人工智能学习与实训笔记(六):百度飞桨套件使用方法
目录
八、百度飞桨套件使用
8.1 飞桨预训练模型套件PaddleHub
8.1.1 一些本机CPU可运行的飞桨预训练简单模型(亲测可用)
8.1.1.1 人脸检测模型
8.1.1.2 中文分词模型
8.1.2 预训练模型Fine-tune
8.2 飞桨开发套件
8.2.1 PaddleSeg - 图像分割
8.2.2 PaddleNLP - 自然语言处理
八、百度飞桨套件使用
深度学习的探索目标:
- 需要针对业务场景提出建模方案;
- 探索众多的复杂模型哪个更加有效;
- 探索将模型部署到各种类型的硬件上。
基于飞桨的开发套件进行开发和学习,可以解决模型资源,二次开发和工业部署的问题:

8.1 飞桨预训练模型套件PaddleHub
PaddleHub属于预训练模型应用工具,集成了最优秀的算法模型,开发者可以快速使用高质量的预训练模型结合Fine-tune API快速完成模型迁移到部署的全流程工作。
8.1.1 一些本机CPU可运行的飞桨预训练简单模型(亲测可用)
注意代码运行前,需要安装相应的Paddle包(代码最开始的几行注释即为安装过程)
8.1.1.1 人脸检测模型
#pip install paddle
#pip install paddlehub==2.1
#hub install ultra_light_fast_generic_face_detector_1mb_640==1.1.2import paddlehub as hub
import matplotlib.image as mpimg
import matplotlib.pyplot as pltmodule = hub.Module(name="ultra_light_fast_generic_face_detector_1mb_640")
res = module.face_detection(paths = ["./test.jpg"], visualization=True, output_dir='test_face_detection_output')res_img_path = './test_face_detection_output/test.jpg'
img = mpimg.imread(res_img_path)
plt.figure(figsize=(10, 10))
plt.imshow(img)
plt.axis('off')
plt.show()8.1.1.2 中文分词模型
#pip install paddle
#pip install paddlehub==2.1
#hub install ultra_light_fast_generic_face_detector_1mb_640==1.1.2import paddlehub as hub
lac = hub.Module(name="lac")
test_text = ["1996年,曾经是微软员工的加布·纽维尔和麦克·哈灵顿一同创建了Valve软件公司。他们在1996年下半年从id software取得了雷神之锤引擎的使用许可,用来开发半条命系列。"]
res = lac.lexical_analysis(texts = test_text)print("中文词法分析结果:", res)8.1.2 预训练模型Fine-tune
研究神经网络模型层间特征图可视化的工作表明,模型最前端的神经网络层倾向于提取一些普遍的、共有的视觉特征,如纹理、边缘等信息。越往后则越倾向于任务相关的特征。涉及计算机视觉图像分类的模型,在特征提取功能上,更多的依赖模型的前端的神经层,而将特征映射到标签的功能则更多的依赖于模型末端的神经层。
也就是说,越靠近输出的神经网络层越具有任务相关性。NLP领域的第三范式(pre-trained + fine tune)便是采用了这种思想。语言模型在大规模语料上进行预训练之后,便具有了强大的语义表征能力。将PLM接上后续任务相关的神经网络层进行微调,便可以在下游任务中获得更好的效果。
因此我们可以基于预训练模型,通过使用私有数据对模型进行Fine-tune,从而实现模型的迁移。
要实现迁移学习,包括如下步骤:
- 安装PaddleHub
- 数据准备
- 模型准备
- 训练准备
具体做法可以参考:飞桨AI Studio星河社区-人工智能学习与实训社区
8.2 飞桨开发套件
如果说PaddleHub提供的是AI任务快速运行方案(POC),飞桨的开发套件则是比PaddleHub提供“更丰富的模型调节”和“领域相关的配套工具”,开发者基于这些开发套件可以实现当前应用场景中的最优方案(State of the Art)。
PaddleHub属于预训练模型应用工具,集成了最优秀的算法模型,开发者可以快速使用高质量的预训练模型结合Fine-tune API快速完成模型迁移到部署的全流程工作。但是在某些场景下,开发者不仅仅满足于快速运行,而是希望能在开源算法的基础上继续调优,实现最佳方案。如果将PaddleHub视为一个拿来即用的工具,飞桨的开发套件则是工具箱,工具箱中不仅包含多种多样的工具(深度学习算法模型),更包含了这些工具的制作方法(模型训练调优方案)。如果工具不合适,可以自行调整工具以便使用起来更顺手。
飞桨提供了一系列的开发套件,内容涵盖各个领域和方向:
- 计算机视觉领域:图像分割 PaddleSeg、目标检测 PaddleDetection、图像分类 PaddleClas、海量类别分类 PLSC,文字识别 PaddleOCR;
- 自然语言领域:语义理解 ERNIE;
- 语音领域:语音识别 DeepSpeech、语音合成 Parakeet;
- 推荐领域:弹性计算推荐 ElasticCTR;
- 其他领域:图学习框架 PGL、深度强化学习框架 PARL。

