(12)Hive调优——count distinct去重优化
离线数仓开发过程中经常会对数据去重后聚合统计,count distinct使得map端无法预聚合,容易引发reduce端长尾,以下是count distinct去重调优的几种方式。
解决方案一:group by 替代
原sql 如下:
#=====7日、14日的app点击的用户数(user_id去重统计)
selectgroup_id,app_id,
-- 7日内UVcount(distinct case when dt >= '${7d_before}' then user_id else null end) as 7d_uv,
--14日内UVcount(distinct case when dt >= '${14d_before}' then user_id else null end) as 14d_uv
from tbl
where dt >= '${14d_before}'
group by group_id, --渠道app_id; --app优化思路:group by两阶段聚合
#=====7日、14日的app点击的用户数(user_id去重统计)
selectgroup_id,app_id,
-- 7日内UVsum(case when 7d_cnt > 0 then 1 else 0 end) as 7d_uv,
--14日内UVsum(case when 14d_uv > 0 then 1 else 0 end) as 14d_uvfrom (selectgroup_id,app_id,-- 7日内各渠道各app下的每个用户的点击量count(case when dt >= '${7d_before}' then user_id else null end) as 7d_cnt,-- 14日内各渠道各app下的每个用户点击量count(case when dt >= '${14d_before}' then user_id else null end) as 14d_uvfrom tblwhere dt >= '${14d_before}'group by group_id,app_id,user_id) tmp1
group by group_id,app_id;方案一弊端:数据倾斜风险
解决方案一通过两阶段group by(分组聚合) 对count (distinct) 进行改造调优,需要注意的是:如果分组字段user_id在tbl 表中存在大量的重复值,group by底层走shuffle,会有数据倾斜的风险,因此方案一还可以进一步优化。
解决方案二:group by调优
1)添加随机数,两阶段聚合(推荐)
#===============优化前
insert overwrite table tblB partition (dt = '2022-10-19')
selectcookie_id,event_query,count(*) as cnt
from tblA
where dt >= '20220718'and dt <= '20221019'and event_query is not null
group by cookie_id, event_query#===============优化后
insert overwrite table tblB partition (dt = '2022-10-19')
selectsplit(tkey, '_')[1] as cookie_id,event_query,#--- 求出最终的聚合值sum(cnt) as cnt
from (selectconcat_ws('_', cast(ceiling(rand() * 99) as string), cookie_id) as tkey,event_query,#---将热点Key值:cookie_id 进行打散后,先局部聚合得到cntcount(*) as cntfrom tblAwhere dt >= '20220718'and dt <= '20221019'and event_query is not null#--- 第一阶段:添加[0-99]随机整数,将热点Key值:cookie_id 进行打散( M -->R)group by concat_ws('_', cast(ceiling(rand() * 99) as string), cookie_id),event_query) temp#--- 第二阶段:对拼接的key值进行切分,还原原本的key值split(tkey, '_')[1] =cookie_id ( R -->R)
group by split(tkey, '_')[1], event_que优化思路为:
- 第一阶段:对需要聚合的Key值添加随机后缀进行打散,基于加工后的key值进行初步聚合(M-->R1)
- 第二阶段:对加工后的key值进行切分还原,对第一阶段的聚合值进行再次聚合,求出最终结果值(R1-->R2)
2)开启Map端聚合
#--开启Map端聚合,默认为true
set hive.map.aggr = true;
#--在Map 端预先聚合操作的条数
set hive.groupby.mapaggr.checkinterval = 100000;
该参数可以将顶层的聚合操作放在 Map 阶段执行,从而减轻shuffle清洗阶段的数据传输和 Reduce阶段的执行时间,提升总体性能。
3)数据倾斜时自动负载均衡
#---有数据倾斜的时候自动负载均衡(默认是 false)
set hive.groupby.skewindata = true;
开启该参数后,当前程序会自动通过两个MapReduce来运行,将M->R阶段 拆解成 M->R->R阶段
- 第一个MapReduce自动进行随机分布到Reducer中(负载均衡),每个Reducer做部分聚合操作,输出结果
- 第二个MapReduce将上一步聚合的结果再按照业务(group by key)进行处理,保障相同的key分发到同一个reduce做最终聚合。
相关文章:
Hive调优——count distinct去重优化)
(12)Hive调优——count distinct去重优化
离线数仓开发过程中经常会对数据去重后聚合统计,count distinct使得map端无法预聚合,容易引发reduce端长尾,以下是count distinct去重调优的几种方式。 解决方案一:group by 替代 原sql 如下: #7日、14日的app点击的…...
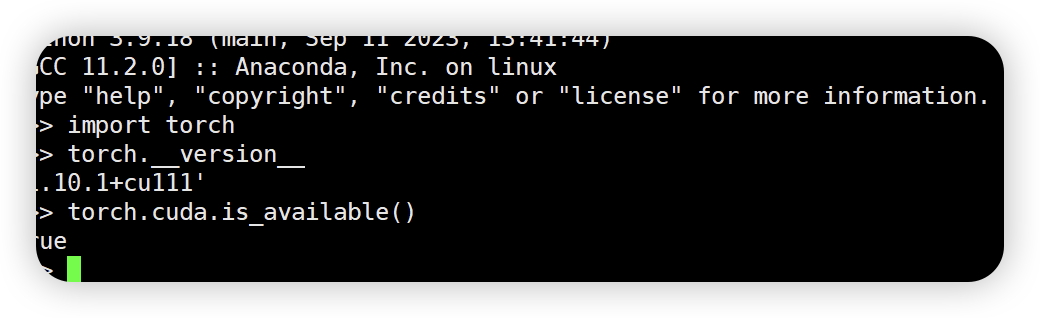
记录 | 验证pytorch-cuda是否安装成功
检测程序如下: import torchprint(torch.__version__) print(torch.cuda.is_available()) 或者用终端 Shell,运行情况如下...

