实例分割论文阅读之:FCN:《Fully Convolutional Networks for Semantica Segmentation》
论文地址:https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf
代码链接:https://github.com/pytorch/vision
摘要
卷积网络是强大的视觉模型,可以产生特征层次结构。我们证明,经过端到端、像素到像素训练的卷积网络本身超过了语义分割的最新技术。我们的主要见解是构建“全卷积”网络,该网络接受任意大小的输入并通过有效的推理和学习产生相应大小的输出。我们定义并详细介绍了全卷积网络的空间,解释了它们在空间密集预测任务中的应用,并与先前的模型建立了联系。我们将当代分类网络(AlexNet [20]、VGG 网络 [31] 和 GoogLeNet [32])改编为完全卷积网络,并通过微调 [3] 将其学习到的表示转移到分割任务。然后,我们定义一个跳跃架构,它将来自深层、粗糙层的语义信息与来自浅层、精细层的外观信息相结合,以产生准确而详细的分割。我们的全卷积网络实现了最先进的 PASCAL VOC 分割(相对于 2012 年平均 IU 提高了 20%,达到 62.2%)、NYUDv2 和 SIFT Flow,而典型图像的推理时间不到五分之一秒。
1.介绍
卷积网络正在推动识别领域的进步。卷积网络不仅在整个图像分类方面有所改进,而且在具有结构化输出的局部任务方面也取得了进展。其中包括边界框对象检测 [29, 10, 17]、部分和关键点预测 [39, 24] 以及局部对应 [24, 8] 方面的进展。从粗略推理到精细推理的自然下一步是对每个像素进行预测。先前的方法已使用卷积网络进行语义分割[27,2,7,28,15,13,9],其中每个像素都用其封闭对象或区域的类别进行标记,但存在本工作解决的缺点。
我们证明,在语义分割上经过端到端、像素到像素训练的全卷积网络(FCN)超越了最先进的技术,而无需进一步的机器。据我们所知,这是第一个端到端训练 FCN 的工作(1)用于像素预测和(2)来自监督预训练。现有网络的全卷积版本可以根据任意大小的输入预测密集输出。
学习和推理都是通过密集前馈计算和反向传播一次性执行整个图像。网络内上采样层可以通过子采样池在网络中进行像素预测和学习。这种方法是有效的,无论是渐进的还是绝对的,并且排除了其他工作中的复杂性。分片训练很常见[27,2,7,28,9],但缺乏全卷积训练的效率。我们的方法不利用预处理和后处理复杂性,包括超像素 [7, 15]、提案 [15, 13] 或通过随机场或局部分类器进行事后细化 [7, 15]。我们的模型通过将分类网络重新解释为完全卷积并根据其学习的表示进行微调,将最近在分类[20,31,32]方面的成功转移到密集预测。相比之下,以前的工作应用了小型卷积网络,没有监督预训练[7,28,27]。
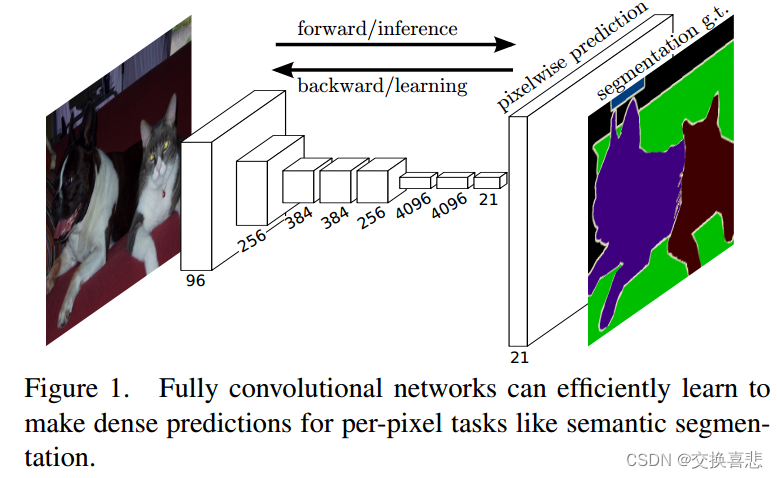
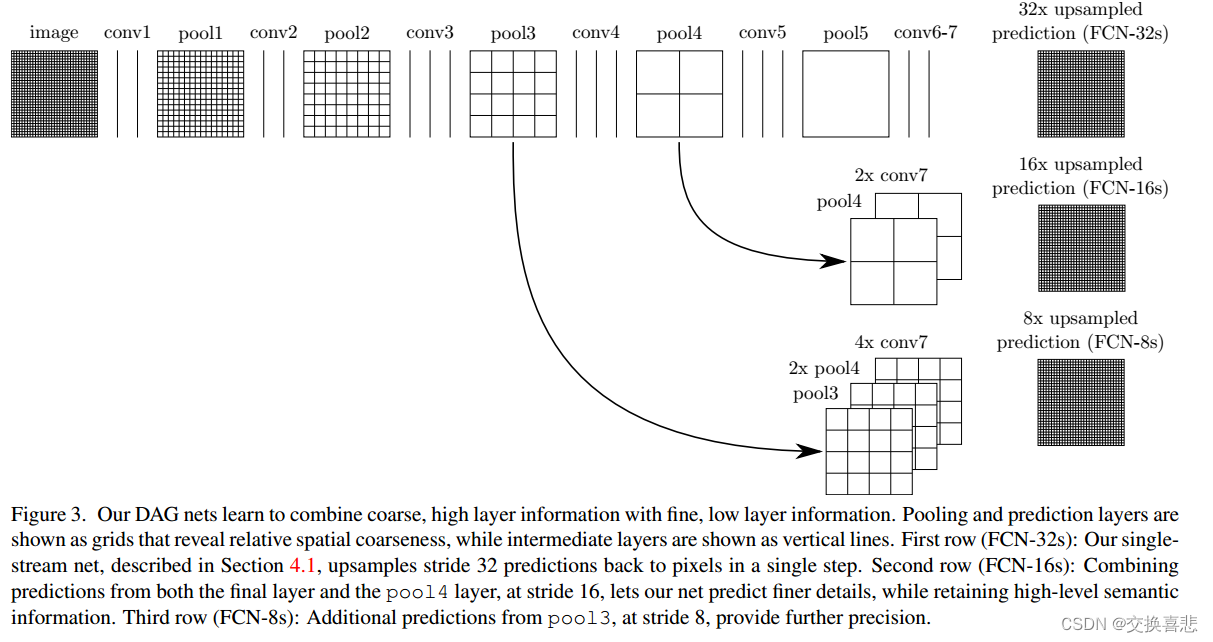
语义分割面临语义和位置之间固有的张力:全局信息解决什么,而本地信息解决哪里。深层特征层次结构在非线性局部到全局金字塔中对位置和语义进行编码。我们定义了一个跳跃架构来利用这个特征谱,它结合了第 4.2 节中的深层、粗糙、语义信息和浅层、精细、外观信息(见图 3)。
在下一节中,我们将回顾深度分类网络、FCN 以及最近使用卷积网络进行语义分割的方法的相关工作。以下部分解释了 FCN 设计和密集预测权衡,介绍了我们的网络内上采样和多层组合的架构,并描述了我们的实验框架。最后,我们展示了 PASCAL VOC 2011-2、NYUDv2 和 SIFT Flow 上的最新结果。
2.相关工作
全卷积网络:据我们所知,将卷积网络扩展到任意大小输入的想法首先出现在 Matan 等人 [26] 中,他们将经典的 LeNet [21] 扩展到识别数字字符串。由于他们的网络仅限于一维输入字符串,Matan 等人使用维特比解码来获得它们的输出。 Wolf 和 Platt [37] 将卷积网络输出扩展为邮政地址块四个角的检测分数的二维图。
这些历史作品都进行了完全卷积的推理和学习以进行检测。 Ning 等人[27]定义了一个卷积网络,用于通过完全卷积推理对线虫组织进行粗略多类分割。
全卷积计算也已在当今多层网络时代得到利用。 Sermanet 等人 [29] 的滑动窗口检测、Pinheiro 和 Collobert [28] 的语义分割以及 Eigen 等人 [4] 的图像恢复进行完全卷积推理。全卷积训练很少见,但 Tompson 等人 [35] 有效地使用它来学习用于姿势估计的端到端部分检测器和空间模型,尽管他们没有阐述或分析这种方法。
或者,He 等人 [17] 丢弃分类网络的非卷积部分来制作特征提取器。他们将提案和空间金字塔池结合起来,产生用于分类的局部固定长度特征。虽然快速有效,但这种混合模型无法端到端学习。
使用卷积网络进行密集预测:最近的几项工作已将卷积网络应用于密集预测问题,包括 Ning 等人 [27]、Farabet 等人以及 Pinheiro 和 Collobert [28] 的语义分割; Ciresan 等人 [2] 对电子显微镜进行边界预测,Ganin 和 Lempitsky [9] 通过混合卷积网络/最近邻模型对自然图像进行边界预测;以及 Eigen 等人的图像恢复和深度估计 [4, 5]。这些方法的共同要素包括:
•小模型限制了容量和感受野
•分段训练
•通过超像素投影、随机场正则化、过滤或局部分类进行后处理
•输入移位和输出交错以实现密集输出
•多尺度金字塔处理
•饱和tanh非线性
•全体
然而,我们的方法不需要这种机制。然而,我们从FCN的角度研究了3.4节的基于补丁的训练和3.2节的“移动和拼接”密集输出。我们还讨论了3.3节的网络内上采样,其中Eigen等人的全连接预测[5]是一种特殊情况。与这些现有方法不同,我们改编和扩展了深度分类架构,使用图像分类作为监督预训练,并通过完全卷积进行微调,以从整个图像输入和整个图像真值中简单高效地学习。Hariharan等人[15]和Gupta等人[13]同样将深度分类网络应用于语义分割,但是采用了混合的提议-分类器模型。这些方法通过对边界框和/或区域提议进行采样,对R-CNN系统[10]进行微调,用于检测、语义分割和实例分割。这两种方法都不是端到端学习。它们在PASCAL VOC和NYUDv2上实现了最先进的分割结果,因此我们在第5节中将我们的独立端到端FCN与它们的语义分割结果进行直接比较。我们跨层融合特征,定义了一个非线性的局部到全局表示,并进行端到端的调整。在当代工作中,Hariharan等人[16]在他们的混合模型中也使用多个层进行语义分割。
3.全卷积网络
卷积网络中的每一层数据都是一个大小为 h × w × d 的三维数组,其中 h 和 w 是空间维度,d 是特征或通道维度。第一层是图像,像素大小为 h × w,有 d 个颜色通道。较高层中的位置对应于它们路径连接到的图像中的位置,称为它们的感受野。
卷积网络建立在平移不变性的基础上。它们的基本组件(卷积、池化和激活函数)在局部输入区域上运行,并且仅依赖于相对空间坐标。将特定层中位置 (i; j) 处的数据向量写入 xij,将 yij 写入后续层,这些函数通过以下方式计算输出 yij。
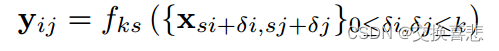
其中 k 称为内核大小,s 是步幅或子采样因子,fks 确定层类型:卷积或平均池化的矩阵乘法、最大池化的空间最大值或激活函数的元素非线性,等等对于其他类型的图层。这种函数形式在组合下保持不变,内核大小和步长遵循转换规则。
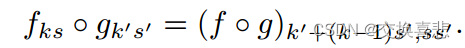
虽然一般的深度网络计算一般的非线性函数,但仅具有这种形式的层的网络计算非线性滤波器,我们将其称为深度滤波器或全卷积网络。 FCN 自然地对任何大小的输入进行操作,并产生相应的(可能是重新采样的)空间维度的输出。
