通过 Prometheus 编写 TiDB 巡检脚本(脚本已开源,内附链接)
作者丨 caiyfc
来自神州数码钛合金战队
神州数码钛合金战队是一支致力于为企业提供分布式数据库 TiDB 整体解决方案的专业技术团队。团队成员拥有丰富的数据库从业背景,全部拥有 TiDB 高级资格证书,并活跃于 TiDB 开源社区,是官方认证合作伙伴。目前已为 10+ 客户提供了专业的 TiDB 交付服务,涵盖金融、证券、物流、电力、政府、零售等重点行业。
背景
笔者最近在驻场,发现这里的 tidb 集群是真的多,有将近 150 套集群。而且集群少则 6 个节点起步,多则有 200 多个节点。在这么庞大的集群体量下,巡检就变得非常的繁琐了。
那么有没有什么办法能够代替手动巡检,并且能够快速准确的获取到集群相关信息的方法呢?答案是,有但不完全有。其实可以利用 tidb 的 Prometheus 来获取集群相关的各项数据,比如告警就是一个很好的例子。可惜了,告警只是获取了当前数据进行告警判断,而巡检需要使用一段时间的数据来作为判断的依据。而且,告警是已经达到临界值了,巡检却是要排查集群的隐患,提前开始规划,避免出现异常。
那直接用 Prometheus 获取一段时间的数据,并且把告警值改低不就行了?
认识 PromQL
要使用 Prometheus ,那必须要先了解什么是 PromQL 。
PromQL 查询语言和日常使用的数据库 SQL 查询语言(SELECT * FROM ...)是不同的,PromQL 是一 种 嵌套的函数式语言 ,就是我们要把需 要查找的数据描述成一组嵌套的表达式,每个表达式都会评估为一个中间值,每个中间值都会被用作它上层表达式中的参数,而查询的最外层表达式表示你可以在表格、图形中看到的最终返回值。比如下面的查询语句:
histogram_quantile( # 查询的根,最终结果表示一个近似分位数。0.9, # histogram_quantile() 的第一个参数,分位数的目标值# histogram_quantile() 的第二个参数,聚合的直方图sum by(le, method, path) (# sum() 的参数,直方图过去5分钟每秒增量。rate(# rate() 的参数,过去5分钟的原始直方图序列demo_api_request_duration_seconds_bucket{job="demo"}[5m]))
)然后还需要认识一下告警的 PromQL 中,经常出现的一些函数:
rate
用于计算变化率的最常见 函数是 rate() , rate() 函数用于计算在指定时间范围内计数器平均每秒的增加量。因为是计算一个时间范围内的平均值,所以我们需要在序列选择器之后添加一个范围选择器。
irate
由于使用 rate 或者 increase 函数去计算样本的平均增长速率,容易陷入长尾问题当中,其无法反应在时间窗口内样本数据的突发变化。
例如,对于主机而言在 2 分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致 CPU 占用 100%的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
为了解决该问题,PromQL 提供了另外一个灵敏度更高 的函数 irate(v range-vector) 。 irate 同样用于计算区间向量的计算率,但是其 反应出的是瞬时增长率。
histogram_quantile
获取数据的分位数。histogram_quantile(φ scalar, b instant-vector) 函数用于计算历史数据指标一段时间内的分位数。该函数将目标分位数 (0 ≤ φ ≤ 1) 和直方图指标作为输入,就是大家平时讲的 pxx,p50 就是中位数,参数 b 一定是包含 le 这个标签的瞬时向量,不包含就无从计算分位数了,但是计算的分位数是一个预估值,并不完全准确,因为这个函数是假定每个区间内的样本分布是线性分布来计算结果值的,预估的准确度取决于 bucket 区间划分的粒度,粒度越大,准确度越低。
该部分引用: Prometheus 基础相关--PromQL 基础(2) ( Prometheus基础相关--PromQL 基础(2) - 知乎 ) 想学习的同学可以去看看原文
修改 PromQL
要让巡检使用 PromQL ,就必须要修改告警中的 PromQL。这里需要介绍一个函数:max_over_time(range-vector),它是获取区间向量内每个指标的最大值。其实还有其他这类时间聚合函数,比如 avg_over_time、min_over_time、sum_over_time 等等,但是我们只需要获取到最大值,来提醒 dba 就行了。
Prometheus 是支持子查询的,它允许我们首先以指定的步长在一段时间内执行内部查询,然后根据子查询的结果计算外部查询。子查询的表示方式类似于区间向量的持续时间,但需要冒号后添加了一个额外的步长参数: [:]。
举个例子:
# 原版
sum(rate(tikv_thread_cpu_seconds_total{name=~"(raftstore|rs)_.*"}[1m])) by (instance)
# 修改
max_over_time(avg(rate(tikv_thread_cpu_seconds_total{name=~"(raftstore|rs)_.*"}[1m])) by (instance)[24h:1m])这是获取 TiKV raftstore 线程池 CPU 使用率的告警项。原版是直接将 1 分钟内所有线程的变化率相加,而笔者的修改版是将 1 分钟内所有线程的使用率取平均值,并且从此刻向后倒 24 小时内,每一分钟执行一次获取平均线程使用率的查询,再取最大值。
也就是说,从 24 小时前,到现在,每分钟执行一次(步长为 1 分钟): avg(rate(tikv_thread_cpu_seconds_total{name=~"(raftstore|rs)_.*"}[1m])) by (instance) ,并获取其中最大的一次值。这样就满足了我们需要使用一段时间的数据来判断集群是否有风险的依据了。
然后我们可以选取合适的 PromQL 来加上时间聚合函数和查询时间及步长信息:
# TiKV 1
'TiDB.tikv.TiKV_server_is_down': {'pql': 'probe_success{group="tikv",instance=~".*"} == 0','pql_max': '','note': 'TiKV 服务不可用'
},
'TiDB.tikv.TiKV_node_restart': {'pql': 'changes(process_start_time_seconds{job="tikv",instance=~".*"}[24h])> 0','pql_max': 'max(changes(process_start_time_seconds{job="tikv",instance=~".*"}[24h]))','note': 'TiKV 服务5分钟内出现重启'
},
'TiDB.tikv.TiKV_GC_can_not_work': {'pql_max': '','pql': 'sum(increase(tikv_gcworker_gc_tasks_vec{task="gc", instance=~".*"}[2d])) by (instance) < 1 and (sum(increase(''tikv_gc_compaction_filter_perform{instance=~".*"}[2d])) by (instance) < 1 and sum(increase(''tikv_engine_event_total{cf="write",db="kv",type="compaction",instance=~".*"}[2d])) by (instance) >= 1)','note': 'TiKV 服务GC无法工作'
},
# TiKV 2
'TiDB.tikv.TiKV_raftstore_thread_cpu_seconds_total': {'pql_max': 'max_over_time(avg(rate(tikv_thread_cpu_seconds_total{name=~"(raftstore|rs)_.*"}[1m])) by (instance)[24h:1m])','pql': 'max_over_time(avg(rate(tikv_thread_cpu_seconds_total{name=~"(raftstore|rs)_.*"}[1m])) by (instance)[24h:1m]) > 0.8','note': 'TiKV raftstore 线程池 CPU 使用率过高'
},
'TiDB.tikv.TiKV_approximate_region_size': {'pql_max': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_raftstore_region_size_bucket{instance=~".*"}[1m])) ''by (le,instance))[24h:1m])','pql': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_raftstore_region_size_bucket{instance=~".*"}[1m])) ''by (le,instance))[24h:1m]) > 1073741824','note': 'TiKV split checker 扫描到的最大的 Region approximate size 大于 1 GB'
},