LeetCode 239.滑动窗口的最大值 Hot100 单调栈
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums [1,3,-1,-3,5,3,6,7], k 3 输…...
463. Island Perimeter(岛屿的周长)
问题描述 给定一个 row x col 的二维网格地图 grid ,其中:grid[i][j] 1 表示陆地, grid[i][j] 0 表示水域。 网格中的格子 水平和垂直 方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有…...
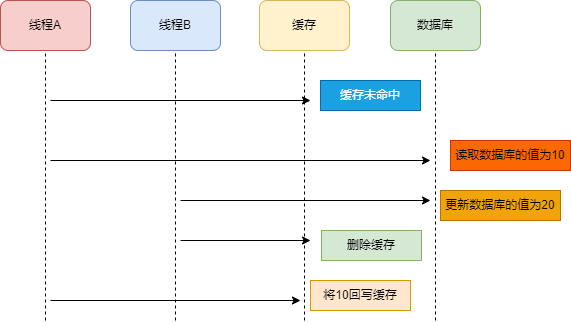
如何解决缓存和数据库的数据不一致问题
数据不一致问题是操作数据库和操作缓存值的过程中,其中一个操作失败的情况。实际上,即使这两个操作第一次执行时都没有失败,当有大量并发请求时,应用还是有可能读到不一致的数据。 如何更新缓存 更新缓存的步骤就两步࿰…...

