[嵌入式AI从0开始到入土]14_orangepi_aipro小修补含yolov7多线程案例
[嵌入式AI从0开始到入土]嵌入式AI系列教程
注:等我摸完鱼再把链接补上
可以关注我的B站号工具人呵呵的个人空间,后期会考虑出视频教程,务必催更,以防我变身鸽王。
第1期 昇腾Altas 200 DK上手
第2期 下载昇腾案例并运行
第3期 官方模型适配工具使用
第4期 炼丹炉的搭建(基于Ubuntu23.04 Desktop)
第5期 炼丹炉的搭建(基于wsl2_Ubuntu22.04)
第6期 Ubuntu远程桌面配置
第7期 下载yolo源码及样例运行验证
第8期 在线Gpu环境训练(基于启智ai协作平台)
第9期 转化为昇腾支持的om离线模型
第10期 jupyter lab的使用
第11期 yolov5在昇腾上推理
第12期 yolov5在昇腾上应用
第13期_orangepi aipro开箱测评
第14期 orangepi_aipro小修补含yolov7多线程案例
未完待续…
文章目录
- [嵌入式AI从0开始到入土]嵌入式AI系列教程
- 前言
- 一、opencv安装
- 1、下载源码
- 2、配置cmake
- 3、编译
- 4、安装
- 5、验证安装
- 二、torch_npu的安装
- 1、克隆torch_npu代码仓
- 2、构建镜像
- 3、进入Docker容器
- 4、编译torch_npu
- 5、安装
- 6、验证安装
- 三、sampleYOLOV7MultiInput案例
- 1、环境准备
- 2、下载模型和数据
- 3、转换模型
- 4、编译程序
- 5、运行推理
- 6、查看推理结果
- 四、问题
- 1、自动休眠问题
- 2、 vnc配置
- 3、dialog: command not found
- 3、apt autoremove
- 4、apt upgrade在firebox卡住
- 5、jupyter lab外部网络访问
- 6、jupyter需要输入密码或者token
- 总结
前言
注:本文基于orangepi_aipro于2023.2.3公布的ubuntu_desktop镜像
拿到手有段时间了,小问题还是比较的多的,整体上和Atlas 200i DK A2差不多。
emmm,没错,连产品名也套娃了。

