编译原理实验1——词法分析(python实现)
文章目录
- 实验目的
- 实现
- 定义单词对应的种别码
- 定义输出形式:三元式
- python代码实现
- 运行结果
- 检错处理
- 总结
实验目的
输入一个C语言代码串,输出单词流,识别对象包含关键字、标识符、整型浮点型字符串型常数、科学计数法、操作符和标点、注释等等。
实现
定义单词对应的种别码
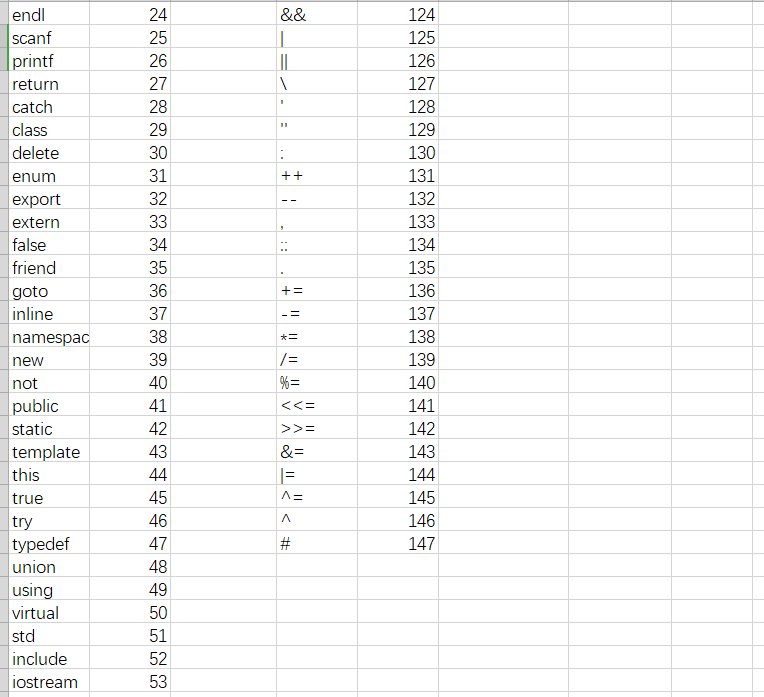
自行定义相关单词的种别码

定义输出形式:三元式
# 三元式
class ThreeFml: # 三元式def __init__(self, syn, inPoint, value):self.syn = syn # 种别码self.inPoint = inPoint # 内码值self.value = value # 自身值def __eq__(self, other): # 重载 判别对象相等的依据return self.syn == other.syn and self.value == other.valuedef __lt__(self, other): # 重载 比较对象大小关系的依据if self.syn == other.syn:return self.inPoint < other.inPointelse:return self.syn < other.syn
每个三元组用一个自定义类表示:
类属性:种别码syn、内码值inPoint、自身值value
类方法:
- 方法1:判断两个三元组相等的方法:种别码syn和自身值value相等
- 方法2:确定展示时的先后顺序的方法:先比较种别码syn,再比较内码值inPoint
例如:
- 输入:double a; int a;
- 输出:
- 分析:有两个标识符a,根据类方法1,判断前后两个a为同一个三元组,因此不重复输a。参见种别码表,double为6,int为2,则根据类方法2,进行三元组的展示排序。

