文生视频:Sora模型报告总结
作为世界模拟器的视频生成模型
我们探索视频数据生成模型的大规模训练。具体来说,我们在可变持续时间、分辨率和宽高比的视频和图像上联合训练文本条件扩散模型。我们利用对视频和图像潜在代码的时空补丁进行操作的变压器架构。我们最大的模型 Sora 能够生成一分钟的高保真视频。我们的结果表明,扩展视频生成模型是构建物理世界通用模拟器的一条有前途的途径。
总结:Sora包含了DALL·E 3 的recaption技术 + 图像/视频Patches + Transformers + Latent Diffusion + 原始数据分辨率训练
资源:查看 Sora 概览
视频生成, 索拉, 里程碑, 发布
Sora文生视频
本技术报告重点关注(1)我们将所有类型的视觉数据转化为统一表示的方法,从而能够大规模训练生成模型,以及(2)对 Sora 的能力和局限性进行定性评估。本报告不包含模型和实施细节。
许多先前的工作已经研究了使用各种方法对视频数据进行生成建模,包括循环网络、1 ,2 ,3生成对抗网络,4 ,5 ,6 ,7自回归变压器,8 ,9和扩散模型。10 ,11、12这些作品通常关注一小类视觉数据、较短的视频或固定大小的视频。Sora 是视觉数据的通用模型,它可以生成不同时长、长宽比和分辨率的视频和图像,最多可达一分钟的高清视频。
将视觉数据转化为补丁
我们从大型语言模型中获得灵感,这些模型通过互联网规模数据的训练来获得通用能力。13、14LLM 范式的成功部分归功于令牌的使用, 这些令牌优雅地统一了文本代码、数学和各种自然语言的不同模式。在这项工作中,我们考虑视觉数据的生成模型如何继承这些好处。LLM 有文本标记,而 Sora 有视觉补丁。此前,补丁已被证明是视觉数据模型的有效表示。15 ,16 ,17、18我们发现补丁是一种高度可扩展且有效的表示形式,可用于在不同类型的视频和图像上训练生成模型。

在较高的层次上,我们首先将视频压缩到较低维的潜在空间,将视频转换为补丁,19然后将表示分解为时空补丁。
视频压缩网络
我们训练一个降低视觉数据维度的网络。20该网络将原始视频作为输入并输出在时间和空间上压缩的潜在表示。Sora 在这个压缩的潜在空间中接受训练并随后生成视频。我们还训练了相应的解码器模型,将生成的潜伏映射回像素空间。
时空潜在斑块
给定一个压缩的输入视频,我们提取一系列时空补丁,充当变压器令牌。该方案也适用于图像,因为图像只是具有单帧的视频。我们基于补丁的表示使 Sora 能够对不同分辨率、持续时间和长宽比的视频和图像进行训练。在推理时,我们可以通过在适当大小的网格中排列随机初始化的补丁来控制生成视频的大小。
用于视频生成的缩放变压器
Sora是一个扩散模型21、22、23、24、25; 给定输入噪声补丁(以及文本提示等调节信息),它被训练来预测原始的“干净”补丁。重要的是,Sora 是一个扩散变压器。26Transformer 在各个领域都表现出了卓越的扩展特性,包括语言建模、13、14计算机视觉,15 ,16 ,17、18和图像生成。27、28 ,29

在这项工作中,我们发现扩散变压器也可以有效地缩放为视频模型。下面,我们展示了训练过程中具有固定种子和输入的视频样本的比较。随着训练计算的增加,样本质量显着提高。

可变的持续时间、分辨率、宽高比
过去的图像和视频生成方法通常会将视频调整大小、裁剪或修剪为标准尺寸,例如,分辨率为 256x256 的 4 秒视频。我们发现,对原始大小的数据进行训练有几个好处。
采样灵活性
Sora 可以采样宽屏 1920x1080p 视频、垂直 1080x1920 视频以及介于两者之间的所有视频。这使得 Sora 可以直接以其原生宽高比为不同设备创建内容。它还使我们能够在以全分辨率生成之前快速以较低尺寸制作原型内容 - 所有这些都使用相同的模型。
改进的框架和构图
我们根据经验发现,以原始长宽比对视频进行训练可以改善构图和取景。我们将 Sora 与将所有训练视频裁剪为正方形的模型版本进行比较,这是训练生成模型时的常见做法。在方形作物(左)上训练的模型有时会生成仅部分可见主体的视频。相比之下,Sora(右)的视频取景有所改善。
语言理解
训练文本到视频生成系统需要大量带有相应文本字幕的视频。我们应用了 DALL·E 3 中引入的重新字幕技术30到视频。我们首先训练一个高度描述性的字幕生成器模型,然后使用它为训练集中的所有视频生成文本字幕。我们发现,对高度描述性视频字幕进行训练可以提高文本保真度以及视频的整体质量。
与 DALL·E 3 类似,我们还利用 GPT 将简短的用户提示转换为较长的详细字幕,然后发送到视频模型。这使得 Sora 能够生成准确遵循用户提示的高质量视频。
通过图像和视频进行提示
上面和我们的着陆页中的所有结果都显示文本到视频的示例。但 Sora 也可以通过其他输入进行提示,例如预先存在的图像或视频。此功能使 Sora 能够执行各种图像和视频编辑任务 - 创建完美的循环视频、动画静态图像、及时向前或向后扩展视频等。
DALL·E 图像动画
Sora 能够生成提供图像和提示作为输入的视频。下面我们展示基于DALL·E 2生成的示例视频31和达尔·E 330图片。

