挑战杯 python的搜索引擎系统设计与实现
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 python的搜索引擎系统设计与实现
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:5分
- 创新点:3分
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题简介
随着互联网和宽带上网的普及, 搜索引擎在中国异军突起, 并日益渗透到人们的日常生活中, 在互联网普及之前,
人们查阅资料首先想到的是拥有大量书籍的资料的图书馆。 但是今天很多人都会选择一种更方便、 快捷、 全面、 准确的查阅方式–互联网。
而帮助我们在整个互联网上快速地查找到目标信息的就是越来越被重视的搜索引擎。
今天学长来向大家介绍如何使用python写一个搜索引擎,该项目常用于毕业设计
2 系统设计实现
2.1 总体设计
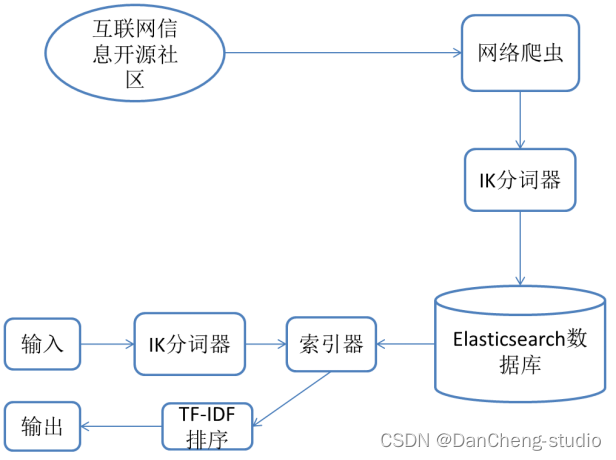
学长设计的系统采用的是非关系型数据库Elasticsearch,因此对于此数据库的查询等基本操作会加以图例的方式进行辅助阐述。在使用者开始进行査询时,系统不可能把使用者输入的关键词与所有本地数据进行匹配,这种检索方式即便建立索引,查询效率仍然较低,而且非常消耗服务器资源。
因此,Elasticsearch将获取到的数据分为两个阶段进行处理。第一阶段:采用合适的分词器,将获取到的数据按照分词器的标准进行分词,第二阶段:对每个关键词的频率以及出现的位置进行统计。
经过以上两个阶段,最后每个词语具体出现在哪些文章中,出现的位置和频次如何,都将会被保存到Elasticsearch数据库中,此过程即为构建倒排索引,需要花费的计算开销很大,但大大提高了后续检索的效率。其中,搜索引擎的索引过程流程图如图

2.2 搜索关键流程
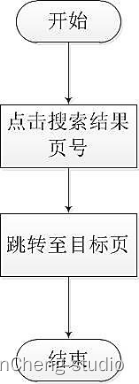
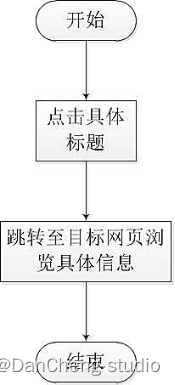
如图所示,每一位用户在搜索框中输入关键字后,点击搜索发起搜索请求,系统后台解析内容后,将搜索结果返回到查询结果页,用户可以直接点击查询结果的标题并跳转到详情页,也可以点击下一页查看其他页面的搜索结果,也可以选择重新在输入框中输入新的关键词,再次发起搜索。
跳转至不同结果页流程图:
浏览具体网页信息流程图:
搜索功能流程图:

2.3 推荐算法
用户可在平台上了解到当下互联网领域中的热点内容,点击文章链接后即可进入到对应的详情页面中,浏览选中的信息的目标网页,详细了解其中的内容。丰富了本搜索平台提供信息的实时性,如图
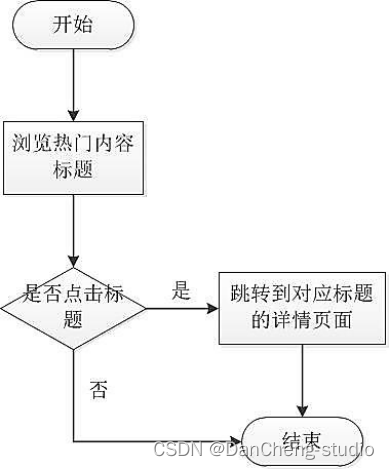
用户可在搜索引擎首页中浏览到系统推送的可能感兴趣的内容,同时用户可点击推送的标题进入具体网页进行浏览详细内容。流程图如图

2.4 数据流的实现
学长设计的系统的数据来源主要是从发布互联网专业领域信息的开源社区上爬虫得到。
再经过IK分词器对获取到的标题和摘要进行分词,再由Elasticsearch建立索引并将数据持久化。
用户通过输入关键词,点击检索,后台程序对获得的关键词再进行分词处理,再到数据库中进行查找,将满足条件的网页标题和摘要用超链接的方式在浏览器中显示出来。
3 实现细节
3.1 系统架构
搜索引擎有基本的五大模块,分别是:
- 信息采集模块
- 信息处理模块
- 建立索引模块
- 查询和 web 交互模块
学长设计的系统目的是在信息处理分析的基础上,建立一个完整的中文搜索引擎。
所以该系统主要由以下几个详细部分组成:
- 爬取数据
- 中文分词
- 相关度排序
- 建立web交互。
3.2 爬取大量网页数据
爬取数据,实际上用的就是爬虫。
我们平时在浏览网页的时候,在浏览器里输入一个网址,然后敲击回车,我们就会看到网站的一些页面,那么这个过程实际上就是这个浏览器请求了一些服务器然后获取到了一些服务器的网页资源,然后我们看到了这个网页。
请求呢就是用程序来实现上面的过程,就需要写代码来模拟这个浏览器向服务器发起请求,然后获取这些网页资源。那么一般来说实际上获取的这些网页资源是一串HTML代码,这里面包含HTML标签,还有一
我们写完程序之后呢就让它一直运行着,它就能代替我们浏览器来向服务器发送请求,然后一直不停的循环的运行进行批量的大量的获取数据了,这就是爬虫的一个基本的流程。
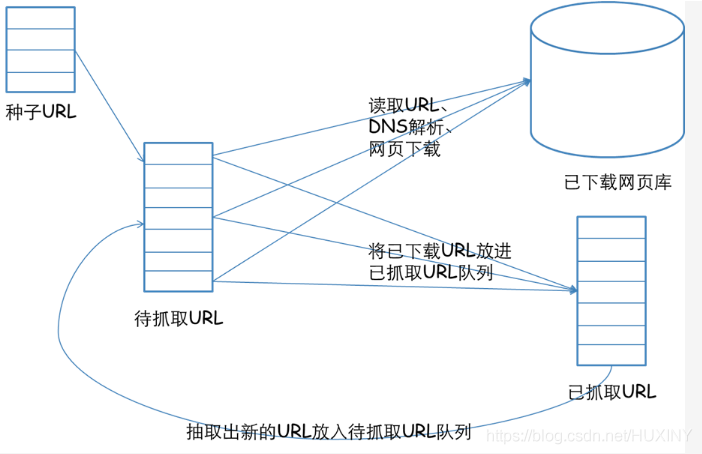
一个通用的网络爬虫的框架如图所示:
这里给出一段爬虫,爬取自己感兴趣的网站和内容,并按照固定格式保存起来:
# encoding=utf-8
# 导入爬虫包
from selenium import webdriver
# 睡眠时间
import time
import re
import os
import requests
# 打开编码方式utf-8打开
# 睡眠时间 传入int为休息时间,页面加载和网速的原因 需要给网页加载页面元素的时间def s(int):time.sleep(int)
# html/body/div[1]/table/tbody/tr[2]/td[1]/input
# http://dmfy.emindsoft.com.cn/common/toDoubleexamp.do
if __name__ == '__main__':#查询的文件位置# fR = open('D:\\test.txt','r',encoding = 'utf-8')# 模拟浏览器,使用谷歌浏览器,将chromedriver.exe复制到谷歌浏览器的文件夹内chromedriver = r"C:\\Users\\zhaofahu\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe"# 设置浏览器os.environ["webdriver.chrome.driver"] = chromedriverbrowser = webdriver.Chrome(chromedriver)# 最大化窗口 用不用都行browser.maximize_window()# header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}# 要爬取的网页neirongs = [] # 