ElasticSearch分词器和相关性详解
目录
ES分词器详解
基本概念
分词发生时期
分词器的组成
切词器:Tokenizer
词项过滤器:Token Filter
停用词
同义词
字符过滤器:Character Filter
HTML 标签过滤器:HTML Strip Character Filter
字符映射过滤器:Mapping Character Filter
正则替换过滤器:Pattern Replace Character Filter
相关性详解
什么是相关性(Relevance)
相关性算法
TF-IDF
BM25
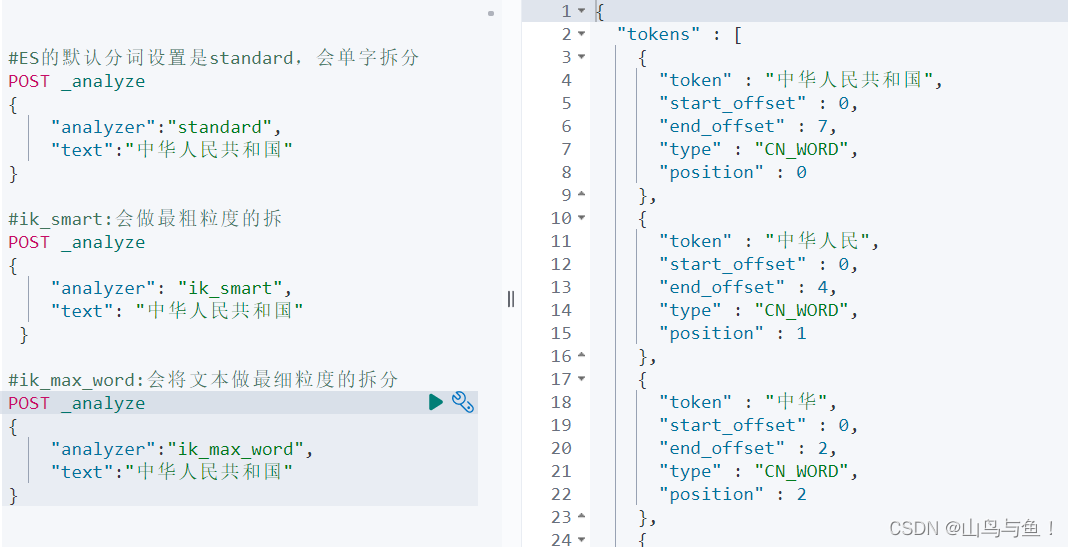
通过Explain API查看TF-IDF
Boosting Query
ES分词器详解
基本概念
分词器官方称之为文本分析器,顾名思义,是对文本进行分析处理的一种手段,基本处理逻辑为按照预先制定的分词规则,把原始文档分割成若干更小粒度的词项,粒度大小取决于分词器规则。
分词发生时期
分词器的处理过程发生在 Index Time 和 Search Time 两个时期。
Index Time:文档写入并创建倒排索引时期,其分词逻辑取决于映射参数analyzer。
Search Time:搜索发生时期,其分词仅对搜索词产生作用。
分词器的组成
切词器(Tokenizer):用于定义切词(分词)逻辑。
词项过滤器(Token Filter):用于对分词之后的单个词项的处理逻辑。
字符过滤器(Character Filter):用于处理单个字符。
注意:分词器不会对源数据造成任何影响,分词仅仅是对倒排索引或者搜索词的行为。
切词器:Tokenizer
tokenizer 是分词器的核心组成部分之一,其主要作用是分词,或称之为切词。主要用来对原始文本进行细粒度拆分。拆分之后的每一个部分称之为一个 Term,或称之为一个词项。可以把切词器理解为预定义的切词规则。官方内置了很多种切词器,默认的切词器位 standard。
词项过滤器:Token Filter
词项过滤器用来处理切词完成之后的词项,例如把大小写转换,删除停用词或同义词处理等。官方同样预置了很多词项过滤器,基本可以满足日常开发的需要。当然也是支持第三方也自行开发的。
GET _analyze{"filter" : ["lowercase"],"text" : "WWW ELASTIC ORG CN"}GET _analyze{"tokenizer" : "standard","filter" : ["uppercase"],"text" : ["www.elastic.org.cn","www elastic org cn"]}停用词
在切词完成之后,会被干掉词项,即停用词。停用词可以自定义
英文停用词(english):a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on,
or, such, that, the, their, then, there, these, they, this, to, was, will, with。
中日韩停用词(cjk):a, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, s,
such, t, that, the, their, then, there, these, they, this, to, was, will, with, www。DELETE test_token_filter_stop
PUT test_token_filter_stop
{"settings": {"analysis": {"filter": {"my_filter": {"type": "stop","stopwords": ["www"],"ignore_case": true}}}}
}
GET test_token_filter_stop/_analyze
{"tokenizer": "standard","filter": ["my_filter"],"text": ["What www WWW are you doing"]
}同义词
同义词定义规则
