【Linux】程序地址空间 -- 详解 Linux 2.6 内核进程调度队列 -- 了解
一、程序地址空间回顾
在学习 C/C++ 时,我们知道内存会被分为几个区域:栈区、堆区、全局/静态区、代码区、字符常量区等。但这仅仅是在语言层面上的理解,是远远不够的。
如下空间布局图,请问这是物理内存吗?
不是,下图是进程地址空间。
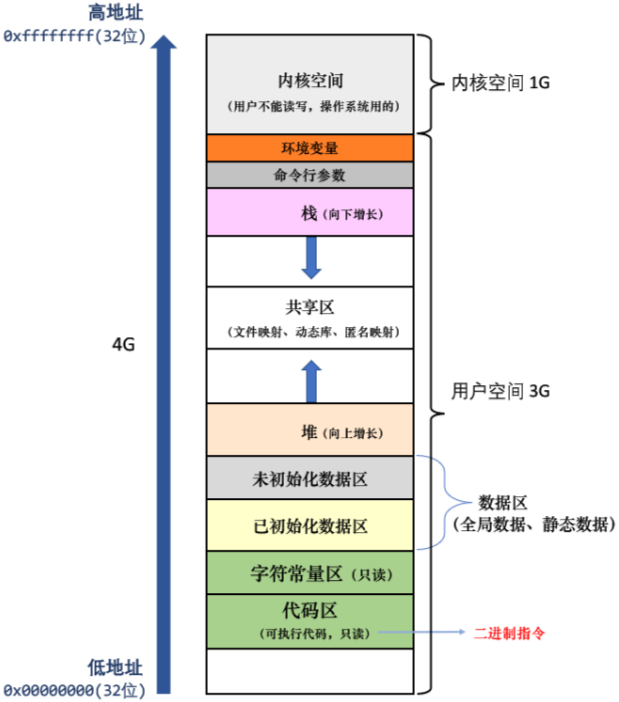
结论:
进程地址空间不是物理内存。
进程地址空间会在进程的整个生命周期内一直存在,直到进程退出。
这也就解释了为什么全局/静态变量的生命周期是整个程序,因为全局/静态变量是随着进程一直存在的
二、验证地址空间的基本排布
// checkarea.c
#include <stdio.h>
#include <stdlib.h> // mallocint g_unval; // 未初始化数据区
int g_val = 10; // 已初始化数据区int main(int argc, char* argv[], char* env[])
{printf("code addr : %p\n", main); // 代码区printf("\n");const char *p = "hello";printf("read only : %p\n", p); // 字符常量区(只读)printf("\n");printf("global val : %p\n", &g_val); // 已初始化数据区printf("global uninit val: %p\n", &g_unval); // 未初始化数据区printf("\n");char *phead = (char*)malloc(1);printf("head addr : %p\n", phead); // 堆区(向上增长)printf("\n");printf("stack addr : %p\n", &p); // 栈区(向下增长)printf("stack addr : %p\n", &phead); // 栈区printf("\n");printf("arguments addr : %p\n", argv[0]); // 命令行参数(第一个参数)printf("arguments addr : %p\n", argv[argc-1]); // 命令行参数(最后一个参数)printf("\n");printf("environ addr : %p\n", env[0]); // 环境变量return 0;
}运行结果:

三、虚拟地址和物理地址
定义一个全局变量 g_val,然后创建子进程,父子进程分别打印出变量值和变量地址。
#include <stdio.h>
#include <sys/types.h> // getpid
#include <unistd.h> // getpid, fork
#include <stdlib.h> // perrorint g_val = 0; // 全局变量int main()
{printf("before creating a new process, g_val = %d\n", g_val);pid_t ret = fork();if (ret == 0){// child processprintf(" child - pid: %u, g_val: %d, &g_val: %p\n", getpid(), g_val, &g_val);}else if (ret > 0){// father processprintf("father - pid: %u, g_val: %d, &g_val: %p\n", getpid(), g_val, &g_val);}else{perror("fork");} return 0;
}运行结果:
before creating a new process, g_val = 0
father - pid: 23014, g_val: 0, &g_val: 0x601058child - pid: 23015, g_val: 0, &g_val: 0x601058通过观察可以发现,父子进程打印的变量值和变量地址是一样的,因为创建子进程通常以父进程为模版,父子进程并没有对变量进行进行任何修改。
如果将代码稍加改动:
#include <stdio.h>
#include <sys/types.h> // getpid
#include <unistd.h> // getpid, fork, sleep
#include <stdlib.h> // perrorint g_val = 0; // 全局变量int main()
