六、Redis之数据持久化及高频面试题
6.1 数据持久化
官网文档地址:https://redis.io/docs/manual/persistence/
Redis提供了主要提供了 2 种不同形式的持久化方式:
- RDB(Redis数据库):RDB 持久性以指定的时间间隔执行数据集的时间点快照。
- AOF(Append Only File):AOF 持久化记录服务器接收到的每个写操作,在服务器启动时再次播放,重建原始数据集。 命令使用与 Redis 协议本身相同的格式以仅附加方式记录。 当日志变得太大时,Redis 能够在后台重写日志。
6.1.1 RDB
6.1.1.1 什么是 RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘, 也就是Snapshot快照,它恢复时是将快照文件直接读到内存里。
6.1.1.2 如何备份
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到 一个临时文件中,待持久化过程都结束后,再用这个临时文件替换上次持久化好的文件。主进程不进行任何的IO操作,这样就保证了较高的性能。如果需要进行大规模数据的恢复,并且对于数据恢复的不完整性非常敏感,那么RDB方式会比AOF方式更加高效。注意点:最后一次持久化后的数据可能丢失。
6.1.1.3 Fork
Fork的作用是复制一个与当前进程一样的进程,且新进程内的所有数据(变量,环境变量,程序计数器等等)数值都和原进程一直,但它是一个全新的进程,并且作为原进程的子进程。
在 Linux 程序中,fork() 会产生一个和父进程完全相同的子进程,但子进程在此后多会 exec 系统调用,出于效率考虑,Linux 中引入了“写时复制技术”。
一般情况下,父进程和子进程会共用一段物理内存,只有进程空间的各段内容发生变化时,才会将父进程的内容复制一份给子进程。
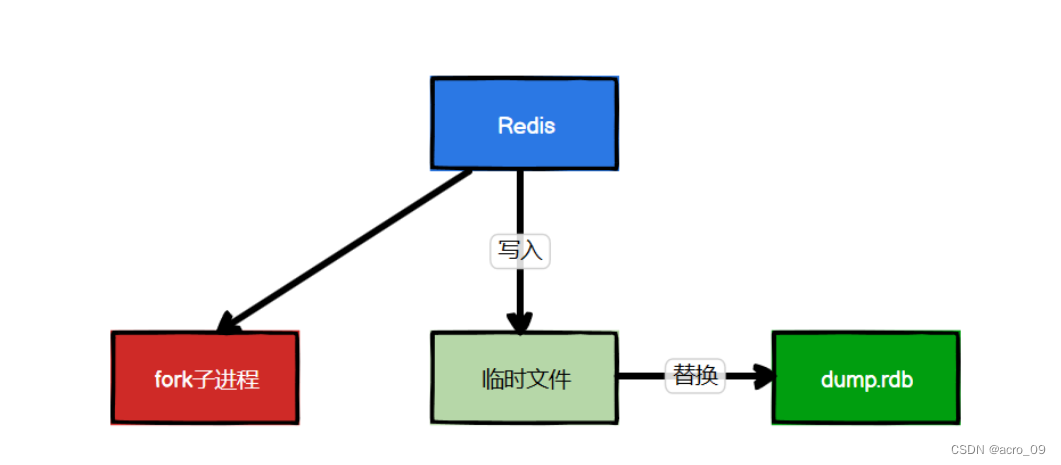
6.1.1.4 备份和恢复
#dump.rdb存放在两个位置上
1、root\ 目录 =====>通过正常的启动和关闭所保存的地址
2、var\lib\redis\ 目录 =====>通过 systemctl restart redis 命令所生成的
我们如果要进行备份还原的实验的话,确定目标地址,并选择适配的命令去观察变化
#步骤1:清空数据库
FLUSHALL
#步骤2:
客户端退出 exit
服务器关闭 ctrl+c
#步骤3:观察root\ 内的dump.rdb文件大小 发现是 92
#步骤4:正常启动redis并登录客户端
服务器启动 redis-server
客户端登录 redis-cli
#步骤5:保存了六组信息
set k1 v1
.......
set k6 v6
#步骤7:
客户端退出 exit
服务器关闭 ctrl+c
#步骤8:观察root\ 内的dump.rdb文件大小 发现是 139
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
#步骤9 将139大小的dump.rdb复制 命名为 dump.rdb.back
cp dump.rdb dump.rdb.back
#步骤10 删除dump.rdb
rm -f dump.rdb
#步骤11:正常启动redis并登录客户端,查看数据
服务器启动 redis-server
客户端登录 redis-cli
客户端查看 keys * ======================> 数据没有了
#步骤12
客户端退出 exit
服务器关闭 ctrl+c
#步骤13:观察root\ 内的dump.rdb文件大小 发现是 92
#步骤14:将139大小的dump.rdb.back复制 命名为 dump.rdb
#步骤15:正常启动redis并登录客户端,查看数据
服务器启动 redis-server
客户端登录 redis-cli
客户端查看 keys * ======================> 数据存在
6.1.2 AOF
6.1.2.1 什么是AOF
以日志的形式来记录每个写操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录), 只追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据。简单说,Redis 重启时会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
在Redis的默认配置中AOF(Append Only File)持久化机制是没有开启的,要想使用AOF持久化需要先开启此功能。AOF持久化会将被执行的写命令写到AOF文件末尾,以此来记录数据发生的变化,因此只要Redis从头到尾执行一次AOF文件所包含的所有写命令,就可以恢复AOF文件的记录的数据集。
6.1.2.2 持久化流程

