【数据结构】图

文章目录
- 图
- 1.图的两种存储结构
- 2.图的两种遍历方式
- 3.最小生成树的两种算法(无向连通图一定有最小生成树)
- 4.单源最短路径的两种算法
- 5.多源最短路径
图
1.图的两种存储结构
1.
图这种数据结构相信大家都不陌生,实际上图就是另一种多叉树,每一个结点都可以向外延伸许多个分支去连接其他的多个结点,而在计算机中表示图其实很简单,只需要存储图的各个结点和结点之间的联系即可表示一个图,顶点可以采取数组vector存储,那顶点和顶点之间的关系该如何存储呢?其实有两种方式可以存储顶点与顶点之间的关系,一种就是利用二维矩阵(二维数组),某一个点和其他另外所有点的连接关系和权值都可以通过二维矩阵来存储,另一种就是邻接表,类似于哈希表的存储方式,数组中存储每一个顶点,每个顶点下面挂着一个个的结点,也就是一个链表,链表中存储着与该结点直接相连的所有其他顶点,这样的方式也可以存储结点间的关系。
2.
图还可以细分为无向图和有向图,其实很好区分,如果AB两个点之间的连线是无向的,那就默认代表A可以到达B,B也可以到达A,那这样的图就是无向图,如果AB两个点之间的连线是有向的,比如A指向B,那就代表只能A到达B,不能B到达A。每两个点之间的连线还可以加权,你可以将他理解为是通过该线到达对方所需要花费的驾驶成本。
(其实图还有很多其他的概念,例如子图,连通图,强连通图,最小生成树,有向完全图,无向完全图等等,但这些概念网上一搜你就知道是什么,所以这里不会再继续聊这些无聊的概念了,直接上图这种数据结构的相关代码)
3.
下面代码是用邻接表来实现的图,主要成员变量就是一个vector来存储所有的顶点,另一个类似于哈希表的邻接表来存储某一个顶点与其他所有顶点之间的关系,还需要一个哈希表的原因是因为我们需要拿到结点对应的下标,在图当中,结点的类型是不确定的,可能是string,double,float,还有可能是自定义类型,所以我们需要vector来存储这些不确定类型的结点,而在vector里每个结点就会和数组的下标索引关联上了,存储结点之间的关系时,我们都是通过操作结点对应的下标来对图进行关系的增查改的,所以为了提高找到结点对应的下标索引,我们额外用一个哈希表来存储结点和索引的键值对关系。
构造函数需要外部传入一个顶点数组的指针,以及顶点的个数,通过这两个参数,我们就可以确定好_vertexes和_index存储的内容了。
添加边关系的接口也会提供给外部,如果图是无向图,则可以外部指定边的默认权值为-1或者是0等等,由使用者来定义。
邻接表的每个顶点由后继指针,顶点下标,权值三部分组成。

4.
邻接矩阵来实现图其实要方便许多,添加顶点之间的关系时,只需要更改矩阵中对应位置存储的值即可,而无需向邻接表似的还需要额外添加顶点,不过邻接矩阵和邻接表相比各有优劣,对于稠密图,也就是图中边的数量很多,这种图就适合用邻接矩阵来存储,因为不管图是稠密还是稀疏,邻接矩阵空间大小都不变,那存储稠密图相对稀疏图空间利用率就会高很多,对于稀疏图就适合用邻接表来存储,因为边的数量较少,用占有空间率较大的邻接矩阵来存储就不太划算,而邻接表可能只需要添加那么几个顶点就可以完成图的构建,这样就会划算很多。但邻接矩阵的好处就是可以快速判断两个点是否相连,而邻接表如果想要判断,就需要遍历一串链表,但当判断某一个点向外连接了哪些顶点时,邻接矩阵的效率就相对低了,因为他要遍历二维矩阵的一整行来判断,时间复杂度就是O(N),而对于邻接表只需要遍历常数次的链表结点即可,效率相对要高一些,但如果要实现后面的算法,比如图的bfs和dfs遍历,kruskal,prim,dijkstral,bellman-ford,floyd-warshall,经常需要拿到两个点相连边的权值,如果是邻接表的话,就需要对结点指针解引用拿到权值,我感觉是比较麻烦的,同时遍历某一个顶点向外与哪些顶点相连时,邻接表需要遍历链表,那就需要while循环来遍历,用邻接表也不是不行,但是邻接矩阵用起来比较符合大部分人的图使用习惯,所以后面实现的算法都是用邻接矩阵来实现的。
下面邻接矩阵的代码中的接口和临界表的实现大差不差,邻接矩阵中存储值我们可以将其初始化为INT_MAX,添加顶点之间的关系时,其实就是对邻接矩阵中存储的值做改动而已。
所以实现图这种数据结构并不困难,难的是实现图相关的算法。

