企业级DevOps实战
第1章 Zookeeper服务及MQ服务
Zookeeper(动物管理员)是一个开源的分布式协调服务,目前由Apache进行维护。
MQ概念
MQ(消息队列)是一种应用程序之间的通信方法,应用程序通过读写出入队列的消息(针对应用程序的数据)通信,而无须专用连接。
MQ是一种先进先出的数据结构,是指把要传输的数据(消息)放在队列中,用队列机制实现消息传递——生产者产生消息并把消息放入队列,然后由消费者处理。消费者可以到指定队列拉取消息或者订阅相应的队列,由MQ服务推送消息。
MQ中间件是分布式系统中的重要组件,主要用于解决应用解耦、异步消息、流量削峰等问题,实现高性能、高可用、可伸缩和最终一致性架构。
MQ的优点
1.应用解耦:通常一个业务需要多个模块共同实现,或者一条消息有多个系统需要对应处理。但使用MQ中间件,在主业务完成后,发送一条MQ消息,其余模块消费MQ消息,即可实现业务,从而降低模块之间的耦合。
2.异步消息:主业务执行结束后从属业务会通过MQ异步执行,从而降低业务的响应时间,提高用户体验。
3.流量削峰:在高并发情况下,业务可以异步处理,分散高峰期业务处理压力,避免系统瘫痪。
MQ简介
RabbitMQ,ActiveMQ,RocketMQ,Kafka等。
MQ通常用于程序之间进行数据通信,程序之间不需要直接调用彼此来通信。
RabbitMQ概念剖析
除了性能高以外,还有以下5个特点。
1.开源,性能优秀,具有稳定性保障。
2.提供可靠性消息投递模式,返回模式。
3.与Spring AMQP完美结合,API丰富。
4.集群模式丰富,表达式配置,HA模式,镜像队列模型。
5.在保证数据不丢失的前提下可保证高可靠性、可用性。
RabbitMQ完整的消息通信过程包括以下3个概念。
1.发布者:发布消息的应用程序。
2.队列:用于消息存储的缓冲。
3.消费者:接收消息的应用程序。
Kafka概念剖析
Zookeeper简介
Zookeeper是一款解决分布式应用架构中一致性问题的工具,Kafka消息队列要用到Zookeeper。在分布式应用架构(去中心化集群模式)中,需要让消费者知道现在有哪些生产者(对于消费者而言,Kafka就是生产者)是可用的。
如果没有Zookeeper注册中心,消费者如何知道生产者呢?如果每次消费者在消费之前都去连接生产者,测试连接是否成功,效率就会变得很低。
Kafka利用Zookeeper的分布式协调服务,将生产者、消费者、消息存储(broker,用于存储信息,消息读写等)结合在一起。借助于Zookeeper,Kafka能够将包括生产者、消费者和broker在内的所有组件在无状态的条件下建立起生产者和消费者的订阅关系,实现生产者的负载均衡。
第3章 Hadoop分布式存储企业实战
Hadoop实现了一个分布式文件系统,其中一个组件是HDFS。HDFS有高容错的特点,用来部署在低廉的硬件上,适合那些有超大数据集的应用程序。
HDFS放宽了POSTIX的要求,可以以流的形式访问文件系统中的数据。Hadoop框架最核心的设计师HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算。
Hadoop服务组件
Hadoop生态圈的服务组件繁多,常见的有Common、HDFS、HBase、MapReduce等。
Kafka、Hive、Pig、Mahout、SparkSQL、MapReduce、Spark、Impala、Hbase、YARN、HDFS、Sqoop、Flume、Common、Zookeeper
1.Hadoop Common是Hadoop体系最底层的一个模块,为Hadoop各个子模块提供各种工具,如系统配置工具Configuration、远程调用RPC、序列化机制和日志操作等,是其他模块的基础。
2.HDFS是Hadoop分布式文件系统缩写,是Hadoop的基石。HDFS是一个具备高度容错性的文件系统,适合部署在廉价的机器上能提供高吞吐量的数据访问,非常适合具有大规模数据集的应用。
3.YARN是统一资源管理和调度平台。它解决了上一代Hadoop资源利用率低和不能兼容异构计算框架等多种问题,实现了资源隔离方案和双调度器。
4.MapReduce是一种编程模型,利用函数式编程思想,将对数据集的过程分为Map和Reduce两个阶段。MapReduce编程模型非常适合进行分布式计算。Hadoop提供MapReduce的计算框架,实现了这种编程模型,开发人员可以通过Java、C++、Python、PHP等多种语言进行编程。
5.Spark与MapReduce相比性能提升明显,可以与YARN集成,还提供了SparkSQL组件。
6.Hbase采用了Bigbase的数据模型——列族。Hbase擅长对大规模数据进行随机、实时读写访问。
7.Zookeeper作为一个分布式服务架构,是基于Fast Paxos算法实现的,解决分布式系统中一致性问题。提供了配置维护、名字服务、分布式同步、组服务等。
Hive是Facebook开发并使用的,是基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张表,提供简单的SQL查询功能,并将SQL转化为MapReduce作业。优点是学习成本低,降低了Hadoop的使用门槛。
8.Pig与Hive类似,也是对大规模数据集进行分析和评估的工具。与Hive不同的是,Pig提供了一种高层的、面向领域的抽象语言Pig Latin。Pig可以将Pig Latin转化为Mapreduce作业。与SQL相比,Pig Latin更加灵活,但学习成本更高。
9.Impala可以对数据提供交互查询的SQL接口。Impala和Hive使用相同的统一存储平台,相同的元数据,SQL语法,ODBC驱动和用户界面。Impala还提供了一个熟悉的面向批量或者实时查询的统一平台。Impala的特点是查询速度非常快,其性能大幅度领先于Hive。Impala并不是基于MapReduce的,他它的定位是OLAP,是Google的新三驾马车之一Dremel的开源实现。