下面以PaddleSeg为例,介绍飞桨开发套件的使用方式。其余开发套件的使用模式相似,均包括快速运行的命令、丰富优化选项的配置文件和与该领域问题配套的专项工具。如果读者对其他领域有需求,可以查阅对应开发套件的使用文档。
8.2.1 PaddleSeg - 图像分割
图像分割任务是对每个像素点进行分类,需要给出每个像素点是什么分类的概率。
一般图像分割网络结构:

(1)网络的输入是H×W(H为高、W为宽)像素的图片,输出是N×H×W的概率图。输出的概率图大小和输入一致(H×W),而这个N就是类别。
(2)中间的网络结构分为Encoder(编码)和Decoder(解码)两部分。Encoder部分是下采样的过程,这是为了增大网络感受野,类似于缩小地图,利于看到更大的区域范围找到区域边界;Decoder部分是上采样的过程,为了恢复像素级别的特征地图,以实现像素点的分类,类似于放大地图,标注图像分割边界时更精细。
PaddleSeg覆盖了DeepLabv3+、U-Net、PSPNet、HRNet和Fast-SCNN等20+主流分割模型,并提供了多个损失函数和多种数据增强方法等高级功能,用户可以根据使用场景从PaddleSeg中选择出合适的图像分割方案,从而更快捷高效地完成图像分割应用。
实例:医学视盘分割
使用过程包括PaddleSeg环境安装,数据处理,模型选择和训练,模型评估,模型导出,模型部署等。具体过程可参考:飞桨AI Studio星河社区-人工智能学习与实训社区
8.2.2 PaddleNLP - 自然语言处理
PaddleNLP是基于Paddle框架开发的自然语言处理 (NLP) 开源项目,项目中包含工具、算法、模型和数据多种资源。PaddleNLP通过丰富的模型库、简洁易用的API,提供飞桨2.0的最佳实践并加速NLP领域应用产业落地效率。
GitHub链接:https://github.com/PaddlePaddle/PaddleNLP
丰富的模型库:涵盖了NLP主流应用相关的前沿模型,包括中文词向量、预训练模型、词法分析、文本分类、文本匹配、文本生成、机器翻译、通用对话、问答系统等。
实例:基于ERNIE模型的新闻标题分类
下面,我们将展示如何基于PaddleNLP中的预训练模型ERINE来实现另外一个文本分类的任务:对新闻标题进行分类。文本分类是指人们使用计算机将文本数据进行自动化归类的任务,是自然语言处理(NLP)中的一项重要任务。
