SORA:OpenAI最新文本驱动视频生成大模型技术报告解读
Video generation models as world simulators:作为世界模拟器的视频生成模型
- 1、概览
- 2、Turning visual data into patches:将视觉数据转换为补丁
- 3、Video compression network:视频压缩网络
- 4、Spacetime Latent Patches:时空潜在补丁
- 5、Scaling transformers for video generation:用于视频生成的缩放变压器
- 6、Variable durations, resolutions, aspect ratios:可变持续时间、分辨率、纵横比
- 采样灵活性
- 改进了框架和构图
- 7、Language understanding:语言理解
- 8、Prompting with images and videos:使用图像和视频进行提示
- DALL·E图像动画制作
- 扩展生成的视频
- 视频到视频编辑
- 连接视频
- 9、Image generation capabilities:图像生成能力
- 10、Emerging simulation capabilities:新兴的模拟能力
- 11、Discussion:讨论
1、概览
本技术报告侧重于:
(1)我们将所有类型的视觉数据转化为统一表示的方法,该方法能够对生成模型进行大规模训练。
(2)对Sora的能力和局限性进行定性评估。模型和实施细节未包含在本报告中。
许多先前的工作已经使用各种方法研究了视频数据的生成建模,包括:
递归网络、
生成对抗性网络、
自回归变换器、
和扩散模型。
这些工作通常关注一小类视觉数据、较短的视频或固定大小的视频。
Sora是一个通用的视觉数据模型,它可以生成不同持续时间、宽高比和分辨率的视频和图像,最高可达一分钟的高清视频。

这里OpenAI声称:Sora已经可以较稳定地生成60s连贯长视频。
2、Turning visual data into patches:将视觉数据转换为补丁
我们从大型语言模型中获得灵感,这些模型通过在互联网规模的数据上进行训练来获得通才能力。LLM范式的成功部分归功于使用了巧妙地统一了文本的各种形式——代码、数学和各种自然语言——的令牌。在这项工作中,我们考虑视觉数据的生成模型如何继承这些优势。LLM有文本标记,而Sora有视觉补丁。补丁先前已被证明是视觉数据模型的有效表示。
我们发现补丁是在不同类型的视频和图像上训练生成模型的高度可扩展和有效的表示。
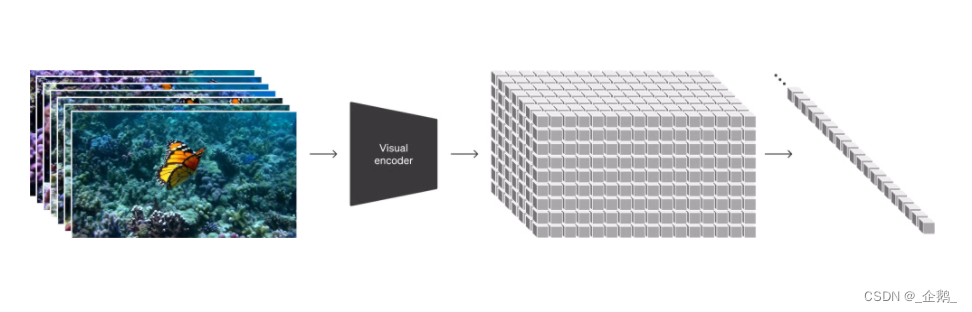
在高水平上,我们通过首先将视频压缩到较低维度的潜在空间中,然后将表示分解为时空补丁,将视频转化为补丁。
值得注意的是,与传统的压缩空间不同,它是对时间维度进行压缩。这也就很好解释了为什么它可以生成60s的长视频。
3、Video compression network:视频压缩网络
我们训练了一个降低视觉数据维度的网络。
这个网络以原始视频作为输入,并输出一个在时间和空间上都被压缩的潜在表示。
Sora在这个压缩的潜在空间中接受训练并随后生成视频。我们还训练了一个相应的解码器模型,该模型将生成的延迟映射回像素空间。
4、Spacetime Latent Patches:时空潜在补丁
给定压缩的输入视频,我们提取一系列时空补丁,这些补丁充当变换器令牌。这种方案也适用于图像,因为图像只是具有单个帧的视频。
我们基于补丁的表示使Sora能够在不同分辨率、持续时间和纵横比的视频和图像上进行训练。在推理时,我们可以通过在适当大小的网格中排列随机初始化的补丁来控制生成的视频的大小。(也就是说Sora支持不同分辨率,不同时长不同横竖比的视频训练及生成)
5、Scaling transformers for video generation:用于视频生成的缩放变压器
Sora是一个扩散模型;给定输入噪声补丁(以及文本提示等条件信息),它被训练来预测原始的“干净”补丁。
重要的是,Sora是一个diffusion transformer。transformer在各种领域都表现出了显著的缩放特性,包括语言建模、计算机视觉和图像生成。