python代码实现
import re# 三元式
class ThreeFml: # 三元式def __init__(self, syn, inPoint, value):self.syn = syn # 种别码self.inPoint = inPoint # 内码值self.value = value # 自身值def __eq__(self, other): # 重载 判别对象相等的依据return self.syn == other.syn and self.value == other.valuedef __lt__(self, other): # 重载 比较对象大小关系的依据if self.syn == other.syn:return self.inPoint < other.inPointelse:return self.syn < other.syn# 词法识别
class WordAnalysis:def __init__(self, input_code_str):self.input_code_str = input_code_str # 源程序字符串self.code_char_list = [] # 源程序字符列表self.code_len = 0 # 源程序字符列表长度self.cp = 0 # 源程序字符列表指针,方便遍历字符串中的字符self.cur = '' # 当前源程序字符列表的某个字符self.val = [] # 单词自身的值self.syn = 0 # 单词种别码self.errInfo = "" # 错误信息self.keyWords = ["main", "int", "short", "long", "float","double", "char", "string", "const", "void","struct", "if", "else", "switch", "case","default", "do", "while", "for", "continue","break", "cout", "cin", "endl", "scanf","printf", "return", 'catch', 'class', 'delete','enum', 'export', 'extern', 'false', 'friend','goto', 'inline', 'namespace', 'new', 'not','public', 'static', 'template', 'this', 'true','try', 'typedef', 'union', 'using', 'virtual','std', 'include', 'iostream'] # 关键字self.TFs = [] # 存储三元式def nextChar(self): # 封装cp++,简化函数scanWord中的代码self.cp += 1self.cur = self.code_char_list[self.cp]def error(self, info): # errInfo错误信息line = 1for i in range(0, self.cp + 1):if self.code_char_list[i] == '\n':line += 1self.errInfo = "第" + str(line) + "行报错:" + infodef bracket_match(self):pattern = r'(\/\/.*?$|\/\*(.|\n)*?\*\/)' # 匹配单行或多行注释comments = re.findall(pattern, self.input_code_str, flags=re.MULTILINE | re.DOTALL)comments = [comment[0].strip() for comment in comments] # 处理结果,去除多余的空格i = 0code_sub_com = [] # 去除注释print(f"comment: {comments}")while i < len(self.input_code_str):ch = self.input_code_str[i]if ch == "/" and comments != []:i += len(comments[0])comments.pop(0)continuecode_sub_com.append((i, ch))i += 1pattern2 = r'"([^"]*)"' # 匹配双引号包裹的字符串strings = re.findall(pattern2, self.input_code_str)code_sub_com_str = [] # 去除字符串变量i = 0while i < len(code_sub_com):item = code_sub_com[i]ch = item[1]if ch == "\"" and comments != []:i += len(strings[0]) + 2strings.pop(0)continuecode_sub_com_str.append(item)i += 1s = []stack = []mapping = {")": "(", "}": "{", "]": "["}for idx, char in code_sub_com_str:if char in mapping.keys() or char in mapping.values():s.append((idx, char))if not s:return "ok"for item in s:idx = item[0]char = item[1]if char in mapping.values(): # 左括号stack.append(item)elif char in mapping.keys(): # 右括号if not stack: # 栈为空,当前右括号匹配不到return idxtopitem = stack[-1]topidx = topitem[0]topch = topitem[1]if mapping[char] != topch: # 当前右括号匹配失败return topidxelse:stack.pop()if not stack: # 栈为空,匹配完毕return "ok"else: # 栈不为空,只剩下左括号item = stack[0]idx = item[0]return idxdef scanWord(self): # 词法分析# 初始化valueself.val = []self.syn = 0# ******获取当前有效字符(去除空白,直至扫描到第一个有效字符)******self.cur = self.code_char_list[self.cp]# print(f"==={self.cp} {self.code_len-1}===")while self.cur == ' ' or self.cur == '\n' or self.cur == '\t':self.cp += 1if self.cp >= self.code_len - 1:print(f"越界{self.cp}")return # 越界直接返回self.cur = self.code_char_list[self.cp]# ********************首字符为数字*****************if self.cur.isdigit():# ====首先默认为整数 ====i_value = 0while self.cur.isdigit(): # string数转inti_value = i_value * 10 + int(self.cur)self.nextChar()six_flag = Falseif (self.cur == 'x' or self.cur == 'X') \and self.code_char_list[self.cp - 1] == '0': # 十六进制整数 0x?????self.nextChar()six_flag = Trues = ""while self.cur.isdigit() or self.cur.isalpha():if self.cur.isalpha():if not (('a' <= self.cur <= 'f') or ('A' <= self.cur <= 'F')):self.syn = -999self.error("十六进制中的字母不为:a~f 或 A~F")returns += self.curself.nextChar()i_value = int(s, 16) # 将16进制数转为整数self.syn = 201self.val = str(i_value) # int转strif six_flag:return# ====有小数点或e,则为浮点数====d_value = i_value * 1.0if self.cur == '.':fraction = 0.1self.nextChar()while self.cur.isdigit(): # 计算小数位上的数 形如 123.45d_value += fraction * int(self.cur)fraction = fraction * 0.1self.nextChar()if self.cur == 'E' or self.cur == 'e': # 形如 123.4E?? 