DolphinScheduler安装与配置
DolphinScheduler概述
Apache DolphinScheduler是一个分布式、易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
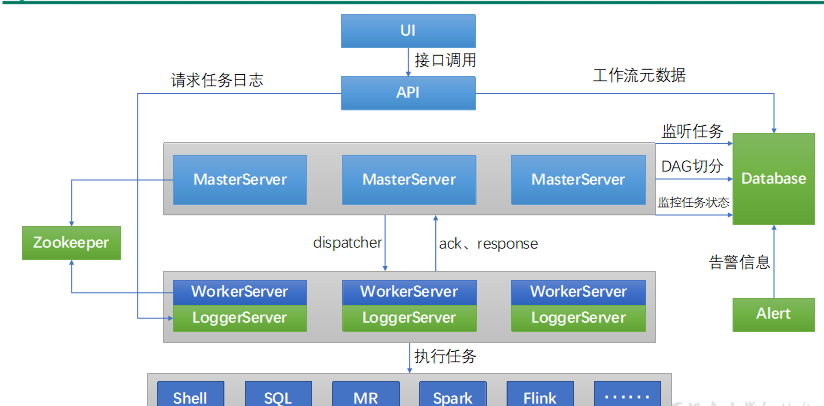
DolphinScheduler的主要角色如下:
MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交、任务监控,并同时监听其它MasterServer和WorkerServer的健康状态。
WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。
ZooKeeper服务,系统中的MasterServer和WorkerServer节点都通过ZooKeeper来进行集群管理和容错。
Alert服务,提供告警相关服务。
API接口层,主要负责处理前端UI层的请求。
UI,系统的前端页面,提供系统的各种可视化操作界面。
安装调度器
一、上传DolphinScheduler安装包到hadoop102节点的/opt/software目录
二、解压安装包到当前目录
注:解压目录并非最终的安装目录
tar -zxvf apache-dolphinscheduler-2.0.5-bin
创建元数据库及用户
DolphinScheduler 元数据存储在关系型数据库中,故需创建相应的数据库和用户。
(1)创建数据库
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
2)创建用户
CREATE USER 'dolphinscheduler'@'%' IDENTIFIED BY 'dolphinscheduler';
注:
若出现以下错误信息,表明新建用户的密码过于简单。
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
可提高密码复杂度或者执行以下命令降低MySQL密码强度级别。
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
(3)赋予用户相应权限
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%';
mysql> flush privileges;
配置一键部署脚本
修改解压目录下的conf/config目录下的install_config.conf文件。
[root@hadoop102 apache-dolphinscheduler-2.0.5-bin]$ vim conf/config/install_config.conf
修改内容如下
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# ---------------------------------------------------------
# INSTALL MACHINE
# ---------------------------------------------------------
# A comma separated list of machine hostname or IP would be installed DolphinScheduler,
# including master, worker, api, alert. If you want to deploy in pseudo-distributed
# mode, just write a pseudo-distributed hostname
# Example for hostnames: ips="ds1,ds2,ds3,ds4,ds5", Example for IPs: ips="192.168.8.1,192.168.8.2,192.168.8.3,192.168.8.4,192.168.8.5"
ips="hadoop102,hadoop103,hadoop104"
# 将要部署任一 DolphinScheduler 服务的服务器主机名或 ip 列表
# Port of SSH protocol, default value is 22. For now we only support same port in all `ips` machine
# modify it if you use different ssh port
sshPort="22"
# A comma separated list of machine hostname or IP would be installed Master server, it
# must be a subset of configuration `ips`.
# Example for hostnames: masters="ds1,ds2", Example for IPs: masters="192.168.8.1,192.168.8.2"
masters="hadoop102"
# master 所在主机名列表,必须是 ips 的子集
# A comma separated list of machine <hostname>:<workerGroup> or <IP>:<workerGroup>.All hostname or IP must be a
# subset of configuration `ips`, And workerGroup have default value as `default`, but we recommend you declare behind the hosts
# Example for hostnames: workers="ds1:default,ds2:default,ds3:default", Example for IPs: workers="192.168.8.1:default,192.168.8.2:default,192.168.8.3:default"
workers="hadoop102:default,hadoop103:default,hadoop104:default"
# worker主机名及队列,此处的 ip 必须在 ips 列表中
# A comma separated list of machine hostname or IP would be installed Alert server, it
# must be a subset of configuration `ips`.
# Example for hostname: alertServer="ds3", Example for IP: alertServer="192.168.8.3"
alertServer="hadoop103"