在这项工作中,我们发现diffusion transformer也可以有效地扩展为视频生成模型。
下面,我们展示了随着训练的进行,具有固定种子和输入的视频样本的比较。随着训练计算量的增加,样本质量显著提高。

(可以见得,越训练越狗模狗样了)
6、Variable durations, resolutions, aspect ratios:可变持续时间、分辨率、纵横比
过去的图像和视频生成方法通常将视频调整大小、裁剪或修剪为标准大小,例如,分辨率为256x256的4秒视频。我们发现,相反,对数据进行原生规模的训练可以带来几个好处。
采样灵活性
Sora可以对宽屏幕1920x1080p视频、垂直1080x1920视频以及其间的所有视频进行采样。这使Sora可以直接按照不同设备的固有纵横比为其创建内容。它还允许我们在以全分辨率生成之前快速原型化较低大小的内容——所有这些都使用相同的模型。

改进了框架和构图
我们根据经验发现,以视频的固有长宽比进行视频训练可以改善构图和取景。我们将Sora与我们的模型的一个版本进行比较,该版本将所有训练视频裁剪为正方形,这是训练生成模型时的常见做法。在方形裁剪上训练的模型(左)有时会生成仅部分可见主题的视频。相比之下,Sora(右)的视频有了更好的取景效果。

(这里是说Sora通过调整视频比例有了更好的生成效果,这里本文作者存疑,技术报告这一段的描述颇有种裁剪拼贴效果更好的感觉)
7、Language understanding:语言理解
训练文本到视频生成系统需要大量具有相应文本字幕的视频。我们将DALL-E3中引入的重字幕技术应用于视频。我们首先训练一个高度描述性的字幕器模型,然后使用它为训练集中的所有视频生成文本字幕。我们发现,对高度描述性视频字幕的训练可以提高文本保真度以及视频的整体质量。
与DALL-E3类似,我们还利用GPT将简短的用户提示转换为发送到视频模型的更长详细的字幕。这使Sora能够准确地按照用户提示生成高质量的视频。
8、Prompting with images and videos:使用图像和视频进行提示
上面和我们的登录页中的所有结果都显示了文本到视频的示例。但Sora也可以被其他输入提示,例如预先存在的图像或视频。这一功能使索拉能够执行广泛的图像和视频编辑任务——创建完美循环的视频、为静态图像设置动画、在时间上向前或向后扩展视频等。
DALL·E图像动画制作
Sora能够生成提供图像和提示作为输入的视频。下面展示了基于DALL·E 231和DALL·E 330图像生成的示例视频。



扩展生成的视频
Sora还能够在时间上向前或向后扩展视频。接下来介绍了四个视频,它们都是从生成的视频片段开始向后扩展的。因此,四个视频中的每个视频的开头都与其他视频不同,但所有四个视频的结局都相同。
我们可以使用这种方法向前和向后扩展视频,以产生无缝的无限循环。
视频到视频编辑
扩散模型已经实现了从文本提示编辑图像和视频的大量方法。下面我们将其中一种方法SDEdit,32应用于Sora。这项技术使Sora能够转换零样本输入视频的风格和环境。
连接视频
我们还可以使用Sora在两个输入视频之间逐渐插值,在具有完全不同主题和场景组成的视频之间创建无缝过渡。在下面的示例中,中心的视频在左侧和右侧的相应视频之间进行插值。