{printf("before creating a new process, g_val = %d\n", g_val);pid_t ret = fork();if (ret == 0){// child processg_val = 100; // 在子进程中对变量进行修改printf(" child - pid: %u, g_val: %-3d, &g_val: %p\n", getpid(), g_val, &g_val);}else if (ret > 0){// father processsleep(3); // 父进程休眠,子进程一定会先退出,让父进程读取变量值和变量地址printf("father - pid: %u, g_val: %-3d, &g_val: %p\n", getpid(), g_val, &g_val);}else{perror("fork");} return 0;
}运行结果:
before creating a new process, g_val = 0child - pid: 25270, g_val: 100, &g_val: 0x601058 # 子进程先退出
father - pid: 25269, g_val: 0 , &g_val: 0x601058 # 父进程休眠3s后退出子进程肯定先跑完,也就是子进程先修改,完成之后,父进程再读取。
可以发现:父子进程打印的变量值是不一样的,但变量地址是一样的。
父子进程代码共享,数据各自私有一份(写时拷贝)。
- 变量内容不一样,说明父子进程中的变量绝对不是同一个变量。
- 打印的变量地址值是一样的,说明绝对不是物理地址。因为在同一物理地址处,不可能读取出两个不同的值。
- 我们曾经在 C/C++ 语言或其它语言中学到或看到的地址(比如:取地址),全都是虚拟地址,而物理地址,用户是一概看不到的,由操作系统统一管理。
- OS 必须负责将虚拟地址转化成物理地址 。
注意:程序的代码和数据一定是存在物理内存上的。
因为想要运行程序就必须先将代码和数据加载到物理内存中,所以需要操作系统负责将虚拟地址转化成物理地址。

上图说明:同一个变量打印的地址相同,其实是虚拟地址相同,而内容不同,其实是被映射到了不同的物理地址处。
四、理解地址空间
1、举例
假设有一个富豪,他有 10 亿美元的家产,而他有 3 个私生子,但这 3 个私生子彼此之间并不知道对方的存在。这个富豪对他的每个私生子都说过同一句话:“儿子,这 10 亿的家产未来都是你的”。站在每个私生子的视角来看,每个私生子都认为自己可以拥有 10 亿美元。
如果每个私生子都找父亲一次性要 10 个亿,那么这个富豪是拿不出来的。但实际上这是不可能的,每个私生子找父亲要钱,一般只会几千几万这样一点点去要,那么这个富豪只要有,就一定会给。而如果私生子要的钱太多,富豪不给,私生子也只会认为是父亲不想给。换而言之,这个富豪给每个私生子在大脑中建立一个虚拟的概念:都认为自己拥有 10 亿美元。
类比到计算机中:
- 富豪 —— 操作系统
- 私生子 —— 进程
- 富豪给私生子画的 10 亿家产的饼 —— 进程的地址空间
通过上述例子,可以得出结论:
- 操作系统默认会给每个进程构建一个地址空间的概念(比如在 32 位下,把物理内存资源抽象成了从 0x00000000 ~ 0xFFFFFFFF 共 4G 的一个线性的虚拟地址空间)
- 假设系统中有 10 个进程,每个进程都会认为自己有 4G 的物理内存资源。(这里可以理解成 OS 在画大饼)
2、认识地址空间
- 在 Linux 中,地址空间其实是内核中的一种数据结构。
- 在 Linux 中,OS 除了会为每个进程创建对应的 PCB(即 struct task_struct 结构体),还会创建对应的进程地址空间,即内核中的 struct mm_struct 结构体。
空间的本质无非就是多个区域(栈、堆…)的集合。
那么在 struct mm_struct 结构体中,OS 是如何表述(划分)这些区域的呢?
定义 start 和 end 变量来表示每个区域起始和结束的虚拟地址。然后通过设置这些 start 和 end 的值,对抽象出的这个线性的虚拟地址空间(在 32 位下,是从 0x00000000 ~ 0xFFFFFFFF 共 4G)进行区域划分。
struct mm_struct {// ...unsigned long code_start; // 代码区起始虚拟地址,比如 0x10000000hunsigned long code_end; // 代码区结束虚拟地址,比如 0x00001111hunsigned long init_start; // 已初始化数据区unsigned long init_end;unsigned long uninit_start; // 未初始化数据区unsigned long uninit_end;unsigned long heap_start; // 堆区unsigned long heap_end;// ...
