Netty应用(一) 之 NIO概念 基本编程
目录
第一章 概念引入
1.分布式概念引入
第二章 Netty基础 - NIO
1.引言
1.1 什么是Netty?
1.2 为什么要学习Netty?
2.NIO编程
2.1 传统网络通信中开发方式及问题(BIO)
2.1.1 多线程版网络编程
2.1.2 线程池版的网络编程
2.2 NIO网络通信中的非阻塞编程
3.NIO的基本开发方式
3.1 Channel简介
3.2 Buffer简介
3.3 第一个NIO程序
3.5 NIO步骤总结
第一章 概念引入
1.分布式概念引入
很多年前的开发其实就是单机开发,但现如今随着流量并发的增加,引入了分布式。
对于后端而言,分布式专注于服务器端。当client客户端过多时,我们在服务端要考虑很多问题,首先第一个就是并发问题,如何支持并发?
先说一个旧时代方案:做水平扩展,扩展成n多台tomcat服务器,并且做负载均衡,但是这仅仅是在硬件层面上去做扩展。
新时代方案:构建分布式系统,也就是使用一系列分布式技术方案进行构建系统,不仅在硬件机器层面去做扩展,而且要在软件层面做扩展。有以下几点需要注意:
(1)如何进行服务的管理?
目前的解决方案为SpringCloud。但是SpringCloud开发有很多弊端:1.代码侵入性太强 --->分析:需要打注解,做注解的过程实际上就是代码侵入的过程。并且当我们需要更改通信模块所使用到的技术时,当前代码基本上废了。2.只支持java语言做开发,go,py不支持。
所以新时代分布式构建时会慢慢的向ServerMash网格化开发靠近,把每一项功能做成一个中间件,降低侵入性和语言局限性
(2)如何进行通信管理?
Netty
(3)如何进行资源管理?
这一部分比较偏向硬件管理了,像如今的k8s,docker容器化管理资源
第二章 Netty基础 - NIO
1.引言
1.1 什么是Netty?
Netty: Home
Netty is an asynchronous event-driven network application frameworkfor rapid development of maintainable high performance protocol servers & clients.
Netty是一个异步事件驱动的网络应用框架。用于快速开发可维护的高性能协议服务器和客户端。
Netty is a NIO client server framework which enables quick and easy development of network applications such as protocol servers and clients. It greatly simplifies and streamlines network programming such as TCP and UDP socket server.
'Quick and easy' doesn't mean that a resulting application will suffer from a maintainability or a performance issue. Netty has been designed carefully with the experiences earned from the implementation of a lot of protocols such as FTP, SMTP, HTTP, and various binary and text-based legacy protocols. As a result, Netty has succeeded to find a way to achieve ease of development, performance, stability, and flexibility without a compromise.
Netty是一个NIO客户服务器框架,它能够快速和容易地开发网络应用,如协议服务器和客户端。它大大简化和精简了网络编程,如TCP和UDP套接字服务器。
快速和简单 "并不意味着开发出来的应用程序会出现可维护性或性能问题。Netty的设计是经过精心设计的,其经验来自于许多协议的实施,如FTP、SMTP、HTTP以及各种基于二进制和文本的遗留协议。因此,Netty成功地找到了一种方法来实现开发的简易性、性能、稳定性和灵活性,而没有任何妥协。
1.2 为什么要学习Netty?
1. Netty已经是行业内网络通信编程的标准,广泛应用于通信领域和很多其他中间件技术的底层。
2. 应用非常广泛
1. 游戏行业 ---》在很多中小型企业策略游戏的后端,都是使用java来写的,使用到java自然用Netty做网络通信。因为游戏对于消息协议的设计是高度定制化以及高要求化的
2. 很多框架的通信底层,解决进程间通信。
Spring WebFlux、storm、rocketMQ、dubbo等,是分布式系统,通信的核心。
-----》对于新兴的WebFlux就是使用Netty作为网络通信框架基础,包括大数据框架storm,还有一些中间件产品,分布式场景下,多节点集群间需要通信,Netty就是Java领域最优的解决方案。
2.NIO编程
1. NIO全称成为None Blocking IO (非阻塞IO)。【JDK1.4引入的一个java自带包】----》多说一句:NIO为非阻塞同步IO,虽然是非阻塞,但依旧是同步的。
2. 非阻塞 主要应用在网络通信中,能够合理利用资源,提高系统的并发效率。支持高并发的系统访问。
----》但是一定注意一点:使用非阻塞网络通信只是提高系统并发的一个环节,对于高并发产品,有更多环节需要去考虑
2.1 传统网络通信中开发方式及问题(BIO)
2.1.1 多线程版网络编程
- 先看代码
public class MessiServer {public static void main(String[] args) {ServerSocket serverSocket = null ;try {serverSocket = new ServerSocket(8080) ;Socket socket = null ;while(true) {socket = serverSocket.accept() ;//服务器每监听到一个新客户端请求建立连接后,开启一个新线程去执行处理对应的请求//start()--->run()new Thread(new MessiServerHandler(socket)).start();}} catch (IOException e) {throw new RuntimeException(e);} finally {if(serverSocket != null) {try {serverSocket.close();} catch (IOException e) {throw new RuntimeException(e);}}}}}
class MessiServerHandler implements Runnable{private Socket socket ;public MessiServerHandler(Socket socket) {this.socket = socket ;}public void run() {BufferedReader bufferedReader = null ;try {bufferedReader = new BufferedReader(new InputStreamReader(this.socket.getInputStream())) ;while(true) {String line = bufferedReader.readLine() ;if(line != null) {System.out.println("line = " + line);}}} catch (IOException e) {throw new RuntimeException(e);} finally {if(bufferedReader != null) {try {bufferedReader.close();} catch (IOException e) {throw new RuntimeException(e);}}}}
}public class MessiClient {public static void main(String[] args) {Socket socket = null ;PrintWriter printWriter = null ;try {socket = new Socket("localhost",8080) ;//<editor-fold desc="IO流读写数据">printWriter = new PrintWriter(socket.getOutputStream());printWriter.write("send date to server ");printWriter.flush();//</editor-fold>} catch (UnknownHostException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);} finally {//<editor-fold desc="关闭Socket资源">if (socket != null) {try {socket.close();} catch (IOException e) {throw new RuntimeException(e);}}if (printWriter != null) {printWriter.close();}//</editor-fold>}}}- 画图概括代码