2.图的两种遍历方式
1.
关于dfs和bfs这两种遍历方式相信大家是不陌生的,深度优先遍历需要借助函数栈帧,也就是函数的递归调用来实现,不断的向深处递归,满足某一条件时递归结束,开始回溯往回走,广度优先遍历需要借助队列,因为每遍历某层的某个数据元素,为了让他所连接的下一层在下次也能够遍历到,那就需要按照FIFO的方式将他下一层相连的元素push到data structure中,这种访问方式刚好就是队列这种数据结构的特性。
2.
对于下面图的bfs来说,当我们访问完A之后,我们想按照顺序访问BCD,因为与A直接相连的只有BCD,假设我们访问完BCD,那么按照顺序来说,下一次就应该访问与B直接相连的E,但此时就有细节需要注意了,因为与B直接相连的不仅仅只有E,还有访问过的A和C,所以在push与当前结点直接相连的下一层的元素时,需要保证已经访问过的结点不要再次push到队列里面。可以通过一个visited[bool]数组来完成这个细节的处理,对于已经访问过的结点,数组里面对应位置存储的值就是true,没有访问过的结点就是false。
代码实现的方式较为简单,每次在pop队头同时访问完毕元素之后,都会把与元素直接相连的其他未访问过的结点尾插到队列里面,我们只需要不断while循环的访问队列中的元素直到队列为空,就可以实现图的bfs方式的访问,这里面有一点实现上的细节就是关于visited数组的modify,下面实现的代码是将当前元素相连的下一层所有元素尾插的同时标记visited数组为true,这样其实是没问题的,想法就是只要在队列里面待着的元素那迟早是要被访问的,所以只要元素一入队列那就直接将该元素在visited中的位置写为true即可。另一种想法就是我不着急一下子就把下一层的元素全写为true,而是每次刚拿出队头的元素时,我再单独将这个元素写为true,那在push下一层结点时,依旧不会影响当前这一层元素误被再一次push到队列中,两种更改visited数组的想法均可以,看个人习惯实现即可。
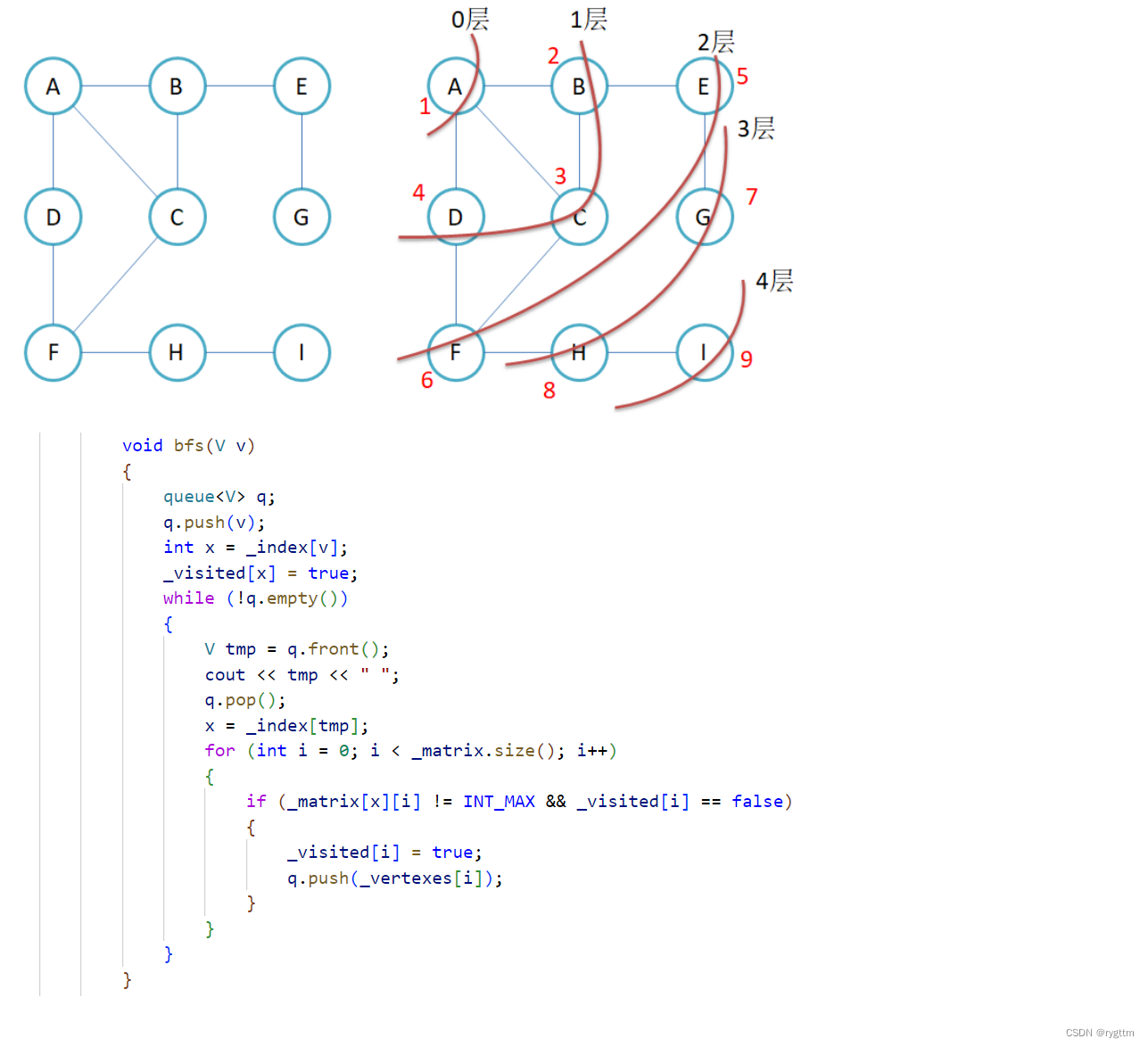
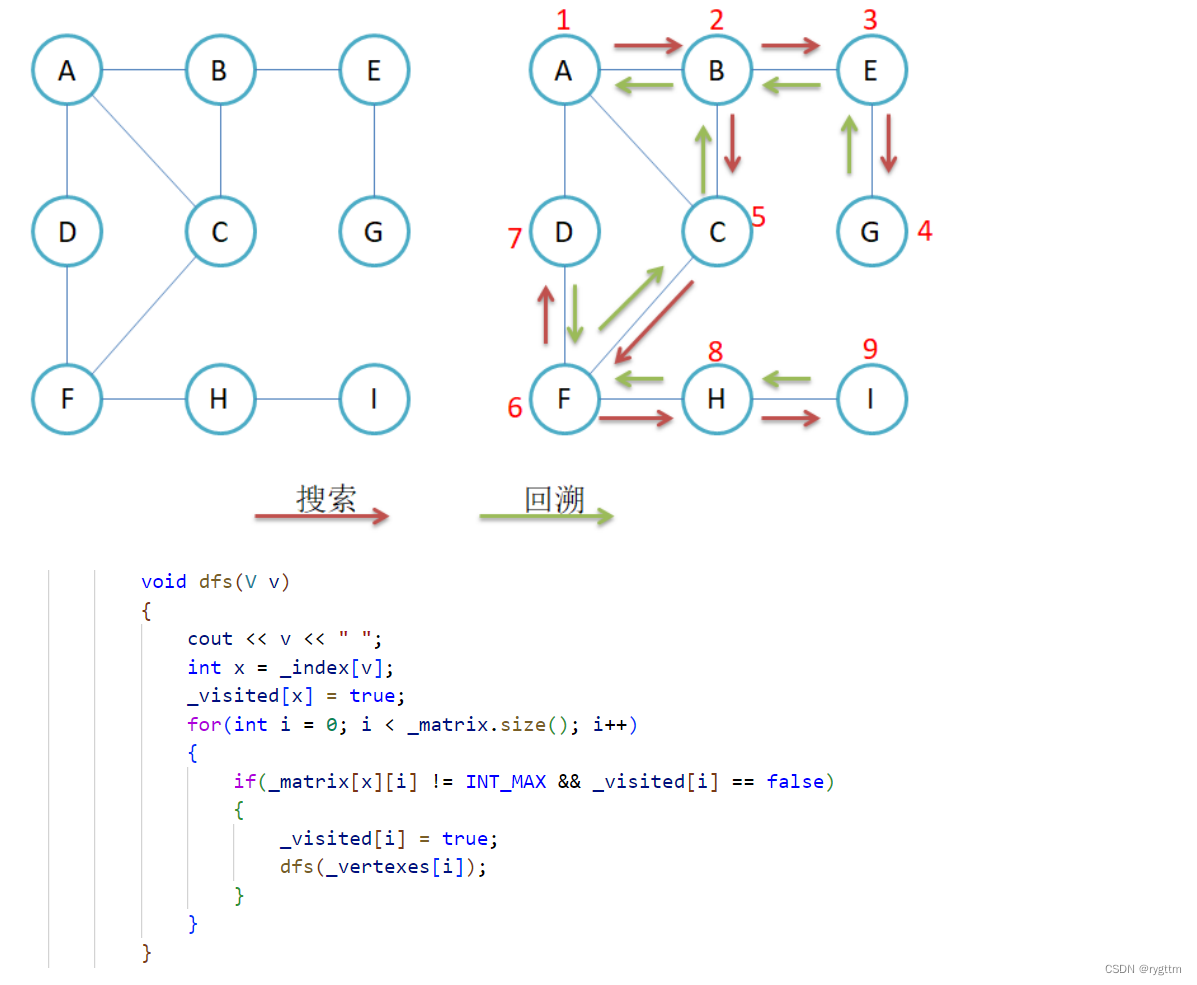
3.
dfs算是一个算法入门程序员的基本功了,回溯算法其实就是在递归的基础上延申出来的,所以学好递归对于学习算法其实是很重要的。实现dfs与bfs同样都有一个点需要注意,在bfs那里,尾插下一层结点时,需要防止当前层的结点重复尾插到队列中,因为我们不希望已经被访问过的结点再次被访。而在dfs这里,当我们递归到最深时,也就是当前结点不再和其他任何结点相连时,代表这一趟的搜索其实已经完成了,那么此时递归就要结束了,因为递归条件已经不满足了,有人可能会问递归条件是什么呢?递归条件其实就是只要当前结点直接相连的结点个数不为0,那就继续向深处进行遍历,当结点个数为0时,那自然递归就结束了。而此时回溯的时候就出现问题了,上一层已经访问过的结点我们还要再访问吗?当然不要!所以在dfs这里依旧需要一个visited数组来标记已经访问过的结点,防止递归在回溯时重复访问已经访问过的结点。
(注意我实现的其实是Graph类的成员函数,如果是在OJ题里面的话,visited数组肯定是要设置成全局的)
3.最小生成树的两种算法(无向连通图一定有最小生成树)
1.
最小生成树通常针对的其实是无向连通图,而求解最小生成树已知的两种算法是kruskal和prim算法,理解完两种算法的思想和实现方式之后,再来讨论为什么最小生成树通常针对于无向连通图,如果应用到有向连通图上呢?得到的还是最小生成树吗?
最小生成树其实就是将图中的所有顶点通过边连通起来,我们当然可以选择任意条不超过图中边总数的边来将各个顶点连接起来,但最小生成树指的是在无向连通图中选择顶点个数-1条边将所有顶点连接起来,同时这些边的权值之和是连通所有顶点需要边的权值之和中最小的,而连接起来的顶点,你将其从图中抽离出来,画到另外一张纸上,经过形状的调整,他其实就是一棵树,这棵树就叫做最小生成树。有人可能会有疑问,为什么边的数量是n-1条呢,因为连接n个顶点,需要的最少的边就是n-1条,如果边的数量超过了n-1条,那么挑选的边就必然会形成环,超出n-1条的边一定是多余的,这样权值之和一定是小于n-1条边的,所以这样肯定不是最小生成树。
(为什么在最小生成树这里不断的强调是连通图呢?(先不谈是有向还是无向),因为如果不是连通图,顶点是一定没有办法通过边来连通起来的,一定会有顶点是孤立的岛,所以最小生成树算法的使用前提是连通图必须是连通图,通常是用于无向的连通图,有向连通图也可以使用,但这里先不谈,了解完prim和kruskal之后再继续谈。)
2.
我大概在2023年的10月份,系统学过一个月左右的各个算法,有难有简单,其中比较特殊的算法就是贪心算法,能想出来这种算法的人基本已经青史留名了,而作为后代的我们其实只要做到脑中理解这种算法,或者是能感受到这种算法的确是正确的就可以了,反正我自己是这么觉得的,而证明贪心算法的正确性是真的要有不错的数学基础,但按照本人的这个算法和数学功底来看,我是没能力证明算法的正确性的,同时在学图这块的算法时,有一说一,我想让我的大脑尽量理解这种算法是正确的,让我的大脑相信这种贪心算法一定是能够考虑到各种特殊情况,最终得到正确答案的这一事实,都是比较困难的,当时让大脑相信这种正确性其实是花费了不少时间的,也有可能是我这个脑子比较笨,不去做证明,仅仅让大脑尽量去理解这种贪心算法的正确性都很吃力,所以下面涉及到所有的贪心算法,只会讲本人对其正确性的理解,而不会谈论证明他的正确性,因为你让我讲我也讲不了,本人太菜了啊。
kruskal算法的本质是贪心算法,在上面了解最小生成树的概念之后,你其实会发现求解最小生成树过程的核心工作其实就是挑选边,在一个无向连通图中所有的边中挑选出来n-1条权值之和最小的边,而kruskal和prim算法的不同,其实就是选边策略的不同,但他们最后都能求出来最小生成树。选边的策略其实就是kruskal和prim作为贪心算法的实际贪心策略,通过合理的贪心策略最终解决问题。
kruskal的贪心策略其实是比较好理解的,他是一种全局站在上帝视角的贪心,对于图中所有的边,我们从小到大进行挑选,每次挑选边都必须保证不能形成环,因为我们知道只要形成环,那其实就代表挑选出来的这条边是多余的边,因为即使没有这条边,也不会影响已经连接在一起的结点的连通性,所以在挑选边的过程中不可以形成环,同时必须从小到大的一直挑选边,直到挑选出n-1条边,当然如果图不是连通图,那我们怎么也无法挑选出能够组成最小生成树的边出来,对于这种特殊情况需要在写代码时特殊注意一下。
总结一下,kruskal从上帝视角来看,每次挑选的边都是最优的,同时防止形成环(防止不必要的边的选入),那么最后挑选出来的边的总和一定也是最小的,这样就可以求出最小生成树。
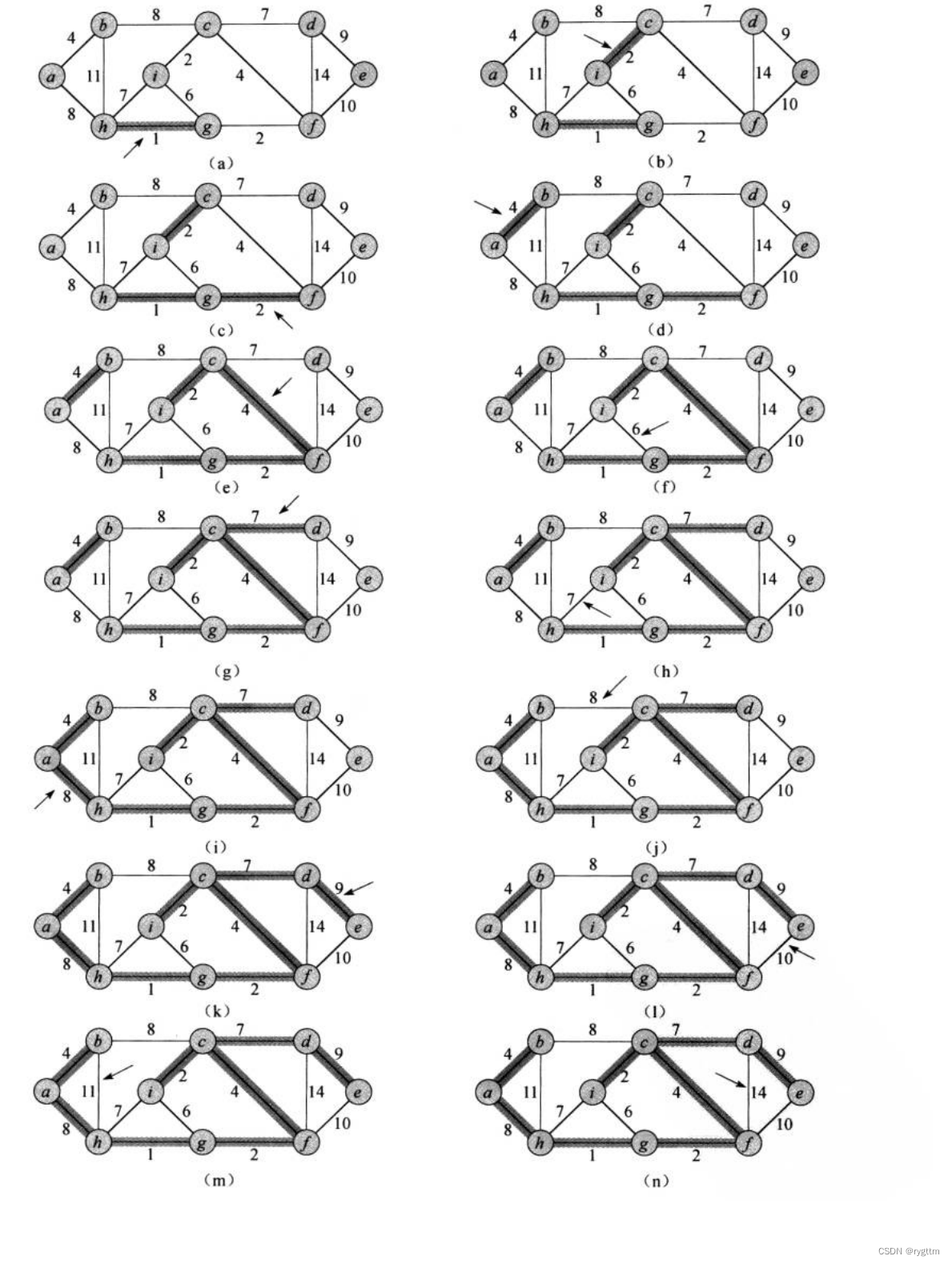
3.
在kruskal挑选边中,我们需要从小到大的挑选边,可以通过数组排序的方式来从小到大依次拿取边,也可以通过优先级队列,也就是堆的方式来实现,建立一个小堆,将图中所有的边push到小堆里面,依次拿出堆顶的元素,就是从小到大拿取边,还有一个需要解决的问题就是如何判环,其实这个步骤需要通过并查集来解决,并查集刚好可以用来判断两个结点是否在同一集合当中,对于挑选出来的边,我们可以判断挑选边所连接的两个顶点是否在同一集合当中,如果在,那就说明挑选出来的边会形成环,如果不在,那就说明挑选出来的边是有效的,是可以连通这两个顶点的。