一只戴着贝雷帽和黑色高领毛衣的柴犬。

不同家族怪物的平面设计风格的怪物插图。该群体包括一个毛茸茸的棕色怪物、一个带有天线的光滑黑色怪物、一个有斑点的绿色怪物和一个小圆点怪物,所有怪物都在一个有趣的环境中互动。

写有“SORA”的现实云的图像。

在一座华丽的历史大厅里,巨大的浪潮达到顶峰并开始崩塌。两名冲浪者抓住时机,熟练地驾驭海浪。
扩展生成的视频
Sora 还能够在时间上向前或向后扩展视频。下面是四个视频,它们都是从生成的视频片段开始向后延伸的。因此,这四个视频的开头都不同,但所有四个视频的结局都是相同的。
我们可以使用此方法向前和向后扩展视频以产生无缝的无限循环。
视频到视频编辑
扩散模型启用了多种根据文本提示编辑图像和视频的方法。下面我们应用其中一种方法,SDEdit,32到索拉。这项技术使 Sora 能够零镜头地改变输入视频的风格和环境。

输入视频
将设置更改为茂密的丛林将场景更改为 1920 年代的旧校车。确保保持红色让它进入水下将视频设置更改为与山不同?也许是约书亚树?将视频放在有彩虹路的太空中保持视频不变,但将时间设为冬天以粘土动画风格制作以炭笔画的风格重新创作,确保是黑白的将设置更改为赛博朋克将视频更改为中世纪主题让它有恐龙以像素艺术风格重写视频
连接视频
我们还可以使用 Sora 在两个输入视频之间逐渐进行插值,从而在具有完全不同主题和场景构成的视频之间创建无缝过渡。在下面的示例中,中心的视频插值在左侧和右侧的相应视频之间。
图像生成能力
Sora 还能够生成图像。我们通过在时间范围为一帧的空间网格中排列高斯噪声块来实现这一点。该模型可以生成各种尺寸的图像,分辨率高达 2048x2048。