'TiDB.tikv.TiKV_async_request_write_duration_seconds': {'pql_max': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_storage_engine_async_request_duration_seconds_bucket''{type="write", instance=~".*"}[1m])) by (le, instance, type))[24h:1m])','pql': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_storage_engine_async_request_duration_seconds_bucket''{type="write", instance=~".*"}[1m])) by (le, instance, type))[24h:1m]) > 1','note': 'TiKV 中Raft写入响应时间过长'
},
'TiDB.tikv.TiKV_scheduler_command_duration_seconds': {'pql_max': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_scheduler_command_duration_seconds_bucket[20m])) by (le, instance, type) / 1000)[24h:20m]) ','pql': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_scheduler_command_duration_seconds_bucket[20m])) by (le, instance, type) / 1000)[24h:20m]) > 20 ','note': 'TiKV 调度器请求响应时间过长'
},
'TiDB.tikv.TiKV_scheduler_latch_wait_duration_seconds': {'pql_max': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_scheduler_latch_wait_duration_seconds_bucket[20m])) by (le, instance, type))[24h:20m]) ','pql': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_scheduler_latch_wait_duration_seconds_bucket[20m])) by (le, instance, type))[24h:20m]) > 20','note': 'TiKV 调度器锁等待响应时间过长'
},
'TiDB.tikv.TiKV_write_stall': {'pql_max': 'max_over_time(delta(tikv_engine_write_stall{instance=~".*"}[10m])[24h:10m])','pql': 'max_over_time(delta(''tikv_engine_write_stall{instance=~".*"}[10m])[24h:10m]) > 10','note': 'TiKV 中存在写入积压'
},
# TiKV 3
'TiDB.tikv.TiKV_server_report_failure_msg_total': {'pql_max': 'max_over_time(sum(rate(tikv_server_report_failure_msg_total{type="unreachable"}[10m])) BY (instance)[24h:10m])','pql': 'max_over_time(sum(rate(tikv_server_report_failure_msg_total{type="unreachable"}[10m])) BY (instance)[24h:10m]) > 10','note': 'TiKV 节点报告失败次数过多'
},
'TiDB.tikv.TiKV_channel_full_total': {'pql_max': 'max_over_time(sum(rate(tikv_channel_full_total{instance=~".*"}[10m])) BY (type, instance)[24h:10m])','pql': 'max_over_time(sum(rate(tikv_channel_full_total{instance=~".*"}[10m])) BY (type, instance)[24h:10m]) > 0','note': 'TIKV 通道已占满 tikv 过忙'
},
'TiDB.tikv.TiKV_raft_log_lag': {'pql_max': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_raftstore_log_lag_bucket{instance=~".*"}[1m])) by (le,instance))[24h:10m])','pql': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_raftstore_log_lag_bucket{instance=~".*"}[1m])) by (le, ''instance))[24h:10m]) > 5000','note': 'TiKV 中 raft 日志同步相差过大'
},
'TiDB.tikv.TiKV_thread_unified_readpool_cpu_seconds': {'pql_max': 'max_over_time(avg(rate(tikv_thread_cpu_seconds_total{name=~"unified_read_po*", instance=~".*"}[1m])) by (instance)[24h:1m])','pql': 'max_over_time(avg(rate(tikv_thread_cpu_seconds_total{name=~"unified_read_po*", instance=~".*"}[1m])) ''by (instance)[24h:1m]) > 0.7','note': 'unifiled read 线程池使用率大于70%'
},
'TiDB.tikv.TiKV_low_space': {'pql_max': 'sum(tikv_store_size_bytes{type="available"}) by (instance) / sum(tikv_store_size_bytes{type="capacity"}) by (instance)','pql': 'sum(tikv_store_size_bytes{type="available"}) by (instance) / sum(tikv_store_size_bytes{type="capacity"}) by (instance) < 0.3','note': 'TiKV 当前存储可用空间小于阈值'
},由于有的告警项是获取了 5 分钟或者 10 分钟的数据,在写步长的时候也要同步修改为 5 分钟或者 10 分钟,保持一致可以保证,检查能覆盖选定的全部时间段,并且不会重复计算造成资源浪费。
顺带一提,如果不加 max_over_time 可以获取到带有时间戳的全部数据,而不是只获取到最大的一个数据。这个带时间戳的全部数据可以方便画图,像 grafana 那样展示数据趋势。
巡检脚本
了解了以上所有知识,我们就可以开始编写巡检脚本了。
这是笔者和同事共同编写的一部分巡检脚本,最重要的是 tasks 中的 PromQL ,在脚本执行之前要写好 PromQL,其他部分可以随意更改。如果一次性巡检天数太多,比如一次巡检一个月的时间,Prometheus 可能会因检查数据太多而报错的,所以使用的时候要注意报错信息,避免漏掉一些巡检项。
# -*- coding: utf-8 -*-
import subprocess
import re
import datetime
import requests
import sys
import pandas as pd
days = None
def get_cluster_name():try:command = "tiup cluster list"result = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)output, error = result.communicate()cluster_name_match = re.search(r'([a-zA-Z0-9_-]+)\s+tidb\s+v', output.decode('utf-8'))if cluster_name_match:return cluster_name_match.group(1)else:return Noneexcept Exception as e:print("An error occurred:", e)return None
def display_cluster_info(cluster_name):if not cluster_name:print("Cluster name not found.")return
try:command = "tiup cluster display {0}".format(cluster_name)result = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)output, error = result.communicate()return output.decode('utf-8')except Exception as e:print("An error occurred:", e)
