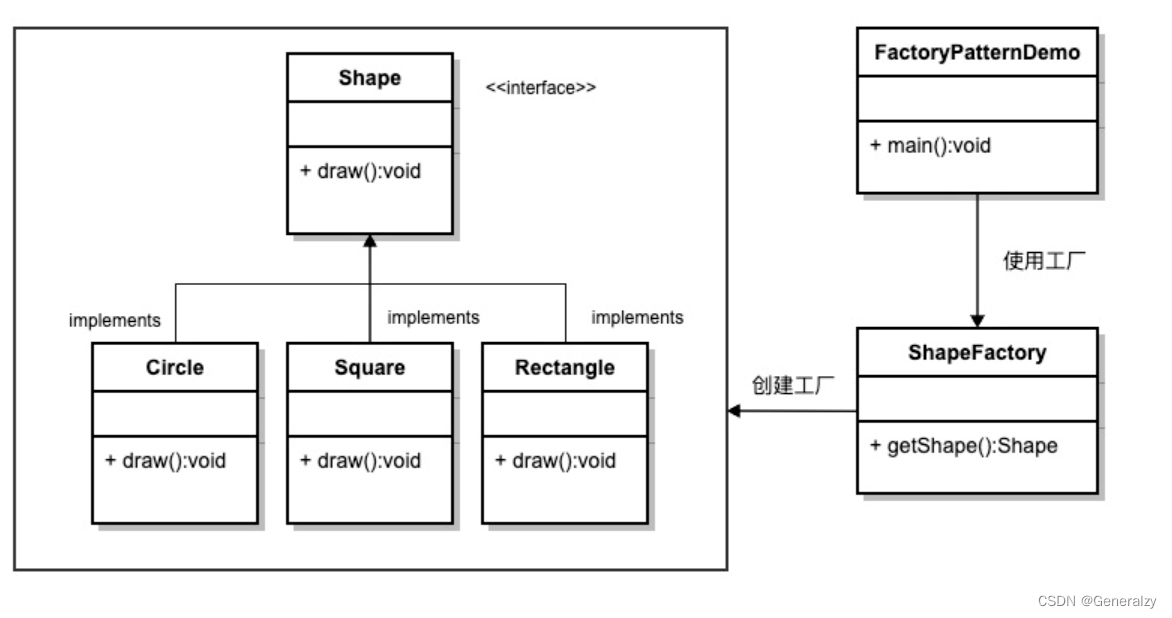
创建一个 Shape 接口和实现 Shape 接口的实体类。下一步是定义工厂类 ShapeFactory。
FactoryPatternDemo 类使用 ShapeFactory 来获取 Shape 对象。它将向 ShapeFactory 传递信息(CIRCLE / RECTANGLE / SQUARE),以便获取它所需对象的类型。
python代码
class ShapeInterface:def draw(self):raise NotImplementedError("this method must be implemented")class Circle(ShapeInterface):def draw(self):# do somethingprint(f"the method of the {self.__class__.__name__} is called")class Square(ShapeInterface):def draw(self):# do somethingprint(f"the method of the {self.__class__.__name__} is called")class Rectangle(ShapeInterface):def draw(self):# do somethingprint(f"the method of the {self.__class__.__name__} is called")class ShapeFactory:@classmethoddef get_shape(cls, classname: str):match classname:case "circle":return Circle()case "square":return Square()case "rectangle":return Rectangle()case _:return Noneif __name__ == '__main__':s = ShapeFactory.get_shape("circle")s.draw()s = ShapeFactory.get_shape("square")s.draw()s = ShapeFactory.get_shape("rectangle")s.draw()
执行结果:
the method of the Circle is called
the method of the Square is called
the method of the Rectangle is called
go代码
go语言原生提供了interface的思想,让工厂模式实现更加简单:
package mainimport "fmt"type ShapeInterface interface {Draw()
}type Rectangle struct {
}func (r *Rectangle) Draw() {fmt.Println("The method of the rectangle Draw is called")
}type Circle struct {
}func (c *Circle) Draw() {fmt.Println("The method of the circle Draw is called")
}type Square struct {
}func (s *Square) Draw() {fmt.Println("The method of the Square Draw is called")
}func GetShape(classname string) ShapeInterface {switch classname {case "circle":return new(Circle)case "square":return new(Square)case "rectangle":return new(Rectangle)default:return nil}
}func main() {s := GetShape("circle")s.Draw()s = GetShape("square")s.Draw()s = GetShape("rectangle")s.Draw()
}
在场景中写成如下形式:
spicy_chicken_burger=simpleFoodFactory.createFood(spicyChickenBurger),省去了将工厂实例化的过程。这种模式就叫做简单工厂模式。- 还是在上述例子中,createFood方法中必须传入foodClass才可以指定生成的food实例种类,如果将每一个细致的产品都建立对应的工厂(如cheeseBurger建立对应一个cheeseBurgerFactory),这样,生成食物时,foodClass也不必指定。此时,burgerFactory就是具体食物工厂的一层抽象。这种模式,就是抽象工厂模式。
建造者模式
建造者模式(Builder Pattern)使用多个简单的对象一步一步构建成一个复杂的对象。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
一个 Builder 类会一步一步构造最终的对象。该 Builder 类是独立于其他对象的。
使用场景
意图:将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。
主要解决:主要解决在软件系统中,有时候面临着"一个复杂对象"的创建工作,其通常由各个部分的子对象用一定的算法构成;由于需求的变化,这个复杂对象的各个部分经常面临着剧烈的变化,但是将它们组合在一起的算法却相对稳定。
何时使用:一些基本部件不会变,而其组合经常变化的时候。
如何解决:将变与不变分离开。
关键代码:建造者:创建和提供实例,导演:管理建造出来的实例的依赖关系。
应用实例:
- 去肯德基,汉堡、可乐、薯条、炸鸡翅等是不变的,而其组合是经常变化的,生成出所谓的"套餐"。
- go 中的 StringBuilder。
- 需要生成的对象具有复杂的内部结构。
- 需要生成的对象内部属性本身相互依赖。
建造者模式在创建复杂对象时非常有用,特别是当对象的构建过程涉及多个步骤或参数时。它可以提供更好的灵活性和可维护性,同时使得代码更加清晰可读。
注意事项:与工厂模式的区别是:建造者模式更加关注与零件装配的顺序。
优缺点
优点:
- 分离构建过程和表示,使得构建过程更加灵活,可以构建不同的表示。
- 封装性好,用户可以不知道对象的内部构造和细节,就可以直接建造对象;
- 系统扩展容易;
- 可以更好地控制构建过程,隐藏具体构建细节。
- 代码复用性高,可以在不同的构建过程中重复使用相同的建造者。
缺点:
- 如果产品的属性较少,建造者模式可能会导致代码冗余。
- 建造者模式增加了系统的类和对象数量。
代码实现
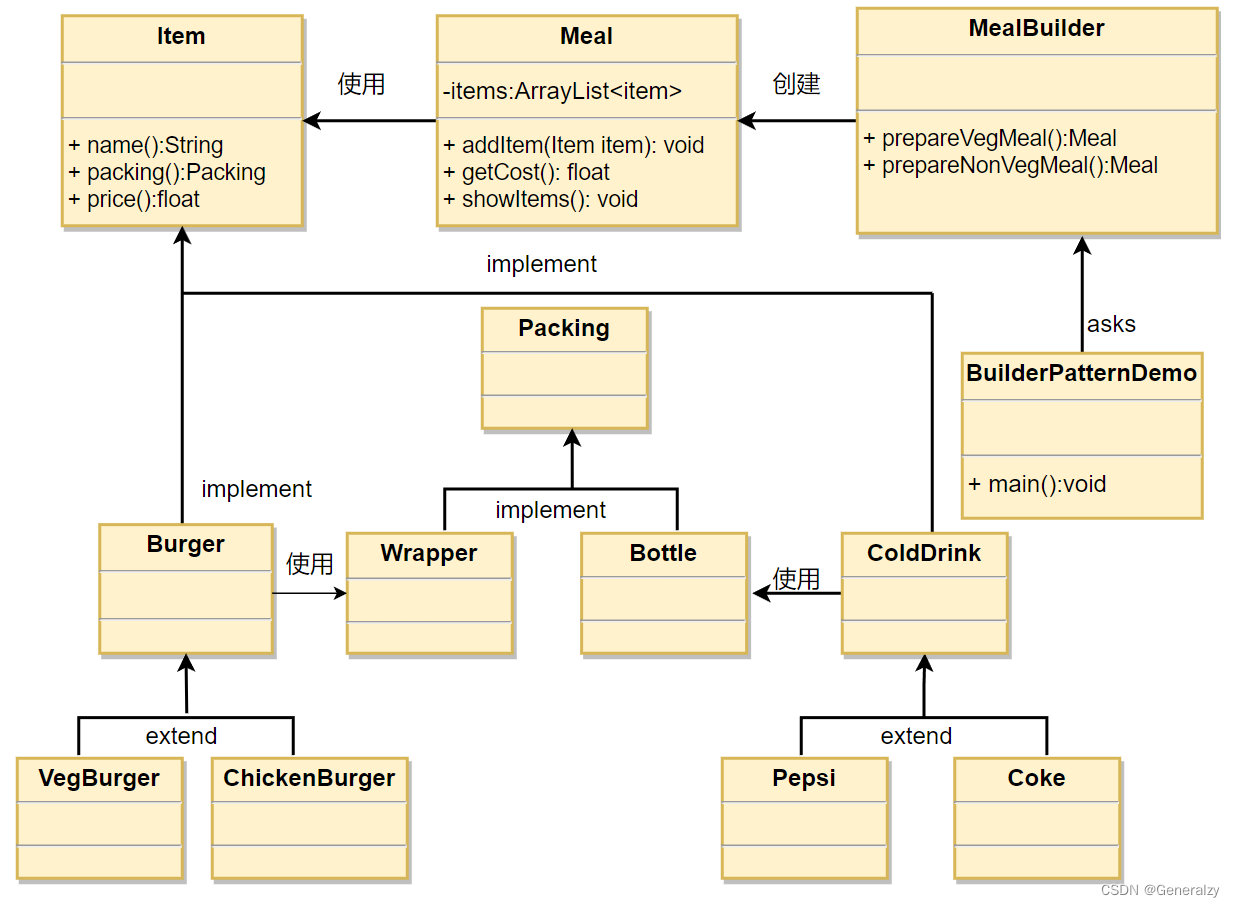
假设一个快餐店的商业案例,其中,一个典型的套餐可以是一个汉堡(Burger)和一杯冷饮(Cold drink)。汉堡(Burger)可以是素食汉堡(Veg Burger)或鸡肉汉堡(Chicken Burger),它们是包在纸盒中。冷饮(Cold drink)可以是可口可乐(coke)或百事可乐(pepsi),它们是装在瓶子中。
我们将创建一个表示食物条目(比如汉堡和冷饮)的 Item 接口和实现 Item 接口的实体类,以及一个表示食物包装的 Packing 接口和实现 Packing 接口的实体类,汉堡是包在纸盒中,冷饮是装在瓶子中。
然后我们创建一个 Meal 类,带有 Item 的 ArrayList 和一个通过结合 Item 来创建不同类型的 Meal 对象的 MealBuilder。BuilderPatternDemo 类使用 MealBuilder 来创建一个 Meal。
python代码
主餐:
class Burger():name=""price=0.0def getPrice(self):return self.pricedef setPrice(self,price):self.price=pricedef getName(self):return self.name
class cheeseBurger(Burger):def __init__(self):self.name="cheese burger"self.price=10.0
class spicyChickenBurger(Burger):def __init__(self):self.name="spicy chicken burger"self.price=15.0
小食:
class Snack():name = ""price = 0.0type = "SNACK"def getPrice(self):return self.pricedef setPrice(self, price):self.price = pricedef getName(self):return self.nameclass chips(Snack):def __init__(self):self.name = "chips"self.price = 6.0class chickenWings(Snack):def __init__(self):self.name = "chicken wings"self.price = 12.0饮料:
class Beverage():name = ""price = 0.0type = "BEVERAGE"def getPrice(self):return self.pricedef setPrice(self, price):self.price = pricedef getName(self):return self.nameclass coke(Beverage):def __init__(self):self.name = "coke"self.price = 4.0class milk(Beverage):def __init__(self):self.name = "milk"self.price = 5.0建造一个订单,因而,需要一个订单类。假设,一个订单,包括一份主食,一份小食,一种饮料。
class order():burger=""snack=""beverage=""def __init__(self,orderBuilder):self.burger=orderBuilder.bBurgerself.snack=orderBuilder.bSnackself.beverage=orderBuilder.bBeveragedef show(self):print "Burger:%s"%self.burger.getName()print "Snack:%s"%self.snack.getName()print "Beverage:%s"%self.beverage.getName()class orderBuilder():bBurger=""bSnack=""bBeverage=""def addBurger(self,xBurger):self.bBurger=xBurgerdef addSnack(self,xSnack):self.bSnack=xSnackdef addBeverage(self,xBeverage):self.bBeverage=xBeveragedef build(self):return order(self)if __name__=="__main__":order_builder=orderBuilder()order_builder.addBurger(spicyChickenBurger())order_builder.addSnack(chips())order_builder.addBeverage(milk())order_1=order_builder.build()order_1.show()
打印结果如下:
Burger:spicy chicken burger
Snack:chips
Beverage:milk
go代码
go中的string build就是很好的建造者的例子:
package mainimport "strings"func main() {builder := new(strings.Builder)builder.WriteString()s := builder.String()
}
builder通过Write类型方法,不断往buf中“建造”内容,最后通过String()方法将其show出来。
只不过go中的“小吃,主食,饮料”是byte,string,rune。
原型模式
原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式之一。
这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则采用这种模式。例如,一个对象需要在一个高代价的数据库操作之后被创建。我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库调用。
使用场景
意图:用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
主要解决:在运行期建立和删除原型。
何时使用: 1、当一个系统应该独立于它的产品创建,构成和表示时。 2、当要实例化的类是在运行时刻指定时,例如,通过动态装载。 3、为了避免创建一个与产品类层次平行的工厂类层次时。 4、当一个类的实例只能有几个不同状态组合中的一种时。建立相应数目的原型并克隆它们可能比每次用合适的状态手工实例化该类更方便一些。
如何解决:利用已有的一个原型对象,快速地生成和原型对象一样的实例。
关键代码: 1、实现克隆操作,在 JAVA 实现 Cloneable 接口,重写 clone(),在 .NET 中可以使用 Object 类的 MemberwiseClone() 方法来实现对象的浅拷贝或通过序列化的方式来实现深拷贝。 2、原型模式同样用于隔离类对象的使用者和具体类型(易变类)之间的耦合关系,它同样要求这些"易变类"拥有稳定的接口。
应用实例: 1、细胞分裂。 2、JAVA 中的 Object clone() 方法。
使用场景: 1、资源优化场景。 2、类初始化需要消化非常多的资源,这个资源包括数据、硬件资源等。 3、性能和安全要求的场景。 4、通过 new 产生一个对象需要非常繁琐的数据准备或访问权限,则可以使用原型模式。 5、一个对象多个修改者的场景。 6、一个对象需要提供给其他对象访问,而且各个调用者可能都需要修改其值时,可以考虑使用原型模式拷贝多个对象供调用者使用。 7、在实际项目中,原型模式很少单独出现,一般是和工厂方法模式一起出现,通过 clone 的方法创建一个对象,然后由工厂方法提供给调用者。原型模式已经与 Java 融为浑然一体,大家可以随手拿来使用。
注意事项:与通过对一个类进行实例化来构造新对象不同的是,原型模式是通过拷贝一个现有对象生成新对象的。浅拷贝实现 Cloneable,重写,深拷贝是通过实现 Serializable 读取二进制流。
优缺点
优点: 1、性能提高。 2、逃避构造函数的约束。
缺点: 1、配备克隆方法需要对类的功能进行通盘考虑,这对于全新的类不是很难,但对于已有的类不一定很容易,特别当一个类引用不支持串行化的间接对象,或者引用含有循环结构的时候。 2、必须实现 Cloneable 接口。
代码实现
创建一个抽象类 Shape 和扩展了 Shape 类的实体类。下一步是定义类 ShapeCache,该类把 shape 对象存储在一个 Hashtable 中,并在请求的时候返回它们的克隆。
PrototypePatternDemo 类使用 ShapeCache 类来获取 Shape 对象。
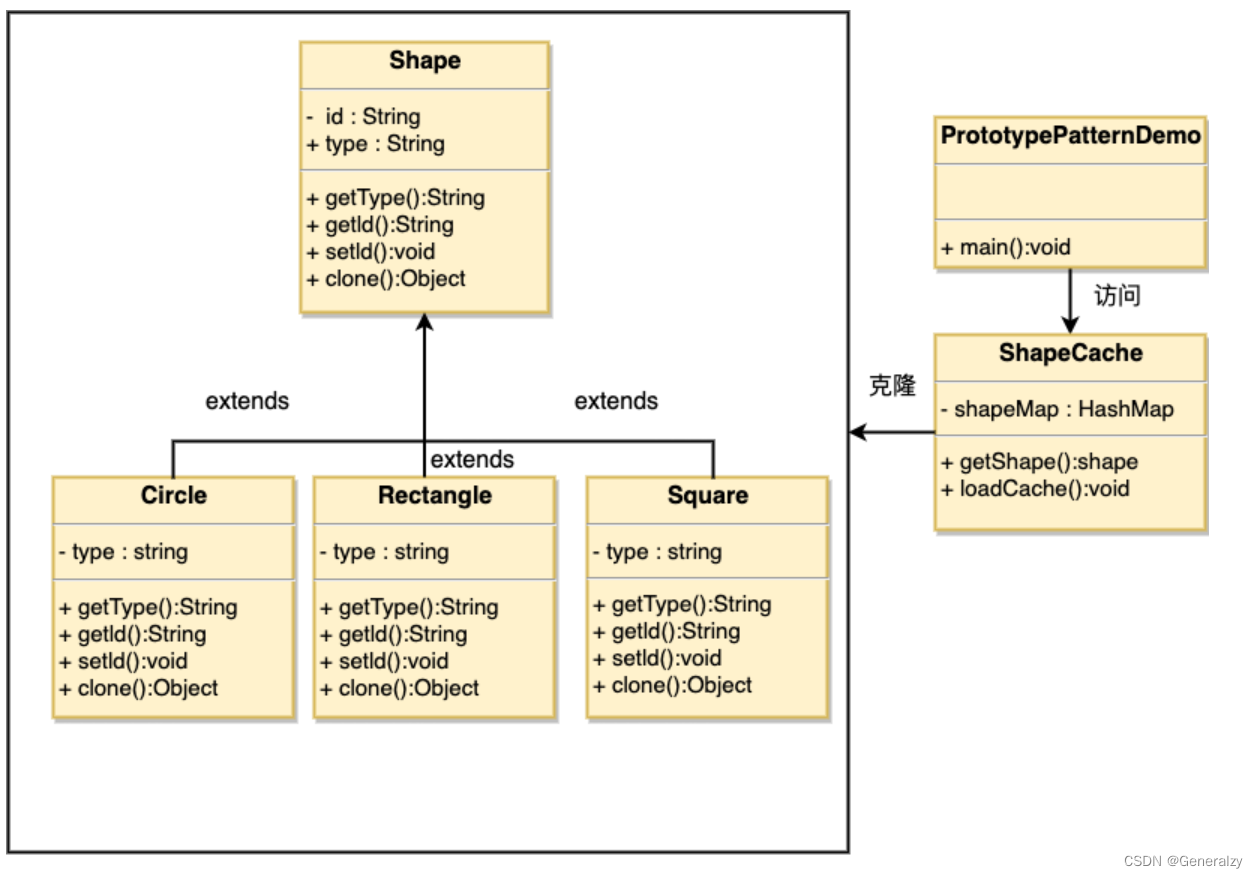
python代码
from copy import copyclass CloneInterface:def clone(self):return copy(self)class Circle(CloneInterface):passclass Square(CloneInterface):passclass ShapeCache:__cache__: dict[str, CloneInterface] = dict()@classmethoddef load_cache(cls):cls.__cache__["1"] = Circle()cls.__cache__["2"] = Square()@classmethoddef get_shape(cls, _id: str):return cls.__cache__[_id].clone()
go代码
package mainimport "fmt"type Cloneable interface {Clone() Cloneable
}type Circle struct {Id int
}func (c *Circle) Clone() Cloneable {return &Circle{Id: c.Id}
}type Square struct {Id int
}func (s *Square) Clone() Cloneable {return &Square{Id: s.Id}
}type ShapeCache struct {cache map[string]Cloneable
}func LoadCache() *ShapeCache {c := &ShapeCache{cache: map[string]Cloneable{"1": &Circle{Id: 1},"2": &Square{Id: 2},}}return c
}func (s *ShapeCache) GetShape(id string) Cloneable {return s.cache[id].Clone()
}func main() {s := LoadCache()shape := s.GetShape("1")fmt.Println(shape)
}
结构类设计模式(7种)
代理模式
在代理模式(Proxy Pattern)中,一个类代表另一个类的功能。这种类型的设计模式属于结构型模式。
在代理模式中,我们创建具有现有对象的对象,以便向外界提供功能接口。
使用场景
意图:为其他对象提供一种代理以控制对这个对象的访问。
主要解决:在直接访问对象时带来的问题,比如说:要访问的对象在远程的机器上。在面向对象系统中,有些对象由于某些原因(比如对象创建开销很大,或者某些操作需要安全控制,或者需要进程外的访问),直接访问会给使用者或者系统结构带来很多麻烦,我们可以在访问此对象时加上一个对此对象的访问层。
何时使用:想在访问一个类时做一些控制。
如何解决:增加中间层。
关键代码:实现与被代理类组合。
使用场景:按职责来划分,通常有以下使用场景:
- 远程代理。
- 虚拟代理。
- Copy-on-Write 代理。
- 保护(Protect or Access)代理。
- Cache代理。
- 防火墙(Firewall)代理。
- 业务系统的非功能性需求开发:如监控、统计、鉴权、限流、事务、幂等、日志等,这些和业务没有关系,所以可以放到Proxy中,RealSubject只关注功能性需求。
注意事项:
- 和适配器模式的区别:适配器模式主要改变所考虑对象的接口,而代理模式不能改变所代理类的接口。
- 和装饰器模式的区别:装饰器模式为了增强功能,而代理模式是为了加以控制。
主要涉及到以下几个核心角色:
- 抽象主题(Subject):定义了真实主题和代理主题的共同接口,这样在任何使用真实主题的地方都可以使用代理主题。
- 真实主题(Real Subject):实现了抽象主题接口,是代理对象所代表的真实对象。客户端直接访问真实主题,但在某些情况下,可以通过代理主题来间接访问。
- 代理(Proxy):实现了抽象主题接口,并持有对真实主题的引用。代理主题通常在真实主题的基础上提供一些额外的功能,例如延迟加载、权限控制、日志记录等。
- 客户端(Client):使用抽象主题接口来操作真实主题或代理主题,不需要知道具体是哪一个实现类。
优缺点
优点:
- 职责清晰:非常符合单一职责原则,主题对象实现真实业务逻辑,而非本职责的事务,交由代理完成;
- 扩展性强:面对主题对象可能会有的改变,代理模式在不改变对外接口的情况下,可以实现最大程度的扩展;
- 保证主题对象的处理逻辑:代理可以通过检查参数的方式,保证主题对象的处理逻辑输入在理想范围内。
缺点:
- 由于在客户端和真实主题之间增加了代理对象,因此有些类型的代理模式可能会造成请求的处理速度变慢。
- 实现代理模式需要额外的工作,有些代理模式的实现非常复杂。
代码实现