说明:本文是作者测试成功并生成完善的镜像后写的,因此截图会比较少,存粹是因为为了一张图需要重走一遍,而一遍需要好几个小时,也可能需要好几遍才能把图凑齐。因此只挑重点截图了。
一、opencv安装
虽然镜像内带了opencv4.5.4,但是opencv应该是从4.7.0开始支持CANN后端的。这里我参考opencv官方github仓库的Wiki,重新编译了支持cann的opencv4.9.0,见文章顶部的资源。
至于为什么要换版本,看下图
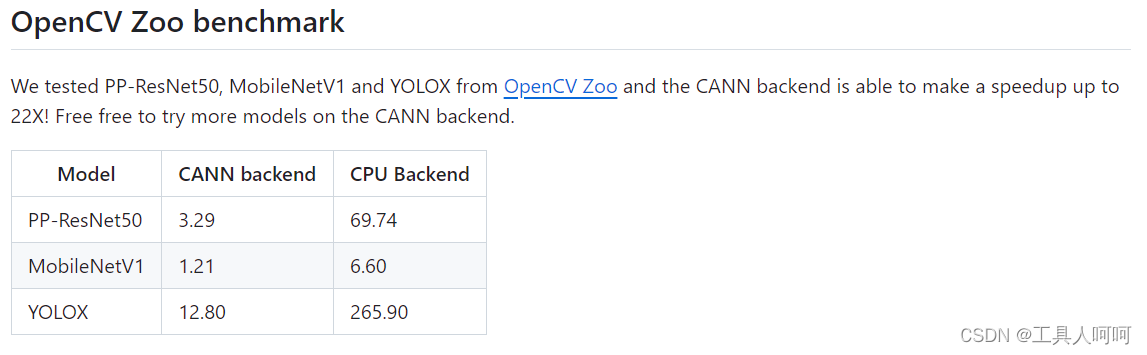
使用我提供的资源时,请将其放置于/home/HwHiAiUser目录下,进入/home/HwHiAiUser/opencv4/build目录,执行第四步即可
1、下载源码
git clone https://github.com/fengyuentau/opencv.git
cd opencv
git checkout cann_backend_221010git clone https://gitee.com/opencv/opencv.git #也可以直接使用gitee镜像
2、配置cmake
这里是大坑
cd opencv
mkdir build
cd build
cmake -D WITH_CANN=ON\-D PYTHON3_EXECUTABLE=/usr/local/miniconda3/bin/python3.9 \-D CMAKE_INSTALL_PREFIX=/usr \-D BUILD_opencv_python3=ON \-D BUILD_opencv_gapi=OFF \-D PYTHON3_LIBRARY=/usr/local/miniconda3/lib/libpython3.so \-D PYTHON3_INCLUDE_DIR=/usr/local/miniconda3/lib/ \-D PYTHON3_NUMPY_INCLUDE_DIRS=/usr/local/miniconda3/lib/python3.9/site-packages/numpy/core/include \..
-
不要更改
CMAKE_INSTALL_PREFIX参数,会导致python import或者cmake include报错找不到文件 -
请确保cmake后生成如下图所示的配置
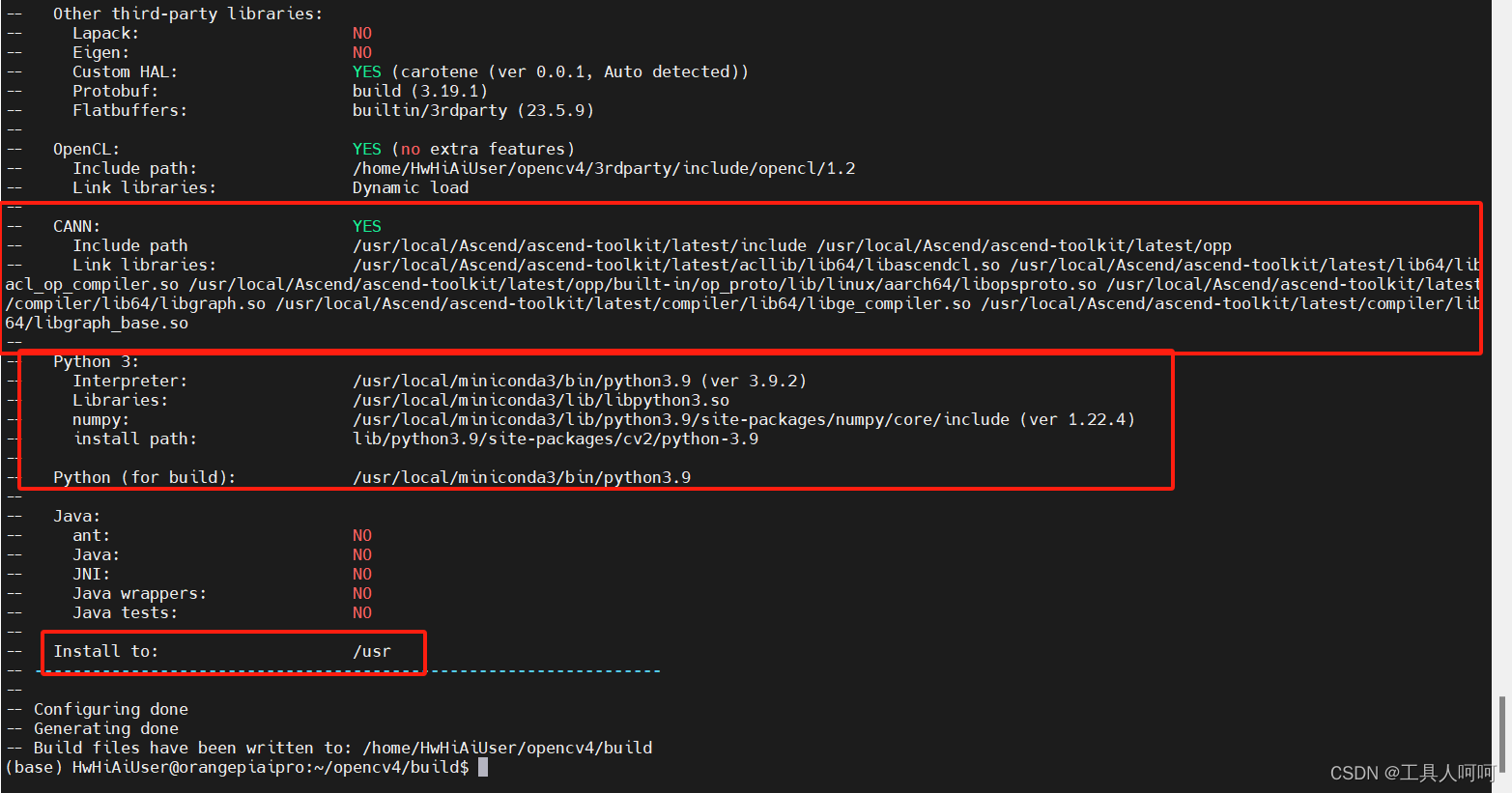
-
如非必要,在生成配置后,不要更改opencv文件夹包括内部文件的位置,否则将会导致错误。
-
如果你的python不是使用的官方镜像miniconda的base环境,需要在配置时修改为自己的路径
3、编译
make -j$(nproc) #-j$(nproc) 表示使用所有可用的 CPU 核心来并行编译
- 这里一定要在开发板上编译,大约需要2小时左右。
- 编译到97%后可能会报错
fatal error: Python.h: No such file or directory,实际上这个文件是在的,我尝试过各种方法,不仅没用,还导致从头开始编译。这里我用了一个最简单粗暴的方法,就是把/usr/local/miniconda3/include/python3.9整个文件夹内的东西都复制的到opencv/build文件夹内,完美解决。
4、安装
sudo make install
5、验证安装
新建mobilenetv1.py,执行python3 mobilenetv1.py
import numpy as np
import cv2 as cvdef preprocess(image):out = image.copy()out = cv.resize(out, (256, 256))out = out[16:240, 16:240, :]out = cv.dnn.blobFromImage(out, 1.0/255.0, mean=(0.485, 0.456, 0.406), swapRB=True)out = out / np.array([0.229, 0.224, 0.225]).reshape(1, -1, 1, 1)return outdef softmax(blob, axis=1):out = blob.copy().astype(np.float64)e_blob = np.exp(out)return e_blob / np.sum(e_blob, axis=axis)image = cv.imread("/path/to/image") # replace with the path to your image
input_blob = preprocess(image)net = cv.dnn.readNet("/path/to/image_classification_mobilenetv1_2022apr.onnx") # replace with the path to the model
net.setPreferableBackend(cv.dnn.DNN_BACKEND_CANN)
net.setPreferableTarget(cv.dnn.DNN_TARGET_NPU)net.setInput(input_blob)
out = net.forward()prob = softmax(out, axis=1)
_, max_prob, _, max_loc = cv.minMaxLoc(prob)
print("cls = {}, score = {:.4f}".format(max_loc[0], max_prob))
或者使用c++版本
CMakeList.txt
cmake_minimum_required(VERSION 3.5.1)
project(cann_demo)# OpenCV
find_package(OpenCV 4.6.0 REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})# PP-ResNet50
add_executable(ppresnet50 ppresnet50.cpp)
target_link_libraries(ppresnet50 ${OpenCV_LIBS})# MobileNetV1
add_executable(mobilenetv1 mobilenetv1.cpp)
target_link_libraries(mobilenetv1 ${OpenCV_LIBS})# YOLOX
add_executable(yolox yolox.cpp)
target_link_libraries(yolox ${OpenCV_LIBS})mobilenetv1.cpp
#include <iostream>
#include <vector>#include "opencv2/opencv.hpp"void preprocess(const cv::Mat& src, cv::Mat& dst)
