Hadoop运行环境搭建
模板虚拟机环境准备
1)准备一台模板虚拟机hadoop100,虚拟机配置要求如下:
模板虚拟机:内存4G,硬盘50G,安装必要环境,为安装hadoop做准备
[root@hadoop100 ~]# yum install -y epel-release
[root@hadoop100 ~]# yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git
这个命令安装了一系列有用的工具和库
使用yum安装需要虚拟机可以正常上网,yum安装前可以先测试下虚拟机联网情况。
[root@hadoop100 ~]# ping www.baidu.com
PING www.baidu.com (14.215.177.39) 56(84) bytes of data.
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=1 ttl=128 time=8.60 ms
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=2 ttl=128 time=7.72 ms
2)关闭防火墙,关闭防火墙开机自启
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld
3)创建atguigu用户,并修改atguigu用户的密码
[root@hadoop100 ~]# useradd atguigu
[root@hadoop100 ~]# passwd 000000
4)配置atguigu用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers
修改/etc/sudoers文件,找到下面一行(91行),在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
atguigu ALL=(ALL) NOPASSWD:ALL
5)在/opt目录下创建文件夹,并修改所属主和所属组
(1)在/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
(2)修改module、software文件夹的所有者和所属组均为atguigu用户
[root@hadoop100 ~]# chown atguigu:atguigu /opt/module
[root@hadoop100 ~]# chown atguigu:atguigu /opt/software
(3)查看module、software文件夹的所有者和所属组
[root@hadoop100 ~]# cd /opt/
[root@hadoop100 opt]# ll
总用量 12
drwxr-xr-x. 2 atguigu atguigu 4096 5月 28 17:18 module
drwxr-xr-x. 2 root root 4096 9月 7 2017 rh
drwxr-xr-x. 2 atguigu atguigu 4096 5月 28 17:18 software
6)卸载虚拟机自带的open JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
7)重启虚拟机
[root@hadoop100 ~]# reboot
克隆虚拟机
1)利用模板机hadoop100,克隆三台虚拟机:hadoop102 hadoop103 hadoop104
2)修改克隆机IP,以下以hadoop102举例说明
修改克隆虚拟机的静态IP
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
改成【第一行是修改源文件,其余结尾添加】
BOOTPROTO=static
IPADDR=192.168.222.102
GATEWAY=192.168.222.2
DNS1=192.168.222.2
3)修改克隆机主机名,以下以hadoop102举例说明
(1)修改/etc/hostname文件
[root@hadoop100 ~]# vim /etc/hostname
hadoop102
(2)配置linux克隆机主机名称映射hosts文件,打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts
添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
4**)重启克隆机hadoop102**
[root@hadoop100 ~]# reboot
安装JDK
1)卸载现有JDK
[atguigu@hadoop102 ~]$ rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
2)在Linux系统下的opt目录中查看软件包是否导入成功
[atguigu@hadoop102 ~]$ ls /opt/software/
看到如下结果:
hadoop-3.1.3.tar.gz jdk-8u212-linux-x64.tar.gz
3)解压JDK到/opt/module目录下
[atguigu@hadoop102 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
4**)配置JDK****环境变量**
(1)新建/etc/profile.d/my_env.sh文件
[atguigu@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容如果不理解,点击这里
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
(2)保存后退出
(3)source一下/etc/profile文件,让新的环境变量PATH生效
[atguigu@hadoop102 ~]$ source /etc/profile
5)测试JDK是否安装成功
[atguigu@hadoop102 ~]$ java -version
如果能看到以下结果,则代表Java安装成功。
java version “1.8.0_212”
注意:重启(如果java -version可以用就不用重启)
[atguigu@hadoop102 ~]$ sudo reboot
Hadoop目录结构
1)查看Hadoop目录结构
[atguigu@hadoop102 hadoop-3.1.3]$ ll
总用量 52
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 bin
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 etc
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 include
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 lib
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 libexec
-rw-r--r--. 1 atguigu atguigu 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 atguigu atguigu 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 atguigu atguigu 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 sbin
2)重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
安装Hadoop
1)进入到Hadoop安装包路径下
[atguigu@hadoop102 ~]$ cd /opt/software/
2)解压安装文件到/opt/module下面
[atguigu@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
3)查看是否解压成功
[atguigu@hadoop102 software]$ ls /opt/module/
hadoop-3.1.3
4)将Hadoop添加到环境变量
(1)获取Hadoop安装路径
[atguigu@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
(2)打开/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh
在my_env.sh文件末尾添加如下内容:(shift+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出
(4)让修改后的文件生效
[atguigu@hadoop102 hadoop-3.1.3]$ source /etc/profile
5)测试是否安装成功
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop version
Hadoop 3.1.3
相关文章:

Hadoop运行环境搭建
模板虚拟机环境准备 1)准备一台模板虚拟机hadoop100,虚拟机配置要求如下: 模板虚拟机:内存4G,硬盘50G,安装必要环境,为安装hadoop做准备 [roothadoop100 ~]# yum install -y epel-release [r…...
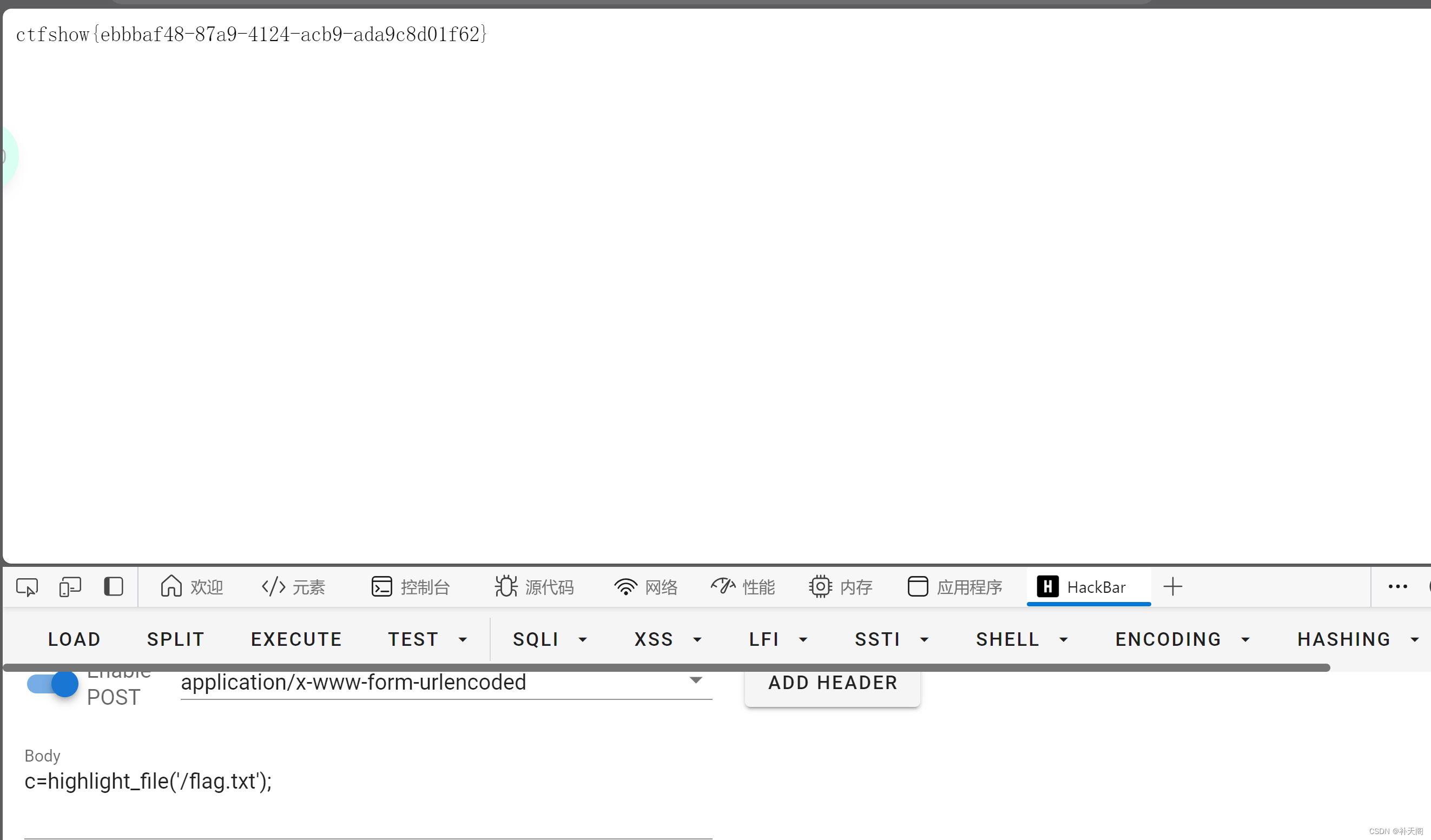
CTFshow web(php命令执行59-67)
web59 <?php /* # -*- coding: utf-8 -*- # Author: Lazzaro # Date: 2020-09-05 20:49:30 # Last Modified by: h1xa # Last Modified time: 2020-09-07 22:02:47 # email: h1xactfer.com # link: https://ctfer.com */ // 你们在炫技吗? if(isset($_POST…...
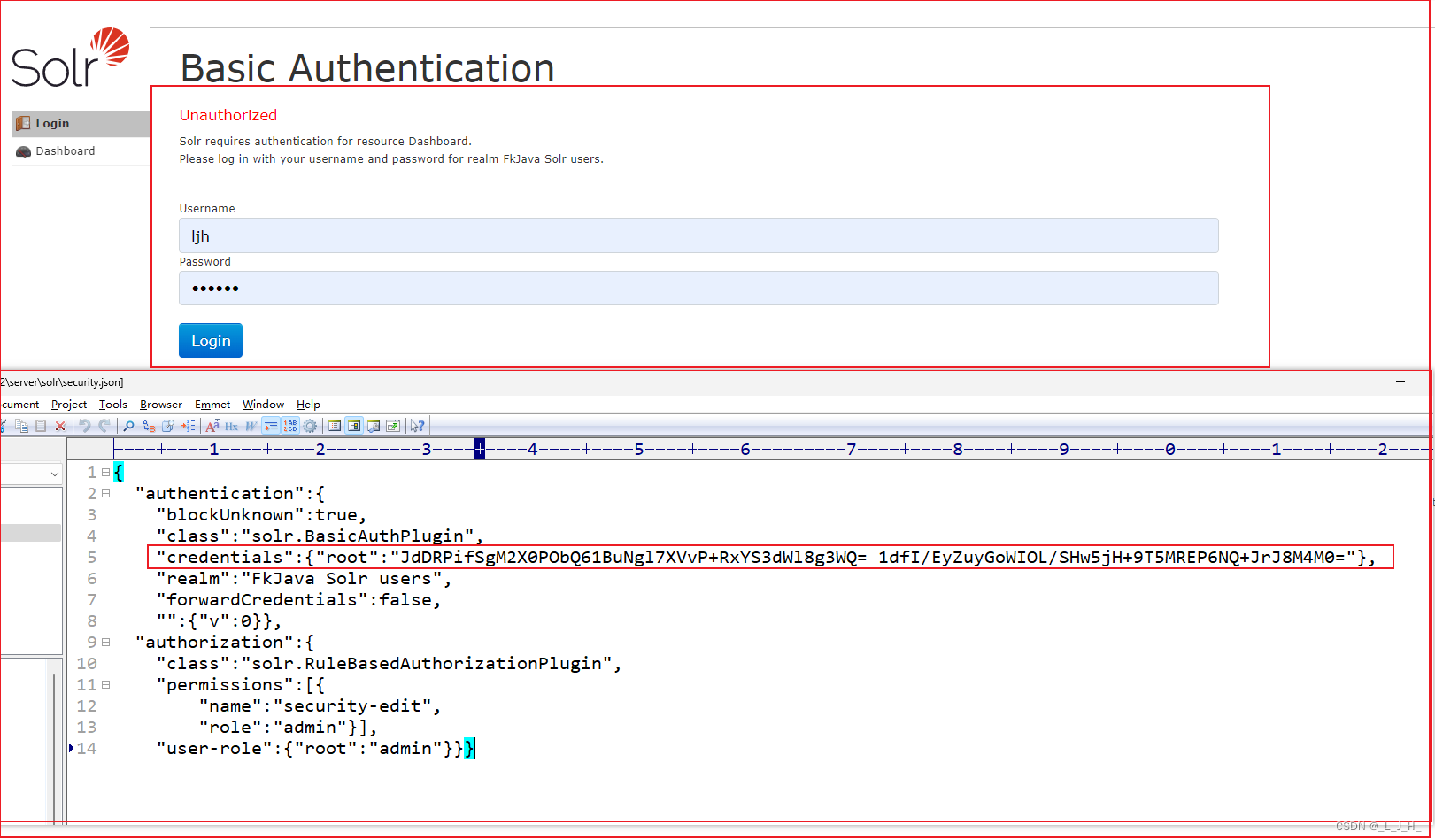
03、全文检索 -- Solr -- Solr 身份验证配置(给 Solr 启动身份验证、添加用户、删除用户)
目录 全文检索 -- Solr -- Solr 身份验证配置启用身份验证:添加用户:删除用户: 全文检索 – Solr – Solr 身份验证配置 学习之前需要先启动 Solr 执行如下命令即可启动Solr: solr start -p <端口>如果不指定端口…...
怎么使用ChatGPT提高工作效率?
怎么使用ChatGPT提高工作效率,这是一个有趣的话题。 相信不同的人有不同的观点,大家的知识背景和从事的工作都不完全相同,所以最终ChatGPT能起到的作用也不一样。 在编程过程中,如果我们要找一个库,我们最先做的肯定…...
【微服务】skywalking自定义告警规则使用详解
目录 一、前言 二、SkyWalking告警功能介绍 2.1 SkyWalking告警是什么 2.2 为什么需要SkyWalking告警功能 2.2.1 及时发现系统异常 2.2.2 保障和提升系统稳定性 2.2.3 避免数据丢失 2.2.4 提高故障处理效率 三、 SkyWalking告警规则 3.1 SkyWalking告警规则配置 3.2 …...