-
客户端的请求写命令会被append追加到AOF缓冲器内。
-
AOF缓冲区根据AOF持久化策略,将sync同步到磁盘的AOF文件中
-
AOF文件大小超过了重写策略或手动重写时,会对AOF文件进行重写,以压缩AOF文件容量
-
Redis服务重启时,会重新load加载AOF文件中的写操作,已达到数据恢复的目的。
6.1.2.3 备份和恢复
#步骤1 开启AOF
修改 redis.conf 配置文件:
- 通过修改redis.conf配置中`appendonly yes`来开启AOF持久化
- 通过appendfilename指定日志文件名字(默认为appendonly.aof)
- 通过appendfsync指定日志记录频率
| 选项 | 同步频率 |
|---|---|
| always | 每个redis写命令都要同步写入硬盘,严重降低redis速度 |
| everysec | 每秒执行一次同步显式的将多个写命令同步到磁盘 |
| no | 由操作系统决定何时同步 |
#步骤2 重启服务以确保配置文件被重新读过
systemctl restart redis
#步骤3 在var/lib/redis目录内找到了 appendonly.aof
#步骤4:登录客户端并保存数据
客户端登录 redis-cli
#步骤5:保存了六组信息
set k1 v1
.......
set k6 v6
#步骤6:基于客户端关闭连接和服务
SHUTDOWN
#步骤7:在var/lib/redis目录内找到了 appendonly.aof (大小由0变成了一组数值)
#步骤8:复制appendonly.aof
cp appendonly.aof appendonly.aof.back
#步骤9:重启服务连接客户端
systemctl restart redis
客户端登录 redis-cli
#步骤10:清空数据库并停止服务
FLUSHDB
SHUTDOWN
#步骤11:在var/lib/redis目录内找到了 appendonly.aof (大小由一组数值变成了另一组数值 后数值>前数值)
#步骤12:复制appendonly.aof.back
cp appendonly.aof.back appendonly.aof
#步骤13:重启服务连接客户端
systemctl restart redis
客户端登录 redis-cli
#步骤14:检查数据
keys *
6.1.3 如何选择
那么,在开发中是选择 RDB 还是选择 AOF 来持久化呢?
官网建议如下:
Ok, so what should I use?
The general indication you should use both persistence methods is if you want a degree of data safety comparable to what PostgreSQL can provide you.
If you care a lot about your data, but still can live with a few minutes of data loss in case of disasters, you can simply use RDB alone.
There are many users using AOF alone, but we discourage it since to have an RDB snapshot from time to time is a great idea for doing database backups, for faster restarts, and in the event of bugs in the AOF engine.
The following sections will illustrate a few more details about the two persistence models.
-
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储
-
AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.
-
Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大
-
只做缓存:如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.
-
同时开启两种持久化方式
-
在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据, 因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