linux系统下vscode portable版本的python环境搭建003:venv
这里写自定义目录标题 python安装方案一. 使用源码安装(有[构建工具](https://blog.csdn.net/ResumeProject/article/details/136095629)的情况下)方案二.使用系统包管理器 虚拟环境安装TESTCG 本文目的:希望在获得一个新的系统之后ÿ…...
使用TinyXML-2解析XML文件
一、XML介绍 当我们想要在不同的程序、系统或平台之间共享信息时,就需要一种统一的方式来组织和表示数据。XML(EXtensible Markup Language,即可扩展标记语言)是一种用于描述数据的标记语言,它让数据以一种结构化的方…...
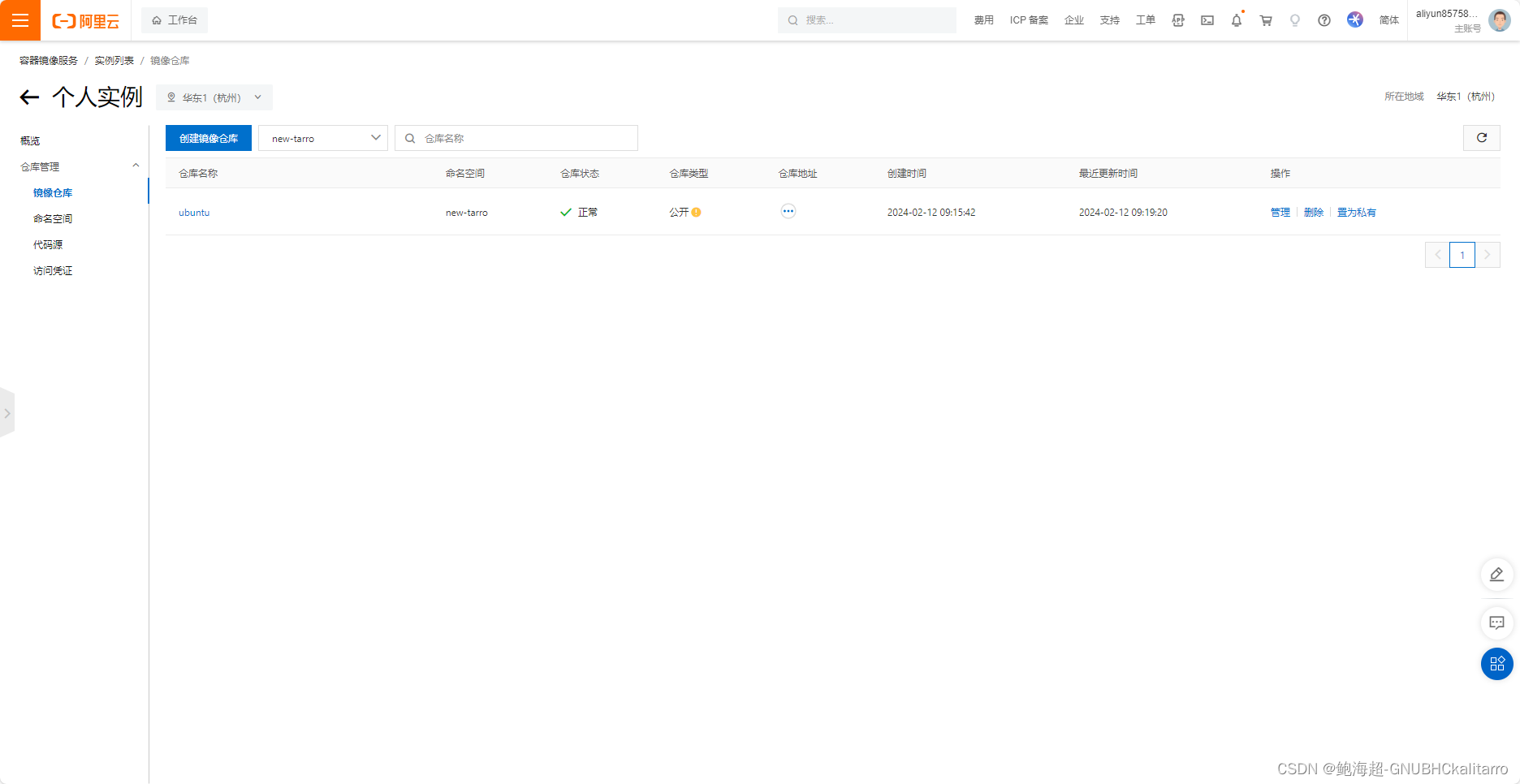
Linux:docker在线仓库(docker hub 阿里云)基础操作
把镜像放到公网仓库,这样可以方便大家一起使用,当需要时直接在网上拉取镜像,并且你可以随时管理自己的镜像——删除添加或者修改。 1.docker hub仓库 2.阿里云加速 3.阿里云仓库 由于docker hub是国外的网站,国内的对数据的把控…...
C语言程序设计(第四版)—习题7程序设计题
目录 1.选择法排序。 2.求一批整数中出现最多的数字。 3.判断上三角矩阵。 4.求矩阵各行元素之和。 5.求鞍点。 6.统计大写辅音字母。 7.字符串替换。 8.字符串转换成十进制整数。 1.选择法排序。 输入一个正整数n(1<n≤10)…...

