【Linux环境基础开发工具的使用(yum、vim、gcc、g++、gdb、make/Makefile)】
Linux环境基础开发工具的使用yum、vim、gcc、g++、gdb、make/Makefile
- Linux软件包管理器- yum
- Linux下安装软件的方式
- 认识yum
- 查找软件包
- 安装软件
- 如何实现本地机器和云服务器之间的文件互传
- 卸载软件
- Linux编辑器 - vim
- vim的基本概念
- vim下各模式的切换
- vim命令模式各命令汇总
- vim底行模式各命令汇总
- vim的简单配置
- Linux编译器- gcc/g++
- gcc/g++的作用
- gcc/g++语法
- 预处理
- 编译
- 汇编
- 链接
- 静态库与动态库
- Linux调试器- gdb
- gdb使用须知
- gdb命令汇总
- Linux项目自动化构建工具-make/Makefile
- make/Makefile的重要性
- 依赖关系和依赖方法
- 多文件编译
- make原理
- 项目清理
- 完善makefile
- Linux第一个小程序-进度条
- 行缓冲区的概念
- r和n
- 进度条代码及效果展示
Linux软件包管理器- yum
Linux下安装软件的方式
Linux下安装软件的方式
在Linux下安装软件的方法大概有以下三种:
1)下载到程序的源代码,自行进行编译,得到可执行程序。
2)获取rpm安装包,通过rpm命令进行安装。(未解决软件的依赖关系)
3)通过yum进行安装软件。(常用)
认识yum
yum是一个在Fedora、RedHat以及CentOS中的前端软件包管理器,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。
注意:一个服务器同一时刻只允许一个yum进行安装,不能在同一时刻同时安装多个软件。
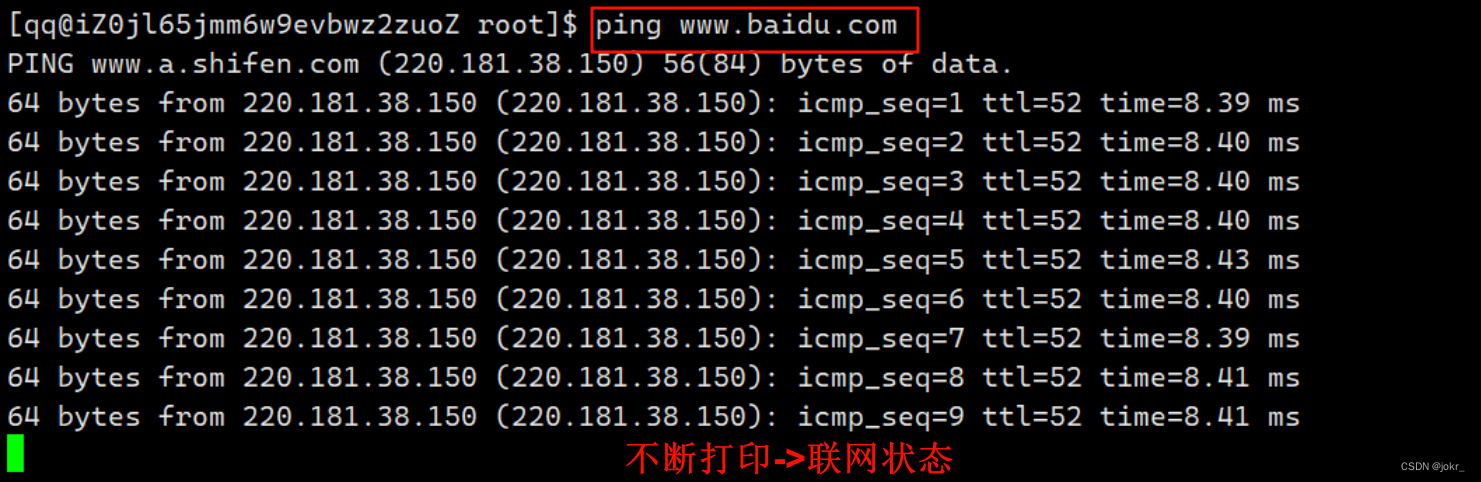
因为yum是从服务器上下载RPM包,所以在下载时必须联网,可以通过ping指令判断当前云服务器是否联网。
查找软件包
[qq@iZ0jl65jmm6w9evbwz2zuoZ root]$ yum list
说明一下:
1)软件包名称:主版本号.次版本号.源程序发行号-软件包的发行号.主机平台.cpu架构。
2)"x86_64"后缀表示64位系统的安装包,"i686"后缀表示32位系统安装包,选择包时要和系统匹配。
3)"el7"表示操作系统发行版的版本,“el7"表示的是"centos7/redhat7”,“el6"表示"centos6/redhat6”。
4)最后一列表示的是“软件源”的名称,类似于“小米应用商店”,“华为应用商店”这样的概念。
这里我们以查找lrzsz为例。
lrzsz可以将Windows当中的文件上传到Linux当中,也可以将Linux当中的文件下载到Windows当中,实现云服务器和本地机器之间进行信息互传。
[qq@iZ0jl65jmm6w9evbwz2zuoZ root]$ yum list | grep lrzsz
由于包的数量非常多,所以我们可以使用grep指令筛选出我们所关注的包,这里我们以lrzsz为例。

此时就只会显示与lrzsz相关的软件包。
安装软件
指令: sudo yum install 软件名
[qq@iZ0jl65jmm6w9evbwz2zuoZ root]$ sudo yum install lrzsz

yum会自动找到都有哪些软件包需要下载,这时候敲“y”确认安装,当出现“complete”字样时,说明安装完成。
注意事项:
1)安装软件时由于需要向系统目录中写入内容,一般需要sudo或者切换到root账户下才能完成。
2)yum安装软件只能一个装完了再装另一个,正在使用yum安装一个软件的过程中,如果再尝试用yum安装另外一个软件,yum会报错。
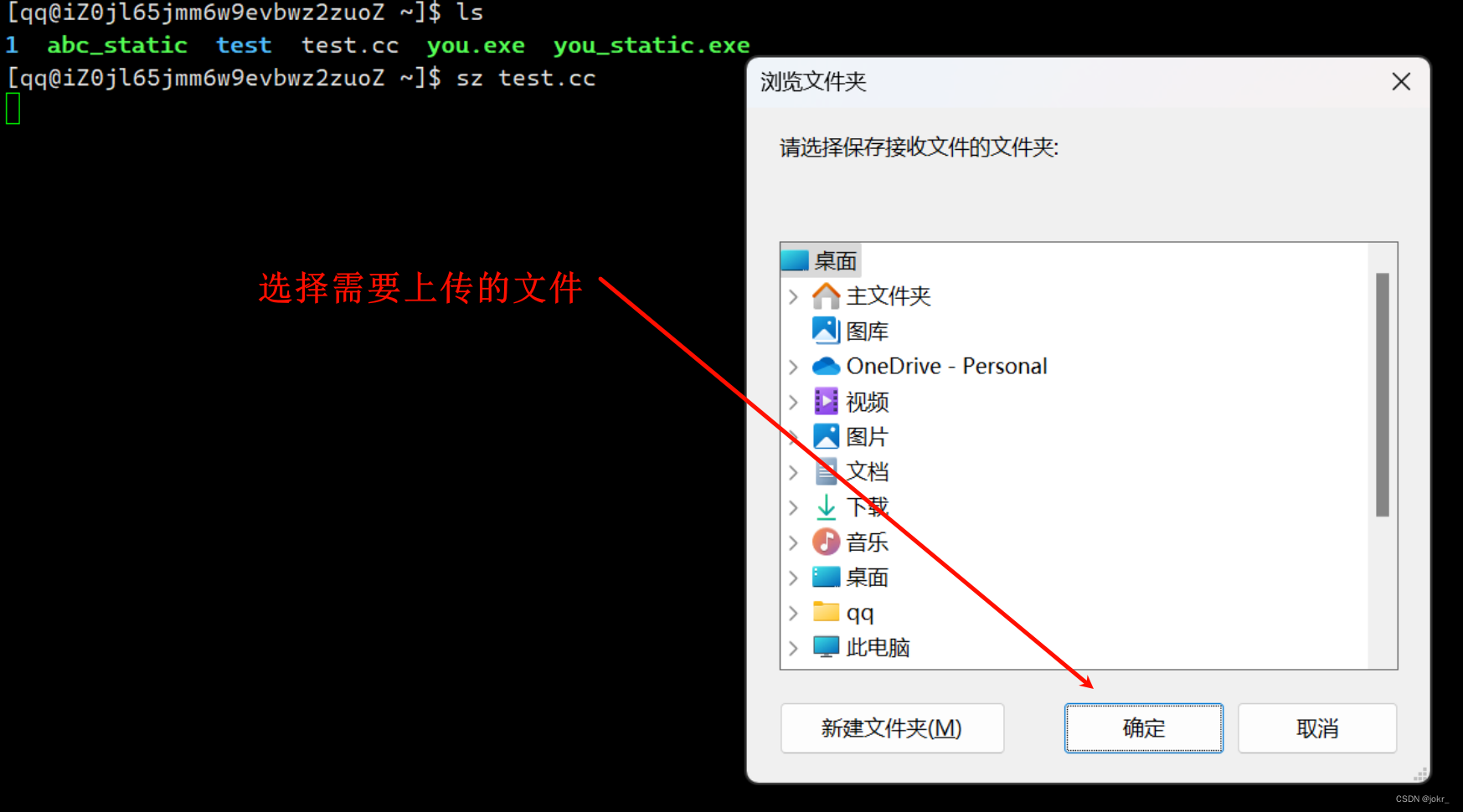
如何实现本地机器和云服务器之间的文件互传
既然已经安装了lrzsz,这里就顺便说一下lrzsz如何使用。
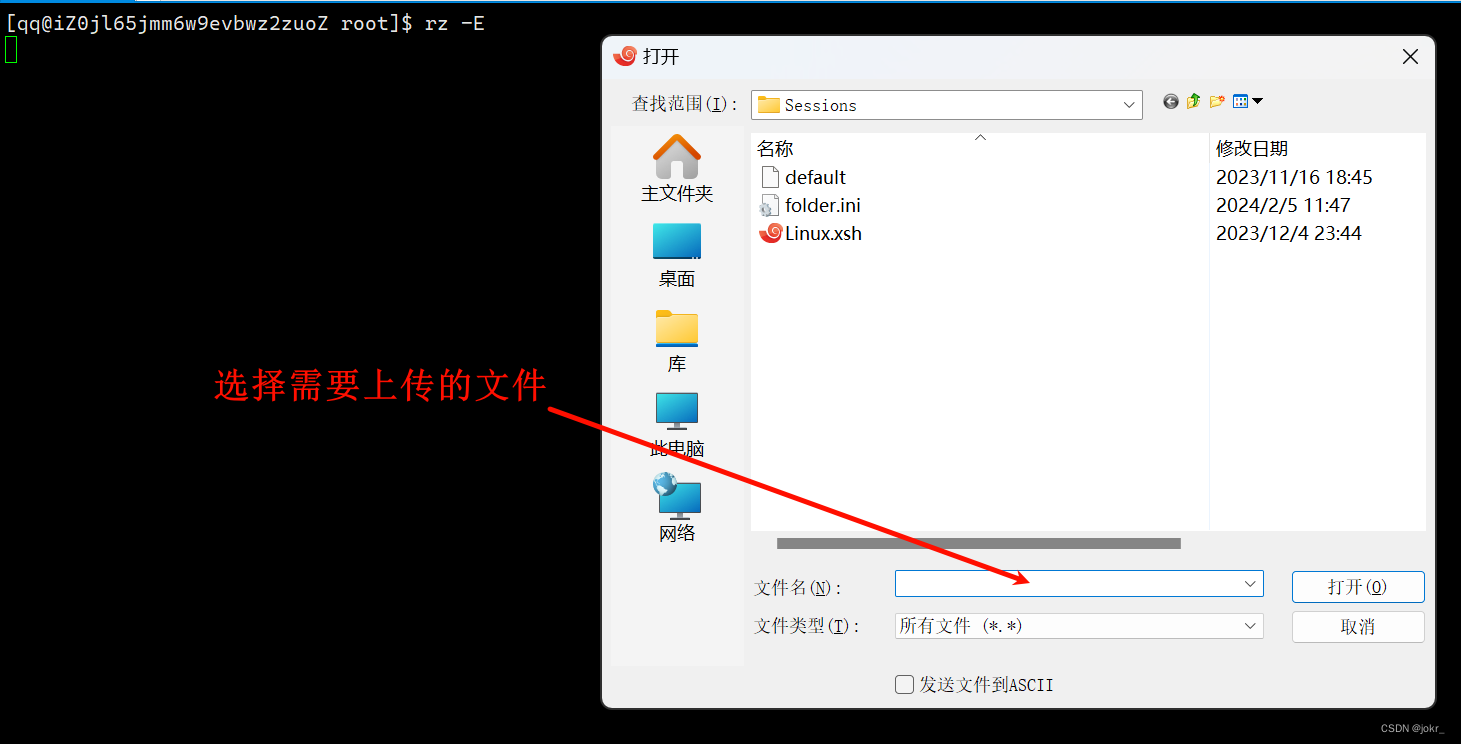
指令: rz -E
通过该指令可选择需要从本地机器上传到云服务器的文件。
指令: sz 文件名
该指令可将云服务器上的文件下载到本地机器的指定文件夹。
卸载软件
指令: sudo yum remove 软件名
[qq@iZ0jl65jmm6w9evbwz2zuoZ ~]$ sudo yum remove lrzszyum会自动卸载该软件,这时候敲“y”确认卸载,当出现“complete”字样时,说明卸载完成。
Linux编辑器 - vim
vim的基本概念
vim在我们做开发的时候,主要解决我们编写代码的问题,本质上就是一个多模式的文本编辑器。
我们这里主要介绍vim最常用的三种模式:命令模式、插入模式、底行模式。
1、命令模式(Normal mode)。
在命令模式下,我们可以控制屏幕光标的移动,字符、字或行的删除,复制粘贴,剪贴等操作。
2、插入模式(Insert mode)。
只有在插入模式下才能进行文字输入,该模式是我们使用最频繁的编辑模式。
3、底行模式(Command mode)。
在底行模式下,我们可以将文件保存或退出,也可以进行查找字符串等操作。在底行模式下我们还可以直接输入vim help-modes查看当前vim的所有模式。
vim下各模式的切换
指令: vim 文件名
[qq@iZ0jl65jmm6w9evbwz2zuoZ ~]$ vim test.cc
进入vim后默认为命令模式(普通模式),要输入文字需切换到插入模式。
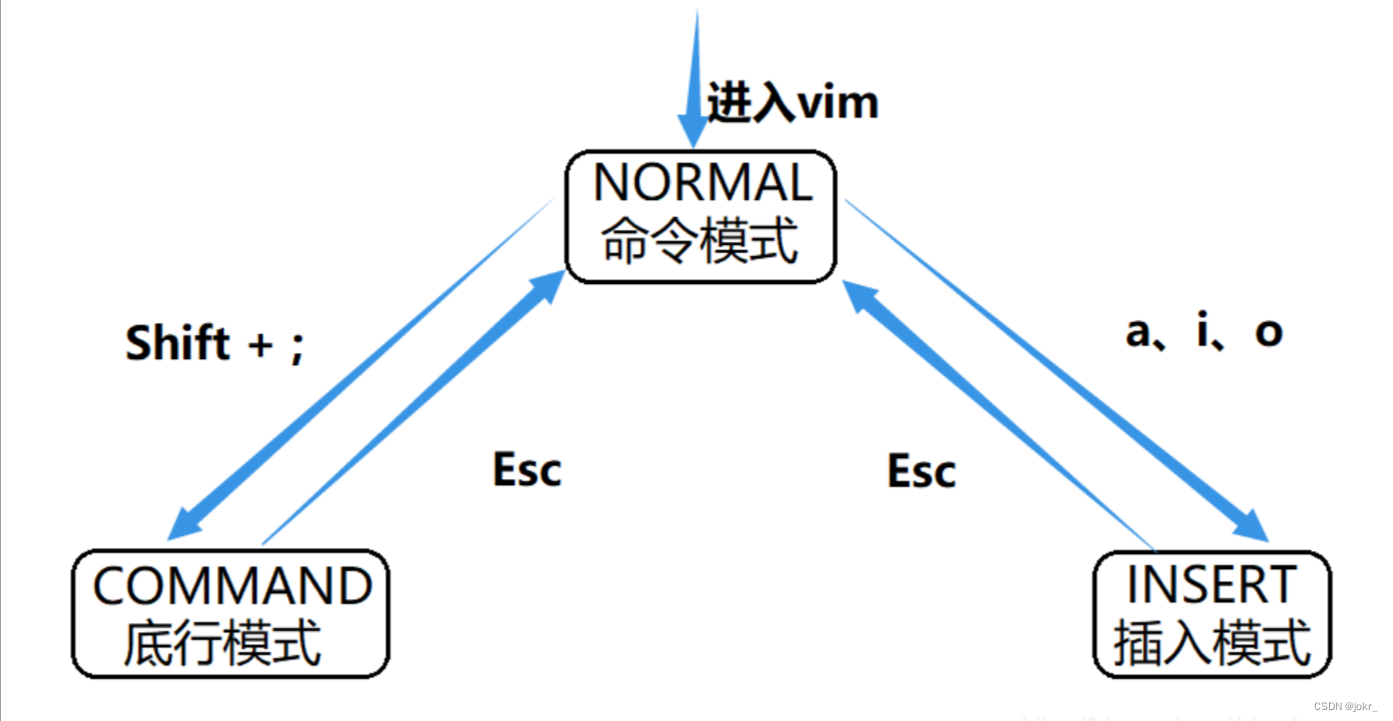
【命令模式】切换至【插入模式】
1)输入「i」:在当前光标处进入插入模式。
2)输入「a」:在当前光标的后一位置进入插入模式。
3)输入「o」:在当前光标处新起一行进入插入模式。
【命令模式】切换至【底行模式】
1)输入「Shift+;」即可,实际上就是输入「:」。
【插入模式】或【底行模式】切换至【命令模式】
1)插入模式或是底行模式切换至命令模式都是直接按一下「Esc」键即可。
vim命令模式各命令汇总
【移动光标】
1)按「k」:光标上移。
2)按「j」:光标下移。
3)按「h」:光标左移。
4)按「l」:光标右移。
5)按「$」:移动到光标所在行的行尾。
6)按「^」:移动到光标所在行的行首。
7)按「gg」:移动到文本开始。
8)按「Shift+g」:移动到文本末尾。
9)按「n+Shift+g」:移动到第n行行首。
10)按「n+Enter」:当前光标向下移动n行。
11)按「w」:光标从左到右,从上到下的跳到下一个字的开头。
12)按「e」:光标从左到右,从上到下的跳到下一个字的结尾。
12)按「b」:光标从右到左,从下到上的跳到上一个字的开头
【删除】
1)按「x」:删除光标所在位置的字符。
2)按「nx」:删除光标所在位置开始往后的n个字符。
3)按「X」:删除光标所在位置的前一个字符。
4)按「nX」:删除光标所在位置的前n个字符。
5)按「dd」:删除光标所在行。
6)按「ndd」:删除光标所在行开始往下的n行。
【复制粘贴】
1)按「yy」:复制光标所在行到缓冲区。
2)按「nyy」:复制光标所在行开始往下的n行到缓冲区。
3)按「yw」:将光标所在位置开始到字尾的字符复制到缓冲区。
4)按「nyw」:将光标所在位置开始往后的n个字复制到缓冲区。
5)按「p」:将已复制的内容在光标的下一行粘贴上。
6)按「np」:将已复制的内容在光标的下一行粘贴n次。
【剪切】
1)按「dd」:剪切光标所在行。
2)按「ndd」:剪切光标所在行开始往下的n行。
3)按「p」:将已剪切的内容在光标的下一行粘贴上。
4)按「np」:将已剪切的内容在光标的下一行粘贴n次。
【撤销】
1)按「u」:撤销。
2)按「Ctrl+r」:恢复刚刚的撤销。
【大小写切换】
1)按「~」:完成光标所在位置字符的大小写切换。
2)按「n~」:完成光标所在位置开始往后的n个字符的大小写切换。
【替换】
1)按「r」:替换光标所在位置的字符。
2)按「R」:替换光标所到位置的字符,直到按下「Esc」键为止。
【更改】
1)按「cw」:将光标所在位置开始到字尾的字符删除,并进入插入模式。
2)按「cnw」:将光标所在位置开始往后的n个字删除,并进入插入模式。
【翻页】
1)按「Ctrl+b」:上翻一页。
2)按「Ctrl+f」:下翻一页。
3)按「Ctrl+u」:上翻半页。
4)按「Ctrl+d」:下翻半页。
vim底行模式各命令汇总
在使用底行模式之前,记住先按「Esc」键确定你已经处于命令模式,再按「:」即可进入底行模式。
【行号设置】
1)「set nu」:显示行号。
2)「set nonu」:取消行号。
【保存退出】
1)「w」:保存文件。
2)「q」:退出vim,如果无法离开vim,可在「q」后面跟一个「!」表示强制退出。
3)「wq」:保存退出。
【分屏指令】
1)「vs 文件名」:实现多文件的编辑。
2)「Ctrl+w+w」:光标在多屏幕下进行切换。
【执行指令】
1)「!+指令」:在不退出vim的情况下,可以在指令前面加上「!」就可以执行Linux的指令,例如查看目录、编译当前代码等。
vim的简单配置
【配置文件的位置】
1)在目录/etc/下面,有个名为vimrc的文件,这是系统中公共的配置文件,对所有用户都有效。
2)在每个用户的主目录/home/xxx下,都可以自己建立私有的配置文件,命名为“.vimrc”,这是该用户私有的配置文件,仅对该用户有效。
例如,普通用户在自己的主目录下建立了“.vimrc”文件后,在文件当中输入set nu指令并保存,下一次打开vim的时候就会自动显示行号。
vim的配置比较复杂,某些vim配置还需要使用插件,建议不要自己一个个去配置。比较简单的方法是直接执行以下指令(想在哪个用户下让vim配置生效,就在哪个用户下执行该指令,不推荐直接在root下执行):
curl -sLf https://gitee.com/HGtz2222/VimForCpp/raw/master/install.sh -o ./install.sh && bash ./install.sh
然后按照提示输入root密码:
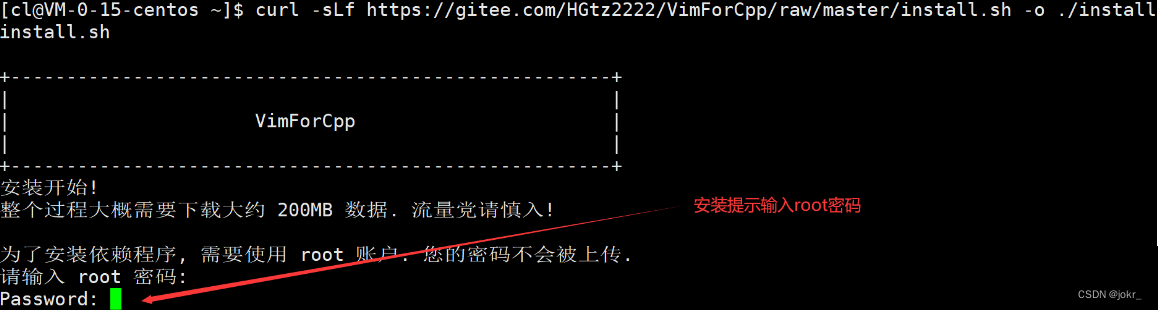
然后等待安装配置,最后手动执行source ~/.bashrc即可。