4.
prim是局部的贪心来挑选边,并不像kruskal一样站在全局上帝的视角来挑选边,他的策略是从已经选择的点向外连接的所有边中,挑选一个最短的边。例如图a,假设从a顶点开始向外挑选,只有4和8两条边,则优先选择4这条边,因为这一步一定是最优的,对于想要从a向外连接其他顶点来说,下一步对于ab两个顶点向外连接的所有边中,再次选择最小的边,不断向外选择,直到连接完毕所有的顶点。需要说明的是prim的思想其实是把图中的顶点分为两类,一类是已经选择好的,另一类是未选择的,每次挑选边都是从已选择的顶点出发到未选择的顶点,看哪条边最小,就选择那条边,虽然思想是这样的,但如果按照这个思想实现代码的话,其实选边的过程是非常头疼的,因为每次选边都需要依次遍历已选择的顶点集合中所有的点,将每个点作为起点连接到未选择的顶点集合中的所有点,相当于要遍历m×n次,m和n分别代表两个集合的顶点个数,等到选择一半的时候,m和n就会相等变为顶点集合总数的一半,那相乘之后的选边时间复杂度就会达到O(N²),无疑这样的选边效率太低,所以我们不用来回遍历的这种方式选边,而是依旧使用优先级队列来选边。
但在prim这里用优先级队列有可能产生环,因为在局部不断选边的过程中,有些无效边会滞留到小堆里面,我们无法做到将具体的某个无效边从小堆里面删除,所以为了解决环的问题,实现prim时依旧需要使用并查集来判环。(下面算法导论给出的例子中,如果使用优先级队列选择当前顶点向外连接的所有边中的最小边,不断不断选的过程中会在c i g f这里形成环)