补充1:
JavaEE为我们封装了很多,比如说:透明化socket,透明化Thread线程,其实都是tomcat服务器为我们做了,当然Tomcat做的很好,比如说使用线程池来优化等等。
补充2:
在如今BS交互层面,一次浏览器客户端请求对应一个新连接,先三次握手建立连接,服务器端会创建一个新线程去处理这个请求(连接),当这个请求处理结束后,这次请求所对应的客户端socket就会close掉,其实我们通信,说白了就是socket通信,主要是看socket。所以可以说成一次请求对应一个线程。
- 分析缺点:
1.线程创建开销大
分析:
线程的创建是操作系统去创建的,在jvm层面是无法去创建的。在系统层面,我们一定会陷入内核态去调用操作系统提供的函数创建线程(通知到操作系统,操作系统与硬件做交互,真正的分配一块内存空间去给线程),这样开销一定是要比直接在jvm用户程序层面的开销大。
2.内存占用高,不能无限制创建线程
分析:
服务器端监听客户端的连接建立,当有一个新客户端过来建立连接时,就会开启一个新线程去处理这次建立连接后的请求,假设说有100万个请求,那么需要进行100万次客户端请求连接,那么服务器端需要建立100万个线程去处理,内存占用太高了。
eg:假设说有1024个客户端进行连接服务器,那么服务器对应就会有1024个线程进行创建并执行对应客户端的任务,一个线程占用的空间大小为1MB,那么1024个线程一共会占用1GB大小的空间,假设说有1万个线程呢?需要创建的内存空间是极大的,占用内存是非常高
3.CPU使用率高
分析:
虽说现在是多核CPU,也就是一个CPU多核心,这样可以很好的让多线程并行,但是核心数也是有上限的,我的电脑好像是八核,也就是说可以8个线程并行操作。一旦开启线程数量超过8个,那么就会并发执行,所谓并发就是CPU不断上下文切换调度到底使用哪一个线程,一旦涉及到上下文切换,一定是高消耗的。我们需要不断的保存和恢复每个线程的上下文数据内容,就算是内存级别的操作,这也是很大的开销,甚至有的上下文数据需要保存到磁盘做持久化,这样消耗更大。一句话:CPU需要不断的上下文切换调度,CPU使用率一定高
2.1.2 线程池版的网络编程
- 先看代码
public class MessiServer1 {private static ExecutorService executorService;static {executorService = new ThreadPoolExecutor(Runtime.getRuntime().availableProcessors(), 20,120L, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(1000));}public static void main(String[] args) {ServerSocket serverSocket = null;try {serverSocket = new ServerSocket(8080);Socket socket = null;while (true) {socket = serverSocket.accept();//new Thread(new SunsServerHandler(socket)).start();//线程池executorService.execute(new MessiServerHandler1(socket));}} catch (Exception e) {e.printStackTrace();} finally {if (serverSocket != null) {try {serverSocket.close();} catch (IOException e) {throw new RuntimeException(e);}}}}
}
class MessiServerHandler1 implements Runnable {private Socket socket;public MessiServerHandler1(Socket socket) {this.socket = socket;}public void run() {BufferedReader bufferedReader = null;try {bufferedReader = new BufferedReader(new InputStreamReader(this.socket.getInputStream()));while (true) {String line = bufferedReader.readLine();if (line != null) {System.out.println("line = " + line);}}} catch (IOException e) {throw new RuntimeException(e);} finally {if (bufferedReader != null) {try {bufferedReader.close();} catch (IOException e) {throw new RuntimeException(e);}}}}
}public class MessiClient1 {public static void main(String[] args) {Socket socket = null ;PrintWriter printWriter = null ;try {socket = new Socket("localhost",8080) ;//<editor-fold desc="IO流读写数据">printWriter = new PrintWriter(socket.getOutputStream());printWriter.write("send date to server ");printWriter.flush();//</editor-fold>} catch (UnknownHostException e) {throw new RuntimeException(e);} catch (IOException e) {throw new RuntimeException(e);} finally {//<editor-fold desc="关闭Socket资源">if (socket != null) {try {socket.close();} catch (IOException e) {throw new RuntimeException(e);}}if (printWriter != null) {printWriter.close();}//</editor-fold>}}}代码细节分析:
executorService = new ThreadPoolExecutor(Runtime.getRuntime().availableProcessors(), 20,
120L, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(1000));
参数1:Runtime.getRuntime().availableProcessors() 为线程池的核心线程数量设置
---》。API结果分情况讨论:1.jdk8以及之前的版本,该API获取到的是CPU所对应的核心数 2.jdk8以后,该值的结果可以通过JVM参数进行自定义设置 (为什么?因为现如今都是docker虚拟容器化,理论上是CPU有8个核,但实际上docker虚拟化后只有4个核,5个核都是有可能的)
参数2:20 为线程池创建最大线程数
----》参数1的结果值传入进去表示线程池申请的核心线程数量,但是当client客户端连接变多时,核心线程不够用了,所以线程池会新创建线程(当然这个创建过程需要陷入内核然后OS......),但是创建的线程上限大小为20个
参数5:
----》当创建的线程数量达到最大线程数20个时,还不够用,那么把该线程对象(Tomcat会封装每一个请求成为一个个线程对象进入操作)加入到阻塞队列中,但是阻塞队列上限为1000,也就是说最多存储1000个阻塞线程对象,超过则通过一些策略淘汰掉。
参数3,参数4:
当前线程超过120s没有执行任务,会被回收销毁,直到线程数量减少到Runtime.getRuntime().availableProcessors()这一设置的核心线程数量为止,这样可以减少内存压力
- 画图概括代码

- 分析它解决的问题以及缺点:
解决的问题:
1.解决线程创建开销大的问题
分析:通过线程池做管理,解决这一问题
2.解决内存占用高,无限创建线程问题
分析:线程池做管理,细节见上
3.解决CPU使用率高的问题
分析:线程数有上限,CPU切换调度不会很频繁
出现的新问题,缺点:
ServerSocket只能负责监听客户端的连接,建立连接后,创建开启一个新线程,把当前连接所对应的客户端请求交给一个线程去做,但是当这次请求过程中发生了一些阻塞(如:IO阻塞或等待客户键盘输入阻塞)的话,由于ServerSocket不能去管控这一阻塞(ServerSocket只能负责监听客户端的连接),所以当前请求所对应的Thread线程会一直阻塞着,等待着这个阻塞,所以会造成有限线程资源数的浪费。我们知道线程池中创建的线程是有限的资源,如果有限的线程资源被阻塞式的任务请求占用着,而那些迫切需要线程去处理的请求任务只能加入到阻塞队列中去等待甚至被拒绝!这就是缺点!极大的降低了并发
这一阻塞缺点就会引出后续的NIO!
2.2 NIO网络通信中的非阻塞编程
- 网络IO所对应的NIO编程
针对于网络IO,我们引入了Selector组件,记住一定是针对于网络IO引入的Selector!!!
常说的IO有:文件IO和网络IO。在网络IO方面,我们引入了一个组件:Selector。该组件实现了监控管理客户端的作用,具体流程如下:在NIO编程过程中,使用的是Channel管道代替传统的IO流,会把不同客户端对应的Channel注册到Selector组件上,Seletor进行监控注册在上面的所有客户端是否是"正常"的?啥是"正常"?正常就是能够在建立连接后,正常的进行读写操作而不阻塞!实现Selector监控后,每一个Channel建立连接,进行读写操作,都会对应分配一个线程去执行。如果当Selector监控到某一分配了线程资源的Channel阻塞了,那么Selector会把该线程资源归还回线程池,而避免有限的线程资源被阻塞浪费!当Channel"正常"后,如果线程资源够用,那么Selector会再一次给其分配线程资源!
我们可以看出,同一个线程资源被多个Channel复用,这就是Select监控的作用,这就是IO多路复用模型。对于Selector组件,不同的操作系统实现不同,有poll,select,epoll。当然最好的就是epoll,支持高并发 高可用,所以我们经常把代码部署在Linux服务器上,Linux服务器作为linux操作系统的计算机,Selector的底层实现为epoll!

- 文件IO所对应的NIO编程也是同理的
3.NIO的基本开发方式
3.1 Channel简介
1.Channel是IO通信的通道,类似于InputStream,OutputStream
2.Channel没有方向性
- 传统IO

- NIO
Channel在NIO中只起到一个管道传输数据的作用,无方向
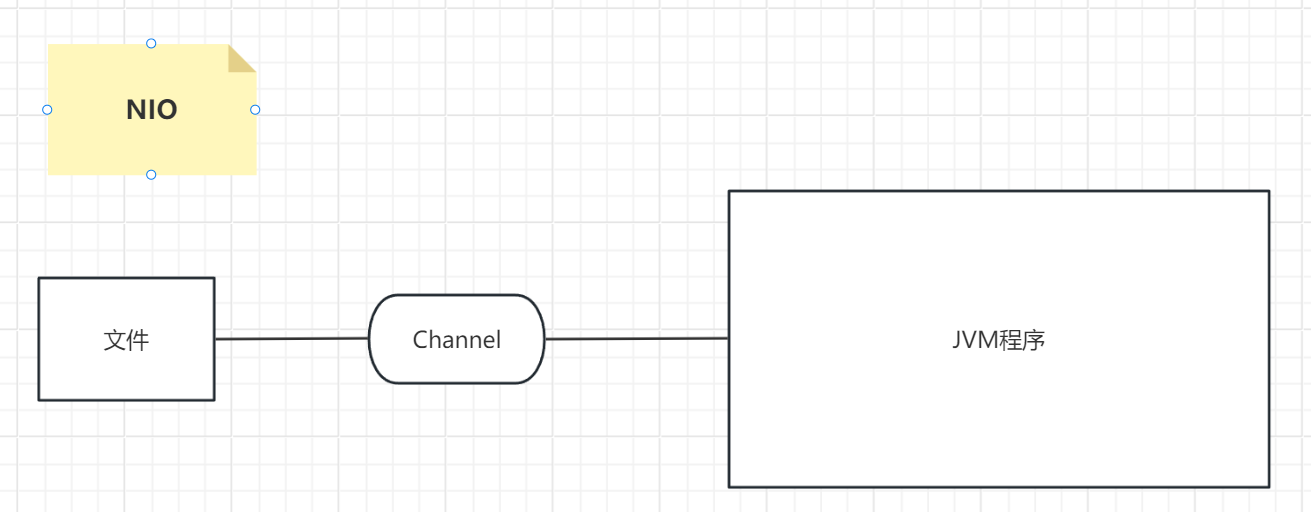
- 常见Channel
1. 文件操作
FileChannel,读写文件中的数据。
2. 网络操作
SocketChannel,通过TCP读写网络中的数据。
ServerSockectChannel,监听新进来的TCP连接,像Web服务器那样。对每一个新进来的连接都会创建一个SocketChannel。
DatagramChannel,通过UDP读写网络中的数据。
- 获取Channel的方式
第一类:如何获取文件IO所对应的Channel
1. FileInputStreanm/FileOutputStream
2. RandomAccessFile
第二类:如何获取网络IO所对应的Channel
3. Socket
4. ServerSocket
5. DatagramSocket
3.2 Buffer简介
1. Channel读取或者写入的数据,都要写到Buffer中,才可以被程序操作。
2. 因为Channel没有方向性,所以Buffer为了区分读写,引入了读模式、写模式进行区分。
3.为什么要Buffer?肯定是为了提升读写的效率,缓冲区的作用就在于此。积攒到一定数据量后再一起读写,比过来一个字节就进行读写要效率高
- 如图