# 告警服务所在服务器主机名
# A comma separated list of machine hostname or IP would be installed API server, it
# must be a subset of configuration `ips`.
# Example for hostname: apiServers="ds1", Example for IP: apiServers="192.168.8.1"
apiServers="hadoop104"
# api服务所在服务器主机名
# A comma separated list of machine hostname or IP would be installed Python gateway server, it
# must be a subset of configuration `ips`.
# Example for hostname: pythonGatewayServers="ds1", Example for IP: pythonGatewayServers="192.168.8.1"
# pythonGatewayServers="ds1"
# 不需要的配置项,可以保留默认值,也可以用 # 注释
# The directory to install DolphinScheduler for all machine we config above. It will automatically be created by `install.sh` script if not exists.
# Do not set this configuration same as the current path (pwd)
installPath="/opt/module/dolphinscheduler"
# DS 安装路径,如果不存在会创建
# The user to deploy DolphinScheduler for all machine we config above. For now user must create by yourself before running `install.sh`
# script. The user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled than the root directory needs
# to be created by this user
deployUser="atguigu"
# 部署用户,任务执行服务是以 sudo -u {linux-user} 切换不同 Linux 用户的方式来实现多租户运行作业,因此该用户必须有免密的 sudo 权限。
# The directory to store local data for all machine we config above. Make sure user `deployUser` have permissions to read and write this directory.
dataBasedirPath="/tmp/dolphinscheduler"
# 前文配置的所有节点的本地数据存储路径,需要确保部署用户拥有该目录的读写权限
# ---------------------------------------------------------
# DolphinScheduler ENV
# ---------------------------------------------------------
# JAVA_HOME, we recommend use same JAVA_HOME in all machine you going to install DolphinScheduler
# and this configuration only support one parameter so far.
javaHome="/opt/module/jdk1.8.0_212"
# JAVA_HOME 路径
# DolphinScheduler API service port, also this is your DolphinScheduler UI component's URL port, default value is 12345
apiServerPort="12345"
# ---------------------------------------------------------
# Database
# NOTICE: If database value has special characters, such as `.*[]^${}\+?|()@#&`, Please add prefix `\` for escaping.
# ---------------------------------------------------------
# The type for the metadata database
# Supported values: ``postgresql``, ``mysql`, `h2``.
# 注意:数据库相关配置的 value 必须加引号,否则配置无法生效
DATABASE_TYPE="mysql"
# 数据库类型
# Spring datasource url, following <HOST>:<PORT>/<database>?<parameter> format, If you using mysql, you could use jdbc
# string jdbc:mysql://127.0.0.1:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8 as example
# SPRING_DATASOURCE_URL=${SPRING_DATASOURCE_URL:-"jdbc:h2:mem:dolphinscheduler;MODE=MySQL;DB_CLOSE_DELAY=-1;DATABASE_TO_LOWER=true"}
SPRING_DATASOURCE_URL="jdbc:mysql://hadoop102:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8"
# 数据库 URL
# Spring datasource username
# SPRING_DATASOURCE_USERNAME=${SPRING_DATASOURCE_USERNAME:-"sa"}
SPRING_DATASOURCE_USERNAME="dolphinscheduler"