10.Mahout是一个机器学习和数据挖掘的库,它利用MapReduce编程模型实现k-means、Native、Bayes、Collaborative Filtering等经典的机器学习算法,并使其具有良好的的可扩展性。
11.Flume是一个高可用、高可靠、分布式的海量日志采集、聚合和传输系统,支持在日志系统中定制各类数据发送方,用于数据收集。Flume拥有对数据进行简单处理并写到各个数据接收方的能力。
12.Sqoop是SQL to Hadoop的缩写,主要作用是在结构化的数据存储与Hadoop之间进行数据双向交换。也就是说,Sqoop可以将关系型数据库的数据导入HDFS,Hive,也可以将其从HDFS,Hive导出到关系型数据库中。Sqoop利用了Hadoop的优点,整个导入导出都是由MapReduce计算框架实现并行化,非常高效。
13.Kafka是一种高吞吐量的分布式发布/订阅的消息系统,具有分布式、高可用的特性,在大数据系统中得到了广泛的应用。如果把大数据系统比作一台计算机,俺么Kafka就是前端总线,来你家诶了平台中的各个组件。
Hadoop除了使用web接口,还可以使用shell命令进行访问,包括了一系列的类shell命令,可直接与HDFS及其他Hadoop支持的文件系统交互。bin/hadoop fs-help命令可以列出所有Hadoop Shell支持的命令。
第4章 Service Mesh及Istio服务治理
Service Mesh即服务网格,是一个用于处理服务之间通信的基础设施层,负责为构建复杂的云原生应用传递可靠的的网络请求,并为服务之间的通信提供了微服务所需的基本组件功能,如服务发现、负载均衡、监控、流量管理、访问控制等。
Service Mesh有以下4个特点。
1.治理能力独立(Sidecar)。
2.应用程序无感知。
3.服务通信的基础设施。
4.解耦应用程序的重试/超时、监控、跟踪和服务发现。
Service Mesh是建立在TCP层之上的微服务层。
简单来说,网络代理可以简单类比成现实生活中的中间人,因为各种原因在通信双方中间加上一道关卡。本来双方能直接完成通信,为何要多此一举呢?因为该关卡(代理)可以为整个通信带来更多的功能,如拦截、统计、缓存、注入、分发、跳板等。
用户请求出现问题无外乎两个:错误和响应慢。
官方对Istio的介绍浓缩成了一句话:
连接、安全加固、控制和观察服务的开放平台。
Istio与Kebernetes结合
Istio是微服务通信和治理的基础设施层,本身并不负责服务的部署和集群管理,因为需要和Kubernetes等服务编排工具协同工作。
Istio在架构设计上支持各种服务部署平台,包括Kubernetes等。Istio作为Google亲儿子,对自家兄弟Kubernetes的支持肯定是优先考虑的。
各种部署平台可以通过插件方式集成到Istio中,为Istio提供服务注册和服务发现功能。
Istio架构与组件
1.数据平面:由一组代理组成,代理微服务所有的网络通信,并接收和实施来自Mixer的策略。
2.Proxy:负责高效转发与策略实现。
3.控制平面:管理和配置代理来路由流量。此外,通过Mixer实施策略与收集来自边车代理的数据。
4.Mixer:适配组件,数据平面与控制平面通过它来交互,为Proxy提供策略和数据上报。
5.Pilot:策略配置组件,为Proxy提供服务发现、智能路由、错误处理等。
6.Citadel:安全组件,提供证书生成下发、加密通信、访问控制功能。
7.Galley:配置管理、验证、分发。
Isito包括如下内容:
1.自动为HTTP、gRPC、WebSocket和TCP流量负载均衡。
2.通过丰富的路由规则、重试、故障转移和故障注入对流量行为进行细粒度控制。
3.可插拔的策略层和配置API,支持访问控制、速率限制和配额。
4.集群内所有流量的自动度量,具有日志记录和跟踪功能,包括集群的入口和出口。
5.通过强大的基于身份的身份验证和授权,在集群中进行安全的通信。
第5章 企业级DevOps应用实战
DevOps是一组过程、方法与系统的统称。
DevOps是一种软件开发方法。
软件在整个开发生命周期中的持续开发、持续测试、持续集成、持续部署和持续监控等活动只能在DevOps中实现,而不是敏捷开发或瀑布开发,这就是为什么顶级互联网公司选择DevOps作为其业务目标前进方向的原因。DevOps是在较短的开发周期内开发高质量软件的首选方法,可以提高客户满意度。
敏捷开发与DevOps的区别
敏捷开发以用户的需求进化为核心,采用迭代、循序渐进的方法进行软件开发。在敏捷开发中,软件项目在构建初期被切分成多个子项目,各个子项目的成果都经过测试,具备可视、可集成和可运行使用的特征。换言之,就是把一个大项目分为多个相互联系,但也可独立运行的小项目,并分别完成,在此过程中软件一直处于可使用状态。
敏捷开发的优点:
1.敏捷开发属于增量式开发,对于需求范围不明确、需求变更较多的项目而言,可以很大程度上响应及拥抱变化。
2.对于互联网产品而言,市场风向转变很快,需要一种及时快速的交付形式,而敏捷开发则能更好地适用于此。
3.敏捷开发可最大程度体现80/20法则的价值,通过增量迭代每次都优先交付那些能产生80%价值效益的20%功能,最大化单位成本收益。
实际上,DevOps是一种敏捷开发的方法,但已超越了它。DevOps是软件开发生命周期从瀑布式到敏捷再到精益的发展。通常情况下,出现浪费或瓶颈的场景包括不一致的环境,人工的构建和部署流程、差的质量和测试实践、IT部门之间缺少沟通和理解、频繁地中断和失败的协定,以及那些需要珍贵的资源、花费大量的时间和金钱才能保持系统运行的全套问题。
相关文章:

企业级DevOps实战
第1章 Zookeeper服务及MQ服务 Zookeeper(动物管理员)是一个开源的分布式协调服务,目前由Apache进行维护。 MQ概念 MQ(消息队列)是一种应用程序之间的通信方法,应用程序通过读写出入队列的消息࿰…...

C++中的new和delete
1.new和delete的语法 我们知道C语言的内存管理方式是malloc、calloc、realloc和free,而我们的C中除了可以使用这些方式之外还可以选择使用new和delete来进行内存管理。 new和delete的主要语法如下 从上面的代码我们只能知道new要比malloc好写一些,但是其…...

rtt设备io框架面向对象学习-dac设备
目录 1.dac设备基类2.dac设备基类的子类3.初始化/构造流程3.1设备驱动层3.2 设备驱动框架层3.3 设备io管理层 4.总结5.使用 1.dac设备基类 此层处于设备驱动框架层。也是抽象类。 在/ components / drivers / include / drivers 下的dac.h定义了如下dac设备基类 struct rt_da…...
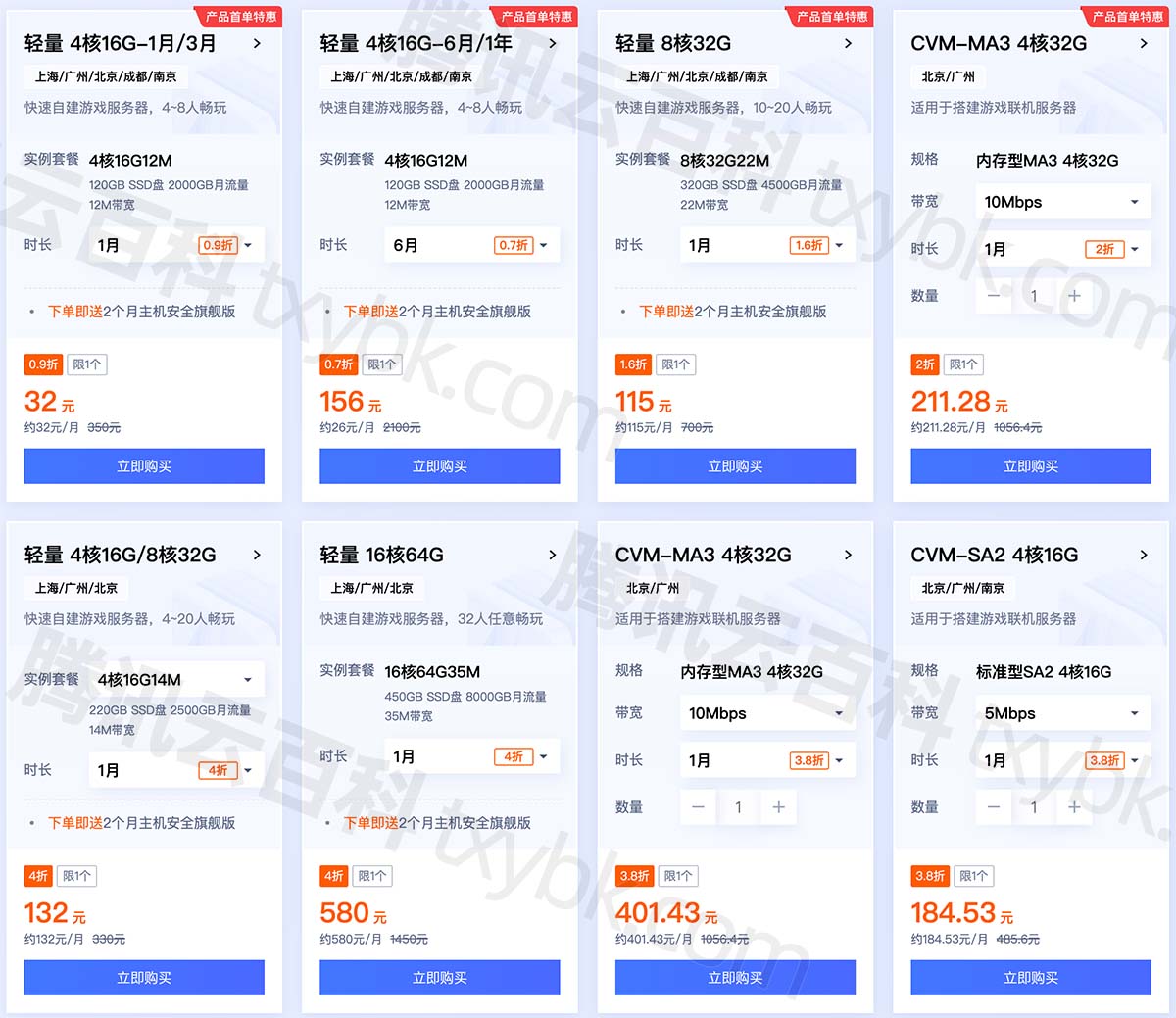
腾讯云幻兽帕鲁服务器配置怎么选择合适?
腾讯云幻兽帕鲁服务器配置怎么选?根据玩家数量选择CPU内存配置,4到8人选择4核16G、10到20人玩家选择8核32G、2到4人选择4核8G、32人选择16核64G配置,腾讯云百科txybk.com来详细说下腾讯云幻兽帕鲁专用服务器CPU内存带宽配置选择方法ÿ…...

796. 子矩阵的和
Problem: 796. 子矩阵的和 文章目录 思路解题方法复杂度Code 思路 这是一个二维前缀和的问题。二维前缀和的主要思想是预处理出一个二维数组,使得每个位置(i, j)上的值表示原数组中从(0, 0)到(i, j)形成的子矩阵中所有元素的和。这样,对于任意的子矩阵(x…...