NIO引入了Channel,但是Channel是无方向的,这不同于IO流的方向区分。
NIO是在Buffer上面做区分的,给Buffer标记不同的状态进行区分到底是读出还是写入,当Buffer缓冲区标记为写模式时,表示写入数据到Buffer缓冲区,下一步要进行的是把Buffer缓冲区的数据写入到文件中。当Buffer缓冲区标记为读模式时,表示读出Buffer缓冲区的数据,下一步要进行的是把Buffer缓冲区的数据读出到JVM程序中。
写模式何时开启?当新创建一个Buffer时,默认为写模式。或当调用clear()方法时,表示转换成写模式。写模式状态下,是谁来写?是外部来写的,外部(文件IO,网络IO)会写入数据到Buffer缓冲区
读模式何时开启?当调用flip()时,改为读模式。读模式下,是读到哪?把Buffer缓冲区的数据读到JVM程序中。
无论读模式还是写模式,都是相对于程序而言,只不过这里把原有传统IO下使用流区分方向转变到现如今使用Buffer的读写模式来区分了!
读模式下,相对JVM程序而言,是把Buffer数据读入到JVM程序的,所以是读。
写模式下,相对于JVM程序而言,是把Buffer数据写出到外部(如:文件),所以是写
- 代码
public class TestNIO1 {public static void main(String[] args) throws Exception{//1.创建ChannelFileChannel channel = new FileInputStream("D:\\Daily_Code\\Netty_NEW\\data.txt").getChannel();//2.创建缓冲区ByteBuffer buffer = ByteBuffer.allocate(10) ;//因为可能缓冲区一次无法读取完文件的所有字节,所以要while循环读取,可能多次反复读取到申请的缓冲区中while (true) {//在创建完缓冲区后,默认是写模式//3.把通道内获取的文件数据,写入缓冲区int read = channel.read(buffer) ;//此时说明文件已读取完,循环应该退出if(read == -1) {break;}//4.程序读取buffer的内容数据,后续的操作,设置buffer为读模式buffer.flip();//5.循环读取缓冲区的数据while(buffer.hasRemaining()) {byte b = buffer.get();//把字节转换成可视化的字符//UTF-8编码中:一个字符占用1~4的字节大小。汉字,日文,韩文占用3个字节,ASCII表的字符占用1个字节,xxx字符占用2个字节,一些少数语言字符占用4个字节System.out.println("(char)b = " + (char) b);}//6.设置buffer为写模式,因为循环上去后需要写入缓冲区,所以需要重新设置为写模式buffer.clear();}}}
- 常见Buffer
1. ByteBuffer
2. CharBuffer
3. DoubleBuffer
4. FloatBuffer
5. IntBuffer
6. LongBuffer
7. ShortBuffer
8. MappedByteBuffer..
最常用的就是:ByteBuffer,因为所有字符类型都可以转换成Byte字节格式。当然还有MappedByteBuffer
- Buffer缓冲区的获得方式
1.ByteBuffer.allocate(10) ----> 创建一个大小为10的Buffer缓冲区
2.encode()
3.3 第一个NIO程序
public class TestNIO1 {public static void main(String[] args) throws Exception{//1.创建ChannelFileChannel channel = new FileInputStream("D:\\Daily_Code\\Netty_NEW\\data.txt").getChannel();//2.创建缓冲区ByteBuffer buffer = ByteBuffer.allocate(10) ;//因为可能缓冲区一次无法读取完文件的所有字节,所以要while循环读取,可能多次反复读取到申请的缓冲区中while (true) {//在创建完缓冲区后,默认是写模式//3.把通道内获取的文件数据,写入缓冲区int read = channel.read(buffer) ;//此时说明文件已读取完,循环应该退出if(read == -1) {break;}//4.程序读取buffer的内容数据,后续的操作,设置buffer为读模式buffer.flip();//5.循环读取缓冲区的数据while(buffer.hasRemaining()) {byte b = buffer.get();//把字节转换成可视化的字符//UTF-8编码中:一个字符占用1~4的字节大小。汉字,日文,韩文占用3个字节,ASCII表的字符占用1个字节,xxx字符占用2个字节,一些少数语言字符占用4个字节System.out.println("(char)b = " + (char) b);}//6.设置buffer为写模式,因为循环上去后需要写入缓冲区,所以需要重新设置为写模式buffer.clear();}}}public class TestNIO2 {public static void main(String[] args) {//RandomAccessFile 异常处理FileChannel channel = null ;try {//第一个参数:指定文件的路径,第二个参数:指定文件的行使权力,rw表示可读写, r表示可读,w表示可写channel = new RandomAccessFile("D:\\Daily_Code\\Netty_NEW\\data.txt","rw").getChannel() ;ByteBuffer buffer = ByteBuffer.allocate(10) ;while (true) {int read = channel.read(buffer) ;if(read == -1) {break;}buffer.flip();while (buffer.hasRemaining()) {byte b = buffer.get();System.out.println("(char)b = " + (char) b);}buffer.clear();}} catch (Exception e) {throw new RuntimeException(e);} finally {if(channel != null) {try {channel.close();} catch (IOException e) {throw new RuntimeException(e);}}}}}public class TestNIO3 {public static void main(String[] args) {try(FileChannel channel = FileChannel.open(Paths.get("D:\\Daily_Code\\Netty_NEW\\data.txt") , StandardOpenOption.READ);) {ByteBuffer buffer = ByteBuffer.allocate(10) ;while (true) {int read = channel.read(buffer) ;if(read == -1) {break;}buffer.flip();while (buffer.hasRemaining()) {byte b = buffer.get();System.out.println("(char) b = " + (char) b);}buffer.clear();}} catch (Exception e) {e.printStackTrace();}}}
- 总结
细节总结:
1.
三个案例代码分别采用不同创建Channel管道对象的方式,并且要指定对Channel的读或写的权限
获取Channel的方式:
(1) new FileInputStream(xxx).getChannel (2) new RandomAccessFile(xxx).getChannel() (3) FileChannel.open(xxx)
2.新语法的使用
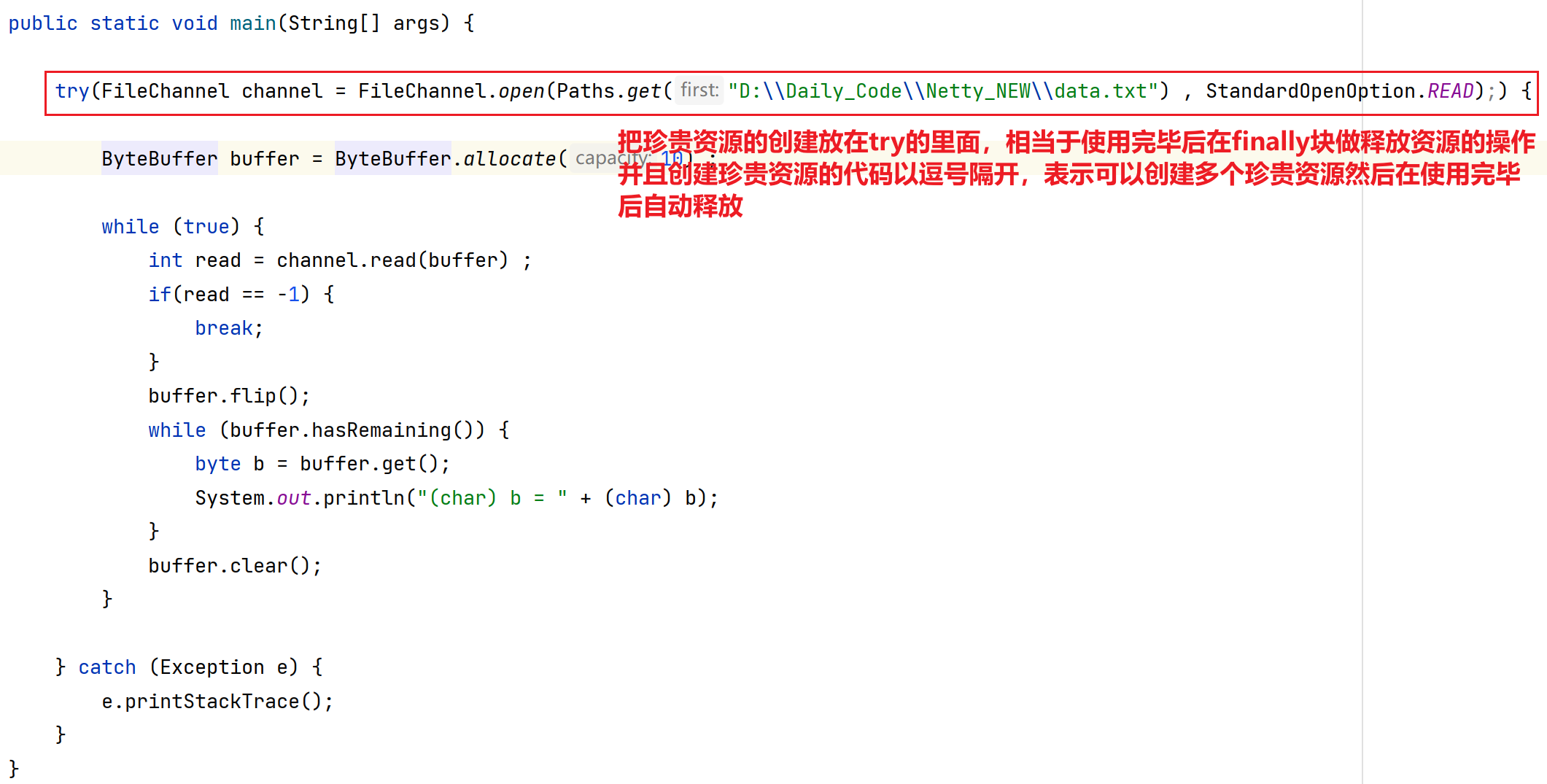
3.5 NIO步骤总结
1.获取Channel
2.创建Buffer
3.循环的从Channel中获取数据,写入到Buffer缓冲区,进行操作
相关文章:
Netty应用(一) 之 NIO概念 基本编程
目录 第一章 概念引入 1.分布式概念引入 第二章 Netty基础 - NIO 1.引言 1.1 什么是Netty? 1.2 为什么要学习Netty? 2.NIO编程 2.1 传统网络通信中开发方式及问题(BIO) 2.1.1 多线程版网络编程 2.1.2 线程池版的网络编程…...
tkinter-TinUI-xml实战(10)展示画廊
tkinter-TinUI-xml实战(10)展示画廊 引言声明文件结构核心代码主界面统一展示控件控件展示界面单一展示已有展示多类展示 最终效果在这里插入图片描述  ………… 结语 引言…...
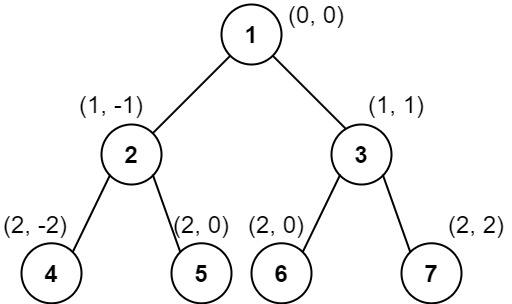
LeetCode二叉树的垂序遍历
题目描述 给你二叉树的根结点 root ,请你设计算法计算二叉树的 垂序遍历 序列。 对位于 (row, col) 的每个结点而言,其左右子结点分别位于 (row 1, col - 1) 和 (row 1, col 1) 。树的根结点位于 (0, 0) 。 二叉树的 垂序遍历 从最左边的列开始直到…...
 函数用法)
[linux c]linux do_div() 函数用法
linux do_div() 函数用法 do_div() 是一个 Linux 内核中的宏,用于执行 64 位整数的除法操作,并将结果存储在给定的变量中,同时将余数存储在另一个变量中。这个宏通常用于内核编程中,特别是在处理大整数和性能敏感的场合。 函数原…...