由 FCN 组成的实值损失函数定义了一个任务。如果损失函数是最后一层空间维度的总和,‘(x; θ) = P ij ‘ 0 (xij ; θ),则其梯度将是其每个空间分量的梯度之和。因此,在整个图像上计算的 ’ 上的随机梯度下降将与 ’ 0 上的随机梯度下降相同,将所有最后层感受野作为一个小批量。
当这些感受野显着重叠时,前馈计算和反向传播在整个图像上逐层计算而不是独立地逐块计算时会更加有效。接下来我们解释如何将分类网络转换为产生粗略输出图的全卷积网络。对于像素预测,我们需要将这些粗略输出连接回像素。 3.2 节描述了为此目的引入的一个技巧,即快速扫描 [11]。我们通过将其重新解释为等效的网络修改来深入了解此技巧。作为一种高效、有效的替代方案,我们在 3.3 节中引入了用于上采样的反卷积层。在第 3.4 节中,我们考虑通过补丁采样进行训练,并在第 4.3 节中给出证据,证明我们的整个图像训练速度更快且同样有效。
3.1 调整分类器进行密集预测
典型的识别网络,包括 LeNet [21]、AlexNet [20] 及其更深层次的后继者 [31、32],表面上采用固定大小的输入并产生非空间输出。这些网络的完全连接层具有固定的尺寸并抛弃空间坐标。然而,这些完全连接的层也可以被视为具有覆盖其整个输入区域的内核的卷积。这样做会将它们放入完全卷积网络中,该网络接受任意大小的输入并输出分类图。这种转换如图 2 所示。此外,虽然生成的映射相当于对特定输入补丁的原始网络的评估,但计算在这些补丁的重叠区域上进行了高度摊销。例如,AlexNet 需要 1:2 毫秒(在典型的 GPU 上)来推断 227×227 图像的分类分数,而全卷积网络需要 22 毫秒才能从 500×500 图像生成 10×10 网格的输出,这比简单方法快 5 倍以上1。
这些卷积模型的空间输出图使它们成为语义分割等密集问题的自然选择。由于每个输出单元都可用真实数据,前向和后向传递都很简单,并且都利用了卷积固有的计算效率(和积极的优化)。 AlexNet 示例的相应后向时间对于单个图像为 2:4 毫秒,对于完全卷积 10 × 10 输出图为 37 毫秒,从而获得与前向传递类似的加速。
虽然我们将分类网络重新解释为完全卷积,可以生成任何大小的输入的输出图,但输出维度通常会通过子采样来减小。分类网络子样本可保持过滤器较小且计算要求合理。这会粗化这些网络的完全卷积版本的输出,将其从输入大小减少一个等于输出单元感受野的像素步长的因子。
3.2 “移位缝合”是过滤稀疏化
通过将输入的移位版本的输出拼接在一起,可以从粗略的输出中获得密集预测。如果输出按因子f 下采样得到的,则对于每个(x, y)0≤x,y<f,将输入x像素向右移动并向下移动y像素。处理每个 f^2 输入,并交错输出,以便预测对应于其感受野中心的像素。
尽管执行这种变换只会将成本增加 f^2 倍,但有一个众所周知的技巧可以有效地产生相同的结果,小波社区将其称为 a` trous算法。考虑一个具有输入步幅为s的层(卷积或池化),以及具有过滤器权重fij(消除不相关的特征维度)的后续卷积层。将下层的输入步长设置为1会将其输出上采样s 倍。然而,将原始滤波器与上采样输出进行卷积不会产生与移位缝合相同的结果,因为原始滤波器仅看到其(现在已上采样)输入的减少部分。 要重现该技巧,请通过将其放大来稀疏过滤器:
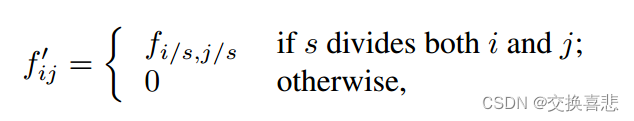
(i 和 j 从零开始)。再现该技巧的完整净输出涉及逐层重复此滤波器放大,直到删除所有子采样。 (实际上,这可以通过处理上采样输入的下采样版本来有效地完成。)
减少网络内的子采样是一种权衡:过滤器可以看到更精细的信息,但感受野更小并且计算时间更长。 移位缝合技巧是另一种权衡:输出更密集,而不会减小滤波器的感受野大小,但滤波器被禁止以比原始设计更精细的尺度尺度信息。尽管我们已经用这个技巧做了初步实验,但我们并没有在我们的模型中使用它。 我们发现通过上采样进行学习(如下一节所述)更加有效和高效,尤其是与稍后描述的跳层融合相结合时。
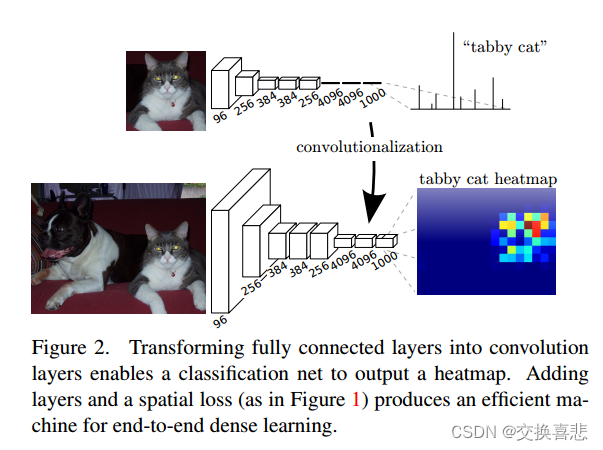
3.3上采样是反向跨步卷积
将粗略输出连接到密集像素的另一种方法是插值。 例如,简单的双线性插值通过线性映射从最近的四个输入计算每个输出 yij,该线性映射仅取决于输入和输出单元的相对位置。从某种意义上说,使用因子 f 进行上采样是使用分数输入步幅为 1/f 的卷积。 只要 f 是积分,上采样的自然方法就是输出步长为 f 的向后卷积(有时称为反卷积)。 这种操作实现起来很简单,因为它只是反转卷积的前向和后向传递。 因此,通过像素损失的反向传播在网络内执行上采样以进行端到端学习。 注意哈,此类层中的反卷积滤波器不需要固定(例如,双线性上采样),但可以被学习。 一堆反卷积层和激活函数甚至可以学习非线性上采样。 在我们的实验中,我们发现网络内上采样对于学习密集预测来说是快速且有效的。 我们最好的分割架构使用这些层来学习上采样以实现第 4.2 节中的精细预测。
3.4 块训练就是损失采样
在随机优化中,梯度计算由训练分布驱动的。块训练和全卷积训练都可以产生任何分布,尽管它们的相对计算效率取决于重叠和小批量大小。 整个图像全卷积训练与块训练相同,其中每个批次由图像(或图像集合)损失下方的单元的所有感受野组成。 虽然这比块的统一采样更有效,但它减少了可能的块数量。 然而,图像内随机选择的块可以简单地被恢复。 将损失限制为其空间项的随机采样子集(或者等效地在输出和损失之间应用 DropConnect mask)可以从梯度计算中排除块。 如果保留的块仍然有显着的重叠,全卷积计算仍然会加速训练。 如果梯度是通过多次反向传播累积的,则块可以包含来自多个图像的块。 块训练中的采样可以纠正类别不平衡并减轻密集块的空间相关性。 在全卷积训练中,还可以通过对损失进行加权来实现类别平衡,并且可以使用损失采样来解决空间相关性。 我们在 4.3 节中探索了采样训练,但没有发现它可以为密集预测带来更快或更好的收敛。 全图训练是有效且高效的。
4.分割结构
我们将 ILSVRC 分类器放入FCN中,并通过网络内上采样和像素损失来增强它们以进行密集预测。 我们通过微调来训练分割。 接下来,我们在层之间添加跳跃以融合粗略的语义和局部外观信息。 这种跳跃架构是端到端学习的,以细化输出的语义和空间精度。 在本次调查中,我们对 PASCAL VOC 2011 分割挑战进行训练和验证 。 我们使用每像素多项式逻辑损失进行训练,并使用均值标准度量像素的交并集的进行验证,包括所有类别(及背景)。 训练忽略了在真实情况中被掩盖(未被标注)(不明确或困难)的像素。
4.1从分类器到密集FCN
我们首先对第 3 章中经过验证的分类架构进行卷积。我们考虑使用再ILSVRC12中获胜的AlexNet 框架 ,以及在 ILSVRC14 中表现出色的 VGG 网络 和 GoogLeNet。 我们选择VGG-16网络,我们发现它与此任务中的19层网络等效。对于GoogLeNet,我们仅使用最终的损失层,并通过丢弃最终的平均池化层来提高性能。 我们截断每个网络通过丢弃最终的分类器层,并将所有全连接层转换为卷积层。 我们在粗略的输出进行双线性上采样为像素密集输出的反卷积层(第 3.3 节中)之后附加一个通道维度为21(PASSCAL共21个分类)的1 × 1卷积来预测每个粗略输出位置处每个 PASCAL 类别(包括背景)的分数。 表1 比较了初步验证结果以及每个网络的基本特征。 我们报告了以固定学习率(至少175迭代)收敛后取得的最佳结果。
从分类到分割的微调为每个网络提供了合理的预测。即使是最差的模型也能达到最先进性能的 75%。配备分段的 VGG 网络 (FCN-VGG16) 看起来已经是最先进的,验证时的平均 IU 为 56.0,而测试时的平均 IU 为 52.6 [15]。对额外数据的训练将 val7 子集上的 FCN-VGG16 平均 IU 提高到 59.4,FCN-AlexNet 平均 IU 提高到 48.0。尽管分类精度相似,但我们的 GoogLeNet 实现与 VGG16 分割结果不匹配。