a, b, c => d:这种方式,a、b、c 会被 d 代替。
a, b, c, d:这种方式下,a、b、c、d 是等价的。
PUT test_token_filter_synonym
{"settings": {"analysis": {"filter": {"my_synonym": {"type": "synonym","synonyms": [ "good, nice => excellent" ] //good, nice, excellent}}}}
}
GET test_token_filter_synonym/_analyze
{"tokenizer": "standard", "filter": ["my_synonym"], "text": ["good"]
}字符过滤器:Character Filter
分词之前的预处理,过滤无用字符。
PUT <index_name>
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "<char_filter_type>"}}}}
}type:使用的字符过滤器类型名称,可配置以下值:
html_strip、mapping、pattern_replace
HTML 标签过滤器:HTML Strip Character Filter
字符过滤器会去除 HTML 标签和转义 HTML 元素,如、&
PUT test_html_strip_filter
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "html_strip", // html_strip 代表使用 HTML 标签过滤器"escaped_tags": [ // 当前仅保留 a 标签 "a"]}}}}
}
GET test_html_strip_filter/_analyze
{"tokenizer": "standard", "char_filter": ["my_char_filter"],"text": ["<p>I'm so <a>happy</a>!</p>"]
}参数:escaped_tags:需要保留的 html 标签。
字符映射过滤器:Mapping Character Filter
通过定义映替换为规则,把特定字符替换为指定字符
PUT test_html_strip_filter
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "mapping", // mapping 代表使用字符映射过滤器"mappings": [ // 数组中规定的字符会被等价替换为 => 指定的字符"滚 => *","垃 => *","圾 => *"]}}}}
}
GET test_html_strip_filter/_analyze
{//"tokenizer": "standard", "char_filter": ["my_char_filter"],"text": "你就是个垃圾!滚"
}正则替换过滤器:Pattern Replace Character Filter
PUT text_pattern_replace_filter
{"settings": {"analysis": {"char_filter": {"my_char_filter": {"type": "pattern_replace", // pattern_replace 代表使用正则替换过滤器 "pattern": """(\d{3})\d{4}(\d{4})""", // 正则表达式"replacement": "$1****$2"}}}}
}
GET text_pattern_replace_filter/_analyze
{"char_filter": ["my_char_filter"],"text": "您的手机号是18868686688"
}相关性详解
搜索是用户和搜索引擎的对话,用户关心的是搜索结果的相关性
1. 是否可以找到所有相关的内容
2. 有多少不相关的内容被返回了
3. 文档的打分是否合理
4. 结合业务需求,平衡结果排名
什么是相关性(Relevance)