如何在 Python 中处理 Unicode
介绍 Unicode 是世界上大多数计算机的标准字符编码。它确保文本(包括字母、符号、表情符号,甚至控制字符)在不同设备、平台和数字文档中显示一致,无论使用的操作系统或软件是什么。它是互联网和计算机行业的重要组成部分…...

CSDN文章导出PDF整理状况一览
最近CSDN有了导出文章PDF功能,导出的PDF还可以查询, 因此,把文章导出PDF,备份一下自己的重要资料。 目前整理内容如下 No.文章标题整理时间整理之后 文章更新Size (M)10001_本地电脑-开发相关软件保持位…...
)
jmeter-05变量(用户定义变量,用户参数,csv文档参数化)
文章目录 一、jmeter有三种变量二、用户定义变量(这个更多的可以理解为全局变量)1、设置2、引用三、用户参数(可以理解为局部变量)1、设置2、引用3、用户参数化要配合线程组的线程数使用4、结果五、csv文档参数1、创建csv文件2、设置2、引用csv文件可以配合线程组的线程数,…...

CSS之水平垂直居中
如何实现一个div的水平垂直居中 <div class"content-wrapper"><div class"content">content</div></div>flex布局 .content-wrapper {width: 400px;height: 400px;background-color: lightskyblue;display: flex;justify-content:…...

2.8日学习打卡----初学RabbitMQ(三)
2.8日学习打卡 一.springboot整合RabbitMQ 之前我们使用原生JAVA操作RabbitMQ较为繁琐,接下来我们使用 SpringBoot整合RabbitMQ,简化代码编写 创建SpringBoot项目,引入RabbitMQ起步依赖 <!-- RabbitMQ起步依赖 --> <dependency&g…...

Unity学习笔记(零基础到就业)|Chapter02:C#基础
Unity学习笔记(零基础到就业)|Chapter02:C#基础 前言一、复杂数据(变量)类型part01:枚举数组1.特点2.枚举(1)基本概念(2)申明枚举变量(3ÿ…...