};3、什么是地址空间
进程地址空间:
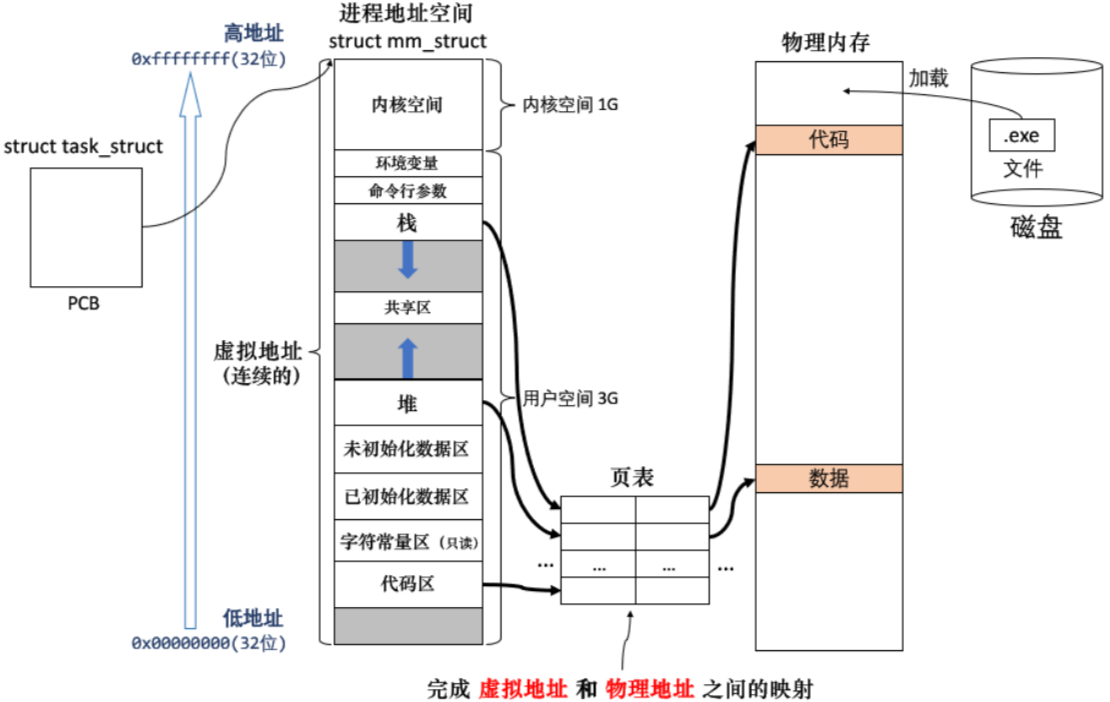
地址空间究竟是什么?
地址空间的本质:操作系统让进程看待物理内存的方式,这是抽象出来的一个概念。地址空间是内核中的一种数据结构,即 struct mm_struct 结构体。由 OS 给每个进程创建,这样每个进程都认为自己独占系统内存资源。
划分区域的本质:把线性的地址空间划分成了一个个的区域,通过设置结构体内的 start 和 end 的值来表示区域的起始和结束。(比如栈区和堆区的增长)
为什么要进行区域划分呢?
- 可以通过 [start, end] 进行初步判断访问某个虚拟地址时,是否越界访问了。
- 因为可执行程序在磁盘中是被划分成一个个的区域存储起来的,所以进程的地址空间才有了区域划分这样的概念,方便进程找到代码和数据。
- 虚拟地址的本质:每个区域 [start, end] 之间的各个地址就是虚拟地址,之间的虚拟地址是连续的。
五、地址空间和物理内存之间的关系
虚拟地址和物理地址之间是通过页表来完成映射的。
六、存在地址空间的原因
直接让进程去访问物理内存不行吗?
- 早期,操作系统是没有进程地址空间的,这就导致物理内存暴露,恶意程序可以直接通过物理地址来进行内存数据的读取,甚至篡改。
- 后来,随着操作系统的发展迭代,有了进程地址空间(虚拟地址),由操作系统完成虚拟地址和物理地址之间的转化。
为什么还要存在地址空间呢?