# 数据库用户名
# Spring datasource password
# SPRING_DATASOURCE_PASSWORD=${SPRING_DATASOURCE_PASSWORD:-""}
SPRING_DATASOURCE_PASSWORD="dolphinscheduler"
# 数据库密码
# ---------------------------------------------------------
# Registry Server
# ---------------------------------------------------------
# Registry Server plugin name, should be a substring of `registryPluginDir`, DolphinScheduler use this for verifying configuration consistency
registryPluginName="zookeeper"
# 注册中心插件名称,DS 通过注册中心来确保集群配置的一致性
# Registry Server address.
registryServers="hadoop102:2181,hadoop103:2181,hadoop104:2181"
# 注册中心地址,即 Zookeeper 集群的地址
# Registry Namespace
registryNamespace="dolphinscheduler"
# DS 在 Zookeeper 的结点名称
# ---------------------------------------------------------
# Worker Task Server
# ---------------------------------------------------------
# Worker Task Server plugin dir. DolphinScheduler will find and load the worker task plugin jar package from this dir.
taskPluginDir="lib/plugin/task"
# resource storage type: HDFS, S3, NONE
resourceStorageType="HDFS"
# 资源存储类型
# resource store on HDFS/S3 path, resource file will store to this hdfs path, self configuration, please make sure the directory exists on hdfs and has read write permissions. "/dolphinscheduler" is recommended
resourceUploadPath="/dolphinscheduler"
# 资源上传路径
# if resourceStorageType is HDFS,defaultFS write namenode address,HA, you need to put core-site.xml and hdfs-site.xml in the conf directory.
# if S3,write S3 address,HA,for example :s3a://dolphinscheduler,
# Note,S3 be sure to create the root directory /dolphinscheduler
defaultFS="hdfs://mycluster"
# 默认文件系统
# if resourceStorageType is S3, the following three configuration is required, otherwise please ignore
s3Endpoint="http://192.168.xx.xx:9010"
s3AccessKey="xxxxxxxxxx"
s3SecretKey="xxxxxxxxxx"
# resourcemanager port, the default value is 8088 if not specified
resourceManagerHttpAddressPort="8088"
# yarn RM http 访问端口
# if resourcemanager HA is enabled, please set the HA IPs; if resourcemanager is single node, keep this value empty
yarnHaIps="hadoop102,hadoop103"
# Yarn RM 高可用 ip,若未启用 RM 高可用,则将该值置空
# if resourcemanager HA is enabled or not use resourcemanager, please keep the default value; If resourcemanager is single node, you only need to replace 'yarnIp1' to actual resourcemanager hostname
singleYarnIp=""
# Yarn RM 主机名,若启用了 HA 或未启用 RM,保留默认值
# who has permission to create directory under HDFS/S3 root path
# Note: if kerberos is enabled, please config hdfsRootUser=
hdfsRootUser="atguigu"
# 拥有 HDFS 根目录操作权限的用户
# kerberos config
# whether kerberos starts, if kerberos starts, following four items need to config, otherwise please ignore
kerberosStartUp="false"
# kdc krb5 config file path
krb5ConfPath="$installPath/conf/krb5.conf"
# keytab username,watch out the @ sign should followd by \\
keytabUserName="hdfs-mycluster\\@ESZ.COM"
# username keytab path
keytabPath="$installPath/conf/hdfs.headless.keytab"