容器化的基础概念:不可变基础设施解释:将服务器视为乐高积木,而非橡皮泥。
不可变基础设施解释:将服务器视为乐高积木,而非橡皮泥。 想象一下用乐高积木代替橡皮泥进行搭建。使用橡皮泥时,您可以直接塑形和改变它。而使用乐高积木,您需要逐个零件搭建特定结构,并在需要时整体替换它们。这就是…...
智胜未来,新时代IT技术人风口攻略-第二版(弃稿)
文章目录 抛砖引玉 鸿蒙生态小科普焦虑之下 理想要落到实处校园鼎力 鸿蒙发展不可挡培训入场 机构急于吃红利企业布局 鸿蒙应用规划动智胜未来 技术人风口来临 鸿蒙已经成为行业的焦点,未来的发展潜力无限。作为一名程序员兼UP主,我非常荣幸地接受了邀请…...
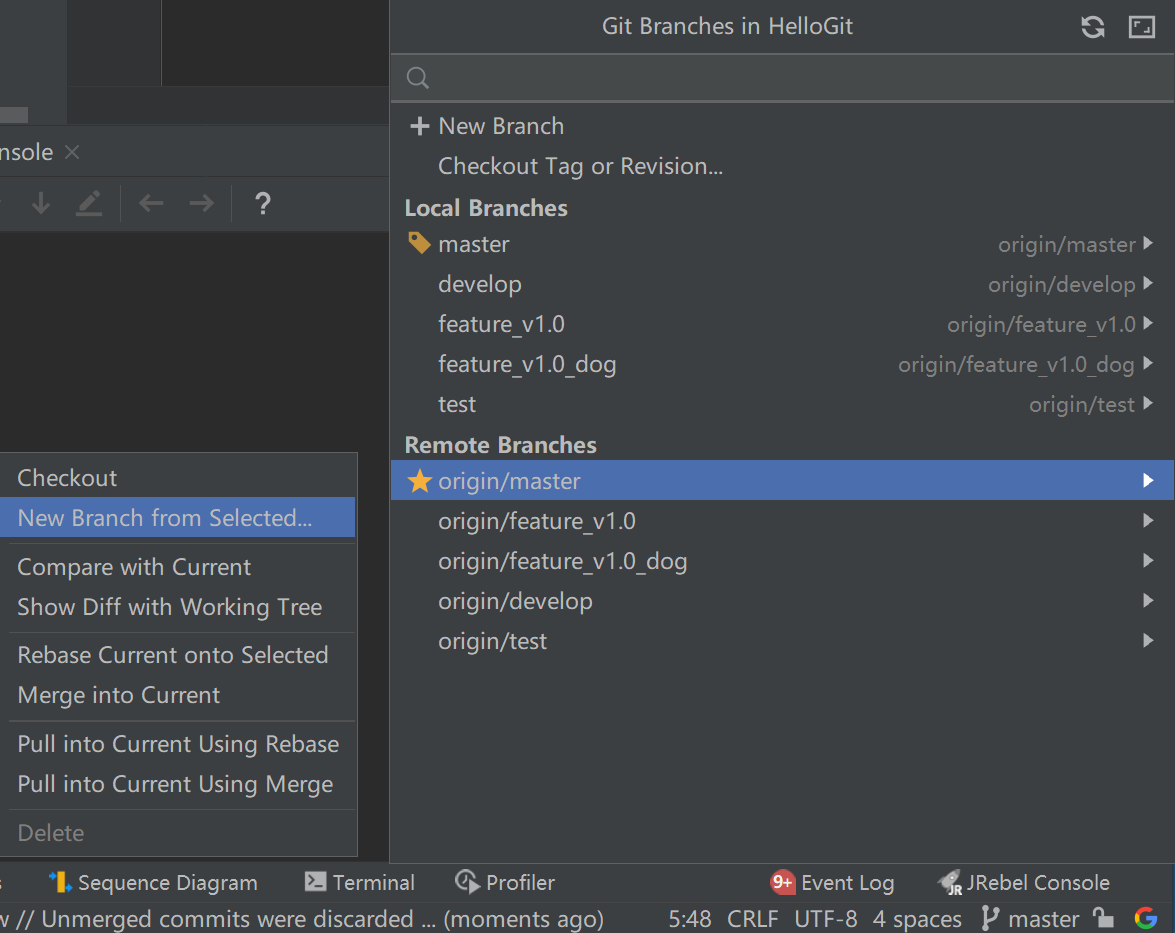
Git分支和迭代流程