搜索的相关性算分,描述了一个文档和查询语句匹配的程度。ES 会对每个匹配查询条件的结果进行算分_score。打分的本质是排序,需要把最符合用户需求的文档排在前面。
如何衡量相关性:
1. Precision(查准率)―尽可能返回较少的无关文档。
2. Recall(查全率)–尽量返回较多的相关文档。
3. Ranking -是否能够按照相关度进行排序。
相关性算法
ES5之前,默认的相关性算分采用TF-IDF,现在采用BM25。
TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。
Lucene中的TF-IDF评分公式:
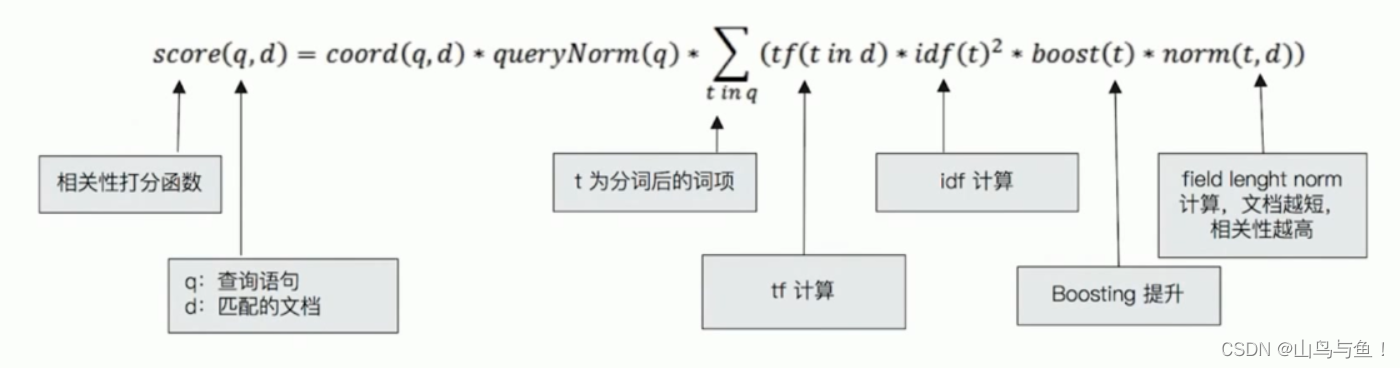
TF是词频(Term Frequency)
检索词在文档中出现的频率越高,相关性也越高。
词频(TF) = 某个词在文档中出现的次数 / 文档的总词数
IDF是逆向文本频率(Inverse Document Frequency)
每个检索词在索引中出现的频率,频率越高,相关性越低。总文档中有些词比如“是”、“的” 、“在” 在所有文档中出现频率都很高,并不重要,可以减少多个文档中都频繁出现的词的权重。
逆向文本频率(IDF)= log (语料库的文档总数 / (包含该词的文档数+1))
字段长度归一值( field-length norm)
检索词出现在一个内容短的 title 要比同样的词出现在一个内容长的 content 字段权重更大。
以上三个因素——词频(term frequency)、逆向文本频率(inverse document frequency)和字段长度归一值(field-length norm)——是在索引时计算并存储的,最后将它们结合在一起计算单个词在特定文档中的权重。
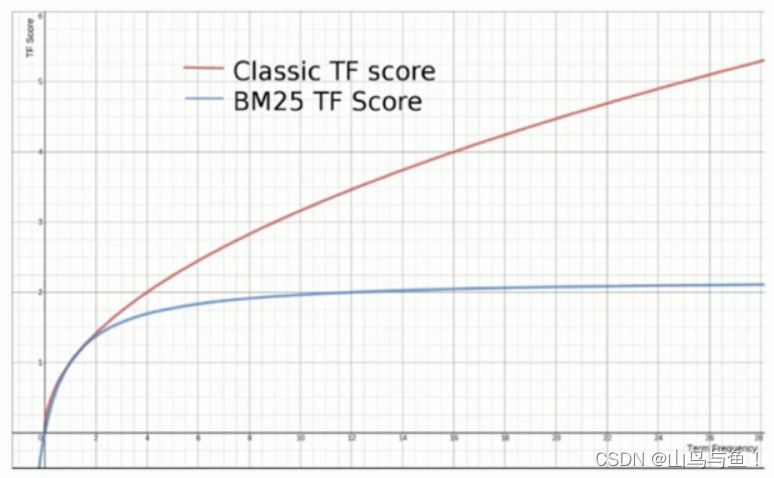
BM25
BM25 就是对 TF-IDF 算法的改进,对于 TF-IDF 算法,TF(t) 部分的值越大,整个公式返回的值就会越大。BM25 就针对这点进行来优化,随着TF(t) 的逐步加大,该算法的返回值会趋于一个数值。
从ES5开始,默认算法改为BM25,和经典的TF-IDF相比,当TF无限增加时,BM25算分会趋于一个数值。
BM25公式
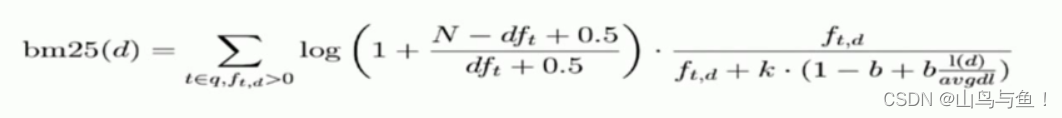
通过Explain API查看TF-IDF
PUT /test_score/_bulk
{"index":{"_id":1}}
{"content":"we use Elasticsearch to power the search"}
{"index":{"_id":2}}
{"content":"we like elasticsearch"}
{"index":{"_id":3}}
{"content":"Thre scoring of documents is caculated by the scoring formula"}
{"index":{"_id":4}}
{"content":"you know,for search"}GET /test_score/_search
{"explain": true, "query": {"match": {"content": "elasticsearch"}}
}GET /test_score/_explain/2
{"query": {"match": {"content": "elasticsearch"}}
}Boosting Query
Boosting是控制相关度的一种手段。可以通过指定字段的boost值影响查询结果
参数boost的含义:
1. 当boost > 1时,打分的权重相对性提升
2. 当0 < boost
3. 当boost
应用场景:希望包含了某项内容的结果不是不出现,而是排序靠后。
POST /blogs/_bulk
{"index":{"_id":1}}
{"title":"Apple iPad","content":"Apple iPad,Apple iPad"}
{"index":{"_id":2}}