-
RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢?
-
建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份), 快速重启,而且不会有AOF可能潜在的bug,留着作为一个万一的手段。
6.2 高频面试题
6.2.1 缓存穿透
6.2.1.1 描述
用户想要查询某个数据,在 Redis 中查询不到,即没有缓存命中,这时就会直接访问数据库进行查询。当请求量超出数据库最大承载量时,就会导致数据库崩溃。这种情况一般发生在非正常 URL 访问,目的不是为了获取数据,而是进行恶意攻击。
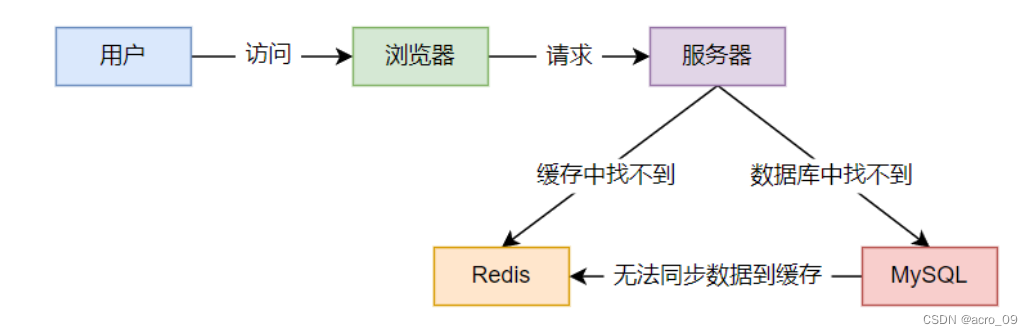
6.2.1.2 现象
-
应用服务器压力变大
-
Redis缓存命中率降低
-
一直查询数据库
6.2.1.3 原因
一个不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
6.2.1.4 解决
① 对空值缓存:如果一个查询数据为空(不管数据是否存在),都对该空结果进行缓存,其过期时间会设置非常短。
② 设置可以访问名单:使用bitmaps类型定义一个可以访问名单,名单id作为bitmaps的偏移量,每次访问时与bitmaps中的id进行比较,如果访问id不在bitmaps中,则进行拦截,不允许访问。
③ 采用布隆过滤器:布隆过滤器可以判断元素是否存在集合中,他的优点是空间效率和查询时间都比一般算法快,缺点是有一定的误识别率和删除困难。
④ 进行实时监控:当发现 Redis 缓存命中率急速下降时,迅速排查访问对象和访问数据,将其设置为黑名单。
6.2.2 缓存击穿
6.2.2.1 描述
key中对应数据存在,当key中对应的数据在缓存中过期,而此时又有大量请求访问该数据,由于缓存中过期了,请求会直接访问数据库并回设到缓存中,高并发访问数据库会导致数据库崩溃。
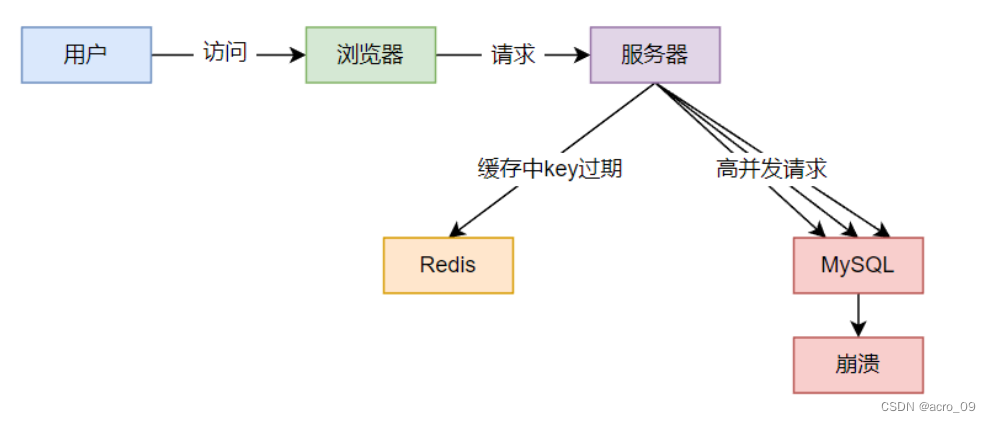
6.2.2.2 现象
-
数据库访问压力瞬时增加
-
Redis中没有出现大量 Key 过期
-
Redis正常运行
-
数据库崩溃
6.2.2.3 原因
由于 Redis 中某个 Key 过期,而正好有大量访问使用这个 Key,此时缓存无法命中,因此就会直接访问数据层,导致数据库崩溃。
最常见的就是非常“热点”的数据访问。
6.2.2.4 解决
① 预先设置热门数据:在redis高峰访问时期,提前设置热门数据到缓存中,或适当延长缓存中key过期时间。
② 实时调整:实时监控哪些数据热门,实时调整key过期时间。
③ 对于热点key设置永不过期。
6.2.3 缓存雪崩
6.2.3.1 描述
key中对应数据存在,在某一时刻,缓存中大量key过期,而此时大量高并发请求访问,会直接访问后端数据库,导致数据库崩溃。
注意:缓存击穿是指一个key对应缓存数据过期,缓存雪崩是大部分key对应缓存数据过期。
正常情况下:
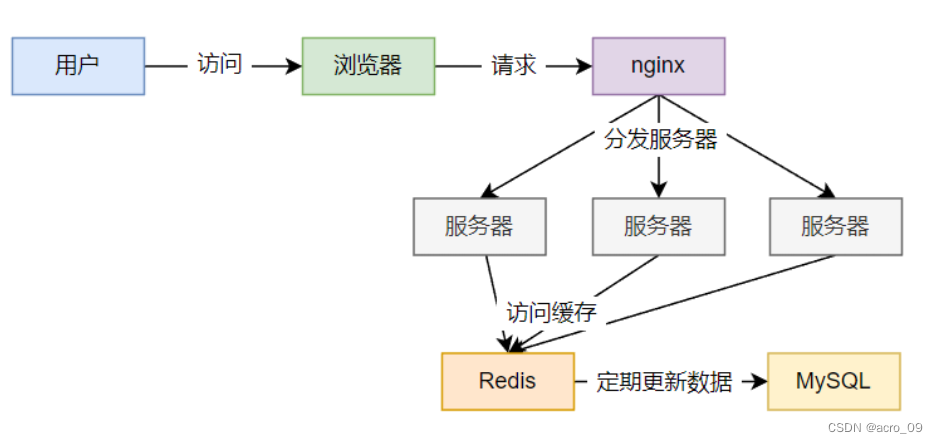
缓存失效瞬间:
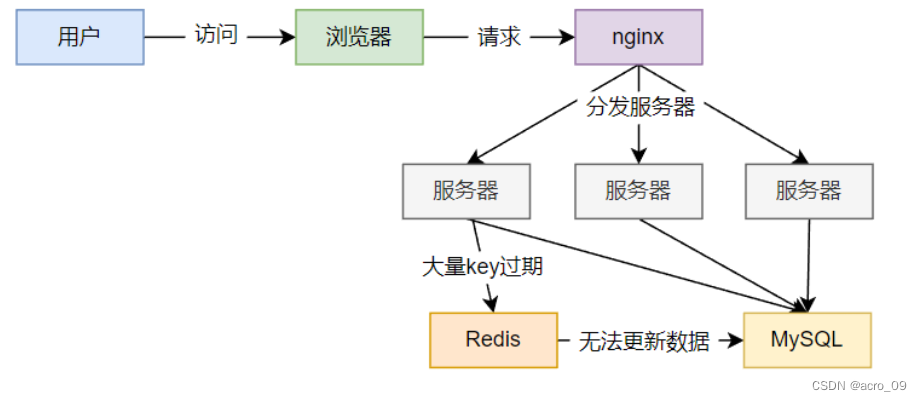
6.2.3.2 现象
- 数据库压力变大导致数据库和 Redis 服务崩溃
6.2.3.3 原因
在极短时间内,查询大量 key 的集中过期数据。
6.2.3.4 解决
① 构建多级缓存机制:nginx缓存 + redis缓存 + 其他缓存。
② 设置过期标志更新缓存:记录缓存数据是否过期,如果过期会触发另外一个线程去在后台更新实时key的缓存。
③ 将缓存可以时间分散:如在原有缓存时间基础上增加一个随机值,这个值可以在1-5分钟随机,这样过期时间重复率就会降低,防止大量key同时过期。
④ 使用锁或队列机制:使用锁或队列保证不会有大量线程一次性对数据库进行读写,从而避免大量并发请求访问数据库,该方法不适用于高并发情况。
相关文章:
六、Redis之数据持久化及高频面试题
6.1 数据持久化 官网文档地址:https://redis.io/docs/manual/persistence/ Redis提供了主要提供了 2 种不同形式的持久化方式: RDB(Redis数据库):RDB 持久性以指定的时间间隔执行数据集的时间点快照。AOF࿰…...
爬虫——ajax和selenuim总结
为什么要写这个博客呢,这个代码前面其实都有,就是结束了。明天搞个qq登录,这个就结束了。 当然也会更新小说爬取,和百度翻译,百度小姐姐的爬取,的对比爬取。总结嘛!!!加…...