ZCC6982-同步升压充双节锂电池充电芯片
特性 ■高达 2A 的可调充电电流(受实际散热和输入功率限制) ■支持 8.4V、8.6V、8.7V、8.8V 的充满电压(限QFN) ■高达 28V 的输入耐压保护 ■高达 28V 的电池端耐压保护 ■宽输入工作电压范围:3.0V~6.5V ■峰值…...
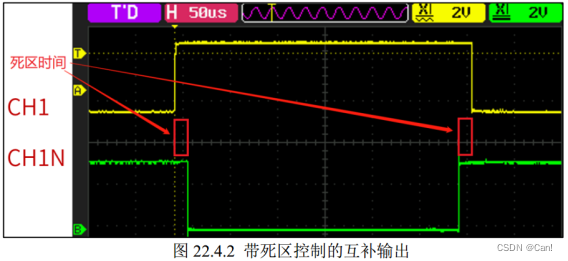
定时器(基本定时器、通用定时器、高级定时器)
目录 一、基本定时器 二、通用定时器 三、高级定时器 一、基本定时器 1、作用:计时和计数。 二、通用定时器 1、除了有基本定时器的计时和计数功能外,主要有输入捕获和输出比较的功能,硬件主要由六大部分组成: ① 时钟源 ② 控…...

009集——磁盘详解——电脑数据如何存储在磁盘
很多人也知道数据能够保存是由于设备中有一个叫做「硬盘」的组件存在,但也有很多人不知道硬盘是怎样储存这些数据的。这里给大家讲讲其中的原理。 首先我们要明白的是,计算机中只有0和1,那么我们存入硬盘的数据,实际上也就是一堆0…...

鸿蒙开发-HarmonyOS UI架构
初步布局Index 当我们新建一个工程之后,首先会进入Index页。我们先简单的做一个文章列表的显示 class Article {title?: stringdesc?: stringlink?: string }Entry Component struct Index {State articles: Article[] []build() {Row() {Scroll() {Column() …...

Flutter 动画(显式动画、隐式动画、Hero动画、页面转场动画、交错动画)
前言 当前案例 Flutter SDK版本:3.13.2 显式动画 Tween({this.begin,this.end}) 两个构造参数,分别是 开始值 和 结束值,根据这两个值,提供了控制动画的方法,以下是常用的; controller.forward() : 向前…...