Python学习之路-爬虫提高:常见的反爬手段和解决思路
Python学习之路-爬虫提高:常见的反爬手段和解决思路 常见的反爬手段和解决思路 明确反反爬的主要思路 反反爬的主要思路就是:尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现。浏览器先请求了地址url1,保留了cookie…...

python_numpy库_ndarray的聚合操作、矩阵操作等
一、ndarray的聚合操作 1、求和np.sum() import numpy as np n np.arange(10) print(n) s np.sum(n) print(s) n np.random.randint(0,10,size(3,5)) print(n) s1 np.sum(n) print(s1) #全部数加起来 s2 np.sum(n,axis0) print(s2) #表示每一列的多行求和 …...
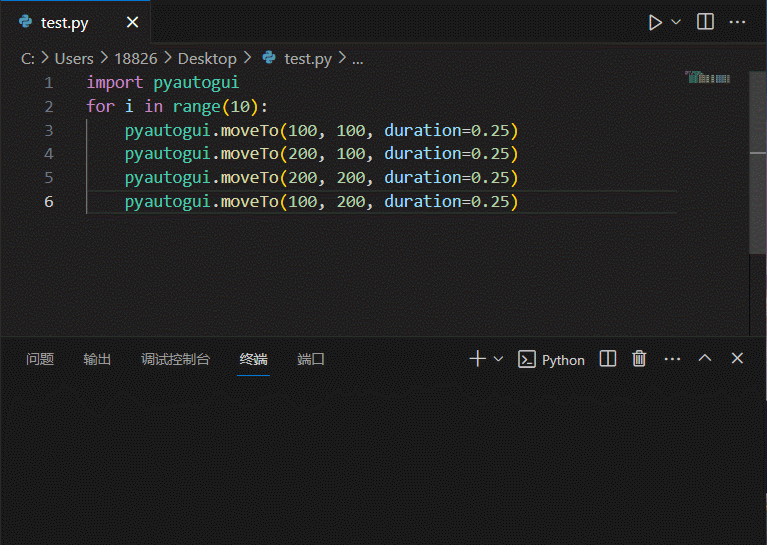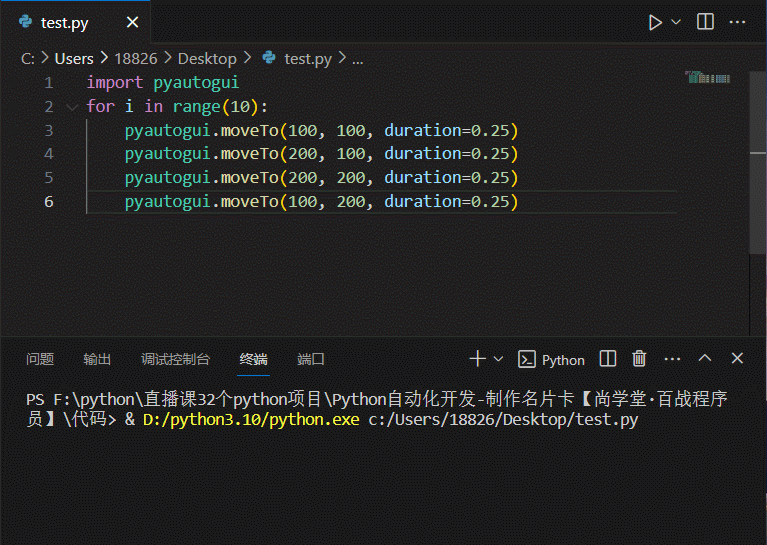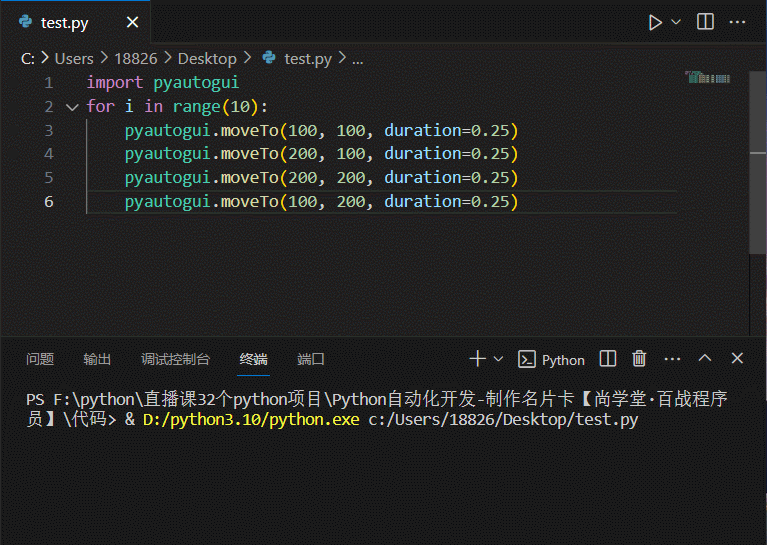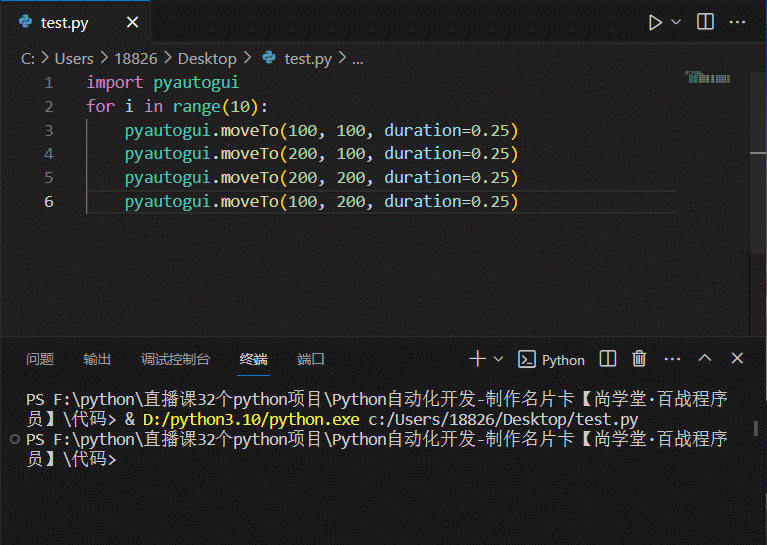
python-自动化篇-终极工具-用GUI自动控制键盘和鼠标-pyautogui
文章目录 用GUI自动控制键盘和鼠标pyautogui 模块鼠标屏幕位置——移动地图——pyautogui.size鼠标位置——自身定位——pyautogui.position()移动鼠标——pyautogui.moveTo拖动鼠标滚动鼠标 键盘按下键盘释放键盘 开始与结束通过注销关闭所有程序 用GUI自动控制键盘和鼠标 在…...
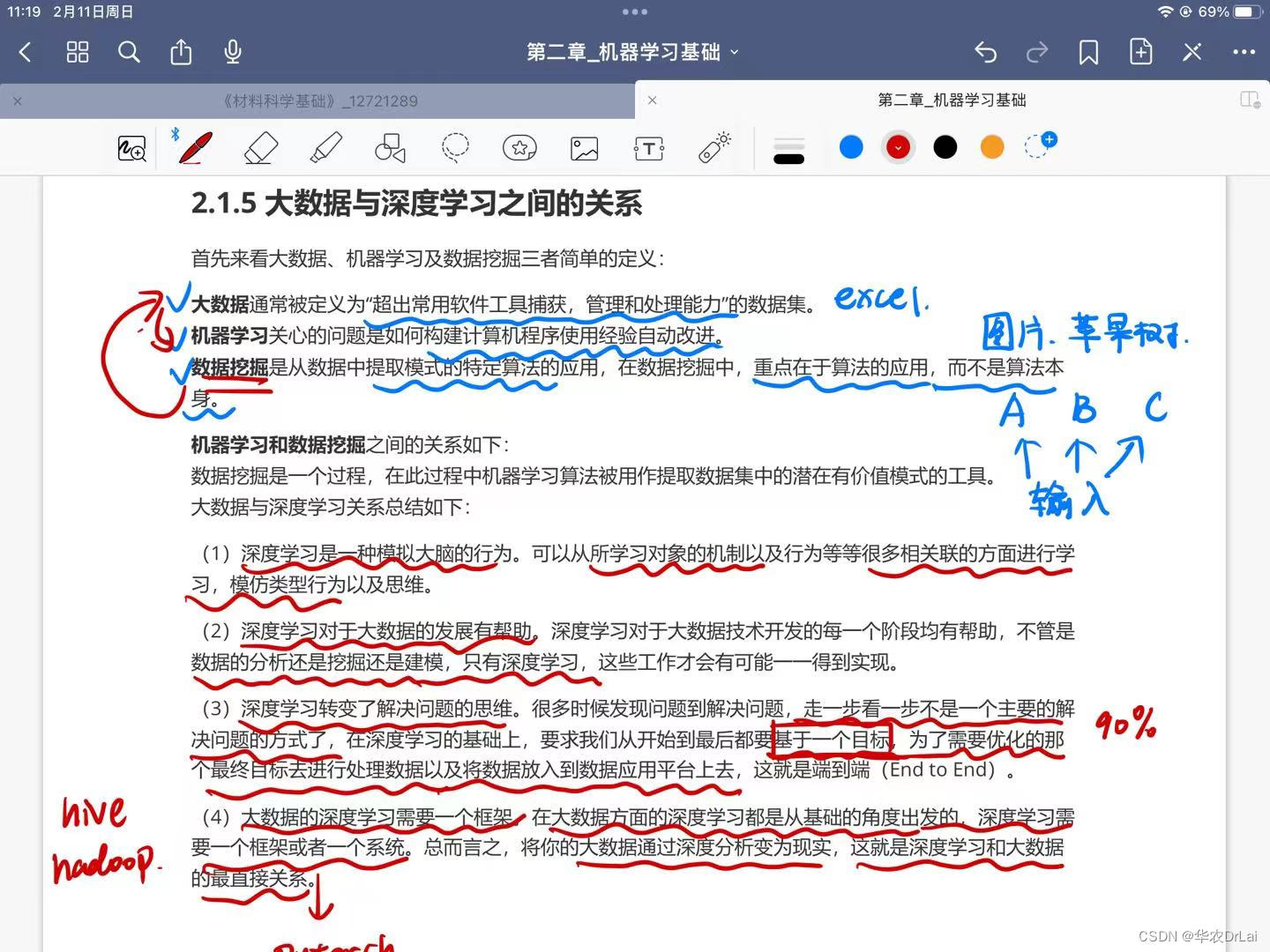
面试:大数据和深度学习之间的关系是什么?
大数据与深度学习之间存在着紧密的相互关系,它们在当今技术发展中相辅相成。 大数据的定义与特点:大数据指的是规模(数据量)、多样性(数据类型)和速度(数据生成及处理速度)都超出了传统数据处理软件和硬件能力范围的数据集。它具有四个主要特点,通常被称…...

航芯ACM32G103开发板评测 08 ADC Timer外设测试
航芯ACM32G103开发板评测 08 ADC Timer外设测试 1. 软硬件平台 ACM32G103 Board开发板MDK-ARM Keil 2. 定时器Timer 在一般的MCU芯片中,定时器这个外设资源是非常重要的,一般可以分为SysTick定时器(系统滴答定时器)、常规定时…...