本案例的模型实现方案如下图所示, 模型的输入是新闻标题的文本,模型的输出就是新闻标题的类别。在建模过程中,对于输入的新闻标题文本,首先需要进行数据处理生成规整的文本序列数据,包括语句分词、将词转换为id,过长文本截断、过短文本填充等等操作;然后使用预训练模型ERNIE对文本序列进行编码,获得文本的语义向量表示;最后经过全连接层和softmax处理得到文本属于各个新闻类别的概率。方案中不仅会使用ERNIE预训练模型,还会使用大量PaddleNLP的API,更便捷的完成数据处理和模型评估等工作。
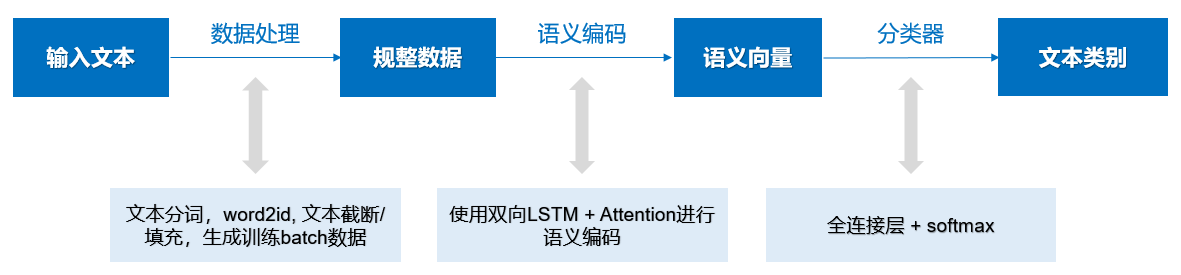
ERNIE是基于Transfomer模型进行的改进,Transfomer模型是一种比LSTM更加复杂的、适合处理序列数据的模型,它使用Self-attenion的方法,将RNN变成每个输入与其他输入部分计算匹配度来决定注意力权重的方式,使得模型引入了Attention机制的同时也具备了并行化计算的能力。以这种Self-attention结构为核心,设计Encoder-Decoder的结构形成Transformer模型。BERT和ERNIE均是将Transformer的Encoder部分结构单独取出,用多个的非标记语料(转成标记数据,如填空/判断句子连续性等)的任务训练,并将得到的Encoder向量作为词汇的基础语义表示用于多种NLP任务(如阅读理解)的模型。
关于Transfomer模型可参考:Transfomer模型详解
使用过程包括PaddleSeg环境安装,数据处理,模型选择和训练,模型评估,模型导出,模型部署等。具体过程可参考:飞桨AI Studio星河社区-人工智能学习与实训社区
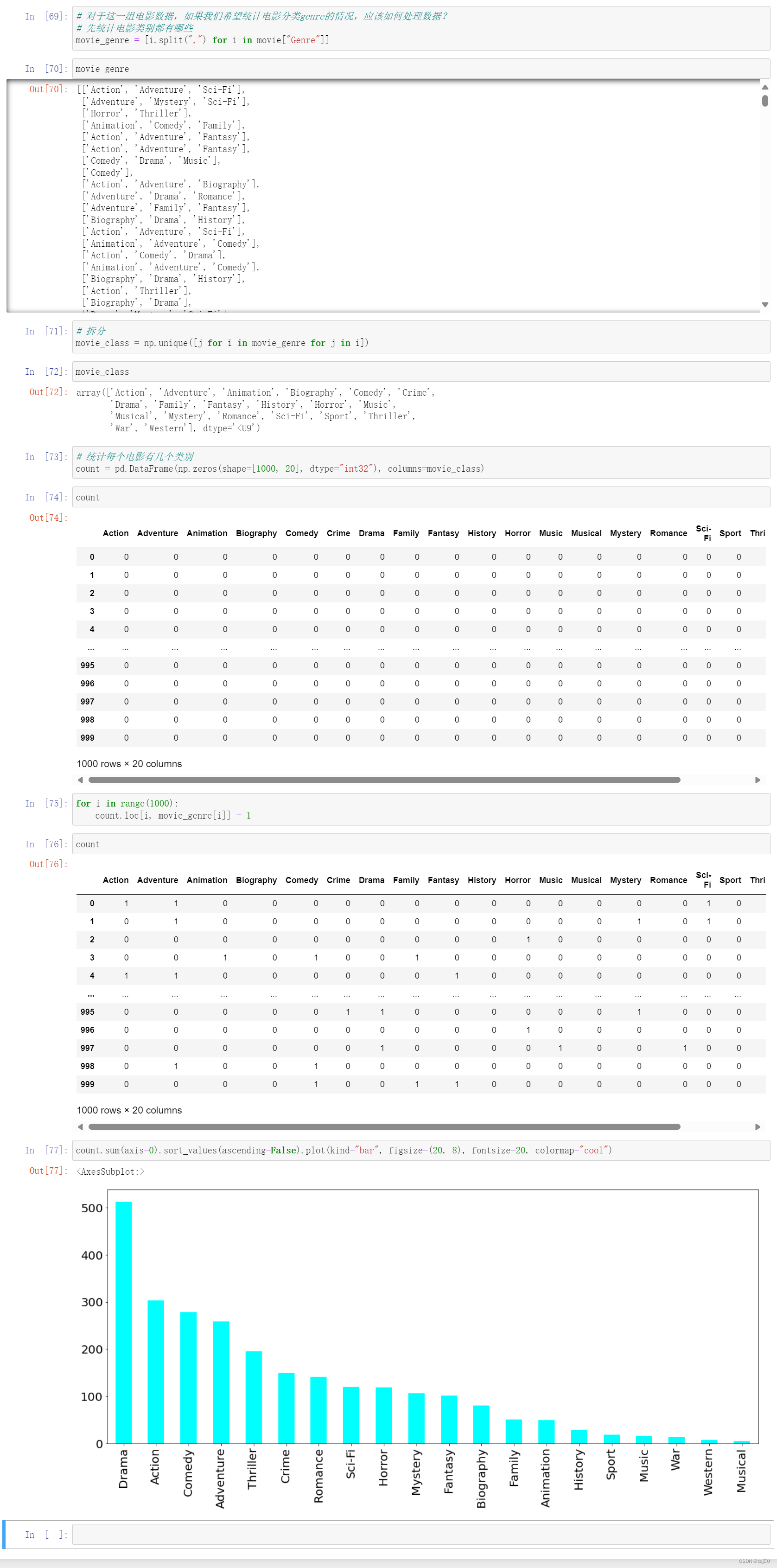
相关文章:
人工智能学习与实训笔记(六):百度飞桨套件使用方法
目录 八、百度飞桨套件使用 8.1 飞桨预训练模型套件PaddleHub 8.1.1 一些本机CPU可运行的飞桨预训练简单模型(亲测可用) 8.1.1.1 人脸检测模型 8.1.1.2 中文分词模型 8.1.2 预训练模型Fine-tune 8.2 飞桨开发套件 8.2.1 PaddleSeg - 图像分割 8…...