(1)有效的保护物理内存。
因为地址空间和页表是 OS 创建并维护的,也就意味着凡是想使用地址空间和页表进行映射,也就一定要在 OS 的监督之下来进行访问,也保护了物理内存中的所有合法数据,包括各个进程,以及内核的相关有效数据。
在进程内不能非法访问或映射,因为 OS 会进行合法性检测,如果非法则终止进程。
- 通过划分区域中虚拟地址的起始和结束(即 start 和 end 的值)来判断当前访问的地址是否合法。
比如:如果用户想在某个虚拟地址处写入,但检测到该虚拟地址在字符常量区的 start 到 end 之间,而字符常量区是只读的,说明非法越界访问了,OS 会直接终止进程。
char *str = "hello world"; *str = 'H'; // error
- 通过页表中的权限属性,来判断当前访问的地址是否合法。页表完成了虚拟地址到物理地址之间的映射,而页表中除了有基本的映射关系之外,还可以进行读写等权限相关的管理。
比如:如果用户想在某个虚拟地址处写入,通过页表进行虚拟地址到物理地址的转换时,发现该地址处只有读权限,说明非法访问了,页表拒绝转换,OS 直接终止进程。
(2)将内存管理模块和进程管理模块在系统层面上进行解耦合。
操作系统的核心功能:内存管理、进程管理、文件管理、驱动管理。
- 没有进程地址空间时,内存管理必须得知道所有的进程的生命状态(创建、退出等)才能为每个进程分配和释放相关内存资源。所以内存管理模块和进程管理模块是强耦合的。
- 而现在有了进程地址空间,内存管理只需要知道哪些内存区域(page)是被页表映射的(已使用),哪些是没有被页表映射的(未使用),不需要知道每个进程的生命状态。当进程管理想要申请内存资源时,让内存管理通过页表建立映射即可;想要释放内存资源时,通过页表取消映射即可。解耦的本质也就是减少模块与模块之间的关联性,所以就是将内存管理模块和进程管理模块进行解耦了。
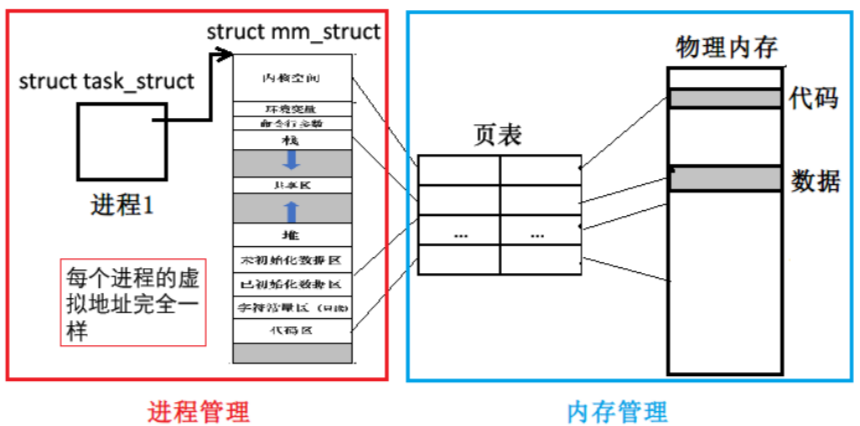
在物理内存中,是否可以对未来的数据进行任意位置的加载?
可以。
物理内存的分配可以和进程的管理做到没有关系。
在 C/C++ 语言上 new/malloc 出一块新的空间时,本质是在哪里申请空间的呢?
虚拟地址空间。
如果申请了空间,但不立马使用这块空间, 是不是对空间造成了浪费呢?