4.2 结合分类和定位
我们定义了一个新的用于分割的全卷积网络(FCN),它结合了特征层次结构的各层并细化了输出的空间精度。参见图 3。
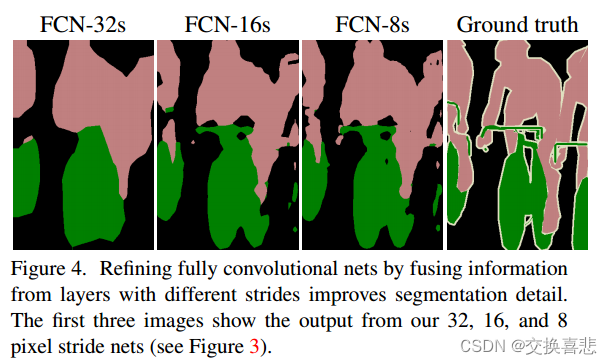
虽然完全卷积分类器可以像 4.1 中所示进行微调以进行分割,甚至在标准指标上得分很高,但它们的输出却非常粗糙(见图 4)。最终预测层的 32 像素步长限制了上采样输出中的细节比例。
我们通过添加跳跃 [1] 来解决这个问题,该跳跃将最终预测层与具有更精细步长的较低层结合起来。这会将线型拓扑转变为 DAG,其边缘从较低层跳到较高层(图 3)。由于他们看到的像素更少,更精细的尺度预测应该需要更少的层,因此从更浅的网络输出中制作它们是有意义的。结合精细层和粗略层可以让模型做出尊重全局结构的局部预测。通过类比 Koenderick 和 van Doorn [19] 的射流,我们将非线性特征层次称为深度射流。
我们首先通过16像素步幅层进行预测,将输出步幅分成一半。 我们在 pool4 之上添加一个 1 × 1 卷积层以产生额外的类预测。 我们将之(pool4的类预测)与步长为32的 conv7(卷积化 fc7)之上计算的预测通过添加 2×上采样结果,这两个两个预测结果进行求和来将此输出与融合起来(见图 3)。 我们将 2× 上采样初始化为双线性插值,但允许按照 3.3 节中的描述来学习参数。 最后,步长为16的预测被上采样回图像。 我们将此网络称为 FCN-16s。 FCN-16s 是端到端学习的,使用最后一个较粗网络(我们现在称为 FCN-32s)的参数进行初始化。 作用于 pool4 的新参数被初始化为零,以便网络以未修改的预测开始。学习率降低了100倍。
学习这个跳跃网络将验证集的性能提高了3.0个平均IU点到到 62.4。 图 4 显示了输出精细结构的改进。 我们将这种融合与仅从 pool4 层学习进行比较,后者导致性能不佳,并且只是降低学习率而不添加跳跃,这导致性能提升不显着,而没有提高输出质量。
我们继续以这种方式,将 pool3预测的2x上采样与 pool4 和 conv7 融合的预测进行融合,构建网络 FCN-8。 我们获得了 62.7 平均 IU 的微小额外改进,并发现输出的平滑度和细节略有改善。 此时,我们的融合改进已经遇到了收益递减的情况,无论是在强调大规模正确性的 IU 指标方面,还是在可见的改进方面,例如在图 4 中,因此我们不会继续融合更低的层。
通过其他方式进行细化 减少池化层的步长是获得更精细预测的最直接方法。 然而,这样做对于我们基于 VGG16 的网络来说是有问题的。 将 pool5 步幅设置为1要求我们的卷积化 fc6 的内核大小为 14 × 14,以维持其感受野大小。 除了计算成本之外,我们还很难学习如此大的过滤器。 我们尝试使用更小的过滤器重新架构 pool5 之上的层,但没有达到可比较的性能; 一种可能的解释是上层的 ILSVRC 初始化很重要。
获得更精细预测的另一种方法是使用第 3.2 节中描述的移位缝合技巧。 在有限的实验中,我们发现这种方法的成本改进比层融合更差。
4.3实验框架
优化 我们通过SGD(随机梯度下降优化算法)进行有动量(momentum)的训练。 对于 FCN-AlexNet、FCN-VGG16 和 FCN-GoogLeNet,我们分别使用 20 张图像的小批量大小和 10 −3 、10 −4 和 5 −5 的固定学习率,通过线性搜索选择得到。 我们使用动量 0.9、权重衰减 5 −4 或 2 −4 以及双倍学习率来应对偏差,尽管我们发现训练仅对学习率敏感。 我们对分类层进行零值初始化,因为随机初始化既不会产生更好的性能,也不会产生更快的收敛。 在原始分类器网络中使用的地方包含了Dropout(沿用原来的Dropout概率)。
微调 我们通过整个网络的反向传播来微调所有层。与表2相比,单独微调输出分类器只能产生完整微调性能的70%。考虑到学习基本分类网络所需的时间,从头开始训练是不可行的。(注意哈,VGG 网络是分阶段训练的,而我们从完整的16层版本进行初始化。)对于粗略的 FCN-32s 版本,在单个GPU上进行微调需要三天时间,升级到 FCN-16s 和 FCN-8s 版本分别需要一天的时间。
更多训练数据 PASCAL VOC 2011 分割训练集标记了 1112 个图像。 哈里哈兰等人收集了更大的 8498个PASCAL训练图像集的标签,用于训练之前最先进的系统SDS。 该训练数据将 FCNVGG16 验证分数 7 提高了 3.4 分,达到 59.4 平均 IU。
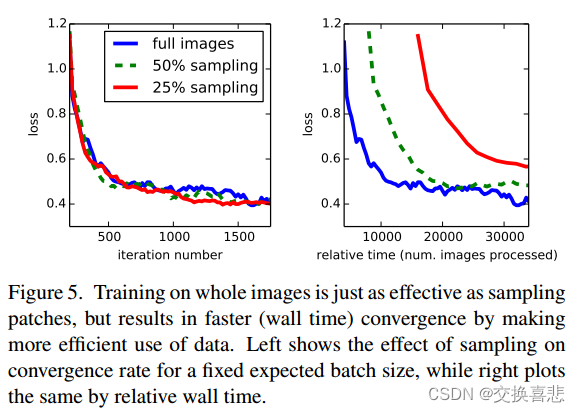
块采样 正如 3.4 节中所解释的,我们的完整图像训练有效地将每个图像批量化为由大的、重叠的块组成的规则网格。 相比之下,先前的工作在完整数据集上随机采样块,可能会导致更高的方差批次,从而加速收敛。 我们通过以前面描述的方式对损失进行空间采样来研究这种权衡,并做出独立选择以概率 1 − p 忽略每个最后层单元。 为了避免改变有效批量大小,我们同时将每批图像数量增加 1/p。 注意哈,由于卷积的效率,对于足够大的 p 值(例如,根据第 3.1 节中的数字,至少 p > 0.2),这种形式的拒绝采样仍然比块训练更快。 图 5 显示了这种形式的采样对收敛的影响。 我们发现,与整个图像训练相比,采样对收敛速度没有显着影响,但由于每批需要考虑的图像数量较多,因此需要花费更多时间。 因此,我们在其他实验中选择未采样的全图像训练。
类平衡 全卷积训练可以通过对损失进行加权或采样来平衡类。 尽管我们的标签稍微不平衡(大约 3/4 是背景),但我们发现类别平衡是不必要的。
密集预测 分数通过网络内的反卷积层上采样到输入维度。 最终层反卷积滤波器固定为双线性插值,而中间上采样层初始化为双线性上采样,然后进行学习。
增强 我们尝试通过随机镜像和“抖动”图像来增强训练数据,方法是将图像在每个方向上使用 32 像素(最粗的预测尺度)(应该是指FCN-32s)。 这没有产生明显的改善。
实现 所有模型均在单个 NVIDIA Tesla K40c 上使用 Caffe 进行训练和测试。 我们的模型和代码可在 http://fcn.berkeleyvision.org 上公开获取。
5.结果