网页内容response = [] # 网页数据travel_urls = []urls = []titles = []writefile = open("docs.txt", 'w', encoding='UTF-8')url = 'http://travel.yunnan.cn/yjgl/index.shtml'# 第一页browser.get(url)response.append(browser.page_source)# 休息时间s(3)# 第二页的网页数据#browser.find_element_by_xpath('// *[ @ id = "downpage"]').click()#s(3)#response.append(browser.page_source)#s(3)# 第三页的网页数据#browser.find_element_by_xpath('// *[ @ id = "downpage"]').click()#s(3)#response.append(browser.page_source)
# 3.用正则表达式来删选数据
reg = r'href="(//travel.yunnan.cn/system.*?)"'
# 从数据里爬取data。。。
# 。travel_urls 旅游信息网址
for i in range(len(response)):
travel_urls = re.findall(reg, response[i])
# 打印出来放在一个列表里for i in range(len(travel_urls)):url1 = 'http:' + travel_urls[i]urls.append(url1)browser.get(url1)content = browser.find_element_by_xpath('/html/body/div[7]/div[1]/div[3]').text# 获取标题作为文件名b = browser.page_sourcetravel_name = browser.find_element_by_xpath('//*[@id="layer213"]').texttitles.append(travel_name)print(titles)print(urls)for j in range(len(titles)):writefile.write(str(j) + '\t\t' + titles[j] + '\t\t' + str(urls[j])+'\n')s(1)browser.close()##
3.3 中文分词
中文分词使用jieba库即可
jieba 是一个基于Python的中文分词工具对于一长段文字,其分词原理大体可分为三步:
1.首先用正则表达式将中文段落粗略的分成一个个句子。
2.将每个句子构造成有向无环图,之后寻找最佳切分方案。
3.最后对于连续的单字,采用HMM模型将其再次划分。
jieba分词分为“默认模式”(cut_all=False),“全模式”(cut_all=True)以及搜索引擎模式。对于“默认模式”,又可以选择是否使用
HMM 模型(HMM=True,HMM=False)。
3.4 相关度排序
上面已经根据用户的输入获取到了相关的网址数据。
获取到的数据中rows的形式如下
[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3…),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3…)]
列表的每个元素是一个元组,每个元素的内容是urlid和每个关键词在该文档中的位置。
wordids形式为[wordid1, wordid2, wordid3…],即每个关键词所对应的单词id
我们将会介绍几种排名算法,所谓排名也就是根据各自的规则为每个链接评分,评分越好。并且最终我们会将几种排名算法综合利用起来,给出最终的排名。既然要综合利用,那么我们就要先实现每种算法。在综合利用时会遇到几个问题。