# kerberos expire time, the unit is hour
kerberosExpireTime="2"
# use sudo or not
sudoEnable="true"
# worker tenant auto create
workerTenantAutoCreate="false"
将必要配置文件拷贝到配置目录:
[root@hadoop102 apache-dolphinscheduler-2.0.5-bin]$ cp /opt/moudle/hadoop/etc/hadoop/core-site.xml conf
[root@hadoop102 apache-dolphinscheduler-2.0.5-bin]$ cp /opt/moudle/hadoop/etc/hadoop/hdfs-site.xml conf
初始化数据库
(1)拷贝MySQL驱动到DolphinScheduler的解压目录下的lib中,要求使用 MySQL JDBC Driver 8.0.16。
[root@hadoop102apache-dolphinscheduler-2.0.5-bin]$cp/opt/software/mysql-connector-java-8.0.16.jar lib/
(2)执行数据库初始化脚本
数据库初始化脚本位于DolphinScheduler解压目录下的script目录中,即/opt/software/ds/apache-dolphinscheduler-2.0.5-bin/script/。
[root@hadoop102 apache-dolphinscheduler-2.0.5-bin]$ script/create-dolphinscheduler.sh
一键部署DolphinScheduler
(1)启动Zookeeper集群
[root@hadoop102 apache-dolphinscheduler-2.0.5-bin]$ zk.sh start
(2)一键部署并启动DolphinScheduler
[root@hadoop102 apache-dolphinscheduler-2.0.5-bin]$ ./install.sh
(3)查看DolphinScheduler进程
--------- hadoop102 ----------
29139 ApiApplicationServer
28963 WorkerServer
3332 QuorumPeerMain
2100 DataNode
28902 MasterServer
29081 AlertServer
1978 NameNode
29018 LoggerServer
2493 NodeManager
29551 Jps
--------- hadoop103 ----------
29568 Jps
29315 WorkerServer
2149 NodeManager
1977 ResourceManager
2969 QuorumPeerMain
29372 LoggerServer
1903 DataNode
--------- hadoop104 ----------
1905 SecondaryNameNode
27074 WorkerServer
2050 NodeManager
2630 QuorumPeerMain
1817 DataNode
27354 Jps
27133 LoggerServer
(4)访问DolphinScheduler UI地址在APIServer的位置
DolphinScheduler UI地址为http://hadoop104:12345/dolphinscheduler
初始用户的用户名为:admin,密码为dolphinscheduler123
DolphinScheduler启停命令
DolphinScheduler的启停脚本均位于其安装目录的bin目录下。
1)一键启停所有服务
./bin/start-all.sh
./bin/stop-all.sh
注意同Hadoop的启停脚本进行区分。
2)启停 Master
./bin/dolphinscheduler-daemon.sh start master-server
./bin/dolphinscheduler-daemon.sh stop master-server
3)启停 Worker
./bin/dolphinscheduler-daemon.sh start worker-server
./bin/dolphinscheduler-daemon.sh stop worker-server
4)启停 Api
./bin/dolphinscheduler-daemon.sh start api-server
./bin/dolphinscheduler-daemon.sh stop api-server
5)启停 Logger
./bin/dolphinscheduler-daemon.sh start logger-server
./bin/dolphinscheduler-daemon.sh stop logger-server
6)启停 Alert
./bin/dolphinscheduler-daemon.sh start alert-server
./bin/dolphinscheduler-daemon.sh stop alert-server
相关文章:
DolphinScheduler安装与配置
DolphinScheduler概述 Apache DolphinScheduler是一个分布式、易扩展的可视化DAG工作流任务调度平台。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。 DolphinScheduler的主要角色如下: MasterServer采用分布式无…...
Qt之条件变量QWaitCondition详解
QWaitCondition内部实现结构图: 相关系列文章 C之Pimpl惯用法 目录 1.简介 2.示例 2.1.全局配置 2.2.生产者Producer 2.3.消费者Consumer 2.4.测试例子 3.原理分析 3.1.辅助函数CreateEvent 3.2.辅助函数WaitForSingleObject 3.3.QWaitConditionEvent …...
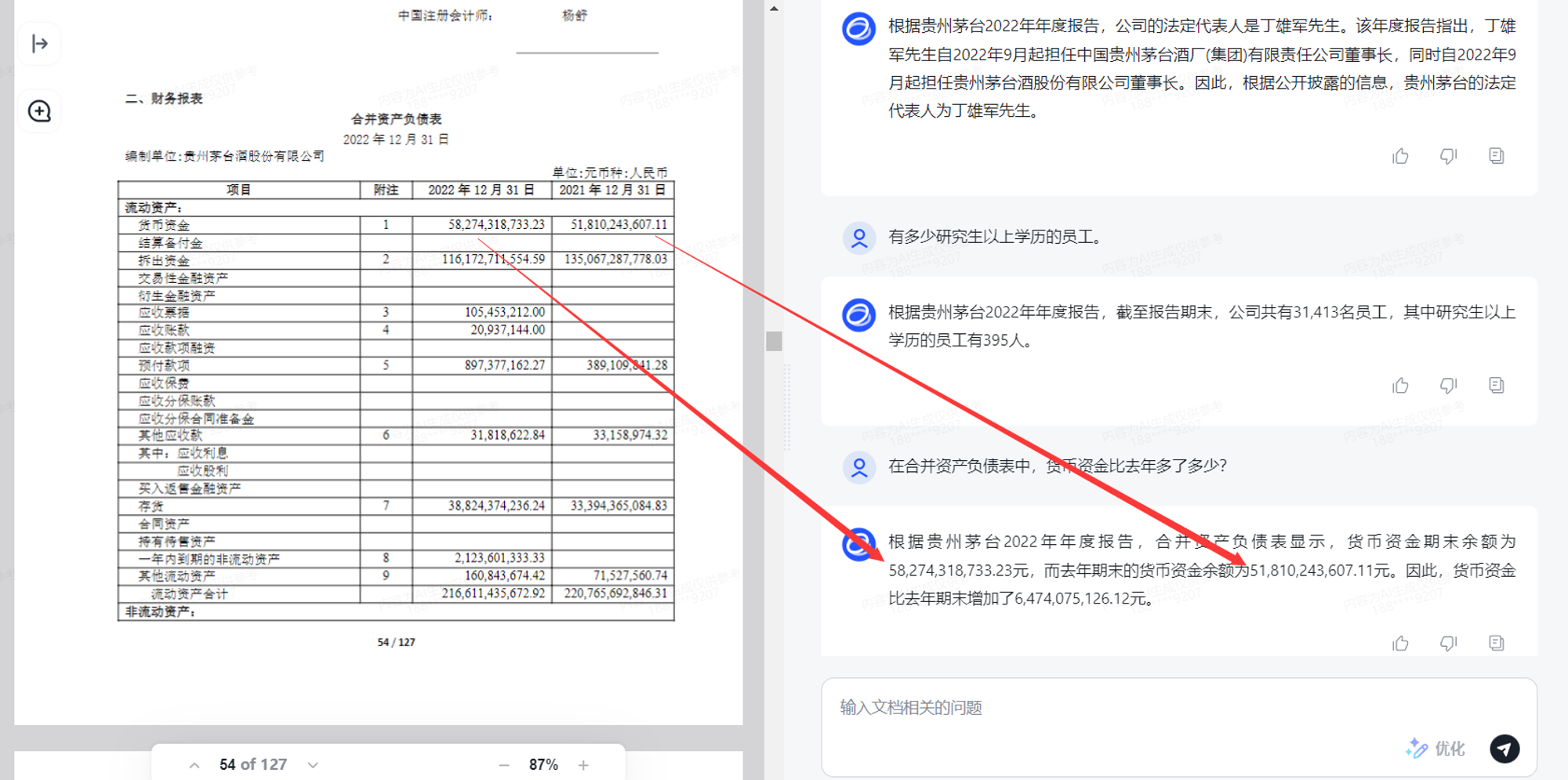
作为国产大模型之光的智谱AI,究竟推出了多少模型?一篇文章带你详细了解!
虽然OpenAI发布了一系列基于GPT模型的产品,在不同领域取得了很高的成就。但是作为LLM领域绝对的领头羊,OpenAI没有按照其最初的Open初衷行事。无论是ChatGPT早期采用的GPT3,还是后来推出的GPT3.5和GPT4模型,OpenAI都因为担心被滥用…...