{"title":"Apple iPad,Apple iPad","content":"Apple iPad"}GET /blogs/_search
{"query": {"bool": {"should": [{"match": {"title": {"query": "apple,ipad","boost": 1}}},{"match": {"content": {"query": "apple,ipad","boost": 4}}}]}}
}案例:要求苹果公司的产品信息优先展示
POST /news/_bulk
{"index":{"_id":1}}
{"content":"Apple Mac"}
{"index":{"_id":2}}
{"content":"Apple iPad"}
{"index":{"_id":3}}
{"content":"Apple employee like Apple Pie and Apple Juice"}GET /news/_search
{"query": {"bool": {"must": {"match": {"content": "apple"}}}}
}利用must not排除不是苹果公司产品的文档
GET /news/_search
{"query": {"bool": {"must": {"match": {"content": "apple"}},"must_not": {"match":{"content": "pie"}}}}
}利用negative_boost降低相关性
对某些返回结果不满意,但又不想排除掉( must_not),可以考虑boosting query的negative_boost。
1. negative_boost 对 negative部分query生效。
2. 计算评分时,boosting部分评分不修改,negative部分query乘以negative_boost值。
3. negative_boost取值:0-1.0,举例:0.3。
GET /news/_search
{"query": {"boosting": {"positive": {"match": {"content": "apple"}},"negative": {"match": {"content": "pie"}},"negative_boost": 0.2}}
}相关文章:
ElasticSearch分词器和相关性详解
目录 ES分词器详解 基本概念 分词发生时期 分词器的组成 切词器:Tokenizer 词项过滤器:Token Filter 停用词 同义词 字符过滤器:Character Filter HTML 标签过滤器:HTML Strip Character Filter 字符映射过滤器&#x…...
DolphinScheduler安装与配置
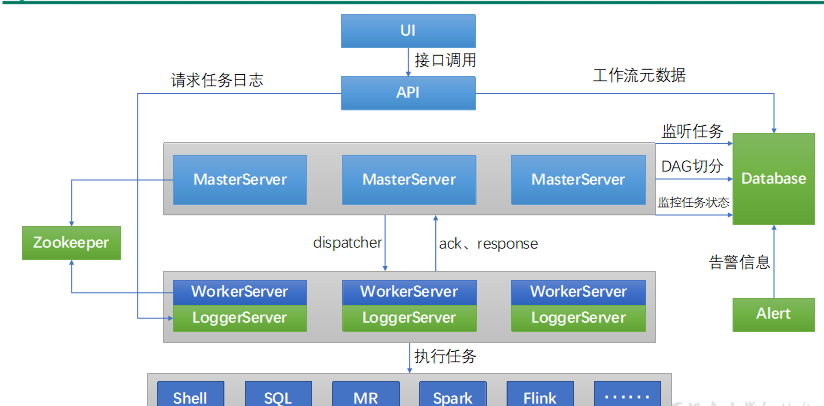
DolphinScheduler概述 Apache DolphinScheduler是一个分布式、易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。 DolphinScheduler的主要角色如下: MasterServer采用分布式无…...
Qt之条件变量QWaitCondition详解
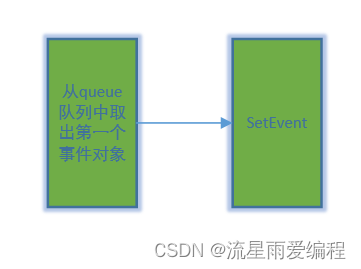
QWaitCondition内部实现结构图: 相关系列文章 C之Pimpl惯用法 目录 1.简介 2.示例 2.1.全局配置 2.2.生产者Producer 2.3.消费者Consumer 2.4.测试例子 3.原理分析 3.1.辅助函数CreateEvent 3.2.辅助函数WaitForSingleObject 3.3.QWaitConditionEvent …...
作为国产大模型之光的智谱AI,究竟推出了多少模型?一篇文章带你详细了解!
虽然OpenAI发布了一系列基于GPT模型的产品,在不同领域取得了很高的成就。但是作为LLM领域绝对的领头羊,OpenAI没有按照其最初的Open初衷行事。无论是ChatGPT早期采用的GPT3,还是后来推出的GPT3.5和GPT4模型,OpenAI都因为担心被滥用…...