5.
当prim和kruskal用于有向连通图时,求出来的就不是最小生成树了,而是最小生成森林,kruskal在选边时,由于全局选边的特性,实际上是无视边的方向的,所以最终选出来的可能是拥有多个根节点的最小生成森林,而prim在局部选边时,就比较麻烦了,因为随机的某个出发点可能没有出度,只有入度,那么出发点就无法到达其他顶点,这样出发点就单独是一棵树,接下来如果要继续选边,那就需要看代码的具体实现了,每个人都可以实现的不同,例如接下来随机或者轮询的选择某一个未确定的顶点作为新的出发点,然后继续向后选边,实现起来可能稍微要比无向连通图麻烦一些。
(我们这里也是思维跳跃的想了想有向连通图下prim和kruskal的实现,但大部分情况下你从网上搜,没人会实现有向连通图下的这两种算法,95%的情况都是针对于无向连通图来求最小生成树进行使用。)
4.单源最短路径的两种算法
1.
单源最短路径指的是选择一个出发点,从这个出发点到其他所有顶点的最短路径是什么,dijkstra和bellman-ford可以求出单源最短路径,但dijkstra只适用于权值为正的图,不能适用于携带负权值的图,bellman-ford可以适用于携带负权值的图,但对于携带负权环的图bellman-ford也无法解决最短路径问题了,只能判断出该图存在负权环。dijkstra的算法时间复杂度最坏情况就是O(N²),bellman-ford算法的时间复杂度最坏情况是O(N三次方),实际上dijkstra是贪心算法,而bellman-ford算法是暴力循环遍历,这也是为什么dijkstra算法效率高的原因。
在谈论两种算法之前还需要补充一个前置知识松弛更新,松弛操作其实很好理解,拿下面的图举例子,在逻辑上每个结点中存储一个权值,该权值其实就是从出发点到该点的最短路径上路径的权值之和,但刚开始时,所有结点中存储的值应该都是+∞,而所谓的松弛操作就是指,从当前结点出发到直接相连的下一个结点,如果当前结点上的权值加上路径的权值小于下一个节点存储的权值,那么此时我们进行下一个结点存储值的松弛更新操作,将其权值之和更新为更小的值。
所以总结一下,所谓的松弛操作就是指从某一结点出发到下一个结点,如果路径权值+当前结点权值之和更小,那就将这个更小的值更新为下一个节点存储的值,这就代表,从出发点到这个新顶点有了一条更短路径。(如果这里看懂有点迷糊也正常,说的都是我自己的理解,可以直接去看下面的dijkstra的例子,这样你就很好理解松弛操作了,他其实就是一个更新权值的操作而已)
2.
刚开始除了s自己是0之外,其他结点都是无穷大,因为s到s自己的路径权值不需要更新,默认为0即可,然后松弛更新与s直接相连的t和y结点,因为10和5均各自小于无穷大,所以可以更新权值,下一步就是挑选下一个出发点作为新的起始点,挑选下一个顶点的策略,其实就是dijkstra的贪心策略了,由于5比10小,所以y存储的值就是从出发点s到y的最短路径,没有其他路径能够比当前这个路径更优了,所以y是第一个已经确定最短路径的顶点,有人会有疑问,凭什么y就已经确定了最短路径呢?
dijkstra适用的图都是权值均为正数的图,那可以想一下,s到y只有两种情况,一种是直接到达y,另一种是通过其他路径,本图中是通过t绕一圈可能到达y,这两种到y的方式一定是前者更优,因为在s第一次松弛更新时,t和y存储的值相比,y就是最小的值了,如果按照后者的方式,s第一步到t,此时的权值就已经大于y了,何况你还要从t作为出发点再继续绕一圈到y,那最后累积的权值一定是要比s直接到y要小的,因为只要你从t向外绕,路上途径的任何一条边的权值都是正数,那权值就一定会累加,所以以s作为起点松弛更新之后,我们就可以拿到一个新的已经确定好最短路径的新的起点了,那就是y。
接下来道理相同,以y作为新起点继续向外松弛更新,那txz三个顶点存储的值都会被更新,此时选择下一个新的起点该如何选择呢?其实还是一样的,我们依旧选择txz三个顶点中存储值最小的点z作为新起点,有人感受这个地方可能觉得还是别扭的不行,别扭还是没抓住关键,关键就是,我们每次选择下一个顶点时,选择的都是权值最小的顶点,这样有什么好处呢?如果我们选择t或x作为新顶点,能不能到达z呢?肯定是可以的,但有意义吗?当然是没有意义的!因为t和x本身的权值都已经大于z的权值了,那从t和x出发,能找到到达z的最短路径吗?一定是找不到的,只有选择当前已经更新的结点中存储权值最小的顶点作为新起点才是最优的选择,因为他存储的值其实就已经确定好了最短路径了。
(我说了这么多不知道你理解没有,核心就是每次选择下一个权值最小的顶点作为新起点,这样一定是最优的,你想嘛,你选的都是最小权值的了,其他顶点都比你大,那他们绕一圈肯定还是比你大,那你当前的存储权值所对应的路径其实就已经是最短路径了,因为没有比你更优的选择了,这样贪心的策略就是dijkstra算法)
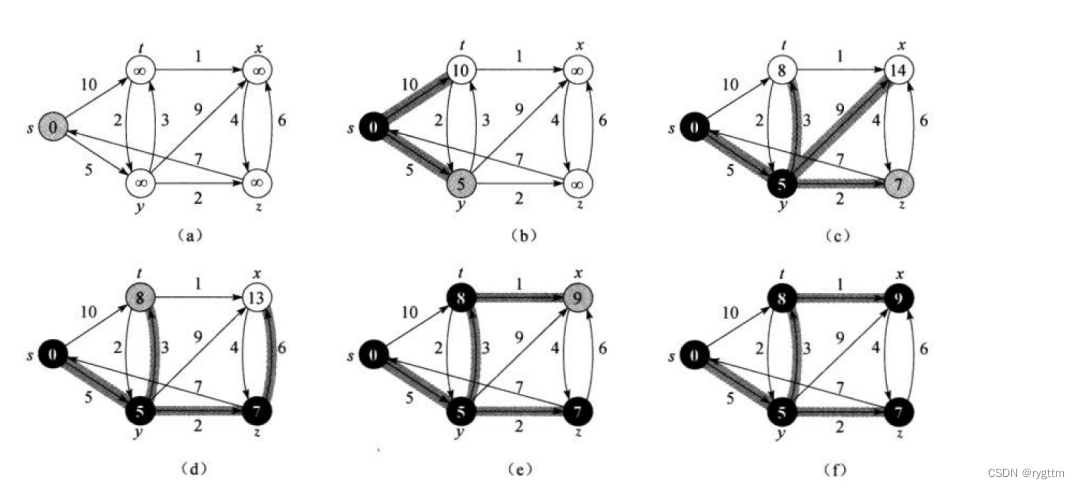
3.
在代码实现上要考虑的细节是比较多的,我们肯定不可能向图中的逻辑表示一样,给每个结点做一层封装,让结点中存储一个权值之和,这样无疑是比较繁琐的,其实完全可以用一个int数组shortPath来解决,数组的下标对应着每个结点,下标中存储的值就是从出发点到该点的最短路径上的权值之和,解决完最短路径的权值之和后,还有一个问题要解决,我们需要能够表示出来这条最短路径,知道路径上都通过了哪些结点,这个问题该如何解决呢?需要用到一个prev数组,prev数组的下标依旧对应每个顶点,存储的值表示前一个结点的下标,如果想要拿到完整的最短路径,则可以不断根据索引访问prev数组,依次拿到前一个结点的下标,直到回溯到最开始的出发点为止。
在松弛更新时,已经确定最短路径的结点实际上是不需要在更新了,所以我们可以再额外搞一个confirm标记数组来标记已经被确定好最短路径的结点,在向外松弛更新时不处理这些结点。
(在理解dijkstra的贪心策略以及实现时上面的需要注意的点,实现代码并不困难,具体可看代码截图)