配置完成后,像什么自动补全、行号显示以及自动缩进什么的就都有了。
Linux编译器- gcc/g++
gcc/g++的作用
gcc和g++分别是GNU的C和C++的编译器,gcc和g++在执行编译的时候一般有以下四个步骤:
1)预处理(头文件展开、去注释、宏替换、条件编译)。
2)编译(C代码翻译成汇编语言)。
3)汇编(汇编代码转为二进制目标代码)。
4)链接(将汇编过程产生的二进制代码进行链接)。
gcc/g++语法
语法: gcc/g++ 选项 文件
常用选项:
1)-E 只进行预处理,这个不生成文件,你需要把他重定向到一个输出文件里面(否则将把预处理后的结果打印到屏幕上)。
2)-S 编译到汇编语言,不进行汇编和链接,即只进行预处理和编译。
3)-c 编译到目标代码
4)-o 将处理结果输出到指定文件,该选项后需紧跟输出文件名。
5)-static 此选项对生成的文件采用静态链接。
6)-g 生成调试信息(若不携带该选项则默认生成release版本)。
7)-shared 此选项将尽量使用动态库,生成文件较小。
8)-w 不生成任何警告信息。
9)Wall 生成所有警告信息。
10)-O0/-O1/-O2/-O3 编译器优化选项的四个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高。
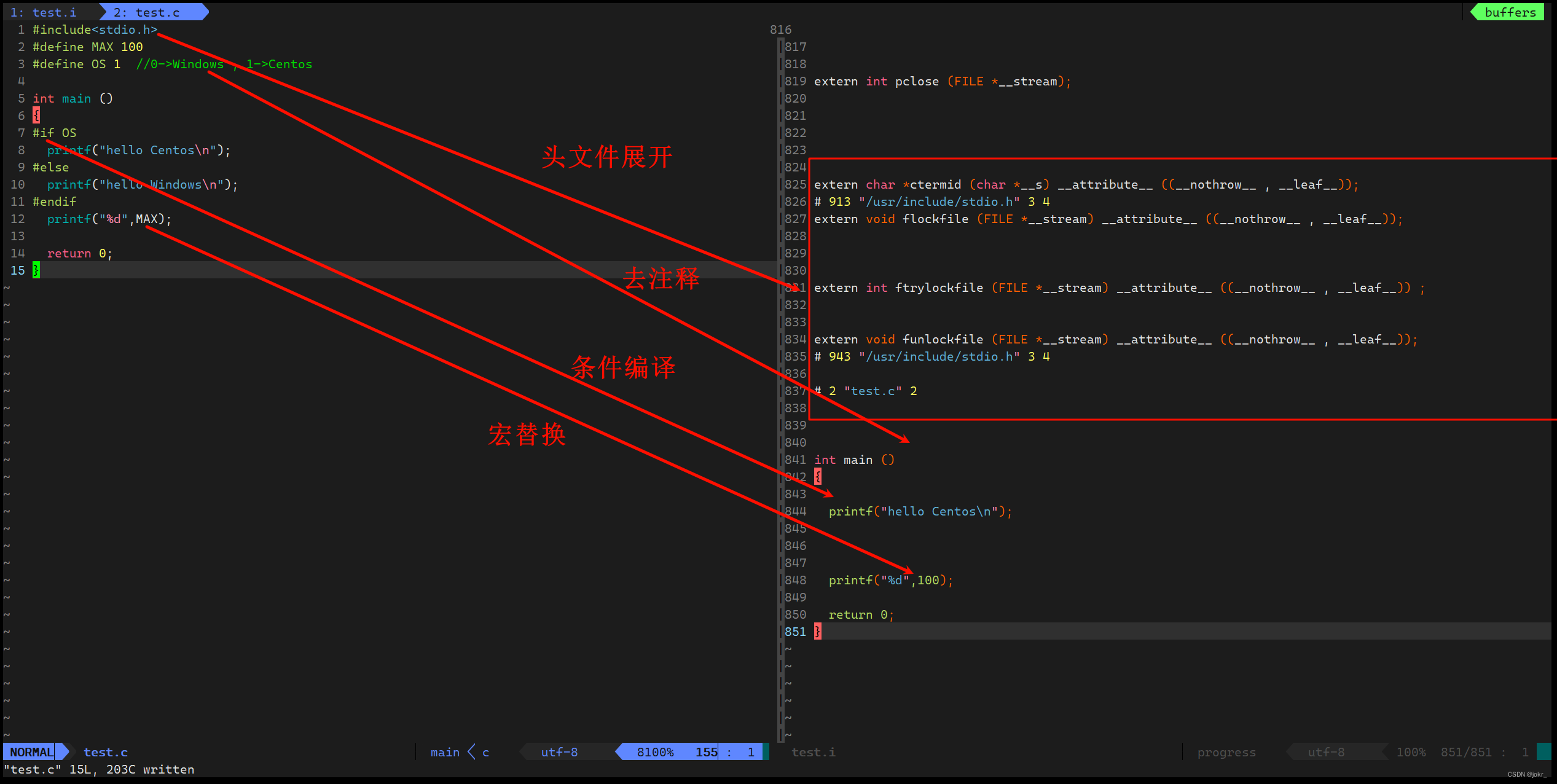
预处理
[qq@iZ0jl65jmm6w9evbwz2zuoZ ~]$ gcc -E test.c -o test.i- 预处理功能主要包括头文件展开、去注释、宏替换、条件编译等。
- 预处理指令是以#开头的代码行。
- -E选项的作用是让gcc/g++在预处理结束后停止编译过程。
- -o选项是指目标文件,“xxx.i”文件为已经过预处理的原始程序。
编译
[qq@iZ0jl65jmm6w9evbwz2zuoZ ~]$ gcc -S test.i -o test.s
- 在这个阶段中,gcc/g++首先检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,将代码翻译成汇编语言。
- 用户可以使用-S选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。
- -o选项是指目标文件,“xxx.s”文件为已经过翻译的原始程序。
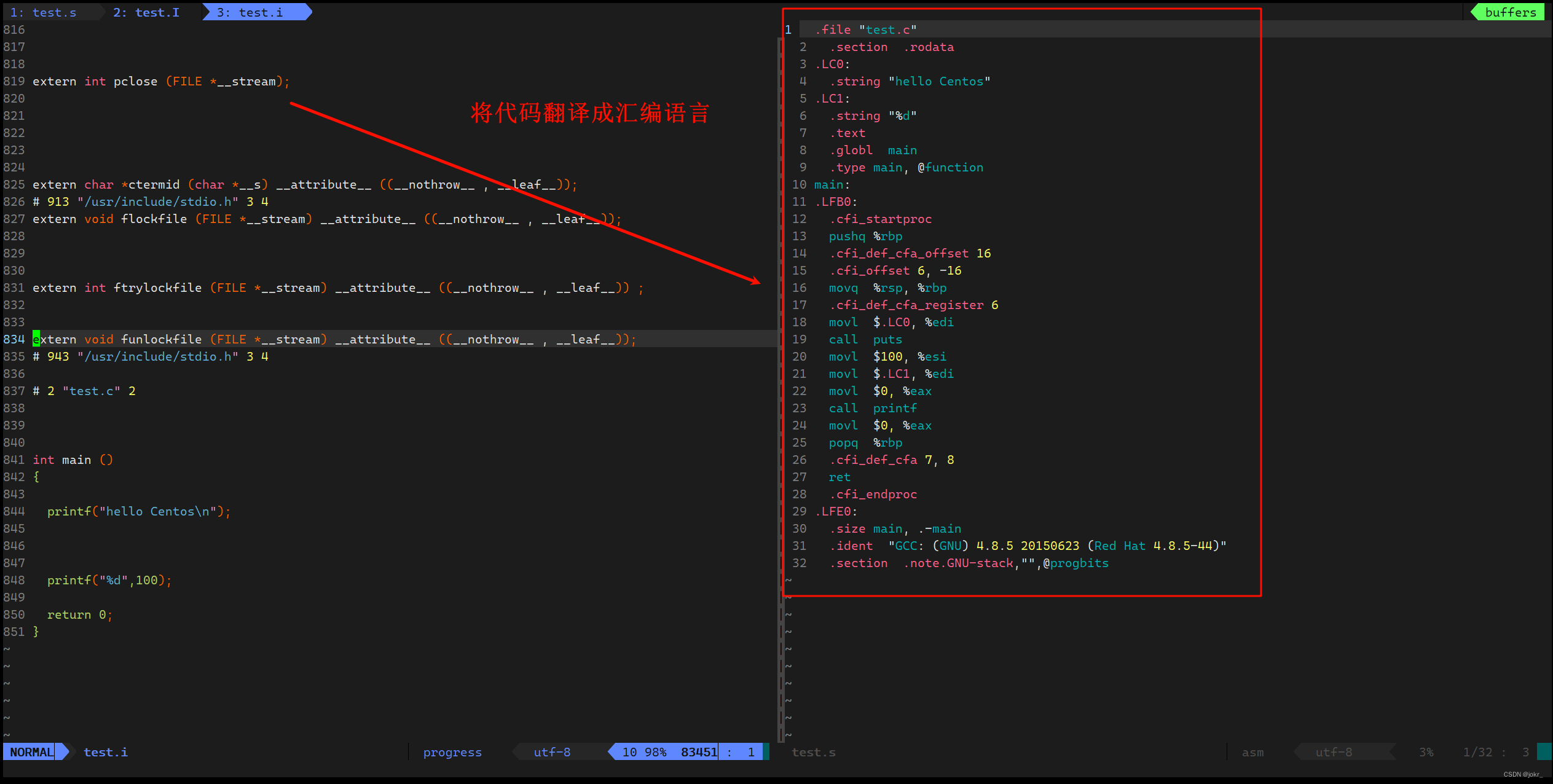
汇编
[qq@iZ0jl65jmm6w9evbwz2zuoZ ~]$ gcc -c test.s -o test.o
- 汇编阶段是把编译阶段生成的“xxx.s”文件转成目标文件。
- 使用-c选项就可以得到汇编代码转化为“xxx.o”的二进制目标代码了。
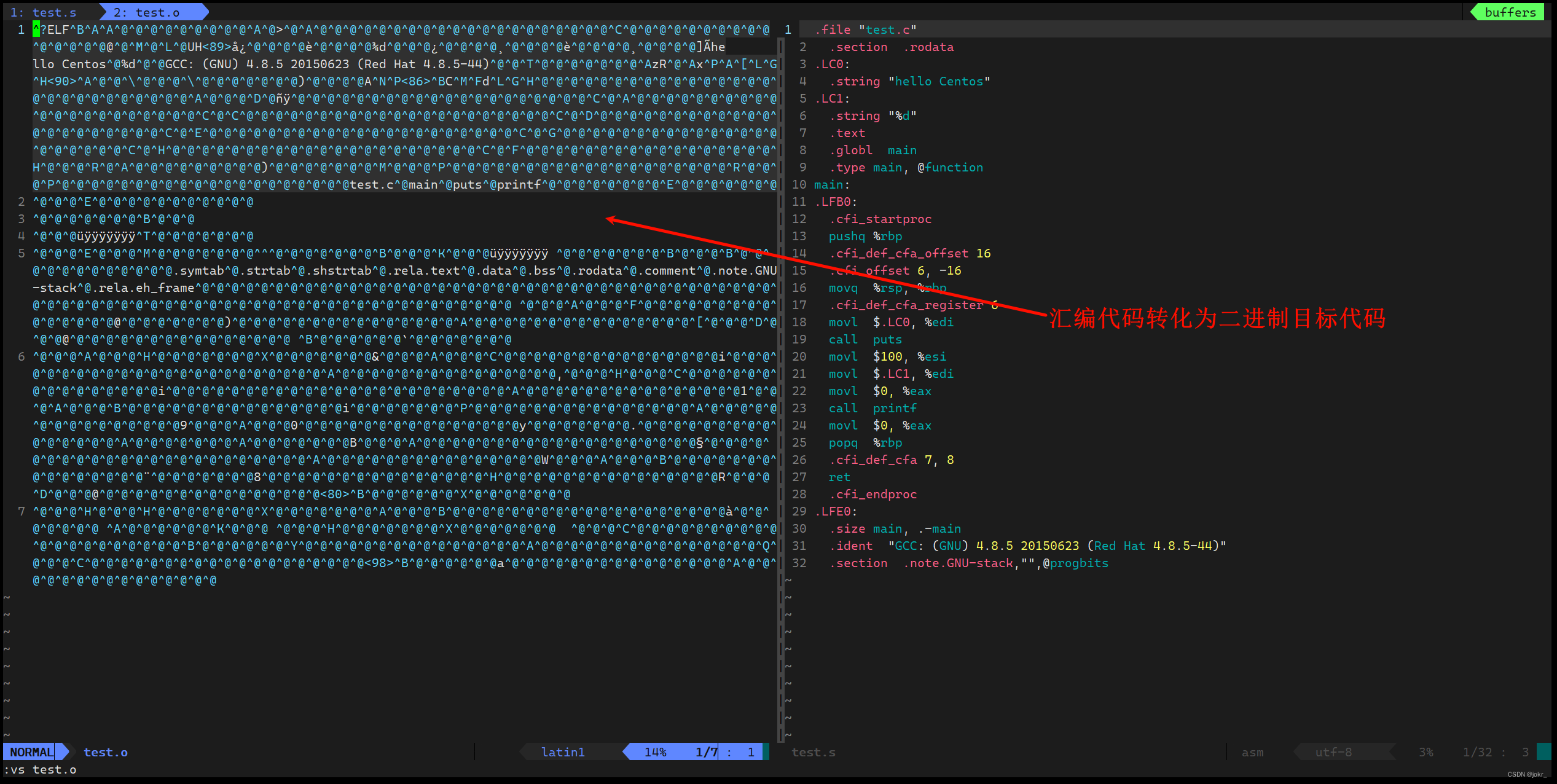
链接
[qq@iZ0jl65jmm6w9evbwz2zuoZ ~]$ gcc test.o -o test
- 在成功完成以上步骤之后,就进入了链接阶段。
- 链接的主要任务就是将生成的各个“xxx.o”文件进行链接,生成可执行文件。
- gcc/g++不带-E、-S、-c选项时,就默认生成预处理、编译、汇编、链接全过程后的文件。
- 若不用-o选项指定生成文件的文件名,则默认生成的可执行文件名为a.out。
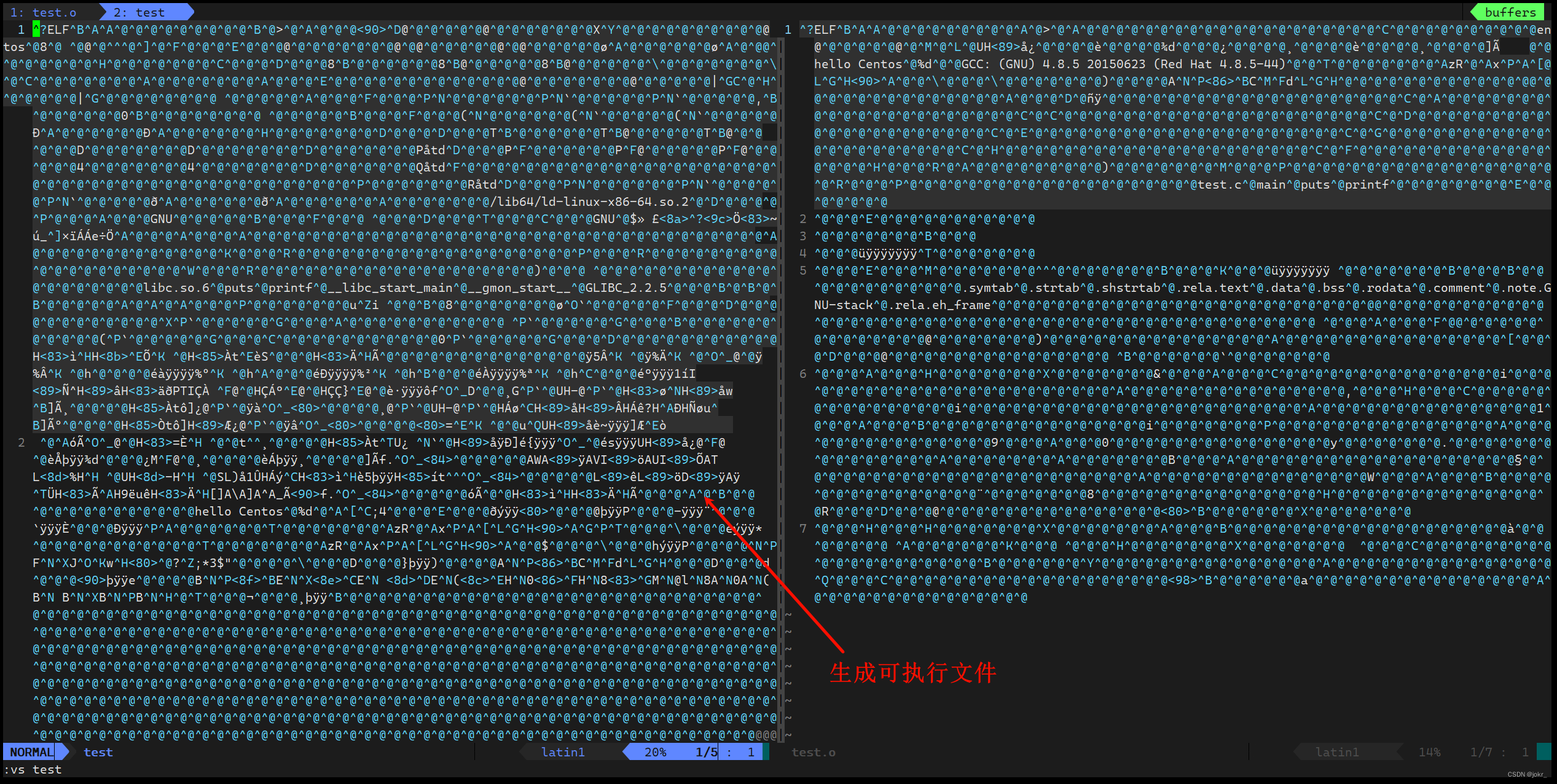
注意: 链接后生成的也是二进制文件。
静态库与动态库
函数库一般分为静态库和动态库两种:
静态库是指编译链接时,把库文件的代码全部加入到可执行文件当中,因此生成的文件比较大,但在运行时也就不再需要库文件了,静态库一般以.a为后缀。
动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件当中,而是在程序运行时由链接文件加载库,这样可以节省系统的开销,动态库一般以.so为后缀。
动态链接:
优点:省空间(磁盘的空间,内存的空间),bin体积小,加载速度快。
缺点:依赖动态库,程序可移植性较差。
静态链接:
优点:不依赖第三方库,程序的可移植性较高。
缺点:浪费空间。