【Python】单元测试unittest框架
note 使用unittest框架进行单元测试是Python标准库的一部分,提供了编写测试用例、测试套件以及运行测试的能力。测试用例是继承自unittest.TestCase的类。在这个类中,你可以定义一系列的方法来测试不同的行为。每个测试方法都应该以test开头。 文章目录…...

(三十七)大数据实战——Solr服务的部署安装
前言 Solr是一个基于Apache Lucene的开源搜索平台,它提供了强大的全文搜索、分布式搜索和数据分析功能。Solr 可以用于构建高性能的搜索应用程序,支持从海量数据中快速检索和分析信息。Solr 使用倒排索引和先进的搜索算法,可实现快速而准确的…...
在Ubuntu22.04上部署FoooCUS2.1
Fooocus 是一款基于 Gradio的图像生成软件,Fooocus 是对 Stable Diffusion 和 Midjourney 设计的重新思考: 1、从 Stable Diffusion 学习,该软件是离线的、开源的和免费的。 2、从 Midjourney 中学到,不需要手动调整,…...
详解C语言中的野指针和assert断言
目录 1.野指针1.1 野指针成因1.1.1 指针未初始化1.1.2 指针越界访问1.1.3 指针指向的空间释放 1.2 如何规避野指针1.2.1 指针初始化1.2.2 小心指针越界1.2.3 指针变量不再使用时,及时置为NULL,指针使用之前检查1.2.4 避免返回局部变量的地址 2.assert断言…...
)
Vue源码系列讲解——模板编译篇【四】(文本解析器)
1. 前言 在上篇文章中我们说了,当HTML解析器解析到文本内容时会调用4个钩子函数中的chars函数来创建文本型的AST节点,并且也说了在chars函数中会根据文本内容是否包含变量再细分为创建含有变量的AST节点和不包含变量的AST节点,如下ÿ…...
微信小程序开发学习笔记《17》uni-app框架-tabBar
微信小程序开发学习笔记《17》uni-app框架-tabBar 博主正在学习微信小程序开发,希望记录自己学习过程同时与广大网友共同学习讨论。建议仔细阅读uni-app对应官方文档 一、创建tabBar分支 运行如下的命令,基于master分支在本地创建tabBar子分支&#x…...