{src.convertTo(dst, CV_32FC3);cv::cvtColor(dst, dst, cv::COLOR_BGR2RGB);// center cropcv::resize(dst, dst, cv::Size(256, 256));cv::Rect roi(16, 16, 224, 224);dst = dst(roi);dst = cv::dnn::blobFromImage(dst, 1.0/255.0, cv::Size(), cv::Scalar(0.485, 0.456, 0.406));cv::divide(dst, cv::Scalar(0.229, 0.224, 0.225), dst);
}void softmax(const cv::Mat& src, cv::Mat& dst, int axis=1)
{using namespace cv::dnn;LayerParams lp;Net netSoftmax;netSoftmax.addLayerToPrev("softmaxLayer", "Softmax", lp);netSoftmax.setPreferableBackend(DNN_BACKEND_OPENCV);netSoftmax.setInput(src);cv::Mat out = netSoftmax.forward();out.copyTo(dst);
}int main(int argc, char** argv)
{using namespace cv;Mat image = imread("/path/to/image"); // replace with the path to your imageMat input_blob;preprocess(image, input_blob);dnn::Net net = dnn::readNet("/path/to/image_classification_mobilenetv1_2022apr.onnx"); // replace with the path to the modelnet.setPreferableBackend(dnn::DNN_BACKEND_CANN);net.setPreferableTarget(dnn::DNN_TARGET_NPU);net.setInput(input_blob);Mat out = net.forward();Mat prob;softmax(out, prob, 1);double min_val, max_val;Point min_loc, max_loc;minMaxLoc(prob, &min_val, &max_val, &min_loc, &max_loc);std::cout << cv::format("cls = %d, score = %.4f\n", max_loc.x, max_val);return 0;
}
二、torch_npu的安装
这里我参考了官方文档
注意,需要提前安装docker
sudo apt install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt update
sudo apt install docker-ce
sudo systemctl start docker
sudo systemctl enable docker #设置Docker服务开机自启
sudo docker run hello-world #验证Docker是否安装成功
1、克隆torch_npu代码仓
git clone https://gitee.com/ascend/pytorch.git -b v2.1.0-5.0.0 --depth 1
2、构建镜像
cd pytorch/ci/docker/{arch} # {arch} for X86 or ARM
docker build -t manylinux-builder:v1 .
3、进入Docker容器
docker run -it -v /{code_path}/pytorch:/home/pytorch manylinux-builder:v1 bash
# {code_path} is the torch_npu source code path
4、编译torch_npu
cd /home/pytorch
bash ci/build.sh --python=3.9
5、安装
pip install ./torch_npu-2.1.0+gitb2bbead-cp39-cp39-linux_aarch64.whl
6、验证安装
终端执行
pythonimport torch
import torch_npux = torch.randn(2, 2).npu()
y = torch.randn(2, 2).npu()
z = x.mm(y)print(z)
三、sampleYOLOV7MultiInput案例
官方镜像内置的是python案例,缺少c++案例,我们访问仓库,获取案例
git clone https://gitee.com/ascend/samples.git
为了压榨板子,我选取了sampleYOLOV7MultiInput这个案例
1、环境准备
cd sample_master/inference/modelInference/sampleYOLOV7MultiInput
sudo apt install libx11-dev
sudo apt-get install libjsoncpp-dev
sudo ln -s /usr/include/jsoncpp/json/ /usr/include/json
vim src/main.cpp
#添加
#include <fstream>
sudo ln -s /usr/include/opencv4/opencv2 /usr/include/opencv2 #这样就不用去将opencv版本了
这里readme中说需要安装x264,ffmpeg,opencv(3.x版本),但是经过我实测,镜像内都已经内置了。
2、下载模型和数据
cd data
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/car0.mp4 --no-check-certificate
cd ../model
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/yolov7/yolov7x.onnx --no-check-certificate
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/yolov7/aipp.cfg --no-check-certificate
3、转换模型
atc --model=yolov7x.onnx --framework=5 --output=yolov7x --input_shape="images:1,3,640,640" --soc_version=Ascend310B4 --insert_op_conf=aipp.cfg
此处大约耗时10-15分钟。
4、编译程序
vim scripts/sample_build.sh
#将29行处make修改为以下内容,来使用多线程编译
make -j$(nproc)