其次,我们还可以使用ldd指令查看动态链接的可执行文件所依赖的库。

(图中的/lib64/libc.so.6就是当前云服务器当中的C标准库)。
虽然gcc和g++默认采用的是动态链接,但如果我们需要使用静态链接,带上-static选项即可。
[qq@iZ0jl65jmm6w9evbwz2zuoZ ~]$ gcc test.c -o test_s -static
此时生成的可执行文件就是静态链接的了。

我们可以查看源代码相同,但链接方式不同而生成的两个可执行程序test和test_s的大小。
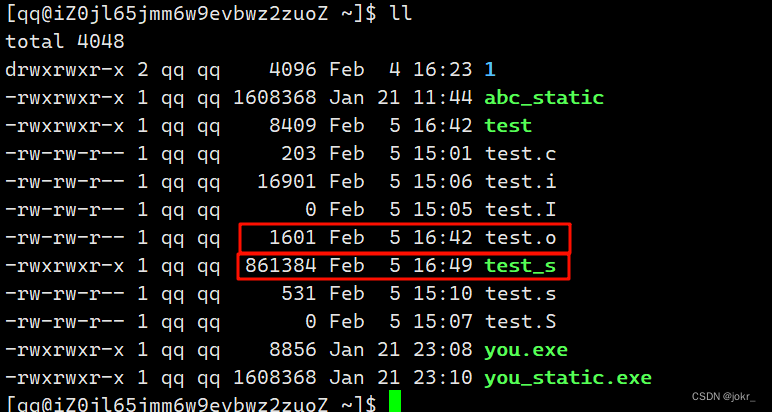
这也证明了动态链接比较节省空间,而静态链接比较浪费空间
Linux调试器- gdb
gdb使用须知
程序发布方式:
1、debug版本:程序本身会被加入更多的调试信息,以便于进行调试。
2、release版本:不会添加任何调试信息,是不可调试的。
在Linux当中gcc/g++默认生成的可执行程序是release版本的,是不可被调试的。如果想生成debug版本,就需要在使用gcc/g++生成可执行程序时加上-g选项。

对同一份源代码分别生成其release版本和debug版本的可执行程序,并通过ll指令可以看到,debug版本发布的可执行程序的大小比release版本发布的可执行程序的大小要大一点,其原因就是以debug版本发布的可执行程序当中包含了更多的调试信息。
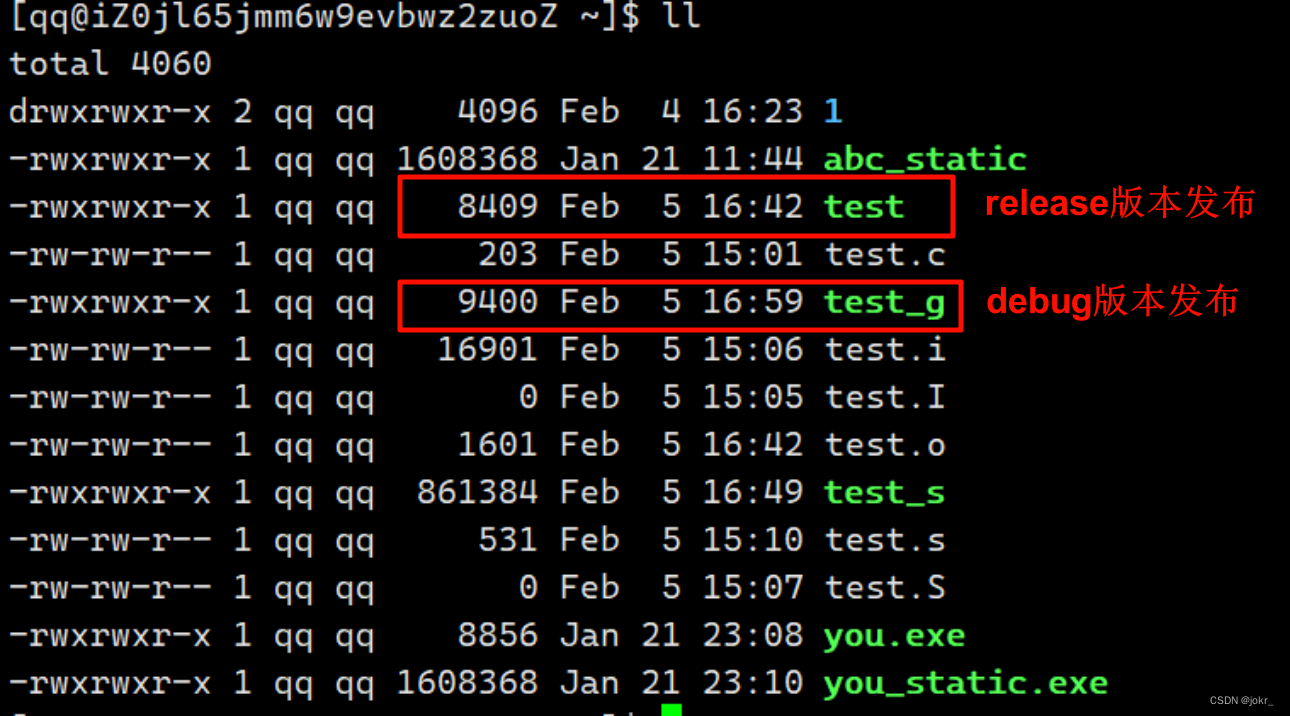
gdb命令汇总
【进入gdb】
指令: gdb 文件名
【调试】
1)「run/r」:运行代码(启动调试)。
2)「next/n」:逐过程调试。
3)「step/s」:逐语句调试。
4)「until 行号」:跳转至指定行。
5)「finish」:执行完当前正在调用的函数后停下来(不能是主函数)。
6)「continue/c」:运行到下一个断点处。
7)「set var 变量=x」:修改变量的值为x。
【显示】
1)「list/l n」:显示从第n行开始的源代码,每次显示10行,若n未给出则默认从上次的位置往下显示.。
2)「list/l 函数名」:显示该函数的源代码。
3)「print/p 变量」:打印变量的值。
4)「print/p &变量」:打印变量的地址。
5)「print/p 表达式」:打印表达式的值,通过表达式可以修改变量的值。
6)「display 变量」:将变量加入常显示(每次停下来都显示它的值)。
7)「display &变量」:将变量的地址加入常显示。
8)「undisplay 编号」:取消指定编号变量的常显示。
9)「bt」:查看各级函数调用及参数。
10)「info/i locals」:查看当前栈帧当中局部变量的值。
【断点】
1)「break/b n」:在第n行设置断点。
2)「break/b 函数名」:在某函数体内第一行设置断点。
3)「info breakpoint/b」:查看已打断点信息。
4)「delete/d 编号」:删除指定编号的断点。
5)「disable 编号」:禁用指定编号的断点。
6)「enable 编号」:启用指定编号的断点。
【退出gdb】
1)「quit/q」:退出gdb。
Linux项目自动化构建工具-make/Makefile
make/Makefile的重要性
- 会不会写Makefile,从侧面说明了一个人是否具备完成大型工程的能力。
- 一个工程的源文件不计其数,按照其类型、功能、模块分别放在若干个目录当中,Makefile定义了一系列的规则来指定:哪些文件需要先编译,哪些文件需要后编译,甚至于进行更复杂的功能操作。
- Makefile带来的好处就是“自动化编译”,一旦写好,只需一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
- mak是一个命令工具,是一个解释Makefile当中指令的命令工具,一般来说,大多数的IDE都有这个命令,例如:Delphi的make,Visual
C++的nmake,Linux下GNU的make。可见,Makefile都成为了一种在工程方面的编译方法。 - make是一条命令,Makefile是一个文件,两个搭配使用,完成项目自动化构建。
依赖关系和依赖方法
在使用make/Makefile前我们首先应该理解各个文件之间的依赖关系以及它们之间的依赖方法。
依赖关系: 文件A的变更会影响到文件B,那么就称文件B依赖于文件A。
- 例如,test.o文件是由test.c文件通过预处理、编译以及汇编之后生成的文件,所以test.c文件的改变会影响test.o,所以说test.o文件依赖于test.c文件。
依赖方法: 如果文件B依赖于文件A,那么通过文件A得到文件B的方法,就是文件B依赖于文件A的依赖方法。
- 例如,test.o依赖于test.c,而test.c通过gcc -c test.c -o
test.o指令就可以得到test.o,那么test.o依赖于test.c的依赖方法就是gcc -c test.c -o test.o。
多文件编译
当你的工程当中有多个源文件的时候,应该如何进行编译生成可执行程序呢?