【Linux学习】生产者-消费者模型
目录 22.1 什么是生产者-消费者模型 22.2 为什么要用生产者-消费者模型? 22.3 生产者-消费者模型的特点 22.4 BlockingQueue实现生产者-消费者模型 22.4.1 实现阻塞队列BlockQueue 1) 添加一个容器来存放数据 2)加入判断Blocking Queue情况的成员函数 3)实现push和pop方法 4)完…...
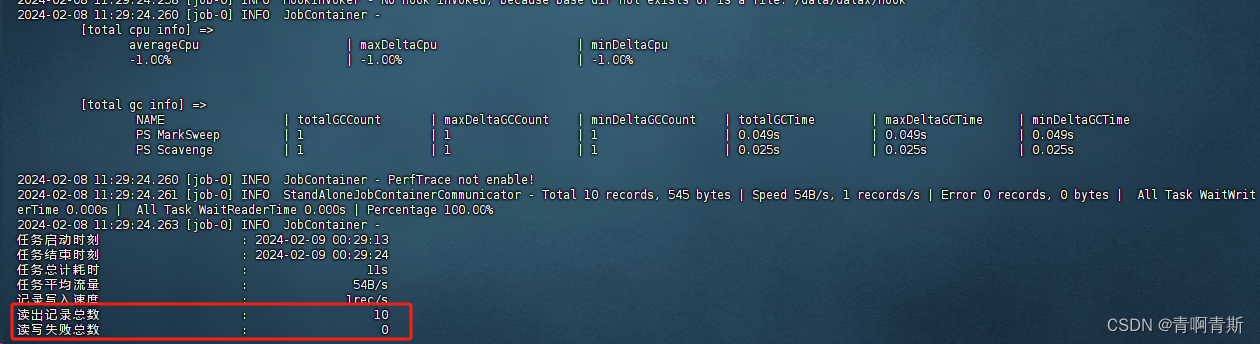
三、案例 - MySQL数据迁移至ClickHouse
MySQL数据迁移至ClickHouse 一、生成测试数据表和数据1.在MySQL创建数据表和数据2.在ClickHouse创建数据表 二、生成模板文件1.模板文件内容2.模板文件参数详解2.1 全局设置2.2 数据读取(Reader)2.3 数据写入(Writer)2.4 性能设置…...