对接大量的第三方支付公司(PayU、PayTM、WX),这些公司发起支付的流程是一样的,核心是获取token,但是还要做很多琐碎、通用的工作,如校验签名、初始化订单数据、参数检查、记录日志等。这些琐碎功能如果让每一个支付类自己处理,不但是重复开发,而且后期修改时不易维护,这时候就很适合用代理模式。
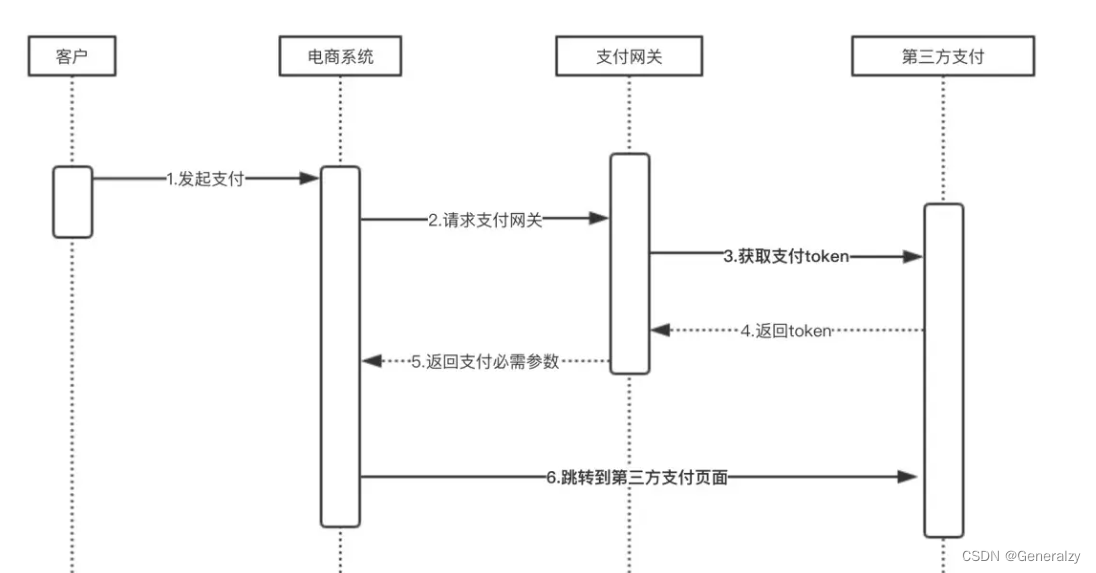
python代码
class PayInterface:def pay(self, order_id: str) -> str:raise NotImplementedError()class WxPay(PayInterface):def pay(self, order_id: str) -> str:return "从微信获取支付token"class AliPay(PayInterface):def pay(self, order_id: str) -> str:return "从阿里获取支付token"class PayProxy(PayInterface):def __init__(self, real_pay: PayInterface):self.real_pay = real_paydef pay(self, order_id: str) -> str:print("处理" + order_id)print("1校验签名")print("2格式化订单数据")print("3参数检查")print("4记录请求日志")token = self.real_pay.pay(order_id)return "http://组装" + token + "然后跳转到第三方支付"if __name__ == '__main__':proxy = PayProxy(AliPay())url = proxy.pay("阿里订单")print(url)
执行结果:
处理阿里订单
1校验签名
2格式化订单数据
3参数检查
4记录请求日志
http://组装从阿里获取支付token然后跳转到第三方支付
go代码
package mainimport ("fmt"
)type PaymentService interface {pay(string) string
}type WXPay struct {
}func (w *WXPay) pay(order string) string {return "从微信获取支付token"
}type AliPay struct {
}func (a *AliPay) pay(order string) string {return "从阿里获取支付token"
}type PaymentProxy struct {realPay PaymentService
}func (p *PaymentProxy) pay(order string) string {fmt.Println("处理" + order)fmt.Println("1校验签名")fmt.Println("2格式化订单数据")fmt.Println("3参数检查")fmt.Println("4记录请求日志")token := p.realPay.pay(order)return "http://组装" + token + "然后跳转到第三方支付"
}
func main() {proxy := &PaymentProxy{realPay: &AliPay{},}url := proxy.pay("阿里订单")fmt.Println(url)
}
再使用上工厂模式,就全自动化了,增加新的支付类只需要实现接口即可。
装饰器模式
装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构。这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装。
装饰器模式通过将对象包装在装饰器类中,以便动态地修改其行为。
这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能。
使用场景
意图:动态地给一个对象添加一些额外的职责。就增加功能来说,装饰器模式相比生成子类更为灵活。
主要解决:一般的,我们为了扩展一个类经常使用继承方式实现,由于继承为类引入静态特征,并且随着扩展功能的增多,子类会很膨胀。
何时使用:在不想增加很多子类的情况下扩展类。
如何解决:将具体功能职责划分,同时继承装饰者模式。
使用场景:
- 扩展一个类的功能。
- 动态增加功能,动态撤销。
注意事项:可代替继承。
装饰器模式包含以下几个核心角色:
- 抽象组件(Component):定义了原始对象和装饰器对象的公共接口或抽象类,可以是具体组件类的父类或接口。
- 具体组件(Concrete Component):是被装饰的原始对象,它定义了需要添加新功能的对象。
- 抽象装饰器(Decorator):继承自抽象组件,它包含了一个抽象组件对象,并定义了与抽象组件相同的接口,同时可以通过组合方式持有其他装饰器对象。
- 具体装饰器(Concrete Decorator):实现了抽象装饰器的接口,负责向抽象组件添加新的功能。具体装饰器通常会在调用原始对象的方法之前或之后执行自己的操作。
装饰器模式通过嵌套包装多个装饰器对象,可以实现多层次的功能增强。每个具体装饰器类都可以选择性地增加新的功能,同时保持对象接口的一致性。
优缺点
优点:
- 装饰类和被装饰类可以独立发展,不会相互耦合,装饰模式是继承的一个替代模式,装饰模式可以动态扩展一个实现类的功能。
- 可以轻量级的扩展被装饰对象的功能;
缺点:
- 多层装饰比较复杂。
代码实现
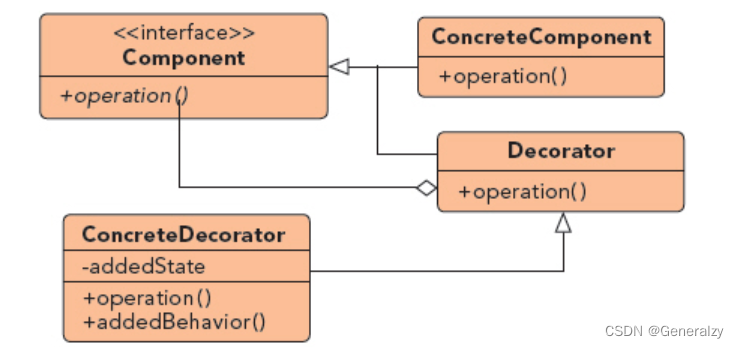
python代码
python原生支持装饰器,并且提供@符语法糖来简化装饰器的使用,包括classmethod,cached…都是python内置的装饰器。
def log(func):def wrapper(*args, **kw):print 'call %s():' % func.__name__return func(*args, **kw)return wrapper@log
def now():print '2016-12-04'
if __name__=="__main__":now()
打印如下:
call now():
2016-12-04
go代码
go的装饰器可能不会像python一样随心所欲,但这不代表你不可以使用装饰器,只是需要更加具体一些,比如实现一个中间件:
package mainimport ("fmt""log""net/http"
)func isAuthorized(endpoint func(http.ResponseWriter, *http.Request)) http.Handler {return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {fmt.Println("Checking to see if Authorized header set...")if val, ok := r.Header["Authorized"]; ok {fmt.Println(val)if val[0] == "true" {fmt.Println("Header is set! We can serve content!")endpoint(w, r)}} else {fmt.Println("Not Authorized!!")fmt.Fprintf(w, "Not Authorized!!")}})
}func homePage(w http.ResponseWriter, r *http.Request) {fmt.Println("Endpoint Hit: homePage")fmt.Fprintf(w, "Welcome to the HomePage!")
}func handleRequests() {http.Handle("/", isAuthorized(homePage))log.Fatal(http.ListenAndServe(":8081", nil))
}func main() {handleRequests()
}
这突出了装饰器模式的主要优点,在我们的代码库中包装代码非常简单。
适配器模式
适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁。这种类型的设计模式属于结构型模式,它结合了两个独立接口的功能。
这种模式涉及到一个单一的类,该类负责加入独立的或不兼容的接口功能。举个真实的例子,读卡器是作为内存卡和笔记本之间的适配器。将内存卡插入读卡器,再将读卡器插入笔记本,这样就可以通过笔记本来读取内存卡。
使用场景
意图:**将一个类的接口转换成客户希望的另外一个接口。**适配器模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
主要解决:主要解决在软件系统中,常常要将一些"现存的对象"放到新的环境中,而新环境要求的接口是现对象不能满足的。
何时使用: 1、系统需要使用现有的类,而此类的接口不符合系统的需要。 2、想要建立一个可以重复使用的类,用于与一些彼此之间没有太大关联的一些类,包括一些可能在将来引进的类一起工作,这些源类不一定有一致的接口。 3、通过接口转换,将一个类插入另一个类系中。(比如老虎和飞禽,现在多了一个飞虎,在不增加实体的需求下,增加一个适配器,在里面包容一个虎对象,实现飞的接口。)
如何解决:继承或依赖(推荐)。
关键代码:适配器继承或依赖已有的对象,实现想要的目标接口。
应用实例: 1、美国电器 110V,中国 220V,就要有一个适配器将 110V 转化为 220V。 2、JAVA JDK 1.1 提供了 Enumeration 接口,而在 1.2 中提供了 Iterator 接口,想要使用 1.2 的 JDK,则要将以前系统的 Enumeration 接口转化为 Iterator 接口,这时就需要适配器模式。 3、在 LINUX 上运行 WINDOWS 程序。
使用场景:有动机地修改一个正常运行的系统的接口,这时应该考虑使用适配器模式。
注意事项:适配器不是在详细设计时添加的,而是解决正在服役的项目的问题。
优缺点
优点:
1、可以让任何两个没有关联的类一起运行。
2、提高了类的复用。
3、增加了类的透明度。
4、灵活性好。
缺点:
-
过多地使用适配器,会让系统非常零乱,不易整体进行把握。比如,明明看到调用的是 A 接口,其实内部被适配成了 B 接口的实现,一个系统如果太多出现这种情况,无异于一场灾难。因此如果不是很有必要,可以不使用适配器,而是直接对系统进行重构。
-
适配器模式与原配接口相比,毕竟增加了一层调用关系,所以,在设计系统时,不要使用适配器模式。
代码实现
假设有一个 MediaPlayer 接口和一个实现了 MediaPlayer 接口的实体类 AudioPlayer。默认情况下,AudioPlayer 可以播放 mp3 格式的音频文件。
还有另一个接口 AdvancedMediaPlayer 和实现了 AdvancedMediaPlayer 接口的实体类。该类可以播放 vlc 和 mp4 格式的文件。
想要让 AudioPlayer 播放其他格式的音频文件。为了实现这个功能,需要创建一个实现了 MediaPlayer 接口的适配器类 MediaAdapter,并使用 AdvancedMediaPlayer 对象来播放所需的格式。
AudioPlayer 使用适配器类 MediaAdapter 传递所需的音频类型,不需要知道能播放所需格式音频的实际类。AdapterPatternDemo 类使用 AudioPlayer 类来播放各种格式。
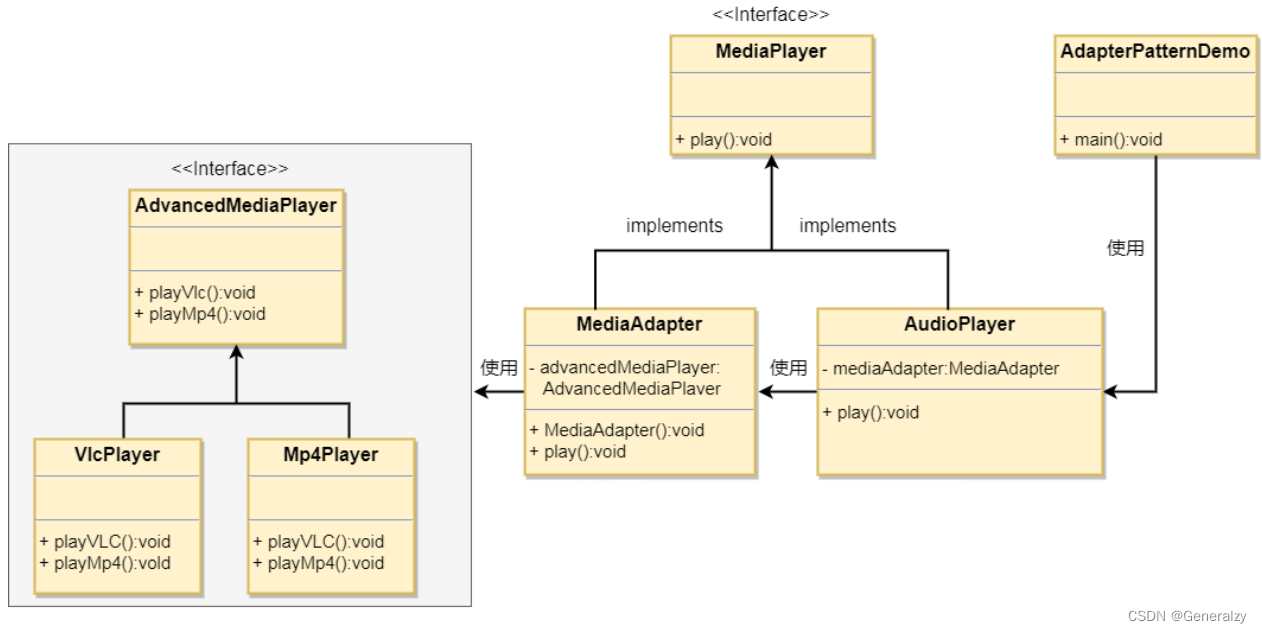
python代码
假设某公司A与某公司B需要合作,公司A需要访问公司B的人员信息,但公司A与公司B协议接口不同,该如何处理?先将公司A和公司B针对各自的人员信息访问系统封装了对象接口。
class ACpnStaff:name=""id=""phone=""def __init__(self,id):self.id=iddef getName(self):print "A protocol getName method...id:%s"%self.idreturn self.namedef setName(self,name):print "A protocol setName method...id:%s"%self.idself.name=namedef getPhone(self):print "A protocol getPhone method...id:%s"%self.idreturn self.phonedef setPhone(self,phone):print "A protocol setPhone method...id:%s"%self.idself.phone=phone
class BCpnStaff:name=""id=""telephone=""def __init__(self,id):self.id=iddef get_name(self):print "B protocol get_name method...id:%s"%self.idreturn self.namedef set_name(self,name):print "B protocol set_name method...id:%s"%self.idself.name=namedef get_telephone(self):print "B protocol get_telephone method...id:%s"%self.idreturn self.telephonedef set_telephone(self,telephone):print "B protocol get_name method...id:%s"%self.idself.telephone=telephone
为在A公司平台复用B公司接口,直接调用B公司人员接口是个办法,但会对现在业务流程造成不确定的风险。为减少耦合,规避风险,我们需要一个帮手,就像是转换电器电压的适配器一样,这个帮手就是协议和接口转换的适配器。适配器构造如下:
class CpnStaffAdapter:b_cpn=""def __init__(self,id):self.b_cpn=BCpnStaff(id)def getName(self):return self.b_cpn.get_name()def getPhone(self):return self.b_cpn.get_telephone()def setName(self,name):self.b_cpn.set_name(name)def setPhone(self,phone):self.b_cpn.set_telephone(phone)
适配器将B公司人员接口封装,而对外接口形式与A公司人员接口一致,达到用A公司人员接口访问B公司人员信息的效果。
业务示例如下:
if __name__=="__main__":acpn_staff=ACpnStaff("123")acpn_staff.setName("X-A")acpn_staff.setPhone("10012345678")print "A Staff Name:%s"%acpn_staff.getName()print "A Staff Phone:%s"%acpn_staff.getPhone()bcpn_staff=CpnStaffAdapter("456")bcpn_staff.setName("Y-B")bcpn_staff.setPhone("99987654321")print "B Staff Name:%s"%bcpn_staff.getName()print "B Staff Phone:%s"%bcpn_staff.getPhone()
go代码
package maintype ACompany interface {GetName() string
}type ACompanyStaff struct {name string
}func (a *ACompanyStaff) GetName() string {return a.name
}type BCompanyStaff struct {name string
}func (b *BCompanyStaff) GetStaffName() string {return b.name
}type CompanyStaffAdapter struct {b *BCompanyStaff
}func (c *CompanyStaffAdapter) GetName() string {return c.b.name
}func main() {}
门面模式/外观模式/Facade Pattern
外观模式(Facade Pattern)隐藏系统的复杂性,并向客户端提供了一个客户端可以访问系统的接口。这种类型的设计模式属于结构型模式,它向现有的系统添加一个接口,来隐藏系统的复杂性。
这种模式涉及到一个单一的类,该类提供了客户端请求的简化方法和对现有系统类方法的委托调用。
使用场景
意图:为子系统中的一组接口提供一个一致的界面,外观模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
主要解决:降低访问复杂系统的内部子系统时的复杂度,简化客户端之间的接口。
何时使用: 1、客户端不需要知道系统内部的复杂联系,整个系统只需提供一个"接待员"即可。 2、定义系统的入口。
如何解决:客户端不与系统耦合,外观类与系统耦合。
关键代码:在客户端和复杂系统之间再加一层,这一层将调用顺序、依赖关系等处理好。
使用场景:
- 为复杂的模块或子系统提供外界访问的模块。
- 子系统相对独立。
- 预防低水平人员带来的风险。
注意事项:在层次化结构中,可以使用外观模式定义系统中每一层的入口。
外观模式涉及以下核心角色:
-
外观(Facade):提供一个简化的接口,封装了系统的复杂性。外观模式的客户端通过与外观对象交互,而无需直接与系统的各个组件打交道。
-
子系统(Subsystem):由多个相互关联的类组成,负责系统的具体功能。外观对象通过调用这些子系统来完成客户端的请求。
-
客户端(Client):使用外观对象来与系统交互,而不需要了解系统内部的具体实现。
优缺点
优点: 1、减少系统相互依赖。 2、提高灵活性。 3、提高了整体系统的安全性:封装起的系统对外的接口才可以用,隐藏了很多内部接口细节,若方法不允许使用,则在门面中可以进行灵活控制。
缺点:门面模式的缺点在于,不符合开闭原则,一旦系统成形后需要修改,几乎只能重写门面代码,这比继承或者覆写等方式,或者其它一些符合开闭原则的模式风险都会大一些。
代码实现
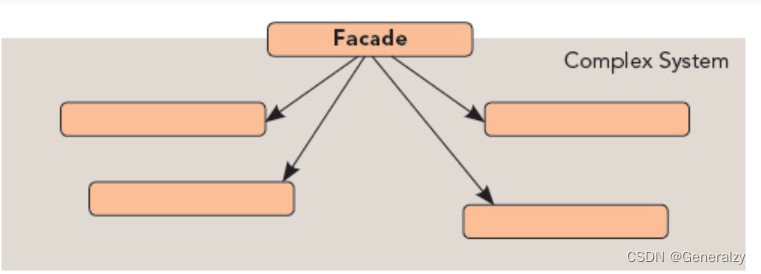
假设有一组火警报警系统,由三个子元件构成:一个警报器,一个喷水器,一个自动拨打电话的装置。
python代码
class AlarmSensor:def run(self):print "Alarm Ring..."
class WaterSprinker:def run(self):print "Spray Water..."
class EmergencyDialer:def run(self):print "Dial 119..."
在业务中如果需要将三个部件启动,例如,如果有一个烟雾传感器,检测到了烟雾。在业务环境中需要做如下操作:
if __name__=="__main__":alarm_sensor=AlarmSensor()water_sprinker=WaterSprinker()emergency_dialer=EmergencyDialer()alarm_sensor.run()water_sprinker.run()emergency_dialer.run()
但如果在多个业务场景中需要启动三个部件,怎么办?需要将其进行封装,在设计模式中,被封装成的新对象,叫做门面。门面构建如下:
class EmergencyFacade:def __init__(self):self.alarm_sensor=AlarmSensor()self.water_sprinker=WaterSprinker()self.emergency_dialer=EmergencyDialer()def runAll(self):self.alarm_sensor.run()self.water_sprinker.run()self.emergency_dialer.run()if __name__=="__main__":emergency_facade=EmergencyFacade()emergency_facade.runAll()
go代码
package maintype AlarmSensor struct {
}func (al *AlarmSensor) run() {print("Alarm Ring...")
}type WaterSprinker struct {
}func (ws *WaterSprinker) run() {print("Spray Water...")
}type EmergencyDialer struct {
}func (ed *EmergencyDialer) run() {print("Dial 119...")
}type EmergencyFacade struct {al *AlarmSensorws *WaterSprinkered *EmergencyDialer
}func (face *EmergencyFacade) Run() {face.al.run()face.ws.run()face.ed.run()
}func main() {}
组合模式
组合模式(Composite Pattern),又叫部分整体模式,是用于把一组相似的对象当作一个单一的对象。组合模式依据树形结构来组合对象,用来表示部分以及整体层次。这种类型的设计模式属于结构型模式,它创建了对象组的树形结构。
这种模式创建了一个包含自己对象组的类。该类提供了修改相同对象组的方式。
使用场景
意图:将对象组合成树形结构以表示"部分-整体"的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。
主要解决:它在我们树型结构的问题中,模糊了简单元素和复杂元素的概念,客户程序可以像处理简单元素一样来处理复杂元素,从而使得客户程序与复杂元素的内部结构解耦。
何时使用: 1、您想表示对象的部分-整体层次结构(树形结构)。 2、您希望用户忽略组合对象与单个对象的不同,用户将统一地使用组合结构中的所有对象。
如何解决:树枝和叶子实现统一接口,树枝内部组合该接口。
关键代码:树枝内部组合该接口,并且含有内部属性 List,里面放 Component。
使用场景:部分、整体场景,如树形菜单,文件、文件夹的管理。
注意事项:定义时为具体类。
组合模式的核心角色包括:
-
组件(Component):定义了组合中所有对象的通用接口,可以是抽象类或接口。它声明了用于访问和管理子组件的方法,包括添加、删除、获取子组件等。
-
叶子节点(Leaf):表示组合中的叶子节点对象,叶子节点没有子节点。它实现了组件接口的方法,但通常不包含子组件。
-
复合节点(Composite):表示组合中的复合对象,复合节点可以包含子节点,可以是叶子节点,也可以是其他复合节点。它实现了组件接口的方法,包括管理子组件的方法。
-
客户端(Client):通过组件接口与组合结构进行交互,客户端不需要区分叶子节点和复合节点,可以一致地对待整体和部分。
优缺点
优点: 1、高层模块调用简单。 2、节点自由增加。
缺点:在使用组合模式时,其叶子和树枝的声明都是实现类,而不是接口,违反了依赖倒置原则。
代码实现
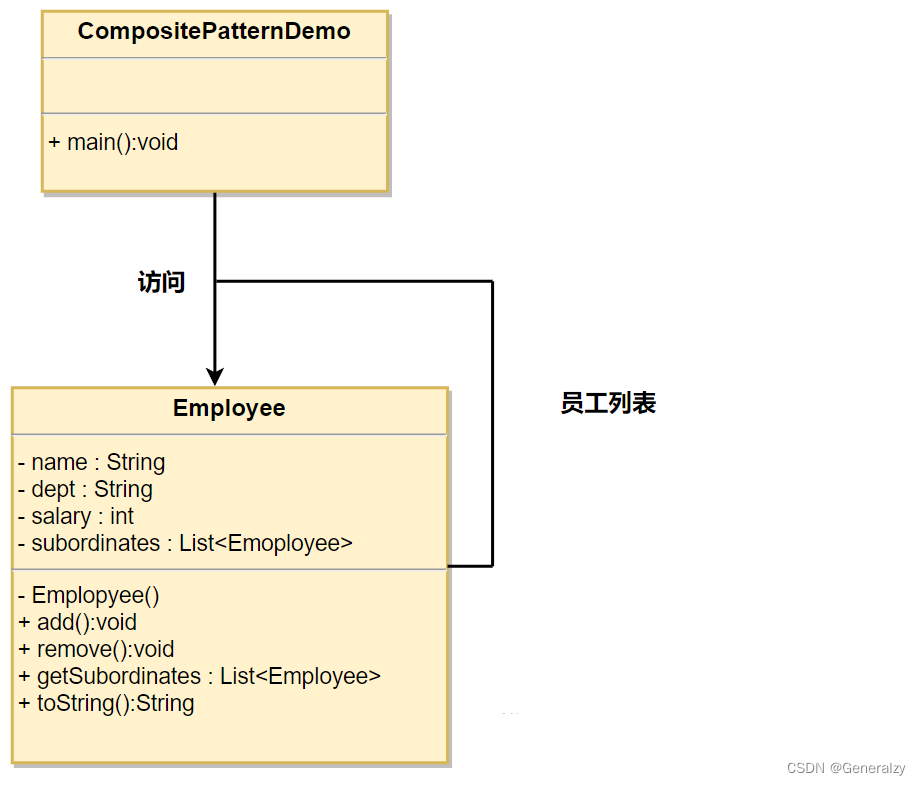
假设有一个类 Employee,该类被当作组合模型类。CompositePatternDemo 类使用 Employee 类来添加部门层次结构,并打印所有员工。
python代码
class Employee:def __init__(self, name: str, subordinate: list["Employee"] = None):self.name = nameself.subordinate = [] if subordinate is None else subordinatedef add(self, employee: "Employee"):self.subordinate.append(employee)def remove(self, employee: "Employee"):self.subordinate.remove(employee)def get_subordinate(self):return [sub.name for sub in self.subordinate]if __name__ == '__main__':CEO = Employee("generalzy")dog1 = Employee("dg1")dog2 = Employee("dg2")CEO.add(dog1)dog1.add(dog2)print(CEO.get_subordinate())CEO.remove(dog1)print(CEO.get_subordinate())
执行程序,输出结果为:
['dg1']
[]
go代码
package mainimport "fmt"type File struct {name stringcontent []bytefiles []*File
}func NewFile(name string) *File {return &File{name: name,content: nil,files: nil,}
}func (f *File) Add(file *File) {if f.files == nil {f.files = make([]*File, 0, 1)}f.files = append(f.files, file)