Linux第一个小程序-进度条
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言 一、回车和换行 二、行缓冲区概念 三、倒计时 四、进度条代码 版本一: 编辑 版本二: 总结 前言 世上有两种耀眼的光芒,一…...

YoloV8改进策略:Block改进|Mamba-UNet改进YoloV8,打造全新的Yolo-Mamba网络
摘要 本文尝试使用Mamba的VSSBlock替换YoloV8的Bottleneck,打造最新的Yolo-Mamba网络。 论文:《Mamba-UNet:用于医学图像分割的类似UNet的纯视觉Mamba网络》 在医学图像分析的最新进展中,卷积神经网络(CNN)和视觉转换器(ViT)都取得了显著的基准成绩。前者通过其卷积…...
数据分析基础之《pandas(8)—综合案例》
一、需求 1、现在我们有一组从2006年到2016年1000部最流行的电影数据 数据来源:https://www.kaggle.com/damianpanek/sunday-eda/data 2、问题1 想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取? 3、问题…...

(17)Hive ——MR任务的map与reduce个数由什么决定?
一、MapTask的数量由什么决定? MapTask的数量由以下参数决定 文件个数文件大小blocksize 一般而言,对于每一个输入的文件会有一个map split,每一个分片会开启一个map任务,很容易导致小文件问题(如果不进行小文件合并&…...