用HTML5 Canvas创造视觉盛宴——动态彩色线条效果
目录 一、程序代码 二、代码原理 三、运行效果 一、程序代码 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <!-- 声明文档类型为XHTML 1.0 Transitional -…...
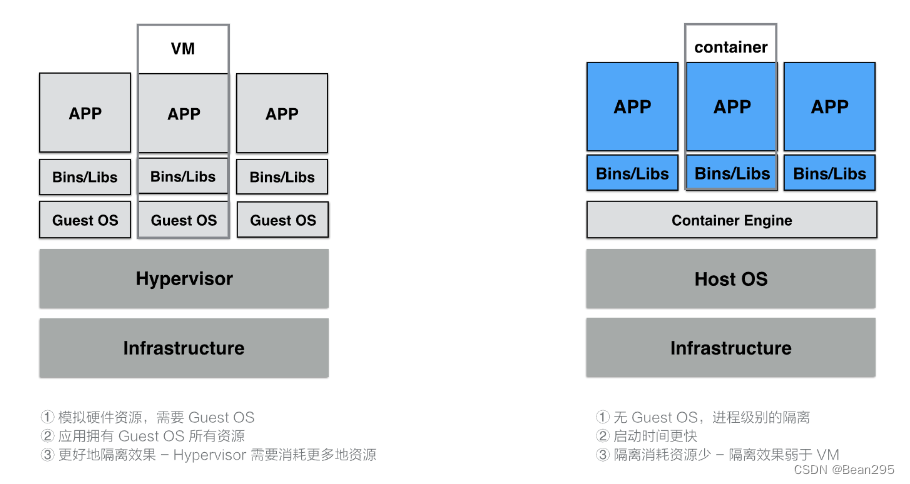
云原生介绍与容器的基本概念
云原生介绍 1、云原生的定义 云原生为用户指定了一条低心智负担的、敏捷的、能够以可扩展、可复制的方式最大化地利用云的能力、发挥云的价值的最佳路径。 2、云原生思想两个理论 第一个理论基础是:不可变基础设施。 第二个理论基础是:云应用编排理…...
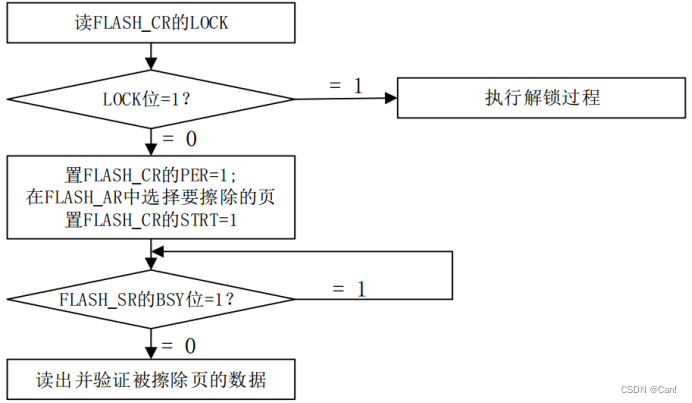
Flash存储
目录 一、MCU读写擦除Flash步骤 1、写flash步骤: 2、读flash步骤: 3、擦除flash步骤: 4、要注意的地方: 一、MCU读写擦除Flash步骤 1、写flash步骤: (1)解锁 2、读flash步骤: 3、擦除flash步骤&#x…...
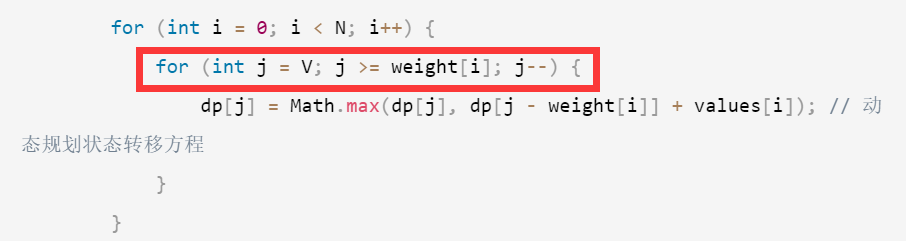
Day 44 | 动态规划 完全背包、518. 零钱兑换 II 、 377. 组合总和 Ⅳ