sudo bash scripts/sample_build.sh
5、运行推理
bash scripts/sample_run.sh
注意,此处不要使用root用户执行,否则可能会提示找不到libascendcl.so
6、查看推理结果
推理大约需要1分钟,输出的视频在out文件夹,可以下载至本地查看
四、问题
1、自动休眠问题
这个问题仅存在于ubuntu桌面镜像,经过和群友的讨论和测试,在不登陆桌面的情况下大约5分钟会自动休眠,且无法唤醒。
目前解决方案如下,注意,这种方法会直接禁用休眠
sudo systemctl status sleep.target
sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target
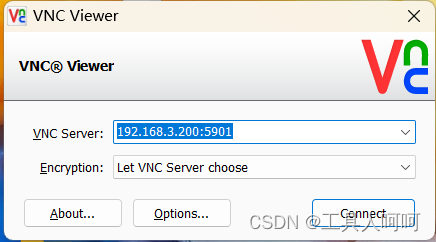
2、 vnc配置
vncserver
netstat -antup | grep vnc #查看vnc端口
vncserver -kill :3 #我们需要杀掉刚才启动的vnc服务,我这是3,视情况而定
vim .vnc/xstartup
#添加以下内容,否则没有桌面,是黑屏的
startxfce4 &
#修改完成后重新启动vnc
vncserver
在本地使用vncview等工具使用ip:端口的方式访问
3、dialog: command not found
这个错误多在使用apt命令的时候会遇到,在Linux系统中,尝试执行含有该命令的脚本或命令行操作时发生。
解决方案如下
sudo apt install dialog
3、apt autoremove
慎用,经大量测试,会导致卸载netplan.io,这将导致除你当前正在使用的网络外,其余的全部嗝屁。
解决方案
sudo apt-mark hold netplan.io
4、apt upgrade在firebox卡住
这个应该是snap导致的,如果你暂时不需要新版的firebox,使用以下指令跳过升级
sudo apt-mark hold firebox #升级时保留选定的软件包
当我们需要升级保留的软件包或者指定的软件包时执行
sudo apt-mark unhold firebox #删除保留设置
sudo apt --only-upgrade install package1 package2 #只升级指定的package
5、jupyter lab外部网络访问
这里使用镜像notebook文件夹内自带的start.sh只能在本地浏览器访问,因此我建议使用命令手动启动jupyter,记得把ip改成开发板的ip,或者将其写入start.sh文件内
jupyter lab --ip 192.168.3.200 --allow-root --no-browser
6、jupyter需要输入密码或者token
这个密码只能说防君子,还使得我们使用变得麻烦,因此我选择直接去掉
执行以下命令,二选一即可
jupyter notebook password #连续两次回车,密码就变成空白了,直接点登录即可
当然,作为终极懒人,这还是太麻烦了
jupyter lab --generate-config
vim /home/HwHiAiUser/.jupyter/jupyter_lab_config.py
#找到c.ServerApp.token这一行,修改为
c.ServerApp.token = ''
总结
不得不说,这个官方镜像小毛病还是挺多的,我已经打包了一份镜像,关注我B站动态获取。
相关文章:
[嵌入式AI从0开始到入土]14_orangepi_aipro小修补含yolov7多线程案例
[嵌入式AI从0开始到入土]嵌入式AI系列教程 注:等我摸完鱼再把链接补上 可以关注我的B站号工具人呵呵的个人空间,后期会考虑出视频教程,务必催更,以防我变身鸽王。 第1期 昇腾Altas 200 DK上手 第2期 下载昇腾案例并运行 第3期 官…...
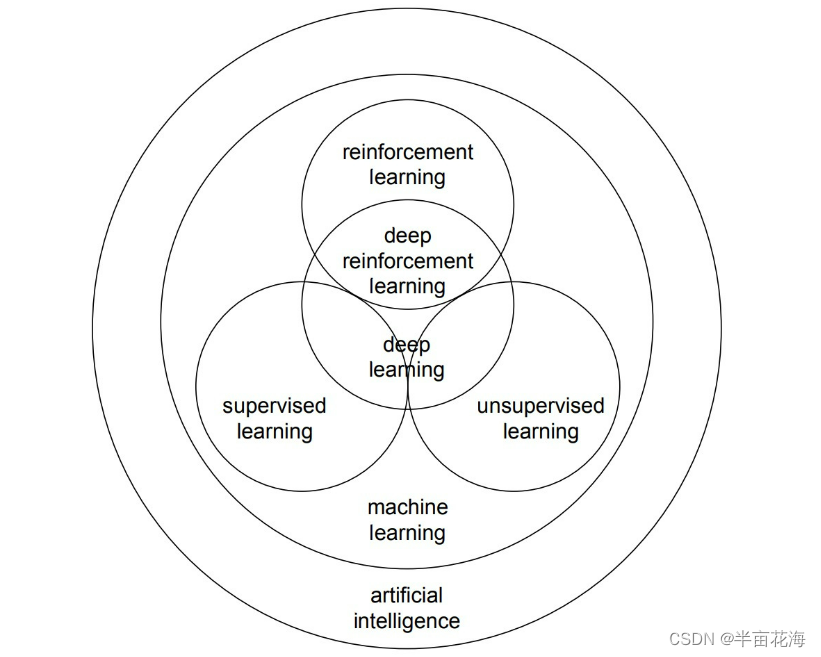
机器学习、深度学习、强化学习、迁移学习的关联与区别
Hi,大家好,我是半亩花海。本文主要了解并初步探究机器学习、深度学习、强化学习、迁移学习的关系与区别,通过清晰直观的关系图展现出四种“学习”之间的关系。虽然这四种“学习”方法在理论和应用上存在着一定的区别,但它们之间也…...