def extract_id_role(output):id_role_dict = {}lines = output.strip().split("\n")for line in lines:print(line)parts = line.split()if is_valid_ip_port(parts[0]):node_id, role = parts[0], parts[1]id_role_dict[node_id] = rolereturn id_role_dict
def is_valid_ip_port(input_str):pattern = re.compile(r'^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}:\d{1,5}$')return bool(pattern.match(input_str))
def get_prometheus_ip(data_dict):prometheus_ip = Nonefor key, value in data_dict.items():if value == 'prometheus':prometheus_ip = keybreakreturn prometheus_ip
def get_tasks():global daystasks = {# TiKV 1'TiDB.tikv.TiKV_server_is_down': {'pql': 'probe_success{group="tikv",instance=~".*"} == 0','pql_max': '','note': 'TiKV 服务不可用'},'TiDB.tikv.TiKV_node_restart': {'pql': 'changes(process_start_time_seconds{job="tikv",instance=~".*"}[24h])> 0','pql_max': 'max(changes(process_start_time_seconds{job="tikv",instance=~".*"}[24h]))','note': 'TiKV 服务5分钟内出现重启'},'TiDB.tikv.TiKV_GC_can_not_work': {'pql_max': '','pql': 'sum(increase(tikv_gcworker_gc_tasks_vec{task="gc", instance=~".*"}[2d])) by (instance) < 1 and (sum(increase(''tikv_gc_compaction_filter_perform{instance=~".*"}[2d])) by (instance) < 1 and sum(increase(''tikv_engine_event_total{cf="write",db="kv",type="compaction",instance=~".*"}[2d])) by (instance) >= 1)','note': 'TiKV 服务GC无法工作'},# TiKV 2'TiDB.tikv.TiKV_raftstore_thread_cpu_seconds_total': {'pql_max': 'max_over_time(avg(rate(tikv_thread_cpu_seconds_total{name=~"(raftstore|rs)_.*"}[1m])) by (instance)[24h:1m])','pql': 'max_over_time(avg(rate(tikv_thread_cpu_seconds_total{name=~"(raftstore|rs)_.*"}[1m])) by (instance)[24h:1m]) > 0.8','note': 'TiKV raftstore 线程池 CPU 使用率过高'},'TiDB.tikv.TiKV_approximate_region_size': {'pql_max': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_raftstore_region_size_bucket{instance=~".*"}[1m])) ''by (le,instance))[24h:1m])','pql': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_raftstore_region_size_bucket{instance=~".*"}[1m])) ''by (le,instance))[24h:1m]) > 1073741824','note': 'TiKV split checker 扫描到的最大的 Region approximate size 大于 1 GB'},'TiDB.tikv.TiKV_async_request_write_duration_seconds': {'pql_max': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_storage_engine_async_request_duration_seconds_bucket''{type="write", instance=~".*"}[1m])) by (le, instance, type))[24h:1m])','pql': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_storage_engine_async_request_duration_seconds_bucket''{type="write", instance=~".*"}[1m])) by (le, instance, type))[24h:1m]) > 1','note': 'TiKV 中Raft写入响应时间过长'},'TiDB.tikv.TiKV_write_stall': {'pql_max': 'max_over_time(delta(tikv_engine_write_stall{instance=~".*"}[10m])[24h:10m])','pql': 'max_over_time(delta(''tikv_engine_write_stall{instance=~".*"}[10m])[24h:10m]) > 10','note': 'TiKV 中存在写入积压'},
# TiKV 3'TiDB.tikv.TiKV_server_report_failure_msg_total': {'pql_max': 'max_over_time(sum(rate(tikv_server_report_failure_msg_total{type="unreachable"}[10m])) BY (instance)[24h:10m])','pql': 'max_over_time(sum(rate(tikv_server_report_failure_msg_total{type="unreachable"}[10m])) BY (instance)[24h:10m]) > 10','note': 'TiKV 节点报告失败次数过多'},'TiDB.tikv.TiKV_channel_full_total': {'pql_max': 'max_over_time(sum(rate(tikv_channel_full_total{instance=~".*"}[10m])) BY (type, instance)[24h:10m])','pql': 'max_over_time(sum(rate(tikv_channel_full_total{instance=~".*"}[10m])) BY (type, instance)[24h:10m]) > 0','note': 'TIKV 通道已占满 tikv 过忙'},'TiDB.tikv.TiKV_raft_log_lag': {'pql_max': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_raftstore_log_lag_bucket{instance=~".*"}[1m])) by (le,instance))[24h:10m])','pql': 'max_over_time(histogram_quantile(0.99, sum(rate(tikv_raftstore_log_lag_bucket{instance=~".*"}[1m])) by (le, ''instance))[24h:10m]) > 5000','note': 'TiKV 中 raft 日志同步相差过大'},'TiDB.tikv.TiKV_thread_unified_readpool_cpu_seconds': {'pql_max': 'max_over_time(avg(rate(tikv_thread_cpu_seconds_total{name=~"unified_read_po*", instance=~".*"}[1m])) by (instance)[24h:1m])','pql': 'max_over_time(avg(rate(tikv_thread_cpu_seconds_total{name=~"unified_read_po*", instance=~".*"}[1m])) ''by (instance)[24h:1m]) > 0.7','note': 'unifiled read 线程池使用率大于70%'},'TiDB.tikv.TiKV_low_space': {'pql_max': 'sum(tikv_store_size_bytes{type="available"}) by (instance) / sum(tikv_store_size_bytes{type="capacity"}) by (instance)','pql': 'sum(tikv_store_size_bytes{type="available"}) by (instance) / sum(tikv_store_size_bytes{type="capacity"}) by (instance) < 0.3','note': 'TiKV 当前存储可用空间小于阈值'},}for key, value in tasks.items():for inner_key, inner_value in value.items():if isinstance(inner_value, str) and 'pql' in inner_key:value[inner_key] = inner_value.replace("24h:", f"{24 * days}h:").replace("[24h]", f"[{24 * days}h]")return tasks
def request_prome(prometheus_address, query):try:response = requests.get('http://%s/api/v1/query' % prometheus_address, params={'query': query})return responseexcept:return None