我们在语义分割和场景解析上测试 FCN,探索 PASCAL VOC、NYUDv2 和 SIFT Flow。 尽管这些任务在对象和区域之上取得了历史性的贡献,但我们将它们统一视为像素预测。 我们在每个数据集上评估我们的 FCN 跳跃架构,然后将其扩展到 NYUDv2 的多模态输入以及 SIFT Flow 的语义和几何标签的多任务预测。
指标 我们报告了常见语义分割和场景解析评估的四个指标,这些指标是像素精度和区域交集(IU)的变化。 设 nij 为预测属于 j 类的第 i 类像素的数量,其中有 ncl 个不同的类,并令 ti =∑j nij 为第 i 类的像素总数。 我们计算:
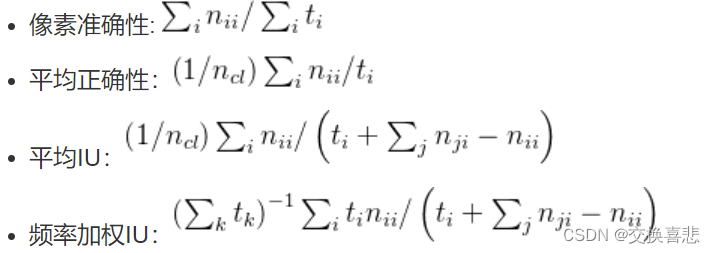
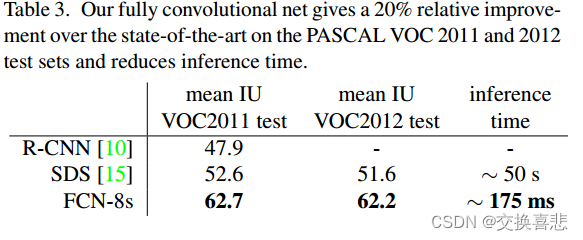
PASCAL VOC 表 3 给出了我们的 FCN-8 在 PASCAL VOC 2011 和 2012 测试集上的性能,并将其与之前的最先进技术SDS和著名的 R-CNN 进行了比较。 我们在平均IU上取得了最佳结果,相对优势为 20%。 推理时间减少了114倍(仅使用卷积网络,忽略提议和细化)或 286 倍(总体)。
NYUDv2 :是使用 Microsoft Kinect 收集的 RGB-D 数据集。 它有 1449 张 RGB-D 图像,带有像素标签,已被 Gupta 等人合并为 40 类语义分割任务。 我们报告了 795 个训练图像和 654 个测试图像的标准分割结果。 (注:所有模型选择均在 PASCAL 2011 val 上进行)表 4 给出了我们的模型在几种变体中的性能。 首先,我们在 RGB 图像上训练未经修改的粗略模型 (FCN-32s)。 为了添加深度信息,我们对升级后的模型进行训练,以采用四通道 RGB-D 输入(早期融合)。 这几乎没有什么好处,可能是因为很难在整个模型中传播有意义的梯度。 继古普塔等人的成功之后,我们尝试了深度的三维 HHA 编码,仅根据该信息训练网络,以及 RGB 和 HHA 的“后期融合”,其中两个网络的预测在最后一层求和,并得到结果 双流网络是端到端学习的。 最后我们将这个后期融合网络升级为16步版本。