苹果为什么需要台积电3nm工艺芯片?
据《经济日报》报道,苹果公司的产品线将迎来重大升级。下一代应用于iPad、MacBook和iPhone的M4和A18处理器预计将会增加内置AI计算核心的数量,从而大幅提高AI运算能力。这一变化将导致对台积电(TSMC)订单的显著增长。据悉…...

力扣:53. 最大子数组和
解题思路: 1.先把数组为空和数组的长度为1时的特殊情况分别开来。声明一个sum变量用于计算数组中的连续子数组的总和值 。在声明一个guo变量用于一种接收sum中的前i-1的总和。另一种接收sum中前i的总和,主要根据sum的值来判断是接收的哪一种。在声明一个…...
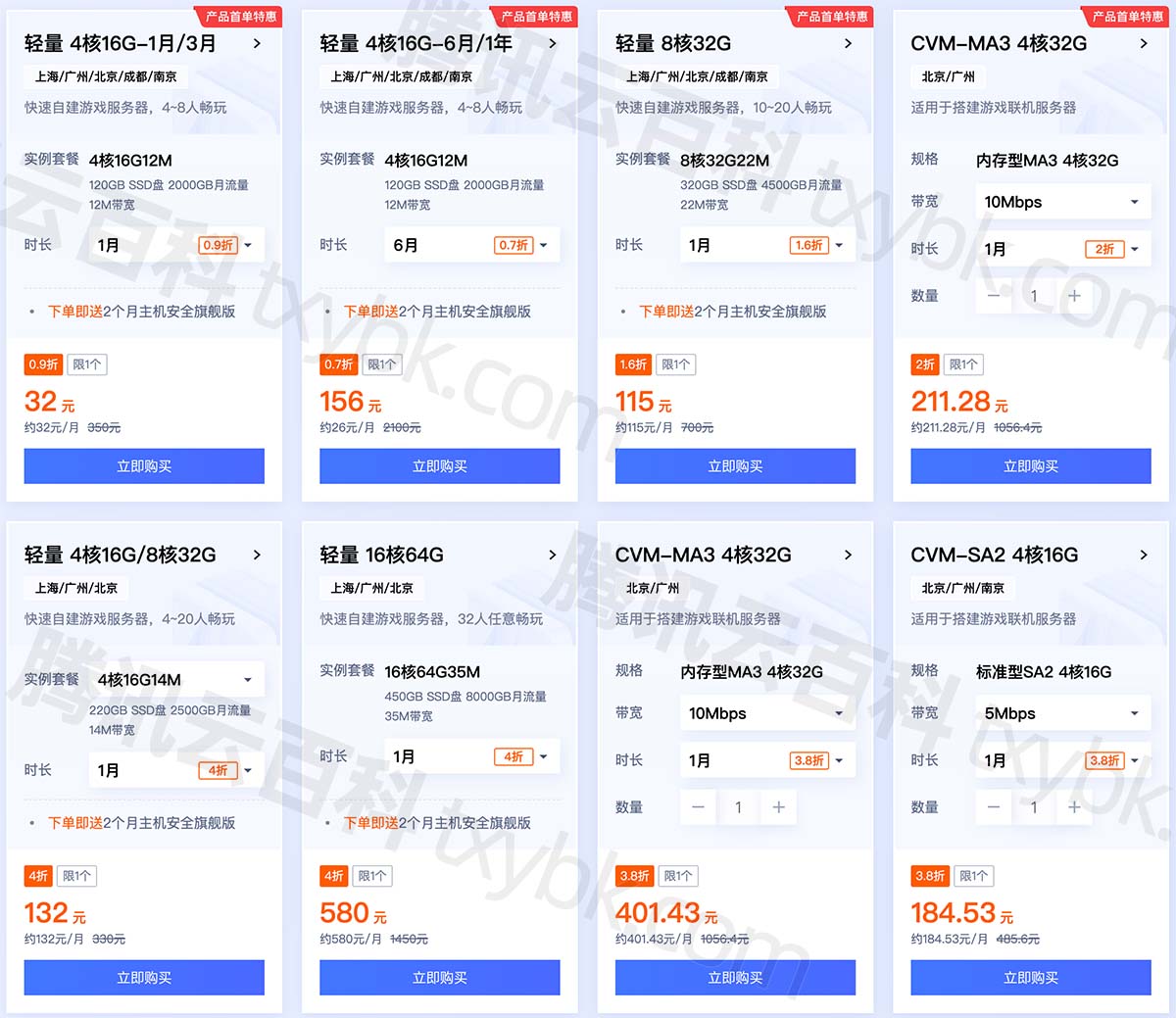
幻兽帕鲁Palworld专用服务器CPU内存配置怎么选择?
腾讯云幻兽帕鲁服务器配置怎么选?根据玩家数量选择CPU内存配置,4到8人选择4核16G、10到20人玩家选择8核32G、2到4人选择4核8G、32人选择16核64G配置,腾讯云百科txybk.com来详细说下腾讯云幻兽帕鲁专用服务器CPU内存带宽配置选择方法ÿ…...