define和typedef
目录 一、define 二、typedef 三、二者之间的区别 一、define 在我们写代码的日常中,经常会用到define去配合数组的定义使用 #define N 10 arr[N]{0}; define不仅仅能做这些 #define是一种宏,我们首先来了解一下宏定义。 宏定义一般作用在C语言的预…...
SpringCloud之Nacos用法笔记
SpringCloud之Nacos注册中心 Nacos注册中心nacos启动服务注册到Nacosnacos服务分级模型NacosRule负载均衡策略根据集群负载均衡加权负载均衡Nacos环境隔离-namespace Nacos与eureka的对比临时实例与非临时实例设置 Nacos配置管理统一配置管理微服务配置拉取配置自动刷新远端配置…...
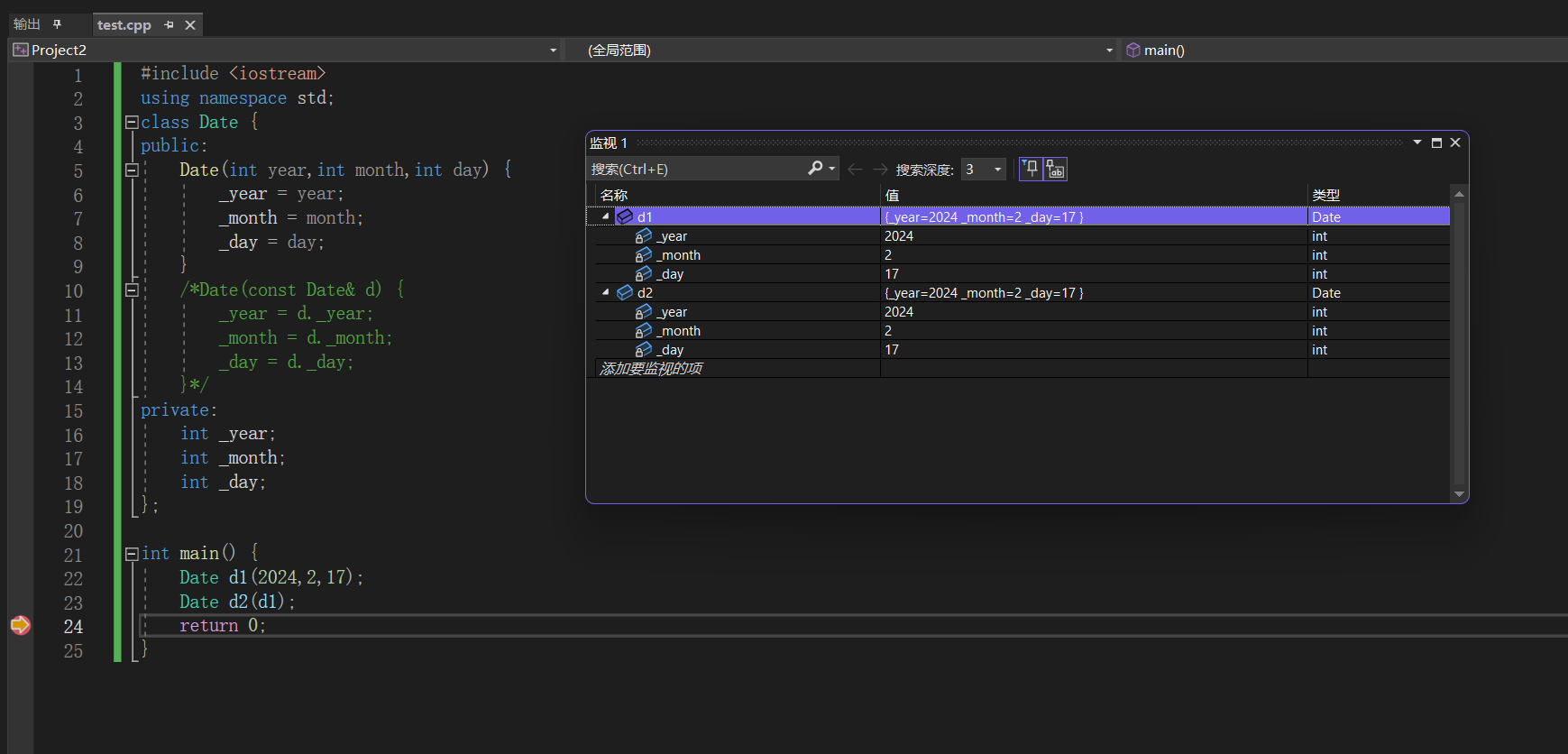
【c++】拷贝构造函数
1.特征 1.拷贝构造函数是构造函数的一个重载形式。 2.若显示定义了拷贝构造函数,编译器就不会自动生成构造函数了。 3.拷贝构造函数的参数只有一个且必须是类型对象的引用,使用传值方式编译器直接报错,因为会引发无穷递归调用。 4.若未显…...

17.3.1.2 曝光
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 基本算法:先定义一个阈值,通常取得是128 原图像:颜色值color(R,G&#…...