}func (f *File) Remove(file *File) {if f.files == nil {f.files = make([]*File, 0, 1)}idx := 0for index := 0; index < len(f.files); index++ {if f.files[index] == file {idx = indexbreak}}f.files = append(f.files[:idx], f.files[idx+1:]...)
}func (f *File) GetFiles() []string {r := make([]string, 0, len(f.files))for _, file := range f.files {r = append(r, file.name)}return r
}func main() {f := NewFile("dir1")f.Add(NewFile("dir2"))fmt.Println(f.GetFiles())f.Remove(NewFile("file1"))fmt.Println(f.GetFiles())
}
[dir2]
[]
享元模式
享元模式(Flyweight Pattern)主要用于减少创建对象的数量,以减少内存占用和提高性能。这种类型的设计模式属于结构型模式,它提供了减少对象数量从而改善应用所需的对象结构的方式。
享元模式尝试重用现有的同类对象,如果未找到匹配的对象,则创建新对象。
使用场景
意图:运用共享技术有效地支持大量细粒度的对象。
主要解决:在有大量对象时,有可能会造成内存溢出,我们把其中共同的部分抽象出来,如果有相同的业务请求,直接返回在内存中已有的对象,避免重新创建。
何时使用: 1、系统中有大量对象。 2、这些对象消耗大量内存。 3、这些对象的状态大部分可以外部化。 4、这些对象可以按照内蕴状态分为很多组,当把外蕴对象从对象中剔除出来时,每一组对象都可以用一个对象来代替。 5、系统不依赖于这些对象身份,这些对象是不可分辨的。
如何解决:用唯一标识码判断,如果在内存中有,则返回这个唯一标识码所标识的对象。
使用场景: 1、系统有大量相似对象。 2、需要缓冲池的场景。
关键代码:用 HashMap 存储这些对象。
注意事项: 1、注意划分外部状态和内部状态,否则可能会引起线程安全问题。 2、这些类必须有一个工厂对象加以控制。
享元模式包含以下几个核心角色:
-
享元工厂(Flyweight Factory):负责创建和管理享元对象,通常包含一个池(缓存)用于存储和复用已经创建的享元对象。
-
具体享元(Concrete Flyweight):实现了抽象享元接口,包含了内部状态和外部状态。内部状态是可以被共享的,而外部状态则由客户端传递。
-
抽象享元(Flyweight):定义了具体享元和非共享享元的接口,通常包含了设置外部状态的方法。
-
客户端(Client):使用享元工厂获取享元对象,并通过设置外部状态来操作享元对象。客户端通常不需要关心享元对象的具体实现。
优缺点
优点:大大减少对象的创建,降低系统的内存,使效率提高。
缺点:
- 提高了系统的复杂度,需要分离出外部状态和内部状态,而且外部状态具有固有化的性质,不应该随着内部状态的变化而变化,否则会造成系统的混乱。
- 享元模式中需要额外注意线程安全问题。
代码实现
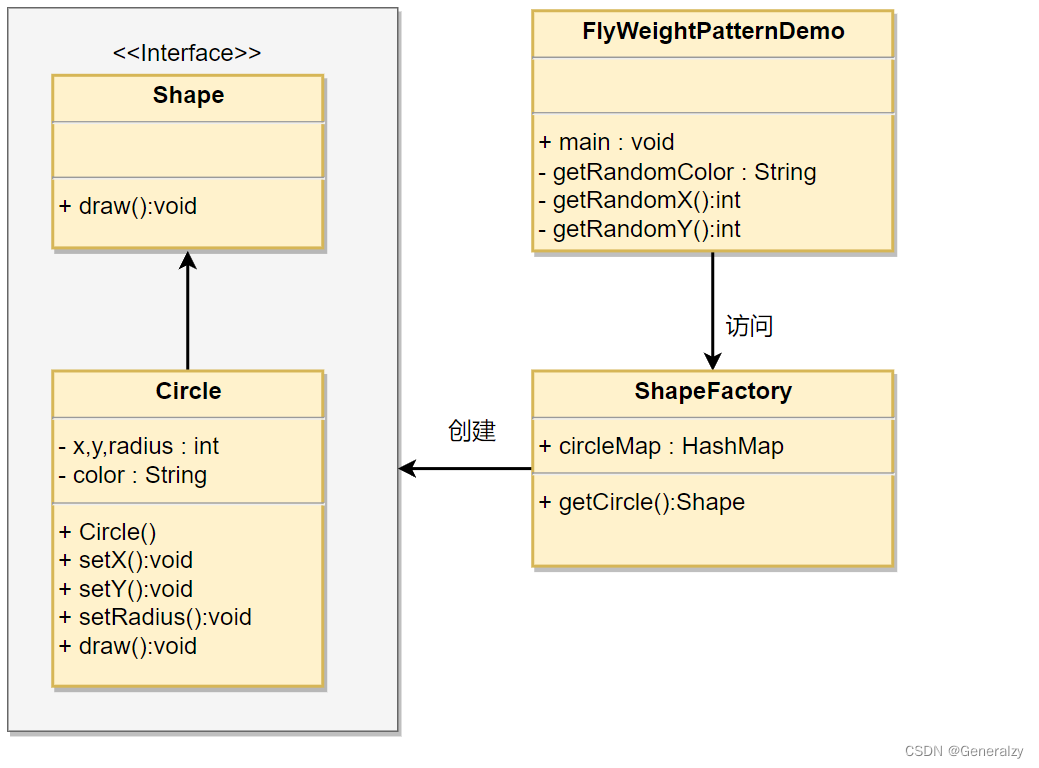
创建一个 Shape 接口和实现了 Shape 接口的实体类 Circle。下一步是定义工厂类 ShapeFactory。
ShapeFactory 有一个 Circle 的 HashMap,其中键名为 Circle 对象的颜色。无论何时接收到请求,都会创建一个特定颜色的圆。ShapeFactory 检查它的 HashMap 中的 circle 对象,如果找到 Circle 对象,则返回该对象,否则将创建一个存储在 hashmap 中以备后续使用的新对象,并把该对象返回到客户端。
FlyWeightPatternDemo 类使用 ShapeFactory 来获取 Shape 对象。它将向 ShapeFactory 传递信息(red / green / blue/ black / white),以便获取它所需对象的颜色。
python代码
class Shape:def draw(self):raise NotImplementedError()class Circle(Shape):def __init__(self, color: str):self.color = colordef draw(self):print(f"create a {self.color} circle")class ShapeFactory:__circle_map__: dict[str, Circle] = dict()def draw_circle(self, color: str):if circle := self.__circle_map__.get(color):return circle.draw()c = Circle(color)c.draw()self.__circle_map__[color] = cif __name__ == '__main__':factory = ShapeFactory()for i in range(20):factory.draw_circle("")
go代码
type Image struct {Name stringData string
}type ImageFactory struct {images map[string]*Imagelock sync.Mutex
}func NewImageFactory() *ImageFactory {return &ImageFactory{images: make(map[string]*Image),}
}func (factory *ImageFactory) GetImage(name string) *Image {factory.lock.Lock()defer factory.lock.Unlock()if img, ok := factory.images[name]; ok {return img}img := &Image{Name: name,Data: fmt.Sprintf("data of %s", name),}factory.images[name] = imgreturn img
}func (factory *ImageFactory) PutImage(img *Image) {factory.lock.Lock()defer factory.lock.Unlock()factory.images[img.Name] = img
}
对于池化的概念,go语言默认提供了sync.Pool,可以更容易实现一个对象的复用
package mainimport ("fmt""sync"
)// Image 表示图像对象
type Image struct {Name stringData []byte
}// ImageFactory 表示图像工厂,用于创建和缓存图像对象
type ImageFactory struct {pool sync.Pool
}// NewImageFactory 创建一个新的图像工厂
func NewImageFactory() *ImageFactory {factory := &ImageFactory{}factory.pool.New = func() interface{} {return &Image{}}return factory
}// GetImage 根据名称获取图像对象,如果对象池中存在相同名称的对象,则直接返回;否则创建一个新对象并将其放入对象池中
func (factory *ImageFactory) GetImage(name string) *Image {obj := factory.pool.Get().(*Image)if obj.Name != name {fmt.Println("Creating new image object")obj.Name = nameobj.Data = []byte(fmt.Sprintf("Image data for %s", name))}return obj
}// PutImage 将使用完的图像对象放回对象池中,以供下次使用
func (factory *ImageFactory) PutImage(img *Image) {factory.pool.Put(img)
}func main() {factory := NewImageFactory()img1 := factory.GetImage("image1")img2 := factory.GetImage("image2")img3 := factory.GetImage("image1")fmt.Println(img1.Data)fmt.Println(img2.Data)fmt.Println(img3.Data)factory.PutImage(img1)factory.PutImage(img2)factory.PutImage(img3)
}
桥接模式
桥接(Bridge)是用于把抽象化与实现化解耦,使得二者可以独立变化。这种类型的设计模式属于结构型模式,它通过提供抽象化和实现化之间的桥接结构,来实现二者的解耦。
这种模式涉及到一个作为桥接的接口,使得实体类的功能独立于接口实现类,这两种类型的类可被结构化改变而互不影响。
桥接模式的目的是将抽象与实现分离,使它们可以独立地变化,该模式通过将一个对象的抽象部分与它的实现部分分离,使它们可以独立地改变。它通过组合的方式,而不是继承的方式,将抽象和实现的部分连接起来。
使用场景
意图:将抽象部分与实现部分分离,使它们都可以独立的变化。
主要解决:在有多种可能会变化的情况下,用继承会造成类爆炸问题,扩展起来不灵活。
何时使用:实现系统可能有多个角度分类,每一种角度都可能变化。
如何解决:把这种多角度分类分离出来,让它们独立变化,减少它们之间耦合。
关键代码:抽象类依赖实现类。
使用场景:
1、如果一个系统需要在构件的抽象化角色和具体化角色之间增加更多的灵活性,避免在两个层次之间建立静态的继承联系,通过桥接模式可以使它们在抽象层建立一个关联关系。
2、对于那些不希望使用继承或因为多层次继承导致系统类的个数急剧增加的系统,桥接模式尤为适用。
3、一个类存在两个独立变化的维度,且这两个维度都需要进行扩展。
注意事项:对于两个独立变化的维度,使用桥接模式再适合不过了。
以下是桥接模式的几个关键角色:
抽象(Abstraction):定义抽象接口,通常包含对实现接口的引用。
扩展抽象(Refined Abstraction):对抽象的扩展,可以是抽象类的子类或具体实现类。
实现(Implementor):定义实现接口,提供基本操作的接口。
具体实现(Concrete Implementor):实现实现接口的具体类。
优缺点
优点: 1、抽象和实现的分离。 2、优秀的扩展能力。 3、实现细节对客户透明。
缺点:桥接模式的引入会增加系统的理解与设计难度,由于聚合关联关系建立在抽象层,要求开发者针对抽象进行设计与编程。
代码实现
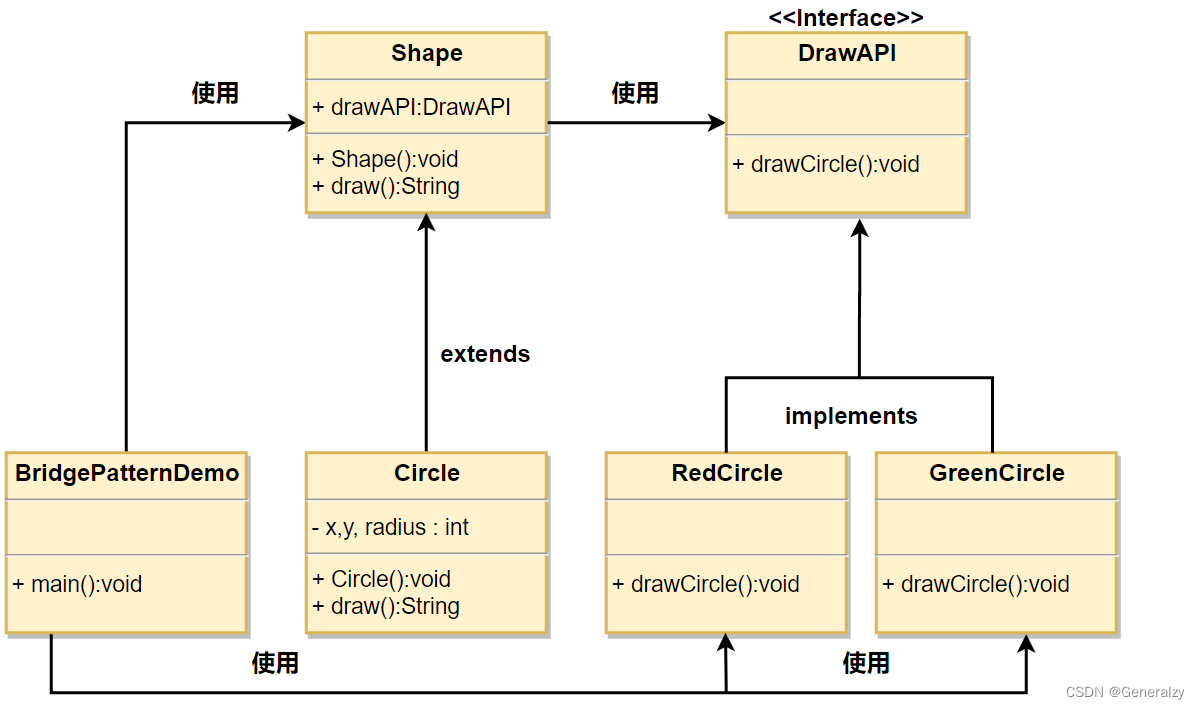
有一个作为桥接实现的 DrawAPI 接口和实现了 DrawAPI 接口的实体类 RedCircle、GreenCircle。Shape 是一个抽象类,将使用 DrawAPI 的对象。BridgePatternDemo 类使用 Shape 类来画出不同颜色的圆。
python代码
class DrawApi:def draw_circle(self, x: int, y: int, radius: int):raise NotImplementedError()class RedCircle(DrawApi):def draw_circle(self, x: int, y: int, radius: int):print(f"create a red circle which radius is {radius} at ({x},{y})")class GreenCircle(DrawApi):def draw_circle(self, x: int, y: int, radius: int):print(f"create a green circle which radius is {radius} at ({x},{y})")class ShapeInterface:def __init__(self, api: DrawApi):self.draw_api = apidef draw(self):raise NotImplementedError()class Circle(ShapeInterface):def __init__(self, x: int, y: int, radius: int, api: DrawApi):super().__init__(api)self.x = xself.y = yself.radius = radiusdef draw(self):self.draw_api.draw_circle(self.x, self.y, self.radius)if __name__ == '__main__':red = Circle(1, 2, 3, RedCircle())green = Circle(4, 5, 6, GreenCircle())red.draw()green.draw()
执行结果:
create a red circle which radius is 3 at (1,2)
create a green circle which radius is 6 at (4,5)
go代码
package mainimport "fmt"/*** @Description: 消息发送接口*/
type MessageSend interface {send(msg string)
}/*** @Description: 短信消息*/
type SMS struct {
}func (s *SMS) send(msg string) {fmt.Println("sms 发送的消息内容为: " + msg)
}/*** @Description: 邮件消息*/
type Email struct {
}func (e *Email) send(msg string) {fmt.Println("email 发送的消息内容为: " + msg)
}/*** @Description: AppPush消息*/
type AppPush struct {
}func (a *AppPush) send(msg string) {fmt.Println("appPush 发送的消息内容为: " + msg)
}/*** @Description: 站内信消息*/
type Letter struct {
}func (l *Letter) send(msg string) {fmt.Println("站内信 发送的消息内容为: " + msg)
}/*** @Description: 用户触达父类,包含触达方式数组messageSends*/
type Touch struct {messageSends []MessageSend
}/*** @Description: 触达方法,调用每一种方式进行触达* @receiver t* @param msg*/
func (t *Touch) do(msg string) {for _, s := range t.messageSends {s.send(msg)}
}/*** @Description: 紧急消息做用户触达*/
type TouchUrgent struct {base Touch
}/*** @Description: 紧急消息,先从db中获取各种信息,然后使用各种触达方式通知用户* @receiver t* @param msg*/
func (t *TouchUrgent) do(msg string) {fmt.Println("touch urgent 从db获取接收人等信息")t.base.do(msg)
}/*** @Description: 普通消息做用户触达*/
type TouchNormal struct {base Touch
}/*** @Description: 普通消息,先从文件中获取各种信息,然后使用各种触达方式通知用户* @receiver t* @param msg*/
func (t *TouchNormal) do(msg string) {fmt.Println("touch normal 从文件获取接收人等信息")t.base.do(msg)
}func main() {//触达方式sms := &SMS{}appPush := &AppPush{}letter := &Letter{}email := &Email{}//根据触达类型选择触达方式fmt.Println("-------------------touch urgent")touchUrgent := TouchUrgent{base: Touch{messageSends: []MessageSend{sms, appPush, letter, email},},}touchUrgent.do("urgent情况")fmt.Println("-------------------touch normal")touchNormal := TouchNormal{ //base: Touch{messageSends: []MessageSend{sms, appPush, letter, email},},}touchNormal.do("normal情况")
}
行为类设计模式(11种)
策略模式
在策略模式(Strategy Pattern)中一个类的行为或其算法可以在运行时更改。这种类型的设计模式属于行为型模式。
在策略模式定义了一系列算法或策略,并将每个算法封装在独立的类中,使得它们可以互相替换。通过使用策略模式,可以在运行时根据需要选择不同的算法,而不需要修改客户端代码。
在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。
使用场景
意图:定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。
主要解决:在有多种算法相似的情况下,使用 if…else 所带来的复杂和难以维护。
何时使用:一个系统有许多许多类,而区分它们的只是他们直接的行为。
如何解决:将这些算法封装成一个一个的类,任意地替换。
关键代码:实现同一个接口。
使用场景: 1、如果在一个系统里面有许多类,它们之间的区别仅在于它们的行为,那么使用策略模式可以动态地让一个对象在许多行为中选择一种行为。 2、一个系统需要动态地在几种算法中选择一种。 3、如果一个对象有很多的行为,如果不用恰当的模式,这些行为就只好使用多重的条件选择语句来实现。
注意事项:如果一个系统的策略多于四个,就需要考虑使用混合模式,解决策略类膨胀的问题。
策略模式包含以下几个核心角色:
- 环境(Context):维护一个对策略对象的引用,负责将客户端请求委派给具体的策略对象执行。环境类可以通过依赖注入、简单工厂等方式来获取具体策略对象。
- 抽象策略(Abstract Strategy):定义了策略对象的公共接口或抽象类,规定了具体策略类必须实现的方法。
- 具体策略(Concrete Strategy):实现了抽象策略定义的接口或抽象类,包含了具体的算法实现。
策略模式通过将算法与使用算法的代码解耦,提供了一种动态选择不同算法的方法。客户端代码不需要知道具体的算法细节,而是通过调用环境类来使用所选择的策略。
优缺点
优点: 1、算法可以自由切换。 2、避免使用多重条件判断。 3、扩展性良好。
缺点: 1、策略类会增多。 2、所有策略类都需要对外暴露。
代码实现
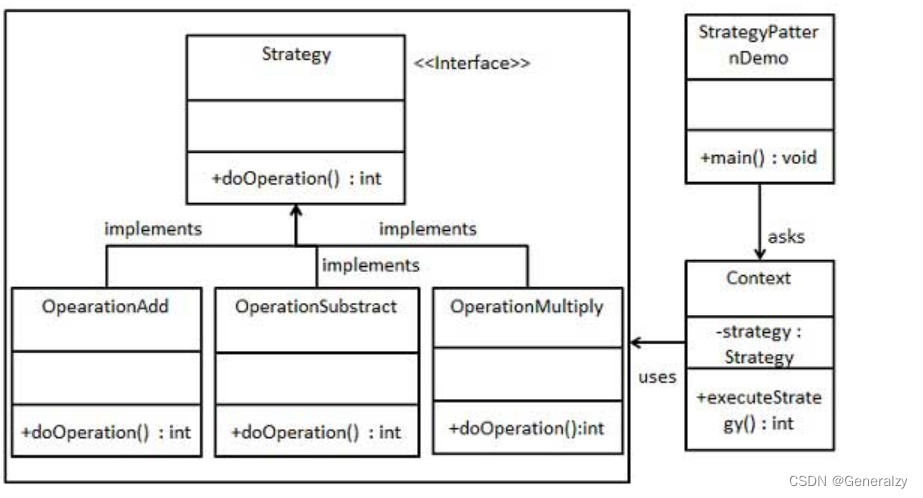
创建一个定义活动的 Strategy 接口和实现了 Strategy 接口的实体策略类。Context 是一个使用了某种策略的类。
StrategyPatternDemo,我们的演示类使用 Context 和策略对象来演示 Context 在它所配置或使用的策略改变时的行为变化。
python代码
# 不是原神...
class Op:def do_op(self, a: int, b: int) -> int:raise NotImplementedError()class OpADD(Op):def do_op(self, a: int, b: int) -> int:return a + bclass OpSubtract(Op):def do_op(self, a: int, b: int) -> int:return a - bclass Context:def __init__(self, op: Op):self.op = opdef exe(self, a: int, b: int) -> int:return self.op.do_op(a, b)if __name__ == '__main__':ctx = Context(OpADD())print(ctx.exe(1, 2))ctx = Context(OpSubtract())print(ctx.exe(1, 3))
执行结果:
3
-2
go代码
package maintype Op interface {do(int, int) int
}type AddOp struct {
}func (add *AddOp) do(a, b int) int {return a + b
}type SubOp struct {
}func (sub *SubOp) do(a, b int) int {return a - b
}type Context struct {op Op
}func (ctx *Context) Exe(a, b int) int {return ctx.op.do(a, b)
}func main() {ctx := Context{op: new(AddOp)}println(ctx.Exe(1, 2))ctx = Context{op: new(SubOp)}println(ctx.Exe(1, 5))
}
执行结果:
3
-4
责任链模式
顾名思义,责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。
在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。
使用场景
意图:避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。
主要解决:职责链上的处理者负责处理请求,客户只需要将请求发送到职责链上即可,无须关心请求的处理细节和请求的传递,所以职责链将请求的发送者和请求的处理者解耦了。
何时使用:在处理消息的时候以过滤很多道。
如何解决:拦截的类都实现统一接口。
关键代码:Handler 里面聚合它自己,在 HandlerRequest 里判断是否合适,如果没达到条件则向下传递,向谁传递之前 set 进去。
使用场景: 1、有多个对象可以处理同一个请求,具体哪个对象处理该请求由运行时刻自动确定。 2、在不明确指定接收者的情况下,向多个对象中的一个提交一个请求。 3、可动态指定一组对象处理请求。
主要涉及到以下几个核心角色:
-
抽象处理者(Handler):定义一个处理请求的接口,通常包含一个处理请求的方法(如 handleRequest)和一个指向下一个处理者的引用(后继者)。
-
具体处理者(ConcreteHandler):实现了抽象处理者接口,负责处理请求。如果能够处理该请求,则直接处理;否则,将请求传递给下一个处理者。
-
客户端(Client):创建处理者对象,并将它们连接成一条责任链。通常,客户端只需要将请求发送给责任链的第一个处理者,无需关心请求的具体处理过程。
优缺点
优点: 1、降低耦合度。它将请求的发送者和接收者解耦。 2、简化了对象。使得对象不需要知道链的结构。 3、增强给对象指派职责的灵活性。通过改变链内的成员或者调动它们的次序,允许动态地新增或者删除责任。 4、增加新的请求处理类很方便。
缺点: 1、不能保证请求一定被接收。 2、系统性能将受到一定影响,而且在进行代码调试时不太方便,可能会造成循环调用。 3、可能不容易观察运行时的特征,有碍于除错。
代码实现
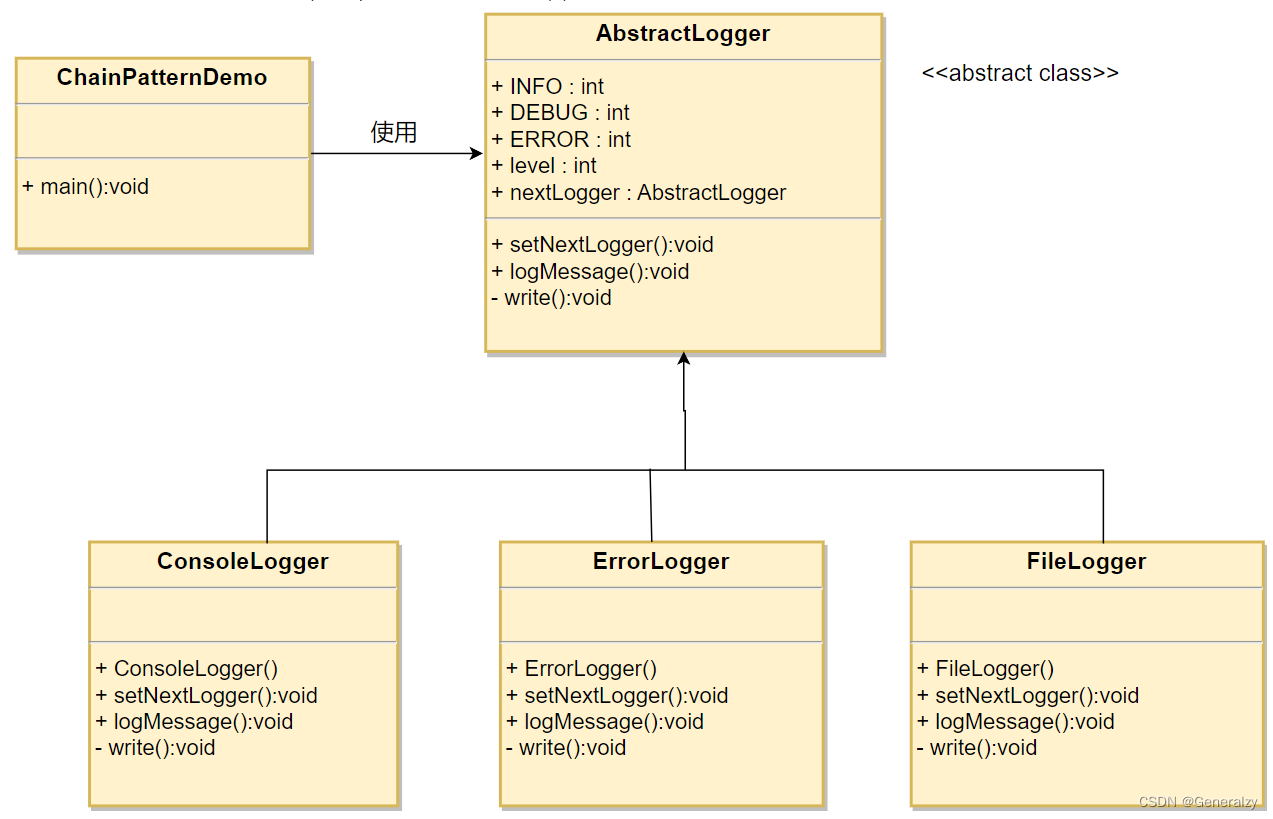
创建抽象类 AbstractLogger,带有详细的日志记录级别。然后我们创建三种类型的记录器,都扩展了 AbstractLogger。每个记录器消息的级别是否属于自己的级别,如果是则相应地打印出来,否则将不打印并把消息传给下一个记录器。
python代码
INFO: int = 1
ERROR: int = 3class Logger:level: int = -1next: "Logger" = Nonedef write(self, content: str) -> None:raise NotImplementedError()def log_message(self, level: int, content: str):if self.level <= level:self.write(content=content)if self.next is not None:self.next.log_message(level, content)class InfoLogger(Logger):level = INFOdef write(self, content: str) -> None:print(f"[INFO] {content}")class ErrorLogger(Logger):level = ERRORdef write(self, content: str) -> None:print(f"[ERROR] {content}")def get_logger():error = ErrorLogger()info = InfoLogger()info.next = errorreturn infoif __name__ == '__main__':logger = get_logger()logger.log_message(ERROR, "hello world")