学习总结11
KMP算法 全称Knuth-Morris-Pratt算法,是一种字符串匹配算法。该算法的目的是在一个文本串S内查找一个模式串P的出现位置。 KMP算法的核心思想是利用模式串自身的特性来避免不必要的字符比较。算法通过构建一个部分匹配表(也称为next数组)&a…...

Hadoop运行环境搭建
模板虚拟机环境准备 1)准备一台模板虚拟机hadoop100,虚拟机配置要求如下: 模板虚拟机:内存4G,硬盘50G,安装必要环境,为安装hadoop做准备 [roothadoop100 ~]# yum install -y epel-release [r…...
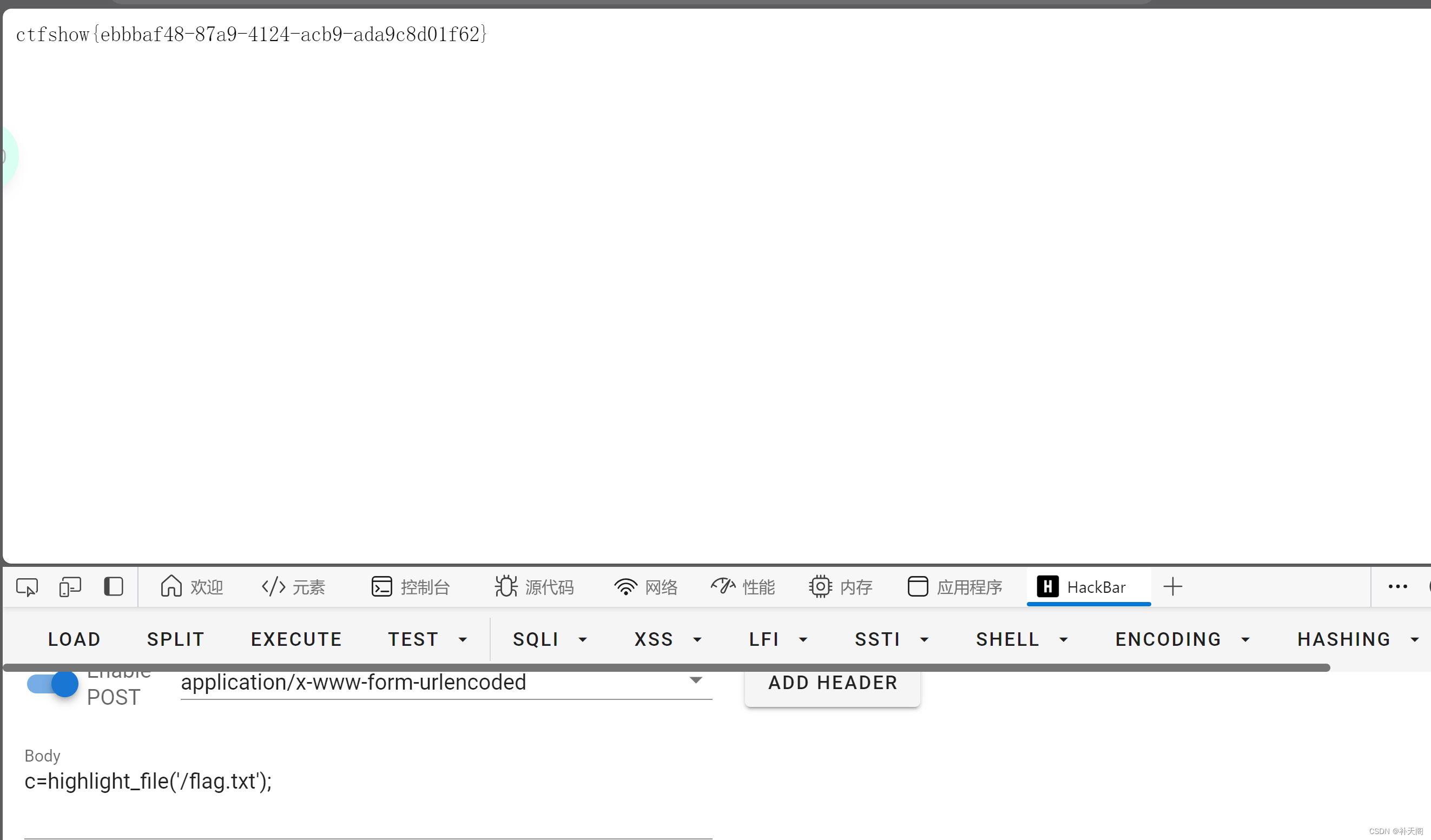
CTFshow web(php命令执行59-67)
web59 <?php /* # -*- coding: utf-8 -*- # Author: Lazzaro # Date: 2020-09-05 20:49:30 # Last Modified by: h1xa # Last Modified time: 2020-09-07 22:02:47 # email: h1xactfer.com # link: https://ctfer.com */ // 你们在炫技吗? if(isset($_POST…...
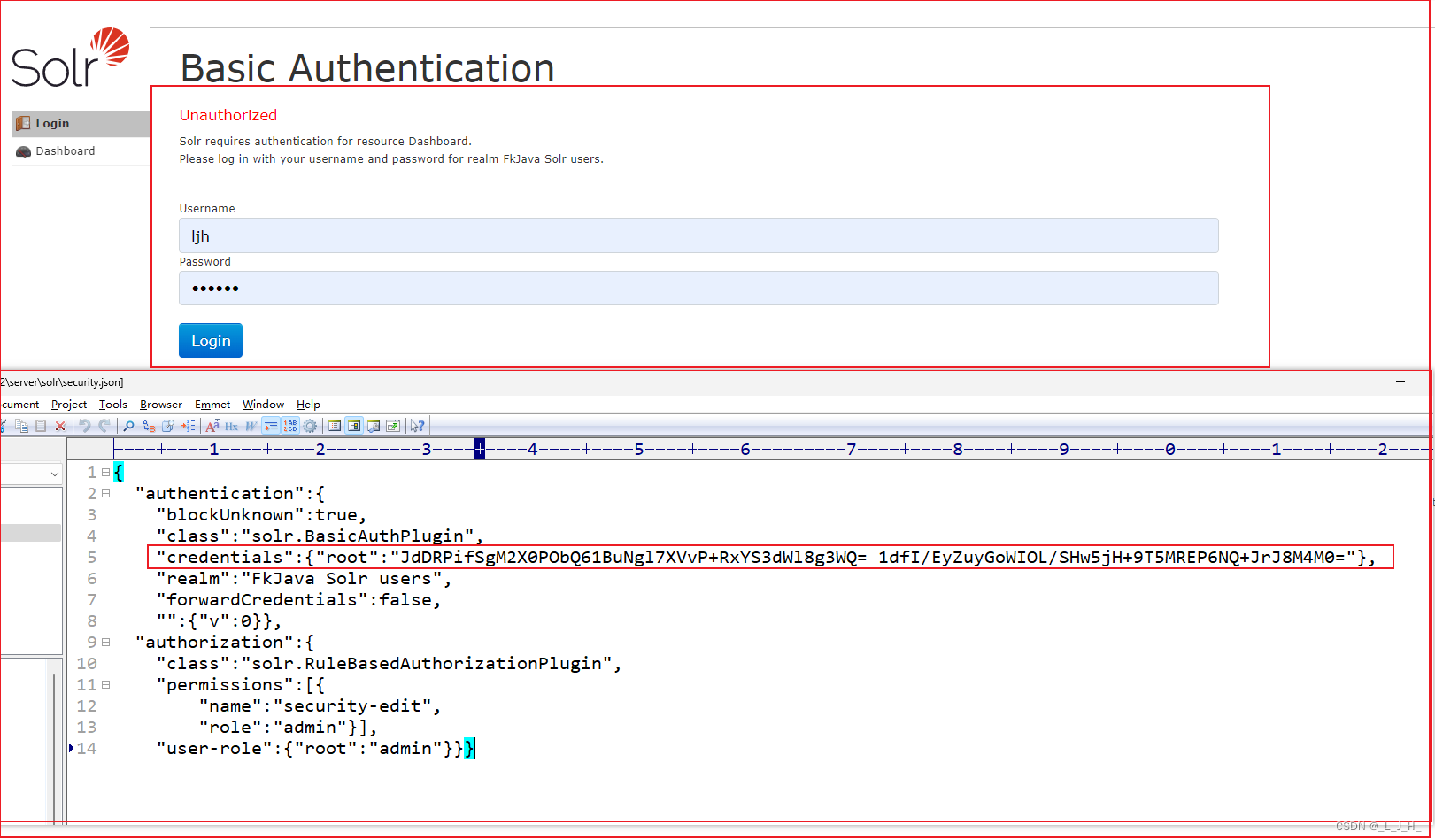
03、全文检索 -- Solr -- Solr 身份验证配置(给 Solr 启动身份验证、添加用户、删除用户)
目录 全文检索 -- Solr -- Solr 身份验证配置启用身份验证:添加用户:删除用户: 全文检索 – Solr – Solr 身份验证配置 学习之前需要先启动 Solr 执行如下命令即可启动Solr: solr start -p <端口>如果不指定端口…...
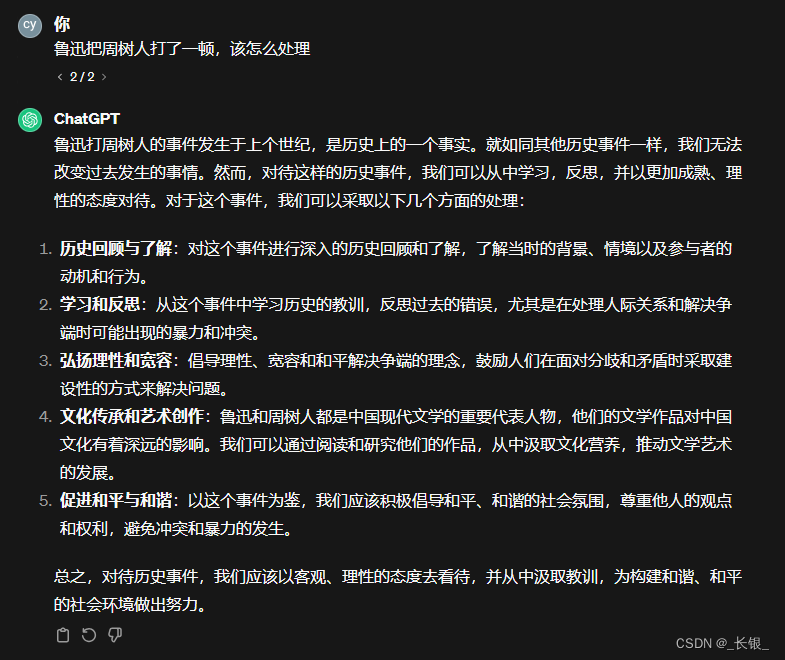
怎么使用ChatGPT提高工作效率?
怎么使用ChatGPT提高工作效率,这是一个有趣的话题。 相信不同的人有不同的观点,大家的知识背景和从事的工作都不完全相同,所以最终ChatGPT能起到的作用也不一样。 在编程过程中,如果我们要找一个库,我们最先做的肯定…...
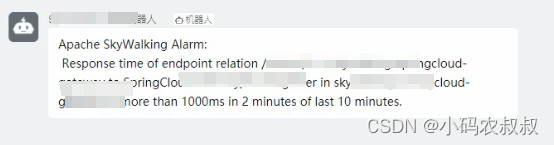
【微服务】skywalking自定义告警规则使用详解
目录 一、前言 二、SkyWalking告警功能介绍 2.1 SkyWalking告警是什么 2.2 为什么需要SkyWalking告警功能 2.2.1 及时发现系统异常 2.2.2 保障和提升系统稳定性 2.2.3 避免数据丢失 2.2.4 提高故障处理效率 三、 SkyWalking告警规则 3.1 SkyWalking告警规则配置 3.2 …...