【Win10 触摸板】在插入鼠标时禁用触摸板,并在没有鼠标时自动启用触摸板。取消勾选连接鼠标时让触摸板保持打开状态,但拔掉鼠标后触摸板依旧不能使用
出现这种问题我的第一反应就是触摸板坏了,但是无意间我换了一个账户发现触摸板可以用,因此推断触摸板没有坏,是之前的账户问题,跟系统也没有关系,不需要重装系统。 解决办法:与鼠标虚拟设备有关 然后又从知…...
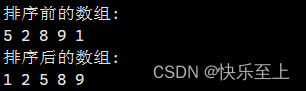
排序算法---桶排序
原创不易,转载请注明出处。欢迎点赞收藏~ 桶排序(Bucket Sort)是一种排序算法,它将待排序的数据分到几个有序的桶中,每个桶再分别进行排序,最后将各个桶中的数据按照顺序依次取出,即可得到有序序…...

FPGA_工程_基于rom的vga显示
一 框图 二 代码修改 module Display #(parameter H_DISP 1280,parameter V_DISP 1024,parameter H_lcd 12d150,parameter V_lcd 12d150,parameter LCD_SIZE 15d10_000 ) ( input wire clk, input wire rst_n, input wire [11:0] lcd_xpos, //lcd horizontal coo…...

代码随想录算法训练营第31天|● 理论基础 ● 455.分发饼干 ● 376. 摆动序列 ● 53. 最大子序和
文章目录 理论基础分发饼干思路:代码: 摆动序列思路一 贪心算法:代码: 思路二:动态规划(想不清楚)代码: 最大子序和思路:代码: 理论基础 贪心算法其实就是没…...

无人机地面站技术,无人机地面站理论基础详解
地面站作为整个无人机系统的作战指挥中心,其控制内容包括:飞行器的飞行过程,飞行航迹, 有效载荷的任务功能,通讯链路的正常工作,以及 飞行器的发射和回收。 无人机地面站总述 地面站作为整个无人机系统的作战指挥中心…...

2024.2.13
21.C 22.D 23.B 5先出栈表示1,2,3,4已经入栈了,5出后4出,但之后想出1得先让3,2先后出栈,所以 B 不可能 24.10,12,120 25.2,5 26.可能会出现段错误…...

论文阅读:四足机器人对抗运动先验学习稳健和敏捷的行走
论文:Learning Robust and Agile Legged Locomotion Using Adversarial Motion Priors 进一步学习:AMP,baseline方法,TO 摘要: 介绍了一种新颖的系统,通过使用对抗性运动先验 (AMP) 使四足机器人在复杂地…...
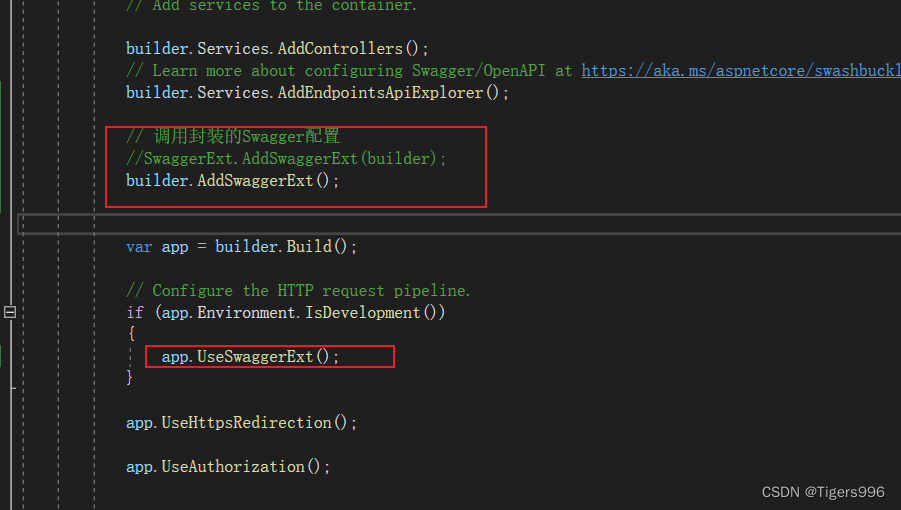
.NET Core WebAPI中封装Swagger配置
一、创建相关文件 创建一个Utility/SwaggerExt文件夹,添加一个类 二、在Program中找到Swagger相关配置信息 三、添加方法,在Program中调用 在SwaggerExt类中添加方法,将相关配置添写入 /// <summary> /// swagger配置 /// </sum…...