是的。
所以本质上,(因为有地址空间的存在,所以上层申请空间,缺页中断:其实是在地址空间上申请的,物理内存可以甚至一个字节都不给。而当我们真正进行对物理地址空间访问时,才执行内存的相关管理算法来申请内存,构建页表映射关系)然后再进行内存的访问。
括号内的部分完全由 OS 自动完成,用户,包括进程完全 0 感知。
- 在分配内存时采用延迟分配的策略来提高整机的效率。(几乎内存的有效使用率是 100%)
(3)通过页表映射到不同的有序区域来实现进程的独立性。
- 在进程的视角,所有的内存分别都可以是有序的。
- 让每个进程以同样的方式来看待代码和数据。(这样对于进程的设计是非常好的)
可执行程序,在磁盘中是被划分成一个个的区域存储起来的(比如代码 .txt、已初始化数据 .data、未初始化数据 .bss 等等)。
因为可执行程序形成时,有一个链接的过程,会把用户代码和库的代码合并在一起,把用户数据和库的数据合并在一起。否则可执行程序的代码和数据如果是混着存放在一起的,会导致链接过程变得很复杂。所以进程的地址空间才有了区域划分这样的概念,方便进程找到代码和数据。
分析:

如图,代码被零散的加载到了内存的各个位置。如果直接让进程去找到代码是非常困难的,尤其是找到代码的起始和结束位置。所以我们在进程的地址空间中划分出一个个区域,再通过页表把内存中的各个位置的代码给整合到一起,使代码的物理地址变成线性的虚拟地址了。然后进程通过其对应地址空间中的代码区(区域中虚拟地址是连续的)可以很方便的找到代码。同时 CPU 也方便执行代码(虚拟地址是连续的,这样 PC 指针才能进行加 1 的操作,得到下一条指今的地址,CPU 才能从上到下顺序执行指令)。
- 地址空间 + 页表的存在可以将内存分布有序化。
- 结合(2),进程要访问物理内存中的数据和代码,可能目前并没有在物理内存中。同样的,也可以让不同的进程映射到不同的物理内存,便很容易做到进程独立性的实现。
- 进程的独立性可以通过进程空间 + 页表的方式实现。
好处:
- 不用在物理内存中找一块连续的区域。
- 站在进程的角度,所有进程的代码(二进制指令)存放的区域,虚拟地址是连续的,可以被顺序执行。(即使物理内存上有可能不连续)
七、重新理解什么是挂起
进程和程序有什么区别呢?
![]()
- 加载的本质就是创建进程。
那么是否必须立刻将所有程序的代码和数据加载到内存中,并创建内核数据结构建立映射关系?
不是。
如果在最极端的情况下,只有内核结构被创建出来了(新建状态)。当真正被调度/执行代码时,才把外设加载内存里,然后再执行代码。
- 理论上,可以实现对程序的分批加载。
如果物理内存只有 4G,有一个游戏 16G,能否运行?
可以运行。
CPU 无论运行多大的程序,都需要从头到尾执行每一行指令。即使物理内存有 32G,也不会一次性把 16G 的程序加载进来(因为内存资源还需要分配给其它进程),而是采用延时加载。比如先加载 200M 进来,执行完了再覆盖式的加载 200M 进来,然后再执行。所以如果物理内存比较小,用户可能会感到游戏卡顿。
- 加载的本质就是换入的过程。
既然可以分批加载,那可以分批换出吗?
可以。
甚至这个进程短时间不会再被执行,比如挂起 / 阻塞。
- 也就相当于其对应的代码和数据占着空间却不创造价值,所以 OS 就可以将它换出,一旦被换出,那么此时这个进程就叫被挂起。
八、Linux2.6 内核进程调度队列
1、Linux2.6 内核中进程队列的数据结构
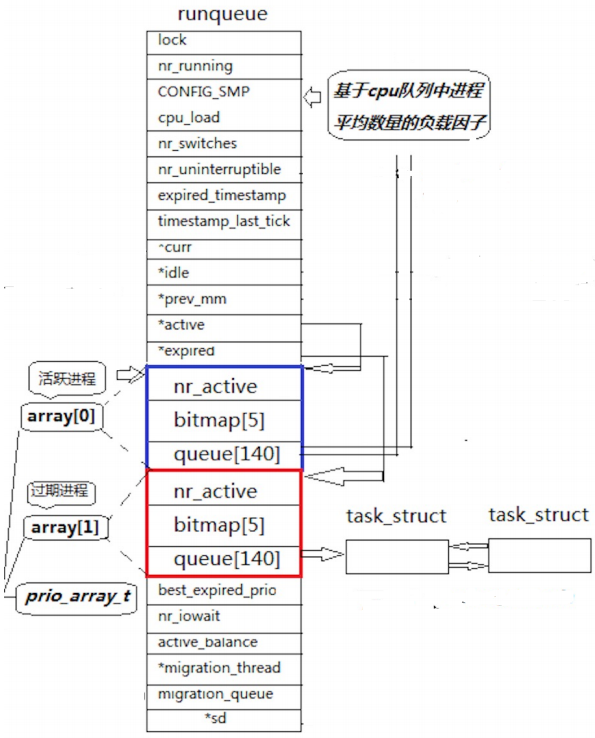
2、一个 CPU 拥有一个 runqueue
3、优先级
- 普通优先级:100~139(我们都是普通的优先级,想想 nice 值的取值范围,可与之对应)
- 实时优先级:0~99(不关心)
4、活动队列
- 时间片还没有结束的所有进程都按照优先级放在该队列。
- nr_active:总共有多少个运行状态的进程。
- queue[140]:一个元素就是一个进程队列,相同优先级的进程按照 FIFO 规则进行排队调度,所以数组下标就是优先级。
- 从该结构中,选择一个最合适的进程,过程怎么回事的呢?