BUGKU-WEB 矛盾
题目描述 进入场景看看: 代码如下: $num$_GET[num]; if(!is_numeric($num)) { echo $num; if($num1) echo flag{**********}; }解题思路 需要读懂一下这段PHP代码的意思明显是一道get相关的题目,需要提供一个num的参数,然后需要传入一个不…...

2024-02-11 Unity 编辑器开发之编辑器拓展2 —— 自定义窗口
文章目录 1 创建窗口类2 显示窗口3 窗口事件回调函数4 窗口中常用的生命周期函数5 编辑器窗口类中的常用成员6 小结 1 创建窗口类 当想为 Unity 拓展一个自定义窗口时,只需实现继承 EditorWindow 的类即可,并在该类的 OnGUI 函数中编写面板控件相关的…...
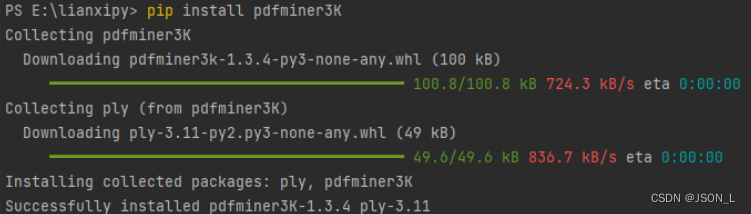
Python 读取pdf文件
Python 实现读取pdf文件简单示例。 安装命令 需要安装操作pdf的三方类库,命令如下: pip install pdfminer3K 安装过程如下: 引入类库 需要引入很多的类库。 示例如下: import sys import importlib importlib.reload(sys)fr…...

人究其一生只是在通用智能模型基础上作微调和对齐
Yann LeCun 在 WGS 上说: 目前的LLM不可能走到AGI,原因很简单,现在训练这些LLM所使用的数据量为10万亿个令牌,也就是130亿个词,如果你计算人类阅读这些数据需要多长时间,一个人每天阅读8小时,需…...
DS:二叉树的链式结构及实现
创作不易,友友们给个三连吧!! 一、前言 前期我们解释过二叉树的顺序结构(堆)为什么比较适用于完全二叉树,因为如果用数组来实现非完全二叉树,那么数组的中间部分就可能会存在大量的空间浪费。 …...
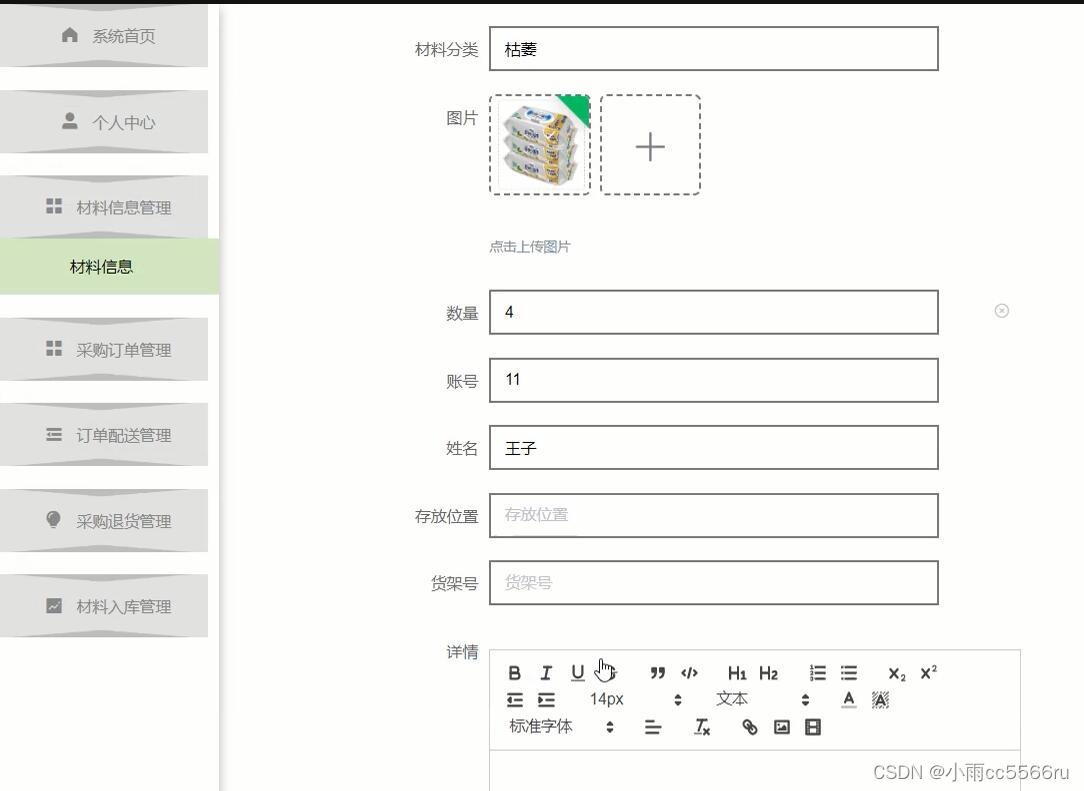
PhP+vue企业原材料采购系统_cxg0o
伴随着我国社会的发展,人民生活质量日益提高。互联网逐步进入千家万户,改变传统的管理方式,原材料采购系统以互联网为基础,利用php技术,结合vue框架和MySQL数据库开发设计一套原材料采购系统,提高工作效率的…...