BUGKU-WEB 矛盾
题目描述 进入场景看看: 代码如下: $num$_GET[num]; if(!is_numeric($num)) { echo $num; if($num1) echo flag{**********}; }解题思路 需要读懂一下这段PHP代码的意思明显是一道get相关的题目,需要提供一个num的参数,然后需要传入一个不…...

2024-02-11 Unity 编辑器开发之编辑器拓展2 —— 自定义窗口
文章目录 1 创建窗口类2 显示窗口3 窗口事件回调函数4 窗口中常用的生命周期函数5 编辑器窗口类中的常用成员6 小结 1 创建窗口类 当想为 Unity 拓展一个自定义窗口时,只需实现继承 EditorWindow 的类即可,并在该类的 OnGUI 函数中编写面板控件相关的…...
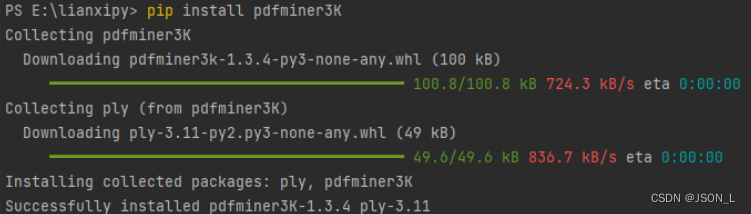
Python 读取pdf文件
Python 实现读取pdf文件简单示例。 安装命令 需要安装操作pdf的三方类库,命令如下: pip install pdfminer3K 安装过程如下: 引入类库 需要引入很多的类库。 示例如下: import sys import importlib importlib.reload(sys)fr…...