Git分支 feature分支:功能分支 dev分支:开发分支 test分支:测试分支 master分支:生产环境分支 hotfix分支:bug修复分支。从master拉取,修复并测试完成merge回master和dev。 某些团队可能还会有 reale…...
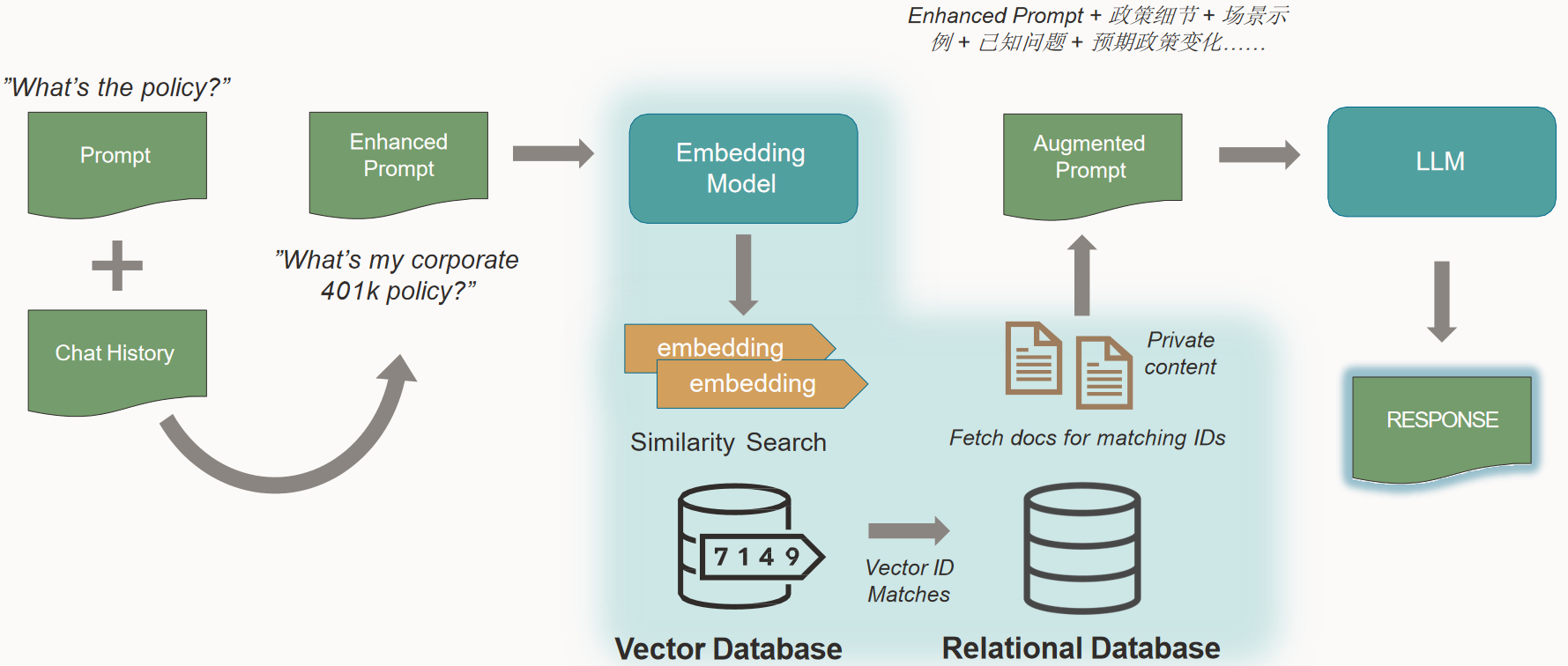
数据库管理-第150期 Oracle Vector DB AI-02(20240212)
数据库管理150期 2024-02-12 数据库管理-第150期 Oracle Vector DB & AI-02(20240212)1 LLM2 LLM面临的挑战3 RAG4 向量数据库LLM总结 数据库管理-第150期 Oracle Vector DB & AI-02(20240212) 作者:胖头鱼的鱼…...