4.
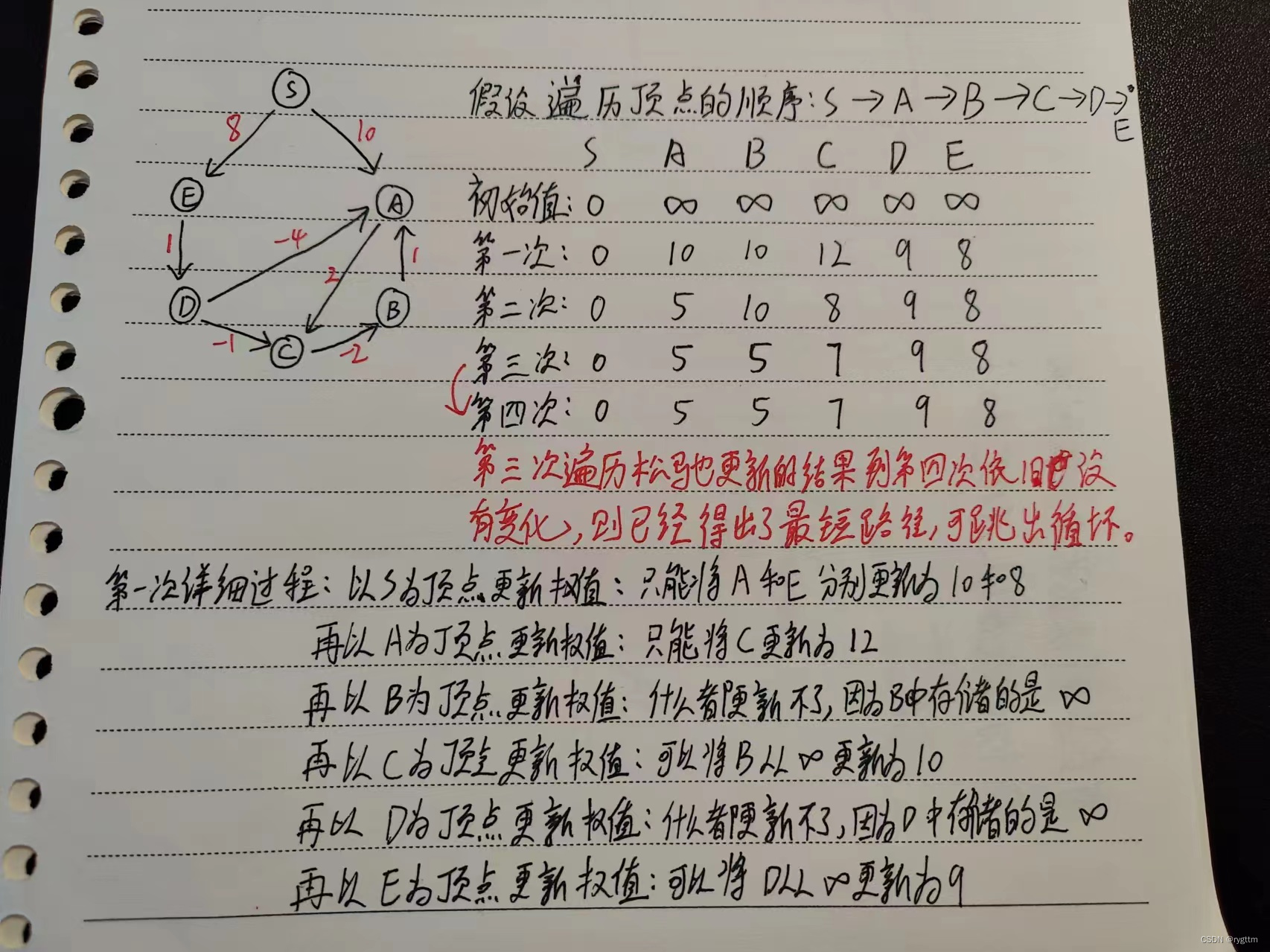
当图中存在了负权边时,dijkstra的贪心策略就无法使用了,道理很简单,如果我们还按照原来的策略进行选边的话,第一步就会出问题,拿下图这个bellman-ford算法执行过程举例的话,第一步s先将t和y分别更新为6和7,此时能因为t的权值6小于y的权值7,就说t已经确定了最短路径吗?这里的第一步贪心就会出错,因为虽然y现在的权值大于t,但由于图中存在负权边,那就可能存在一种情况,也就是从y绕出去,最后绕到t,绕一圈之后的权值之和是可能小于6的,所以6并不一定是最短路径,也就是说我们的贪心策略失效了,不能用这种取巧的方法来求解单源最短路径了,那该怎么办呢?
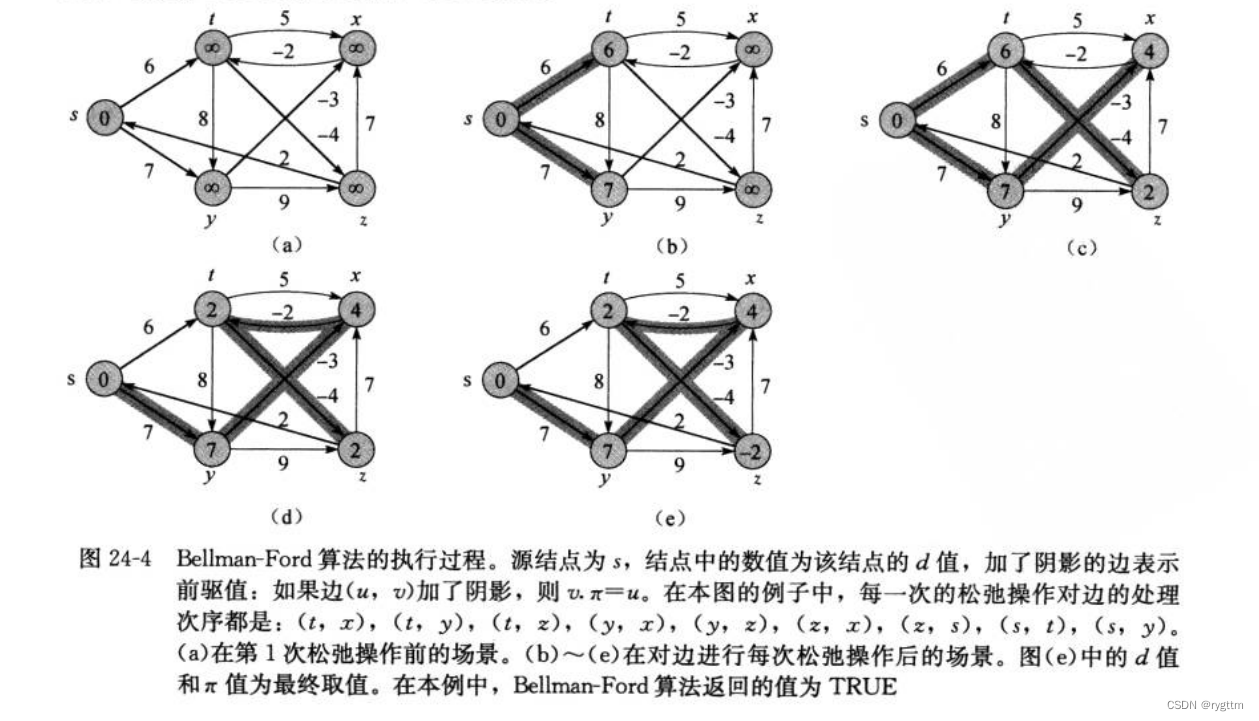
解决的思想很简单,就是直接暴力遍历,以所有的顶点为起点去向外松弛更新,遍历一圈顶点,每个顶点都松弛更新一遍,这样算是完成一次循环,最多需要完成n(顶点个数) - 1次循环即可得出所有顶点的最短路径,我上面简单叙述的过程就是bellman-ford的算法思想,思想说起来可能很简单,但确实不太好理解,所以下面为大家准备了两张示例图,一张是我自己画的图,一张是算法导论上面的,推荐先看我画的图,然后再看算法导论上面的图,因为算法导论总结的比较精炼和抽象,没那么容易读懂。
在bellman-ford这里,经典的一个疑问就是为什么最多要遍历n-1次循环?因为求解一条最短路径,这条最短路径最长也就是n-1条边组成的,bellman-ford每次循环,最少最少都能够确定出这条最短路径的一条边出来,所以最坏的情况下,假设每次bellman-ford只能确定出某个顶点的最短路径上的一条边,那么经过n-1次循环后,也就能够求出最短路径的权值之和了。
如果情况比较好的话,向下图所示,只需要经历4次循环,我们发现第三次和第四次结果没有发生变化,那就不需要继续经历循环,因为最短路径已经求解出来了,那就可以提前跳出循环。
总结bellman-ford的算法思想就是,以所有的顶点为起点向外松弛更新,至多循环n-1次即可求出所有顶点的单源最短路径
(遍历顶点的顺序可以变,但不管怎么变,bellman-ford都是可以求出来最短路径的)
5.
在实现代码时,需要额外判断的就是负权环,因为当图中存在负权环时,无论你继续暴力循环遍历多少次,遍历无数次都一样,每一次仍然能够进行松弛更新操作,因为只要有负权环,以某一个负权边连接的两个顶点的任意一个顶点为起点向外松弛更新,每次权值之和都会减小。
所以bellman-ford会返回一个bool值,用来表明图中是否存在负权环。