人究其一生只是在通用智能模型基础上作微调和对齐
Yann LeCun 在 WGS 上说: 目前的LLM不可能走到AGI,原因很简单,现在训练这些LLM所使用的数据量为10万亿个令牌,也就是130亿个词,如果你计算人类阅读这些数据需要多长时间,一个人每天阅读8小时,需…...
DS:二叉树的链式结构及实现
创作不易,友友们给个三连吧!! 一、前言 前期我们解释过二叉树的顺序结构(堆)为什么比较适用于完全二叉树,因为如果用数组来实现非完全二叉树,那么数组的中间部分就可能会存在大量的空间浪费。 …...
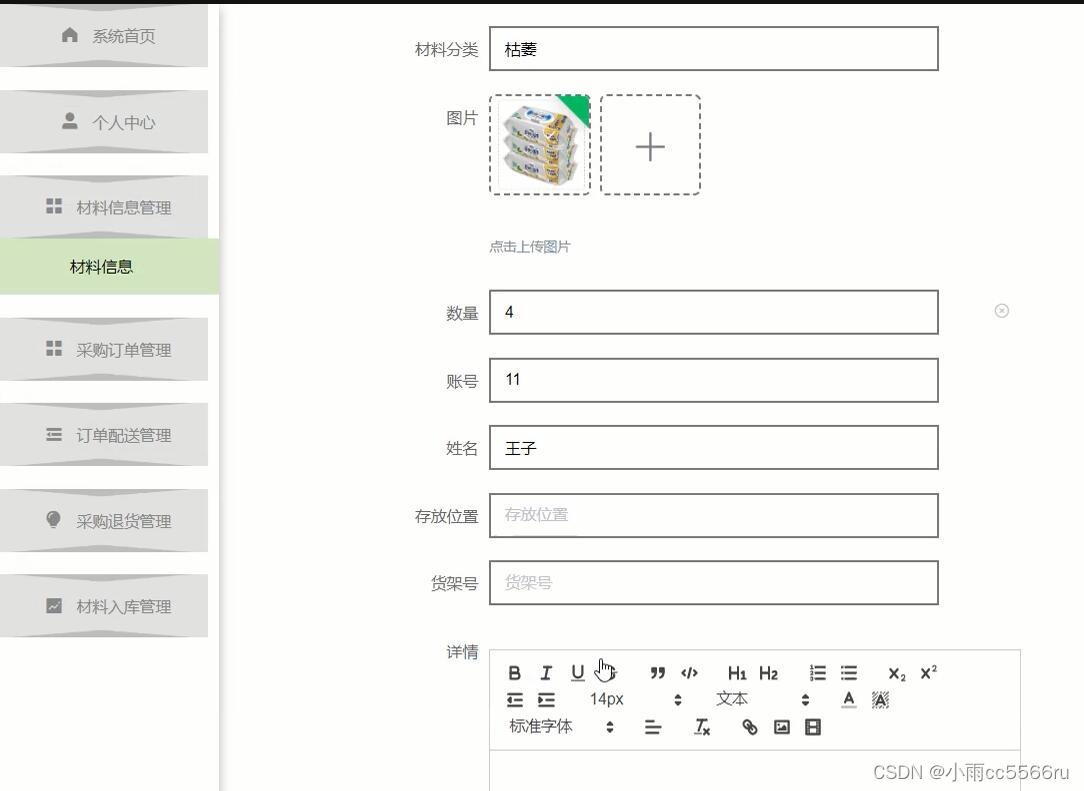
PhP+vue企业原材料采购系统_cxg0o
伴随着我国社会的发展,人民生活质量日益提高。互联网逐步进入千家万户,改变传统的管理方式,原材料采购系统以互联网为基础,利用php技术,结合vue框架和MySQL数据库开发设计一套原材料采购系统,提高工作效率的…...