《区块链公链数据分析简易速速上手小册》第5章:高级数据分析技术(2024 最新版)
文章目录 5.1 跨链交易分析5.1.1 基础知识5.1.2 重点案例:分析以太坊到 BSC 的跨链交易理论步骤和工具准备Python 代码示例构思步骤1: 设置环境和获取合约信息步骤2: 分析以太坊上的锁定交易步骤3: 跟踪BSC上的铸币交易 结论 5.1.3 拓展案例 1:使用 Pyth…...
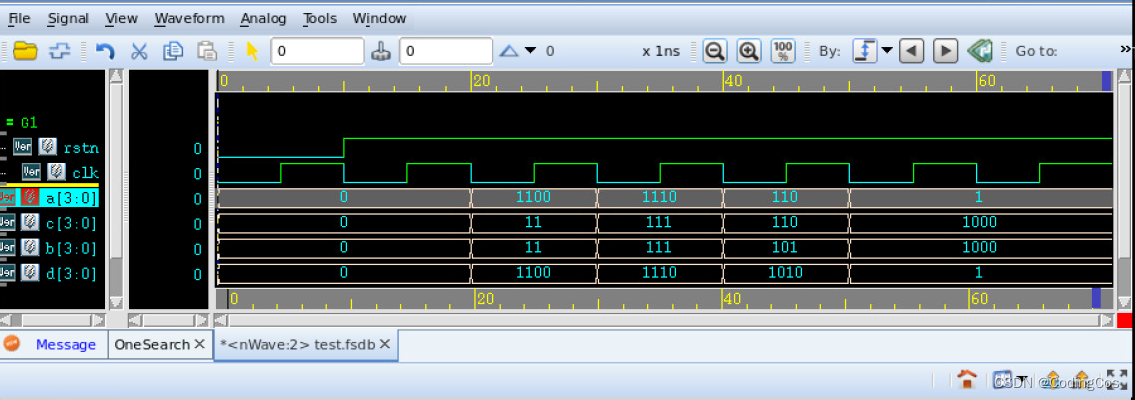
【芯片设计- RTL 数字逻辑设计入门 15 -- 函数实现数据大小端转换】
文章目录 函数实现数据大小端转换函数语法函数使用的规则Verilog and Testbench综合图VCS 仿真波形 函数实现数据大小端转换 在数字芯片设计中,经常把实现特定功能的模块编写成函数,在需要的时候再在主模块中调用,以提高代码的复用性和提高设…...