[WinForm开源]概率计算器 - Genshin Impact(V1.0)
创作目的:为方便旅行者估算自己拥有的纠缠之缘能否达到自己的目的,作者使用C#开发了一款小型软件供旅行者参考使用。 创作说明:此软件所涉及到的一切概率与规则完全按照游戏《原神》(V4.4.0)内公示的概率与规则(包括保底机制&…...
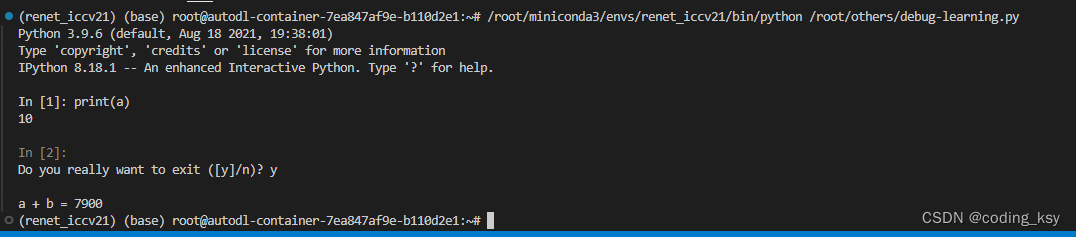
vscode 代码调试from IPython import embed
一、讲解 这种代码调试方法非常的好用。 from IPython import embed上面的代码片段是用于Python中嵌入一个交互式IPython shell的方法。这可以在任何Python脚本或程序中实现,允许在执行到该点时暂停程序,并提供一个交互式环境,以便于检查、…...
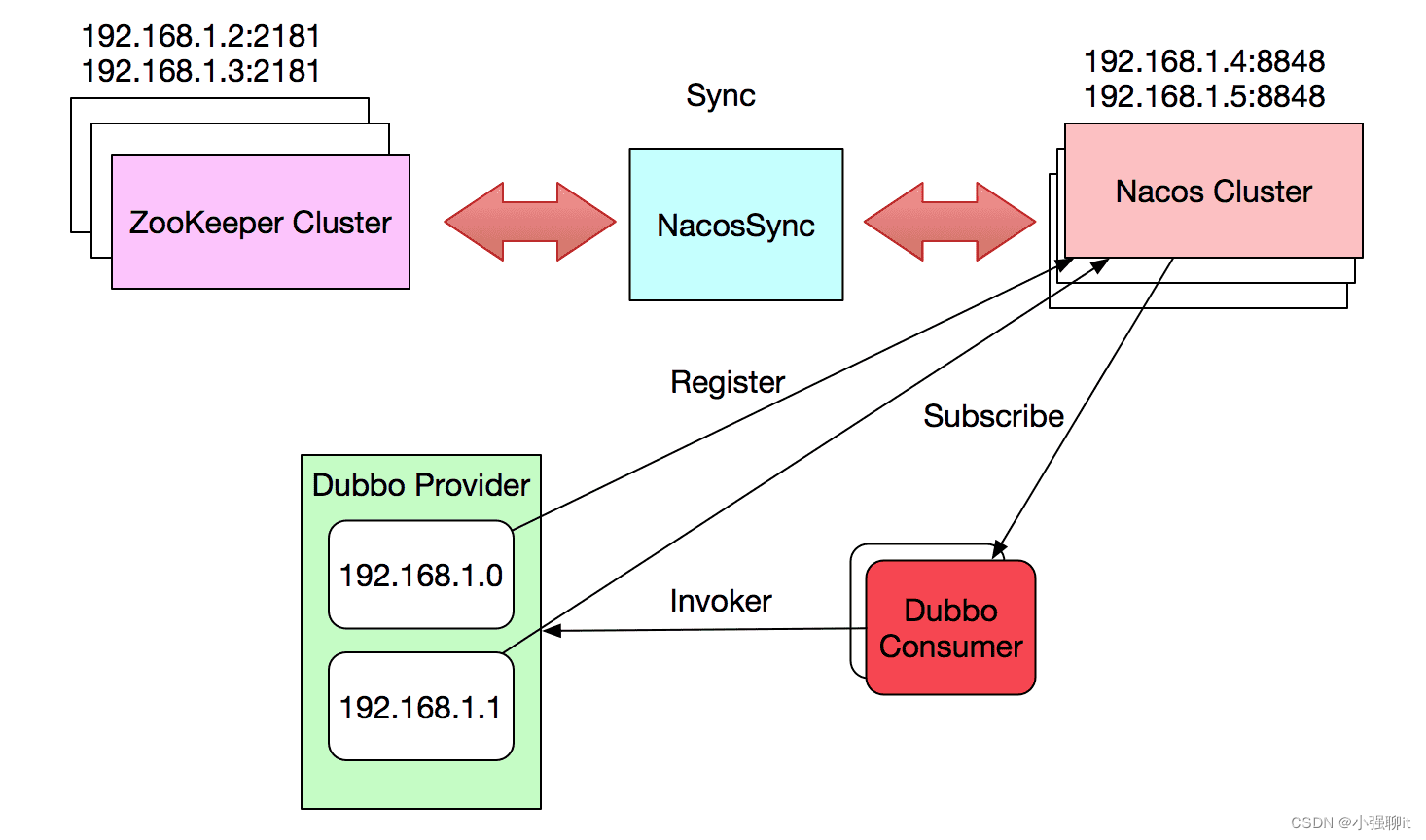
双活工作关于nacos注册中心的数据迁移
最近在做一个双活的项目,在纠结一个注册中心是在双活机房都准备一个,那主机房的数据如果传过去呢,查了一些资料,最终在官网查到了一个NacosSync 的组件,主要用来做数据传输的,并且支持在线替换注册中心的&a…...
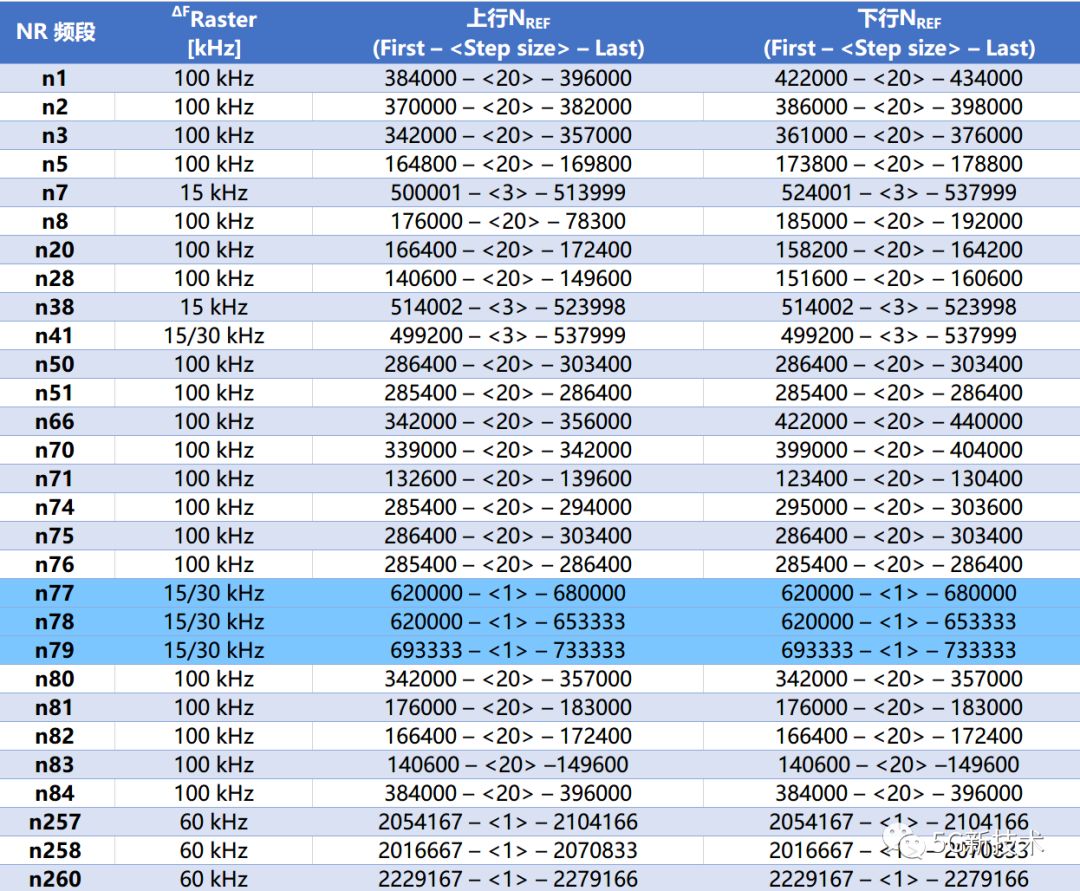