MySQL双写机制
双写机制 问题的出现 在发生数据库宕机时,可能Innodb正在写入某个页到表中,但是这个页只写了一部分,这种情况被称为部分写失效,虽然innodb会先写重做日志,在修改页,但是重做日志中记录的是对页的物理操作,但…...
uniapp的配置和使用
①安装环境和编辑器 注册小程序账号 微信开发者工具下载 uniapp 官网 HbuilderX 下载 首先先下载Hbuilder和微信开发者工具 (都是傻瓜式安装),然后注册小程序账号: 拿到appid: ②简单通过demo使用微信开发者工具和…...

【ES】--Elasticsearch的分词器深度研究
目录 一、问题描述及分析二、analyze分析器原理三、 multi-fields字段支持多场景搜索(如同时简繁体、拼音等)1、ts_match_analyzer配置分词2、ts_match_all_analyzer配置分词3、ts_match_1_analyzer配置分词4、ts_match_2_analyzer配置分词5、ts_match_3_analyzer配置分词6、ts…...
【Langchain Agent研究】SalesGPT项目介绍(三)
【Langchain Agent研究】SalesGPT项目介绍(二)-CSDN博客 上节课,我们介绍了salesGPT项目的初步的整体结构,poetry脚手架工具和里面的run.py。在run.py这个运行文件里,引用的最主要的类就是SalesGPT类,今天我…...
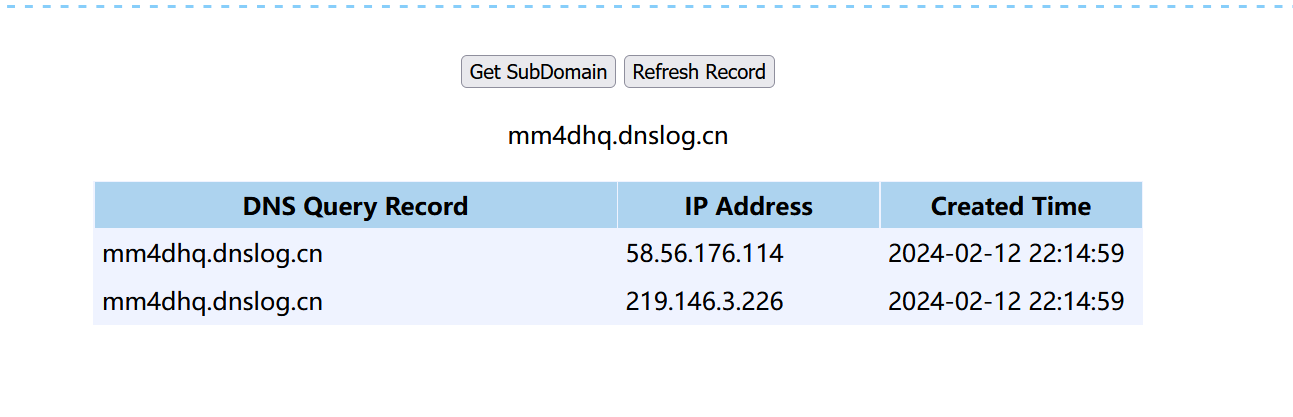
Java安全 URLDNS链分析
Java安全 URLDNS链分析 什么是URLDNS链URLDNS链分析调用链路HashMap类分析URL类分析 exp编写思路整理初步expexp改进最终exp 什么是URLDNS链 URLDNS链是Java安全中比较简单的一条利用链,无需使用任何第三方库,全依靠Java内置的一些类实现,但…...