def has_response(prometheus_address, query):response = request_prome(prometheus_address, query)if not response:return Falsetry:if response.json()["data"]['result']:return Trueelse:return Falseexcept:return False
def check_prome_alive(prometheus_address):# dummy query is used to judge if prometheus is alivedummy_query = 'probe_success{}'return has_response(prometheus_address, dummy_query)
def find_alive_prome(prometheus_addresses):if check_prome_alive(prometheus_addresses):return prometheus_addressesreturn None
# ip:port -> ip_port
def decode_instance(instance):return instance.replace(':', '_')
def check_metric(alert_name, prometheus_address, pql, is_value, pql_max):record = []try:is_warning = "异常"response = request_prome(prometheus_address, pql)alert_name = alert_name.split('.')result = response.json()['data']['result']
# 判断是否出现异常if len(result) == 0:is_warning = "正常"if pql_max == '':result = [{'metric': {}, 'value': [0, '0']}]else:response = request_prome(prometheus_address, pql_max)result = response.json()['data']['result']
for i in result:# 判断是否按节点显示if 'instance' in i['metric']:instance = i['metric']['instance']node = decode_instance(instance)else:node = '集群'# 判断是否有typeif 'type' in i['metric']:type = i['metric']['type']else:type = '无类型'value = i['value'][1]
if value == 'NaN':value = 0else:value = round(float(value), 3)message = "%s,%s,%s,%s,%s,%s,%s,%s" % (datetime.datetime.now(), node, alert_name[1], alert_name[2], type, is_warning, is_value, value)print(message)record.append(message)except Exception as e:print(alert_name[2] + "----An error occurred check_metric:", e)returnreturn record
def csv_report(record):data = pd.DataFrame([line.split(',') for line in record],columns=['timestamp', 'ip_address', 'service', 'event_type', 'type', 'status', 'description','value'])grouped = data.groupby("service")writer = pd.ExcelWriter("inspection_report.xlsx", engine="xlsxwriter")for name, group in grouped:group.to_excel(writer, sheet_name=name, index=False)worksheet = writer.sheets[name]for i, col in enumerate(group.columns):column_len = max(group[col].astype(str).str.len().max(), len(col)) + 2worksheet.set_column(i, i, column_len)writer.save()
def run_tasks(role_metrics, prometheus_address):record = []for alert in role_metrics:pql = role_metrics[alert]['pql']is_value = role_metrics[alert]['note']pql_max = role_metrics[alert]['pql_max']message = check_metric(alert, prometheus_address, pql, is_value, pql_max)for data in message:record.append(data)csv_report(record)
def run_script(prometheus_addresses):active_prometheus_address = find_alive_prome(prometheus_addresses)
# check if all prometheus are downif not active_prometheus_address:sys.exit()tasks = get_tasks()run_tasks(tasks, active_prometheus_address)
def get_user_input():global daystry:user_input = int(input("请输入需要巡检的天数: "))days = user_inputexcept ValueError:print("输入无效,请输入一个有效的数字。")
if __name__ == "__main__":# 输入巡检天数get_user_input()
prometheus_ip = '10.3.65.136:9091'# prometheus_ip = Noneif prometheus_ip is None:cluster_name = get_cluster_name()cluster_info = display_cluster_info(cluster_name)id_role_dict = extract_id_role(cluster_info)print(id_role_dict)prometheus_ip = get_prometheus_ip(id_role_dict)print(prometheus_ip)run_script(prometheus_ip)总结
一个完善的巡检脚本的编写是一个长期的工作。因为时间有限,笔者只编写了基于 Prometheus 的一部分巡检项,有兴趣的同学可以继续编写更多巡检项。
目前巡检脚本都是基于 Prometheus 的数据来作判断,但是在真实的巡检当中,dba 还会查看一些 Prometheus 没有的数据,比如表的健康度、一段时间内的慢 SQL、热力图、日志信息等等,这些信息在后面一些时间,可能会慢慢入到巡检脚本中。
现在该脚本已在 Gitee 上开源,欢迎大家使用:https://gitee.com/mystery-cyf/prometheus--for-inspection/tree/master
相关文章:
)
通过 Prometheus 编写 TiDB 巡检脚本(脚本已开源,内附链接)
作者丨 caiyfc 来自神州数码钛合金战队 神州数码钛合金战队是一支致力于为企业提供分布式数据库 TiDB 整体解决方案的专业技术团队。团队成员拥有丰富的数据库从业背景,全部拥有 TiDB 高级资格证书,并活跃于 TiDB 开源社区,是官方认证合作伙…...