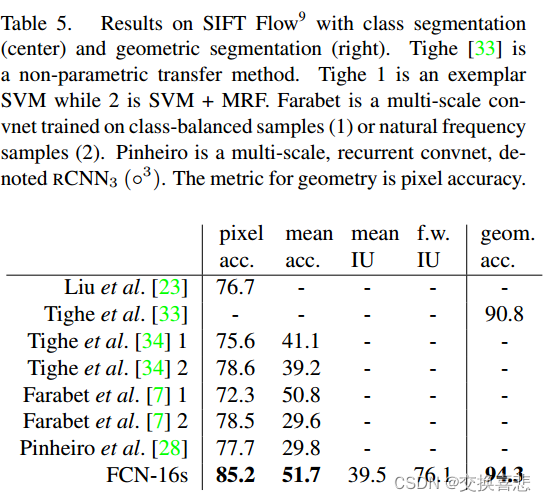
SIFT Flow :是一个包含 2,688 张图像的数据集,这些图像带有 33 个语义类别(“桥”、“山”、“太阳”)以及 3 个几何类别(“水平”、“垂直”和“天空”)的像素标签。 FCN 可以自然地学习同时预测两种类型标签的联合表示。 我们学习 FCN-16 的双头版本,具有语义和几何预测层和损失。 学习模型在这两项任务上的表现与两个独立训练的模型一样好,而学习和推理基本上与每个独立模型本身一样快。 表 5 中的结果按照标准计算,分为 2,488 个训练图像和 200 个测试图像, 显示了这两项任务的最先进性能。
6.结论
全卷积网络是一类丰富的模型,现代分类卷积网络是其中的一个特例。 认识到这一点,将这些分类网络扩展到分割,并通过多分辨率层组合改进架构,可以显着提高最先进的水平,同时简化和加速学习和推理。
致谢: 这项工作得到了 DARPA 的 MSEE 和 SMISC 项目、NSF 奖项 IIS1427425、IIS-1212798、IIS-1116411 以及 NSF GRFP、丰田和伯克利视觉与学习中心的部分支持。 我们衷心感谢 NVIDIA 的 GPU 捐赠。 我们感谢 Bharath Hariharan 和 Saurabh Gupta 的建议和数据集工具。 我们感谢 Sergio Guadarrama 在 Caffe 中重现了 GoogLeNet。 我们感谢 Jitendra Malik 的有益评论。 感谢 Wei Liu 指出了 SIFT Flow 平均 IU 计算的问题以及频率加权平均 IU 公式中的错误。
相关文章:
实例分割论文阅读之:FCN:《Fully Convolutional Networks for Semantica Segmentation》
论文地址:https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf 代码链接:https://github.com/pytorch/vision 摘要 卷积网络是强大的视觉模型,可以产生特征层次结构。我们证明,…...