6.
额外补充一点的是bellman-ford还有一个优化叫做SPFA,用一个普通队列来统计每次松弛更新操作后存储权值改变了的结点,如果这个结点改变了,那就入队列,下次循环时,只需要对队列中存储的结点向外进行松弛更新操作即可,那些没有被更改存储权值的结点就不需要入队列了,因为这些顶点现存的值其实就已经是最短路径的权值了,这样在每次循环时,就不需要无脑遍历所有顶点作为起始点进行松弛更新了,这样也可以进行优化。
但对于某些刁钻图的情况,我从知乎上看到SPFA可能不会产生任何优化,对于这些特殊情况这里也就不再讨论了,因为本人的水平也就这么多了,讨论不下去了。

5.多源最短路径
1.
floyd-warshall算法是解决任意两点间的最短路径的算法,也就是允许多个顶点作为源出发点,故而称为多源最短路径。这个算法我觉得是图算法里面最不好理解的了,因为他本质用的是动态规划,而且还是二维的dp问题,所以理解起来确实有点难搞。
我们需要求出从i到j的最短路径,i和j代表任意的两个顶点的下标,i到j的最短路径,无非两种情况,一种是i直接到j,另一种是i先到其他顶点,然后再到j,中间可能经历过很多其他的结点,所以针对这两种情况我们就可以列出dp的状态转移方程,即当i到k加上k到j的权值小于i直接到j,那么就更新shortPath这个二维dp数组存储的值,k代表任意个中间结点的个数。
如果你看一下算法导论中关于动态规划的介绍,其实就会发现,动态规划和递归相比刚好是反过来的过程,递归站在一个大问题的角度,通过不断向深层次调用栈的过程,将问题化解为最小的问题,当最小的问题解决之后,就开始回溯,而动态规划是站在小问题的角度,从下向上来解决问题,一步一步解决小问题,问题的规模逐渐变大,最后将大问题解决,floyd-warshall正是如此,从下向上来解决问题,所有的动态规划都是从下向上解决,在向上解决的过程中,如果要用到下面刚开始解决完毕的一些值时,直接从dp数组里面去拿值即可,光这么说确实很抽象,但是想要理解floyd-warshall确实得需要你有一点dp的基础,因为所有的dp问题都是先初始化dp数组,然后逐步扩大问题的规模,每次求解都会向前去找dp数组刚开始存储的值。
(下面的代码也是这样的,先将图中的边全部初始化到dp数组里面,接下来就是列状态转移方程,只要i到k+k到j的权值和小于i到j,那就更新dp数组存储的值,同时我们要维护的二维prev数组也是如此)

相关文章:
【数据结构】图
文章目录 图1.图的两种存储结构2.图的两种遍历方式3.最小生成树的两种算法(无向连通图一定有最小生成树)4.单源最短路径的两种算法5.多源最短路径 图 1.图的两种存储结构 1. 图这种数据结构相信大家都不陌生,实际上图就是另一种多叉树&…...
32.3K Star,再见 Postman,这款开源 API 客户端更香
Hi,骚年,我是大 G,公众号「GitHub指北」会推荐 GitHub 上有趣有用的项目,一分钟 get 一个优秀的开源项目,挖掘开源的价值,欢迎关注。 使用 API 工具来调试接口是后端开发经常会使用的,之前一直…...