Codeforces Round 925 (Div. 3) D. Divisible Pairs (Java)
Codeforces Round 925 (Div. 3) D. Divisible Pairs (Java) 比赛链接:Codeforces Round 925 (Div. 3) D题传送门:D.Divisible Pairs 题目:D.Divisible Pairs 题目描述 输出格式 For each test case, output a single integer — the num…...

【C语言】实现单链表
目录 (一)头文件 (二)功能实现 (1)打印单链表 (2)头插与头删 (3)尾插与尾删 (4) 删除指定位置节点 和 删除指定位置之后的节点 …...

Hive调优——合并小文件
目录 一、小文件产生的原因 二、小文件的危害 三、小文件的解决方案 3.1 小文件的预防 3.1.1 减少Map数量 3.1.2 减少Reduce的数量 3.2 已存在的小文件合并 3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…...
责任链模式)
设计模式(行为型模式)责任链模式
目录 一、简介二、责任链模式2.1、处理器接口2.2、具体处理器类2.3、使用 三、优点与缺点 一、简介 责任链模式(Chain of Responsibility Pattern)是一种行为设计模式,允许你将请求沿着处理者链进行传递,直到有一个处理者能够处理…...
HTTP和HTTPS区别!
http 是我们几乎天天都要打交道的东西,相关知识点有点多,所以也有不少面试必问的点,这里做了一些整理,帮且大家树立完整的 http 知识体系,对面试官说 so easy HTTP 的特点和缺点 特点:无连接、无状态、灵…...
)
麻将普通胡牌算法(带混)
最近在玩腾讯的麻将游戏,但是经常需要充值,于是就想自己实现一个简单的单机麻将游戏.第一个难点就是实现胡牌的判断.这里写一下心得. 术语 本文的胡牌是指手牌构成了3N2的牌型,即一对做将,剩下的牌均为刻子(3张一样的牌)或者顺子(3张连续的牌比如234饼). 下面就是一个14张牌…...

Rust结构体详解:定义、使用及方法
Rust 是一门强调安全性和性能的系统级编程语言,它引入了结构体(struct)作为一种自定义的数据类型,允许程序员以更加灵活的方式组织和操作数据。在本篇博客中,我们将深入探讨 Rust 结构体的定义、使用以及相关概念。 什…...
LeetCode、435. 无重叠区间【中等,贪心 区间问题】
文章目录 前言LeetCode、435. 无重叠区间【中等,贪心 区间问题】题目链接及分类思路贪心、区间问题 资料获取 前言 博主介绍:✌目前全网粉丝2W,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技…...
 —— 前端要学的测试课 从Jest入门到TDD BDD双实战(三))
【实战】一、Jest 前端自动化测试框架基础入门(三) —— 前端要学的测试课 从Jest入门到TDD BDD双实战(三)
文章目录 一、Jest 前端自动化测试框架基础入门7.异步代码的测试方法8.Jest 中的钩子函数9.钩子函数的作用域 学习内容来源:Jest入门到TDD/BDD双实战_前端要学的测试课 相对原教程,我在学习开始时(2023.08)采用的是当前最新版本&a…...