28. 找出字符串中第一个匹配项的下标
Problem: 28. 找出字符串中第一个匹配项的下标 文章目录 思路解题方法复杂度Code 思路 这个问题可以通过使用KMP(Knuth-Morris-Pratt)算法来解决。KMP算法是一种改进的字符串匹配算法,它的主要思想是当子串与目标字符串不匹配时,能…...

宿舍|学生宿舍管理小程序|基于微信小程序的学生宿舍管理系统设计与实现(源码+数据库+文档)
学生宿舍管理小程序目录 目录 基于微信小程序的学生宿舍管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、管理员模块的实现 (1)学生信息管理 (2)公告信息管理 (3)宿舍信息管理 &am…...
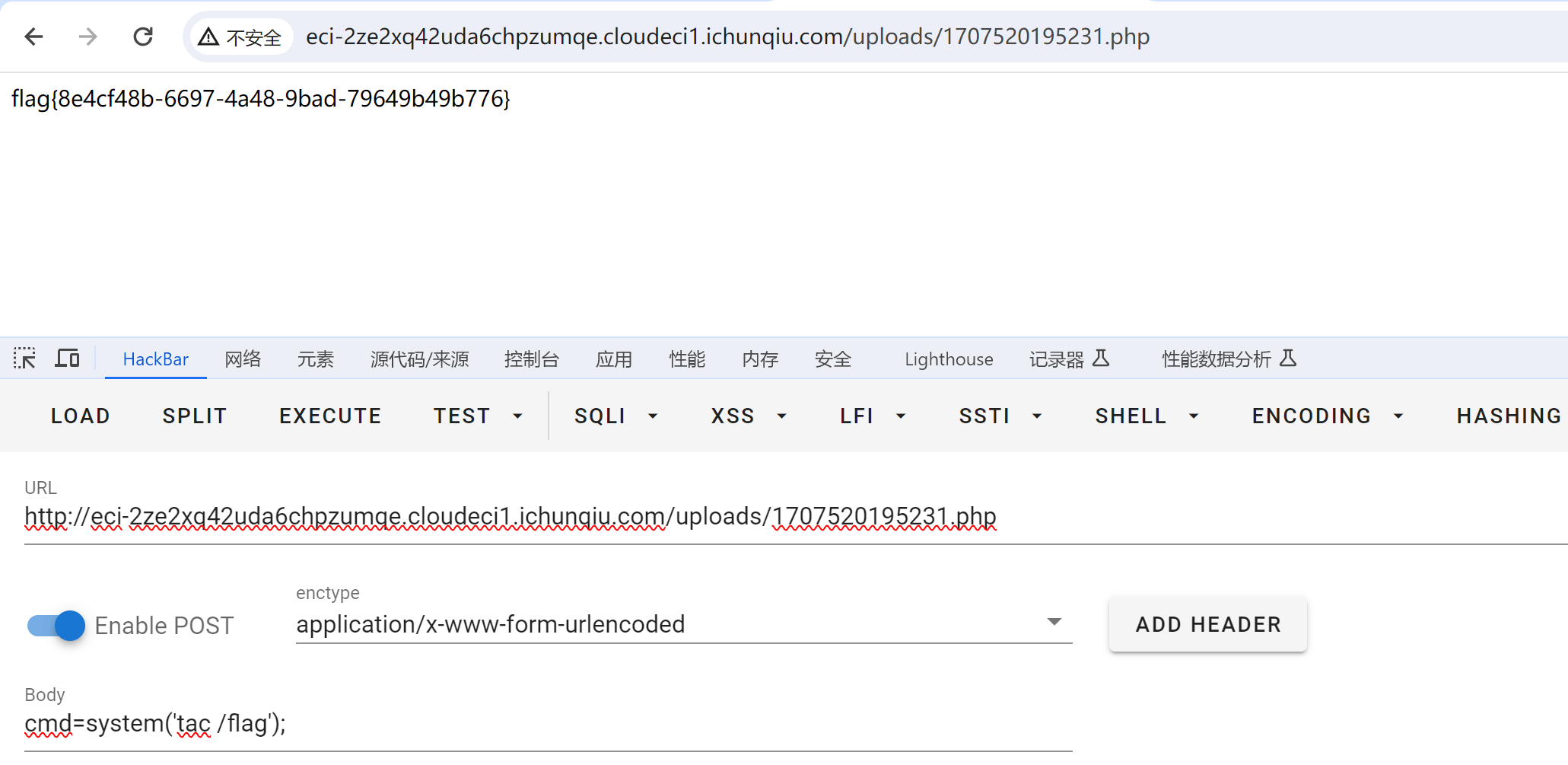
CVE-2022-25487 漏洞复现
漏洞描述:Atom CMS 2.0版本存在远程代码执行漏洞,该漏洞源于/admin/uploads.php 未能正确过滤构造代码段的特殊元素。攻击者可利用该漏洞导致任意代码执行。 其实这就是一个文件上传漏洞罢了。。。。 打开之后,/home路由是个空白 信息搜集&…...