sql语句学习(一)--查询
【有道云笔记】基本sql语句2—查询基础 数据库表结构 DROP TABLE IF EXISTS class; CREATE TABLE class (id int(11) NOT NULL AUTO_INCREMENT,class_num varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT 班级号,class_name varchar(255) CHARACTE…...

【HTML】交友软件上照片的遮罩是如何做的
笑谈 我不知道大家有没有在夜深人静的时候感受到孤苦难耐,🐶。于是就去下了一些交友软件来排遣寂寞。可惜的是,有些交友软件真不够意思,连一些漂亮小姐姐的图片都要进行遮罩,完全不考虑兄弟们的感受,😠。所…...
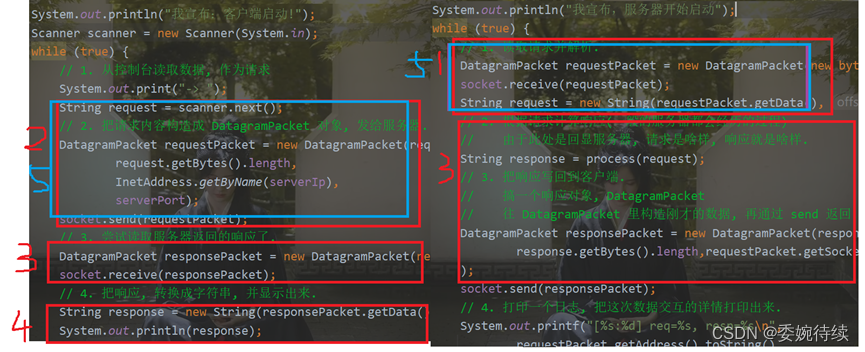
【Java EE初阶十二】网络编程TCP/IP协议(一)
1. 网络编程 通过网络,让两个主机之间能够进行通信->就这样的通信来完成一定的功能,进行网络编程的时候,需要操作系统给咱们提供一组API,通过这些API来完成编程;API可以认为是应用层和传输层之间交互的路径…...