首先,我们可以直接使用gcc指令对多个源文件进行编译,进而生成可执行程序。
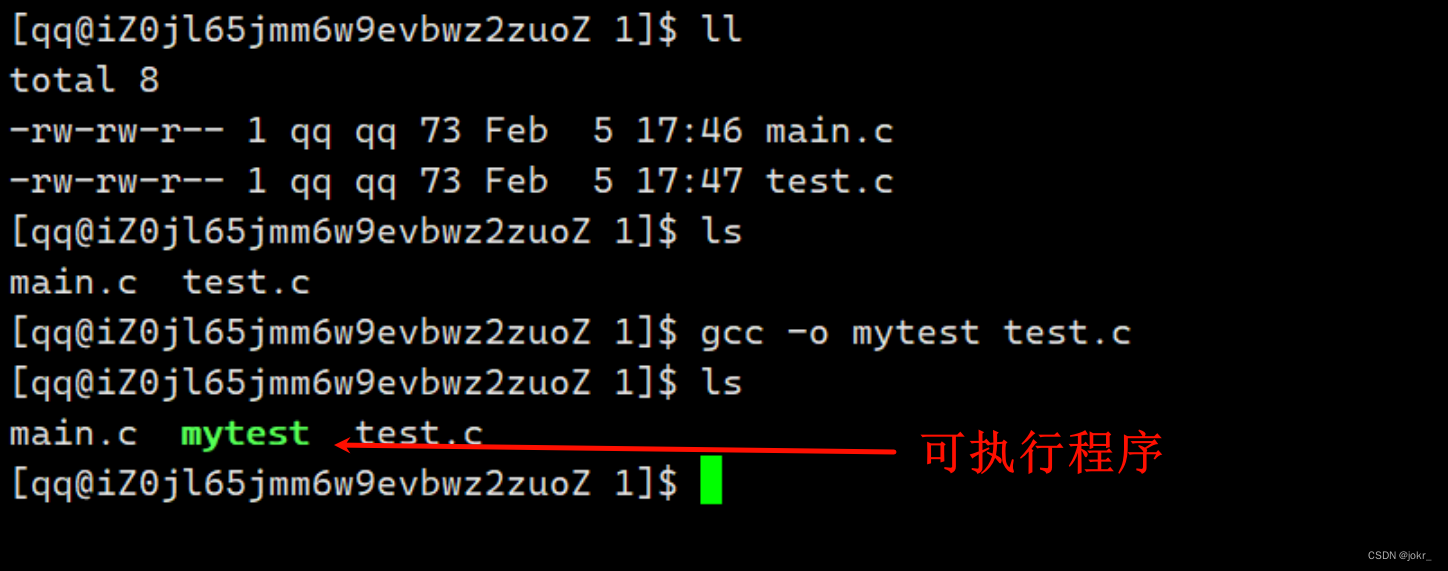
但进行多文件编译的时候一般不使用源文件直接生成可执行程序,而是先用每个源文件各自生成自己的二进制文件,然后再将这些二进制文件通过链接生成可执行程序。

原因:
- 若是直接使用源文件生成可执行程序,那么其中一个源文件进行了修改,再生成可执行程序的时候就需要将所以的源文件重新进行编译链接。
- 而若是先用每个源文件各自生成自己的二进制文件,那么其中一个源文件进行了修改,就只需重新编译生成该源文件的二进制文件,然后再将这些二进制文件通过链接生成可执行程序即可。
注意: 编译链接的时候不需要加上头文件,因为编译器通过源文件的内容可以知道所需的头文件名字,而通过头文件的包含方式(“尖括号”包含和“双引号”包含),编译器可以知道应该从何处去寻找所需头文件。
但是随着源文件个数的增加,我们每次重新生成可执行程序时,所需输入的gcc指令的长度与个数也会随之增加。这时我们就需要使用make和Makefile了,这将大大减少我们的工作量。
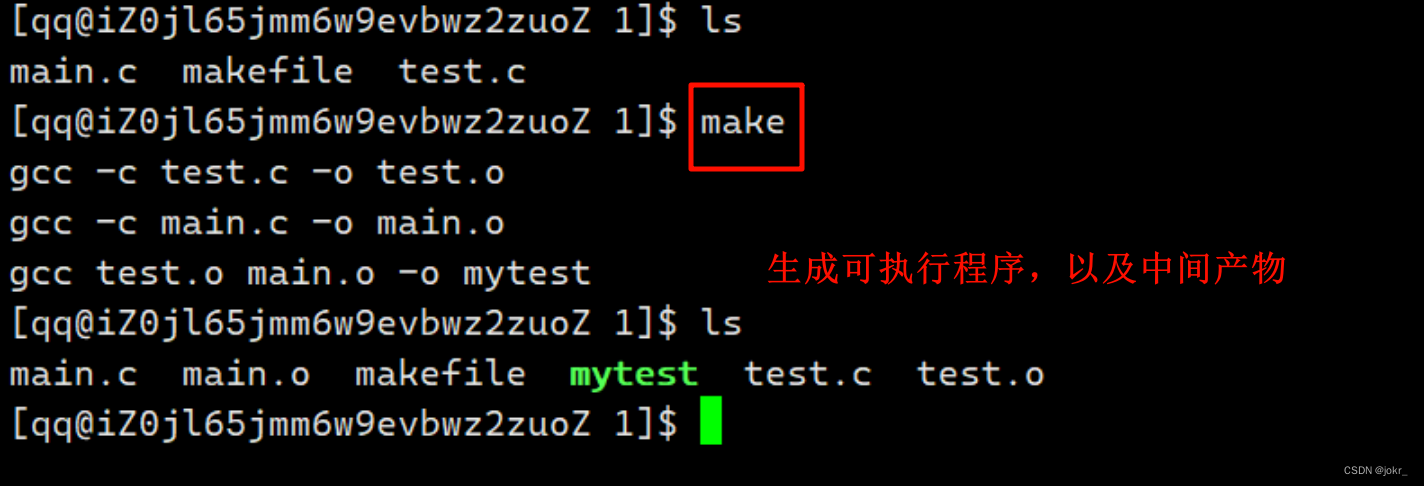
步骤一: 在源文件所在目录下创建一个名为Makefile/makefile的文件。