学习转置矩阵
转置矩阵 将矩阵的行列互换得到的新矩阵称为转置矩阵 输入描述: 第一行包含两个整数n和m,表示一个矩阵包含n行m列,用空格分隔。 (1≤n≤10,1≤m≤10) 从2到n1行,每行输入m个整数(范围-231~231-1)&#x…...

AJAX——常用请求方法
1 请求方法 请求方法:对服务器资源,要执行的操作 2 数据提交 场景:当数据需要在服务器上保存 3 axios请求配置 url:请求的URL网址 method:请求的方法,GET可以省略(不区分大小写) …...

sqlserver2012 解决日志大的问题
当SQL Server 2012的事务日志变得过大时,这通常意味着日志备份没有被定期执行,或者日志文件的自动增长设置被设置得太高,导致它不断增长以容纳所有未备份的事务。解决日志大的问题通常涉及以下几个步骤: 备份事务日志:…...
Vue3快速上手(三)Composition组合式API及setup用法
一、Vue2的API风格 Vue2的API风格是Options API,也叫配置式API。一个功能的数据,交互,计算,监听等都是分别配置在data, methods,computed, watch等模块里的。如下: <template><div class"person"…...
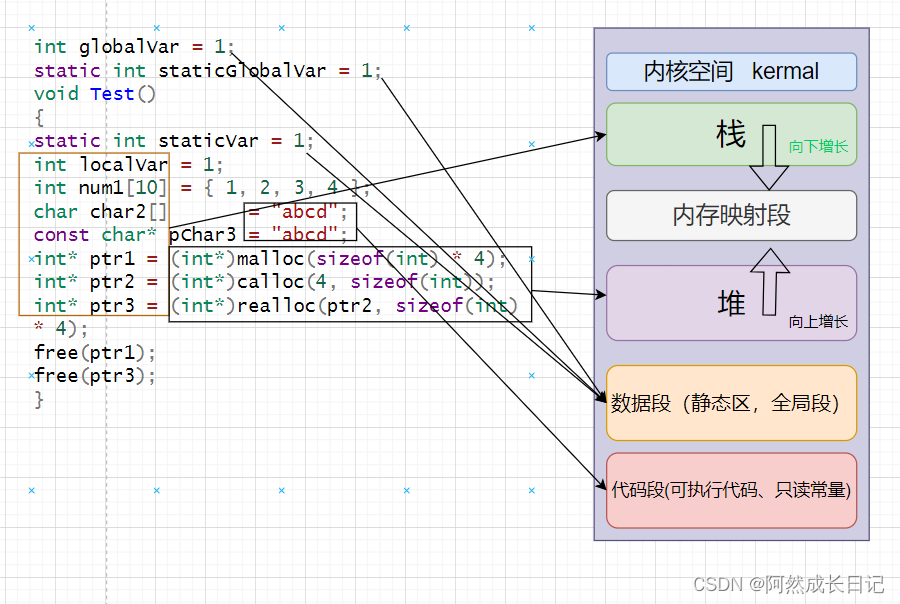
【C++】内存五大区详解
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
Django学习笔记教程全解析:初步学习Django模型,初识API,以及Django的后台管理系统(Django全解析,保姆级教程)
把时间用在思考上是最能节省时间的事情。——[美]卡曾斯 导言 写在前面 本文部分内容引用的是Django官方文档,对官方文档进行了解读和理解,对官方文档的部分注释内容进行了翻译,以方便大家的阅读和理解。 概述 在上一篇文章里࿰…...