1、每种排名算法评分机制不同,给出的评分尺度和含义也不尽相同
2、如何综合利用,要考虑每种算法的效果。为效果好的给与较大的权重。
我们先来考虑第一个问题,如何消除每种评分算法所给出的评分尺度和含义不相同的问题。
第2个问题,等研究完所有的算法以后再来考虑。
简单,使用归一化,将每个评分值缩放到0-1上,1代表最高,0代表最低。
对爬去到的数据进行排序, 有好几种排序算法:
第1个排名算法:根据单词位置进行评分的函数
我们可以认为对用户输入的多个关键词,在文档中,这些关键词出现的位置越靠前越好。比如我们往往习惯在文章的前面添加一些摘要性、概括性的描述。
# 根据单词位置进行评分的函数.# rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)] def locationscore(self,rows):
locations=dict([(row[0],1000000) for row in rows])
for row in rows:
loc=sum(row[1:]) #计算每个链接的单词位置总和,越小说明越靠前
if loc<locations[row[0]]: #记录每个链接最小的一种位置组合
locations[row[0]]=loc
return self.normalizescores(locations,smallIsBetter=1)####
第2个排名算法:根据单词频度进行评价的函数
我们可以认为对用户输入的多个关键词,在文档中,这些关键词出现的次数越多越好。比如我们在指定主题的文章中会反复提到这个主题。
# 根据单词频度进行评价的函数# rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)]def frequencyscore(self,rows):counts=dict([(row[0],0) for row in rows])for row in rows: counts[row[0]]+=1 #统计每个链接出现的组合数目。 每个链接只要有一种位置组合就会保存一个元组。所以链接所拥有的组合数,能一定程度上表示单词出现的多少。return self.normalizescores(counts)
第3个排名算法:根据单词距离进行评价的函数
我们可以认为对用户输入的多个关键词,在文档中,这些关键词出现的越紧凑越好。这是因为我们更希望所有单词出现在一句话中,而不是不同的关键词出现在不同段落或语句中。
# 根据单词距离进行评价的函数。
# rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)]
def distancescore(self,rows):
# 如果仅查询了一个单词,则得分都一样
if len(rows[0])<=2: return dict([(row[0],1.0) for row in rows])
# 初始化字典,并填入一个很大的值mindistance=dict([(row[0],1000000) for row in rows])for row in rows:dist=sum([abs(row[i]-row[i-1]) for i in range(2,len(row))]) # 计算每种组合中每个单词之间的距离if dist<mindistance[row[0]]: # 计算每个链接所有组合的距离。并为每个链接记录最小的距离mindistance[row[0]]=distreturn self.normalizescores(mindistance,smallIsBetter=1)4 实现效果
热门主题推荐实现
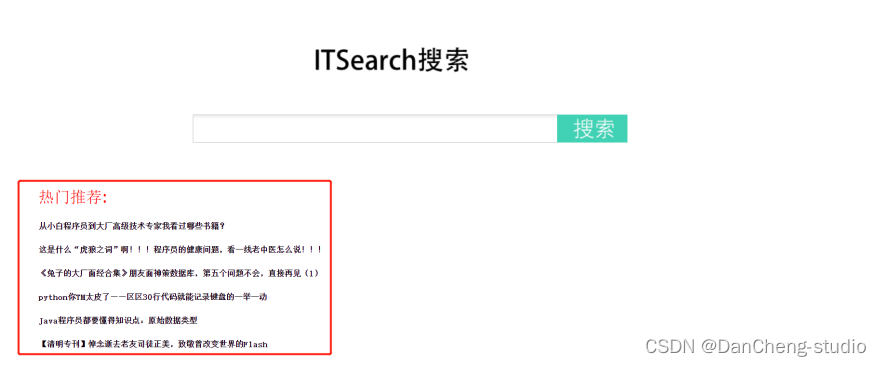
搜索界面的实现