C++线程池
原因 如果线程的数量很多,频繁的创建和销毁线程会降低系统的效率。线程池可以使线程复用。 using typedef 内联函数和宏定义区别: 内联函数代替部分#define宏定义;代替普通函数,提高程序效率...
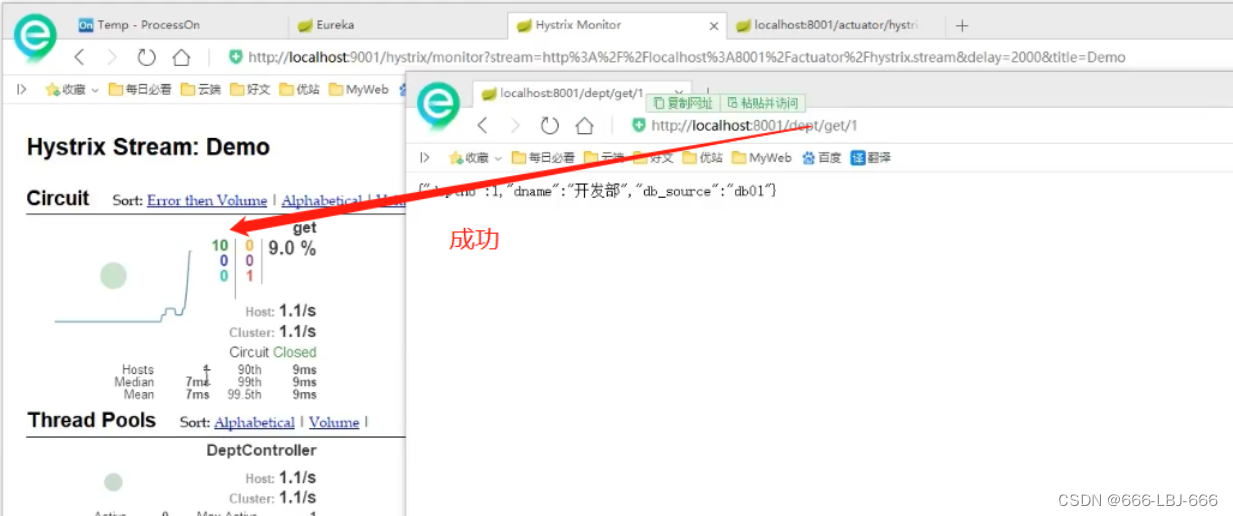
SpringCloud-Hystrix:服务熔断与服务降级
8. Hystrix:服务熔断 分布式系统面临的问题 复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免失败! 8.1 服务雪崩 多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服…...
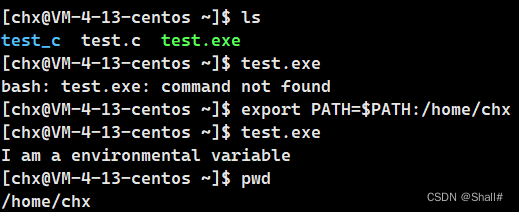
浅谈Linux环境
冯诺依曼体系结构: 绝大多数的计算机都遵守冯诺依曼体系结构 在冯诺依曼体系结构下各个硬件相互配合处理数据并反馈结果给用户 其中控制器和运算器统称为中央处理器(CPU),是计算机硬件中最核心的部分,像人类的大脑操控…...

ArcGIS 10.2也能用天地图!手把手教你用WMTS服务和lyr文件搞定低版本兼容
ArcGIS 10.2兼容天地图WMTS服务的工程级解决方案 在GIS项目实施过程中,我们常常会遇到软件版本滞后于服务更新的尴尬局面。天地图作为国内权威的地理信息服务,自2019年起仅支持ArcGIS 10.6及以上版本直接加载,这对仍在使用ArcGIS 10.2/10.3等…...

大模型小白必看:收藏!揭秘京东面试官如何破解多轮RAG“越聊越蠢”的难题
本文深入剖析多轮RAG在对话场景中容易出现的问题——越聊越“蠢”,即系统无法准确理解用户意图。文章指出,主要原因是历史对话内容污染了当前检索query,导致检索偏离用户真实意图。作者提出了四点判断框架:区分四类对象、检索quer…...
基于CircuitPython与NeoPixel的智能圣诞树:从硬件搭建到动态灯光算法
1. 项目概述:从零打造一棵会“思考”的圣诞树又到年底了,看着家里那棵年复一年、只会默默发光的传统圣诞树,总觉得少了点“灵魂”。作为一个常年和微控制器、代码打交道的创客,我总琢磨着能不能给节日装饰加点科技感,让…...

Perplexity图标搜索效率提升300%:从零配置到精准获取的5步实战工作流
更多请点击: https://kaifayun.com 第一章:Perplexity图标资源搜索 在构建与 Perplexity AI 集成的前端应用或开发调试工具时,获取其官方图标资源是品牌一致性与用户体验的关键环节。Perplexity 官方未提供公开的图标下载中心,但…...

嵌入式Linux应用开发实战:DR1平台GDB调试、Python优化与MQTT通信
1. 项目概述:从零到一,构建嵌入式Linux应用的实战手册最近在DR1平台上折腾了几个应用项目,从简单的数据采集到复杂的网络通信,整个过程踩了不少坑,也积累了不少心得。DR1作为一款资源受限但功能完整的嵌入式平台&#…...

智能硬件行业现状与未来趋势:技术、市场与盈利三重门解析
1. 项目概述:为什么现在要聊智能硬件?最近几年,身边的朋友、客户,甚至家里的长辈,都在问我同一个问题:“现在做智能硬件还有机会吗?” 这个问题背后,其实反映了一个普遍的行业焦虑&a…...
)
C盘告急?手把手教你用mklink命令把Fusion 360挪到D盘(Win11保姆级教程)
拯救C盘空间:用符号链接将Fusion 360迁移到D盘的完整指南 当C盘空间告急时,很多用户会发现Fusion 360默认安装在系统盘,占用了大量宝贵空间。本文将详细介绍如何利用Windows的mklink命令,在不影响软件功能的前提下,将F…...

在OpenClaw项目中接入Taotoken实现多模型Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw项目中接入Taotoken实现多模型Agent工作流 对于使用OpenClaw框架构建智能体工作流的开发者而言,如何稳定、灵…...

别再只用BLAST了!试试MAFFT+HMMER这套组合拳,挖掘基因家族新成员更精准
基因家族分析进阶指南:MAFFT与HMMER的高效组合策略 在基因组学研究领域,识别基因家族成员是一项基础而关键的工作。传统方法如BLAST虽然广为人知,但在面对远缘同源基因或高度分化的基因家族时,其灵敏度往往不尽如人意。这时&#…...

【亲测免费】 Zebra打印机中文转ZPL指令的.NET实现
Zebra打印机中文转ZPL指令的.NET实现 【下载地址】Zebra打印机中文转ZPL指令的.NET实现 本项目提供了一个用于将中文文本转换为ZPL指令的.NET实现,旨在替代Zebra官方提供的非托管组件FNTHEX32.DLL。该组件在托管环境下需要额外的封装,并且缺乏64位程序的…...