Python学习之路-爬虫提高:selenium
Python学习之路-爬虫提高:selenium 什么是selenium Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)…...
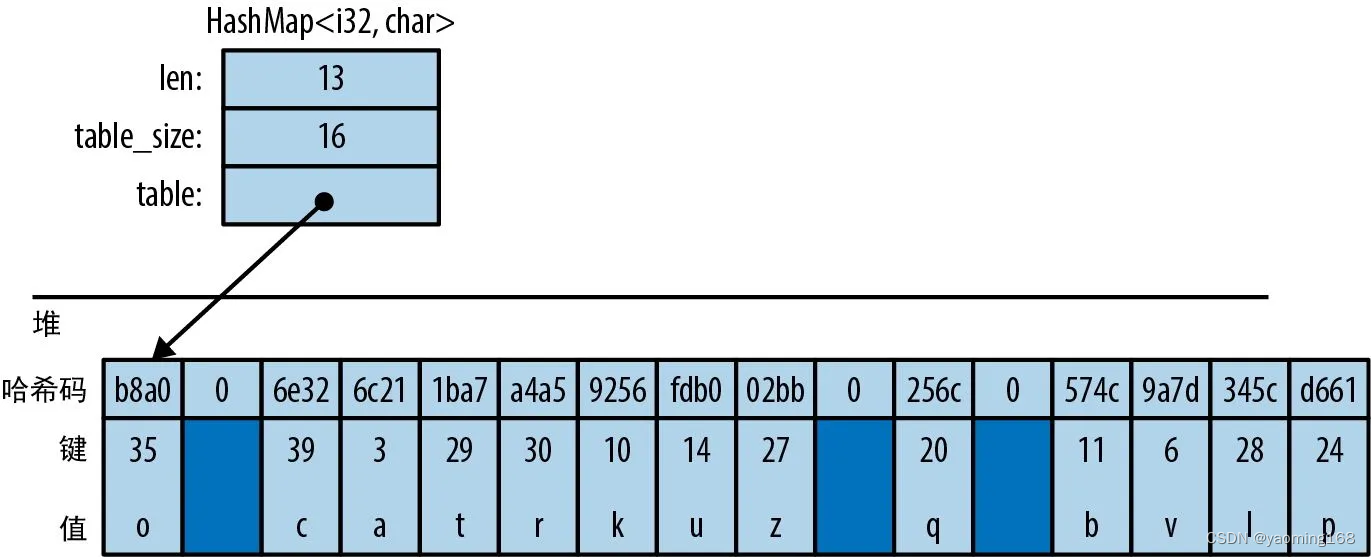
Rust基础拾遗--进阶
Rust基础拾遗 前言1.结构体1.1 具名字段型结构体1.2 元组型结构体1.3 单元型结构体1.4 结构体布局1.5 用impl定义方法1.5.1 以Box、Rc或Arc形式传入self1.5.2 类型关联函数 1.6 关联常量1.7 泛型结构体1.8 带生命周期参数的泛型结构体1.9 带常量参数的泛型结构体1.10 让结构体类…...