element-ui解决上传文件时需要携带请求数据的问题
一、问题描述 在前端使用element-ui进行文件上传时,需要携带请求头信息,比如Token。 二、问题解决 1. 表单实现 action置空添加:http-request属性覆盖默认的上传行为,实现自定义上传文件。注意:src后的图片路径如果是个网络请求(外链)&…...

【AI视野·今日NLP 自然语言处理论文速览 第七十九期】Thu, 18 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 18 Jan 2024 Totally 35 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics …...

Docker容器运行
1、通过--name参数显示地为容器命名,例如:docker run --name “my_http_server” -d httpd 2、容器重命名可以使用docker rename。 3、两种进入容器的方法: 3.1、Docker attach 例如: 每间隔一秒打印”Hello World”。 Sudo docker run…...

【计算机网络】网络层之IP协议
文章目录 1.基本概念2.协议头格式3.网段划分4.特殊的IP地址5.IP地址的数量限制6.私有IP地址和公网IP地址7.路由 1.基本概念 IP地址是定位主机的,具有一个将数据报从A主机跨网络可靠的送到B主机的能力。 但是有能力就一定能做到吗,只能说有很大的概率。…...
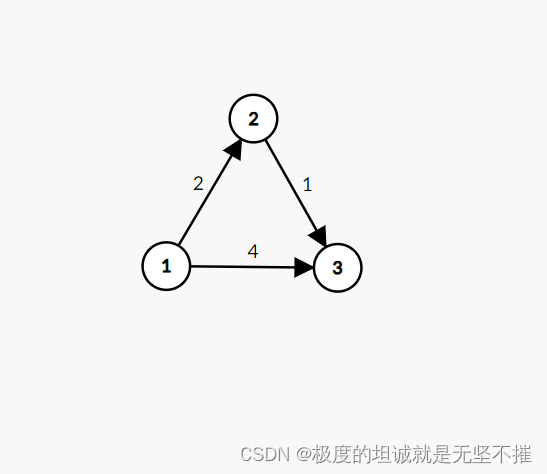
2024/2/17 图论 最短路入门 dijkstra 1
目录 算法思路 Dijkstra求最短路 AcWing 849. Dijkstra求最短路 I - AcWing 850. Dijkstra求最短路 II - AcWing题库 最短路 最短路 - HDU 2544 - Virtual Judge (vjudge.net) 【模板】单源最短路径(弱化版) P3371 【模板】单源最短路径…...

交通管理|交通管理在线服务系统|基于Springboot的交通管理系统设计与实现(源码+数据库+文档)
交通管理在线服务系统目录 目录 基于Springboot的交通管理系统设计与实现 一、前言 二、系统功能设计 三、系统实现 1、用户信息管理 2、驾驶证业务管理 3、机动车业务管理 4、机动车业务类型管理 四、数据库设计 1、实体ER图 五、核心代码 六、论文参考 七、最新计…...

最适合初学者的Python入门详细攻略,一文讲清,赶紧收藏!
前言 目前python可以说是一门非常火爆的编程语言,应用范围也非常的广泛,工资也挺高,未来发展也极好。 Python究竟应该怎么学呢,我自己最初也是从零基础开始学习Python的,给大家分享Python的学习思路和方法。一味的买…...