步骤二: 编写Makefile文件。
Makefile文件最简单的编写格式是,先写出文件的依赖关系,然后写出这些文件之间的依赖方法,建议从下往上写。

编写完毕Makefile文件后保存退出,然后在命令行当中执行make指令便可以生成可执行程序,以及该过程产生的中间产物。
Makefile文件的简写方式:
- $@:表示依赖关系中的目标文件(冒号左侧)。
- $^:表示依赖关系中的依赖文件列表(冒号右侧全部)。
- $<:表示依赖关系中的第一个依赖文件(冒号右侧第一个)。
例如以上Makefile文件可以简写为:
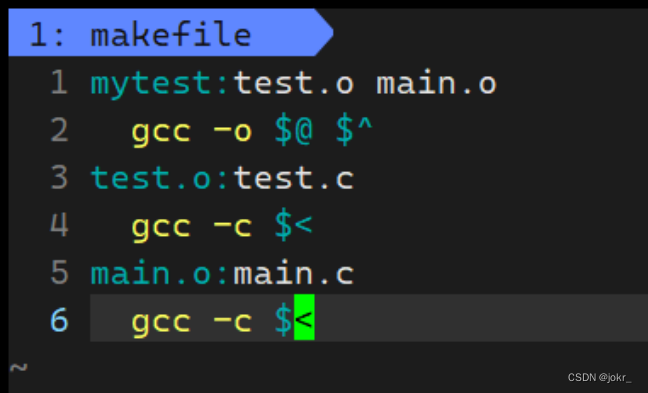
说明: gcc/g++携带-c选项时,若不指定输出文件的文件名,则默认输出文件名为xxx.o,所以这里也可以不用指定输出文件名。
make原理
- make会在当前目录下找名字为“Makefile”或“makefile”的文件。
- 如果找到,它会找文件当中的第一个目标文件,在上面的例子中,它会找到mytest这个文件,并把这个文件作为最终的目标文件。
- 如果mytest文件不存在,或是mytest所依赖的后面的test.o文件和main.o文件的文件修改时间比mytest文件新,那么它就会执行后面的依赖方法来生成mytest文件。
- 如果mytest所依赖的test.o文件不存在,那么make会在Makefile文件中寻找目标为test.o文件的依赖关系,如果找到则再根据其依赖方法生成test.o文件(类似于堆栈的过程)。
- 当然,你的test.c文件和main.c文件是存在的,于是make会生成test.o文件和main.o文件,然后再用test.o文件和main.o文件生成最终的mytest文件。
- make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
- 在寻找的过程中,如果出现错误,例如最后被依赖的文件找不到,那么make就会直接退出,并报错。
项目清理
在我们每次重新生成可执行程序前,都应该将上一次生成可执行程序时生成的一系列文件进行清理,但是如果我们每次都手动执行一系列指令进行清理工作的话,未免有些麻烦,因为每次清理时执行的都是相同的清理指令,这时我们可以将项目清理的指令也加入到Makefile文件当中。
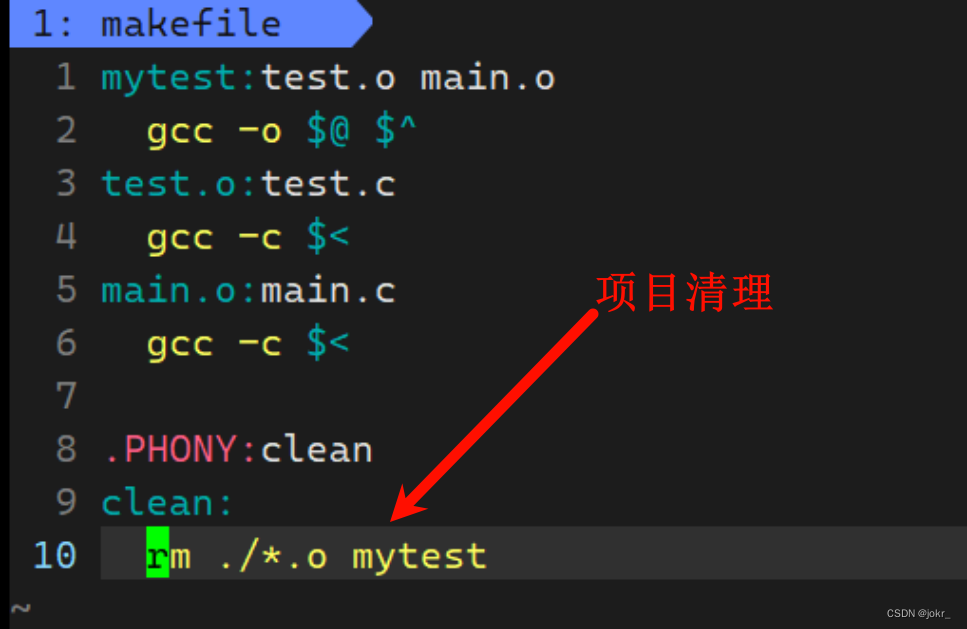
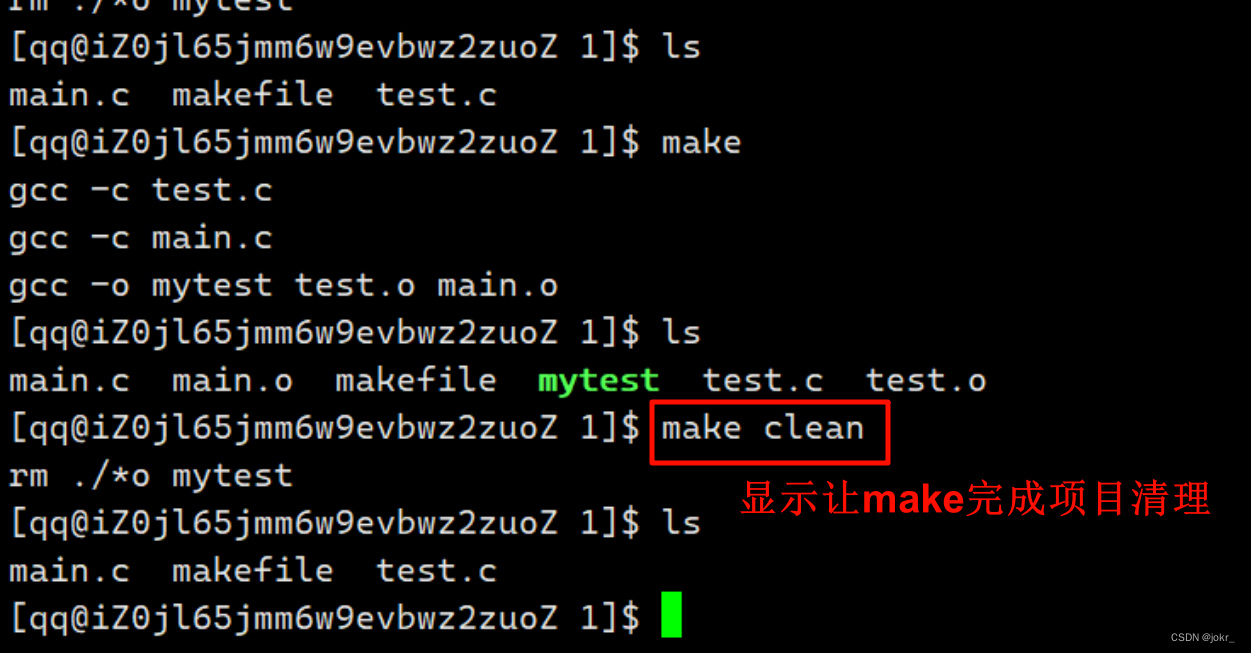
想clean这种,没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,但我们可以显示要make执行。
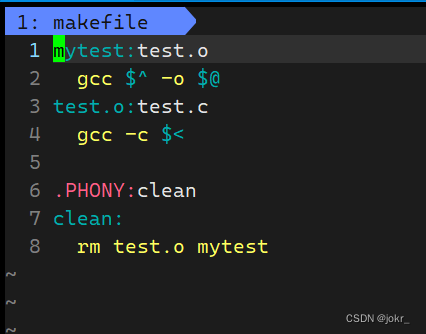
完善makefile
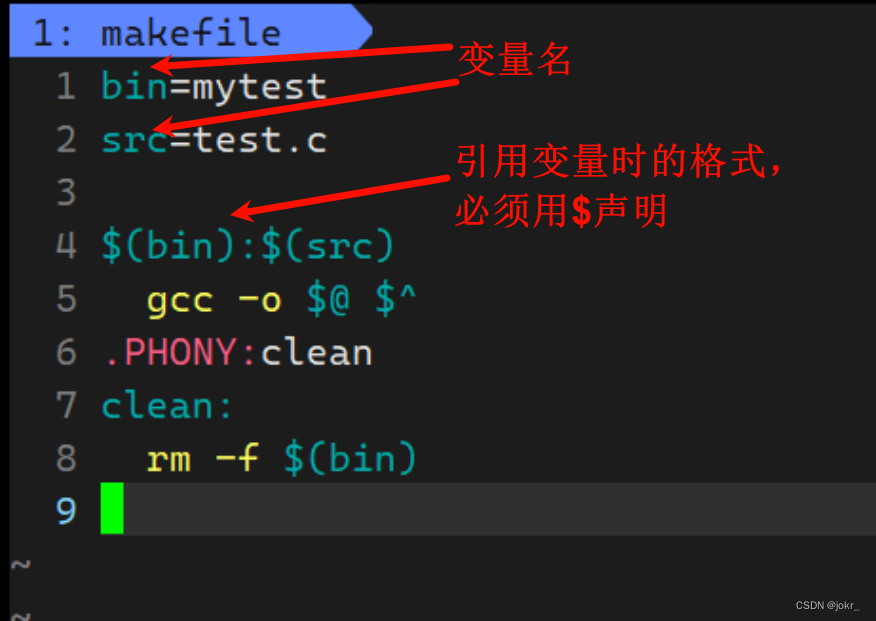
在makefile中,我们也可以使用变量来批量化编译,即定义一个宏,然后以后更换这个宏就可以让这个makefile编译不同的文件了。
格式: 变量名=变量所指文件 等号中间没有空格。
例如:
完善下面这个makefile
但是每一次我们运行依次makefile都会有下面的提示,如果想去除提示,我们可以加@:
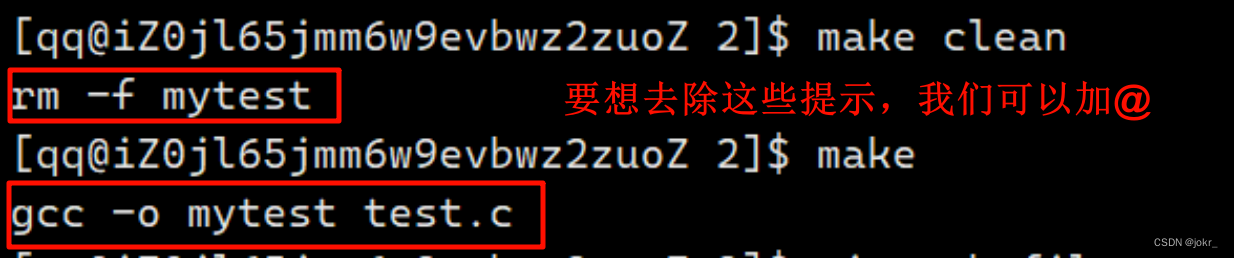
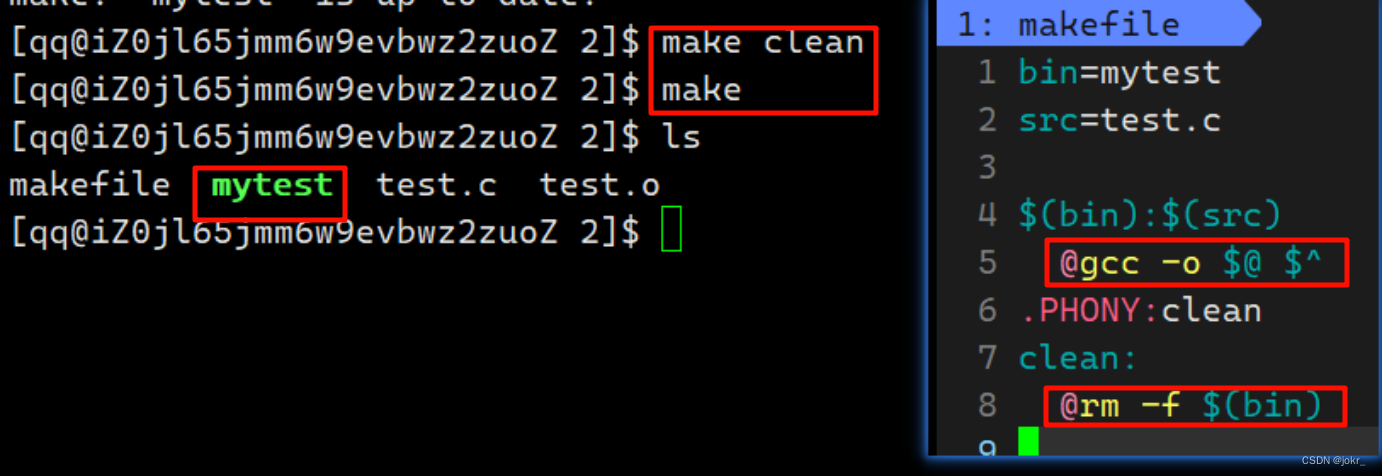
最后我们可以做一些修饰:
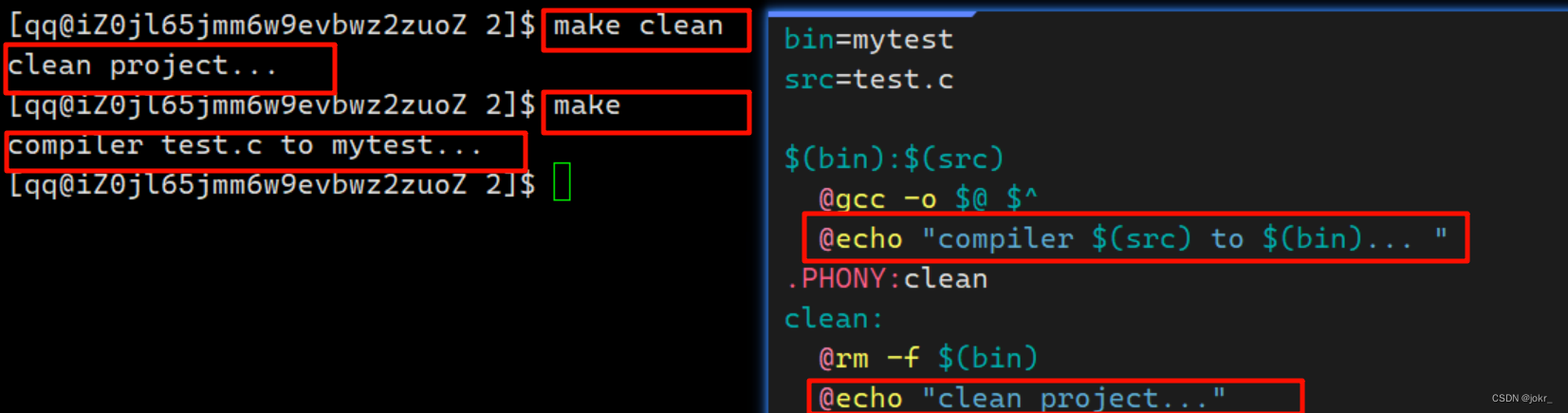
Linux第一个小程序-进度条
行缓冲区的概念
我们先来看看这个代码,这里使用了sleep函数,具体sleep的使用可以查看sleep
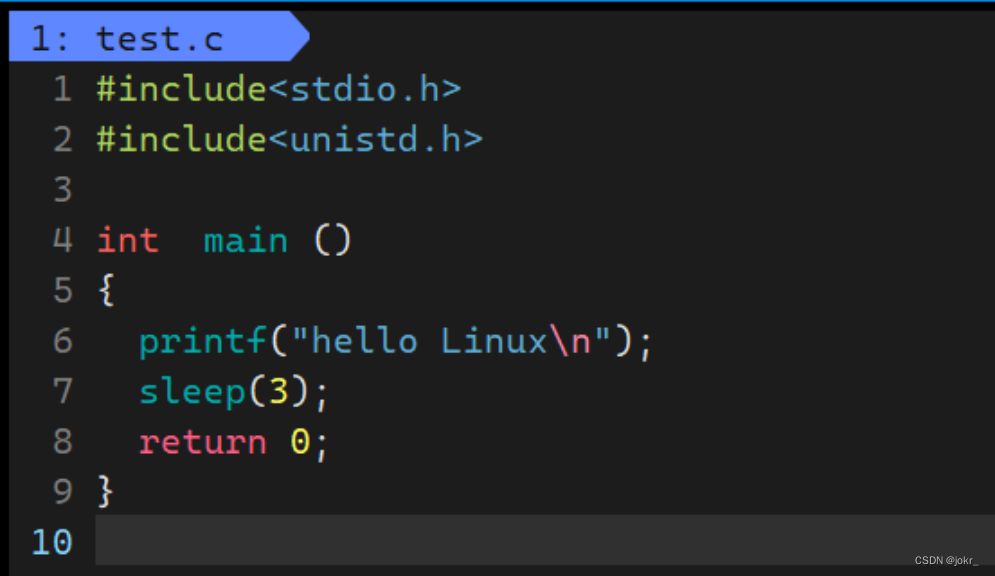
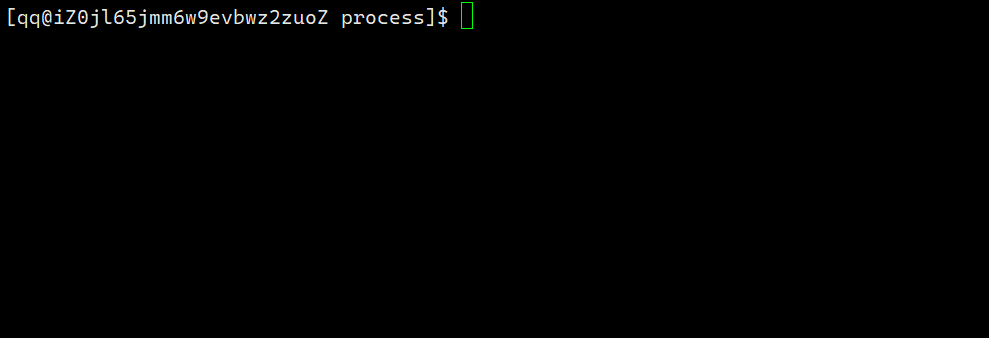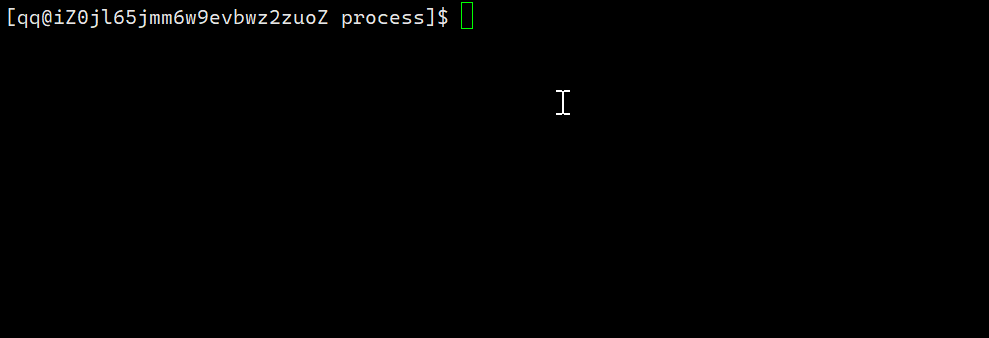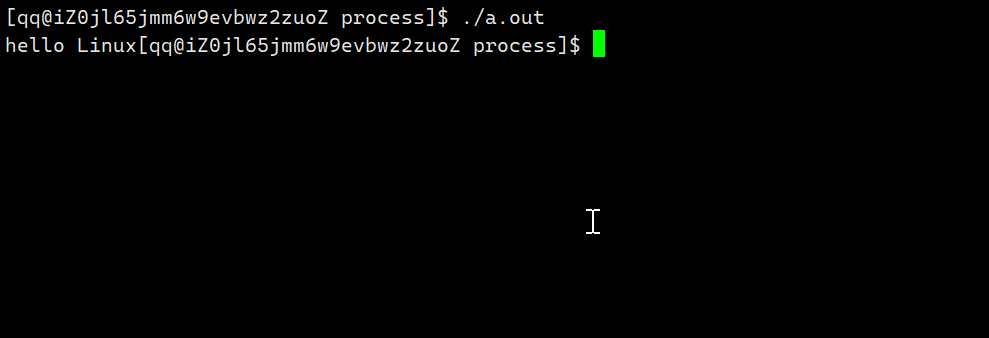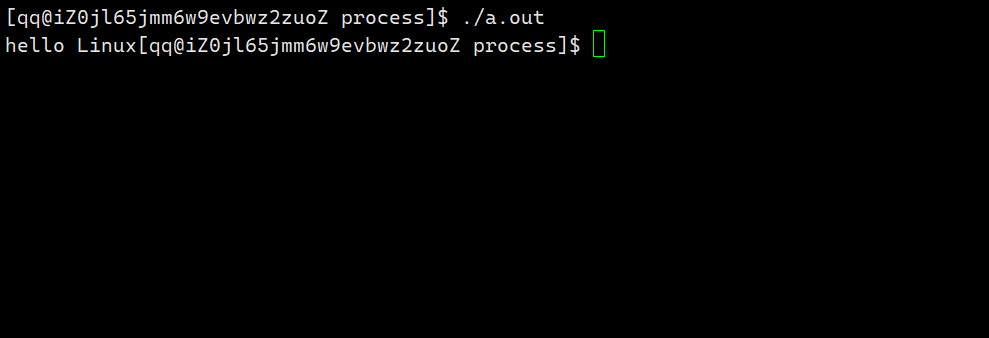
运行如下:
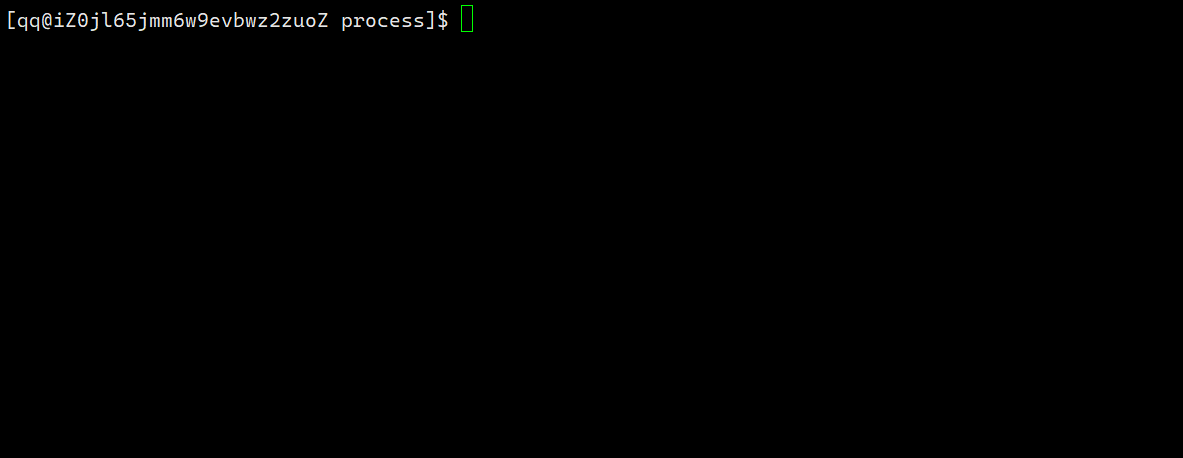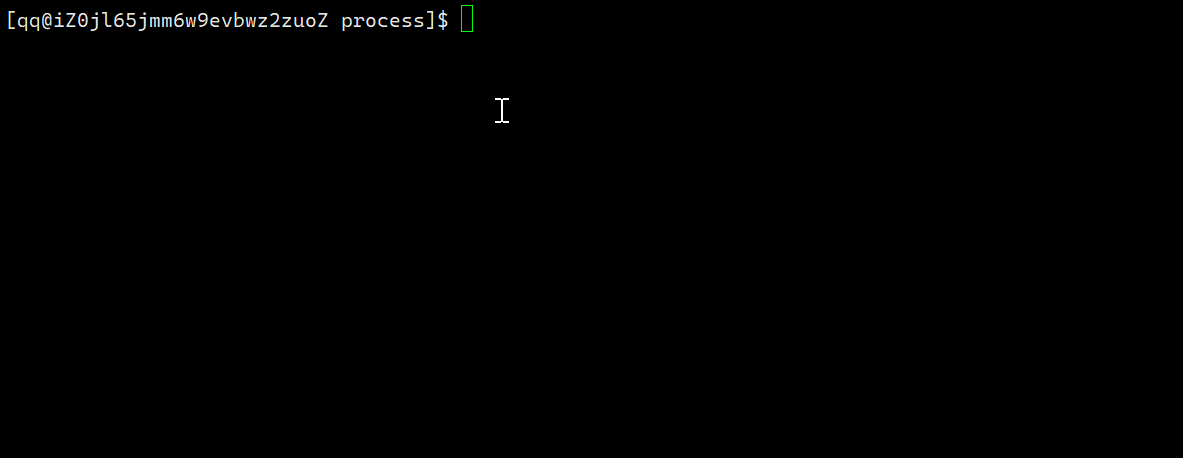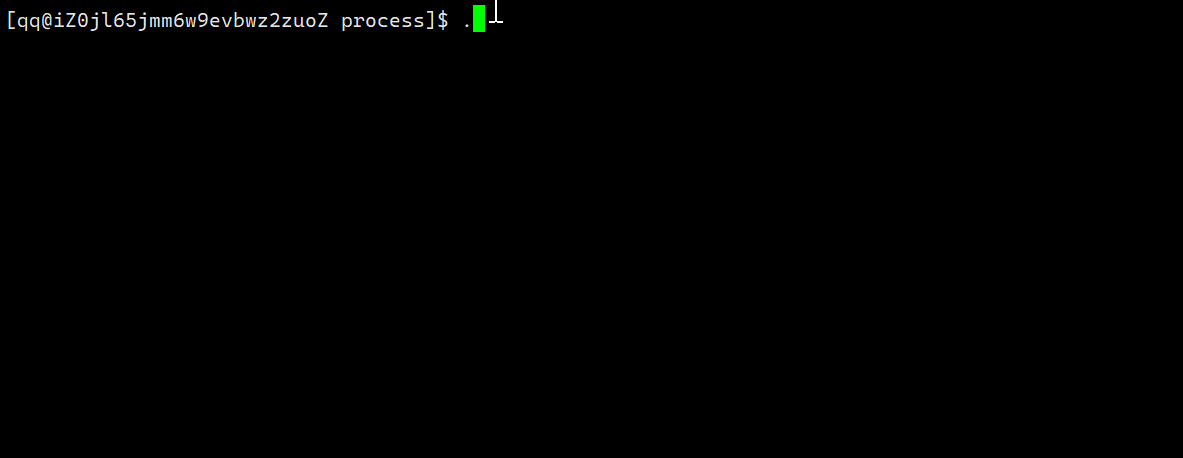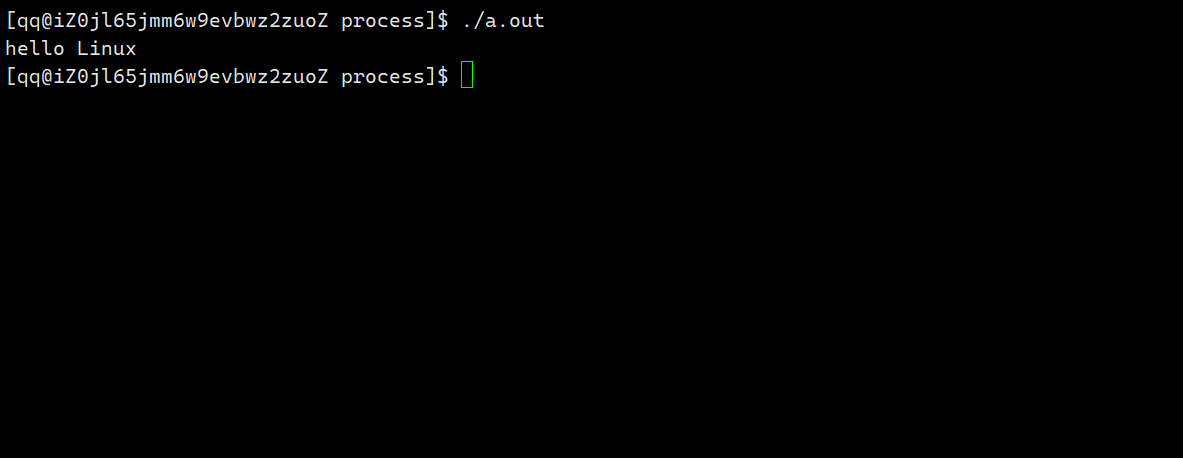
该代码先输出字符串hello world然后休眠3秒之后结束运行。那么对于以下代码呢?
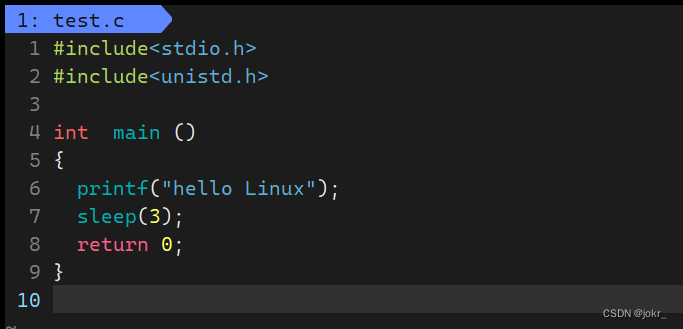
可以看到代码中仅仅删除了字符串后面的’\n’,那么代码的运行结果还与之前相同吗?答案否定的,该代码的运行结果是:先休眠3秒,然后打印字符串hello world之后结束运行。该现象就证明了行缓冲区的存在。
显示器对应的是行刷新,即当缓冲区当中遇到’\n’或是缓冲区被写满才会被打印出来,而在第二份代码当中并没有’\n’,所以字符串hello world先被写到缓冲区当中去了,然后休眠3秒后,直到程序运行结束时才将hello world打印到显示器当中。
r和n
\r: 回车,使光标回到本行行首。
\n: 换行,使光标下移一格。
而我们键盘上的Enter键实际上就等价于\n+\r。