10分钟终极指南:用Cortex-Debug打造VSCode最强STM32嵌入式开发环境
10分钟终极指南:用Cortex-Debug打造VSCode最强STM32嵌入式开发环境 【免费下载链接】cortex-debug Visual Studio Code extension for enhancing debug capabilities for Cortex-M Microcontrollers 项目地址: https://gitcode.com/gh_mirrors/co/cortex-debug …...

伯朗特机器人集成智能料库,为多台激光切割机提供24小时不间断的板材上下料服务
在现代钣金加工、机箱电柜及金属构件制造领域,激光切割已成为核心工序。然而,随着多台激光切割机集群化作业成为常态,传统的板材上下料模式——依赖叉车转运、行车吊运及人工操作——日益暴露出效率瓶颈、劳动力密集、安全隐患及设备利用率不…...

Mac用户必看:3分钟解决NTFS硬盘读写难题,免费开源工具Nigate完整指南
Mac用户必看:3分钟解决NTFS硬盘读写难题,免费开源工具Nigate完整指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mo…...

PPTist免费在线演示文稿制作完全指南:从零到专业演示的终极教程
PPTist免费在线演示文稿制作完全指南:从零到专业演示的终极教程 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, al…...

AutoCAD字体管理终极指南:如何彻底解决字体缺失问题
AutoCAD字体管理终极指南:如何彻底解决字体缺失问题 【免费下载链接】FontCenter AutoCAD自动管理字体插件 项目地址: https://gitcode.com/gh_mirrors/fo/FontCenter 还在为AutoCAD字体缺失问题而烦恼吗?FontCenter是您的专业字体管理解决方案&a…...

长鑫存储逆袭:从近10年亏损超366亿到盈利超预期,能否成“中国海力士”?
长鑫存储逆袭:从巨亏到盈利超预期,能否成为“中国海力士”?“韩国巨头布局存储,中国巨头热衷于外卖。”这一波存储涨价潮,很多人用戏谑的方式来表达对中国几家互联网公司的“恨铁不成钢”。但长鑫存储却凭借一份极度亮…...

词达人自动化助手终极指南:如何让英语学习效率提升10倍
词达人自动化助手终极指南:如何让英语学习效率提升10倍 【免费下载链接】cdr 微信词达人,高正确率,高效简洁。支持班级任务及自选任务 项目地址: https://gitcode.com/gh_mirrors/cd/cdr 你是否曾经面对堆积如山的英语词汇任务感到力不…...

还在熬夜改论文格式?okbiye 本科毕业论文写作功能,一键搞定你的毕业难题
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 当查重报告里飘红的句子、学校格式手册里密密麻麻的排版要求、凌晨三点还没理顺的论文大纲,成为每个本科生毕业季的共同记忆时&…...

【职场】职场“贵人“的真相:他们从不随机出现,也从不无缘无故消失
职场"贵人"的真相:他们从不随机出现,也从不无缘无故消失每个在职场里走得还不错的人,回头看,都能说出一两个名字。 那个在你最迷茫的时候,把你带进了某个重要的圈子;那个在关键会议上,…...

【GEO实战密码】GEO 的真正护城河,是 RAG
《GEO实战密码》节选:GEO 的真正护城河,是 RAG企业做生成式搜索优化,别只盯着外部曝光。AI 愿不愿意引用你,首先取决于你的内容值不值得被信任。最近和不少企业聊 GEO,也就是生成式搜索优化,发现一个非常典…...