9、Image generation capabilities:图像生成能力
Sora还能够生成图像。我们通过在时间范围为一帧的空间网格中排列高斯噪声块来实现这一点。该模型可以生成各种尺寸的图像,分辨率高达2048x2048。
(是对图像生成领域的冲击)
10、Emerging simulation capabilities:新兴的模拟能力
我们发现,视频模型在大规模训练时表现出许多有趣的突发能力。这些功能使索拉能够从物理世界模拟人、动物和环境的某些方面。这些特性的出现对3D、物体等没有任何明显的归纳偏差——它们纯粹是尺度现象。
3D一致性。Sora可以生成具有动态相机运动的视频。随着相机的移动和旋转,人和场景元素在三维空间中一致移动。
(也是对三维模型生成领域的冲击)
(好狠的Sora,主打一个吃干抹净)
远距离连贯性和物体持久性。视频生成系统的一个重大挑战是在对长视频进行采样时保持时间一致性。我们发现Sora通常(尽管并非总是)能够有效地对短期和长期依赖关系进行建模。例如,我们的模型可以持久化人、动物和物体,即使它们被遮挡或离开框架。同样,它可以在单个样本中生成同一角色的多个镜头,从而在整个视频中保持其外观。
与世界互动。Sora有时可以用简单的方式模拟影响世界状态的动作。例如,一个画家可以在画布上留下新的笔触,并随着时间的推移而持续,或者一个男人可以吃汉堡并留下咬痕。
模拟数字世界:Sora还能够模拟人工过程,例如电子游戏。索拉可以用一个基本策略同时控制《我的世界》中的玩家,同时也可以高保真地渲染世界及其动态。这些功能可以通过提示索拉使用提及“我的世界”的标题来引发零样本
这些能力表明,视频模型的持续扩展是开发物理和数字世界以及生活在其中的物体、动物和人的高效模拟器的一条很有前途的道路。
11、Discussion:讨论

Sora目前作为一个模拟器表现出许多局限性。
例如,它不能准确地模拟许多基本相互作用的物理过程,比如玻璃破碎。其他相互作用,比如吃食物,并不总是能产生物体状态的正确变化。
我们在登录页中列举了该模型的其他常见故障模式,如长时间样本中出现的不相干或对象的自发出现。

我们相信,Sora今天的能力表明,视频模型的持续扩展是开发物理和数字世界以及生活在其中的物体、动物和人的强大模拟器的一条很有前途的道路。
相关文章:
SORA:OpenAI最新文本驱动视频生成大模型技术报告解读
Video generation models as world simulators:作为世界模拟器的视频生成模型 1、概览2、Turning visual data into patches:将视觉数据转换为补丁3、Video compression network:视频压缩网络4、Spacetime Latent Patches:时空潜在…...