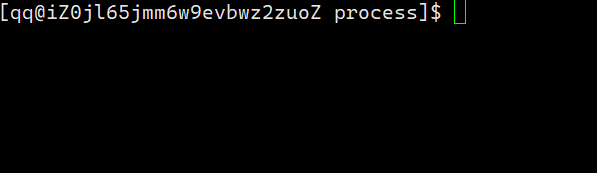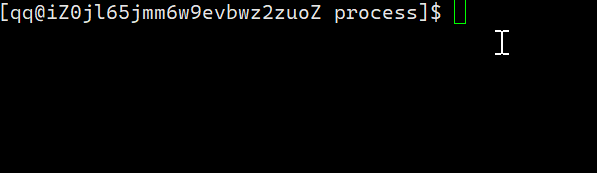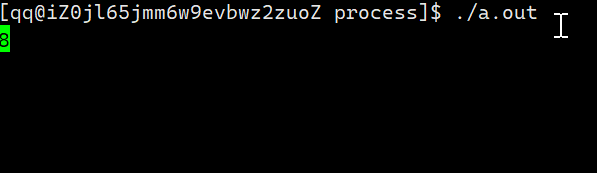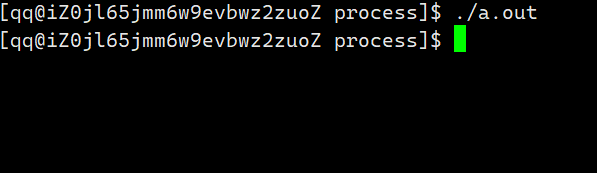
既然是\r是使光标回到本行行首,那么如果我们向显示器上写了一个数之后再让光标回到本行行首,然后再写一个数,不就相当于将前面一个数字覆盖了吗?
但这里有一个问题:不使用’\n’进行换行怎么将缓冲区当中数据打印出来?
这里我们可以使用fflush函数,该函数可以刷新缓冲区,即将缓冲区当中的数据刷新当显示器当中。
对此我们可以编写一个倒计时的程序。
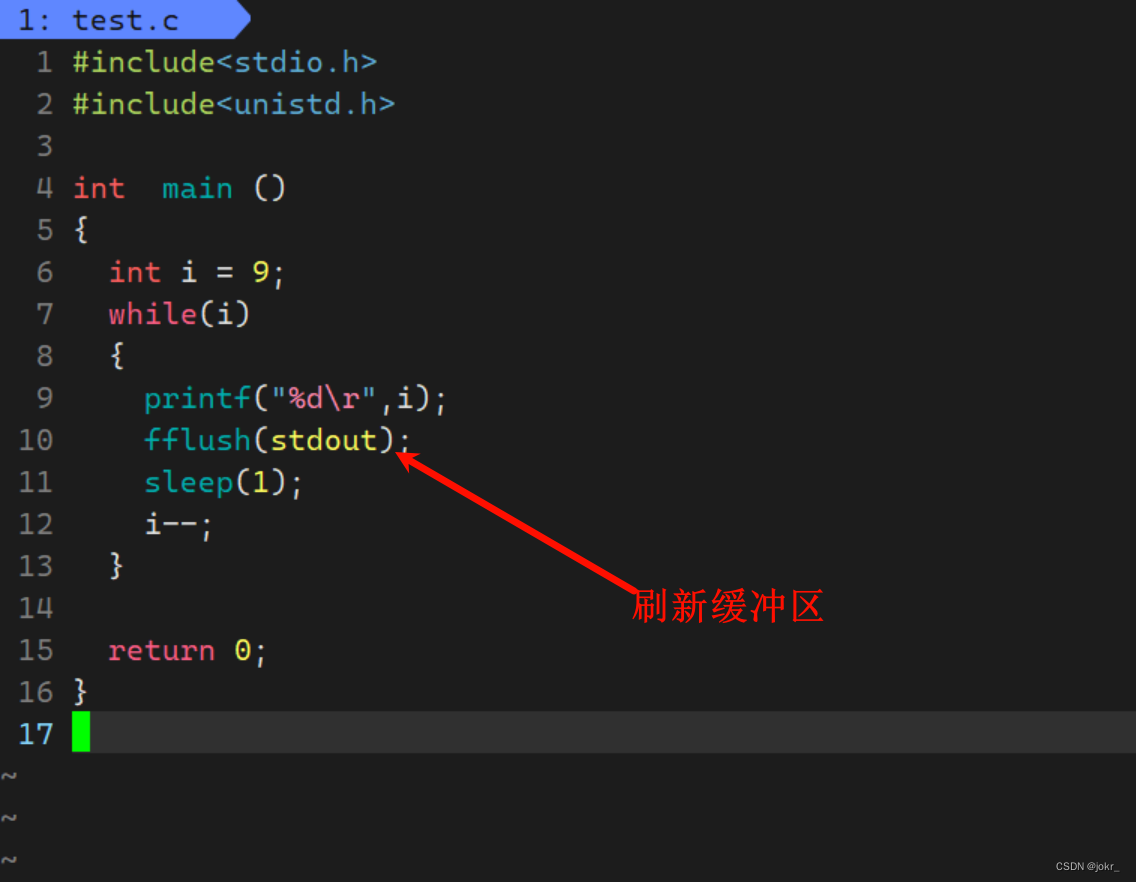
在输出下一个数之前都让光标先回到本行行首,就得到了倒计时的效果
我们来实现一个简单的进度条:
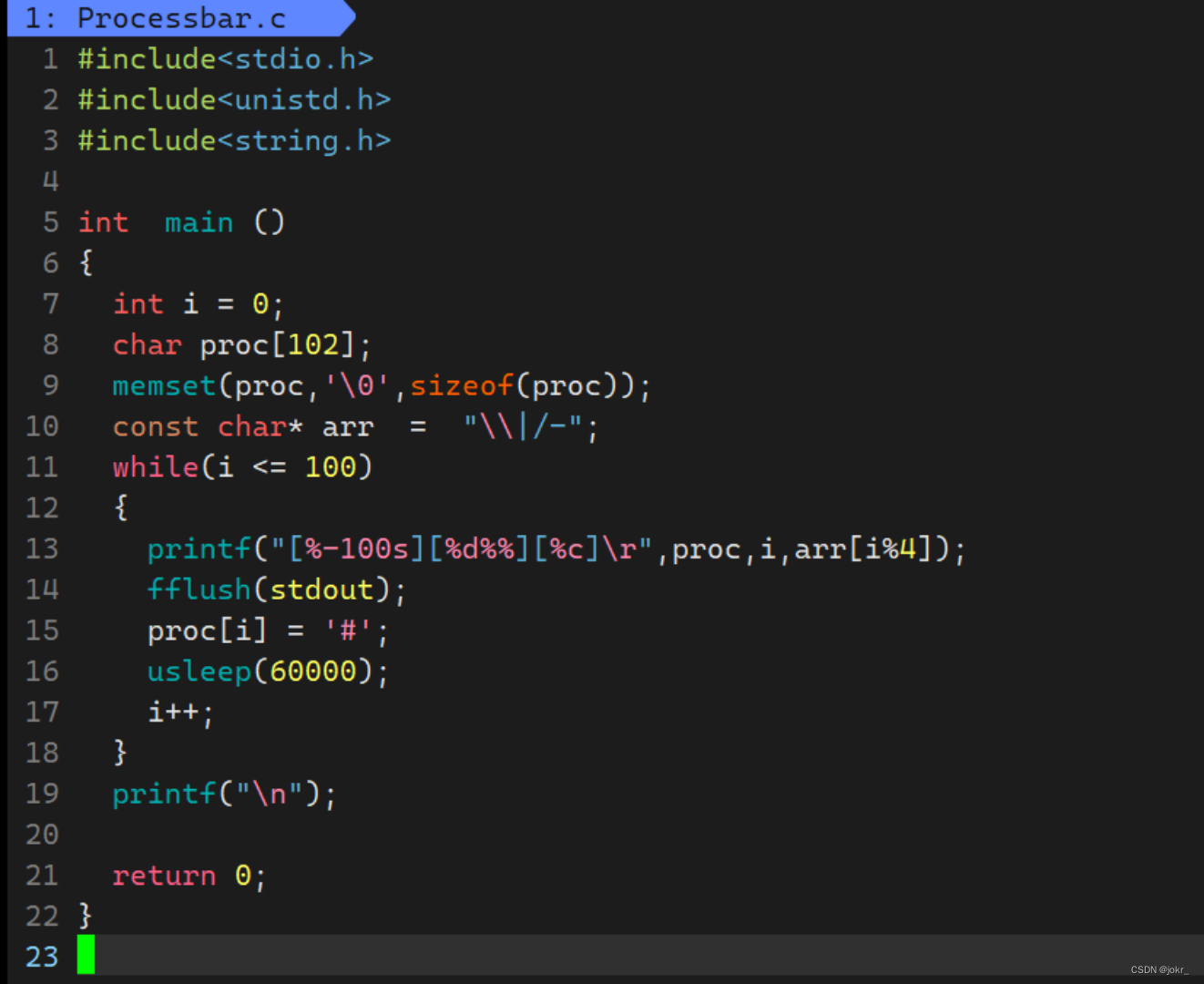
进度条代码及效果展示

相关文章:
【Linux环境基础开发工具的使用(yum、vim、gcc、g++、gdb、make/Makefile)】
Linux环境基础开发工具的使用yum、vim、gcc、g、gdb、make/Makefile Linux软件包管理器- yumLinux下安装软件的方式认识yum查找软件包安装软件如何实现本地机器和云服务器之间的文件互传卸载软件 Linux编辑器 - vimvim的基本概念vim下各模式的切换vim命令模式各命令汇总vim底行…...
幻兽帕鲁官方更新了,服务器端怎么更新?
幻兽帕鲁官方客户端更新了,那么它的服务器端版本也是需要更新的,不然版本不一致的话,就不能进入游戏了。 具体的更新方法有两种,一是手动输入命令进行更新。第二种是在面板一键更新。 无论你是在阿里云或者腾讯云购买的一键部署…...

axios-retry 响应异常
最近项目中遇到 axios 异步请求异常中断, 错误码为 “ECONNABORTED” 奇怪的是排查前端代码并没有发现有主动调用 abort 取消请求的 由于为何网络请求失败的原因找不到, 但是重试请求就是成功的, 所以计划使用 axios-retry 在网络错误时重新请求 import axiosRetry from axios…...
Vue项目创建和nodejs使用
Vue项目创建和nodejs使用 一、环境准备1.1.安装 node.js【下载历史版本node-v14.21.3-x64】1.2.安装1.3.检查是否安装成功:1.4.在Node下新建两个文件夹 node_global和node_cache并设置权限1.5.配置npm在安装全局模块时的路径和缓存cache的路径1.6.配置系统变量&…...