查询结果页面显示
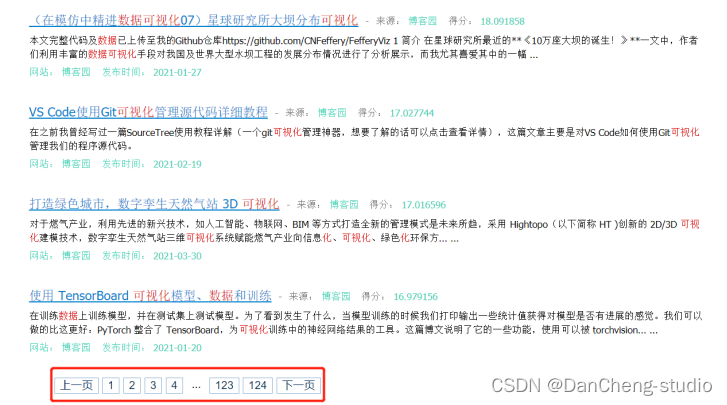
查询结果分页显示
查询结果关键字高亮标记显示
4 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
挑战杯 python的搜索引擎系统设计与实现
0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 python的搜索引擎系统设计与实现 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:5分创新点:3分 该项目较为新颖ÿ…...

【LeetCode: 103. 二叉树的锯齿形层序遍历 + BFS】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...
C#学习(十三)——多线程与异步
一、什么是线程 程序执行的最小单元 一次页面的渲染、一次点击事件的触发、一次数据库的访问、一次登录操作都可以看作是一个一个的进程 在一个进程中同时启用多个线程并行操作,就叫做多线程 由CPU来自动处理 线程有运行、阻塞、就绪三态 代码示例: cl…...
)
MySQL 数据库安装教程详解(linux系统和windows系统)
MySQL 数据库是一种广泛使用的开源关系数据库管理系统。在 Linux 和 Windows 系统上安装 MySQL 数据库的步骤略有不同。以下是详细的安装教程。 Linux 系统安装教程 1. **安装前提**:确保你的 Linux 系统已经安装了 wget、unzip、tar 等必要的工具。 2. **下…...

从汇编分析C语言可变参数的原理,并实现一个简单的sprintf函数
C语言可变参数 使用printf等函数的时候函数原型是printf(const char* fmt, ...), 这一类参数的个数不限的函数是可变参数 使用 使用一个头文件stdarg.h, 主要使用以下的宏 typedef char * va_list;// 把 n 圆整到 sizeof(int) 的倍数 #define _INTSIZEOF(n) ( (sizeo…...
Word docx文件重命名为zip文件,解压后直接查看和编辑
一个不知道算不算冷的知识[doge]: docx格式的文件本质上是一个ZIP文件 当把一个.docx文件重命名为.zip文件并解压后,你会发现里面包含了一些XML文件和媒体文件,它们共同构成了Word文档的内容和格式。 例如,word/document.xml文件…...

SpringBoot中公共字段的自动填充
目录 1 前言 2 使用方法 2.1 自定义枚举类 2.2 自定义注解AutoFill 2.3 自定义切面类并设定切入点 2.4 切面类中设置前置通知,对公共字段赋值 2.5 在方法上添加自定义注解 3 最后 1 前言 在我们的项目中,项目表可能会有一些公共的字段需要我们的…...

【天衍系列 03】深入理解Flink的Watermark:实时流处理的时间概念与乱序处理
文章目录 01 基本概念02 工作原理03 优势与劣势04 核心组件05 Watermark 生成器 使用06 应用场景07 注意事项08 案例分析8.1 窗口统计数据不准8.2 水印是如何解决延迟与乱序问题?8.3 详细分析 09 项目实战demo9.1 pom依赖9.2 log4j2.properties配置9.3 Watermark水印…...

day07.C++类与对象
一.类与对象的思想 1.1面向对象的特点 封装、继承、多态 1.2类的概念 创建对象的过程也叫类的实例化。每个对象都是类的一个具体实例(Instance),拥有类的成员变量和成员函数。由{ }包围,由;结束。 class name{ //类的…...
String讲解
文章目录 String类的重要性常用的方法常用的构造方法String类的比较字符串的查找转化数字转化为字符串字符串转数字 字符串替换字符串的不可变性 字符串拆分字符串截取字符串修改 StringBuilder和StringBuffer String类的重要性 在c/c的学习中我们接触到了字符串,但…...