- 从 0 下表开始遍历 queue[140]。
- 找到第一个非空队列,该队列必定为优先级最高的队列。
- 拿到选中队列的第一个进程,开始运行,调度完成。
- 遍历 queue[140] 时间复杂度是常数,但还是太低效了。
- bitmap[5]:一共 140 个优先级,140 个进程队列,为了提高查找非空队列的效率,就可以用 5*32 个比特位表示队列是否为空,这样便可以大大提高查找效率。
5、过期队列
- 过期队列和活动队列结构一模一样。
- 过期队列上放置的进程,都是时间片耗尽的进程。
- 当活动队列上的进程都被处理完毕之后,对过期队列的进程进行时间片重新计算。
6、active 指针和 expired 指针
- active 指针永远指向活动队列。
- expired 指针永远指向过期队列。
- 可是活动队列上的进程会越来越少,过期队列上的进程会越来越多,因为进程时间片到期时一直都存在的。
- 但在合适的时候,只要能够交换 active 指针和 expired 指针的内容,就相当于有具有了一批新的活动进程。
7、总结
在系统当中查找一个最合适调度的进程的时间复杂度是一个常数,不随着进程增多而导致时间成本增加,我们称之为进程调度 O(1) 算法。
相关文章:
【Linux】程序地址空间 -- 详解 Linux 2.6 内核进程调度队列 -- 了解
一、程序地址空间回顾 在学习 C/C 时,我们知道内存会被分为几个区域:栈区、堆区、全局/静态区、代码区、字符常量区等。但这仅仅是在语言层面上的理解,是远远不够的。 如下空间布局图,请问这是物理内存吗? 不是&…...

10-通用类型、特质和生命周期
上一篇: 09-错误处理 每种编程语言都有有效处理概念重复的工具。在 Rust 中,泛型就是这样一种工具:具体类型或其他属性的抽象替身。我们可以表达泛型的行为或它们与其他泛型的关系,而不需要知道在编译和运行代码时它们的位置。 函…...
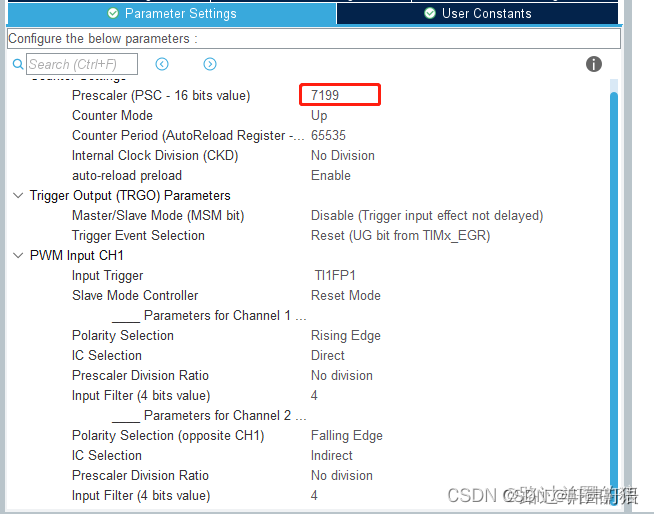
STM32CubeMX,定时器之定时功能,入门学习,如何设置prescaler,以及timer计算PWM输入捕获方法(重要)
频率变小,周期变长 1,参考链接(重要) STM32CubeMX——定时器之定时功能(学习使用timer定时器的设置) STM32测量PWM信息(学习使用设置pwm输入捕获) 通用定时器中两个重要参数的设置心…...

蓝桥杯:C++队列、优先队列、链表
C普通队列 算法竞赛中一般用静态数组来模拟队列,或者使用STL queue。使用C的STL queue时,由于不用自己管理队列,因此代码很简洁。队列的部分操作如下。 C优先队列 很多算法需要用到一种特殊的队列:优先队列。它的特点是最优数据…...

【C语言】长篇详解,字符系列篇1-----“混杂”的各种字符类型字符转换和strlen的模拟实现【图文详解】
欢迎来CILMY23的博客喔,本期系列为【C语言】长篇详解,字符系列篇1-----“混杂”的各种字符函数……,图文讲解各种字符函数,带大家更深刻理解C语言中各种字符函数的应用,感谢观看,支持的可以给个赞哇。 前言…...