【机器学习案例3】从科学论文图片中提取标题、作者和摘要【含源码】
在这个项目中,我的目标是从科学论文图片中提取某些部分(标题、作者和摘要)。预期提取部分是科学论文中常见的部分,例如标题、摘要和作者。输入与最终结果。我的输入是将第一页纸转换成图像。最终结果是一个 txt 文件,其中包含标题、作者和摘要部分,如下图1和图2所示。我将…...

【开源】JAVA+Vue.js实现天然气工程运维系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 系统角色分类2.2 核心功能2.2.1 流程 12.2.2 流程 22.3 各角色功能2.3.1 系统管理员功能2.3.2 用户服务部功能2.3.3 分公司(施工单位)功能2.3.3.1 技术员角色功能2.3.3.2 材料员角色功能 2.3.4 安…...

什么是智慧隧道,如何建设智慧隧道
一、隧道管理的难点痛点 近年来隧道建设规模不断扩大,作为隧道通车里程最多、规模最大的国家,截至2022年底,我国公路隧道共有24850处、2678.43万延米,其中特长隧道1752处、795.11万延米,长隧道6715处、1172.82万延米。…...

jupyter notebook
输入jupyter notebook 停止运行就用ctrlc 全部注释先全选 ,在按ctrl/...

MongoDB聚合:$listSearchIndexes
$listSearchIndexes返回指定集合现有Atlas Search索引的信息。 **重要:**该命令只能在托管的MongoDB Allas,并且要求群集层级至少为M10。 语法 db.<collection>.aggregate([{$listSearchIndexes:{id: <indexId>,name: <indexName>}…...
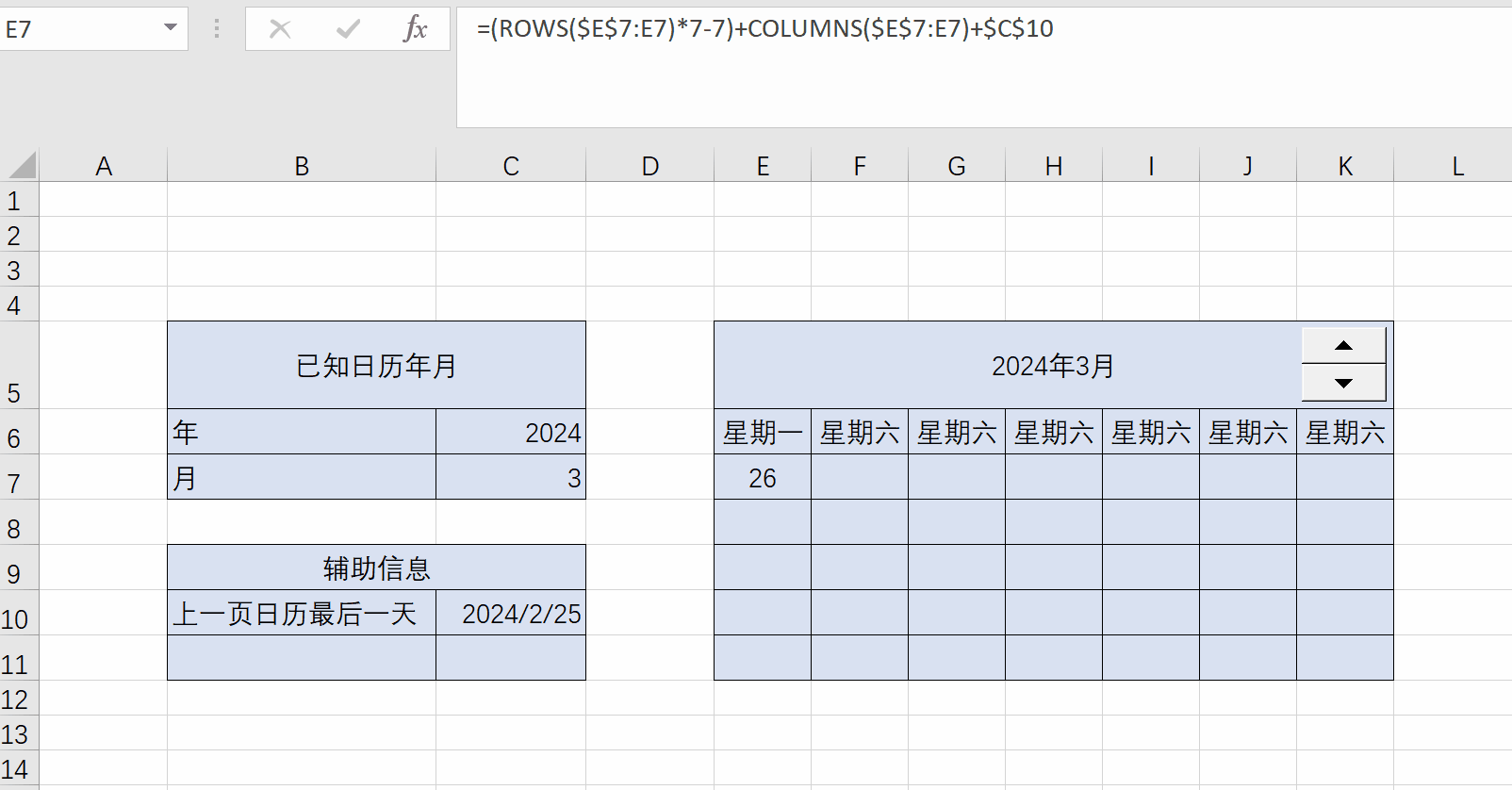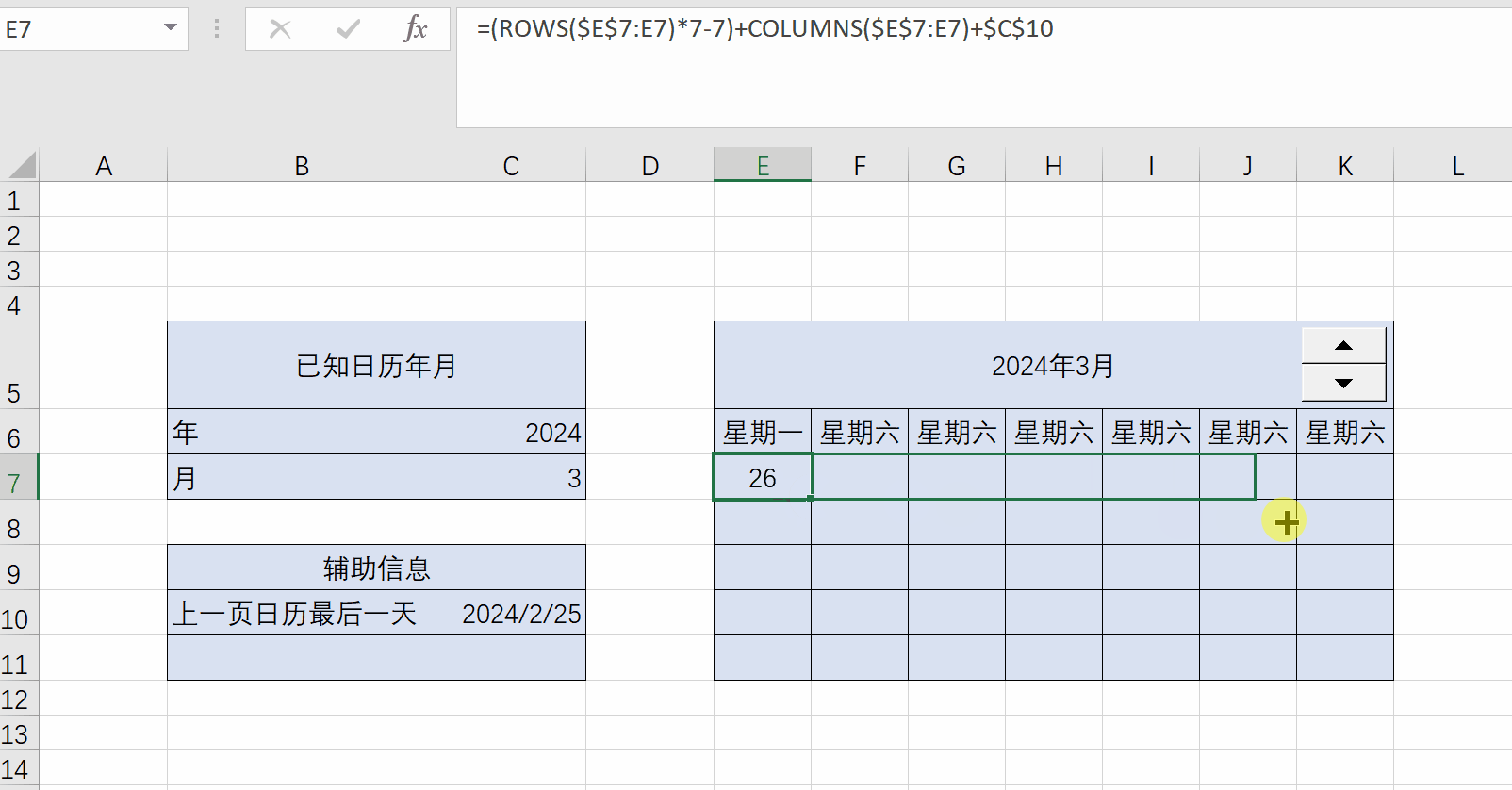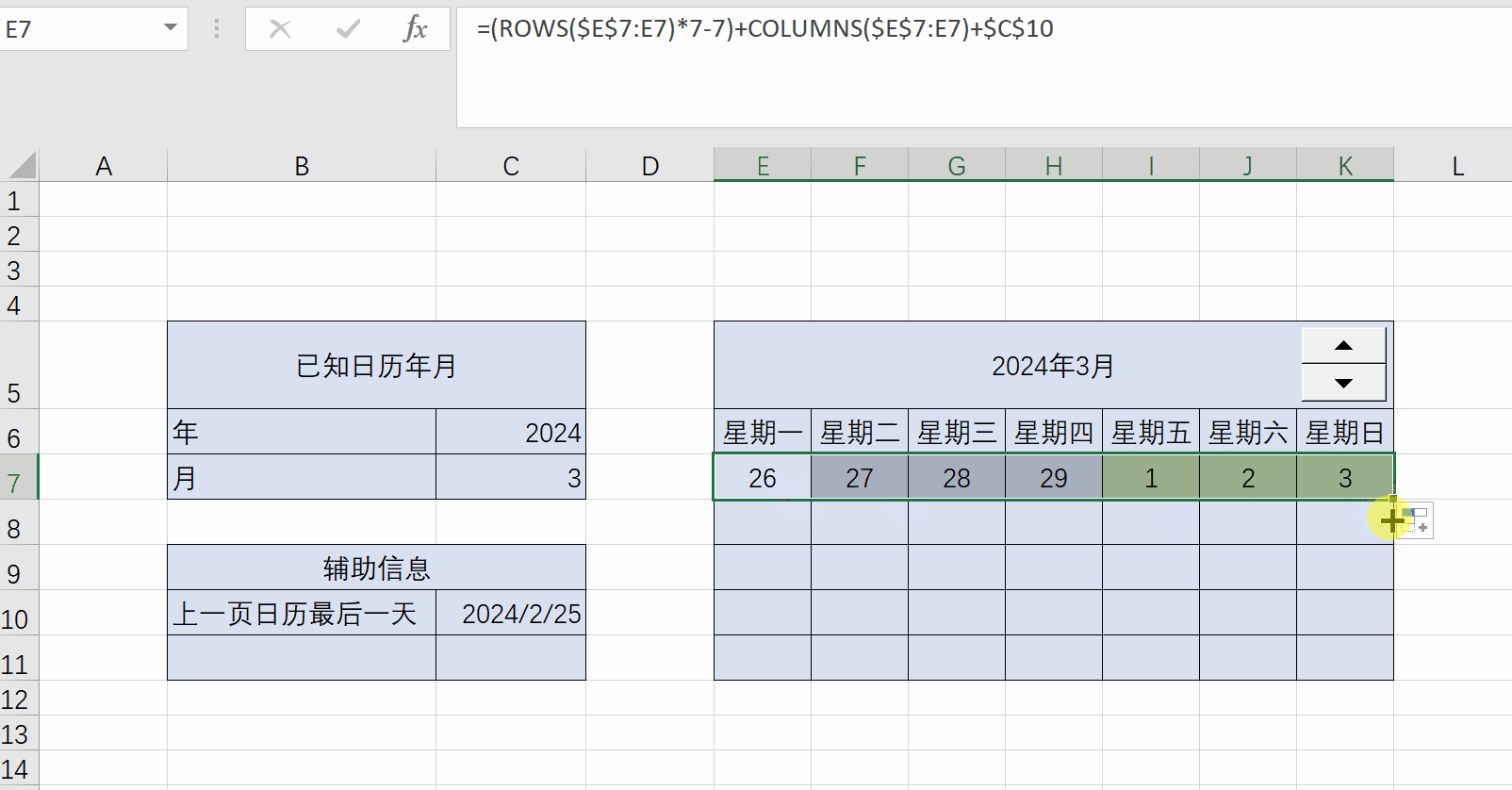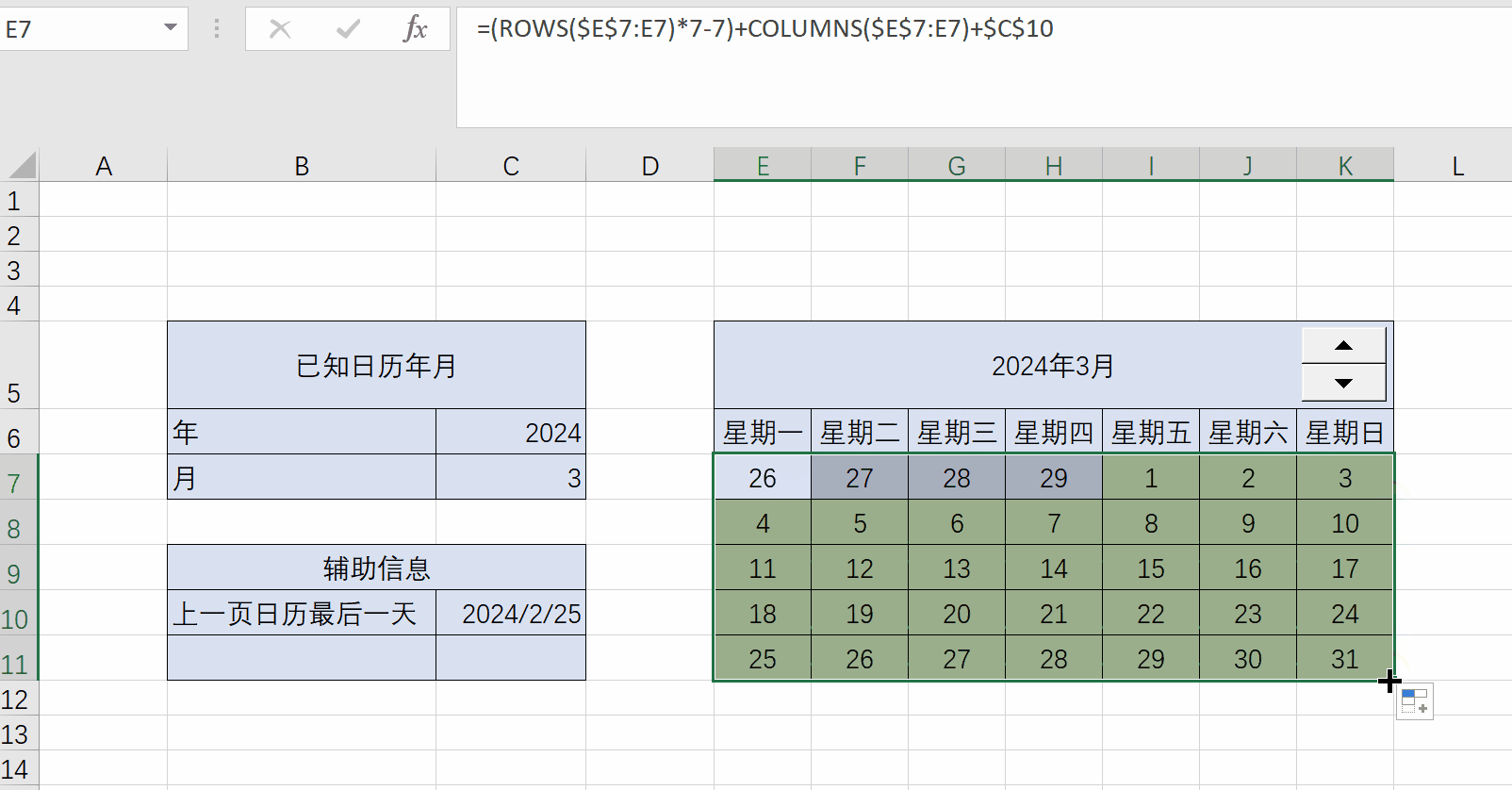
Excel练习:日历
Excel练习:日历 题目:制作日历 用rows和columns函数计算日期单元格偏移量 一个公式填充所有日期单元格 ...