数据同步工具对比——SeaTunnel 、DataX、Sqoop、Flume、Flink CDC
在大数据时代,数据的采集、处理和分析变得尤为重要。业界出现了多种工具来帮助开发者和企业高效地处理数据流和数据集。本文将对比五种流行的数据处理工具:SeaTunnel、DataX、Sqoop、Flume和Flink CDC,从它们的设计理念、使用场景、优缺点等方…...

随机过程及应用学习笔记(四) 马尔可夫过程
马尔可夫过程是理论上和实际应用中都十分重要的一类随机过程。 目录 前言 一、马尔可夫过程的概念 二、离散参数马氏链 1 定义 2 齐次马尔可夫链 3 齐次马尔可夫链的性质 三、齐次马尔可夫链状态的分类 四、有限马尔可夫链 五、状态的周期性 六、极限定理 七、生灭过…...

prometheus
文章目录 一、Prometheus简介什么是Prometheus?Prometheus的优势Prometheus的组件、架构Prometheus适用于什么场景Prometheus不适合什么场景 二、相关概念数据模型指标名称和标签样本表示方式 指标类型Counter计数器Gauge仪表盘Histogram直方图Summary摘要 Jobs和In…...

Vi 和 Vim 编辑器
Vi 和 Vim 编辑器 vi 和 vim 的基本介绍 Linux 系统会内置 vi 文本编辑器 Vim 具有程序编辑的能力,可以看做是 Vi 的增强版本,可以主动的以字体颜色辨别语法的正确性,方便程序设计。 代码补完、编译及错误跳转等方便编程的功能特别丰富&…...
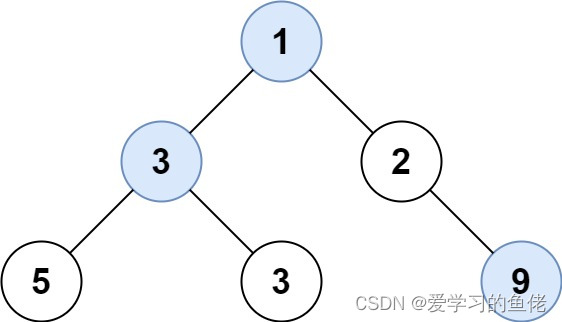
算法沉淀——队列+宽度优先搜索(BFS)(leetcode真题剖析)
算法沉淀——队列宽度优先搜索(BFS) 01.N 叉树的层序遍历02.二叉树的锯齿形层序遍历03.二叉树最大宽度04.在每个树行中找最大值 队列 宽度优先搜索算法(Queue BFS)是一种常用于图的遍历的算法,特别适用于求解最短路径…...
编辑器的新选择(基本不用配置)
Cline 不用看网上那些教程Cline几乎不用配置。 点击设置直接选择Chinese, C直接在选择就行了。 Cline是一个很好的编辑器,有很多懒人必备的功能。 Lightly 这是一个根本不用配置的C编辑器。 旁边有目录,而且配色也很好,语言标准可以自己…...

算法沉淀——栈(leetcode真题剖析)
算法沉淀——栈 01.删除字符串中的所有相邻重复项02.比较含退格的字符串03.基本计算器 II04.字符串解码05.验证栈序列 栈(Stack)是一种基于先进后出(Last In, First Out,LIFO)原则的数据结构。栈具有两个主要的操作&am…...

耳机壳UV树脂制作私模定制耳塞需要注意什么问题?
制作私模定制耳塞需要注意以下问题: 耳模制作:获取准确的耳模是制作私模定制耳塞的关键步骤。需要使用合适的材料和方法,确保耳模的准确性和稳定性。材料选择:选择合适的UV树脂和其它相关材料,确保它们的质量和性能符…...