C++线程池
原因 如果线程的数量很多,频繁的创建和销毁线程会降低系统的效率。线程池可以使线程复用。 using typedef 内联函数和宏定义区别: 内联函数代替部分#define宏定义;代替普通函数,提高程序效率...
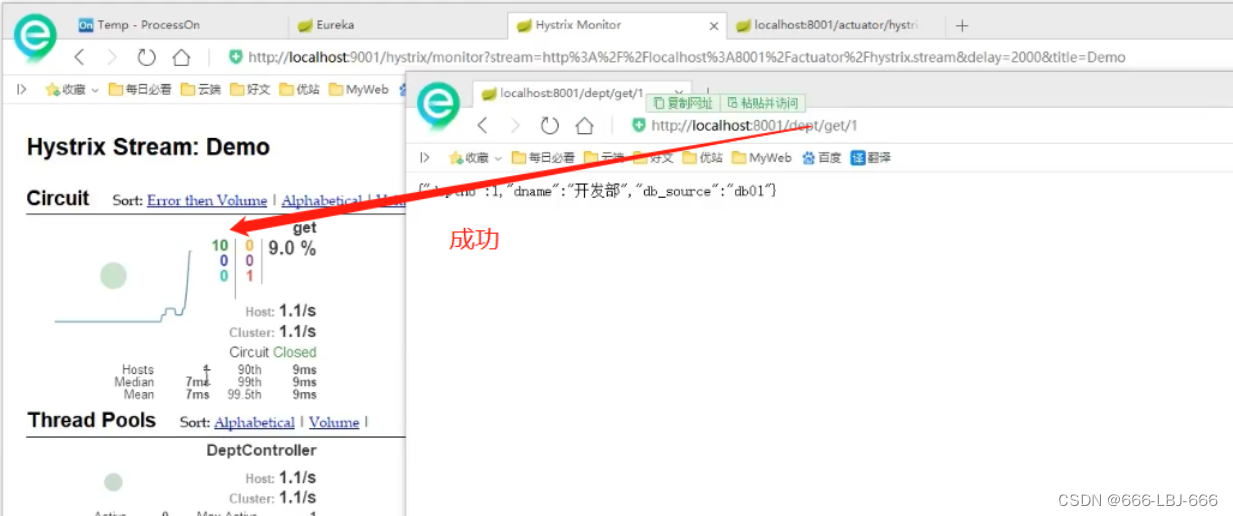
SpringCloud-Hystrix:服务熔断与服务降级
8. Hystrix:服务熔断 分布式系统面临的问题 复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免失败! 8.1 服务雪崩 多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服…...
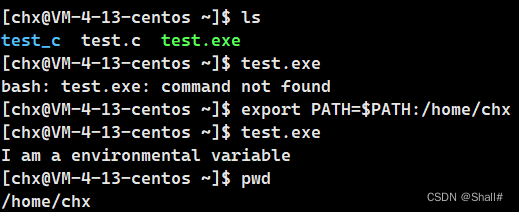
浅谈Linux环境
冯诺依曼体系结构: 绝大多数的计算机都遵守冯诺依曼体系结构 在冯诺依曼体系结构下各个硬件相互配合处理数据并反馈结果给用户 其中控制器和运算器统称为中央处理器(CPU),是计算机硬件中最核心的部分,像人类的大脑操控…...
Spring 用法学习总结(一)之基于 XML 注入属性
百度网盘: 👉 Spring学习书籍链接 Spring学习 1 Spring框架概述2 Spring容器3 基于XML方式创建对象4 基于XML方式注入属性4.1 通过set方法注入属性4.2 通过构造器注入属性4.3 使用p命名空间注入属性4.4 注入bean与自动装配4.5 注入集合4.6 注入外部属性…...
免费软件推荐-开源免费批量离线图文识别(OCR)
近期要批量处理图片转电子化,为了解决这个世纪难题,试了很多软件(华为手机自带OCR识别、 PandaOCR、天若OCR、Free OCR)等软件,还是选择了这一款,方便简单 一、什么是OCR? 光学字符识别(Opt…...

2 scala集合-元组和列表
1 元组 元组也是可以存放不同数据类型的元素,并且最重要的是,元组中的元素是不可变的。 例如,定义一个元组,包含字符串 hello,数字 20。如果试图把数字 20 修改为 1,则会报错。 scala> var a ("…...

Spring Boot开启SSL/Https进行交互。
为2个springboot工程开启进行SSL进行交互的认证步骤 //哪个犬玩意举报我侵权的? 一、认证步骤 1、 为服务器生成证书 keytool -genkey -v -alias testServer -keyalg RSA -keystore E:\ssl\testServer.p12 -validity 36500 2、 为客户端生成证书 keytool -genkey -v -alias…...