新兴的模拟功能
我们发现,视频模型在大规模训练时表现出许多有趣的新兴功能。这些功能使 Sora 能够模拟现实世界中人、动物和环境的某些方面。这些属性的出现对 3D、物体等没有任何明确的归纳偏差——它们纯粹是尺度现象。
3D 一致性。 Sora 可以生成带有动态摄像机运动的视频。随着摄像机的移动和旋转,人和场景元素在三维空间中一致移动。
远程相干性和物体持久性。 视频生成系统面临的一个重大挑战是在采样长视频时保持时间一致性。我们发现 Sora 通常(尽管并非总是)能够有效地对短期和长期依赖关系进行建模。例如,我们的模型可以保留人、动物和物体,即使它们被遮挡或离开框架。同样,它可以在单个样本中生成同一角色的多个镜头,并在整个视频中保持其外观。
与世界互动。 索拉有时可以用简单的方式模拟影响世界状况的动作。例如,画家可以在画布上留下新的笔触,并随着时间的推移而持续存在,或者一个人可以吃汉堡并留下咬痕。
模拟数字世界。 Sora 还能够模拟人工过程——一个例子是视频游戏。Sora 可以同时通过基本策略控制《我的世界》中的玩家,同时以高保真度渲染世界及其动态。这些能力可以通过用提及“我的世界”的标题提示 Sora 来零射击。
这些功能表明,视频模型的持续扩展是开发物理和数字世界以及生活在其中的物体、动物和人的高性能模拟器的一条有前途的道路。
讨论
Sora 目前作为模拟器表现出许多局限性。例如,它不能准确地模拟许多基本相互作用的物理过程,例如玻璃破碎。其他交互(例如吃食物)并不总是会产生对象状态的正确变化。我们在登陆页面中列举了模型的其他常见故障模式,例如长时间样本中出现的不连贯性或对象的自发出现。
我们相信,Sora 今天所拥有的能力表明,视频模型的持续扩展是开发物理和数字世界以及生活在其中的物体、动物和人的强大模拟器的一条有前途的道路。
参考
- 斯里瓦斯塔瓦、尼蒂什、埃尔曼·曼西莫夫和鲁斯兰·萨拉胡迪诺夫。“使用 lstms 进行视频表示的无监督学习。” 机器学习国际会议。PMLR,2015。↩︎
- 奇亚帕、西尔维娅等人。“循环环境模拟器。” arXiv 预印本 arXiv:1704.02254 (2017)。↩︎
- 哈,大卫和尤尔根·施米德胡贝尔。“世界模特。” arXiv 预印本 arXiv:1803.10122 (2018)。↩︎
- 冯德里克、卡尔、哈米德·皮尔西亚瓦什和安东尼奥·托拉尔巴。“生成具有场景动态的视频。” 神经信息处理系统的进展 29 (2016)。↩︎
- 图利亚科夫,谢尔盖,等人。“Mocogan:分解运动和内容以生成视频。” IEEE 计算机视觉和模式识别会议论文集。2018. ↩︎
- 克拉克、艾丹、杰夫·多纳休和凯伦·西蒙尼安。“复杂数据集上的对抗性视频生成。” arXiv 预印本 arXiv:1907.06571 (2019)。↩︎
- 布鲁克斯、蒂姆等人。“生成动态场景的长视频。” 神经信息处理系统的进展 35 (2022): 31769-31781。↩︎
- 严,威尔逊,等人。“Videogpt:使用 vq-vae 和 Transformer 生成视频。” arXiv 预印本 arXiv:2104.10157 (2021)。↩︎
- 吴晨飞,等。“女娲:神经视觉世界创建的视觉合成预训练。” 欧洲计算机视觉会议。Cham:施普林格自然瑞士,2022。↩︎
- 何乔纳森等人。“Imagen 视频:使用扩散模型生成高清视频。” arXiv 预印本 arXiv:2210.02303 (2022)。↩︎
- 布拉特曼、安德烈亚斯等人。“对齐你的潜在特征:高分辨率视频合成与潜在扩散模型。” IEEE/CVF 计算机视觉和模式识别会议论文集。2023.↩︎ _
- 古普塔、阿格里姆等人。“使用扩散模型生成逼真的视频。” arXiv 预印本 arXiv:2312.06662 (2023)。↩︎
- 瓦斯瓦尼、阿什什等人。“你所需要的就是注意力。” 神经信息处理系统的进展30 (2017)。↩︎ ↩︎
- 布朗、汤姆等人。“语言模型是小样本学习者。” 神经信息处理系统的进展33(2020):1877-1901。↩︎ ↩︎
- 多索维茨基,阿列克谢,等人。“一张图像相当于 16x16 个单词:用于大规模图像识别的 Transformer。” arXiv 预印本 arXiv:2010.11929 (2020)。↩︎ ↩︎
- 阿纳布、阿努拉格等人。“Vivit:视频视觉转换器。” IEEE/CVF 计算机视觉国际会议论文集。2021. ↩︎ ↩︎
- 他,凯明,等人。“蒙面自动编码器是可扩展的视觉学习器。” IEEE/CVF 计算机视觉和模式识别会议论文集。2022. ↩︎ ↩︎
- 德加尼、穆斯塔法等人。“Patch n’Pack:NaViT,适用于任何宽高比和分辨率的视觉转换器。” arXiv 预印本 arXiv:2307.06304 (2023)。↩︎ ↩︎
- 罗姆巴赫、罗宾等人。“利用潜在扩散模型进行高分辨率图像合成。” IEEE/CVF 计算机视觉和模式识别会议论文集。2022.↩︎ _
- Kingma、Diederik P. 和马克斯·威灵。“自动编码变分贝叶斯。” arXiv 预印本 arXiv:1312.6114 (2013)。↩︎
- 索尔-迪克斯坦、贾沙等人。“利用非平衡热力学进行深度无监督学习。” 机器学习国际会议。PMLR,2015。↩︎
- 何乔纳森、阿杰·贾恩和彼得·阿贝尔。“去噪扩散概率模型。” 神经信息处理系统的进展33(2020):6840-6851。↩︎
- 尼科尔、亚历山大·奎因和普拉富拉·达里瓦尔。“改进的去噪扩散概率模型。” 国际机器学习会议。PMLR,2021。↩︎
- 达里瓦尔、普拉富拉和亚历山大·奎因·尼科尔。“扩散模型在图像合成方面击败了 GAN。” 神经信息处理系统的进展。2021.↩︎ _
- 卡拉斯、泰罗等人。“阐明基于扩散的生成模型的设计空间。” 神经信息处理系统的进展35 (2022): 26565-26577。↩︎
- 皮布尔斯、威廉和谢赛宁。“带有变压器的可扩展扩散模型。” IEEE/CVF 国际计算机视觉会议论文集。2023.↩︎ _
- 陈、马克等人。“从像素进行生成预训练。” 机器学习国际会议。PMLR,2020。↩︎
- 拉梅什、阿迪亚等人。“零镜头文本到图像生成。” 国际机器学习会议。PMLR,2021。↩︎
- 于家辉,等。“扩展自回归模型以生成内容丰富的文本到图像。” arXiv 预印本 arXiv:2206.10789 2.3 (2022): 5. ↩︎
- 贝特克、詹姆斯等人。“通过更好的字幕改进图像生成。” 计算机科学。https://cdn.openai.com/papers/dall-e-3。pdf 2.3 (2023): 8 ↩︎ ↩︎
- 拉梅什、阿迪亚等人。“具有剪辑潜在特征的分层文本条件图像生成。” arXiv 预印本 arXiv:2204.06125 1.2 (2022): 3. ↩︎
- 孟陈林,等。“Sdedit:使用随机微分方程引导图像合成和编辑。” arXiv 预印本 arXiv:2108.01073 (2021)。↩︎
相关文章:
文生视频:Sora模型报告总结
作为世界模拟器的视频生成模型 我们探索视频数据生成模型的大规模训练。具体来说,我们在可变持续时间、分辨率和宽高比的视频和图像上联合训练文本条件扩散模型。我们利用对视频和图像潜在代码的时空补丁进行操作的变压器架构。我们最大的模型 Sora 能够生成一分钟…...