Geothermal Power Generation Global Market Trends 2026:地热发电为何正在成为新一轮能源工程竞争核心
观点|地热发电的竞争逻辑已经发生变化过去很多人认为地热发电属于区域性能源项目。但现在,行业真正变化的是:地热正在从“资源开发工程”,转向“稳定电力基础设施工程”。相比波动性较强的风电与光伏,地热发电最大的优…...

别再乱用pt和px了!LaTeX排版中em、mm、pt单位选哪个?看完这篇实战避坑指南
LaTeX排版单位选择实战指南:从em到pt的精准避坑策略 当你熬夜完成的论文在导师的打印机上变成一团乱码,当精心设计的报告在不同设备上显示得七零八落——这些悲剧往往源于一个被忽视的细节:长度单位的选择。LaTeX作为科研排版的事实标准&…...
)
避开FPGA设计里的“定时炸弹”:用Vivado Report Clock Interaction排查跨时钟域隐患(附常见约束误区)
避开FPGA设计里的"定时炸弹":用Vivado Report Clock Interaction排查跨时钟域隐患(附常见约束误区) 在FPGA系统级设计中,时钟域交叉(CDC)问题就像一颗隐藏的定时炸弹,随时可能在产品量产或现场运行时引爆。据…...

Android MediaCodec解码实战:从H.264文件到ImageView,同步与异步模式代码对比与避坑指南
Android MediaCodec解码实战:同步与异步模式深度解析与性能优化 在移动端视频处理领域,Android MediaCodec作为系统级硬件加速接口,一直是开发者实现高效视频解码的首选方案。但面对同步与异步两种工作模式的选择,许多中高级开发者…...

一款面向高清多媒体应用的高性价比解决方案
Hi-CHIP C3100是一款面向高清多媒体应用的高性价比解决方案。它集成了高性能32位RISC CPU与强大的多媒体处理系统,支持2K视频解码和显示,并提供丰富的外设接口。主要规格与特性特性类别具体规格CPU双核高性能32位RISC CPU,性能达2000 DMIPS&a…...

RK3506J邮票孔核心板:三核A7架构如何重塑工业AIoT边缘设备设计
1. 项目概述:从一枚邮票孔核心板,看工业AIoT的“小而美”进化在嵌入式开发这个行当里待久了,你会发现一个有趣的现象:越是前沿的技术盛会,越能看见那些“小而美”的硬核产品。2025年7月的第九届瑞芯微开发者大会&#…...

香橙派Zero3部署Homeassistant:从零到一打造智能家居中枢
1. 香橙派Zero3开箱与硬件准备 第一次拿到香橙派Zero3时,确实被它的小巧惊艳到了。整块开发板只有信用卡大小,却集成了四核ARM Cortex-A53处理器和2GB/4GB内存选项。我选择的是2GB版本,对于运行Homeassistant来说完全够用。包装内除了主板外&…...

Next.js Monorepo包管理:使用Yarn Workspace的10个最佳实践指南
Next.js Monorepo包管理:使用Yarn Workspace的10个最佳实践指南 【免费下载链接】nextjs-monorepo-example Collection of monorepo tips & tricks 项目地址: https://gitcode.com/gh_mirrors/ne/nextjs-monorepo-example 在现代前端开发中,…...

LongWriter应用案例大全:从旅游指南到爱情故事的10,000+字生成示例
LongWriter应用案例大全:从旅游指南到爱情故事的10,000字生成示例 【免费下载链接】LongWriter [ICLR 2025] LongWriter: Unleashing 10,000 Word Generation from Long Context LLMs 项目地址: https://gitcode.com/gh_mirrors/lo/LongWriter LongWriter是一…...

FanControl风扇控制软件:5分钟快速上手指南,轻松解决电脑噪音与散热难题
FanControl风扇控制软件:5分钟快速上手指南,轻松解决电脑噪音与散热难题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gi…...