apk反编译修改教程系列---简单去除apk登陆 修改vip与一些反编译基础常识【十二】
往期教程: 安卓玩机-----反编译apk 修改apk 去广告 去弹窗等操作中的一些常识apk反编译修改教程系列-----修改apk应用名称 任意修改名称 签名【一】 apk反编译修改教程系列-----任意修改apk版本号 版本名 防止自动更新【二】 apk反编译修改教程系列-----修改apk中…...

网络安全习题集
第一章 绪论 4 ISO / OSI 安全体系结构中的对象认证安全服务使用( C ) 机制来完成。 A .访问控制 B .加密 C .数字签名 D .数据完整性 5 身份鉴别是安全服务中的重要一环,以下关于身份鉴别的叙述不正确的是…...

C++中的volatile:穿越编译器的屏障
C中的volatile:穿越编译器的屏障 在C编程中,我们经常会遇到需要与硬件交互或多线程环境下访问共享数据的情况。为了确保程序的正确性和可预测性,C提供了关键字volatile来修饰变量。本文将深入解析C中的volatile关键字,介绍其作用、…...
(07)Hive——窗口函数详解
一、 窗口函数知识点 1.1 窗户函数的定义 窗口函数可以拆分为【窗口函数】。窗口函数官网指路: LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundationhttps://cwiki.apache.org/confluence/display/Hive/LanguageManual%20Windowing…...
【开源图床】使用Typora+PicGo+Github+CDN搭建个人博客图床
准备工作: 首先电脑得提前完成安装如下: 1. nodejs环境(node ,npm):【安装指南】nodejs下载、安装与配置详细教程 2. Picgo:【安装指南】图床神器之Picgo下载、安装与配置详细教程 3. Typora:【安装指南】markdown神器之Typora下载、安装与无限使用详细教…...

阅读笔记(SOFT COMPUTING 2018)Seam elimination based on Curvelet for image stitching
参考文献: Wang Z, Yang Z. Seam elimination based on Curvelet for image stitching[J]. Soft Computing, 2018: 1-16. 注:SOFT COMPUTING 大类学科小类学科Top期刊综述期刊工程技术 3区 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE 计算机…...