幻兽帕鲁新手游戏攻略分享
在幻兽帕鲁中,提高实力是玩家不断追求的目标。以下是一些提高实力的攻略: 1、升级和进化:通过战斗和完成任务,玩家可以获得经验值,提升自己的等级。随着等级的提升,玩家可以获得技能点,用于提升…...
代码随想录算法训练营DAY19 | 二叉树 (6)
一、LeetCode 654 最大二叉树 题目链接:654.最大二叉树https://leetcode.cn/problems/maximum-binary-tree/ 思路:坚持左开右闭原则,递归划分数组元素生成左右子树。 class Solution {public TreeNode constructMaximumBinaryTree(int[] num…...

【C++】实现Date类的各种运算符重载
上一篇文章只实现了operator操作符重载,由于运算符较多,该篇文章单独实现剩余所有的运算符重载。继续以Date类为例,实现运算符重载: 1.Date.h #pragma once#include <iostream> #include <assert.h>using namespace …...
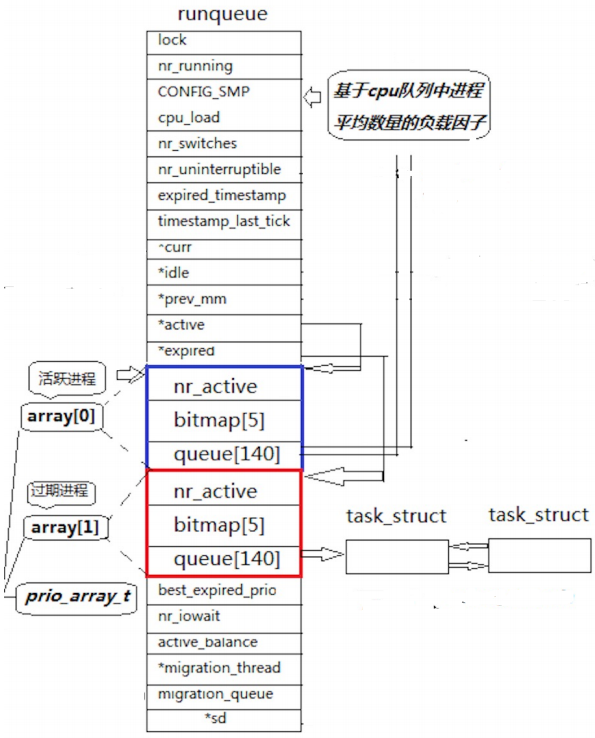
【Linux】程序地址空间 -- 详解 Linux 2.6 内核进程调度队列 -- 了解
一、程序地址空间回顾 在学习 C/C 时,我们知道内存会被分为几个区域:栈区、堆区、全局/静态区、代码区、字符常量区等。但这仅仅是在语言层面上的理解,是远远不够的。 如下空间布局图,请问这是物理内存吗? 不是&…...

10-通用类型、特质和生命周期
上一篇: 09-错误处理 每种编程语言都有有效处理概念重复的工具。在 Rust 中,泛型就是这样一种工具:具体类型或其他属性的抽象替身。我们可以表达泛型的行为或它们与其他泛型的关系,而不需要知道在编译和运行代码时它们的位置。 函…...
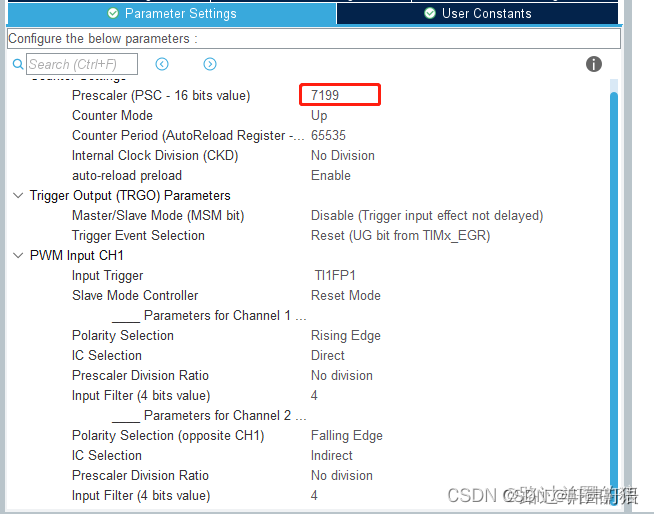
STM32CubeMX,定时器之定时功能,入门学习,如何设置prescaler,以及timer计算PWM输入捕获方法(重要)
频率变小,周期变长 1,参考链接(重要) STM32CubeMX——定时器之定时功能(学习使用timer定时器的设置) STM32测量PWM信息(学习使用设置pwm输入捕获) 通用定时器中两个重要参数的设置心…...