阿里云第七代云服务器ECS计算c7、通用g7和内存r7配置如何选择?
阿里云服务器配置怎么选择合适?CPU内存、公网带宽和ECS实例规格怎么选择合适?阿里云服务器网aliyunfuwuqi.com建议根据实际使用场景选择,例如企业网站后台、自建数据库、企业OA、ERP等办公系统、线下IDC直接映射、高性能计算和大游戏并发&…...
视觉slam十四讲学习笔记(六)视觉里程计 1
本文关注基于特征点方式的视觉里程计算法。将介绍什么是特征点,如何提取和匹配特征点,以及如何根据配对的特征点估计相机运动。 目录 前言 一、特征点法 1 特征点 2 ORB 特征 FAST 关键点 BRIEF 描述子 3 特征匹配 二、实践:特征提取…...
PyTorch-线性回归
已经进入大模微调的时代,但是学习pytorch,对后续学习rasa框架有一定帮助吧。 <!-- 给出一系列的点作为线性回归的数据,使用numpy来存储这些点。 --> x_train np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],[9.779], [6.1…...
C++数据结构与算法——栈与队列
C第二阶段——数据结构和算法,之前学过一点点数据结构,当时是基于Python来学习的,现在基于C查漏补缺,尤其是树的部分。这一部分计划一个月,主要利用代码随想录来学习,刷题使用力扣网站,不定时更…...
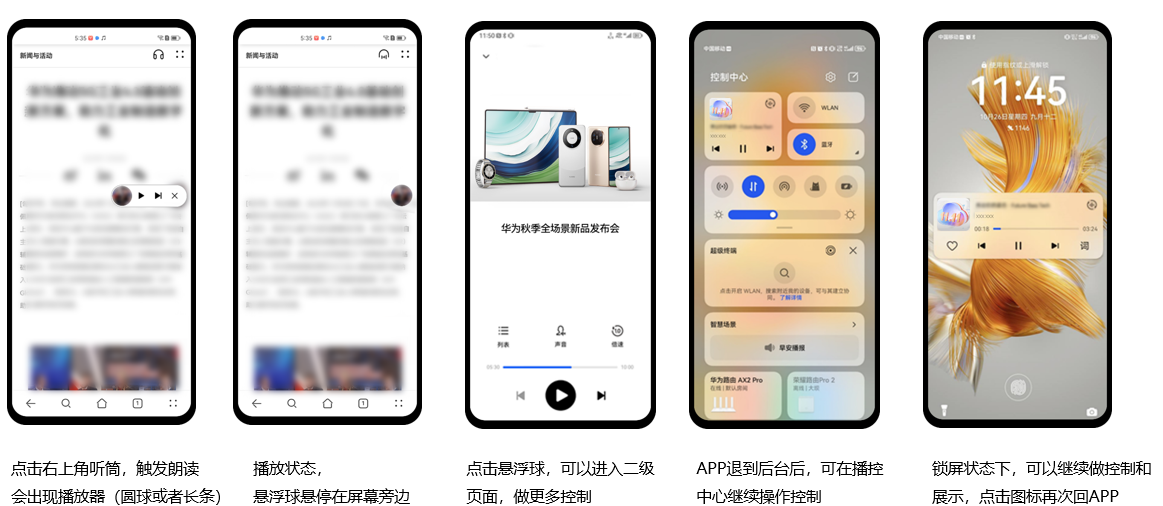
掌上新闻随心播控,HarmonyOS SDK助力新浪新闻打造精致易用的资讯服务新体验
原生智能是HarmonyOS NEXT的核心亮点之一,依托HarmonyOS SDK丰富全面的开放能力,开发者只需通过几行代码,即可快速实现AI功能。新浪新闻作为鸿蒙原生应用开发的先行者之一,从有声资讯入手,将基于Speech Kit朗读控件上线…...
2024年危险化学品经营单位主要负责人证模拟考试题库及危险化学品经营单位主要负责人理论考试试题
题库来源:安全生产模拟考试一点通公众号小程序 2024年危险化学品经营单位主要负责人证模拟考试题库及危险化学品经营单位主要负责人理论考试试题是由安全生产模拟考试一点通提供,危险化学品经营单位主要负责人证模拟考试题库是根据危险化学品经营单位主…...

C/C++如何把指针所指向的指针设为空指针?
实践出真知,指针对于初学的友友来说,头都要大了。喵喵一直遵循在实践中学,在学习中实践,相信你也会有所得! 以下是该问题的解决方案: int** ptrPtr new int*; // 创建指向指针的指针 int* ptr new int;…...
第三节:基于 InternLM 和 LangChain 搭建你的知识库(课程笔记)
视频链接:https://www.bilibili.com/video/BV1sT4y1p71V/?vd_source3bbd0d74033e31cbca9ee35e111ed3d1 文档地址: https://github.com/InternLM/tutorial/tree/main/langchain 课程笔记: 1.仅仅包含训练时间点之前的数据,无法…...
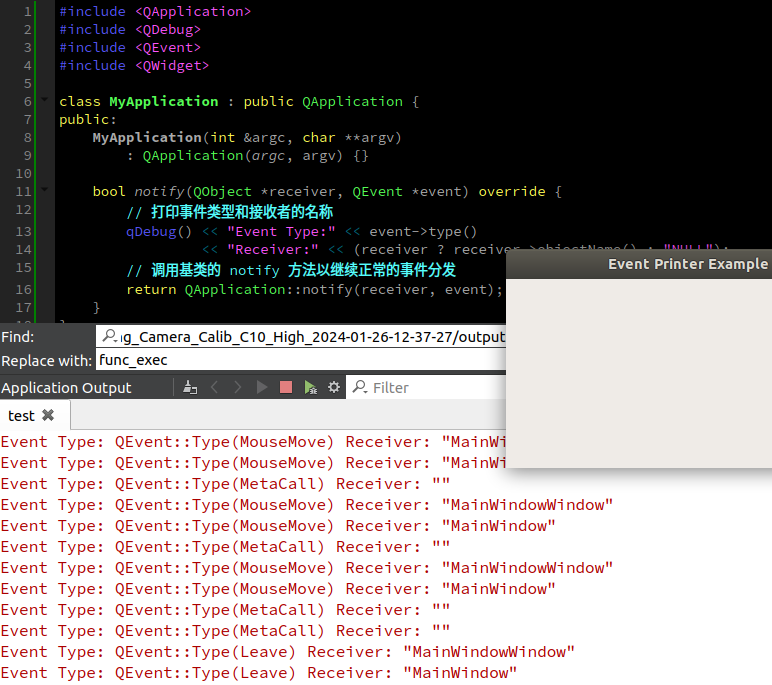
qt-C++笔记之打印所有发生的事件
qt-C笔记之打印所有发生的事件 code review! 文章目录 qt-C笔记之打印所有发生的事件1.ChatGPT问答使用 QApplication 的 notify 方法使用 QObject 的 event 方法 2.使用 QObject 的 event 方法3.使用 QApplication 的 notify 方法 1.ChatGPT问答 在Qt C中,若要打…...