人群异常聚集监测系统-聚众行为检测与识别算法---豌豆云
聚众识别系统对指定区域进行实时监测,当监测到人群大量聚集、达到设置上限时,立即告警及时疏散。 旅游业作为国民经济战略性支柱产业,随着客流量不断增加,旅游景区和一些旅游城市的管理和服务面临着前所未有的挑战: …...

多模态基础---BERT
1. BERT简介 BERT用于将一个输入的句子转换为word_embedding,本质上是多个Transformer的Encoder堆叠在一起。 其中单个Transformer Encoder结构如下: BERT-Base采用了12个Transformer Encoder。 BERT-large采用了24个Transformer Encoder。 2. BERT的…...

图表示学习 Graph Representation Learning chapter2 背景知识和传统方法
图表示学习 Graph Representation Learning chapter2 背景知识和传统方法 2.1 图统计和核方法2.1.1 节点层次的统计和特征节点的度 节点中心度聚类系数Closed Triangles, Ego Graphs, and Motifs 图层次的特征和图的核节点袋Weisfieler–Lehman核Graphlets和基于路径的方法 邻域…...
)
OpenMVG(计算两个球形图像之间的相对姿态、细化重建效果)
目录 1 Bundle Adjustment(细化重建效果) 2 计算两个球形图像之间的相对姿态 1 Bundle Adjustment(细化重建效果) 数...
)
【QT+QGIS跨平台编译】之三十四:【Pixman+Qt跨平台编译】(一套代码、一套框架,跨平台编译)
文章目录 一、Pixman介绍二、文件下载三、文件分析四、pro文件五、编译实践一、Pixman介绍 Pixman是一款开源的软件库,提供了高质量的像素级图形处理功能。它主要用于在图形渲染、合成和转换方面进行优化,可以帮助开发人员在应用程序中实现高效的图形处理。 Pixman的主要特…...

2.17学习总结
tarjan 【模板】缩点https://www.luogu.com.cn/problem/P3387 题目描述 给定一个 �n 个点 �m 条边有向图,每个点有一个权值,求一条路径,使路径经过的点权值之和最大。你只需要求出这个权值和。 允许多次经过一条边或者…...

Unity类银河恶魔城学习记录7-7 P73 Setting sword type源代码
Alex教程每一P的教程原代码加上我自己的理解初步理解写的注释,可供学习Alex教程的人参考 此代码仅为较上一P有所改变的代码 【Unity教程】从0编程制作类银河恶魔城游戏_哔哩哔哩_bilibili Sword_Skill_Controller.cs using System.Collections; using System.Col…...
安卓版本与鸿蒙不再兼容,鸿蒙开发工程师招疯抢
最近,互联网大厂纷纷开始急招华为鸿蒙开发工程师。这是一个新的信号。在Android和iOS长期霸占市场的今天,鸿蒙的崛起无疑为整个行业带来了巨大的震动。 2023年11月10日,网易更新了高级/资深Android开发工程师岗位,职位要求参与云音…...
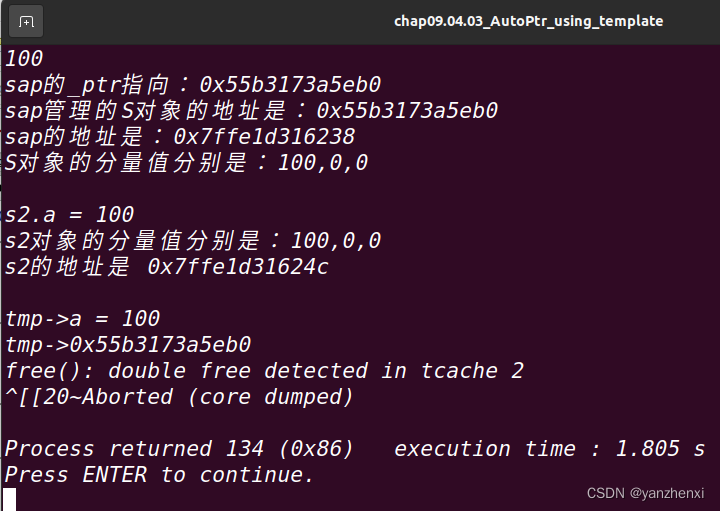
《白话C++》第9章 泛型,Page842~844 9.4.2 AutoPtr
源起: C编程中,最容易出的问题之一,就是内存泄露,而new一个对象,却忘了delete它,则是造成内存泄露的主要原因之一 例子一: void foo() {XXXObject* xo new XXXObject;if(!xo->DoSomethin…...
服务流控(Sentinel)
引入依赖 <!-- 必须的 --> <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId> </dependency><!-- sentinel 核心库 --> <dependency><groupId>com.ali…...