完全背包 题目 文章讲解 视频讲解 完全背包和0-1背包的区别在于:物品是否可以重复使用 思路:对于完全背包问题,内层循环的遍历方式应该是从weight[i]开始一直遍历到V,而不是从V到weight[i]。这样可以确保每种物品可以被选择多次…...
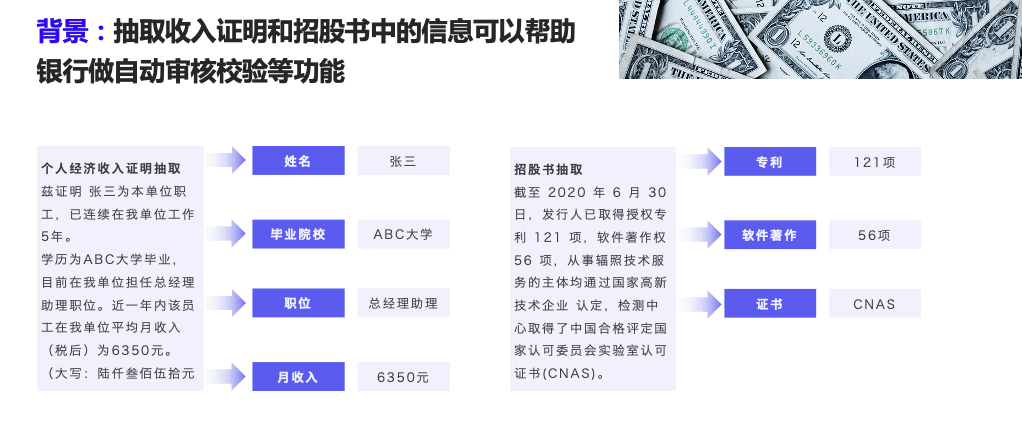
使用PaddleNLP UIE模型提取上市公司PDF公告关键信息
项目地址:使用PaddleNLP UIE模型抽取PDF版上市公司公告 - 飞桨AI Studio星河社区 (baidu.com) 背景介绍 本项目将演示如何通过PDFPlumber库和PaddleNLP UIE模型,抽取公告中的相关信息。本次任务的PDF内容是破产清算的相关公告,目标是获取受理…...
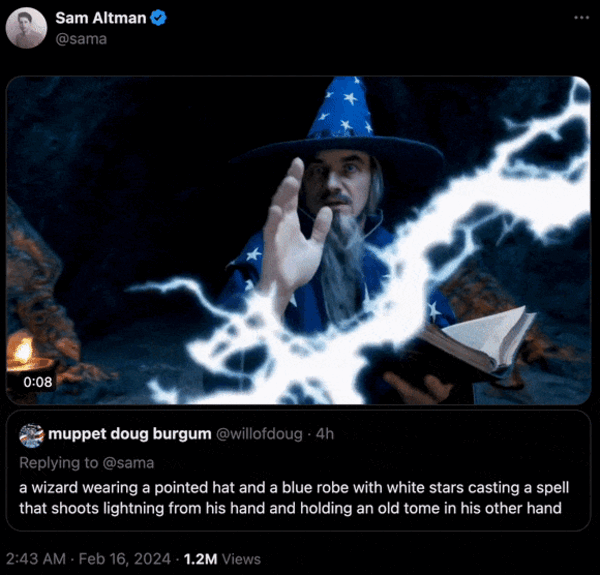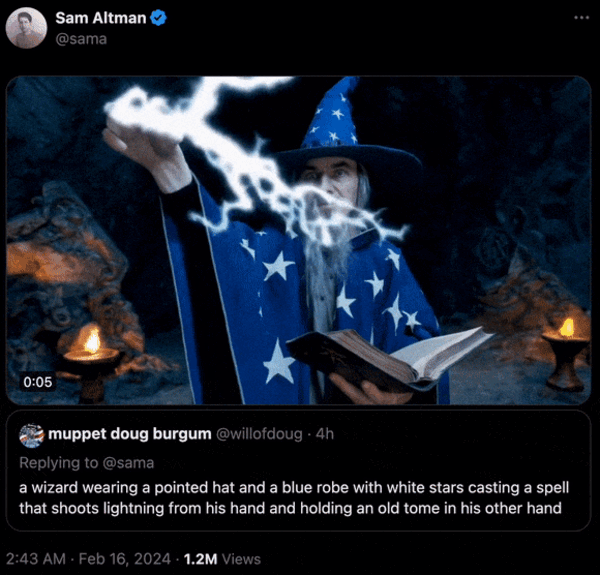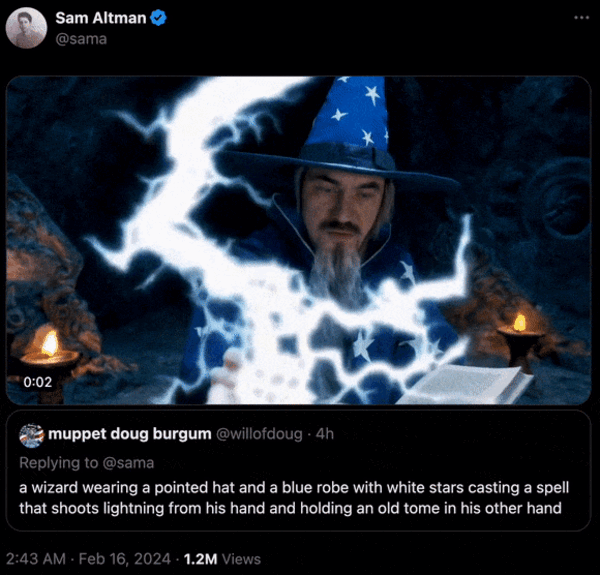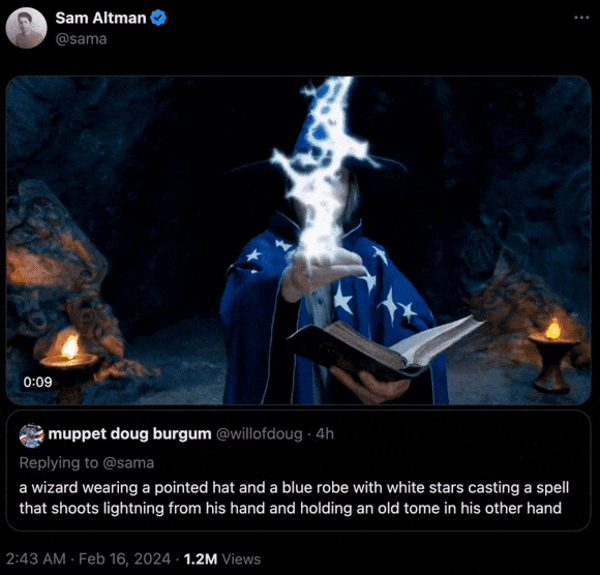
软件工程师,OpenAI Sora驾到,快来围观
概述 近期,OpenAI在其官方网站上公布了Sora文生视频模型的详细信息,展示了其令人印象深刻的能力,包括根据文本输入快速生成长达一分钟的高清视频。Sora的强大之处在于其能够根据文本描述,生成长达60秒的视频,其中包含&…...

