机器学习:过拟合和欠拟合的介绍与解决方法

过拟合和欠拟合的表现和解决方法。
其实除了欠拟合和过拟合,还有一种是适度拟合,适度拟合就是我们模型训练想要达到的状态,不过适度拟合这个词平时真的好少见。
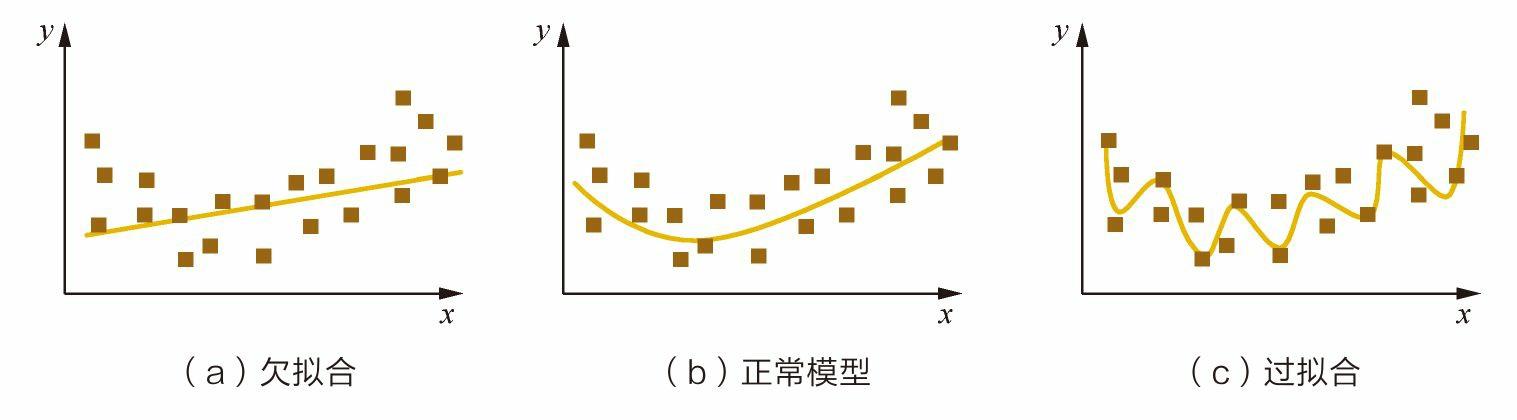
过拟合
过拟合的表现
模型在训练集上的表现非常好,但是在测试集、验证集以及新数据上的表现很差,损失曲线呈现一种高方差,低偏差状态。(高方差指的是训练集误差较低,而测试集误差比训练集大较多)
过拟合的原因
从两个角度去分析:
- 模型的复杂度:模型过于复杂,把噪声数据的特征也学习到模型中,导致模型泛化性能下降
- 数据集规模大小:数据集规模相对模型复杂度来说太小,使得模型过度挖掘数据集中的特征,把一些不具有代表性的特征也学习到了模型中。例如训练集中有一个叶子图片,该叶子的边缘是锯齿状,模型学习了该图片后认为叶子都应该有锯齿状边缘,因此当新数据中的叶子边缘不是锯齿状时,都判断为不是叶子。
过拟合的解决方法
-
获得更多的训练数据:使用更多的训练数据是解决过拟合问题最有效的手段,因为更多的样本能够让模型学习到更多更有效的特征,减少噪声的影响。
当然直接增加实验数据在很多场景下都是没那么容易的,因此可以通过数据扩充技术,例如对图像进行平移、旋转和缩放等等。
除了根据原有数据进行扩充外,还有一种思路是使用非常火热的**生成式对抗网络 GAN **来合成大量的新训练数据。
还有一种方法是使用迁移学习技术,使用已经在更大规模的源域数据集上训练好的模型参数来初始化我们的模型,模型往往可以更快地收敛。但是也有一个问题是,源域数据集中的场景跟我们目标域数据集的场景差异过大时,可能效果会不太好,需要多做实验来判断。
-
降低模型复杂度:在深度学习中我们可以减少网络的层数,改用参数量更少的模型;在机器学习的决策树模型中可以降低树的高度、进行剪枝等。
-
正则化方法如 L2 将权值大小加入到损失函数中,根据奥卡姆剃刀原理,拟合效果差不多情况下,模型复杂度越低越好。至于为什么正则化可以减轻过拟合这个问题可以看看这个博客,挺好懂的.。
添加BN层(这个我们专门在BN专题中讨论过了,BN层可以一定程度上提高模型泛化性能)
使用dropout技术(dropout在训练时会随机隐藏一些神经元,导致训练过程中不会每次都更新(预测时不会发生dropout),最终的结果是每个神经元的权重w都不会更新的太大,起到了类似L2正则化的作用来降低过拟合风险。)
-
Early Stopping:Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