学习转置矩阵
转置矩阵 将矩阵的行列互换得到的新矩阵称为转置矩阵 输入描述: 第一行包含两个整数n和m,表示一个矩阵包含n行m列,用空格分隔。 (1≤n≤10,1≤m≤10) 从2到n1行,每行输入m个整数(范围-231~231-1)&#x…...

AJAX——常用请求方法
1 请求方法 请求方法:对服务器资源,要执行的操作 2 数据提交 场景:当数据需要在服务器上保存 3 axios请求配置 url:请求的URL网址 method:请求的方法,GET可以省略(不区分大小写) …...

sqlserver2012 解决日志大的问题
当SQL Server 2012的事务日志变得过大时,这通常意味着日志备份没有被定期执行,或者日志文件的自动增长设置被设置得太高,导致它不断增长以容纳所有未备份的事务。解决日志大的问题通常涉及以下几个步骤: 备份事务日志:…...
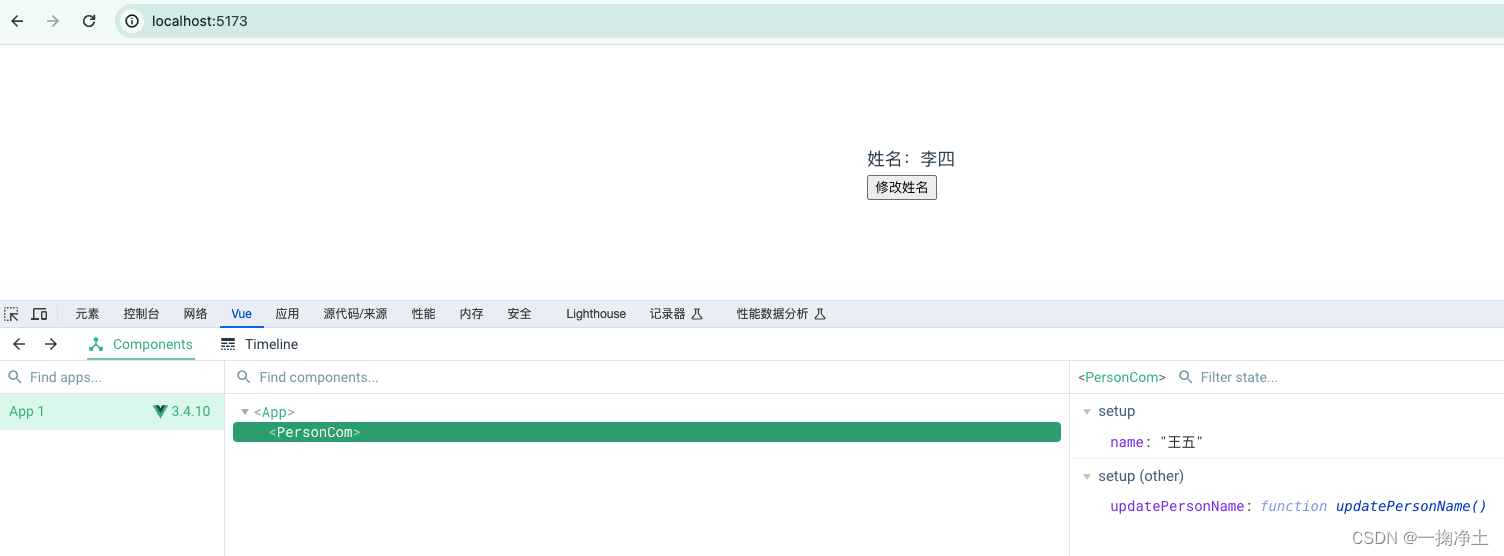
Vue3快速上手(三)Composition组合式API及setup用法
一、Vue2的API风格 Vue2的API风格是Options API,也叫配置式API。一个功能的数据,交互,计算,监听等都是分别配置在data, methods,computed, watch等模块里的。如下: <template><div class"person"…...
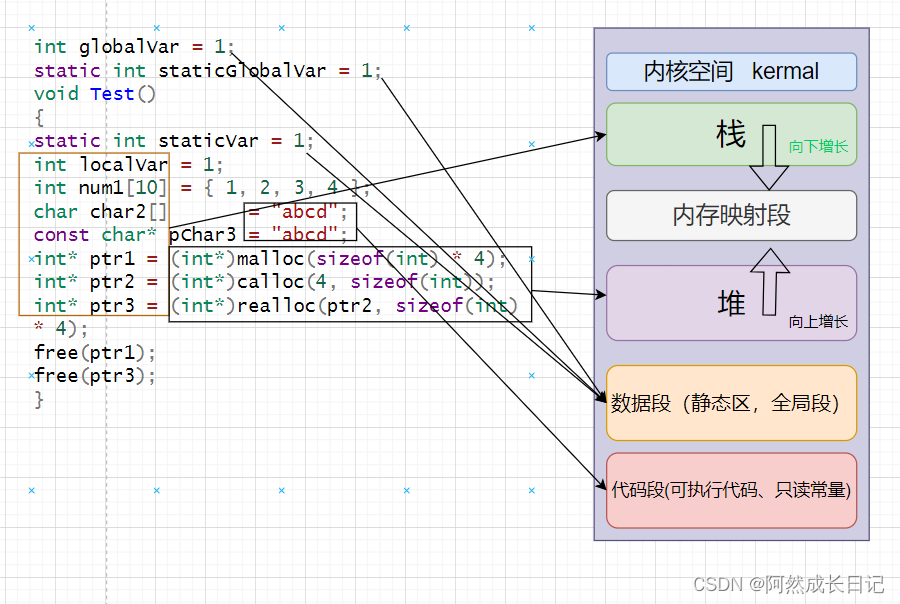
【C++】内存五大区详解
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
Django学习笔记教程全解析:初步学习Django模型,初识API,以及Django的后台管理系统(Django全解析,保姆级教程)
把时间用在思考上是最能节省时间的事情。——[美]卡曾斯 导言 写在前面 本文部分内容引用的是Django官方文档,对官方文档进行了解读和理解,对官方文档的部分注释内容进行了翻译,以方便大家的阅读和理解。 概述 在上一篇文章里࿰…...