go代码
package mainimport "fmt"const (INFO = iotaERROR
)type Logger interface {Log(int, string)Next() Logger
}type BaseLogger struct {level intnext Logger
}func (bl *BaseLogger) Next() Logger {return bl.next
}func (bl *BaseLogger) Log(level int, content string) {panic("not implement")
}type ErrorLogger struct {BaseLogger
}func (e *ErrorLogger) Log(level int, content string) {if e.level <= level {fmt.Println("[ERROR]", content)}if next := e.Next(); next != nil {next.Log(level, content)}
}type InFoLogger struct {BaseLogger
}func (e *InFoLogger) Log(level int, content string) {if e.level <= level {fmt.Println("[INFO]", content)}if next := e.Next(); next != nil {next.Log(level, content)}
}func getLogger() Logger {info := InFoLogger{BaseLogger{level: INFO, next: nil}}err := ErrorLogger{BaseLogger{level: ERROR, next: nil}}info.next = &errreturn &info
}func main() {l := getLogger()l.Log(ERROR, "hello world")
}

go语言中匿名结构体的嵌套也可以实现类似其他语言中的继承关系。但go更赞同的是组合的概念,而不是继承关系。
命令模式
命令模式(Command Pattern)是一种数据驱动的设计模式,它属于行为型模式。请求以命令的形式包裹在对象中,并传给调用对象。调用对象寻找可以处理该命令的合适的对象,并把该命令传给相应的对象,该对象执行命令。
使用场景
意图:将一个请求封装成一个对象,从而使您可以用不同的请求对客户进行参数化。
主要解决:在软件系统中,行为请求者与行为实现者通常是一种紧耦合的关系,但某些场合,比如需要对行为进行记录、撤销或重做、事务等处理时,这种无法抵御变化的紧耦合的设计就不太合适。
如何解决:通过调用者调用接受者执行命令,顺序:调用者→命令→接受者。
关键代码:定义三个角色:1、received 真正的命令执行对象 2、Command 3、invoker 使用命令对象的入口
应用实例:struts 1 中的 action 核心控制器 ActionServlet 只有一个,相当于 Invoker,而模型层的类会随着不同的应用有不同的模型类,相当于具体的 Command。
使用场景:认为是命令的地方都可以使用命令模式,比如: 1、GUI 中每一个按钮都是一条命令。 2、模拟 CMD。
注意事项:系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作,也可以考虑使用命令模式,见命令模式的扩展。
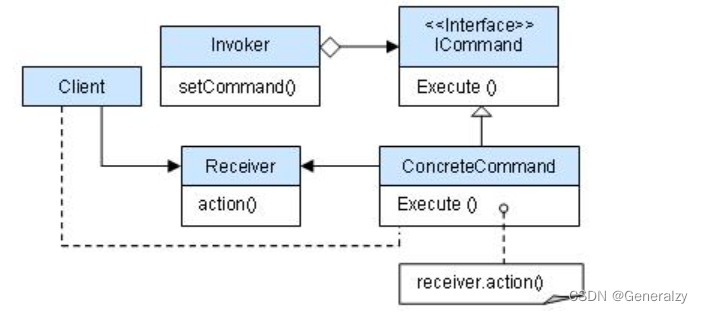
命令模式结构示意图:
主要涉及到以下几个核心角色:
-
命令(Command):定义了执行操作的接口,通常包含一个 execute 方法,用于调用具体的操作。
-
具体命令(ConcreteCommand):实现了命令接口,负责执行具体的操作。它通常包含了对接收者的引用,通过调用接收者的方法来完成请求的处理。
-
接收者(Receiver):知道如何执行与请求相关的操作,实际执行命令的对象。
-
调用者/请求者(Invoker):发送命令的对象,它包含了一个命令对象并能触发命令的执行。调用者并不直接处理请求,而是通过将请求传递给命令对象来实现。
-
客户端(Client):创建具体命令对象并设置其接收者,将命令对象交给调用者执行。
优缺点
优点: 1、降低了系统耦合度。 2、新的命令可以很容易添加到系统中去。
缺点:使用命令模式可能会导致某些系统有过多的具体命令类。
代码实现
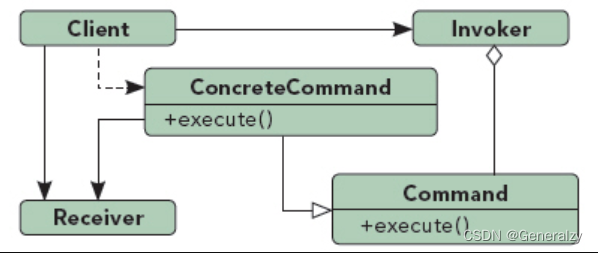
一个点餐系统,可以将该系统设计成前台服务员系统和后台系统,后台系统进一步细分成主食子系统,凉菜子系统,热菜子系统。
python代码
后台三个子系统设计如下:
class backSys():def cook(self,dish):pass
class mainFoodSys(backSys):def cook(self,dish):print "MAINFOOD:Cook %s"%dish
class coolDishSys(backSys):def cook(self,dish):print "COOLDISH:Cook %s"%dish
class hotDishSys(backSys):def cook(self,dish):print "HOTDISH:Cook %s"%dish
前台服务员系统与后台系统的交互,可以通过命令的模式来实现,服务员将顾客的点单内容封装成命令,直接对后台下达命令,后台完成命令要求的事即可。前台系统构建如下:
class waiterSys():menu_map=dict()commandList=[]def setOrder(self,command):print "WAITER:Add dish"self.commandList.append(command)def cancelOrder(self,command):print "WAITER:Cancel order..."self.commandList.remove(command)def notify(self):print "WAITER:Nofify..."for command in self.commandList:command.execute()
前台系统中的notify接口直接调用命令中的execute接口,执行命令。命令类构建如下:
class Command():receiver = Nonedef __init__(self, receiver):self.receiver = receiverdef execute(self):pass
class foodCommand(Command):dish=""def __init__(self,receiver,dish):self.receiver=receiverself.dish=dishdef execute(self):self.receiver.cook(self.dish)class mainFoodCommand(foodCommand):pass
class coolDishCommand(foodCommand):pass
class hotDishCommand(foodCommand):pass
为使场景业务精简一些,我们再加一个菜单类来辅助业务,菜单类在本例中直接写死。
class menuAll:menu_map=dict()def loadMenu(self):#加载菜单,这里直接写死self.menu_map["hot"] = ["Yu-Shiang Shredded Pork", "Sauteed Tofu, Home Style", "Sauteed Snow Peas"]self.menu_map["cool"] = ["Cucumber", "Preserved egg"]self.menu_map["main"] = ["Rice", "Pie"]def isHot(self,dish):if dish in self.menu_map["hot"]:return Truereturn Falsedef isCool(self,dish):if dish in self.menu_map["cool"]:return Truereturn Falsedef isMain(self,dish):if dish in self.menu_map["main"]:return Truereturn False
业务场景如下:
if __name__=="__main__":dish_list=["Yu-Shiang Shredded Pork","Sauteed Tofu, Home Style","Cucumber","Rice"]#顾客点的菜waiter_sys=waiterSys()main_food_sys=mainFoodSys()cool_dish_sys=coolDishSys()hot_dish_sys=hotDishSys()menu=menuAll()menu.loadMenu()for dish in dish_list:if menu.isCool(dish):cmd=coolDishCommand(cool_dish_sys,dish)elif menu.isHot(dish):cmd=hotDishCommand(hot_dish_sys,dish)elif menu.isMain(dish):cmd=mainFoodCommand(main_food_sys,dish)else:continuewaiter_sys.setOrder(cmd)waiter_sys.notify()
打印如下:
WAITER:Add dish
WAITER:Add dish
WAITER:Add dish
WAITER:Add dish
WAITER:Nofify...
HOTDISH:Cook Yu-Shiang Shredded Pork
HOTDISH:Cook Sauteed Tofu, Home Style
COOLDISH:Cook Cucumber
MAINFOOD:Cook Rice
go代码
package mainimport "fmt"type BackSys interface {Cook(dish string)
}type MainFoodSys struct{}func (m *MainFoodSys) Cook(dish string) {fmt.Printf("MAINFOOD:Cook %s\n", dish)
}type CoolDishSys struct{}func (c *CoolDishSys) Cook(dish string) {fmt.Printf("COOLDISH:Cook %s\n", dish)
}type HotDishSys struct{}func (h *HotDishSys) Cook(dish string) {fmt.Printf("HOTDISH:Cook %s\n", dish)
}type WaiterSys struct {commandList []Command
}func (w *WaiterSys) SetOrder(command Command) {fmt.Println("WAITER:Add dish")w.commandList = append(w.commandList, command)
}func (w *WaiterSys) CancelOrder(command Command) {fmt.Println("WAITER:Cancel order...")// Assuming Command interface has an IsEqual method to identify the command to removefor i, cmd := range w.commandList {if cmd.IsEqual(command) {w.commandList = append(w.commandList[:i], w.commandList[i+1:]...)break}}
}func (w *WaiterSys) Notify() {fmt.Println("WAITER:Notify...")for _, command := range w.commandList {command.Execute()}
}type Command interface {Execute()IsEqual(Command) bool
}type FoodCommand struct {receiver BackSysdish string
}func (f *FoodCommand) Execute() {f.receiver.Cook(f.dish)
}func (f *FoodCommand) IsEqual(command Command) bool {// Implement comparison logic based on the needsreturn false
}type MainFoodCommand struct {FoodCommand
}type CoolDishCommand struct {FoodCommand
}type HotDishCommand struct {FoodCommand
}type MenuAll struct {menuMap map[string][]string
}func (m *MenuAll) LoadMenu() {m.menuMap = make(map[string][]string)m.menuMap["hot"] = []string{"Yu-Shiang Shredded Pork", "Sauteed Tofu, Home Style", "Sauteed Snow Peas"}m.menuMap["cool"] = []string{"Cucumber", "Preserved egg"}m.menuMap["main"] = []string{"Rice", "Pie"}
}func (m *MenuAll) IsHot(dish string) bool {for _, d := range m.menuMap["hot"] {if d == dish {return true}}return false
}func (m *MenuAll) IsCool(dish string) bool {for _, d := range m.menuMap["cool"] {if d == dish {return true}}return false
}func (m *MenuAll) IsMain(dish string) bool {for _, d := range m.menuMap["main"] {if d == dish {return true}}return false
}func main() {dishList := []string{"Yu-Shiang Shredded Pork", "Sauteed Tofu, Home Style", "Cucumber", "Rice"}waiterSys := WaiterSys{}mainFoodSys := MainFoodSys{}coolDishSys := CoolDishSys{}hotDishSys := HotDishSys{}menu := MenuAll{}menu.LoadMenu()for _, dish := range dishList {var cmd Commandif menu.IsCool(dish) {cmd = &CoolDishCommand{FoodCommand{receiver: &coolDishSys, dish: dish}}} else if menu.IsHot(dish) {cmd = &HotDishCommand{FoodCommand{receiver: &hotDishSys, dish: dish}}} else if menu.IsMain(dish) {cmd = &MainFoodCommand{FoodCommand{receiver: &mainFoodSys, dish: dish}}} else {continue}waiterSys.SetOrder(cmd)}waiterSys.Notify()
}
中介者模式
中介者模式(Mediator Pattern)是用来降低多个对象和类之间的通信复杂性。这种模式提供了一个中介类,该类通常处理不同类之间的通信,并支持松耦合,使代码易于维护。中介者模式属于行为型模式。
使用场景
意图:用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。
主要解决:对象与对象之间存在大量的关联关系,这样势必会导致系统的结构变得很复杂,同时若一个对象发生改变,我们也需要跟踪与之相关联的对象,同时做出相应的处理。
何时使用:多个类相互耦合,形成了网状结构。
如何解决:将上述网状结构分离为星型结构。
关键代码:对象 Colleague 之间的通信封装到一个类中单独处理。
使用场景: 1、系统中对象之间存在比较复杂的引用关系,导致它们之间的依赖关系结构混乱而且难以复用该对象。 2、想通过一个中间类来封装多个类中的行为,而又不想生成太多的子类。
注意事项:不应当在职责混乱的时候使用。
优缺点
优点: 1、降低了类的复杂度,将一对多转化成了一对一。 2、各个类之间的解耦。 3、符合迪米特原则。
缺点:中介者会庞大,变得复杂难以维护。
代码实现
通过聊天室实例来演示中介者模式。实例中,多个用户可以向聊天室发送消息,聊天室向所有的用户显示消息。我们将创建两个类 ChatRoom 和 User。User 对象使用 ChatRoom 方法来分享他们的消息。
MediatorPatternDemo,我们的演示类使用 User 对象来显示他们之间的通信。
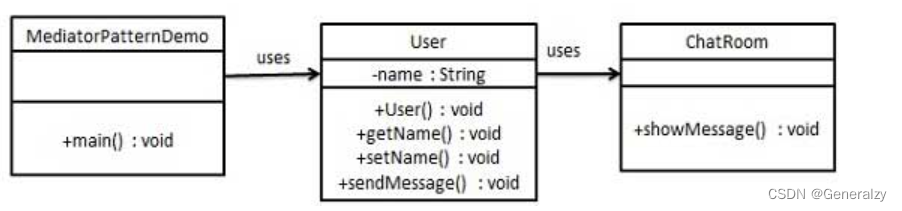
python代码
from datetime import datetime# 创建中介类
class ChatRoom:@staticmethoddef show_message(user, message):print(f"{datetime.now()} [{user.get_name()}] : {message}")
# 创建 user 类
class User:def __init__(self, name):self.__name = namedef get_name(self):return self.__namedef set_name(self, name):self.__name = namedef send_message(self, message):ChatRoom.show_message(self, message)# Demo
if __name__ == "__main__":robert = User("Robert")john = User("John")robert.send_message("Hi! John!")john.send_message("Hello! Robert!")
go代码
package mainimport ("fmt""time"
)type ChatRoom struct{}func (cr *ChatRoom) ShowMessage(user *User, message string) {fmt.Printf("%s [%s] : %s\n", time.Now().Format("2006-01-02 15:04:05"), user.GetName(), message)
}type User struct {name string
}func NewUser(name string) *User {return &User{name: name}
}func (u *User) GetName() string {return u.name
}func (u *User) SetName(name string) {u.name = name
}func (u *User) SendMessage(message string, chatRoom *ChatRoom) {chatRoom.ShowMessage(u, message)
}func main() {chatRoom := &ChatRoom{}robert := NewUser("Robert")john := NewUser("John")robert.SendMessage("Hi! John!", chatRoom)john.SendMessage("Hello! Robert!", chatRoom)
}
模板模式
在模板模式(Template Pattern)中,一个抽象类公开定义了执行它的方法的方式/模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。这种类型的设计模式属于行为型模式。
使用场景
意图:定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
主要解决:一些方法通用,却在每一个子类都重新写了这一方法。
何时使用:有一些通用的方法。
如何解决:将这些通用算法抽象出来。
关键代码:在抽象类实现,其他步骤在子类实现。
使用场景: 1、有多个子类共有的方法,且逻辑相同。 2、重要的、复杂的方法,可以考虑作为模板方法。
注意事项:为防止恶意操作,一般模板方法都加上 final 关键词。
优缺点
优点: 1、封装不变部分,扩展可变部分。 2、提取公共代码,便于维护。 3、行为由父类控制,子类实现。
缺点:每一个不同的实现都需要一个子类来实现,导致类的个数增加,使得系统更加庞大。
代码实现
将创建一个定义操作的 Game 抽象类,Cricket 和 Football 是扩展了 Game 的实体类,它们重写了抽象类的方法。
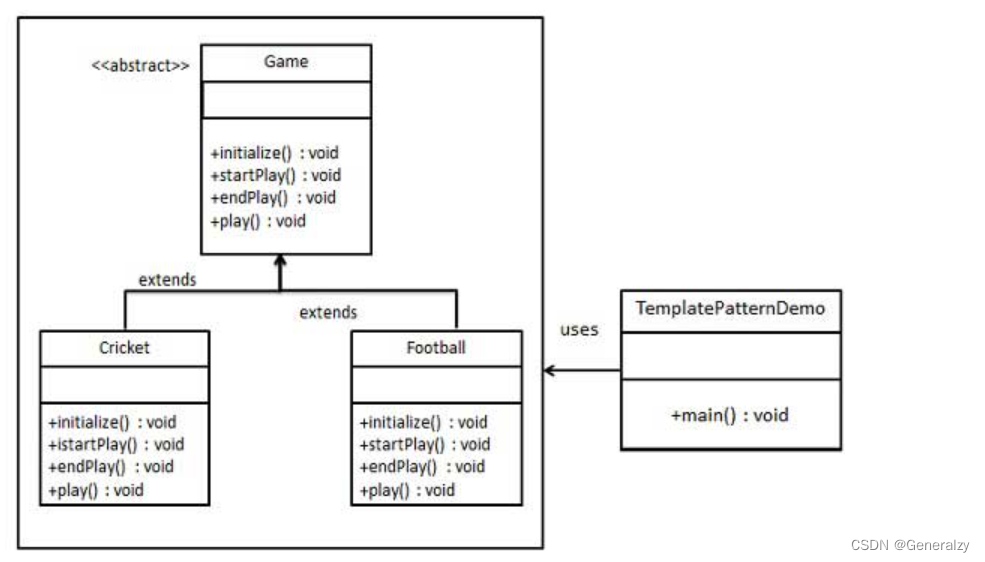
python代码
from abc import ABC, abstractmethodclass Game(ABC):@abstractmethoddef initialize(self):pass@abstractmethoddef start_play(self):pass@abstractmethoddef end_play(self):passdef play(self):self.initialize()self.start_play()self.end_play()class Cricket(Game):def end_play(self):print("Cricket Game Finished!")def initialize(self):print("Cricket Game Initialized! Start playing.")def start_play(self):print("Cricket Game Started. Enjoy the game!")class Football(Game):def end_play(self):print("Football Game Finished!")def initialize(self):print("Football Game Initialized! Start playing.")def start_play(self):print("Football Game Started. Enjoy the game!")if __name__ == "__main__":game = Cricket()game.play()print()game = Football()game.play()
go代码
package mainimport "fmt"type Game interface {initialize()startPlay()endPlay()play()
}type BaseGame struct{}func (g *BaseGame) play(game Game) {game.initialize()game.startPlay()game.endPlay()
}type Cricket struct {BaseGame
}func (c *Cricket) initialize() {fmt.Println("Cricket Game Initialized! Start playing.")
}func (c *Cricket) startPlay() {fmt.Println("Cricket Game Started. Enjoy the game!")
}func (c *Cricket) endPlay() {fmt.Println("Cricket Game Finished!")
}type Football struct {BaseGame
}func (f *Football) initialize() {fmt.Println("Football Game Initialized! Start playing.")
}func (f *Football) startPlay() {fmt.Println("Football Game Started. Enjoy the game!")
}func (f *Football) endPlay() {fmt.Println("Football Game Finished!")
}func main() {cricket := &Cricket{}cricket.play(cricket)fmt.Println()football := &Football{}football.play(football)
}
迭代器模式
迭代器模式的定义如下:它提供一种方法,访问一个容器对象中各个元素,而又不需要暴露对象的内部细节。
使用场景
意图:提供一种方法顺序访问一个聚合对象中各个元素, 而又无须暴露该对象的内部表示。
主要解决:不同的方式来遍历整个整合对象。
何时使用:遍历一个聚合对象。
如何解决:把在元素之间游走的责任交给迭代器,而不是聚合对象。
使用场景: 1、访问一个聚合对象的内容而无须暴露它的内部表示。 2、需要为聚合对象提供多种遍历方式。 3、为遍历不同的聚合结构提供一个统一的接口。
注意事项:迭代器模式就是分离了集合对象的遍历行为,抽象出一个迭代器类来负责,这样既可以做到不暴露集合的内部结构,又可让外部代码透明地访问集合内部的数据。
优缺点
优点: 1、它支持以不同的方式遍历一个聚合对象。 2、迭代器简化了聚合类。 3、在同一个聚合上可以有多个遍历。 4、在迭代器模式中,增加新的聚合类和迭代器类都很方便,无须修改原有代码。
缺点:由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
代码实现
在python中,迭代器并不用举太多的例子,因为python中的迭代器应用实在太多了(不管是python还是其它很多的编程语言中,实际上迭代器都已经纳入到了常用的库或者包中)。
而且在当前,也几乎没有人专门去开发一个迭代器,而是直接去使用list、string、set、dict等python可迭代对象,或者直接使用__iter__和next函数来实现迭代器。
if __name__=="__main__":lst=["hello Alice","hello Bob","hello Eve"]lst_iter=iter(lst)print lst_iterprint lst_iter.next()print lst_iter.next()print lst_iter.next()print lst_iter.next()
python代码
class MyIter(object):def __init__(self, n):self.index = 0self.n = ndef __iter__(self):return selfdef __next__(self):if self.index < self.n:value = self.index ** 2self.index += 1return valueelse:raise StopIteration()if __name__ == "__main__":x_square = MyIter(10)for x in x_square:print(x)
注意:yield 主要用于生成器函数,而 __iter__ 和 __next__ 主要用于创建自定义迭代器对象。生成器是一种特殊的迭代器,而迭代器是实现了 __iter__ 和 __next__ 方法的对象。
go代码
go语言的bufio.NewScanner()就是一个迭代器的案例:
package mainimport ("bufio""fmt""log""os"
)func main() {file, err := os.Open("./xx.txt")if err != nil {log.Fatal(err)}defer file.Close()scanner := bufio.NewScanner(file)for scanner.Scan() {fmt.Println(scanner.Text())}if err := scanner.Err(); err != nil {log.Fatal(err)}
}
读取文件只需要调用Scan()即可加载到缓存中,同时隐藏了复杂的文件操作流程
func (s *Scanner) Scan() bool {if s.done {return false}s.scanCalled = true// Loop until we have a token.for {// See if we can get a token with what we already have.// If we've run out of data but have an error, give the split function// a chance to recover any remaining, possibly empty token.if s.end > s.start || s.err != nil {advance, token, err := s.split(s.buf[s.start:s.end], s.err != nil)if err != nil {if err == ErrFinalToken {s.token = tokens.done = truereturn true}s.setErr(err)return false}if !s.advance(advance) {return false}s.token = tokenif token != nil {if s.err == nil || advance > 0 {s.empties = 0} else {// Returning tokens not advancing input at EOF.s.empties++if s.empties > maxConsecutiveEmptyReads {panic("bufio.Scan: too many empty tokens without progressing")}}return true}}// We cannot generate a token with what we are holding.// If we've already hit EOF or an I/O error, we are done.if s.err != nil {// Shut it down.s.start = 0s.end = 0return false}// Must read more data.// First, shift data to beginning of buffer if there's lots of empty space// or space is needed.if s.start > 0 && (s.end == len(s.buf) || s.start > len(s.buf)/2) {copy(s.buf, s.buf[s.start:s.end])s.end -= s.starts.start = 0}// Is the buffer full? If so, resize.if s.end == len(s.buf) {// Guarantee no overflow in the multiplication below.const maxInt = int(^uint(0) >> 1)if len(s.buf) >= s.maxTokenSize || len(s.buf) > maxInt/2 {s.setErr(ErrTooLong)return false}newSize := len(s.buf) * 2if newSize == 0 {newSize = startBufSize}if newSize > s.maxTokenSize {newSize = s.maxTokenSize}newBuf := make([]byte, newSize)copy(newBuf, s.buf[s.start:s.end])s.buf = newBufs.end -= s.starts.start = 0}// Finally we can read some input. Make sure we don't get stuck with// a misbehaving Reader. Officially we don't need to do this, but let's// be extra careful: Scanner is for safe, simple jobs.for loop := 0; ; {n, err := s.r.Read(s.buf[s.end:len(s.buf)])if n < 0 || len(s.buf)-s.end < n {s.setErr(ErrBadReadCount)break}s.end += nif err != nil {s.setErr(err)break}if n > 0 {s.empties = 0break}loop++if loop > maxConsecutiveEmptyReads {s.setErr(io.ErrNoProgress)break}}}
}
访问者模式
在访问者模式(Visitor Pattern)中,我们使用了一个访问者类,它改变了元素类的执行算法。通过这种方式,元素的执行算法可以随着访问者改变而改变。这种类型的设计模式属于行为型模式。根据模式,元素对象已接受访问者对象,这样访问者对象就可以处理元素对象上的操作。(封装一些作用于某种数据结构中的各元素的操作,它可以在不改变数据结构的前提下定义于作用于这些元素的新操作。)
使用场景
意图:主要将数据结构与数据操作分离。
主要解决:稳定的数据结构和易变的操作耦合问题。
何时使用:需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作"污染"这些对象的类,使用访问者模式将这些封装到类中。
使用场景: 1、对象结构中对象对应的类很少改变,但经常需要在此对象结构上定义新的操作。 2、需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作"污染"这些对象的类,也不希望在增加新操作时修改这些类。
优缺点
优点: 1、符合单一职责原则。 2、优秀的扩展性。 3、灵活性。
缺点: 1、具体元素对访问者公布细节,违反了迪米特原则。 2、具体元素变更比较困难。 3、违反了依赖倒置原则,依赖了具体类,没有依赖抽象。
代码实现
创建一个定义接受操作的 ComputerPart 接口。Keyboard、Mouse、Monitor 和 Computer 是实现了 ComputerPart 接口的实体类。我们将定义另一个接口 ComputerPartVisitor,它定义了访问者类的操作。Computer 使用实体访问者来执行相应的动作。
VisitorPatternDemo,演示类使用 Computer、ComputerPartVisitor 类来演示访问者模式的用法。
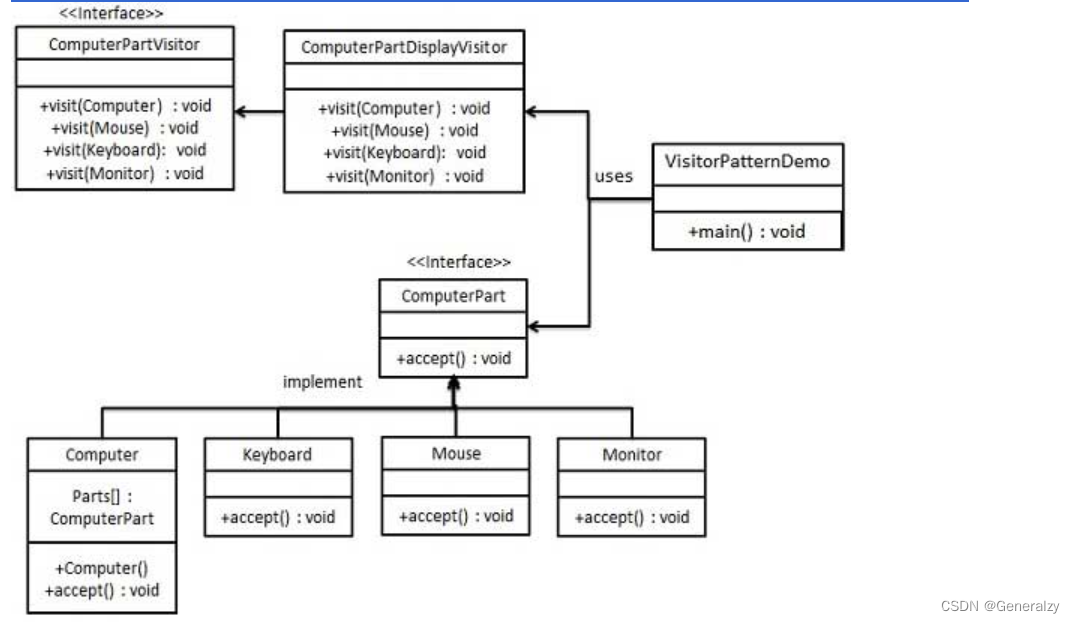
python代码
# Visitor Pattern with Python Code
from abc import abstractmethod,ABCMeta
# 定义一个表示元素(Element)的接口
class ComputerPart(metaclass=ABCMeta):@abstractmethoddef accept(self, inComputerPartVisitor):pass
#创建阔爱站了ComputerPart的实体类
class Keyboard(ComputerPart):def accept(self, inComputerPartVisitor):inComputerPartVisitor.visitKeyboard(self)
class Monitor(ComputerPart):def accept(self, inComputerPartVisitor):inComputerPartVisitor.visitMonitor(self)
class Mouse(ComputerPart):def accept(self, inComputerPartVisitor):inComputerPartVisitor.visitMouse(self)
class Computer(ComputerPart):_parts = []def __init__(self):self._parts.append(Mouse())self._parts.append(Keyboard())self._parts.append(Monitor())def accept(self, inComputerPartVisitor):for aPart in self._parts :aPart.accept(inComputerPartVisitor)inComputerPartVisitor.visitComputer(self)
# 定义一个表示访问者的接口
class ComputerPartVisitor(metaclass=ABCMeta):@abstractmethoddef visitComputer(self,inComputer):pass@abstractmethoddef visitMouse(self,inMouse):pass@abstractmethoddef visitKeyboard(self,inKeyboard):pass@abstractmethoddef visitMonitor(self,inMonitor):pass
# 实现访问者接口的实体类
class ComputerPartDisplayVisitor(ComputerPartVisitor):def visitComputer(self,inComputer):print("Displaying {0}. Called in {1}".format(inComputer.__class__.__name__,self.__class__.__name__))def visitMouse(self,inMouse):print("Displaying {0}. Called in {1}".format(inMouse.__class__.__name__,self.__class__.__name__))def visitKeyboard(self,inKeyboard):print("Displaying {0}. Called in {1}".format(inKeyboard.__class__.__name__,self.__class__.__name__))def visitMonitor(self,inMonitor):print("Displaying {0}. Called in {1}".format(inMonitor.__class__.__name__,self.__class__.__name__))
# 调用输出
if __name__ == '__main__':aComputer = Computer()aComputer.accept(ComputerPartDisplayVisitor())
go代码
package mainimport "fmt"type ComputerPart interface {Accept(computerPartVisitor ComputerPartVisitor)
}type Keyboard struct{}
func (k *Keyboard) Accept(computerPartVisitor ComputerPartVisitor) {computerPartVisitor.VisitKeyboard(k)
}type Monitor struct{}
func (m *Monitor) Accept(computerPartVisitor ComputerPartVisitor) {computerPartVisitor.VisitMonitor(m)
}type Mouse struct{}
func (m *Mouse) Accept(computerPartVisitor ComputerPartVisitor) {computerPartVisitor.VisitMouse(m)
}type Computer struct {parts []ComputerPart
}
func NewComputer() *Computer {return &Computer{parts: []ComputerPart{&Mouse{}, &Keyboard{}, &Monitor{}},}
}
func (c *Computer) Accept(computerPartVisitor ComputerPartVisitor) {for _, part := range c.parts {part.Accept(computerPartVisitor)}computerPartVisitor.VisitComputer(c)
}type ComputerPartVisitor interface {VisitComputer(computer *Computer)VisitMouse(mouse *Mouse)VisitKeyboard(keyboard *Keyboard)VisitMonitor(monitor *Monitor)
}type ComputerPartDisplayVisitor struct{}
func (cpdv *ComputerPartDisplayVisitor) VisitComputer(computer *Computer) {fmt.Printf("Displaying %T. Called in %T\n", computer, cpdv)
}
func (cpdv *ComputerPartDisplayVisitor) VisitMouse(mouse *Mouse) {fmt.Printf("Displaying %T. Called in %T\n", mouse, cpdv)
}
func (cpdv *ComputerPartDisplayVisitor) VisitKeyboard(keyboard *Keyboard) {fmt.Printf("Displaying %T. Called in %T\n", keyboard, cpdv)
}
func (cpdv *ComputerPartDisplayVisitor) VisitMonitor(monitor *Monitor) {fmt.Printf("Displaying %T. Called in %T\n", monitor, cpdv)
}func main() {computer := NewComputer()computer.Accept(&ComputerPartDisplayVisitor{})
}
观察者模式
观察者模式是一种行为型设计模式,它定义了一种一对多的依赖关系,当一个对象的状态发生改变时,其所有依赖者都会收到通知并自动更新。
当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知依赖它的对象。观察者模式属于行为型模式。
使用场景
意图:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
主要解决:一个对象状态改变给其他对象通知的问题,而且要考虑到易用和低耦合,保证高度的协作。
何时使用:一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知,进行广播通知。
使用场景:
- 一个抽象模型有两个方面,其中一个方面依赖于另一个方面。将这些方面封装在独立的对象中使它们可以各自独立地改变和复用。
- 一个对象的改变将导致其他一个或多个对象也发生改变,而不知道具体有多少对象将发生改变,可以降低对象之间的耦合度。
- 一个对象必须通知其他对象,而并不知道这些对象是谁。
- 需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,可以使用观察者模式创建一种链式触发机制。
观察者模式包含以下几个核心角色:
- 主题(Subject):也称为被观察者或可观察者,它是具有状态的对象,并维护着一个观察者列表。主题提供了添加、删除和通知观察者的方法。
- 观察者(Observer):观察者是接收主题通知的对象。观察者需要实现一个更新方法,当收到主题的通知时,调用该方法进行更新操作。
- 具体主题(Concrete Subject):具体主题是主题的具体实现类。它维护着观察者列表,并在状态发生改变时通知观察者。
- 具体观察者(Concrete Observer):具体观察者是观察者的具体实现类。它实现了更新方法,定义了在收到主题通知时需要执行的具体操作。
观察者模式通过将主题和观察者解耦,实现了对象之间的松耦合。当主题的状态发生改变时,所有依赖于它的观察者都会收到通知并进行相应的更新。
优缺点
优点: 1、观察者和被观察者是抽象耦合的。 2、建立一套触发机制。
缺点: 1、如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。 2、如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。 3、观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
代码实现
观察者模式使用三个类 Subject、Observer 和 Client。Subject 对象带有绑定观察者到 Client 对象和从 Client 对象解绑观察者的方法。
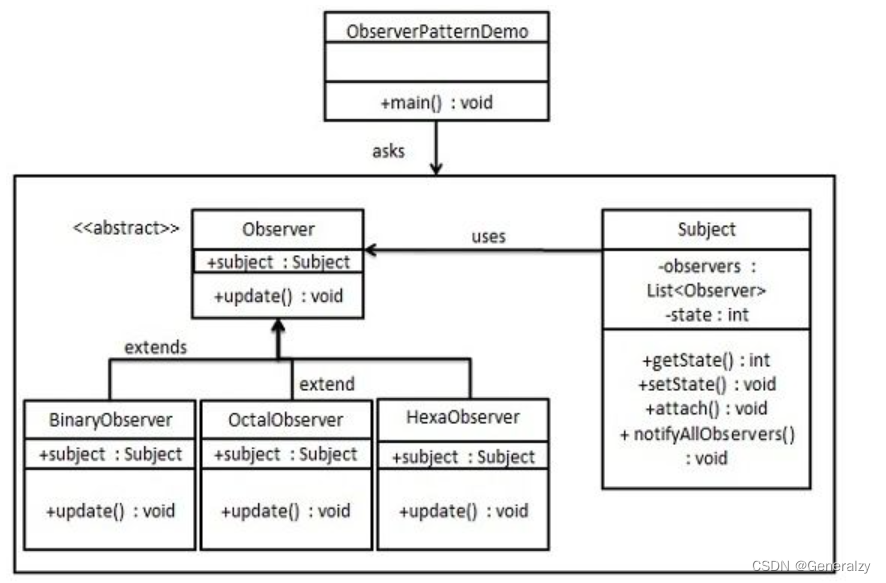
python代码
class Subject:def __init__(self):self._observers = []self._state = Nonedef get_state(self):return self._statedef set_state(self, state):self._state = stateself._notify_all_observers()def attach(self, observer):self._observers.append(observer)def _notify_all_observers(self):for observer in self._observers:observer.update()class Observer:def __init__(self, subject):self._subject = subjectdef update(self):passclass BinaryObserver(Observer):def __init__(self, subject):super().__init__(subject)self._subject.attach(self)def update(self):state = self._subject.get_state()print("Binary String:", bin(state)[2:])class OctalObserver(Observer):def __init__(self, subject):super().__init__(subject)self._subject.attach(self)def update(self):state = self._subject.get_state()print("Octal String:", oct(state)[2:])class HexaObserver(Observer):def __init__(self, subject):super().__init__(subject)self._subject.attach(self)def update(self):state = self._subject.get_state()print("Hex String:", hex(state)[2:].upper())if __name__ == "__main__":subject = Subject()HexaObserver(subject)OctalObserver(subject)BinaryObserver(subject)print("First state change: 15")subject.set_state(15)print("Second state change: 10")subject.set_state(10)
执行结果:

go代码
package mainimport ("fmt""strconv"
)type Observer interface {Update()
}type BinaryObserver struct {subject *Subject
}func NewBinaryObserver(subject *Subject) {bin := new(BinaryObserver)bin.subject = subjectbin.subject.Attach(bin)
}func (bin *BinaryObserver) Update() {fmt.Println(strconv.FormatInt(int64(bin.subject.stat), 2))
}type Subject struct {stat intobservers []Observer
}func NewSubject() *Subject {return &Subject{observers: make([]Observer, 0),}
}func (sub *Subject) Attach(observer Observer) {sub.observers = append(sub.observers, observer)
}func (sub *Subject) Notify() {for _, obs := range sub.observers {obs.Update()}
}func (sub *Subject) GetStat() int {return sub.stat
}func (sub *Subject) SetStat(stat int) {sub.stat = statsub.Notify()
}func main() {sub := NewSubject()// 注册到sub中NewBinaryObserver(sub)sub.SetStat(10)
}
解释器模式
解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。这种模式被用在 SQL 解析、符号处理引擎等。
使用场景
意图:给定一个语言,定义它的文法表示,并定义一个解释器,这个解释器使用该标识来解释语言中的句子。
主要解决:对于一些固定文法构建一个解释句子的解释器。
何时使用:如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。
如何解决:构建语法树,定义终结符与非终结符。
应用实例:编译器、运算表达式计算。
使用场景: 1、可以将一个需要解释执行的语言中的句子表示为一个抽象语法树。 2、一些重复出现的问题可以用一种简单的语言来进行表达。 3、一个简单语法需要解释的场景。
优缺点
优点: 1、可扩展性比较好,灵活。 2、增加了新的解释表达式的方式。 3、易于实现简单文法。
缺点: 1、可利用场景比较少。 2、对于复杂的文法比较难维护。 3、解释器模式会引起类膨胀。 4、解释器模式采用递归调用方法。
代码实现
创建一个接口 Expression 和实现了 Expression 接口的实体类。定义作为上下文中主要解释器的 TerminalExpression 类。其他的类 OrExpression、AndExpression 用于创建组合式表达式。
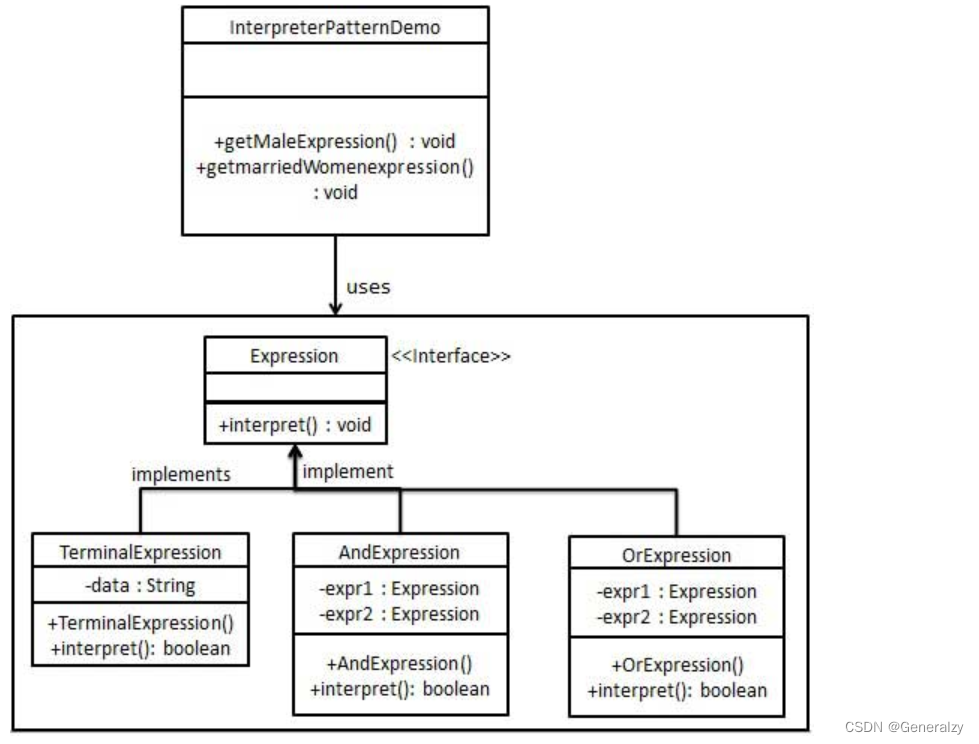
python代码
# Interpreter Pattern with Python Code
from abc import abstractmethod,ABCMeta
#创建一个表达式接口
class Expression(metaclass=ABCMeta):@abstractmethoddef interpret(self, inContext):pass
# 创建实现Expression接口的实体类
class TerminalExpression(Expression):_data = ""def __init__(self,inData):self._data = inDatadef interpret(self,inContext):if inContext.find(self._data) >= 0:return Truereturn False
class OrExpression(Expression):_expr1 = None_expr2 = Nonedef __init__(self,inExpr1,inExpr2):self._expr1 = inExpr1self._expr2 = inExpr2def interpret(self, inContext):return self._expr1.interpret(inContext) or self._expr2.interpret(inContext)
class AndExpression(Expression):_expr1 = None_expr2 = Nonedef __init__(self,inExpr1,inExpr2):self._expr1 = inExpr1self._expr2 = inExpr2def interpret(self, inContext):return self._expr1.interpret(inContext) and self._expr2.interpret(inContext)
# 调用输出
if __name__ == '__main__':# 规则:Robert和John是男性 def getMaleExpression(): robert = TerminalExpression("Robert") john = TerminalExpression("John") return OrExpression(robert,john) # 规则:Julie是一个已婚的女性 def getMarriedWomanExpression(): julie = TerminalExpression("Julie") married = TerminalExpression("Married") return AndExpression(julie,married) isMale = getMaleExpression() isMarriedWoman = getMarriedWomanExpression() print("John is male? " + str(isMale.interpret("John"))) print("Julie is a married women? " + str(isMarriedWoman.interpret("Married Julie")))
go代码
package mainimport ("fmt""strings"
)type Expression interface {interpret(string) bool
}type TerminalExpression struct {data string
}func (t *TerminalExpression) interpret(ctx string) bool {return strings.Contains(ctx, t.data)
}type OrExpression struct {expr1, expr2 Expression
}func (or *OrExpression) interpret(ctx string) bool {return or.expr1.interpret(ctx) || or.expr2.interpret(ctx)
}type AndExpression struct {expr1, expr2 Expression
}func (and *AndExpression) interpret(ctx string) bool {return and.expr1.interpret(ctx) && and.expr2.interpret(ctx)
}func main() {// 为解释器定义语法将John,Robert解释为trueisMale := new(OrExpression)isMale.expr1 = &TerminalExpression{data: "John"}isMale.expr2 = &TerminalExpression{data: "Robert"}//isMarriedWoman := new(AndExpression)isMarriedWoman.expr1 = &TerminalExpression{data: "Julie"}isMarriedWoman.expr2 = &TerminalExpression{data: "Married"}fmt.Println("John is male?", isMale.interpret("John"))}
备忘录模式
备忘录模式(Memento Pattern)保存一个对象的某个状态,以便在适当的时候恢复对象。备忘录模式属于行为型模式。
使用场景
意图:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。
主要解决:所谓备忘录模式就是在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样可以在以后将对象恢复到原先保存的状态。
何时使用:很多时候我们总是需要记录一个对象的内部状态,这样做的目的就是为了允许用户取消不确定或者错误的操作,能够恢复到他原先的状态,使得他有"后悔药"可吃。
应用实例: 1、后悔药。 2、打游戏时的存档。 3、Windows 里的 ctrl + z。 4、IE 中的后退。 5、数据库的事务管理。
使用场景: 1、需要保存/恢复数据的相关状态场景。 2、提供一个可回滚的操作。
注意事项: 1、为了符合迪米特原则,还要增加一个管理备忘录的类。 2、为了节约内存,可使用原型模式+备忘录模式
优缺点
优点: 1、给用户提供了一种可以恢复状态的机制,可以使用户能够比较方便地回到某个历史的状态。 2、实现了信息的封装,使得用户不需要关心状态的保存细节。
缺点:消耗资源。如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存。
代码实现
备忘录模式使用三个类 Memento、Originator 和 CareTaker。Memento 包含了要被恢复的对象的状态。Originator 创建并在 Memento 对象中存储状态。Caretaker 对象负责从 Memento 中恢复对象的状态。
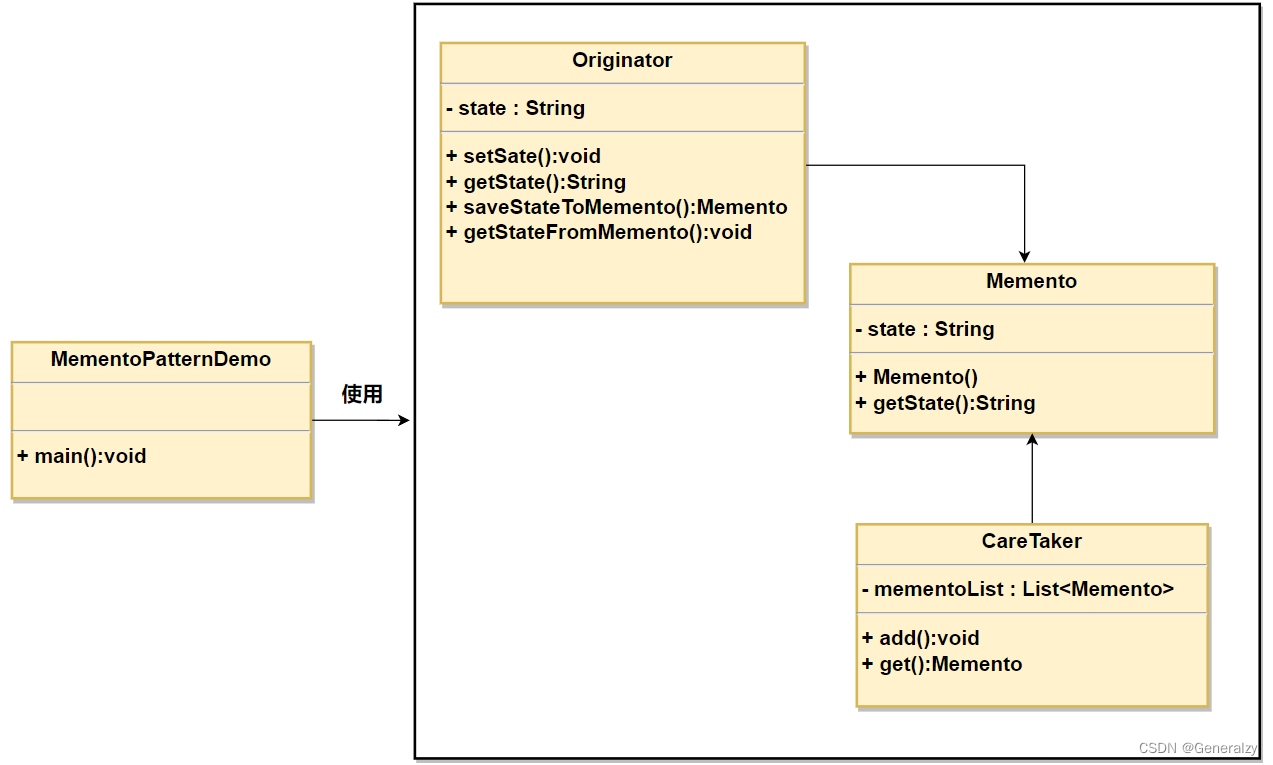
python代码
# Memento Pattern with Python Code
from abc import abstractmethod,ABCMeta# 创建Memento类
class Memento():_state = ""def __init__(self,strState):self._state = strStatedef getState(self):return self._state# 创建Originator类
class Originator():_state = ""def setState(self,strState):self._state = strStatedef getState(self):return self._statedef saveStateToMemento(self):return Memento(self._state)def getStateFromMemento(self,inMemento):self._state = inMemento.getState()# 创建CareTaker类
class CareTaker():_mementoList = []def add(self,inMemento):self._mementoList.append(inMemento)def get(self,inIndex):return self._mementoList[inIndex]# 调用输出
if __name__ == '__main__':originator = Originator()careTaker = CareTaker()originator.setState("State #1")originator.setState("State #2")careTaker.add(originator.saveStateToMemento())originator.setState("State #3")careTaker.add(originator.saveStateToMemento())originator.setState("State #4")print("Current State: " + originator.getState())originator.getStateFromMemento(careTaker.get(0))print("First saved State: " + originator.getState())originator.getStateFromMemento(careTaker.get(1))print("First saved State: " + originator.getState())
go代码
package mainimport "fmt"// 存档
type Memento struct {stat int
}func NewMemento(stat int) *Memento {return &Memento{stat: stat}
}// 主线
type Originator struct {stat int
}func (o *Originator) Set(stat int) {o.stat = stat
}func (o *Originator) saveStateToMemento() *Memento {return &Memento{stat: o.stat}
}func (o *Originator) getStateFromMemento(m *Memento) {o.stat = m.stat
}type CareTaker struct {core []*Memento
}func NewCareTaker() *CareTaker {return &CareTaker{core: make([]*Memento, 0)}
}func (taker *CareTaker) Add(m *Memento) {taker.core = append(taker.core, m)
}func (taker *CareTaker) Get(index int) *Memento {if index > len(taker.core) {return nil}return taker.core[index]
}func main() {origin := Originator{stat: 0}taker := NewCareTaker()origin.Set(1)taker.Add(origin.saveStateToMemento())fmt.Println("current", origin.stat)origin.Set(3)fmt.Println("current", origin.stat)origin.getStateFromMemento(taker.Get(0))fmt.Println("current", origin.stat)
}
执行结果:

状态模式
在状态模式(State Pattern)中,类的行为是基于它的状态改变的。这种类型的设计模式属于行为型模式。
在状态模式中,我们创建表示各种状态的对象和一个行为随着状态对象改变而改变的 context 对象。
使用场景
意图:允许对象在内部状态发生改变时改变它的行为,对象看起来好像修改了它的类。
主要解决:对象的行为依赖于它的状态(属性),并且可以根据它的状态改变而改变它的相关行为。
何时使用:代码中包含大量与对象状态有关的条件语句。
使用场景: 1、行为随状态改变而改变的场景。 2、条件、分支语句的代替者。
注意事项:在行为受状态约束的时候使用状态模式,而且状态不超过 5 个。
优缺点
优点: 1、封装了转换规则。 2、枚举可能的状态,在枚举状态之前需要确定状态种类。 3、将所有与某个状态有关的行为放到一个类中,并且可以方便地增加新的状态,只需要改变对象状态即可改变对象的行为。 4、允许状态转换逻辑与状态对象合成一体,而不是某一个巨大的条件语句块。 5、可以让多个环境对象共享一个状态对象,从而减少系统中对象的个数。
缺点: 1、状态模式的使用必然会增加系统类和对象的个数。 2、状态模式的结构与实现都较为复杂,如果使用不当将导致程序结构和代码的混乱。 3、状态模式对"开闭原则"的支持并不太好,对于可以切换状态的状态模式,增加新的状态类需要修改那些负责状态转换的源代码,否则无法切换到新增状态,而且修改某个状态类的行为也需修改对应类的源代码。
代码实现
创建一个 State 接口和实现了 State 接口的实体状态类。Context 是一个带有某个状态的类。
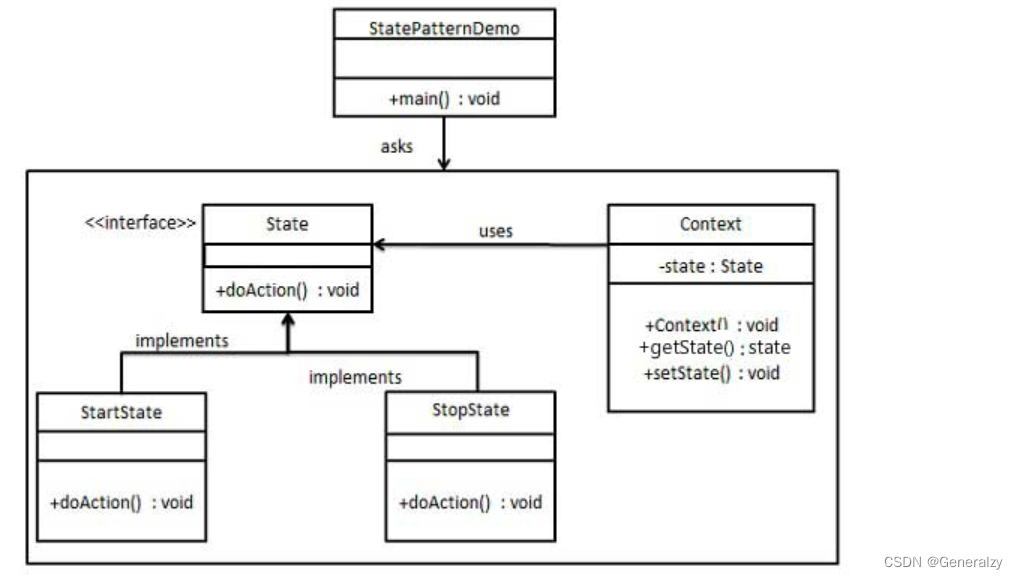
python代码
class State:def __str__(self):return self.__class__.__name__def do_action(self, context: "Context"):raise NotImplementedError()class StopState(State):def do_action(self, context: "Context"):print("Player is in stop state")context.state = selfclass StartState(State):def do_action(self, context: "Context"):print("Player is in start state")context.state = selfclass Context:def __init__(self):self._state = None@propertydef state(self):return self._state@state.setterdef state(self, state: State):self._state = stateif __name__ == '__main__':ctx = Context()start = StartState()start.do_action(ctx)print(ctx.state)
go代码
package mainimport "fmt"type State interface {doAction(*Context)
}type StartState struct {
}func (start *StartState) doAction(ctx *Context) {fmt.Println("Player is in start state")ctx.SetState(start)
}func (start *StartState) String() string {return "startState"
}type Context struct {state State
}func (ctx *Context) SetState(state State) {ctx.state = state
}func (ctx *Context) GetState() State {return ctx.state
}func main() {ctx := Context{state: nil}start := StartState{}start.doAction(&ctx)fmt.Println(ctx.GetState())
}
相关文章:
23种计模式之Python/Go实现
目录 设计模式what?why?设计模式:设计模式也衍生出了很多的新的种类,不局限于这23种创建类设计模式(5种)结构类设计模式(7种)行为类设计模式(11种) 六大设计原则开闭原则里氏替换原…...