【C语言】指针练习篇(上),深入理解指针---指针和数组练习题和sizeof,strlen的对比【图文讲解,详细解答】
欢迎来CILMY23的博客喔,本期系列为【C语言】指针练习篇(上),深入理解指针---指针数组练习题和sizeof,strlen的对比【图文讲解,详细解答】,图文讲解指针和数组练习题,带大家更深刻理解指针的应用…...
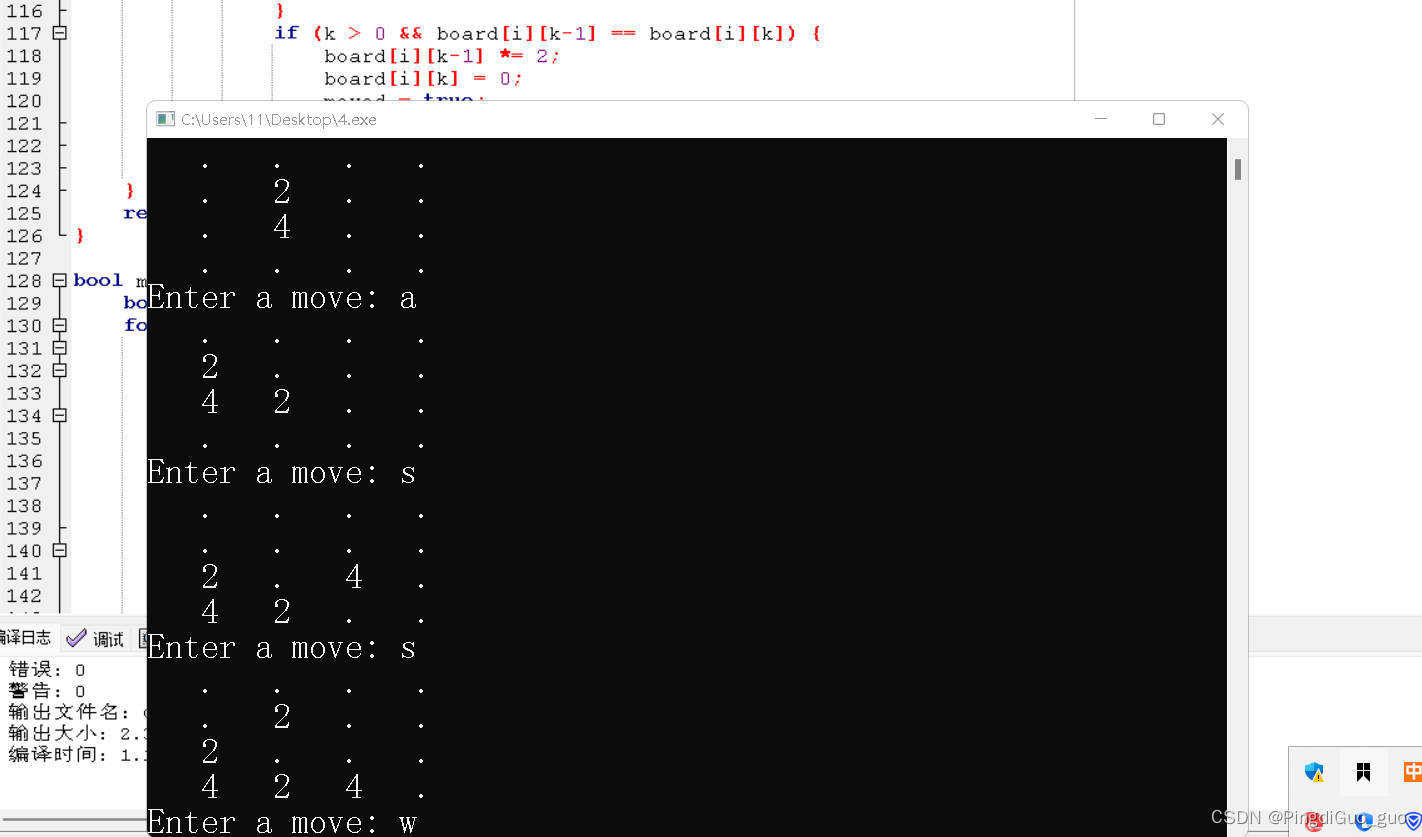
2048游戏C++板来啦!
个人主页:PingdiGuo_guo 收录专栏:C干货专栏 大家好呀,我是PingdiGuo_guo,今天我们来学习如何用C编写一个2048小游戏。 文章目录 1.2048的规则 2.步骤实现 2.1: 初始化游戏界面 2.1.1知识点 2.1.2: 创建游戏界面 2.2: 随机…...
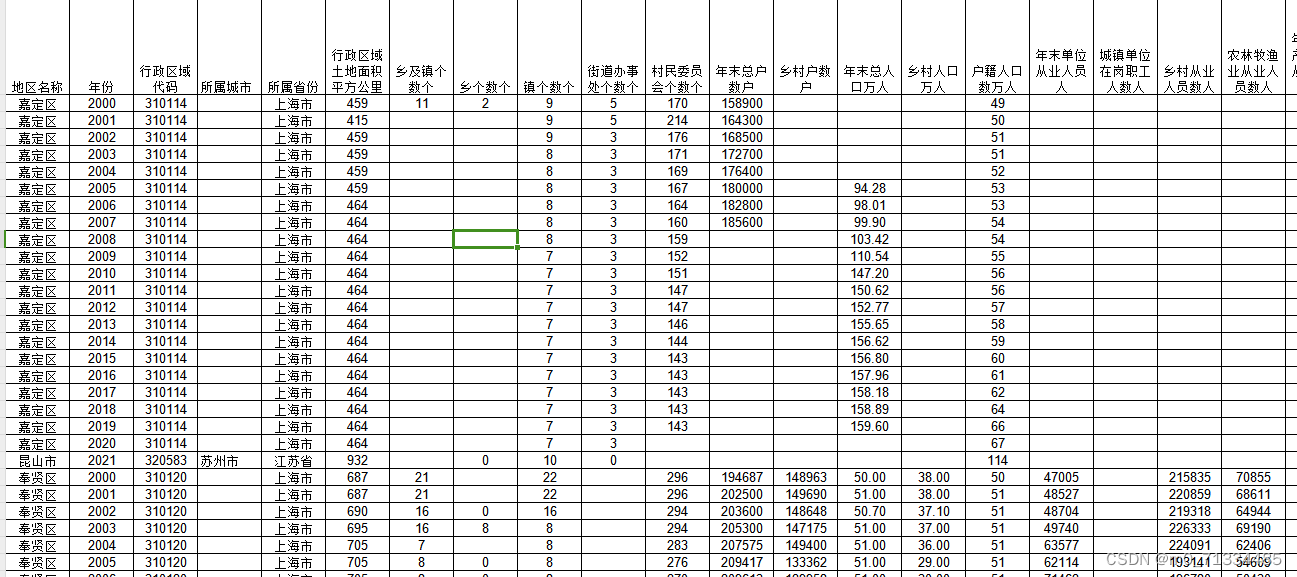
2000-2021年县域指标统计数据库
2000-2021年县域统计数据库 1、时间:2000-2021年 2、来源:县域统计年鉴 3、范围:2500县 5、指标: 地区名称、年份、行政区域代码、所属城市、所属省份、行政区域土地面积平方公里、乡及镇个数个、乡个数个、镇个数个、街道办…...

Hive on Spark配置
前提条件 1、安装好Hive,参考:Hive安装部署-CSDN博客 2、下载好Spark安装包,链接:https://pan.baidu.com/s/1plIBKPUAv79WJxBSbdPODw?pwd6666 3、将Spark安装包通过xftp上传到/opt/software 安装部署Spark 1、解压spark-3.3…...

计算机网络——11EMail
EMail 电子邮件(EMail) 3个主要组成部分 用户代理邮件服务器简单邮件传输协议:SMTP 用户代理 又名“邮件阅读器”撰写、编辑和阅读邮件输入和输出邮件保存在服务器上 邮件服务器 邮箱中管理和维护发送给用户的邮件输出报文队列保持待发…...
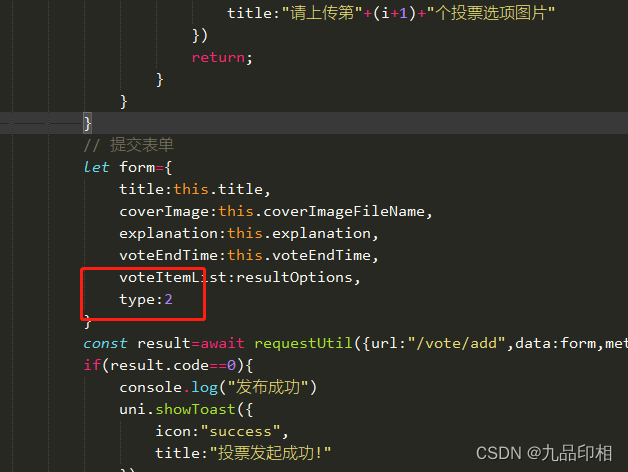
第13讲创建图文投票
创建图文投票实现 图文投票和文字投票基本一样,就是在投票选项里面,多了一个选项图片;、 <view class"option_item" v-for"(item,index) in options" :key"item.id"><view class"option_input&…...
Vulnhub靶机:DC3
一、介绍 运行环境:Virtualbox 攻击机:kali(10.0.2.15) 靶机:DC3(10.0.2.56) 目标:获取靶机root权限和flag 靶机下载地址:https://www.vulnhub.com/entry/dc-32,312…...

代码随想录算法训练营第三十一天|● 理论基础 ● 455.分发饼干 ● 376. 摆动序列 ● 53. 最大子序和
仅做学习笔记,详细请访问代码随想录 ● 理论基础 ● 455.分发饼干 ● 376. 摆动序列 ● 53. 最大子序和 ● 理论基础 有同学问了如何验证可不可以用贪心算法呢? 最好用的策略就是举反例,如果想不到反例,那么就试一试贪心吧。 …...
【光学】学习记录1-几何光学的近轴理论
课程来源:b站资源-光学-中科大-崔宏滨老师(感谢),本系列仅为自学笔记 【光学 中科大 崔宏滨老师 1080p高清修复(全集)】https://www.bilibili.com/video/BV1NG4y1C7T9?p2&vd_source7ba37b2cff2a1b783…...

【51单片机】AT24C02(江科大、爱上半导体)
一、AT24C02 1.AT24C02介绍 AT24C02是一种可以实现掉电不丢失的存储器,可用于保存单片机运行时想要永久保存的数据信息 存储介质:E2PROM 通讯接口:12C总线 容量:256字节 2.引脚即应用电路 本开发板AT24C02原理图 12C地址全接地,即全为0 WE接地,没有写使能 SCL接P21 S…...

无人机载RIS混合能量收集系统设计与优化
1. 无人机载RIS混合能量收集系统概述 在6G物联网通信场景中,无人机搭载可重构智能表面(RIS)的技术组合正在重塑无线网络架构。这种创新方案通过将RIS的被动波束赋形能力与无人机的三维机动性相结合,有效解决了传统地面基站覆盖范围有限、部署不灵活的痛点…...

给地球做CT时,那些‘捣乱’的波都是什么来头?聊聊地震勘探里的‘噪音’家族
给地球做CT时,那些‘捣乱’的波都是什么来头?聊聊地震勘探里的‘噪音’家族 想象一下医生用CT扫描人体时,如果患者不停移动或周围有手机干扰,图像就会出现模糊和伪影。地球物理学家用地震波给地球做"CT扫描"时…...

MaterialSkin终极指南:10分钟让WinForms应用焕然一新
MaterialSkin终极指南:10分钟让WinForms应用焕然一新 【免费下载链接】MaterialSkin Theming .NET WinForms, C# or VB.Net, to Googles Material Design Principles. 项目地址: https://gitcode.com/gh_mirrors/mat/MaterialSkin 你是否厌倦了传统WinForms应…...
)
保姆级教程:用PHPStudy+Nginx一键部署新麦同城V3开源版(附数据库配置避坑点)
零基础30分钟部署新麦同城V3:PHPStudyNginx全流程避坑指南 第一次接触本地部署开源系统时,最怕的不是代码复杂,而是明明按教程操作却卡在某个配置环节。本文将以真实踩坑记录为核心,手把手带你在Windows环境下用PHPStudy快速搭建…...

为内部工具集成 AI 能力时选择 Taotoken 作为中间层的考量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部工具集成 AI 能力时选择 Taotoken 作为中间层的考量 当企业计划为内部管理系统、数据分析工具等引入大模型能力时࿰…...
实战:从配置到调试,手把手教你防止程序‘饿死’)
ESP32任务看门狗(TWDT)实战:从配置到调试,手把手教你防止程序‘饿死’
ESP32任务看门狗深度实战:构建高可靠多任务系统的关键技巧 在物联网设备开发中,系统稳定性往往决定着产品的成败。想象一下这样的场景:你的智能家居网关在凌晨3点突然停止响应,或者工业传感器节点在关键时刻丢失数据——这些问题的…...
)
从LaTeX到手写笔记:希腊字母的‘两栖’书写实战指南(含清晰对比图)
从LaTeX到手写笔记:希腊字母的‘两栖’书写实战指南 在数字化与纸质化并行的学术工作流中,希腊字母的书写问题常常成为效率瓶颈。当你在深夜推导公式时,是否曾因手写θ与δ难以区分而被迫重新查阅资料?当你在整理课堂笔记时&#…...

AMD Ryzen SMU调试工具完全指南:免费开源硬件调优神器入门教程
AMD Ryzen SMU调试工具完全指南:免费开源硬件调优神器入门教程 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

如何让老旧游戏手柄重获新生:XOutput输入转换器完整指南
如何让老旧游戏手柄重获新生:XOutput输入转换器完整指南 【免费下载链接】XOutput DirectInput to XInput wrapper 项目地址: https://gitcode.com/gh_mirrors/xo/XOutput 你是否拥有一些老旧但质量优秀的游戏手柄、摇杆或方向盘,却发现在现代游戏…...

麦当劳中国启动2026全国招聘周招募新生代人才
美通社消息:麦当劳中国正式启动2026年全国招聘周。今年,首批年满16周岁的10后将步入职场,与00后共同构成新生代主力军。在AI的变革时代,麦当劳以"有保障、有福利、有发展"的薪酬福利成长体系,以及长期、系统…...