从CVE到ATTCK:如何用Elastic Stack构建你的个人安全情报仪表盘
从CVE到ATT&CK:如何用Elastic Stack构建你的个人安全情报仪表盘 在安全运营领域,数据孤岛一直是分析师面临的主要挑战。CVE漏洞数据库、CWE弱点分类、CAPEC攻击模式以及ATT&CK框架各自提供了宝贵的安全情报,但这些数据往往分散在不同…...
)
毕设救星:手把手教你用Android Studio和OkHttp3搞定OneNET新版API数据获取(附完整Java代码)
物联网毕设实战:Android Studio对接OneNET新版API全流程解析 在物联网相关专业的毕业设计中,如何快速构建一个能实际运行的设备数据监控APP往往是让本科生头疼的难题。本文将手把手带你完成从零开始的完整开发流程,重点解决三个核心痛点&…...

明日方舟自动化助手MAA:3步解放双手,让游戏回归乐趣
明日方舟自动化助手MAA:3步解放双手,让游戏回归乐趣 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: ht…...

AI技术总监的晋升密码:搞定这6件事,你也能领导AI团队
在AI技术重塑各行各业的当下,软件测试从业者正站在职业转型的关键路口。从测试工程师到AI技术总监,不仅是职位的跃迁,更是能力模型的全面升级。想要在AI浪潮中脱颖而出,成为引领团队的技术掌舵人,你需要搞定这6件事。一…...

大模型注意力机制深度解析:从Dot-Product到Flash Attention的演进之路
引言如果让你用一句话概括过去七年人工智能领域最重要的技术突破,答案几乎毫无悬念——注意力机制(Attention Mechanism) 。2017年,Google团队在论文《Attention Is All You Need》中首次提出Transformer架构,彻底摒弃…...

别再死记硬背了!用Pointer Network让AI学会‘抄作业’,搞定文本摘要和对话生成
别再死记硬背了!用Pointer Network让AI学会‘抄作业’,搞定文本摘要和对话生成 想象一下,当你面对一篇冗长的技术文档时,最有效的学习方法是什么?不是逐字背诵,而是用荧光笔划出关键概念——这正是Pointer …...

BiliBiliToolPro:解放双手的B站自动化神器,让你的账号管理从未如此轻松
BiliBiliToolPro:解放双手的B站自动化神器,让你的账号管理从未如此轻松 【免费下载链接】BiliBiliToolPro B 站(bilibili)自动任务工具,支持docker、青龙、k8s等多种部署方式。全面拥抱AI。敏感肌也能用。 项目地址:…...

对比直接购买与通过Taotoken聚合使用大模型API的体验差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买与通过Taotoken聚合使用大模型API的体验差异 在开发和集成大模型能力的过程中,开发者或团队通常面临两种主…...

为 OpenClaw 智能体工作流配置 Taotoken 作为其大模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 OpenClaw 智能体工作流配置 Taotoken 作为其大模型供应商 在构建基于 OpenClaw 框架的 AI 智能体工作流时,开发者通…...

在OpenClaw中快速接入Taotoken并开始你的第一个Agent任务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw中快速接入Taotoken并开始你的第一个Agent任务 对于使用OpenClaw进行AI应用开发的工程师来说,接入不同的模型…...