pytorch 实现线性回归(深度学习)
一 查看原始函数 初始化 %matplotlib inline import random import torch from d2l import torch as d2l 1.1 生成原始数据 def synthetic_data(w, b, num_examples):x torch.normal(0, 1, (num_examples, len(w)))y torch.matmul(x, w) bprint(x:, x)print(y:, y)y tor…...
[Doris] Doris的安装和部署 (二)
文章目录 1.安装要求1.1 Linux操作系统要求1.2 软件需求1.3 注意事项1.4 内部端口 2.集群部署2.1 操作系统安装要求2.2 下载安装包2.3 解压2.4 配置FE2.5 配置BE2.6 添加BE2.7 FE 扩容和缩容2.8 Doris 集群群起脚本 3.图形化 1.安装要求 1.1 Linux操作系统要求 1.2 软件需求 1…...
)
【QT+QGIS跨平台编译】之三十五:【cairo+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、cairo介绍二、文件下载三、文件分析四、pro文件五、编译实践一、cairo介绍 Cairo是一个功能强大的开源2D图形库,它提供了一套跨平台的API,用于绘制矢量图形和文本。Cairo支持多种输出目标,包括屏幕、图像文件、PDF、SVG等。 Cairo的设计目标是简单易用、高效…...

MySQL(基础)
第01章_数据库概述 1. 为什么要使用数据库 持久化(persistence):把数据保存到可掉电式存储设备中以供之后使用。大多数情况下,特别是企业级应用,数据持久化意味着将内存中的数据保存到硬盘上加以”固化”,而持久化的实现过程大多…...
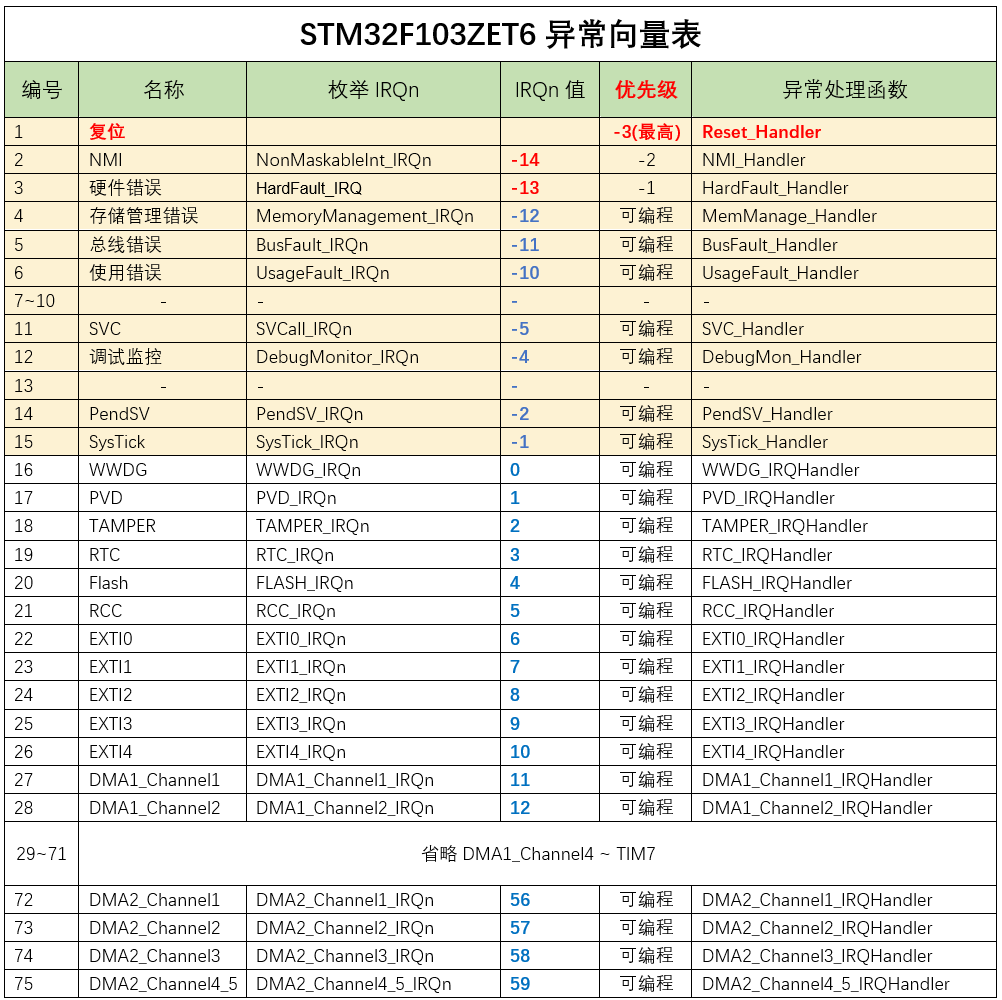
STM32F1 - 中断系统
Interrupt 1> 硬件框图2> NVIC 中断管理3> EXTI 中断管理3.1> EXTI与NVIC3.2> EXTI内部框图 4> 外部中断实验4.1> 实验概述4.2> 程序设计 5> 中断向量表6> 总结 1> 硬件框图 NVIC:Nested Vectored Interrupt Controller【嵌套向量…...
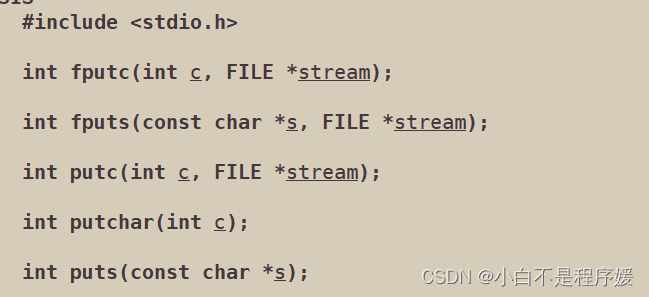