或 123.E??self.nextChar()powNum = 0if self.cur == '+': # 形如 123.4E+5self.nextChar()while self.cur.isdigit():powNum = powNum * 10 + int(self.cur)self.nextChar()d_value *= 10 ** powNumelif self.cur == '-': # 形如 123.4E-5self.nextChar()while self.cur.isdigit():powNum = powNum * 10 + int(self.cur)self.nextChar()d_value /= 10 ** powNumelif self.cur.isdigit(): # 形如 123.4E5while self.cur.isdigit():powNum = powNum * 10 + int(self.cur)self.nextChar()d_value *= 10 ** powNumif self.cur.isalpha():self.syn = -999self.error(f"科学计数法后含有多余字母{self.cur}")returnself.syn = 202self.val = str(d_value) # double转strelif self.cur == 'E' or self.cur == 'e': # 形如 123E??self.nextChar()powNum = 0if self.cur == '+': # 形如 123E+4self.nextChar()while self.cur.isdigit():powNum = powNum * 10 + int(self.cur)self.nextChar()d_value *= 10 ** powNumelif self.cur == '-': # 形如 123E-4self.nextChar()while self.cur.isdigit():powNum = powNum * 10 + int(self.cur)self.nextChar()d_value /= 10 ** powNumelif self.cur.isdigit(): # 形如 123E4while self.cur.isdigit():powNum = powNum * 10 + int(self.cur)self.nextChar()d_value *= 10 ** powNumif self.cur.isalpha():self.syn = -999self.error(f"科学计数法后含有多余字母{self.cur}")returnself.syn = 202self.val = str(d_value)# ********************首字符为字母*****************elif self.cur.isalpha():# ====标识符====while self.cur.isdigit() or self.cur.isalpha() or self.cur == '_':self.val.append(self.cur)self.nextChar()self.syn = 222# ====判断是否为关键字====for i, keyword in enumerate(self.keyWords):if ''.join(self.val) == keyword:self.syn = i + 1break# ********************首字符为标点*****************else:if self.cur == '+':self.syn = 101self.val.append(self.cur)self.nextChar()if self.cur == '+':self.syn = 131self.val.append(self.cur)self.nextChar()elif self.cur == '=':self.syn = 136self.val.append(self.cur)self.nextChar()elif self.cur == '-':self.syn = 102self.val.append(self.cur)self.nextChar()if self.cur == '-':self.syn = 132self.val.append(self.cur)self.nextChar()elif self.cur == '=':self.syn = 137self.val.append(self.cur)self.nextChar()elif self.cur == '*':self.syn = 103self.val.append(self.cur)self.nextChar()if self.cur == '=':self.syn = 138self.val.append(self.cur)self.nextChar()elif self.cur == '/':self.syn = 104self.val.append(self.cur)self.nextChar()if self.cur == '=':self.syn = 139self.val.append(self.cur)self.nextChar()# 单行注释elif self.cur == '/':self.nextChar()while self.cur != '\n':self.nextChar()self.syn = 0# 多行注释elif self.cur == '*':self.cp += 1haveEnd = Falseflag = 0for i in range(self.cp + 1, self.code_len):# print(self.code_char_list[i])if self.code_char_list[i - 1] == '*' and self.code_char_list[i] == '/':haveEnd = Trueflag = ibreakif haveEnd:self.syn = 0self.cp = flag + 1else:self.syn = -999self.error(" 多行注释没有结尾*/ ")elif self.cur == '%':self.syn = 105self.val.append(self.cur)self.nextChar()if self.cur == '=':self.syn = 140self.val.append(self.cur)self.nextChar()elif self.cur == '=':self.syn = 106self.val.append(self.cur)self.nextChar()if self.cur == '=':self.syn = 118self.val.append(self.cur)self.nextChar()elif self.cur == '(':self.syn = 107self.val.append(self.cur)self.nextChar()elif self.cur == ')':self.syn = 108self.val.append(self.cur)self.nextChar()elif self.cur == '[':self.syn = 109self.val.append(self.cur)self.nextChar()elif self.cur == ']':self.syn = 110self.val.append(self.cur)self.nextChar()elif self.cur == '{':self.syn = 111self.val.append(self.cur)self.nextChar()elif self.cur == '}':self.syn = 112self.val.append(self.cur)self.nextChar()elif self.cur == ';':self.syn = 113self.val.append(self.cur)self.nextChar()elif self.cur == '>':self.syn = 114self.val.append(self.cur)self.nextChar()if self.cur == '=':self.syn = 116self.val.append(self.cur)self.nextChar()elif self.cur == '>':self.syn = 119self.val.append(self.cur)self.nextChar()if self.cur == '=':self.syn = 141self.val.append(self.cur)self.nextChar()elif self.cur == '<':self.syn = 