Early stopping方法的具体做法是:在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data的accuracy,当accuracy不再提高时,就停止训练。这种做法很符合直观感受,因为accurary都不再提高了,在继续训练也是无益的,只会提高训练的时间。那么该做法的一个重点便是怎样才认为validation accurary不再提高了呢?并不是说validation accuracy一降下来便认为不再提高了,因为可能经过这个Epoch后,accuracy降低了,但是随后的Epoch又让accuracy又上去了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。
-
集成学习方法:集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险,例如Bagging方法。
如DNN可以用Bagging的思路来正则化。首先我们要对原始的m个训练样本进行有放回随机采样,构建N组m个样本的数据集,然后分别用这N组数据集去训练我们的DNN。即采用我们的前向传播算法和反向传播算法得到N个DNN模型的W,b参数组合,最后对N个DNN模型的输出用加权平均法或者投票法决定最终输出。不过用集成学习Bagging的方法有一个问题,就是我们的DNN模型本来就比较复杂,参数很多。现在又变成了N个DNN模型,这样参数又增加了N倍,从而导致训练这样的网络要花更加多的时间和空间。因此一般N的个数不能太多,比如5-10个就可以了。
-
交叉检验,如S折交叉验证,通过交叉检验得到较优的模型参数,其实这个跟上面的Bagging方法比较类似,只不过S折交叉验证是随机将已给数据切分成S个互不相交的大小相同的自己,然后利用S-1个子集的数据训练模型,利用余下的子集测试模型;将这一过程对可能的S种选择重复进行;最后选出S次评测中平均测试误差最小的模型。
欠拟合
欠拟合的表现
模型无论是在训练集还是在测试集上的表现都很差,损失曲线呈现一种高偏差,低方差状态。(高偏差指的是训练集和验证集的误差都较高,但相差很少)
欠拟合的原因
同样可以从两个角度去分析:
- 模型过于简单:简单模型的学习能力比较差
- 提取的特征不好:当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合
欠拟合的解决方法
- 增加模型复杂度:如线性模型增加高次项改为非线性模型、在神经网络模型中增加网络层数或者神经元个数、深度学习中改为使用参数量更多更先进的模型等等。
- 增加新特征:可以考虑特征组合等特征工程工作(这主要是针对机器学习而言,特征工程还真不太了解……)
- 如果损失函数中加了正则项,可以考虑减小正则项的系数 λ \lambda λ
参考资料
过拟合与欠拟合及方差偏差 (这个博客总结地很好,可以看看)
机器学习+过拟合和欠拟合+方差和偏差
如何判断欠拟合、适度拟合、过拟合
相关文章:
机器学习:过拟合和欠拟合的介绍与解决方法
过拟合和欠拟合的表现和解决方法。 其实除了欠拟合和过拟合,还有一种是适度拟合,适度拟合就是我们模型训练想要达到的状态,不过适度拟合这个词平时真的好少见。 过拟合 过拟合的表现 模型在训练集上的表现非常好,但是在测试集…...