【Linux系统化学习】缓冲区
目录 缓冲区 一个样例 现象解释 缓冲区存在的位置 缓冲区 在刚开始学习C语言的时候我们就听过缓冲区这个名词,很是晦涩难懂;在Linux下进程退出时也包含缓冲区,因此缓冲区到底是什么?有什么作用? 让我们先从一个小…...
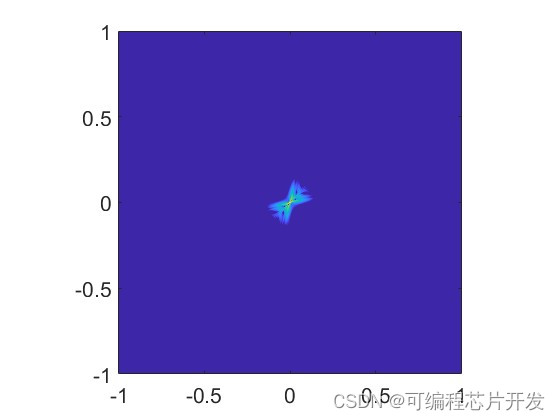
基于BP算法的SAR成像matlab仿真
目录 1.课题概述 2.系统仿真结果 3.核心程序与模型 4.系统原理简介 4.1 BP算法的基本原理 4.2 BP算法的优点与局限性 5.完整工程文件 1.课题概述 基于BP算法的SAR成像。合成孔径雷达(SAR)是一种高分辨率的雷达系统,能够在各种天气和光…...
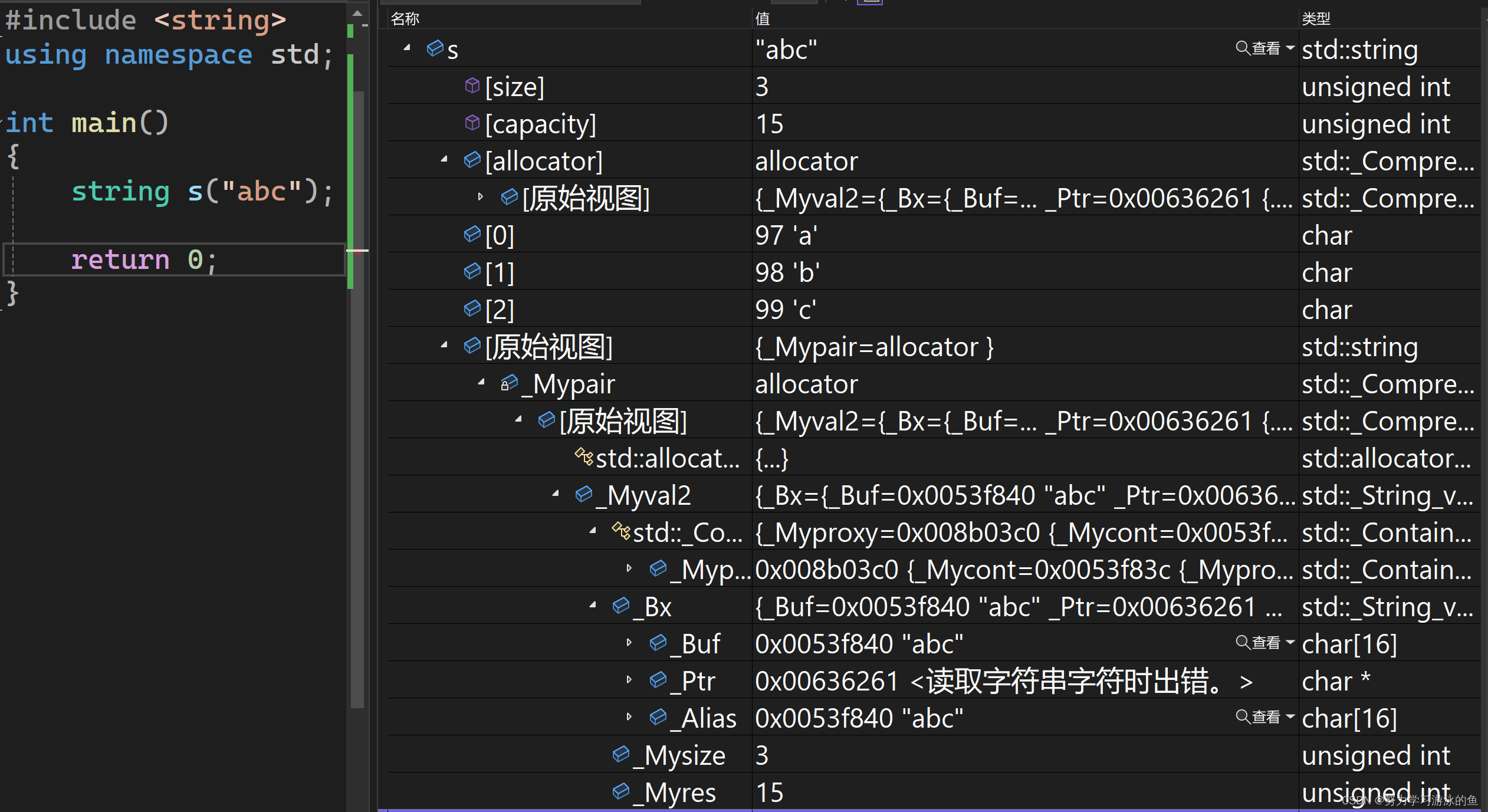
【C++ STL】你真的了解string吗?浅谈string的底层实现
文章目录 底层结构概述扩容机制浅拷贝与深拷贝插入和删除的效率浅谈VS和g的优化总结 底层结构概述 string可以帮助我们很好地管理字符串,但是你真的了解她吗?事实上,string的设计是非常复杂的,拥有上百个接口,但最常用…...