115self.val.append(self.cur)self.nextChar()if self.cur == '=':self.syn = 117self.val.append(self.cur)self.nextChar()elif self.cur == '<':self.syn = 120self.val.append(self.cur)self.nextChar()if self.cur == '=':self.syn = 142self.val.append(self.cur)self.nextChar()elif self.cur == '!':self.syn = 121self.val.append(self.cur)self.nextChar()if self.cur == '=':self.syn = 122self.val.append(self.cur)self.nextChar()elif self.cur == '&':self.syn = 123self.val.append(self.cur)self.nextChar()if self.cur == '&':self.syn = 124self.val.append(self.cur)self.nextChar()elif self.cur == '=':self.syn = 143self.val.append(self.cur)self.nextChar()elif self.cur == '|':self.syn = 125self.val.append(self.cur)self.nextChar()if self.cur == '|':self.syn = 126self.val.append(self.cur)self.nextChar()elif self.cur == '=':self.syn = 144self.val.append(self.cur)self.nextChar()elif self.cur == '\\': # \self.syn = 127self.val.append(self.cur)self.nextChar()elif self.cur == '\'': # ‘self.syn = 128self.val.append(self.cur)self.nextChar()elif self.cur == '\"': # ”self.nextChar()haveEnd = Falseflag = 0for i in range(self.cp, self.code_len):if self.code_char_list[i] == '"':haveEnd = Trueflag = ibreakif haveEnd:for j in range(self.cp, flag):self.val.append(self.code_char_list[j])self.cp = flag + 1self.cur = self.code_char_list[self.cp]self.syn = 203else:self.syn = -999self.error(" string常量没有闭合的\" ")elif self.cur == ':':self.syn = 130self.val.append(self.cur)self.nextChar()if self.cur == ':':self.syn = 134self.val.append(self.cur)self.nextChar()elif self.cur == ',':self.syn = 133self.val.append(self.cur)self.nextChar()elif self.cur == '^': # 按位异或self.syn = 146self.val.append(self.cur)self.nextChar()if self.cur == '=':self.syn = 145self.val.append(self.cur)self.nextChar()elif self.cur == '#':self.syn = 147self.val.append(self.cur)self.nextChar()else:self.syn = -999self.error(f" 无效字符: {self.cur}")def solve(self):print("\n================scan-main begin================")self.code_char_list = list(self.input_code_str.strip()) # 去除头尾的空格self.code_char_list.append('\n') # 末尾补充一个\n, 可在一些while判断中 防止越界self.code_len = len(self.code_char_list)if self.bracket_match() != "ok": # 检测括号匹配self.cp = self.bracket_match()self.error(f"{self.code_char_list[self.cp]}匹配缺失!")intCnt, doubleCnt, stringCnt, idCnt = 0, 0, 0, 0 # 内码值while True: # 至少执行一次,如同do whileself.scanWord() # 进入词法分析value = ''.join(self.val) # char列表 ===> Stringnew_tf = ThreeFml(self.syn, -1, value) # 创建三元式对象if self.syn == 201: # 整型常数# print(f"整型常数: {value}")if not any(tf == new_tf for tf in self.TFs): # append前先判断是否有重复intCnt += 1new_tf.inPoint = intCntself.TFs.append(new_tf)elif self.syn == 202: # 浮点型常数# print(f"浮点型常数: {value}")if not any(tf == new_tf for tf in self.TFs):doubleCnt += 1new_tf.inPoint = doubleCntself.TFs.append(new_tf)elif self.syn == 203: # 字符串常数# print(f"字符串常数: {value}")if not any(tf == new_tf for tf in self.TFs):stringCnt += 1new_tf.inPoint = stringCntself.TFs.append(new_tf)elif self.syn == 222: # 标识符# print(f"标识符: {value}")if not any(tf == new_tf for tf in self.TFs):idCnt += 1new_tf.inPoint = idCntself.TFs.append(new_tf)elif 1 <= self.syn <= 100: # 关键字# print(f"关键字: {value}")if not any(tf == new_tf for tf in self.TFs):new_tf.inPoint = 1self.TFs.append(new_tf)elif self.syn == 0: # 注释内容、或者最后的\n# print("注释 or 结束")passelif self.syn == -999: # 报错# print(f"error: {self.errInfo}")breakelse: # 符号:标点符、算符# print(f"符号: {value}")if not any(tf == new_tf for tf in self.TFs):new_tf.inPoint = 1self.TFs.append(new_tf)if self.cp >= (self.code_len - 1): # 最后一个元素 为自主添加的\n,代表结束# print(f"{cp} 跳出")breakif self.errInfo: # 检查是否有报错print(self.errInfo)returnself.TFs.sort() # 给三元式列表TFs排序(按种别码、内码)for tf in self.TFs: # 打印print(f"({tf.syn}, {tf.inPoint}, {tf.value})")print("================scan-main end================")if __name__ == '__main__':filepath = "./code.txt"with open(filepath, "r") as file:code = file.read()word_analysis = WordAnalysis(code)word_analysis.solve()运行结果
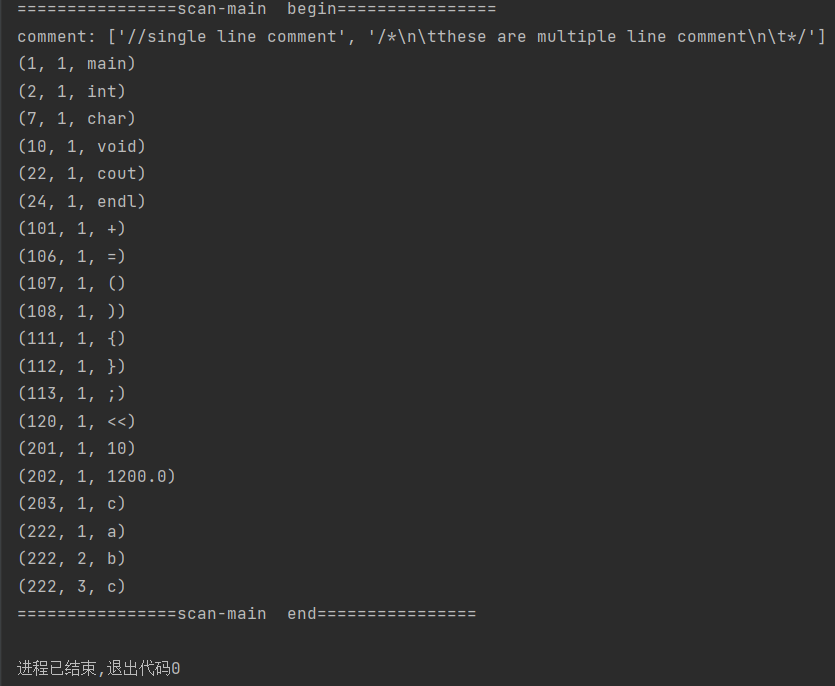
输入:通过读取txt文件输入要分析的源程序串