GA 374-2019 电子防盗锁检测
电子防盗锁是指以电子方式识别,处理相关信息并控制执行机构实施启闭且达到规定安全级别的锁具。 GA 374-2019 电子防盗锁检测项目 测试项目 测试标准 外观 GA 374 外壳防护等级 GA 374 功能 GA 374 编码组合数 GA 374 主锁舌伸出长度 GA 374 主锁舌灵活…...

代码随想录day26 Java版
今天开始刷贪心算法,新手保护期中爽得一批 455.分发饼干 先把两个数组排序,采用先满足胃口小的孩子,饼干数组无条件向后扫描,能满足孩子后再向后扫描胃口数组 class Solution {public int findContentChildren(int[] g, int[] …...
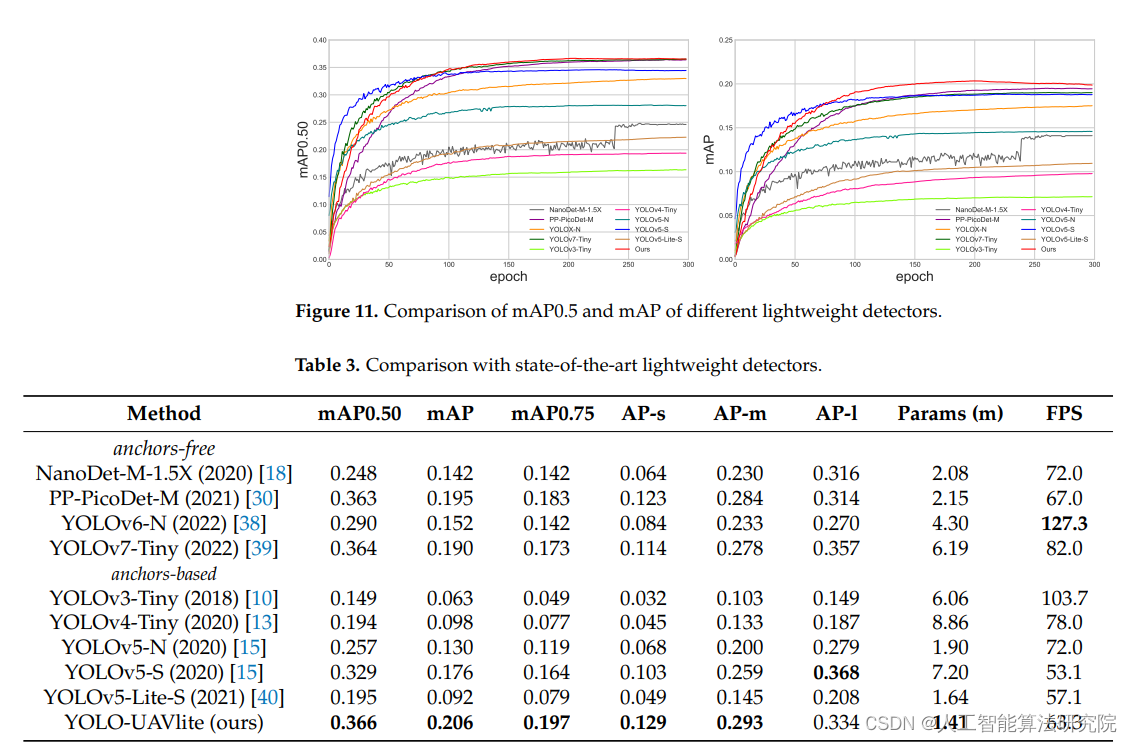
英文论文(sci)解读复现【NO.21】一种基于空间坐标的轻量级目标检测器无人机航空图像的自注意
此前出了目标检测算法改进专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读发表高水平学术期刊中的 SCI论文&a…...

数据集合
目录 并集 union union all 区别 交集 intersect 差集 minus 错误操作 Oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 常用的数学集合有:交集、并集、差集、补集 每一次查询实际上都会返回数据集合,…...

php基础学习之作用域和静态变量
作用域 变量(常量)能够被访问的区域,变量可以在常规代码中定义,也可以在函数内部定义 变量的作用域 在 PHP 中作用域严格来说分为两种,但是 PHP内部还定义一些在严格意义之外的一种,所以总共算三种—— 局部…...