Qt可视化大屏布局
科技大屏现在非常流行,这里分享一下某个项目的大屏布局(忘了源码是哪个博主的了) 展示 这个界面整体是垂直布局,分为两个部分,标题是一个部分,然后下面的整体是一个layout布局,为另外一部分。 l…...

re:从0开始的CSS之旅 14. 显示模式的切换
1. 两个属性 display 属性可以用于转换元素的显示模式 可选值: block 转换为块元素 inline 转换为行内元素 inline-block 转换为行内块元素 none 不显示元素,并且不占用元素的位置 visibility 属性用于设置元素是否显示 可选值: visible 显示…...

K8S系列文章之 [Alpine基础环境配置]
用户手册:Alpine User Handbook 官方WIKI:Alpine Linux WIKI 安装 安装的实际逻辑是通过 setup-alpine 脚本去调用其他功能的脚本进行配置,可以通过 vi 查看脚本。如果某个部分安装失败,可退出后单独再次执行。通过镜像文件&a…...
单页404源码
<!doctype html> <html> <head> <meta charset"utf-8"> <title>简约 404错误页</title><link rel"shortcut icon" href"./favicon.png"><style> import url("https://fonts.googleapis.co…...

MySQL-运维
一、日志 1.错误日志 错误日志是MySQL中最重要的日志之一,它记录了当mysql启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关性息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。 该日志是默认开启的…...
Waymo数据集下载与使用
在撰写论文时,接触到一个自动驾驶数据集Waymo Dataset 论文链接为:https://arxiv.org/abs/1912.04838v7 项目链接为:https://github.com/waymo-research/waymo-open-dataset 数据集链接为:https://waymo.com/open waymo提供了两种…...

蓝桥杯每日一题----素数筛
素数筛 素数筛的作用是筛选出[2,N]范围内的所有素数,本次主要讲解两种方法,分别是埃氏筛和欧拉筛。证明时会提到唯一分解定理,如果不知道的小伙伴可以先去学一学,那我们开始啦! 1.埃氏筛 主要思想:当找到…...
20240212请问如何将B站下载的软字幕转换成为SRT格式?
20240212请问如何将B站下载的软字幕转换成为SRT格式? 2024/2/12 12:47 百度搜索:字幕 json 转 srt json srt https://blog.csdn.net/a_wh_white/article/details/120687363?share_token2640663e-f468-4737-9b55-73c808f5dcf0 https://blog.csdn.net/a_w…...

《CSS 简易速速上手小册》第6章:高级 CSS 技巧(2024 最新版)
文章目录 6.1 使用 CSS 变量进行设计:魔法配方的调配6.1.1 基础知识6.1.2 重点案例:创建可定制的主题6.1.3 拓展案例 1:响应式字体大小6.1.4 拓展案例 2:使用 CSS 变量创建动态阴影效果 6.2 calc(), min(), max() 等函数的应用&am…...

2024-02-11 多进程、多线程 work
1. 创建一个多进程服务器和多线程服务器 a. 多进程 #include<myhead.h> #define PORT 9999 //端口号 #define IP "192.168.125.113" //IP地址//定义信号处理函数,用于回收僵尸进程 void handler(int signo) {if(signo S…...