输出:
第一行表示注释内容
后面为三元式(种别码,内码值,自身值)
从结果可以看到:
- 输入代码串中有两个int关键字,并没有重复输出,只保留1个
- 输入代码串中识别到多个标识符(我设定的种别码为222),由于它们的值不同,所以在种别码相同的情况下,给出不同的内码值。
检错处理
括号匹配

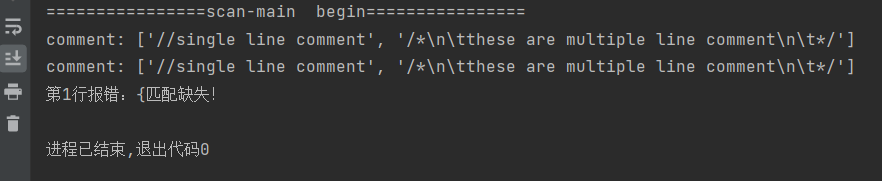
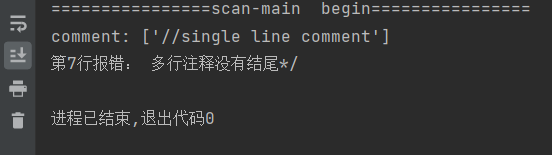
字符串常量未闭合


多行注释未闭合

十六进制数不规范


科学计数法不规范


总结
体会
在本次的实验中,通过对词法分析器的编写,在理论的基础上加深了对词法分析的理解和实践,所编写的词法分析器在多次的测试中均得到了正确的结果。
此外,我是先用c++编写的代码,确认大部分功能无误后,再改用python编写。在改语言的过程中,明显感受到python 的便利之处,就比如一个简单的判断字符是否为字母,在c++里需要自定义一个函数来判断(if ch>=’a’ and if ch<=’z’),而python则直接使用系统自带的isalpha函数即可,大大简化了代码量。
问题
编写的程序中,虽然已完成绝大部分单词分析功能,但对一些小细节就没有进行直接的编写。例如在识别用科学表示法表示的浮点型常量时,并没有考虑是否会溢出C++语言中的double类型,当然,这也可以认为是语义分析的任务,而非词法分析的任务,但这可以是程序改善的一处地方。
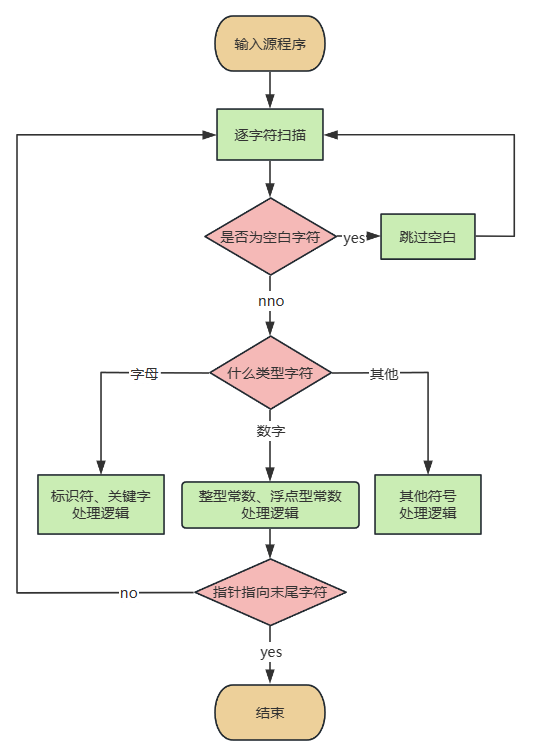
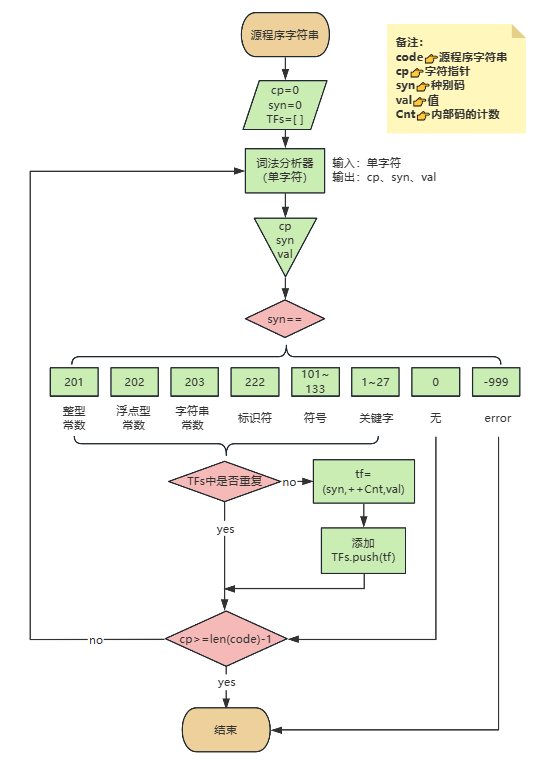
附思路流程图
总体逻辑:
主函数逻辑
相关文章:
编译原理实验1——词法分析(python实现)
文章目录 实验目的实现定义单词对应的种别码定义输出形式:三元式python代码实现运行结果检错处理 总结 实验目的 输入一个C语言代码串,输出单词流,识别对象包含关键字、标识符、整型浮点型字符串型常数、科学计数法、操作符和标点、注释等等。…...