MCP39F501电能计量芯片:高精度单相计量方案与工程实践详解
1. 项目概述:为什么我们需要一颗专用的电能计量芯片?在智能家居、工业物联网和新能源领域,精确测量交流电(AC)的用电参数——比如电压、电流、功率、电能——是底层最核心的需求之一。你可能觉得,用个高精度…...

如何高效使用Display Driver Uninstaller:显卡驱动清理终极指南
如何高效使用Display Driver Uninstaller:显卡驱动清理终极指南 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-uni…...

实战应用场景:Codex CLI在开发工作流中的最佳实践
实战应用场景:Codex CLI在开发工作流中的最佳实践 本文详细介绍了Codex CLI在现代化开发工作流中的四个关键应用场景:代码重构与组件现代化迁移、自动化测试生成与执行、安全漏洞扫描与代码审查、以及批量文件操作与Git集成。通过实际案例展示了如何利用…...
)
迷宫算法避坑指南:为什么你的‘流水算法’跑不出最短路径?(附Python调试技巧)
迷宫算法避坑指南:为什么你的‘流水算法’跑不出最短路径?(附Python调试技巧) 迷宫寻路算法一直是编程学习者和算法爱好者热衷探索的领域。其中,流水算法因其独特的物理模拟思路而备受关注。但在实际实现过程中&#x…...

Altium Designer 21 多通道设计保姆级教程:用Repeat语句快速搞定4路蜂鸣器模块
Altium Designer 21 多通道设计实战:4路蜂鸣器模块的高效实现 在复杂的电子系统设计中,我们常常会遇到需要重复使用相同功能模块的情况。传统的手动复制粘贴不仅效率低下,更会给后期维护带来巨大挑战。Altium Designer 21的多通道设计功能正…...

操作插件方法
事件触发时机事务状态适用场景beforeExecuteOperationTransaction操作校验通过后,开启事务之前事务未开启✅ 修改源单据关联的其他单据beginOperationTransaction开启事务后,提交数据库之前事务已开启修改当前操作的单据自身数据...

从零到一:ComfyUI IPAdapter 图像风格迁移终极指南
从零到一:ComfyUI IPAdapter 图像风格迁移终极指南 【免费下载链接】ComfyUI_IPAdapter_plus 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_IPAdapter_plus 你是否曾梦想过将自己拍摄的照片变成大师级的艺术作品?或者想把朋友的肖像变成…...

备战蓝桥杯国赛【Day 17】
📌 写在前面:今天的4道题全部来自蓝桥杯真题,,核心考点包括:贪心策略排序、自定义比较器、差分思想、前缀和贪心选择。这些题目看似简单,但暗藏陷阱,是检验"代码实现能力"和"思维…...

ESP32秒变双模调试器:一份代码实现有线DAP-LINK与无线WiFi调试自由切换
ESP32双模调试器实战:有线DAP-LINK与无线WiFi的智能切换方案 在嵌入式开发领域,调试工具的选择往往决定了开发效率的上限。传统调试方案通常需要在有线连接的高性能和无线调试的灵活性之间做出取舍,而ESP32芯片的出现为这个困境提供了全新的…...
)
别再让烙铁头‘烧死’了!手把手教你电烙铁日常保养与复活术(附温度设置建议)
电烙铁头养护全攻略:从氧化原理到实战修复技巧 1. 烙铁头氧化背后的科学原理 烙铁头氧化并非单纯由高温引起,而是高温与氧气共同作用的结果。当烙铁头暴露在空气中时,高温会加速金属表面与氧气的化学反应,形成一层致密的氧化层。这…...