Python学习之路-爬虫提高:selenium
Python学习之路-爬虫提高:selenium 什么是selenium Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)…...
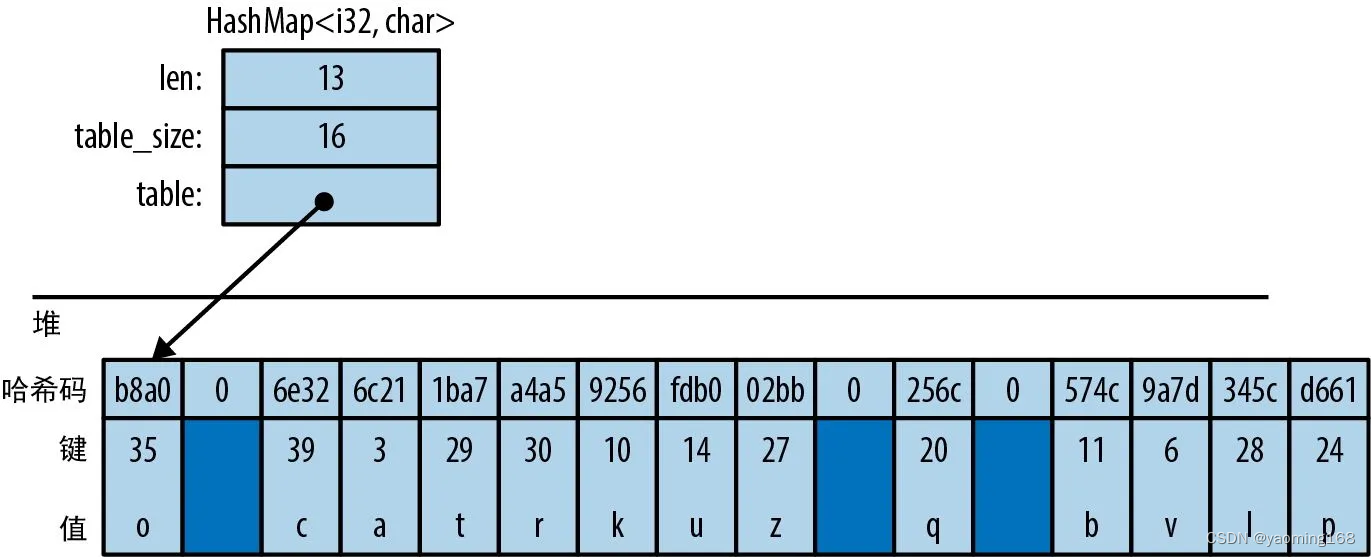
Rust基础拾遗--进阶
Rust基础拾遗 前言1.结构体1.1 具名字段型结构体1.2 元组型结构体1.3 单元型结构体1.4 结构体布局1.5 用impl定义方法1.5.1 以Box、Rc或Arc形式传入self1.5.2 类型关联函数 1.6 关联常量1.7 泛型结构体1.8 带生命周期参数的泛型结构体1.9 带常量参数的泛型结构体1.10 让结构体类…...