C语言——oj刷题——模拟实现库函数strlen
目录 方法一:迭代法 方法二:递归法 方法三:指针算术法 方法四:汇编指令法 当我们使用C语言进行字符串操作时,经常会用到库函数strlen来获取字符串的长度。strlen函数的作用是计算一个以null字符结尾的字符串的长度…...
对进程与线程的理解
目录 1、进程/任务(Process/Task) 2、进程控制块抽象(PCB Process Control Block) 2.1、PCB重要属性 2.2、PCB中支持进程调度的一些属性 3、 内存分配 —— 内存管理(Memory Manage) 4、线程(Thread)…...

「数据结构」线性表
定义和基本操作 定义:相同数据类型的 n ( n ≥ 0 ) n(n \ge 0) n(n≥0)个数据元素的有限序列,其中n为表长,当n0时线性表是一个空表一般表示: L ( a 1 , a 2 , … … , a i , a i 1 , a n ) L(a_1,a_2,……,a_i,a_{i1},a_n) L(a…...

GEE:关于在GEE平台上进行回归计算的若干问题
作者:CSDN _养乐多_ 记录一些在Google Earth Engine (GEE)平台上进行机器学习回归计算的问题和解释。 文章目录 一、回归1.1 问:GEE平台上可以进行哪些机器学习回归算法?1.2 问:为什么只有这四种…...

Vivado -RAM
ip_ram 定义了一个名为ip_ram的模块,该模块具有以下端口: sys_clk:系统时钟输入。 sys_rst_n:系统复位输入。 module ip_ram( input sys_clk, input sys_rst_n);wire ram_en ; wire ram_wea …...
备战蓝桥杯---图论之最短路dijkstra算法
目录 先分个类吧: 1.对于有向无环图,我们直接拓扑排序,和AOE网类似,把取max改成min即可。 2.边权全部相等,直接BFS即可 3.单源点最短路 从一个点出发,到达其他顶点的最短路长度。 Dijkstra算法&#x…...
)
C#系列-C#实现秒杀功能(14)
在C#中实现商品秒杀功能,通常需要考虑并发控制、数据库事务、缓存策略、限流措施等多个方面。下面是一个简单的示例,演示了如何使用C#和数据库来实现一个基本的商品秒杀功能。 首先,假设你有一个商品表(Product)和一个…...

Java ‘Elasticsearch‘ 操作
依赖 <!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-elasticsearch --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</ar…...

【AI视野·今日NLP 自然语言处理论文速览 第七十八期】Wed, 17 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 17 Jan 2024 (showing first 100 of 163 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Deductive Closure Training of Language Models for Coherence, Accur…...

实验5-4 使用函数计算两点间的距离
本题要求实现一个函数,对给定平面任意两点坐标(x1,y1)和(x2,y2),求这两点之间的距离。 函数接口定义: double dist( double x1, double y1, double x2, double y2 );其中用户传入的参数为平面上两个点的坐标(x1, y1)和(x2, y2)&…...
【JavaEE】_JavaScript(Web API)
目录 1. DOM 1.1 DOM基本概念 1.2 DOM树 2. 选中页面元素 2.1 querySelector 2.2 querySelectorAll 3. 事件 3.1 基本概念 3.2 事件的三要素 3.3 示例 4.操作元素 4.1 获取/修改元素内容 4.2 获取/修改元素属性 4.3 获取/修改表单元素属性 4.3.1 value…...

ARM交叉编译搭建SSH
首先搭建好arm-linux交叉编译环境,开发板和主机可以ping通。 一、下载需要的源码 下载zlib: zlib-1.2.3.tar.gz 下载ssl: openssl-0.9.8d.tar.gz 下载ssh: openssh-4.6p1.tar.gz 二、交叉编译 新建目录/home/leo/ssh,并且将三个源码复制到该目录下。…...