2024年【高处安装、维护、拆除】考试总结及高处安装、维护、拆除考试技巧
题库来源:安全生产模拟考试一点通公众号小程序 高处安装、维护、拆除考试总结根据新高处安装、维护、拆除考试大纲要求,安全生产模拟考试一点通将高处安装、维护、拆除模拟考试试题进行汇编,组成一套高处安装、维护、拆除全真模拟考试试题&a…...

开源无处不在,发展创新下又有何弊端
随着信息技术的快速发展,开源软件已经成为软件开发的趋势,并产生了深远的影响。开源软件的低成本、可协作性和透明度等特点,使得越来越多的企业和个人选择使用开源软件,促进了软件行业的繁荣。然而,在使用开源软件的过…...
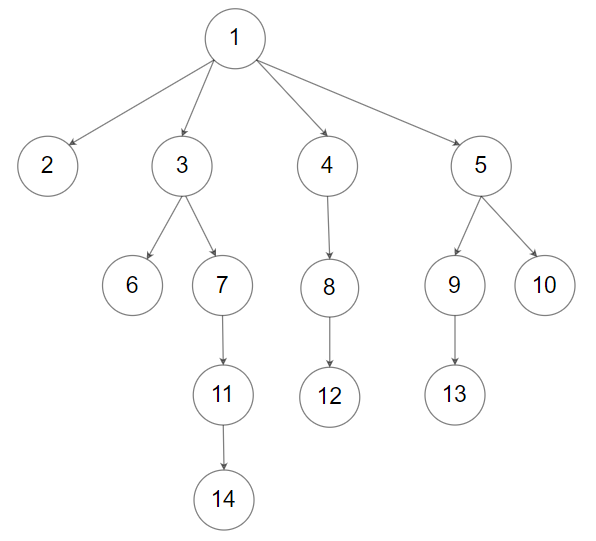
LeetCode 0429.N 叉树的层序遍历:广度优先搜索(BFS)
【LetMeFly】429.N 叉树的层序遍历:广度优先搜索(BFS) 力扣题目链接:https://leetcode.cn/problems/n-ary-tree-level-order-traversal/ 给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)…...
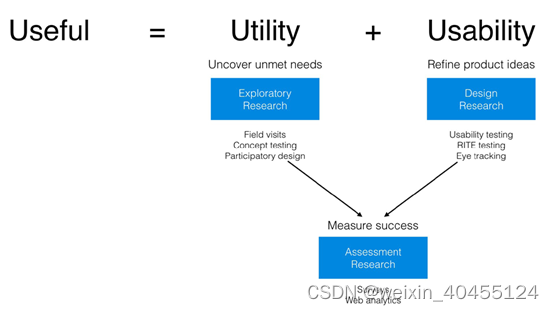
Practical User Research for Enterprise UX
2.1 Why It’s Hard to Get Support for Research in Enterprises 2.1.1 Time and Budget Instead of answering the question “What dowe gain if we do this research?”, ask instead “What do we stand to lose if we don’t do the research?” 2.1.2 Legacy Thinkin…...

文生视频:Sora模型报告总结
作为世界模拟器的视频生成模型 我们探索视频数据生成模型的大规模训练。具体来说,我们在可变持续时间、分辨率和宽高比的视频和图像上联合训练文本条件扩散模型。我们利用对视频和图像潜在代码的时空补丁进行操作的变压器架构。我们最大的模型 Sora 能够生成一分钟…...

GA 374-2019 电子防盗锁检测
电子防盗锁是指以电子方式识别,处理相关信息并控制执行机构实施启闭且达到规定安全级别的锁具。 GA 374-2019 电子防盗锁检测项目 测试项目 测试标准 外观 GA 374 外壳防护等级 GA 374 功能 GA 374 编码组合数 GA 374 主锁舌伸出长度 GA 374 主锁舌灵活…...

代码随想录day26 Java版
今天开始刷贪心算法,新手保护期中爽得一批 455.分发饼干 先把两个数组排序,采用先满足胃口小的孩子,饼干数组无条件向后扫描,能满足孩子后再向后扫描胃口数组 class Solution {public int findContentChildren(int[] g, int[] …...