SP1:基于Plonky3构建的zkVM
1. 引言 SP1为SuccictLab开源的,基于Plonky3构建的zkVM。 开源代码见: https://github.com/succinctlabs/sp1(Rust) 当前暂未实现onchain-verifier,但会采用标准的STARK->SNARK verifier。 SP1 zkVM基于的指令…...
Python爬虫之文件存储#5
爬虫专栏:http://t.csdnimg.cn/WfCSx 文件存储形式多种多样,比如可以保存成 TXT 纯文本形式,也可以保存为 JSON 格式、CSV 格式等,本节就来了解一下文本文件的存储方式。 TXT 文本存储 将数据保存到 TXT 文本的操作非常简单&am…...
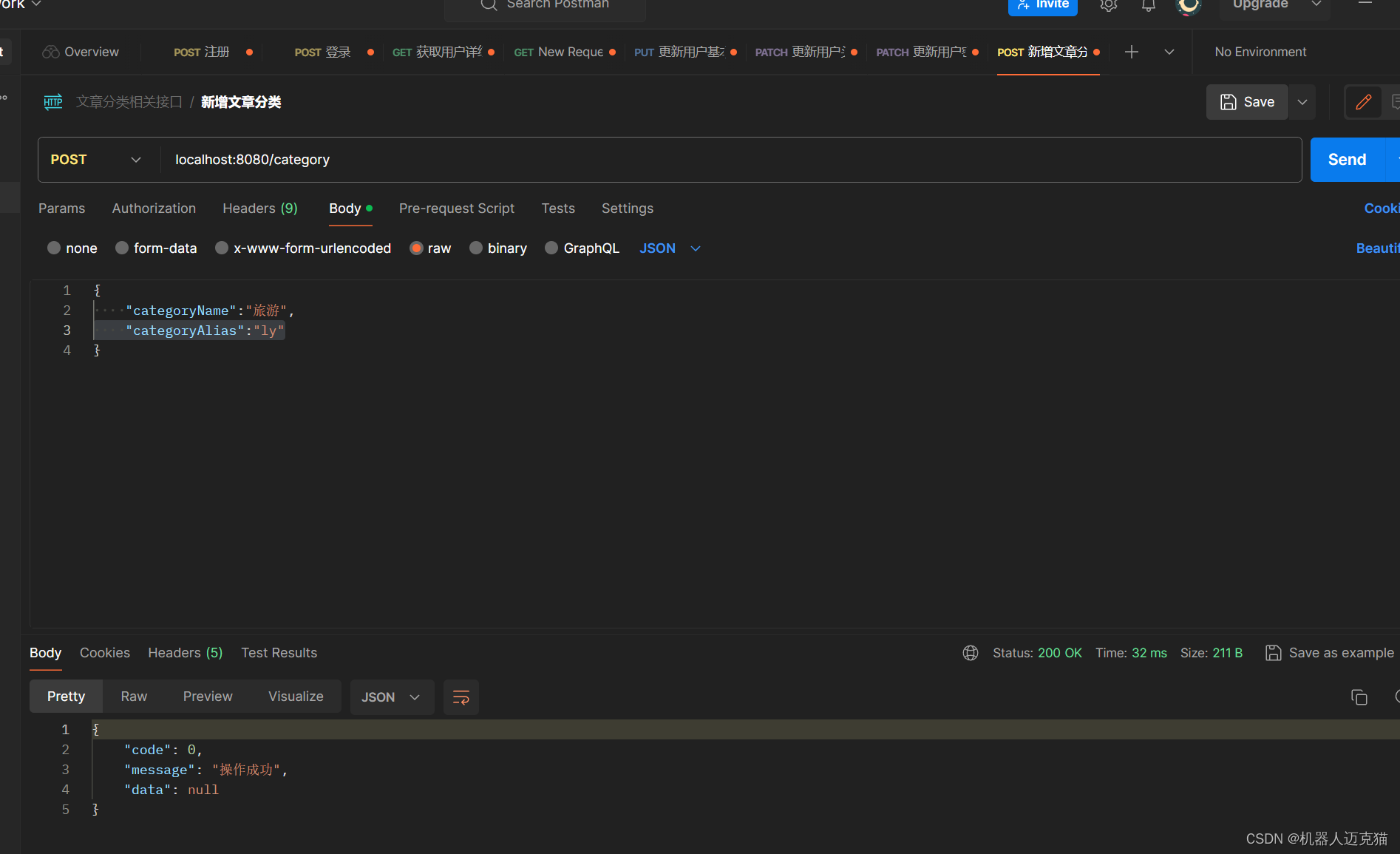
Spring Boot 笔记 012 创建接口_添加文章分类
1.1.1 实体类添加校验 package com.geji.pojo;import jakarta.validation.constraints.NotEmpty; import lombok.Data;import java.time.LocalDateTime;Data public class Category {private Integer id;//主键IDNotEmptyprivate String categoryName;//分类名称NotEmptypriva…...