88.Go设计优雅的错误处理
文章目录 导言一、Go 的约定二、简单错误创建1、 errors.New()2、fmt.Errorf() 三、哨兵错误四、对错误进行编程1、优雅的错误处理设计2、与错误有关的的API 五、总结 导言 在 75.错误码设计、实现统一异常处理和封装统一返回结果 中,我们介绍了错误码的设计&#…...
Python4Delphi: Delphi 程序使用 Python 抓取网页
想用程序去抓取一个网页的内容,Delphi 有自己的 HTTP 库。比如 Indy 的 TIdHTTP,或者 TNetHTTPClient。 这里测试一下使用 Python 的 HTTP 库抓取网页,然后把抓取的内容给 Delphi 的程序。 Delphi 程序,界面上拖控件如下&#x…...

初次使用 Taotoken 模型广场进行模型选型与测试的流程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用 Taotoken 模型广场进行模型选型与测试的流程指引 对于刚接触大模型服务的开发者而言,面对众多厂商和模型&…...

基于CW32F030的BLDC电机控制:从国产MCU到完整评估方案
1. 项目概述:从一颗国产MCU到一套完整的BLDC评估方案最近在做一个直流无刷电机(BLDC)的小项目,选型时发现了一款挺有意思的国产MCU——武汉芯源的CW32F030C8T6,以及围绕它打造的一套完整的评估套件CW32_BLCD_EVA。对于…...

PX4开环控制避坑指南:为什么你的仿真无人机转圈总失败?从`setpoint_raw`话题到模式切换的深度解析
PX4开环控制避坑指南:为什么你的仿真无人机转圈总失败?从setpoint_raw话题到模式切换的深度解析 当你在Gazebo中启动PX4仿真环境,满怀期待地运行自己编写的开环控制代码,却发现无人机要么拒绝转圈,要么突然坠毁&#…...

PostgreSQL 13.8 子查询优化实战:手把手教你读懂 `pull_up_sublinks` 源码
PostgreSQL 13.8 子查询优化实战:手把手教你读懂 pull_up_sublinks 源码 数据库查询优化器是数据库系统的核心组件之一,它负责将用户提交的SQL语句转换为高效的执行计划。在PostgreSQL中,子查询优化是查询优化的重要环节,而pull_u…...
)
告别标注烦恼!用DINO+ViT自监督训练,5步搞定你的图像特征提取器(附代码)
5步实战DINOViT自监督训练:零标注构建高效图像特征提取器 在计算机视觉领域,数据标注一直是制约模型性能提升的瓶颈。传统监督学习需要大量人工标注数据,而高质量标注不仅成本高昂,还可能引入人为偏见。自监督学习(self-supervise…...
)
【微信取证篇】从微信收藏文件看微信存储加密逻辑(附解密工具思路)
1. 微信收藏文件的存储结构解析 第一次打开微信收藏夹时,你可能不会想到那些随手保存的图片、视频和文档,在手机存储里竟会以三种完全不同的形态存在。作为一名长期研究移动应用数据存储的开发者,我发现微信对收藏文件的处理方式堪称"精…...

RT-Thread裁剪实战:从98KB到28KB的嵌入式系统瘦身指南
1. 项目概述:为什么我们需要裁剪RT-Thread?如果你是一名嵌入式软件工程师,或者正在学习RT-Thread,那么“裁剪”这个词对你来说一定不陌生。RT-Thread作为一款优秀的国产开源实时操作系统,其标准版(或称完整…...

Mac视频预览终极指南:QuickLookVideo让你的Finder焕然一新
Mac视频预览终极指南:QuickLookVideo让你的Finder焕然一新 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gi…...

如何在MATLAB中调用Taotoken聚合大模型API进行智能分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在MATLAB中调用Taotoken聚合大模型API进行智能分析 对于使用MATLAB进行科学计算、数据分析或算法开发的工程师和研究人员而言&…...

LATENCY和INITIATION_INTERVAL同时约束时HLS决策
一、关于Latency和II同时约束 1.对同一个设计的II和latency同时约束,这两者在很多情况下是存在冲突的。 2.对同一个函数或者循环,使用HLS调度器来优化,HLS调度器内置设置了一些优先级的规则, 这种规则大多情况和设计者的直觉不一样…...