Python循环语句——continue和break
一、引言 在Python编程中,循环是常见的控制流语句,它允许我们重复执行一段代码,直到满足某个条件为止。而在循环中,continue和break是两个非常重要的控制语句,它们可以帮助我们更加灵活地控制循环的行为。 二、contin…...

C++面向对象程序设计-北京大学-郭炜【课程笔记(三)】
C面向对象程序设计-北京大学-郭炜【课程笔记(三)】 1、构造函数(constructor)1.1、基本概念 2、赋值构造函数2.1、基本概念2.1、复制构造函数起作用的三种情况2.2、常引用参数的使用 3、类型转换构造函数3.1、什么事类型转换构造函…...
Linux:搭建docker私有仓库(registry)
当我们内部需要存储镜像时候,官方提供了registry搭建好直接用,废话少说直接操作 1.下载安装docker 在 Linux 上安装 Docker Desktop |Docker 文档https://docs.docker.com/desktop/install/linux-install/安装 Docker 引擎 |Docker 文档https://docs.do…...

用HTML、CSS和JS打造绚丽的雪花飘落效果
目录 一、程序代码 二、代码原理 三、运行效果 一、程序代码 <!DOCTYPE html> <html><head><meta http-equiv"Content-Type" content"text/html; charsetGBK"><style>* {margin: 0;padding: 0;}#box {width: 100vw;heig…...

订餐|网上订餐系统|基于springboot的网上订餐系统设计与实现(源码+数据库+文档)
网上订餐系统目录 目录 基于springboot的网上订餐系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、用户功能模块的实现 (1)用户注册界面 (2)用户登录界面 (3)菜品详情界面 (…...

从零开始学howtoheap:解题西湖论剑Storm_note
how2heap是由shellphish团队制作的堆利用教程,介绍了多种堆利用技术,后续系列实验我们就通过这个教程来学习。环境可参见从零开始配置pwn环境:从零开始配置pwn环境:从零开始配置pwn环境:优化pwn虚拟机配置支持libc等指…...

Rust 基本环境安装
rust 基本介绍请看上一篇文章:rust 介绍 rustup 介绍 rustup 是 Rust 语言的安装器和版本管理工具。通过 rustup,可以轻松地安装 Rust 编译器(rustc)、标准库和文档。它也允许你切换不同的 Rust 版本或目标平台,以及…...
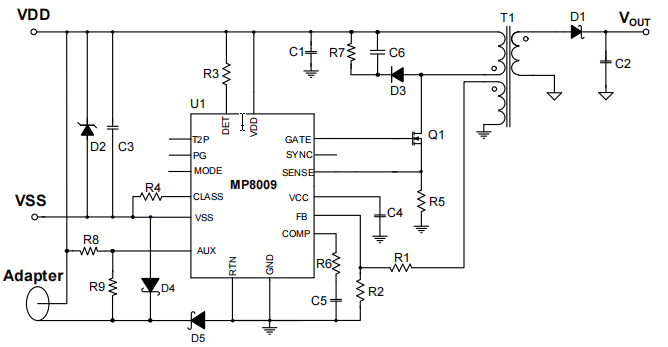
【电源】POE系统供电原理(二)
转载本博客文章,请注明出处 上一篇文章中,有提到POE系统工作原理及动态检测机制,下面我们继续介绍受电端PD技术及原理。POE供电系统包含PSE、PD及互联接口部分组成,如下图所示。 图1 POE供电系统 PSE控制器的主要作用ÿ…...
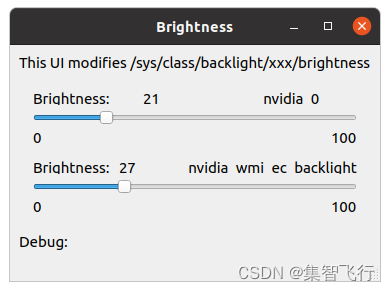
GPU独显下ubuntu屏幕亮度不能调节解决方法
GPU独显下屏幕亮度不能调节(假设你已经安装了合适的nvidia显卡驱动),我试过修改 /etc/default/grub 的 GRUB_CMDLINE_LINUX_DEFAULT"quiet splash acpi_backlightvendor" ,没用。修改和xorg.conf相关的文件,…...

Linux篇:网络基础1
一、网络基础:网络本质就是在获取和传输数据,而系统的本质是在加工和处理数据。 1、应用问题: ①如何处理发来的数据?—https/http/ftp/smtp ②长距离传输的数据丢失的问题?——TCP协议 ③如何定位的主机的问题&#…...
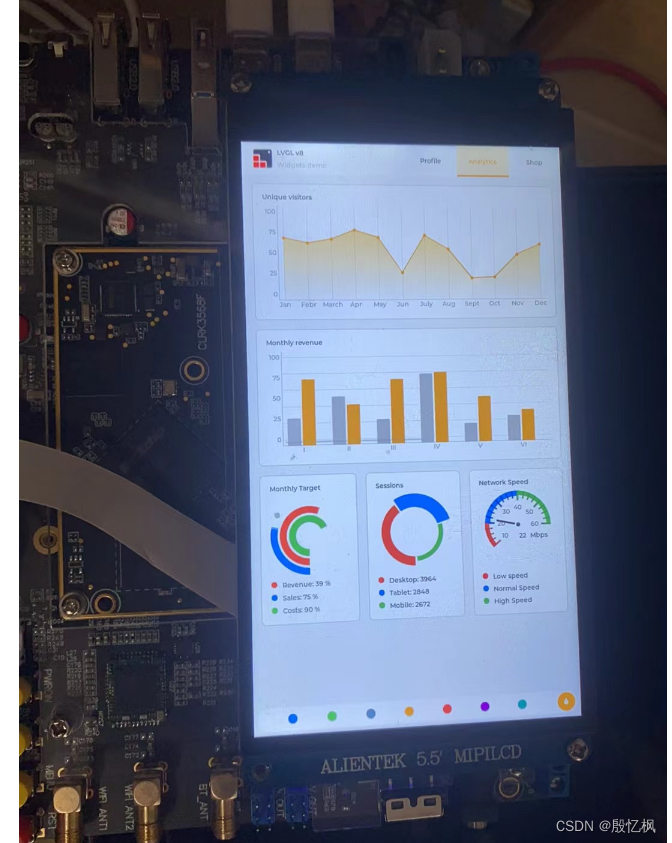
RK3568笔记十七:LVGL v8.2移植
若该文为原创文章,转载请注明原文出处。 本文介绍嵌入式轻量化图形库LVGL 8.2移植到Linux开发板ATK-RK3568上的步骤。 主要是参考大佬博客: LVGL v8.2移植到IMX6ULL开发板_lvgl移植到linux-CSDN博客 一、环境 1、平台:rk3568 2、开发板:…...
)
C#系列-C#访问MongoDB+redis+kafka(7)
目录 一、 C#中访问MongoDB. 二、 C#访问redis. 三、 C#访问kafka. C#中访问MongoDB 在C#中访问MongoDB,你通常会使用MongoDB官方提供的MongoDB C#/.NET Driver。这个驱动提供了丰富的API来执行CRUD(创建、读取、更新、删除&#x…...
Hive调优——count distinct去重优化)
(12)Hive调优——count distinct去重优化
离线数仓开发过程中经常会对数据去重后聚合统计,count distinct使得map端无法预聚合,容易引发reduce端长尾,以下是count distinct去重调优的几种方式。 解决方案一:group by 替代 原sql 如下: #7日、14日的app点击的…...
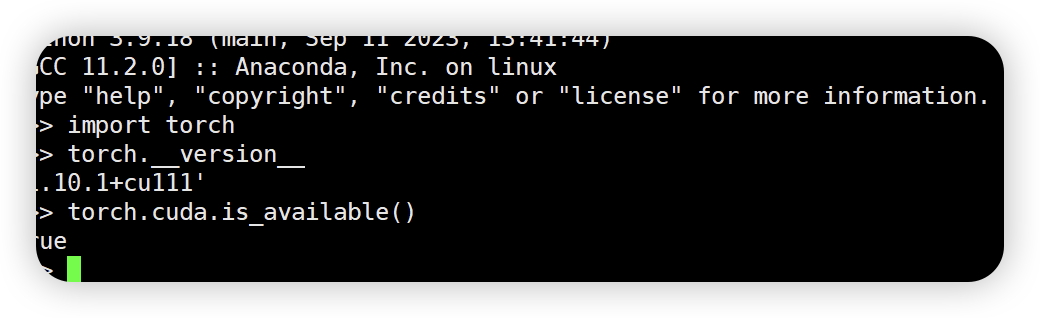
记录 | 验证pytorch-cuda是否安装成功
检测程序如下: import torchprint(torch.__version__) print(torch.cuda.is_available()) 或者用终端 Shell,运行情况如下...