信息学奥赛一本通1228:书架
1228:书架 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 18190 通过数: 10557 【题目描述】 John最近买了一个书架用来存放奶牛养殖书籍,但书架很快被存满了,只剩最顶层有空余。 John共有N�头奶牛(1≤N≤20,0001≤…...

一文读懂:文档解析、RAG、知识库及文档Agent
AI会取代人类工作吗?斯坦福大学教授、AI领域顶尖学者吴恩达近日明确表示:不会有AI就业末日。在他看来,AI会影响岗位、改变技能要求、替代部分任务,但将其描绘成大规模失业灾难,“是在制造不必要的恐惧,也是…...

5分钟快速上手APK Installer:Windows电脑安装Android应用的终极指南
5分钟快速上手APK Installer:Windows电脑安装Android应用的终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上直接运行Android应用…...

告别Resources.Load!Unity动态加载材质资源的最佳实践与性能优化指南
Unity材质资源动态加载:从基础实现到架构级优化方案 在AR涂鸦、实时换装、用户自定义皮肤等现代游戏交互场景中,动态材质加载已成为核心需求。传统Resources.Load虽简单直接,但在大型项目中常引发资源管理混乱、内存泄漏和热更新障碍。本文将…...

测试TVS:SP0503BAHTG
简 介: 本文测试了SP0503BAHTG三通道TVS二极管阵列的特性。通过设计测试电路板,测量了该器件对1kHz正弦波的限幅效果,测得反向导通电压约-0.8V,顶部饱和电压6.3V。在1MHz高频测试中观察到快速响应特性,通过矩形波上升沿…...
)
Midjourney年度订阅最后上车机会:官方邮件暗藏“早鸟密钥”,输入即解锁终身$129→$79(已验证有效期至2024-12-15)
更多请点击: https://kaifayun.com 第一章:Midjourney年度订阅优惠的官方政策与背景解析 Midjourney自2023年起正式将年度订阅(Annual Plan)纳入其核心付费体系,旨在为长期用户降低平均月成本并强化服务稳定性。该政策…...

Android Studio中文界面终极解决方案:告别官方插件的兼容性烦恼
Android Studio中文界面终极解决方案:告别官方插件的兼容性烦恼 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为…...

Captain AI助Ozon Listing全链路优化,流量与转化双提升
Listing是Ozon商家获取流量、提升转化的核心载体,优质的Listing能让商品在海量竞品中脱颖而出,而多数商家却深陷“标题违规、主图不达标、关键词无效”的困境,导致商品曝光低、转化率差,难以突破运营瓶颈。Captain AI深耕Ozon Lis…...

3个核心功能+5个实战技巧:用B站神奇弹幕彻底解放你的直播双手
3个核心功能5个实战技巧:用B站神奇弹幕彻底解放你的直播双手 【免费下载链接】MagicalDanmaku 本仓库及所有相关项目已永久停止开发、维护和任何形式的分发。 项目地址: https://gitcode.com/gh_mirrors/bi/MagicalDanmaku 你是否还在直播时手忙脚乱地回复弹…...

半年飙到 15.7 万 Star!OpenCode:Claude Code 最强开源对手,模型随便挑
👉 这是一个或许对你有用的社群🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料: 《项目实战(视频)》:从书中学,往事上…...

【源码篇】地牢里的钟摆,解析引擎与运算核心的 C++ 映射
概要:光有律令是不够的,我们需要看到法则在地牢里真正流动的样子。响应大家的呼声,本篇将正式公开我为这台 4-bit 处理器设计的运算核心(ALU)与指令解析引擎(Decoder)的部分源码。看 C11 如何精…...