LinkedList数据结构链表
LinkedList在Java中是一个实现了List和Deque接口的双向链表。它允许我们在列表的两端添加或删除元素,同时也支持在列表中间插入或移除元素。在分析LinkedList之前,需要理解链表这种数据结构: 链表:链表是一种动态数据结构&#x…...
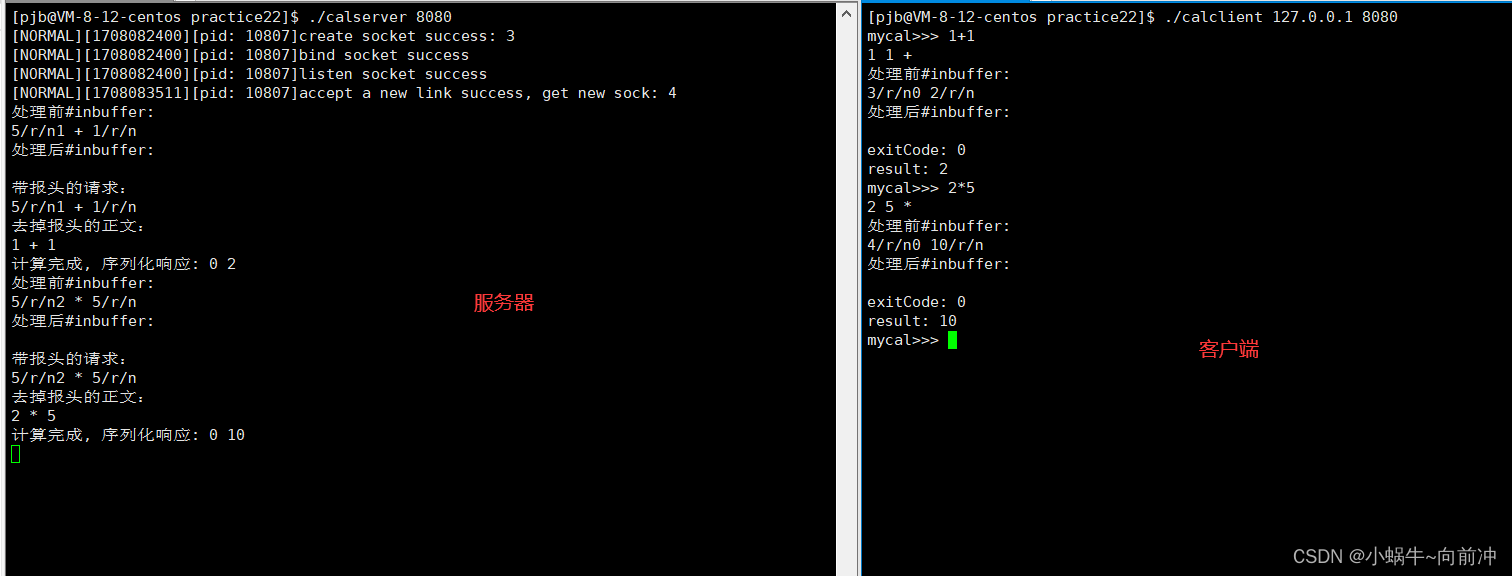
[计算机网络]---序列化和反序列化
前言 作者:小蜗牛向前冲 名言:我可以接受失败,但我不能接受放弃 如果觉的博主的文章还不错的话,还请点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正 目录 一、再谈协议…...

[前端开发] 常见的 HTML CSS JavaScript 事件
代码示例指路 常见的 HTML、CSS、JavaScript 事件代码示例 常见的 HTML CSS JavaScript 事件 事件HTML 事件鼠标事件键盘事件表单事件 JavaScript 事件对象事件代理(事件委托) 事件 在 Web 开发中,事件是用户与网页交互的重要方式之一。通过…...
)
H5/CSS 笔试面试考题(71-80)
简述哪种输入类型用于定义周和年控件(无时区)( ) A:date B:week C:year 面试通过率:67.0% 推荐指数: ★★★★★ 试题难度: 初级 试题类型: 选择题 答案:b 简述下列哪个元素表示外部资源?该元素可以被视为图像、嵌套的浏览上下文或插件要处理的资源。它包括各种属性…...
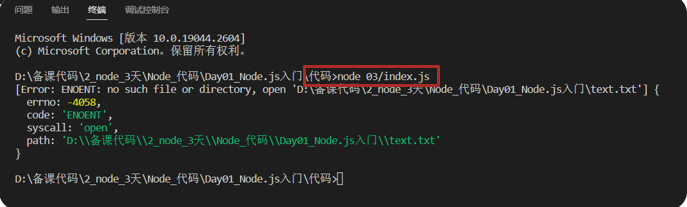
【Node.js】path 模块进行路径处理
Node.js 执行 JS 代码时,代码中的路径都是以终端所在文件夹出发查找相对路径,而不是以我们认为的从代码本身出发,会遇到问题,所以在 Node.js 要执行的代码中,访问其他文件,建议使用绝对路径 实例࿱…...
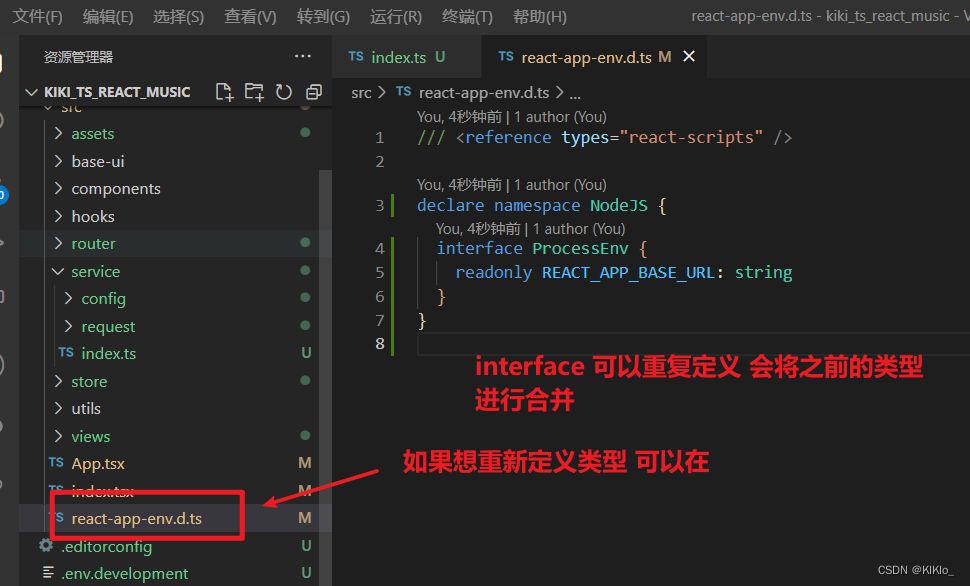
react+ts【项目实战一】配置项目/路由/redux
文章目录 1、项目搭建1、创建项目1.2 配置项目1.2.1 更换icon1.2.2 更换项目名称1.2.1 配置项目别名 1.3 代码规范1.3.1 集成editorconfig配置1.3.2 使用prettier工具 1.4 项目结构1.5 对css进行重置1.6 注入router1.7 定义TS组件的规范1.8 创建代码片段1.9 二级路由和懒加载1.…...
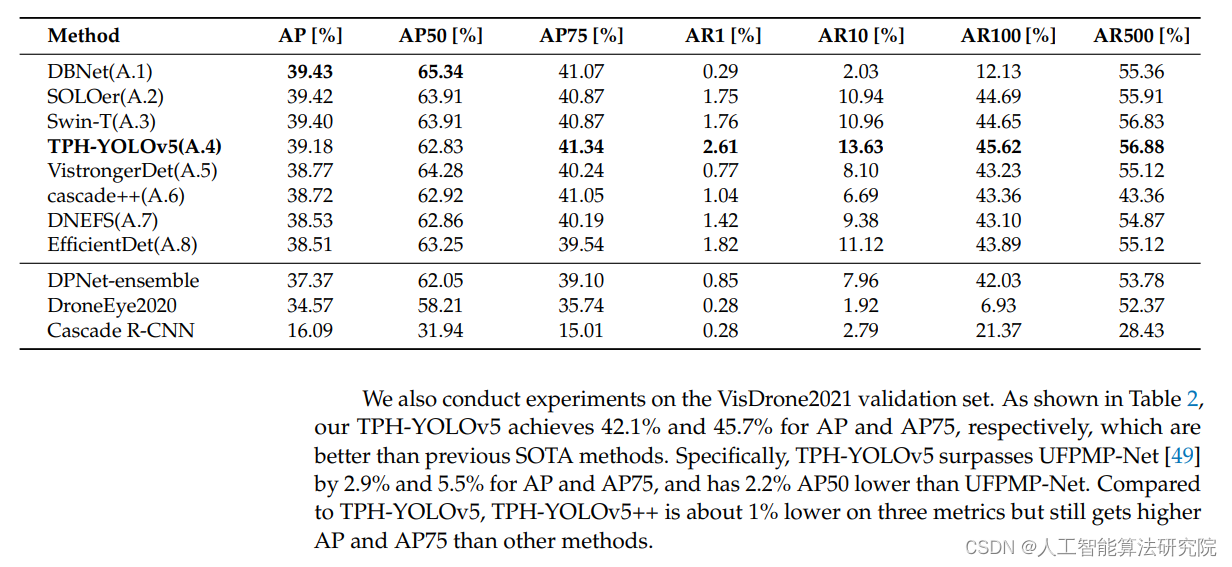
英文论文(sci)解读复现【NO.20】TPH-YOLOv5++:增强捕获无人机的目标检测跨层不对称变压器的场景
此前出了目标检测算法改进专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读发表高水平学术期刊中的 SCI论文&a…...