Spring-面试题
一、Spring 1、Spring的优势 通过IOC、AOP简化java开发 IOC减低业务对象替换的复杂性,降低耦合AOP允许将一些通用的事务、日志进行集中处理,从而提高更好的复用性Spring生态圈低嵌入式涉及,代码污染小高度开放性,用的人多2、Spring的核心 IOC控制反转: Spring容器为我们创…...
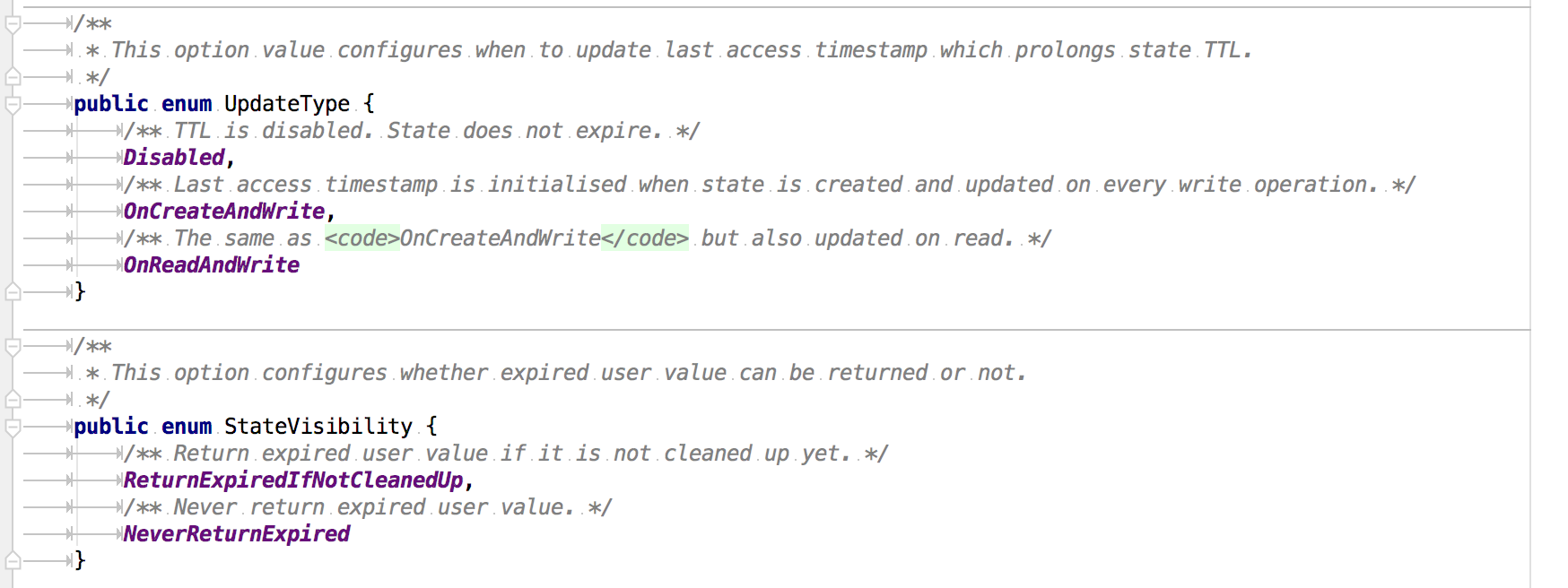
Flink理论—容错之状态
Flink理论—容错之状态 在 Flink 的框架中,进行有状态的计算是 Flink 最重要的特性之一。所谓的状态,其实指的是 Flink 程序的中间计算结果。Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。 Flink 使用…...
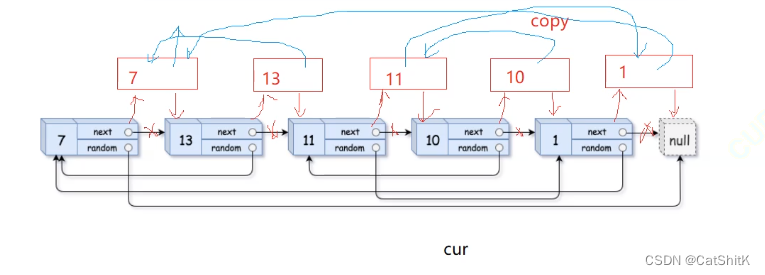
【数据结构】链表OJ面试题5《链表的深度拷贝》(题库+解析)
1.前言 前五题在这http://t.csdnimg.cn/UeggB 后三题在这http://t.csdnimg.cn/gbohQ 给定一个链表,判断链表中是否有环。http://t.csdnimg.cn/Rcdyc 给定一个链表,返回链表开始入环的第一个结点。 如果链表无环,则返回 NULLhttp://t.cs…...
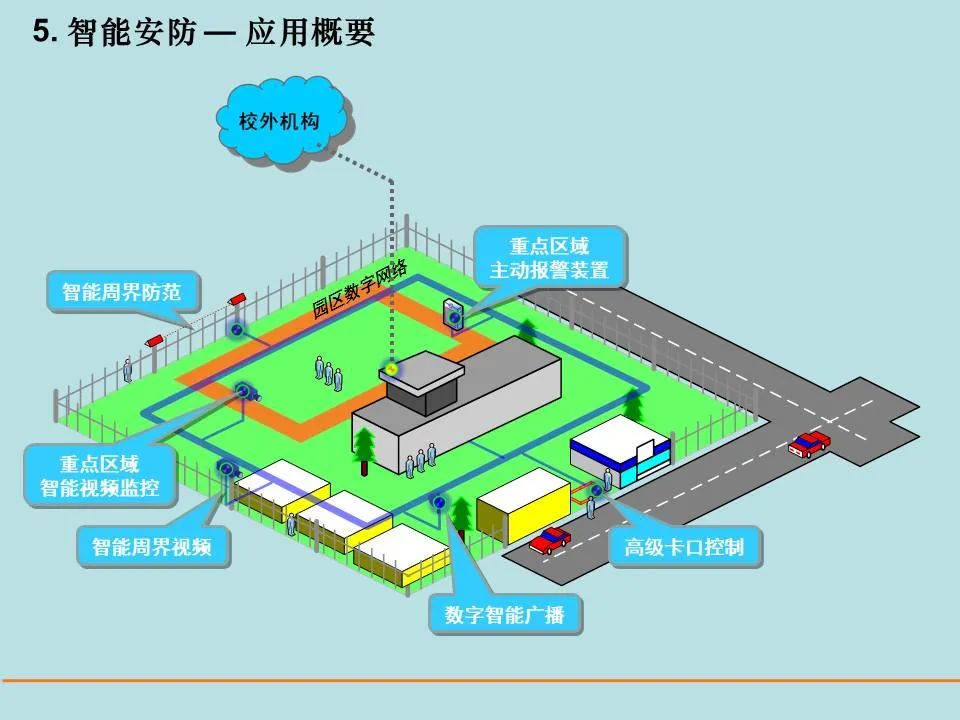
智慧校园规划建设方案
校园信息化建设呈现智能化、应用多样化发展趋势,多种技术和应用交叉渗透至校园生活的各个方面,全面的智慧校园时代已经到来。 对智慧校园的四大应用领域分析 智慧的教学 信息共享交互:建立信息发布、共享、传播与交互的公共平台 教学流程…...