变分自编码器(VAE)PyTorch Lightning 实现
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…...

设备驱动开发_1
可加载模块如何工作的 主要内容 描述可加载模块优势使用模块命令效率使用和定义模块密钥和模块工作1 描述可加载模块优势 开发周期优势: 静态模块在/boot下的vmlinuz中,需要配置、编译、重启。 开发周期长。 LKM 不需要重启。 开发周期优于静态模块。 2 使用模块命令效率…...
知识点精要解析)
C语言位域(Bit Fields)知识点精要解析
在C语言中,位域(Bit Field)是一种独特的数据结构特性,它允许程序员在结构体(struct)中定义成员变量,并精确指定其占用的位数。通过使用位域,我们可以更高效地利用存储空间࿰…...

离散数学——图论(笔记及思维导图)
离散数学——图论(笔记及思维导图) 目录 大纲 内容 参考 大纲 内容 参考 笔记来自【电子科大】离散数学 王丽杰...
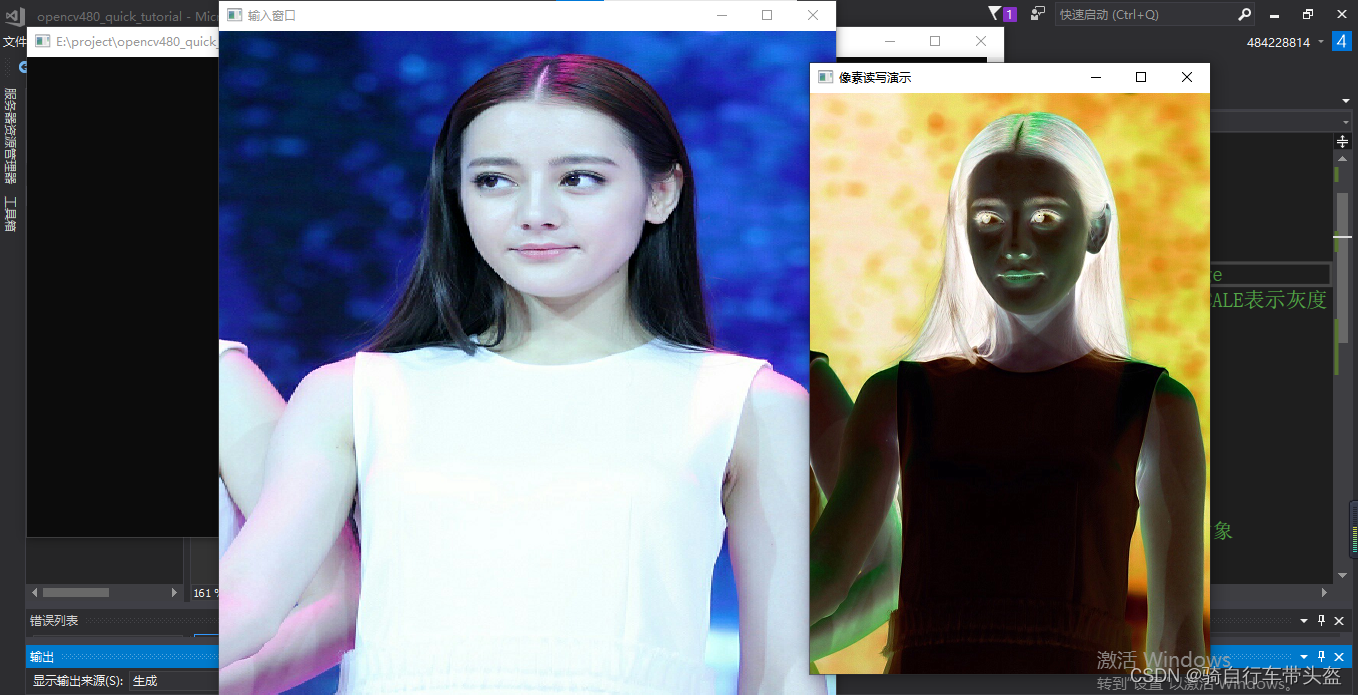
opencv图像像素的读写操作
void QuickDemo::pixel_visit_demo(Mat & image) {int w image.cols;//宽度int h image.rows;//高度int dims image.channels();//通道数 图像为灰度dims等于一 图像为彩色时dims等于三 for (int row 0; row < h; row) {for (int col 0; col < w; col) {if…...