详解结构体内存对齐及结构体如何实现位段~
目录 编辑 一:结构体内存对齐 1.1对齐规则 1.2.为什么存在内存对齐 1.3修改默认对齐数 二.结构体实现位段 2.1什么是位段 2.2位段的内存分配 2.3位段的跨平台问题 2.4位段的应用 2.5位段使用的注意事项 三.完结散花 悟已往之不谏,知来者犹可…...
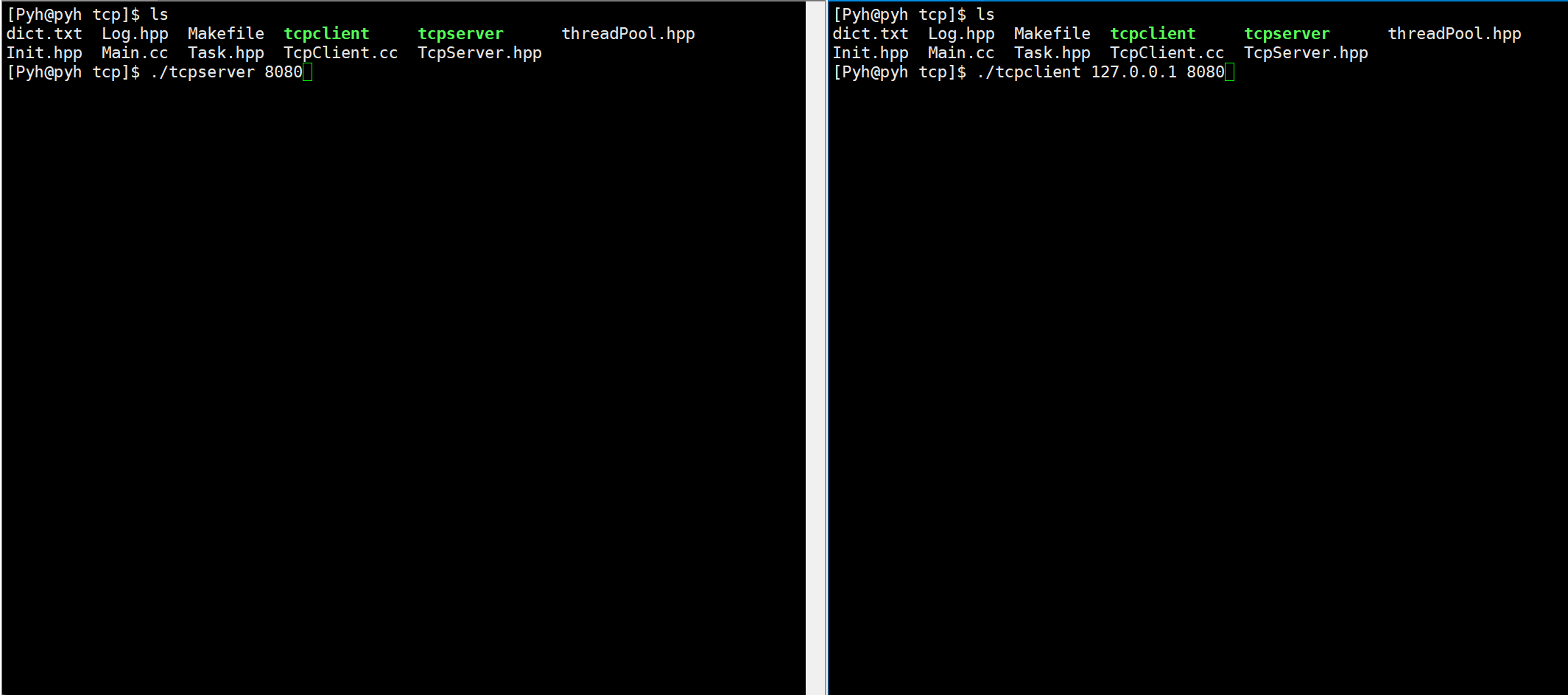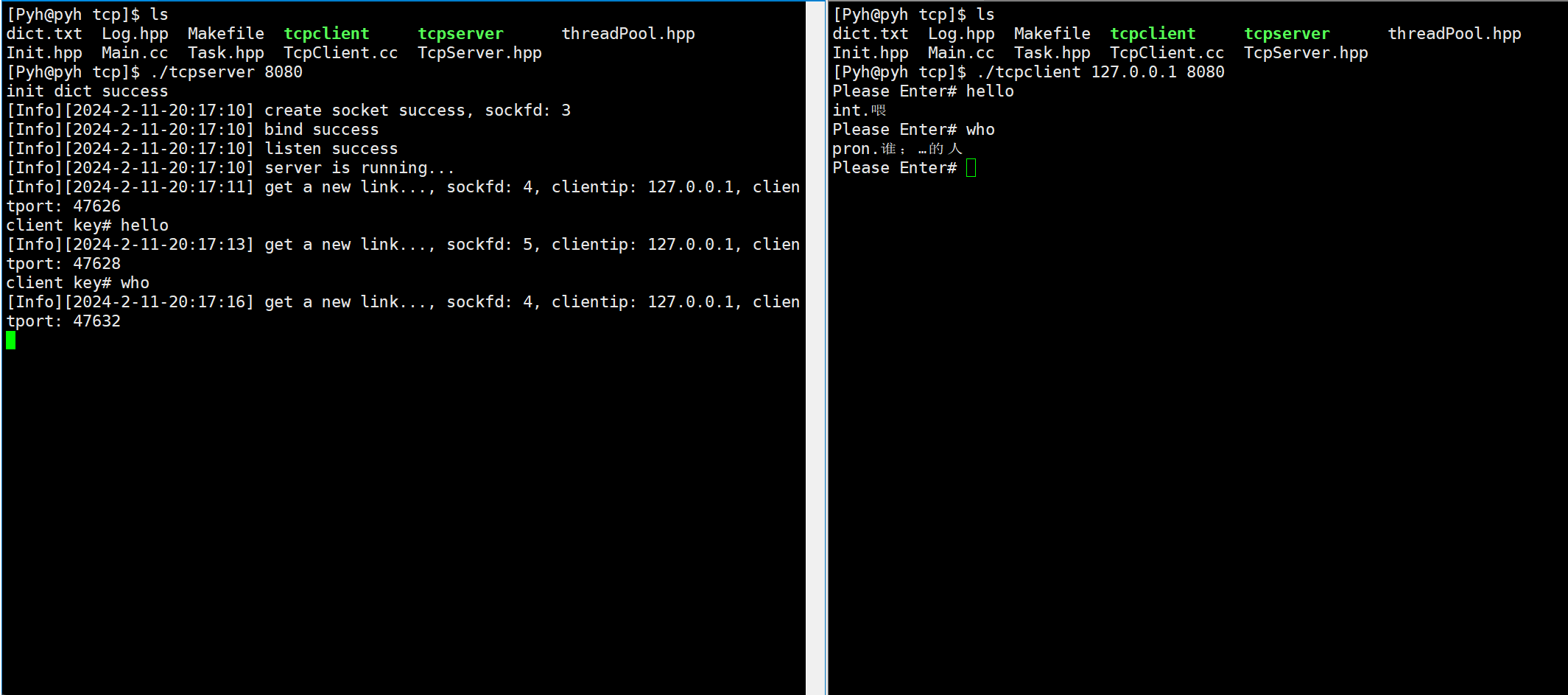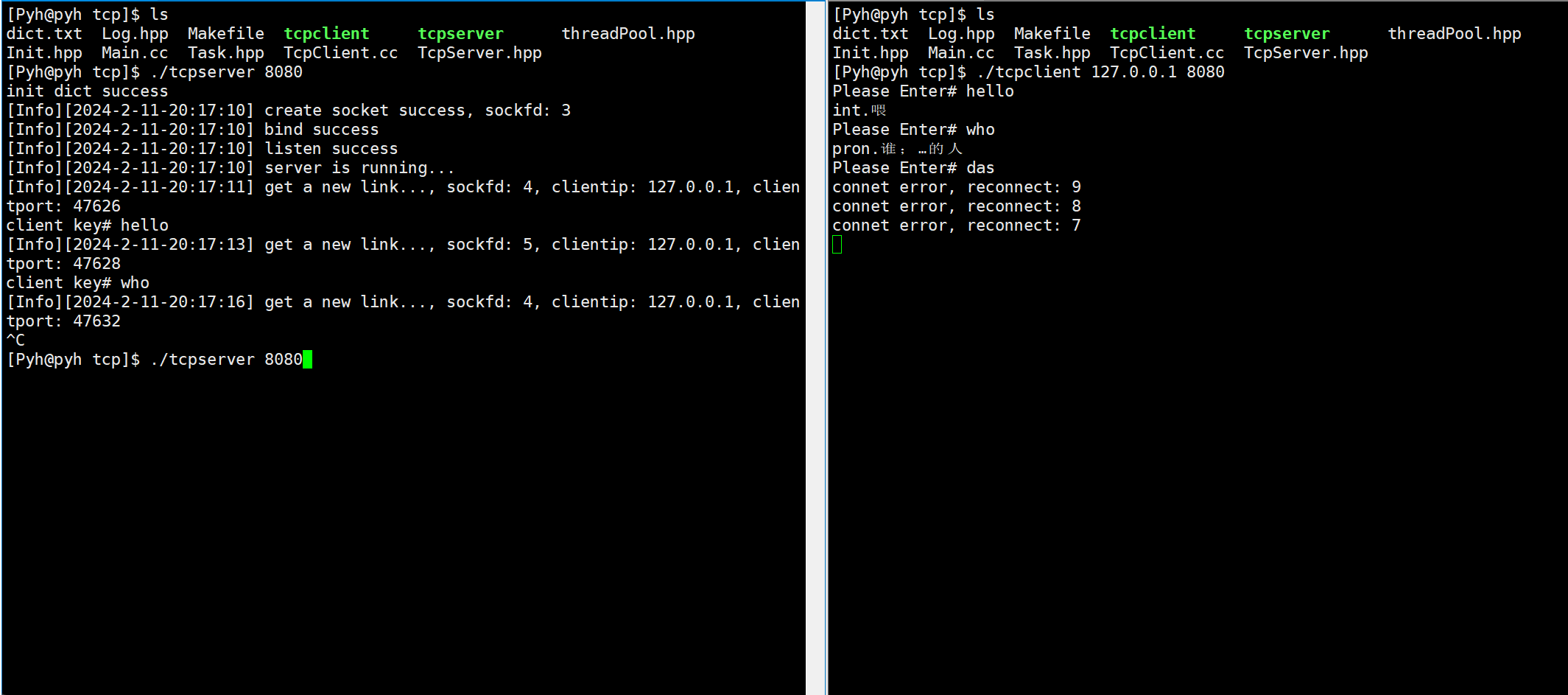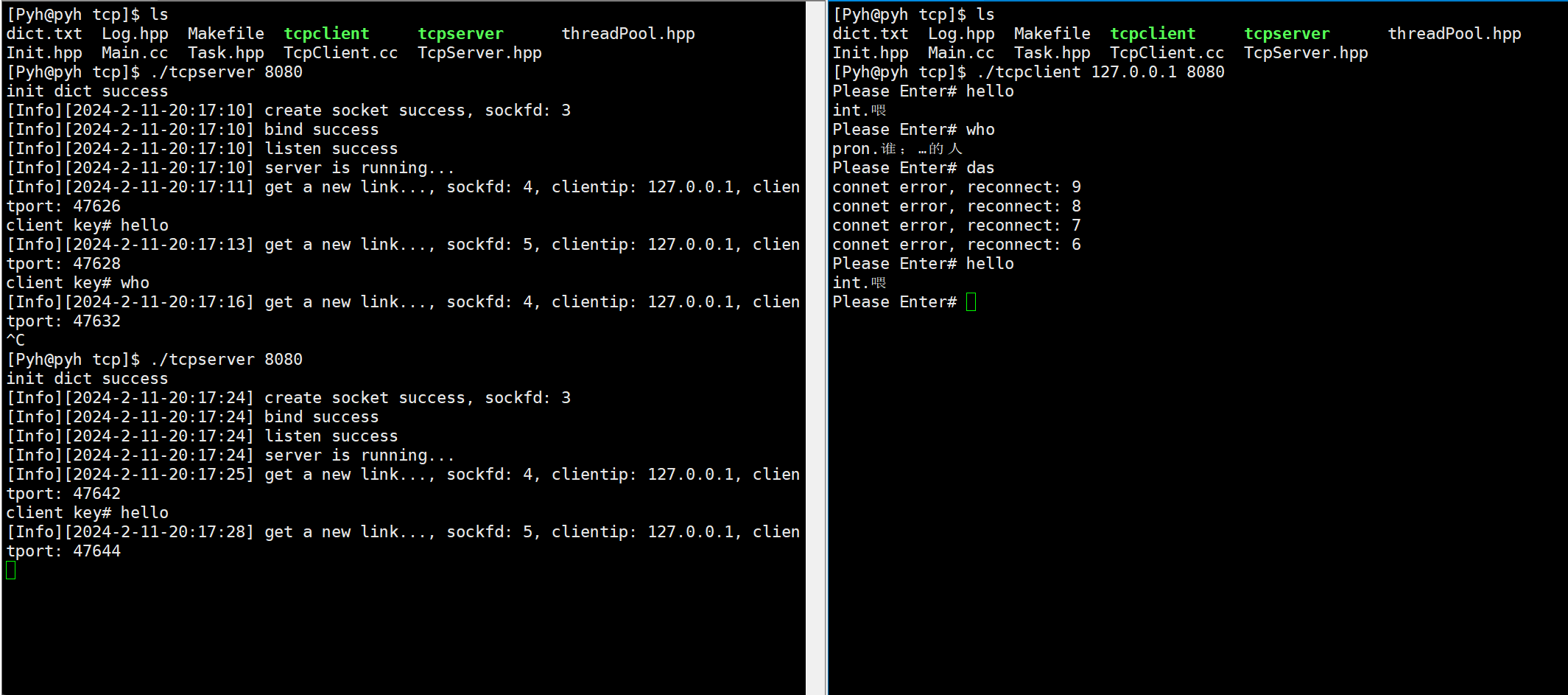
Linux网络编程——tcp套接字
文章目录 主要代码关于构造listen监听accepttelnet测试读取信息掉线重连翻译服务器演示 本章Gitee仓库:tcp套接字 主要代码 客户端: #pragma once#include"Log.hpp"#include<iostream> #include<cstring>#include<sys/wait.h…...

【计算机网络】协议层次及其服务模型
协议栈(protocol stack) 物理层链路层网络层运输层应用层我们自顶向下,所以从应用层开始探究应用层 协议 HTTP 提供了WEB文档的请求和传送SMTP 提供电子邮件报文的传输FTP 提供两个端系统之间的文件传输报文(message)是…...

prometheus之redis_exporter部署
下载解压压缩包 mkdir /opt/redis_exporter/ cd /opt/redis_exporter/ wget http://soft.download/soft/linux/prometheus/redis_exporter/redis_exporter-v1.50.0.linux-amd64.tar.gz tar -zxvf redis_exporter-v1.50.0.linux-amd64.tar.gz ln -s /opt/redis_exporter/redis_…...

js 解构赋值
搬运:JavaScript系列之解构赋值_js解构赋值-CSDN博客...

Vivado用ILA抓波形保存为CSV文件
将ILA观察到的波形数据捕获为CSV文件,抓10次,把文件合并,把源文件删除 运行方法:Vivado的 Tcl console 窗口输入命令 set tcl_dir F:/KLD_FPGA/Code/sim set tcl_filename TCL_ILA_TRIG_V1.2.tcl source $tcl_dir/$tcl_filenam…...
微软AD域替代方案,助力企业摆脱hw期间被攻击的窘境
在红蓝攻防演练(hw行动)中,AD域若被攻击成功,是其中一个扣分最多的一项内容。每年,宁盾都会接到大量AD在hw期间被攻击,甚至是被打穿的企业客户。过去,企业还会借助2FA双因子认证加强OA、Exchang…...

Git教程I
Git教程I 本地Git创建git仓库将修改存到暂存区将暂存区提交到当前分支查看提交历史回退版本恢复到更晚的版本创建新分支切换分支简单的分支合并冲突分支合并不使用fast forward: --no-ff 远程Git连接远程仓库将本地分支上传到远程仓库从远程仓库拉取 本地Git 学习如何使用本地…...
镜像验证)
containerd中文翻译系列(十)镜像验证
下面将介绍默认的 "bindir"ImageVerifier插件实现。 要启用图像验证,请在 containerd 配置中添加类似下面的一段: [plugins][plugins."io.containerd.image-verifier.v1.bindir"]bin_dir "/opt/containerd/image-verifier/b…...
的三大优势)
EMD过时了?从故障诊断实战看经验小波变换(EWT)的三大优势
EMD过时了?从故障诊断实战看经验小波变换(EWT)的三大优势 在工业设备状态监测领域,振动信号分析一直是故障诊断的黄金标准。传统方法如经验模态分解(EMD)曾因其自适应特性广受推崇,但工程师们逐渐发现它在处理轴承点蚀、齿轮断齿等典型故障时…...

别再一段段拼了!用UE4蓝图+Spline Component一键生成连续管道/道路模型
UE4蓝图Spline Component自动化生成复杂路径模型实战指南 在游戏开发中,创建蜿蜒的管道、复杂的赛道或是连绵的城墙往往需要耗费大量时间。传统的手动拼接SplineMesh组件的方式不仅效率低下,而且难以保证模型的连续性和一致性。本文将深入探讨如何利用UE…...

终极指南:如何在Windows上免费扩展虚拟显示器,轻松打造多屏工作空间
终极指南:如何在Windows上免费扩展虚拟显示器,轻松打造多屏工作空间 【免费下载链接】virtual-display-rs A Windows virtual display driver to add multiple virtual monitors to your PC! For Win10. Works with VR, obs, streaming software, etc …...

自动同步总失败?NotebookLM本地缓存+云端快照双轨备份,手把手配置到上线仅需7分钟
更多请点击: https://intelliparadigm.com 第一章:NotebookLM数据备份方案 NotebookLM 是 Google 推出的基于用户上传文档进行 AI 助理问答的工具,但其本身不提供原生数据导出或持久化存储功能。为防止项目上下文丢失、模型重置或账户异常导…...

ARM Thumb指令集内存屏障详解:DMB、DSB与ISB
1. ARM Thumb指令集中的内存屏障指令概述在嵌入式系统和移动设备开发中,ARM处理器占据着主导地位。作为RISC架构的代表,ARM提供了多种指令集以适应不同场景的需求,其中Thumb指令集以其高代码密度著称。在多核处理器和并发编程场景下ÿ…...
)
别再为调试发愁!FreeRTOS下STM32串口打印的三种实用方案(含USART3重定向避坑)
FreeRTOS下STM32串口调试的三大实战方案与深度优化指南 在嵌入式开发中,调试信息的输出如同黑夜中的灯塔,为开发者指明程序运行的轨迹。当FreeRTOS遇上STM32,串口打印这个看似基础的功能却可能成为项目推进的绊脚石。本文将带您深入探索三种经…...

第1章:AI Agent认知与全景图
本章你将收获:AI Agent的核心概念与演变历程;主流框架(LangChain、AutoGPT、CrewAI)的深度对比与选型指南;5个真实Agent应用案例的拆解;一套评估项目是否需要引入Agent的决策方法论;以及可运行的Agent代码示例(含免费API)。 📌 本章导读 2024年以来,“AI Agent”成…...

多平台布局时代,店群账号高效管控之道
在电商行业持续精细化运营的当下,店群模式仍是商家拓宽渠道、分散风险、提升规模效应的主流选择。伴随抖店、拼多多、TikTok Shop、Temu、亚马逊等国内外平台规则趋严,多店铺账号管理已成为制约店群商家稳定经营的关键瓶颈。传统依赖人工登记、多设备登录…...

激光雷达仿真:禾赛与NVIDIA联手,如何用数字孪生重塑自动驾驶研发?
1. 项目概述:当激光雷达遇上数字孪生最近,禾赛科技和NVIDIA的合作又往前迈了一大步,这事儿在自动驾驶圈子里挺受关注的。简单来说,就是禾赛的激光雷达模型,现在可以直接在NVIDIA的DRIVE Sim仿真平台里调用了。这意味着…...

【亲测免费】 Realtek-RTD2660源代码:开启显示设备定制化的新纪元
Realtek-RTD2660源代码:开启显示设备定制化的新纪元 【下载地址】Realtek-RTD2660源代码源程序 本仓库提供Realtek-RTD2660源代码源程序的下载。该资源文件适用于7至19寸的显示设备,为开发者提供了完整的源代码,方便进行二次开发和定制 项目…...