数据同步工具对比——SeaTunnel 、DataX、Sqoop、Flume、Flink CDC
在大数据时代,数据的采集、处理和分析变得尤为重要。业界出现了多种工具来帮助开发者和企业高效地处理数据流和数据集。本文将对比五种流行的数据处理工具:SeaTunnel、DataX、Sqoop、Flume和Flink CDC,从它们的设计理念、使用场景、优缺点等方…...

随机过程及应用学习笔记(四) 马尔可夫过程
马尔可夫过程是理论上和实际应用中都十分重要的一类随机过程。 目录 前言 一、马尔可夫过程的概念 二、离散参数马氏链 1 定义 2 齐次马尔可夫链 3 齐次马尔可夫链的性质 三、齐次马尔可夫链状态的分类 四、有限马尔可夫链 五、状态的周期性 六、极限定理 七、生灭过…...

prometheus
文章目录 一、Prometheus简介什么是Prometheus?Prometheus的优势Prometheus的组件、架构Prometheus适用于什么场景Prometheus不适合什么场景 二、相关概念数据模型指标名称和标签样本表示方式 指标类型Counter计数器Gauge仪表盘Histogram直方图Summary摘要 Jobs和In…...

Vi 和 Vim 编辑器
Vi 和 Vim 编辑器 vi 和 vim 的基本介绍 Linux 系统会内置 vi 文本编辑器 Vim 具有程序编辑的能力,可以看做是 Vi 的增强版本,可以主动的以字体颜色辨别语法的正确性,方便程序设计。 代码补完、编译及错误跳转等方便编程的功能特别丰富&…...
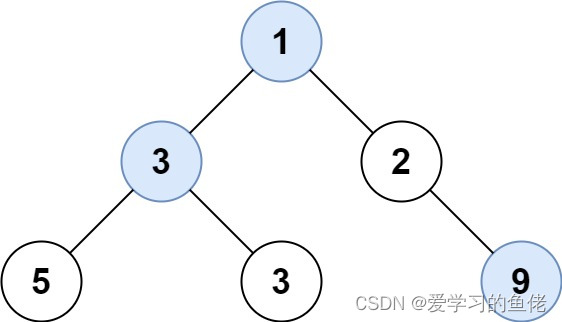
算法沉淀——队列+宽度优先搜索(BFS)(leetcode真题剖析)
算法沉淀——队列宽度优先搜索(BFS) 01.N 叉树的层序遍历02.二叉树的锯齿形层序遍历03.二叉树最大宽度04.在每个树行中找最大值 队列 宽度优先搜索算法(Queue BFS)是一种常用于图的遍历的算法,特别适用于求解最短路径…...
编辑器的新选择(基本不用配置)
Cline 不用看网上那些教程Cline几乎不用配置。 点击设置直接选择Chinese, C直接在选择就行了。 Cline是一个很好的编辑器,有很多懒人必备的功能。 Lightly 这是一个根本不用配置的C编辑器。 旁边有目录,而且配色也很好,语言标准可以自己…...