Java学习第十四节之冒泡排序
冒泡排序 package array;import java.util.Arrays;//冒泡排序 //1.比较数组中,两个相邻的元素,如果第一个数比第二个数大,我们就交换他们的位置 //2.每一次比较,都会产生出一个最大,或者最小的数字 //3.下一轮则可以少…...

第1章 计算机网络体系结构-1.1计算机网络概述
1.1.1计算机网络概念 计算机网络是将一个分散的,具有独立功能的计算机系统通过通信设备与路线连接起来,由功能完善的软件实现资源共享和信息传递的系统。(计算机网络就是一些互连的,自治的计算机系统的集合) 1.1.2计算机网络的组成 从不同角…...

蓝桥杯:C++排序
排序 排序和排列是算法题目常见的基本算法。几乎每次蓝桥杯软件类大赛都有题目会用到排序或排列。常见的排序算法如下。 第(3)种排序算法不是基于比较的,而是对数值按位划分,按照以空间换取时间的思路来排序。看起来它们的复杂度更好,但实际…...
数据结构-堆
1.容器 容器用于容纳元素集合,并对元素集合进行管理和维护. 传统意义上的管理和维护就是:增,删,改,查. 我们分析每种类型容器时,主要分析其增,删,改ÿ…...

奔跑吧小恐龙(Java)
前言 Google浏览器内含了一个小彩蛋当没有网络连接时,浏览器会弹出一个小恐龙,当我们点击它时游戏就会开始进行,大家也可以玩一下试试,网址:恐龙快跑 - 霸王龙游戏. (ur1.fun) 今天我们也可以用Java来简单的实现一下这…...

Ubuntu 1804 And Above Coredump Settings
查看 coredump 是否开启 # 查询, 0 未开启, unlimited 开启 xiaoUbuntu:/var/core$ ulimit -c 0# 开启 xiaoUbuntu:/var/core$ ulimit -c unlimited查看 coredump 保存路径 默认情况下,Ubuntu 使用 apport 服务处理 coredump 文件ÿ…...