5G NR 信道号计算
一、5G NR的频段 增加带宽是增加容量和传输速率最直接的方法,目前5G最大带宽将会达到400MHz,考虑到目前频率占用情况,5G将不得不使用高频进行通信。 3GPP协议定义了从Sub6G(FR1)到毫米波(FR2)的5G目标频谱。 其中FR1是5G的核心频段࿰…...
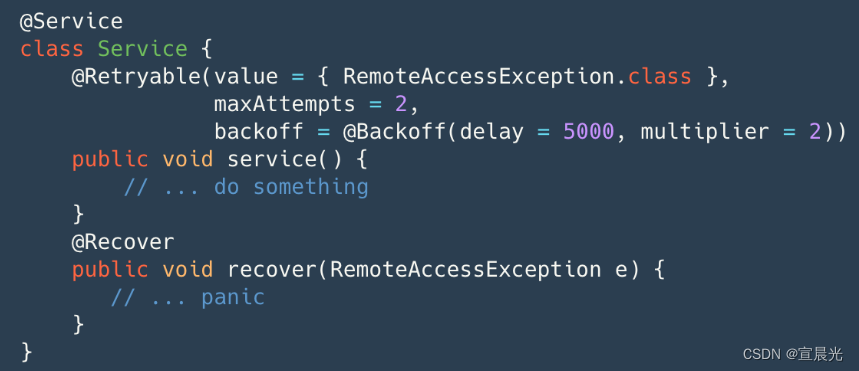
01-Spring实现重试和降级机制
主要用于在模块调用中,出现失败、异常情况下,仍需要进行重复调用。并且在最终调用失败时,可以采用降级措施,返回一般结果。 1、重试机制 我们采用spring 提供的retry 插件,其原理采用aop机制,所以需要额外…...
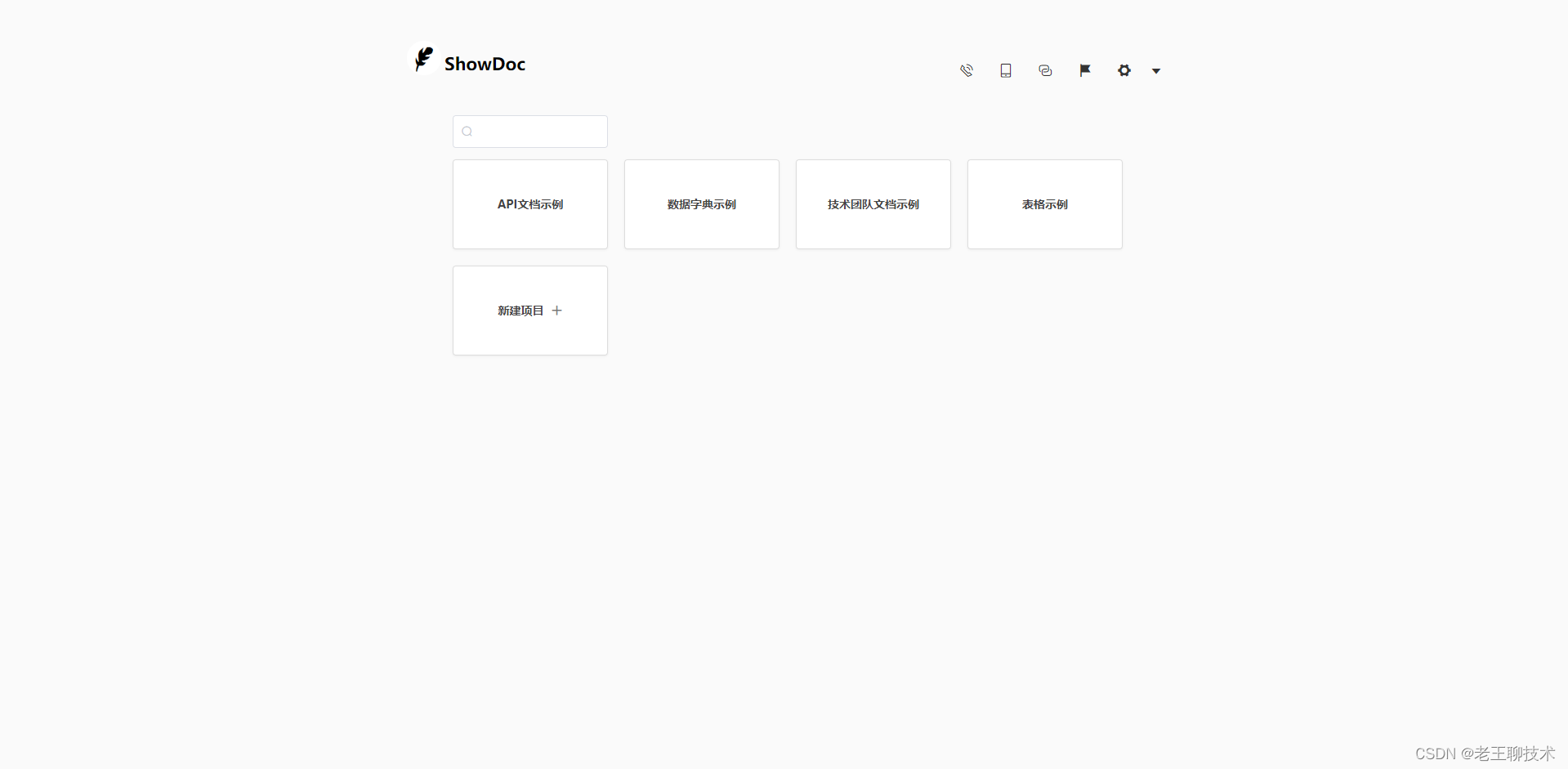
docker部署showdoc
目录 安装 1.拉取镜像 2.创建容器 使用 1.选择语言 2.默认账户/密码:showdoc/123456编辑 3.登陆 4.首页 安装 1.拉取镜像 docker pull star7th/showdoc 2.创建容器 mkdir -p /opt/showdoc/html docker run -d --name showdoc --userroot --privilegedtrue -p 1005…...