第十五章 以编程方式使用 SQL 网关 - %SQLGatewayConnection 方法和属性
文章目录 第十五章 以编程方式使用 SQL 网关 - %SQLGatewayConnection 方法和属性FetchRows()GatewayStatus propertyGatewayStatusGet()GetConnection()GetGTWVersion()GetLastSQLCode() 第十五章 以编程方式使用 SQL 网关 - %SQLGatewayConnection 方法和属性 FetchRows() …...

【QTableView】
QTableView是Qt框架中用于显示表格形式数据的部件,通常用于显示数据库查询结果、数据集以及其他类似的结构化数据。 以下是一个使用QTableView的简单示例,假设我们有一个数据库表存储了学生的信息,我们可以使用QSqlTableModel将数据库表关联到QTableView上,并显示出来: …...

VS-Code-C#配置
C#开发环境配置 查看更多学习笔记:GitHub:LoveEmiliaForever 1. 安装 .NET SDK 官方下载网址按照安装程序指引安装即可 2. VS Code 安装插件 插件名:C#发布者是Microsoft 该插件是基础语法插件 插件名:C# Dev Kit发布者是Mic…...
第七篇【传奇开心果系列】Python微项目技术点案例示例:数据可视化界面图形化经典案例
传奇开心果微博系列 系列微博目录Python微项目技术点案例示例系列 微博目录一、微项目开发背景和项目目标:二、雏形示例代码三、扩展思路介绍四、数据输入示例代码五、数据分析示例代码六、排名统计示例代码七、数据导入导出示例代码八、主题定制示例代码九、数据过…...

LeetCode 第33天 | 1005. K 次取反后最大化的数组和 135. 分发糖果 134. 加油站
1005. K 次取反后最大化的数组和 按照绝对值大小降序排序,然后将负值变正,如果所有负值都正了,但是还有k余量且为奇数,那就将绝对值最小值(最后一个元素)取反,否则直接结束。 class Solution {…...

PointMixer论文阅读笔记
MLP-mixer是最近很流行的一种网络结构,比起Transformer和CNN的节构笨重,MLP-mixer不仅节构简单,而且在图像识别方面表现优异。但是MLP-mixer在点云识别方面表现欠佳,PointMixer就是在保留了MLP-mixer优点的同时,还可以…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

探索Windows HEIC缩略图:跨平台照片管理深度解析
探索Windows HEIC缩略图:跨平台照片管理深度解析 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails Windows HEIC缩略图…...

LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理
LangGraph 并发执行不是开 Goroutine 那么简单:状态竞争与事务处理深度解析 元数据 关键词:LangGraph, 大语言模型工作流, 有状态并发, 状态一致性, 事务处理, 多Agent系统, 分布式状态管理 摘要:很多开发者初次接触LangGraph的并发特性时,会下意识将其等同于传统协程/线程…...

Taotoken用量看板如何帮助个人开发者管理月度预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板如何帮助个人开发者管理月度预算 对于独立工作的个人开发者而言,项目预算往往是决定技术选型与使用策…...

qmcdump终极指南:三步解锁QQ音乐加密音频文件
qmcdump终极指南:三步解锁QQ音乐加密音频文件 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 还在为QQ音乐下…...

如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南
如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在寻找百度网盘资源时,被一个小小的提取码卡住,不得不花费…...

Arm Morello平台模型与CHERI安全扩展开发指南
1. Arm Morello平台模型概述Morello是Arm公司推出的实验性处理器架构,基于CHERI(Capability Hardware Enhanced RISC Instructions)安全扩展技术。这个平台模型本质上是一个功能准确的虚拟硬件环境,允许开发者在物理芯片问世前18-…...

基于Stable Diffusion与LoRA技术打造个人AI头像:从原理到实战
1. 项目概述:当AI开始“自拍”——SelfyAI的定位与核心价值最近在AI图像生成领域,一个名为SelfyAI的项目引起了我的注意。它不是一个简单的文生图工具,而是瞄准了一个非常具体且高频的需求:生成高质量、风格一致的个人AI头像。简单…...

数据流编排与异步任务调度中间件kelivo部署与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的项目,叫“Chevey339/kelivo”。乍一看这个标题,可能有点摸不着头脑,它不像那些直接告诉你“XX管理系统”或“XX工具库”的项目名那么直白。但恰恰是这种看似神秘的命名,背后往往隐藏…...

知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧
知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧 【免费下载链接】zhihu-api Zhihu API for Humans 项目地址: https://gitcode.com/gh_mirrors/zh/zhihu-api 在当今数据驱动的时代,知乎数据采集和Python API开发已成为获取高质量中文知识…...