docker 2:安装
docker 2:安装 ubuntu 安装 docker sudo apt install docker.io 把当前用户放进 docker 用户组,避免每次运行 docker 命都要使用 sudo 或者 root 权限。 sudo usermod -aG docker $USERid $USER 看到用户已加入 docker 组 …...
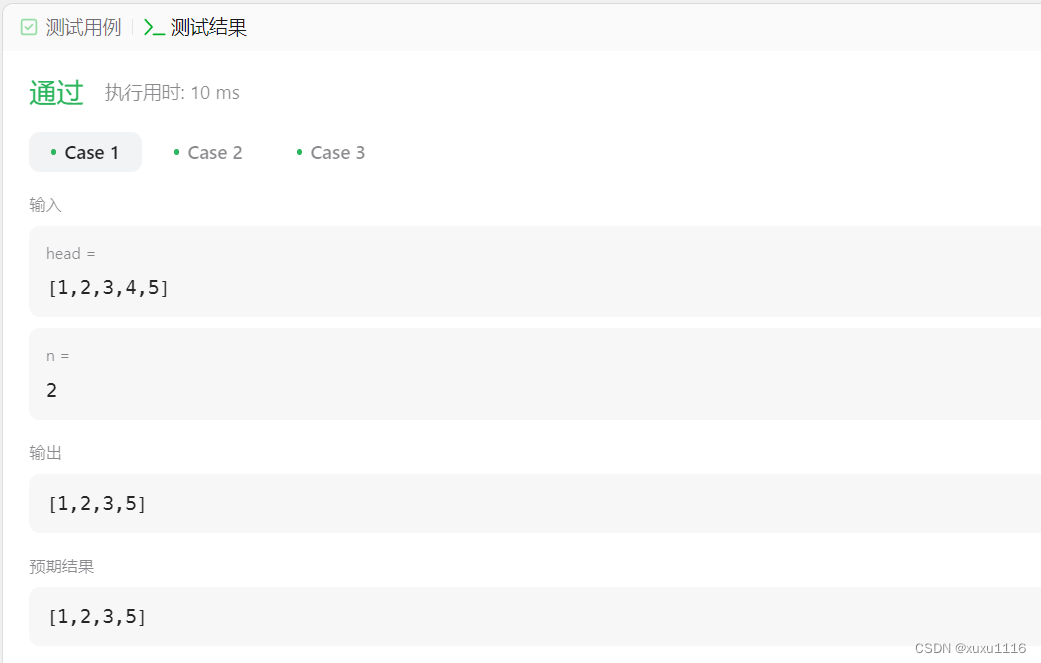
LeetCode Python - 19.删除链表的倒数第N个结点
目录 题目答案运行结果 题目 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5] 示例 2: 输入:head [1], n 1 输出&a…...
Spring Boot 笔记 005 环境搭建
1.1 创建数据库和表(略) 2.1 创建Maven工程 2.2 补齐resource文件夹和application.yml文件 2.3 porn.xml中引入web,mybatis,mysql等依赖 2.3.1 引入springboot parent 2.3.2 删除junit 依赖--不能删,删了会报错 2.3.3 引入spring web依赖…...
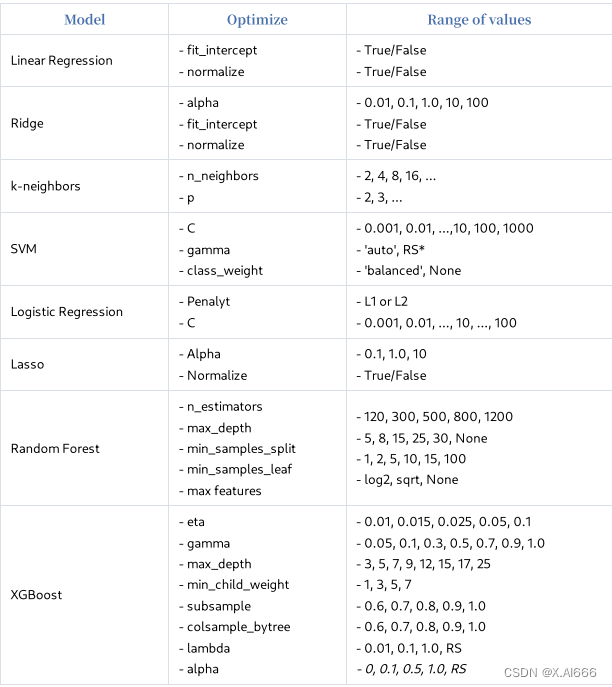
【解决(几乎)任何机器学习问题】:超参数优化篇(超详细)
这篇文章相当长,您可以添加至收藏夹,以便在后续有空时候悠闲地阅读。 有了优秀的模型,就有了优化超参数以获得最佳得分模型的难题。那么,什么是超参数优化呢?假设您的机器学习项⽬有⼀个简单的流程。有⼀个数据集&…...

面试计算机网络框架八股文十问十答第七期
面试计算机网络框架八股文十问十答第七期 作者:程序员小白条,个人博客 相信看了本文后,对你的面试是有一定帮助的!关注专栏后就能收到持续更新! ⭐点赞⭐收藏⭐不迷路!⭐ 1)UDP协议为什么不可…...