蓝桥杯:C++队列、优先队列、链表
C普通队列 算法竞赛中一般用静态数组来模拟队列,或者使用STL queue。使用C的STL queue时,由于不用自己管理队列,因此代码很简洁。队列的部分操作如下。 C优先队列 很多算法需要用到一种特殊的队列:优先队列。它的特点是最优数据…...

【C语言】长篇详解,字符系列篇1-----“混杂”的各种字符类型字符转换和strlen的模拟实现【图文详解】
欢迎来CILMY23的博客喔,本期系列为【C语言】长篇详解,字符系列篇1-----“混杂”的各种字符函数……,图文讲解各种字符函数,带大家更深刻理解C语言中各种字符函数的应用,感谢观看,支持的可以给个赞哇。 前言…...

2024年【高处安装、维护、拆除】考试总结及高处安装、维护、拆除考试技巧
题库来源:安全生产模拟考试一点通公众号小程序 高处安装、维护、拆除考试总结根据新高处安装、维护、拆除考试大纲要求,安全生产模拟考试一点通将高处安装、维护、拆除模拟考试试题进行汇编,组成一套高处安装、维护、拆除全真模拟考试试题&a…...

Claude Code 2026 路线图深度拆解:5 大新增能力与企业级项目落地时间表
1. 5 大新增能力不是“功能列表”,而是上下文治理的5个切口 大多数人看到「Claude Code 2026 路线图」的第一反应,是去官网截图那张带箭头和时间轴的PPT——然后立刻开始评估“哪个功能我团队下周就能用上”。我试过。去年Q4我们团队在三个项目里并行接入了路线图中已发布的…...

W5500 TCP客户端实战:从寄存器配置到网络调试助手,一步步打通你的第一个物联网连接
W5500 TCP客户端实战:从寄存器配置到网络调试助手,一步步打通你的第一个物联网连接 在嵌入式物联网开发中,网络通信模块的选择往往决定了项目的稳定性和开发效率。W5500作为一款全硬件TCP/IP协议栈芯片,以其稳定的性能和简单的开发…...

RedisDesktopManager Windows版:5步打造高效Redis数据库管理体验
RedisDesktopManager Windows版:5步打造高效Redis数据库管理体验 【免费下载链接】RedisDesktopManager-Windows RedisDesktopManager Windows版本 项目地址: https://gitcode.com/gh_mirrors/re/RedisDesktopManager-Windows RedisDesktopManager Windows版…...

N_m3u8DL-RE:终极跨平台流媒体下载工具,轻松保存加密视频内容
N_m3u8DL-RE:终极跨平台流媒体下载工具,轻松保存加密视频内容 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/…...
)
别再只用默认模型了!手把手教你用SnowNLP训练专属情感分析模型(附完整代码)
突破SnowNLP默认模型局限:打造高精度领域情感分析系统的实战指南 从"水土不服"到精准预测:为什么你需要自定义情感模型 去年夏天,我们的产品团队在分析用户反馈时遇到了一个诡异现象:明明用户留言中充斥着"卡顿严重…...
百科全书从“深“到“无限深“)
深度神经网络(DNN)百科全书从“深“到“无限深“
一、开篇:深度的奇迹 2012 年 9 月 30 日。 ImageNet 挑战赛的结果在 Florence 公布。所有人都以为冠军会延续过去 3 年的传统——传统计算机视觉方法(SIFT、HOG、SVM)小幅领先。 但那一年,一个叫 AlexNet 的"怪物"出现了。8 层的卷积神经网络,Top-5 错误率 …...

3大核心技术深度解析:cursor-free-vip如何高效破解Cursor AI编辑器限制
3大核心技术深度解析:cursor-free-vip如何高效破解Cursor AI编辑器限制 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve …...

2026年京东云OpenClaw/Hermes Agent配置Token Plan搭建详细指南
2026年京东云OpenClaw/Hermes Agent配置Token Plan搭建详细指南。OpenClaw是开源的个人AI助手,Hermes Agent则是一个能自我进化的AI智能体框架。阿里云提供计算巢、轻量服务器及无影云电脑三种部署OpenClaw 与 Hermes Agent的方案、百炼Token Plan兼容主流 AI 工具&…...

STM32定时器中断配置详解:从时钟树到回调函数,一次搞懂ARR和PSC怎么算
STM32定时器中断配置详解:从时钟树到回调函数,一次搞懂ARR和PSC怎么算 在嵌入式开发中,定时器是最基础也最强大的外设之一。很多开发者虽然能够通过复制代码让定时器工作,但对于如何精确控制定时周期、理解时钟信号的传递路径以及…...

3分钟掌握NCM音乐解密:ncmdump工具让你的音乐随处播放
3分钟掌握NCM音乐解密:ncmdump工具让你的音乐随处播放 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经下载了网易云音乐的NCM格式歌曲,却发现无法在其他设备上播放?这种专有加密格式虽然…...