2.14作业
1.请编程实现二维数组的杨辉三角。 2.请编程实现二维数组计算每一行的和以及列和。 3.请编程实现二维数组计算第二大值。 4.请使用非函数方法实现系统函数strcat,strcmp,strcpy,strlen. strcat: strcmp: strcpy: strlen:...
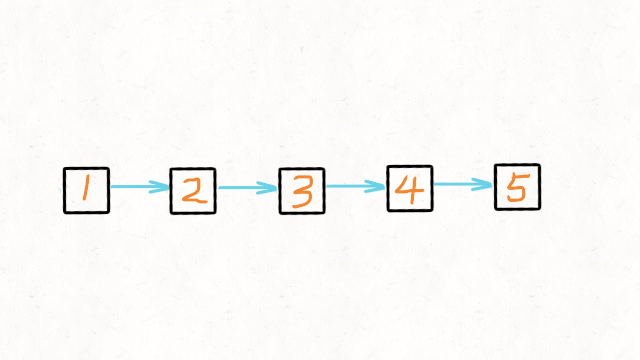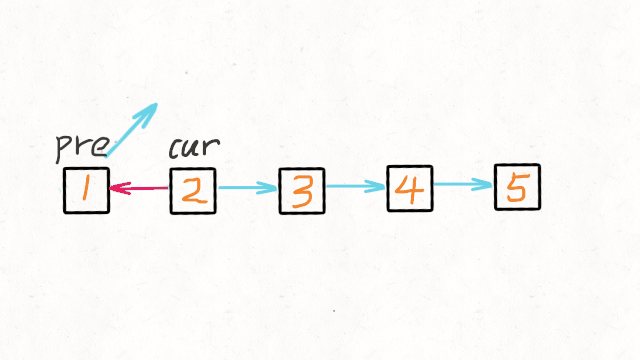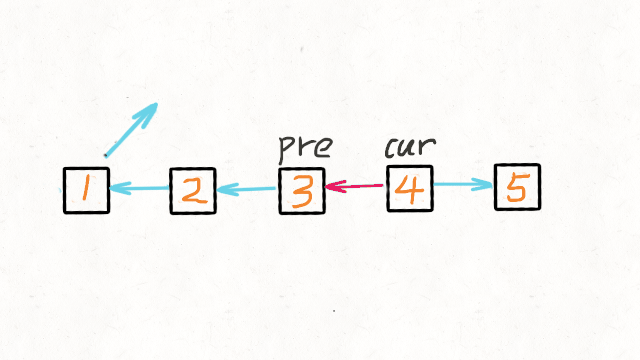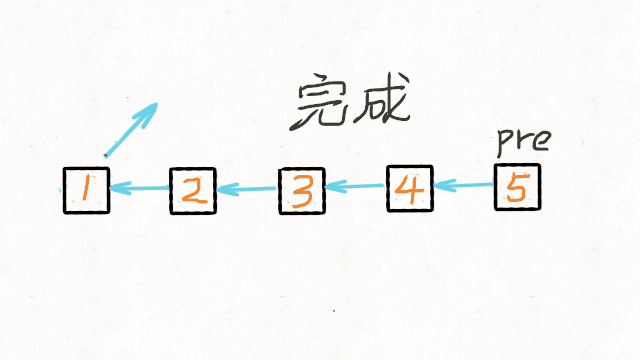
01.数据结构篇-链表
1.找出两个链表的交点 160. Intersection of Two Linked Lists (Easy) Leetcode / 力扣 例如以下示例中 A 和 B 两个链表相交于 c1: A: a1 → a2↘c1 → c2 → c3↗ B: b1 → b2 → b3 但是不会出现以下相交的情况,因为每个节点只有一个…...

揭秘产品迭代计划制定:从0到1打造完美迭代策略
产品迭代计划是产品团队确保他们能够交付满足客户需求的产品以及实现其业务目标的重要工具。开发一个成功的产品迭代计划需要仔细考虑产品的目标、客户需求、市场趋势和可用资源。以下是帮助您创建产品迭代计划的一些步骤:建立产品目标、收集客户反馈、分析市场趋势…...

【Perplexity文学研究黄金配置】:1个提示词模板+2个权威元数据过滤器+4类文学体裁专属指令集
更多请点击: https://codechina.net 第一章:Perplexity文学作品查询 Perplexity 是一款以实时网络检索与引用溯源为特色的 AI 助手,其在人文领域尤其适用于文学研究场景。不同于传统大模型的静态知识库,Perplexity 在响应用户查询…...

从IP到SoC:构建可重用验证环境的核心架构与实战
1. 项目概述:从IP到SoC,验证重用的价值与挑战在芯片设计这个行当里摸爬滚打十几年,最深的感触之一就是:验证,永远是那个最“烧钱”也最“烧时间”的环节。我们常开玩笑说,一个SoC项目,设计工程师…...

RISC-V开放架构如何重塑垂直半导体商业模式
1. 从边缘到中心:RISC-V的崛起与半导体模式的裂变最近和几位在芯片设计公司工作的老朋友聊天,话题总绕不开RISC-V。十年前,当我们还在讨论ARM和x86谁主沉浮时,RISC-V还只是学术界论文里的一个概念。如今,它已经成了行业…...

如何快速掌握JavaQuestPlayer:一站式QSP游戏开发与运行的终极指南
如何快速掌握JavaQuestPlayer:一站式QSP游戏开发与运行的终极指南 【免费下载链接】JavaQuestPlayer 项目地址: https://gitcode.com/gh_mirrors/ja/JavaQuestPlayer 还在为QSP游戏的兼容性和开发效率问题而烦恼吗?JavaQuestPlayer作为一款基于J…...

CTF命令执行绕过:从空格过滤到cat被禁,我的实战踩坑与绕过思路全记录
CTF命令执行绕过:从空格过滤到cat被禁,我的实战踩坑与绕过思路全记录 第一次参加CTF比赛时,面对命令执行题目总是手足无措。直到那次遇到著名的"Ping Ping Ping"挑战,才真正体会到什么叫"绝处逢生"。本文将还…...

分布式事务解决方案TCC实战
分布式事务解决方案TCC实战 一、分布式事务概述 在分布式系统中,事务跨越多个服务或数据库,传统的ACID事务无法直接适用,需要采用分布式事务解决方案。 1.1 分布式事务挑战 挑战说明网络延迟跨服务调用存在网络延迟和超时数据一致性多个数据源…...

G-Helper完整指南:3分钟掌握华硕笔记本性能优化神器
G-Helper完整指南:3分钟掌握华硕笔记本性能优化神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expe…...

别让“AI味”代码毁了你的项目:一份AI生成代码的质量评估与防御指南
别让“AI味”代码毁了你的项目:一份AI生成代码的质量评估与防御指南 前段时间,团队里一个新人在周会上展示了他用 AI 辅助完成的一个支付模块。代码跑通了,测试用例全绿,乍一看没什么问题。但我顺手点开一个 Service 层方法&#…...

CH340G模块除了下载程序,还能这么玩?一个硬件调试小技巧分享
CH340G模块的隐藏技能:用串口调试提升硬件开发效率 当你拿到一片CH340G模块时,第一反应可能是"这是个下载程序的好工具"。确实,这个价格亲民的小模块在51单片机开发中扮演着重要角色。但今天,我要分享的是它另一个被低估…...

LeetCode 合并K个排序链表题解
LeetCode 合并K个排序链表题解 题目描述 合并 k 个排序链表,返回合并后的排序链表。 示例: 输入:lists [[1,4,5],[1,3,4],[2,6]]输出:[1,1,2,3,4,4,5,6] 解题思路 方法:堆 思路: 使用最小堆存储每个链表的…...