LeetCode 239.滑动窗口的最大值 Hot100 单调栈
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动窗口中的最大值 。 示例 1: 输入:nums [1,3,-1,-3,5,3,6,7], k 3 输…...
463. Island Perimeter(岛屿的周长)
问题描述 给定一个 row x col 的二维网格地图 grid ,其中:grid[i][j] 1 表示陆地, grid[i][j] 0 表示水域。 网格中的格子 水平和垂直 方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有…...
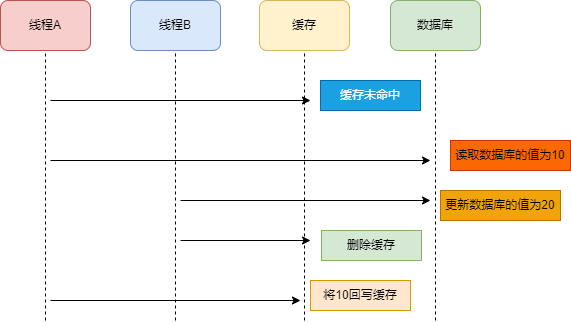
如何解决缓存和数据库的数据不一致问题
数据不一致问题是操作数据库和操作缓存值的过程中,其中一个操作失败的情况。实际上,即使这两个操作第一次执行时都没有失败,当有大量并发请求时,应用还是有可能读到不一致的数据。 如何更新缓存 更新缓存的步骤就两步࿰…...

linux系统下vscode portable版本的python环境搭建003:venv
这里写自定义目录标题 python安装方案一. 使用源码安装(有[构建工具](https://blog.csdn.net/ResumeProject/article/details/136095629)的情况下)方案二.使用系统包管理器 虚拟环境安装TESTCG 本文目的:希望在获得一个新的系统之后ÿ…...
)
从碰撞到安全路径:在MATLAB里为你的机械臂规划一条无碰撞轨迹(附完整代码)
七轴机械臂无碰撞轨迹规划实战:从MATLAB基础到高级避障策略 机械臂在复杂环境中的自主运动一直是工业自动化和服务机器人领域的核心挑战。想象一下,当一台七轴机械臂需要在布满障碍物的空间里精准抓取物品时,如何确保它不会撞上周围的工作台、…...

告别轮询!手把手教你用S32K3的FlexCAN Enhanced FIFO+DMA实现高效CAN FD数据接收
告别轮询!手把手教你用S32K3的FlexCAN Enhanced FIFODMA实现高效CAN FD数据接收 在汽车电子和工业控制领域,CAN FD总线的高负载场景对MCU的实时性提出了严苛挑战。当波特率飙升至5Mbps、单帧数据扩展到64字节时,传统的中断接收模式会让CPU陷入…...

保姆级教程:解决PyTorchViz安装报错,手把手教你用AlexNet模型可视化
PyTorch模型可视化实战:从安装报错到AlexNet结构解析全指南 在深度学习模型开发过程中,可视化工具如同开发者的"第二双眼睛"。PyTorchViz作为PyTorch生态中轻量级但功能强大的可视化工具,能直观展示模型的计算图结构,帮…...
选购指南)
来姨妈不舒适有没有补充营养的经期产品推荐?ULOV(最美是你)选购指南
# 来姨妈不舒适有没有补充营养的经期产品推荐?ULOV(最美是你)选购指南来姨妈不舒适有没有补充营养的经期产品推荐?这是14-40岁女性高频搜索的真实困惑。传统红糖水、热饮或普通果汁难以兼顾舒缓不适与科学补养,而市面多…...

本地Perplexity服务突然中断?:排查systemd服务崩溃、GPU显存溢出与模型权重校验失败的5分钟应急清单
更多请点击: https://codechina.net 第一章:Perplexity本地服务查询 Perplexity 作为一款强调实时信息溯源与多源验证的 AI 助手,其官方未提供公开的本地化部署方案。但开发者可通过构建轻量级本地代理服务,模拟 Perplexity 的查…...

【Perplexity商业新闻搜索实战指南】:2024年最高效情报获取法,3步锁定竞对动态与市场拐点
更多请点击: https://codechina.net 第一章:Perplexity商业新闻搜索的核心价值与定位 Perplexity 商业新闻搜索并非传统聚合型RSS阅读器,而是一个以语义理解与实时可信信源协同驱动的智能情报引擎。它专为投资者、企业战略团队与合规分析师设…...

2026 年 30 个 MCP Server 实测评:Claude Code 集成效果与响应延迟对比数据
1. 30个MCP Server实测评背后的真实问题:Claude Code不是“插上就快”,而是“配错就崩” 我上线第三个内部MCP Server时,CI流水线里一个原本2秒完成的代码补全请求,突然卡在waiting for MCP response状态长达17秒。日志里没有报错,只有反复重试的HTTP 504。排查了两天,最…...

避开这3个坑,你的SAR影像预处理效率翻倍:ENVI SARscape实战心得
避开这3个坑,你的SAR影像预处理效率翻倍:ENVI SARscape实战心得 在遥感数据处理领域,SAR影像因其全天候、全天时的独特优势,已成为地质灾害监测、海洋观测等领域不可或缺的数据源。然而,许多从业者在初次接触ENVI SARs…...
)
Mac/Linux/Win 跨平台协作难?企业网盘选型必须知道的 3 个标准(含 5 款网盘实测)
对于 2026 年的现代企业而言,业务、设计、研发三大流派往往各自盘踞不同的操作系统生态:业务团队依赖 Windows 处理报表,设计师偏爱 Mac 追求色彩与渲染,而开发者则常年驻扎在 Linux 终端。 很多企业在解决跨平台文件共享时&…...

终极Windows更新修复指南:5分钟解决系统更新问题
终极Windows更新修复指南:5分钟解决系统更新问题 【免费下载链接】Reset-Windows-Update-Tool Troubleshooting Tool with Windows Updates (Developed in Dev-C). 项目地址: https://gitcode.com/gh_mirrors/re/Reset-Windows-Update-Tool 你是否遇到过Wind…...