Codeforces Round 926 (Div. 2)
A. Sasha and the Beautiful Array(模拟) 思路 最大值减去最小值 #include<iostream> #include<algorithm> using namespace std; const int N 110; int a[N];int main(){int t, n;cin>>t;while(t--){cin>>n;for(int i 0; i…...
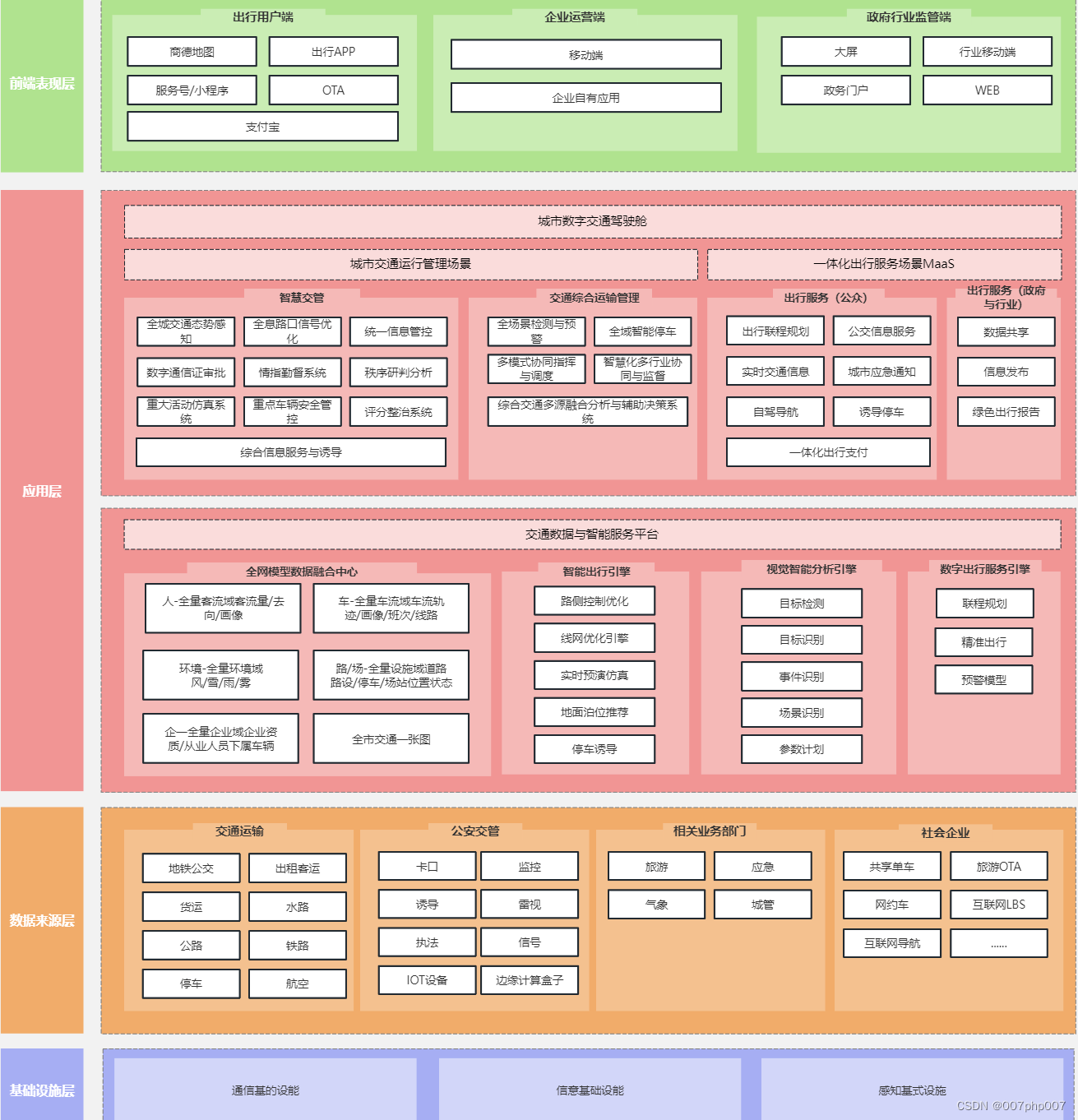
构建智慧交通平台:架构设计与实现
随着城市交通的不断发展和智能化技术的迅速进步,智慧交通平台作为提升城市交通管理效率和水平的重要手段备受关注。本文将探讨如何设计和实现智慧交通平台的系统架构,以应对日益增长的城市交通需求,并提高交通管理的智能化水平。 ### 1. 智慧…...
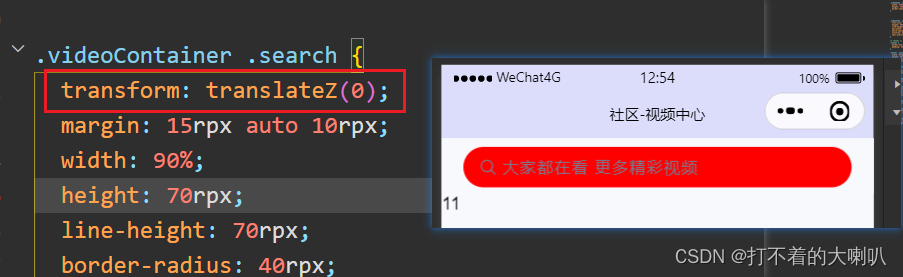
移动端设置position: fixed;固定定位,底部出现一条缝隙,不知原因,欢迎探讨!!!
1、问题 在父盒子中有一个子盒子,父盒子加了固定定位,需要子盒子上下都有要边距,用margin或者padding挤开时,会出现缝隙是子盒子背景颜色的。 测试过了,有些手机型号有,有些没有,微信小程序同移…...