###51单片机学习(2)-----如何通过C语言运用延时函数设计LED流水灯
前言:感谢您的关注哦,我会持续更新编程相关知识,愿您在这里有所收获。如果有任何问题,欢迎沟通交流!期待与您在学习编程的道路上共同进步。 目录 一. 延时函数的生成 1.通过延时计算器得到延时函数 2.可赋值改变…...

回归预测模型:MATLAB多项式回归
1. 多项式回归模型的基本原理 多项式回归是线性回归的一种扩展,用于分析自变量 X X X与因变量 Y Y Y之间的非线性关系。与简单的线性回归模型不同,多项式回归模型通过引入自变量的高次项来增加模型的复杂度,从而能够拟合数据中的非线性模式。…...

「计算机网络」数据链路层
数据链路层的地位:网络中的主机、路由器等都必须实现数据链路层信道类型 点对点信道:使用一对一的点对点通信方式广播信道 使用一对多的广播通信方式必须使用专用的共享信道协议来协调这些主机的数据发送 使用点对点信道的数据链路层 数据链路和帧 链…...

【Linux】Ubuntu 22.04 升级 nodejs 到 v18
Ubuntu 22.04 已经安装的nodejs 版本 nodejs is already the newest version (12.22.9~dfsg-1ubuntu3.3). 删除以前的 nodejs 版本: 1. sudo apt remove nodejs rooterp:~# sudo apt remove nodejs Reading package lists... Done Building dependency tree..…...

当go get获取不到软件包时
当使用go get命令获取软件包时,如果无法成功获取,您可以尝试以下方法来解决问题: 检查网络连接:首先,确保您的计算机能够访问互联网,并且没有任何网络防火墙或代理设置阻止了go get命令的正常运行。 设置代…...

全网最详细解法|同济大学|高等数学|第八版|习题1-5
文章目录 全网最详细解法|同济大学|高等数学|第八版|习题1-5|5.1全网最详细解法|同济大学|高等数学|第八版|习题1-5|5.2 全网最详细解法|同济大学…...
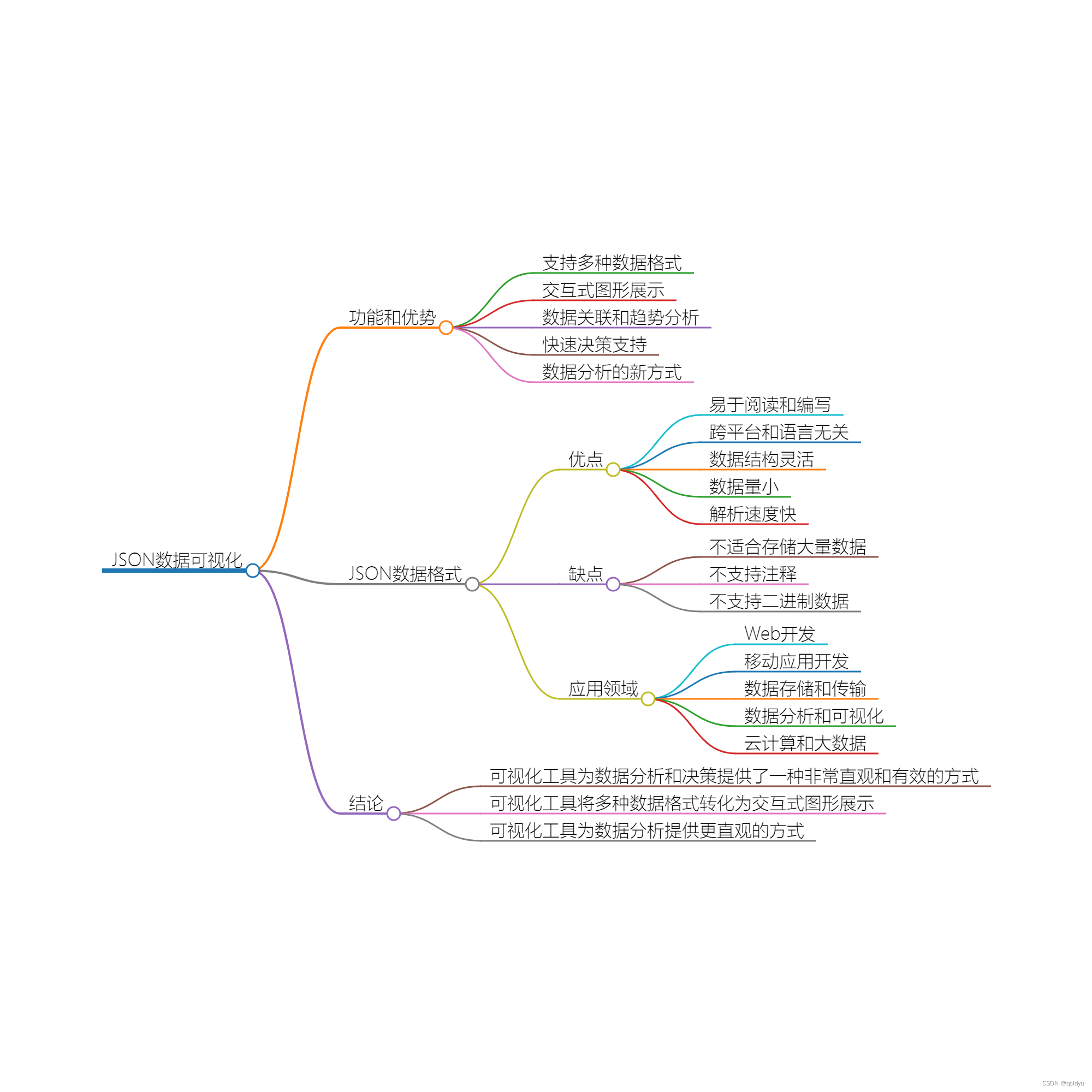
可视化工具:将多种数据格式转化为交互式图形展示的利器
引言 在数据驱动的时代,数据的分析和理解对于决策过程至关重要。然而,不同的数据格式和结构使得数据的解读变得复杂和困难。为了解决这个问题,一种强大的可视化工具应运而生。这个工具具有将多种数据格式(包括JSON、YAML、XML、C…...