003 - Hugo, 创建文章
003 - Hugo, 创建文章创建文章单个md文件md文件图片总结 文章内容Front Matter文章目录数学公式的显示KaTeXMathJax 图片 003 - Hugo, 创建文章 创建文章 单个md文件 创建文章的方式: 手动创建:在post目录下,手动创建md文件。命令创建&am…...
HCIA-HarmonyOS设备开发认证V2.0-IOT硬件子系统-GPIO
目录 一、GPIO 概述二、GPIO模块相关API三、实例四、GPIO HDF驱动开发4.1、LED驱动程序(待续...)4.2、LED驱动配置(待续...) 坚持就有收获 轻量系统设备通常需要进行外设控制,例如温湿度数据的采集、灯开关的控制,因此在完成内核开发后,需要进…...

《Java 简易速速上手小册》第7章:Java 网络编程(2024 最新版)
文章目录 7.1 网络基础和 Java 中的网络 - 揭开神秘的面纱7.1.1 基础知识7.1.2 重点案例:实现一个简单的聊天程序7.1.3 拓展案例 1:使用 UDP 进行消息广播7.1.4 拓展案例 2:建立一个简单的 Web 服务器 7.2 创建客户端和服务器 - 构建沟通的桥…...

用keras对电影评论进行情感分析
文章目录 下载IMDb数据读取IMDb数据建立分词器将评论数据转化为数字列表让转换后的数字长度相同加入嵌入层建立多层感知机模型加入平坦层加入隐藏层加入输出层查看模型摘要 训练模型评估模型准确率进行预测查看测试数据预测结果完整函数用RNN模型进行IMDb情感分析用LSTM模型进行…...
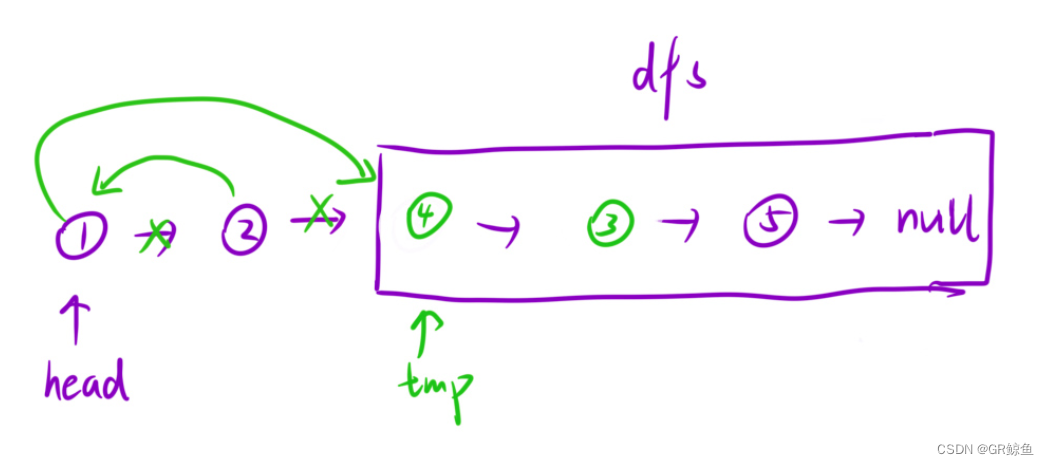
每日OJ题_算法_递归④力扣24. 两两交换链表中的节点
目录 ④力扣24. 两两交换链表中的节点 解析代码 ④力扣24. 两两交换链表中的节点 24. 两两交换链表中的节点 难度 中等 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即…...