用废旧材料制作发光机械鱼:Circuit Playground Express与MakeCode入门实践
1. 项目概述:当废旧材料遇见微控制器每次清理工作室,看着角落里堆满的包装盒、塑料瓶和旧电线,我总在想,除了扔掉,它们还能不能有第二次生命?直到我尝试将一块小小的微控制器塞进这些“垃圾”里,…...

SaaS ERP和传统ERP,到底差在哪?
这几年,ERP这个词越来越火。但有意思的是,很多企业老板、管理层,甚至已经在用ERP的人,其实都没真正分清:“SaaS ERP”和“传统ERP”,到底差在哪。很多人会觉得:“不都是ERP吗?不就是…...


RAG优化秘籍:为何“检索系统”才是关键?掌握这三大核心,效果飙升!
本文深入探讨了RAG(检索增强生成)系统中被忽视的“检索系统”对整体效果的决定性影响。核心内容围绕三种主流检索方式(向量检索、关键词检索、混合检索)展开,重点解析了混合检索的必要性和具体架构,同时强调…...

车间违规操作难监管?AI Box 智能视频监控系统解决方案
干工控这么多年,我最不愿意看到的就是安全事故。每次听到哪个工厂出了安全事故,心里都特别难受。其实很多安全事故都是因为违规操作引起的,比如不戴安全帽、不系安全带、在车间吸烟等等。传统的监控只能事后追溯,不能事前预警&…...

终极ncmdump使用指南:3步解锁网易云NCM加密音乐,实现跨平台自由播放
终极ncmdump使用指南:3步解锁网易云NCM加密音乐,实现跨平台自由播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾为网易云音乐下载的NCM格式文件无法在其他设备播放而烦恼?ncmdump作为…...

告别手动标注!R语言ggplot2+ggannotate高效绘制组间差异柱状图保姆级教程
R语言科研绘图革命:ggplot2ggannotate自动化差异标注全攻略 科研图表的美观程度直接影响论文的第一印象,而统计显著性标注更是数据可视化的灵魂所在。传统手动添加p值和星号的方式不仅效率低下,还容易出错——标注位置偏移、字体大小不一、连…...
:仅向高校科研组开放72小时)
【限时开放】NotebookLM气候专项Prompt Library(含AR6 WGII章节级语义索引模板):仅向高校科研组开放72小时
更多请点击: https://codechina.net 第一章:NotebookLM气候研究辅助概述 NotebookLM 是 Google 推出的基于人工智能的文档理解与推理工具,专为研究人员设计,支持上传 PDF、TXT 等格式的学术文献、观测报告及政策文件,…...

八大排序算法-选择排序
介绍选择排序:每一次从待排序序列中找出最小值和待排序序列的第一个值进行交换,重复这个过程,直到待排序序列没有值选择排序:时间复杂度O(n^2) 空间复杂度O(1) 稳定性:不稳定 难度范围:简单可以设置一个变量来保存最小…...

开源MCP服务器集合OpenClaw:模块化AI工具链的架构与实践
1. 项目概述:当开源AI工具链遇上“机械爪”如果你最近在折腾AI应用开发,特别是那些需要让大语言模型(LLM)与现实世界或复杂工具进行交互的项目,那么你很可能已经接触过“MCP”(Model Context Protocol&…...