在模型广场中根据任务需求与预算选择合适的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场中根据任务需求与预算选择合适的模型 面对文本生成、代码编写、逻辑推理等多样化的任务,开发者常常需要从众…...

ESXi 8.0支持ARM架构吗?一文说清兼容性真相
在虚拟化运维过程中,很多运维人员会关注ESXi 8.0的硬件兼容性,尤其是随着ARM架构服务器的普及,不少人会疑问“ESXi 8.0支持ARM架构吗?”。答案非常明确:ESXi 8.0不支持ARM架构,仅支持x86-64架构。本文详细拆…...

MultiFunPlayer完整指南:3分钟学会设备与媒体完美同步,打造沉浸式娱乐体验
MultiFunPlayer完整指南:3分钟学会设备与媒体完美同步,打造沉浸式娱乐体验 【免费下载链接】MultiFunPlayer flexible application to synchronize various devices with media playback 项目地址: https://gitcode.com/gh_mirrors/mu/MultiFunPlayer …...

从零搭建自托管AI实验室:基于Docker Compose的完整实践指南
1. 项目概述:从零搭建一个属于自己的AI实验室最近在GitHub上看到一个挺有意思的项目,叫self-hosted-ai-lab。这个名字本身就很有吸引力,直译过来就是“自托管的AI实验室”。作为一个在AI和系统运维领域摸爬滚打多年的从业者,我第一…...

Adobe-GenP完整指南:5步轻松激活Adobe全系列软件
Adobe-GenP完整指南:5步轻松激活Adobe全系列软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专为Adobe Creative Cloud用户设计的通…...

FFXIV TexTools:终极《最终幻想14》模组管理完全指南
FFXIV TexTools:终极《最终幻想14》模组管理完全指南 【免费下载链接】FFXIV_TexTools_UI 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_TexTools_UI FFXIV TexTools 是一款为《最终幻想14》玩家量身打造的开源模组管理框架,让游戏外观定…...

ClawLink:配置驱动的数据抓取与链接工具实战解析
1. 项目概述与核心价值最近在折腾一些自动化流程和跨平台数据同步时,发现了一个挺有意思的项目,叫 ClawLink。乍一看这个名字,可能有点摸不着头脑,但如果你也在为如何把不同平台、不同格式的数据“抓取”并“链接”起来而头疼&…...

Linux系统功耗调优实战:从监控到内核级优化指南
1. 项目概述:为什么要在Linux上折腾功耗? 最近几年,我手头的服务器、开发板和笔记本越来越多,从24小时开机的家庭服务器,到需要长续航的移动开发环境,再到追求极致静音和低发热的桌面工作站,“电…...

快充协议芯片技术解析:从原理到选型与实战应用
1. 市场爆发与资本热潮:快充芯片的“黄金时代”最近两年,如果你关注半导体和消费电子行业,会发现一个很有意思的现象:一批做快充协议芯片的公司,正在扎堆冲刺IPO。从科创板到创业板,再到港交所,…...

从零到一:在个人PC上部署并集成ChatGLM-6B到Unity应用
1. 环境准备与模型下载 在个人PC上部署ChatGLM-6B需要先搞定三件事:硬件检查、软件环境搭建和模型文件获取。我的老款游戏本(i7-9750H RTX2060 6GB显存)实测可以流畅运行,关键在于正确的量化配置。 硬件检查要点: 显存…...