17.3.1.3 灰度
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 灰度的算法主要有以下三种: 1、最大值法: 原图像:颜色值color(R,G,B&a…...

基于CAS操作的atomic原子类型
在上一节的卖票程序中,我们讲解了如何在多线程中保证临界资源的正确访问——使用互斥锁,即 lock_guard<mutex> lock(mtx); count;lock_guard<mutex> lock(mtx); count--; 从汇编角度解释线程间互斥-mutex互斥锁与lock_guard的使用-CSDN博客…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...

NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南
NVIDIA Profile Inspector深度解析:解锁显卡隐藏性能的实战指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 你是否曾为游戏卡顿而烦恼?是否觉得显卡性能总差那么一点&#x…...

攻克R与Python的壁垒:Giotto空间转录组分析环境一站式搭建指南
1. 为什么你的Giotto安装总是失败? 每次看到空间转录组数据就手痒想用Giotto分析,结果安装环节就被劝退?这可能是大多数生物信息学新手都会遇到的尴尬。作为一个在生信领域摸爬滚打多年的"环境配置工程师",我太理解这种…...
)
【限时公开】后印象派专属--ar 16:9 --style raw --stylize 800参数组合包(含塞尚构图/修拉点彩/劳特累克动态线共12套已验证prompt模板)
更多请点击: https://intelliparadigm.com 第一章:后印象派艺术精神与Midjourney风格迁移的本质逻辑 后印象派并非对印象派的简单延续,而是对主观表达、结构重构与象征张力的自觉回归——梵高旋转的星云、塞尚凝练的几何体、高更原始的色域&…...

开源虚拟世界引擎Vircadia核心架构与部署实战指南
1. 项目概述:一个开源虚拟世界的核心引擎如果你对构建一个属于自己的、去中心化的虚拟世界感兴趣,那么你很可能已经听说过或者正在寻找一个合适的底层引擎。今天要聊的这个项目,就是这样一个领域的重量级选手:vircadia/vircadia-n…...

罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性
罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求…...

开源办公套件自动化部署与集成实战:基于OpenOffice的服务化解决方案
1. 项目概述:为什么我们需要一个“开源”的办公套件?如果你在GitHub上搜索过办公软件相关的仓库,大概率会看到过longyangxi/OpenOffice这个项目。乍一看,你可能会以为这是一个Apache OpenOffice的镜像或者某个分支。但点进去仔细研…...

LLM应用快速演示框架:从架构解析到智能体开发的实战指南
1. 项目概述:一个面向开发者的LLM应用快速演示框架最近在GitHub上闲逛,发现了一个名为wronai/llm-demo的项目,点进去一看,瞬间觉得眼前一亮。这可不是又一个简单的“Hello World”式的大语言模型调用示例,而是一个结构…...

从零构建专属大语言模型:Self-LLM开源项目全流程实践指南
1. 项目概述与核心价值最近在开源社区里,一个名为datawhalechina/self-llm的项目引起了我的注意。乍一看,这像是一个关于大语言模型(LLM)的仓库,但“self”这个前缀又让人浮想联翩。经过一段时间的深入研究和实践&…...
Pixel Framebuf库:图形化编程驱动LED矩阵,告别底层坐标换算
1. 项目概述:告别点灯,拥抱图形化LED矩阵编程如果你玩过Arduino或者树莓派,大概率接触过WS2812B这类可寻址LED,也就是大家常说的NeoPixel。单个灯珠的控制很简单,setPixelColor一下就能亮。但当你面对一个8x8、16x16甚…...