算法沉淀——栈(leetcode真题剖析)
算法沉淀——栈 01.删除字符串中的所有相邻重复项02.比较含退格的字符串03.基本计算器 II04.字符串解码05.验证栈序列 栈(Stack)是一种基于先进后出(Last In, First Out,LIFO)原则的数据结构。栈具有两个主要的操作&am…...

耳机壳UV树脂制作私模定制耳塞需要注意什么问题?
制作私模定制耳塞需要注意以下问题: 耳模制作:获取准确的耳模是制作私模定制耳塞的关键步骤。需要使用合适的材料和方法,确保耳模的准确性和稳定性。材料选择:选择合适的UV树脂和其它相关材料,确保它们的质量和性能符…...

easyx搭建项目-永七大作战(割草游戏)
永七大作战 游戏介绍: 永七大作战 游戏代码链接:永七大作战 提取码:ABCD 不想水文了,直接献出源码,表示我的诚意...

避坑指南:Houdini风格化树木导入Unity URP后,光照和裁剪效果不对怎么办?
Houdini风格化树木在Unity URP中的渲染问题深度解析与实战修复 当你在Houdini中精心雕琢的风格化树木模型导入Unity URP管线后,可能会遭遇一系列令人沮丧的渲染问题:叶片边缘出现锯齿状裁剪、光照效果与预期不符、阴影投射异常等。这些问题的根源往往在于…...

iOS 27 Siri 自动删除聊天记录:深度解析与行业启示
上周同事跟我吐槽,说他跟Siri聊了点私事,换手机时发现聊天记录全在iCloud里躺着。我跟他说,等iOS 27吧,Siri终于要加自动删除功能了。这个功能不算革命性创新,但方向是对的。下面从用户价值、技术实现和行业影响三个维…...

Claude Code + OpenCode + OpenSpec 规范驱动开发实战:AI 驱动智能客服管理系统开发
当 AI 编程从“凭感觉聊天”升级为“按规范执行的流水线” 一、引言:AI 编程的“效率悖论” 2024 年 Google DORA 报告揭示了一个令人困惑的数据:AI 编码助手采用率每提升 25%,软件交付稳定性反而下降 7.2%。主观上开发者觉得用 AI 写代码速…...

数据科学工具链实战指南:从核心工具到架构选型
1. 项目概述:数据科学工具生态的实战视角聊起数据科学,很多人第一反应是复杂的算法和模型。但干了这么多年,我越来越觉得,工具链的选型和熟练度,才是决定一个数据科学项目能否高效落地、甚至能否成功的关键。算法是“道…...

Matlab阶跃响应性能指标自动化计算:从原理到工程实践
1. 项目概述:从阶跃响应曲线到量化性能的灵魂拷问在控制系统、信号处理乃至电路设计的日常工作中,我们常常会面对一个看似简单却至关重要的任务:给一个系统施加一个“阶跃”输入,然后观察它的输出如何从静止状态“爬升”到新的稳态…...

Google Cloud Dataflow 背后的流式处理模型
原文:towardsdatascience.com/the-stream-processing-model-behind-google-cloud-dataflow-0d927c9506a0?sourcecollection_archive---------3-----------------------#2024-04-27 在无界数据处理中的正确性、延迟和成本平衡 https://medium.com/vutrinh274?sour…...
可视化)
别再只画折线图了!用Python的pyts库5分钟搞定时间序列的递归图(Recurrence Plot)可视化
解锁时间序列分析新维度:用Python高效构建递归图 时间序列分析早已超越了简单的折线图时代。当我们需要挖掘数据中隐藏的周期性、突变点或非线性特征时,传统可视化方法往往力不从心。递归图(Recurrence Plot)作为一种强大的分析工具,能够将时…...

终极QR二维码修复工具:QRazyBox完整指南与高效恢复技巧
终极QR二维码修复工具:QRazyBox完整指南与高效恢复技巧 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 还在为损坏的二维码无法扫描而烦恼吗?QRazyBox是一款专业的免费…...

3大核心功能构建学术研究知识库:Obsidian科研模板实战指南
3大核心功能构建学术研究知识库:Obsidian科研模板实战指南 【免费下载链接】obsidian_vault_template_for_researcher This is an vault template for researchers using obsidian. 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian_vault_template_for_res…...

终极指南:如何一键重置JetBrains IDE试用期,免费获得全新30天评估时间
终极指南:如何一键重置JetBrains IDE试用期,免费获得全新30天评估时间 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置是每个开发者都需要的实用技能,当…...