高级磁盘空间管理:WinDirStat深度配置与自动化清理指南
高级磁盘空间管理:WinDirStat深度配置与自动化清理指南 【免费下载链接】windirstat WinDirStat is a disk usage statistics viewer and cleanup tool for Microsoft Windows 项目地址: https://gitcode.com/gh_mirrors/wi/windirstat 在当今数据爆炸的时代…...

Perplexity实时新闻查询失效真相:Webhook劫持、缓存穿透与CDN时钟漂移三重陷阱
更多请点击: https://codechina.net 第一章:Perplexity实时新闻查询失效真相:Webhook劫持、缓存穿透与CDN时钟漂移三重陷阱 Perplexity 的实时新闻查询功能近期频繁返回陈旧或空结果,表面看是 API 延迟,实则深陷 Webh…...

小学期第一周作业
...

MySQL通用查询日志写Webshell:绕过过滤的侧信道攻击详解
1. 从常规注入到日志利用:一个被忽视的攻击路径在渗透测试或者安全审计中,我们常常会遇到一些“硬骨头”——目标系统对常见的SQL注入利用方式做了严格的过滤。outfile、dumpfile这些直接写文件的函数被禁用了,drop database这类高危操作也被…...

TikTok 短视频生成工具哪家好?TikTok 爆款视频复刻,有什么工具推荐
在 TikTok 流量竞争愈发激烈的 2026 年,想要快速起号、稳定爆单,离不开优质短视频量产和爆款视频复刻。不用从零原创创作,借助成熟 AI 工具复刻平台热门爆款,已经成为跨境卖家和内容创作者的主流玩法。 不少人都在纠结两大问题&a…...

别再混淆了!用PyTorch代码带你彻底搞懂PointNet里的Shared MLP和普通MLP
用PyTorch代码解密PointNet中的Shared MLP与普通MLP本质差异 第一次阅读PointNet论文时,看到"Shared MLP"这个术语总让人困惑——它和普通MLP到底有什么区别?为什么点云处理非要强调"共享"这个概念?本文将通过PyTorch代码…...

从鼠类到人体:汉坦病毒的全球威胁与科研突破
2026年5月17日,加拿大正式确诊一名“洪迪厄斯”号邮轮乘员感染汉坦病毒。结合世界卫生组织(WHO)的通报,疫情已陆续造成9人感染并出现3例死亡。这引起广泛的关注和担忧。汉坦病毒究竟是哪类病毒呢?感染力强吗࿱…...

M9A:重返未来1999自动化助手 - 解放双手的智能游戏管家
M9A:重返未来1999自动化助手 - 解放双手的智能游戏管家 【免费下载链接】M9A 重返未来:1999 小助手 | Assistant For Reverse: 1999 项目地址: https://gitcode.com/gh_mirrors/m9/M9A 你是否厌倦了每天重复刷取《重返未来:1999》的日…...

Video2X:你的AI视频画质修复专家,让老旧视频重获新生
Video2X:你的AI视频画质修复专家,让老旧视频重获新生 【免费下载链接】video2x A machine learning-based video super resolution and frame interpolation framework. Est. Hack the Valley II, 2018. 项目地址: https://gitcode.com/GitHub_Trendin…...

告别‘涂抹感’:深入浅出聊聊Chromatix ISP里ABF模块的‘边缘保留’与‘噪声消除’如何平衡
告别‘涂抹感’:深入浅出聊聊Chromatix ISP里ABF模块的‘边缘保留’与‘噪声消除’如何平衡 在手机摄影普及的今天,我们常常会遇到这样的困扰:夜间拍摄的照片要么噪点明显,要么经过降噪处理后变得模糊不清,丢失了细节…...