110 C++ decltype含义,decltype 主要用途
一,decltype 含义和举例 decltype有啥返回啥,auto则不一样,auto可能会舍弃一些东西。 decltype 是 C11提出的说明符。主要作用是:返回操作数的数据类型。 decltype 是用来推导类型,decltype对于一个给定的 变量名或…...
)
PYTHON 120道题目详解(85-87)
85.Python中如何使用enumerate()函数获取序列的索引和值? enumerate()函数是Python的内置函数,它可以将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中。 以下是一个…...

Vue3生态系统:打造完整的前端开发体系
Vue3生态系统:打造完整的前端开发体系 前言 大家好,我是前端老炮儿。今天咱们来聊聊Vue3的生态系统。 如果说Vue3是一辆超级跑车,那它的生态系统就是配套的加油站、维修站和改装厂。一个好的框架不仅要有强大的核心能力,还要有…...

Perplexity到底值不值得替代搜索引擎?37小时实测+127次对比查询,答案出人意料
更多请点击: https://intelliparadigm.com 第一章:Perplexity到底值不值得替代搜索引擎?37小时实测127次对比查询,答案出人意料 实测设计与数据采集方法 我们构建了覆盖技术文档、学术论文、实时新闻、API调试、开源项目溯源五大…...
保姆级接线图解,附万用表检测电池坏点技巧)
别再乱接线了!12V手电钻保护板(B+/B-/B1/B2)保姆级接线图解,附万用表检测电池坏点技巧
12V手电钻保护板接线全攻略:从原理到实战的安全操作指南 面对手电钻保护板上密密麻麻的接线端子,即使是经验丰富的DIY爱好者也难免感到困惑。B、B-、B1、B2这些看似简单的标记背后,实际上隐藏着锂电池组安全工作的关键机制。本文将带您深入理…...

从‘均分误差’到‘功率打架’:实战中调试微电网逆变器下垂系数的避坑指南
从‘均分误差’到‘功率打架’:实战中调试微电网逆变器下垂系数的避坑指南 微电网系统中,多个分布式电源并联运行时,有功功率分配不均的问题如同暗礁,稍有不慎就会导致系统效率下降甚至设备过载。这种被工程师们戏称为"功率打…...

翻转电饼铛生产厂家:竞争突围与渠道升级策略解析
翻转电饼铛生产厂家竞争突围与渠道升级策略FAQ:从技术到服务的破局之道"低价内卷走不远,翻转电饼铛生产厂家需靠技术差异化与服务价值突围"——这是食品机械行业从业者的共同感悟。当前市场竞争加剧,厂家面临人工成本高、品控不稳定…...

AIGC 检测‘信息密度‘到底是什么?嘎嘎降 AI 帮你 AI 率从 65% 降到 8%
AIGC 检测"信息密度"到底是什么?嘎嘎降 AI 帮你 AI 率从 65% 降到 8% AIGC 检测算法 4.0 版本看的 5 项底层指标里——信息密度权重排第二(约 25%)。理解了这一项你才知道为什么"工整学术风"也会被判 AI。这篇文章把&quo…...

STM32体重秤电子秤称重超重报警Proteus仿真资源包
STM32体重秤电子秤称重超重报警Proteus仿真资源包 【下载地址】STM32体重秤电子秤称重超重报警Proteus仿真资源包 本资源包提供了基于STM32单片机的体重秤电子秤称重超重报警系统的完整解决方案。资源内容包括源代码、Proteus仿真文件以及全套相关资料,帮助用户快速…...

多VM同时启动卡爆?2种方法设置启动延迟,避免启动风暴
在虚拟化运维中,多台虚拟机(VM)同时启动时,很容易引发“启动风暴”——CPU、内存、存储IO瞬间被占满,导致所有虚拟机启动缓慢、卡顿,甚至部分VM启动失败,严重影响业务正常运行。其实解决方法很简…...

CH348芯片全平台驱动实战:从Windows Server到树莓派Linux,一次搞定8串口配置
CH348芯片全平台驱动实战:从Windows Server到树莓派Linux,一次搞定8串口配置 工业自动化、物联网网关、多设备调试等场景中,工程师常面临一个核心痛点:如何在各类操作系统环境下高效管理多串口设备。南京沁恒微电子的CH348芯片以其…...

昇思大模型预训练数据来源
昇思 MindSpore 大模型(如鹏程・盘古、Qwen、Skywork 等)的预训练数据以中文为核心、多源异构融合、高质量过滤为特点,依托开源数据、互联网爬虫、电子书与领域数据构建,经分布式清洗、去重、过滤后形成百亿至千亿级 Token 的训练…...