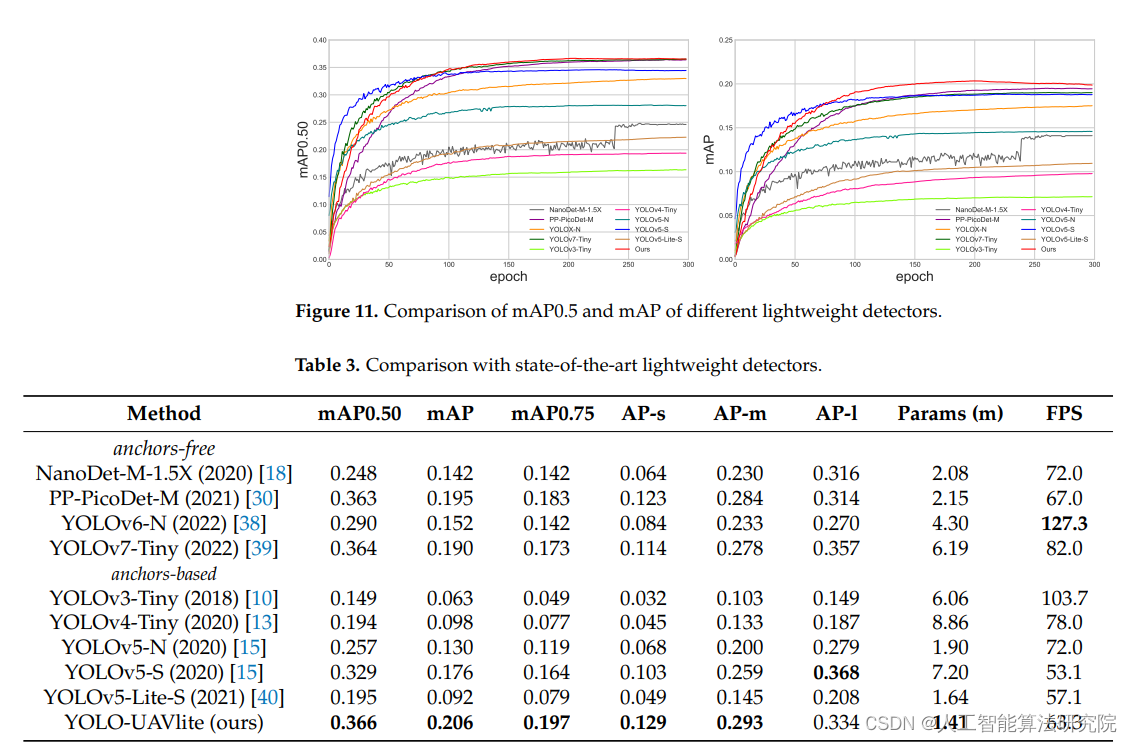
英文论文(sci)解读复现【NO.21】一种基于空间坐标的轻量级目标检测器无人机航空图像的自注意
此前出了目标检测算法改进专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读发表高水平学术期刊中的 SCI论文&a…...

数据集合
目录 并集 union union all 区别 交集 intersect 差集 minus 错误操作 Oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 常用的数学集合有:交集、并集、差集、补集 每一次查询实际上都会返回数据集合,…...

php基础学习之作用域和静态变量
作用域 变量(常量)能够被访问的区域,变量可以在常规代码中定义,也可以在函数内部定义 变量的作用域 在 PHP 中作用域严格来说分为两种,但是 PHP内部还定义一些在严格意义之外的一种,所以总共算三种—— 局部…...

SP1:基于Plonky3构建的zkVM
1. 引言 SP1为SuccictLab开源的,基于Plonky3构建的zkVM。 开源代码见: https://github.com/succinctlabs/sp1(Rust) 当前暂未实现onchain-verifier,但会采用标准的STARK->SNARK verifier。 SP1 zkVM基于的指令…...
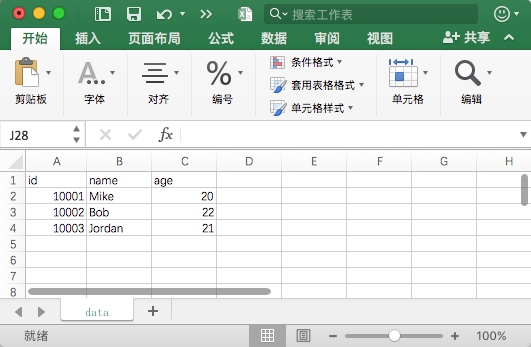
Python爬虫之文件存储#5
爬虫专栏:http://t.csdnimg.cn/WfCSx 文件存储形式多种多样,比如可以保存成 TXT 纯文本形式,也可以保存为 JSON 格式、CSV 格式等,本节就来了解一下文本文件的存储方式。 TXT 文本存储 将数据保存到 TXT 文本的操作非常简单&am…...
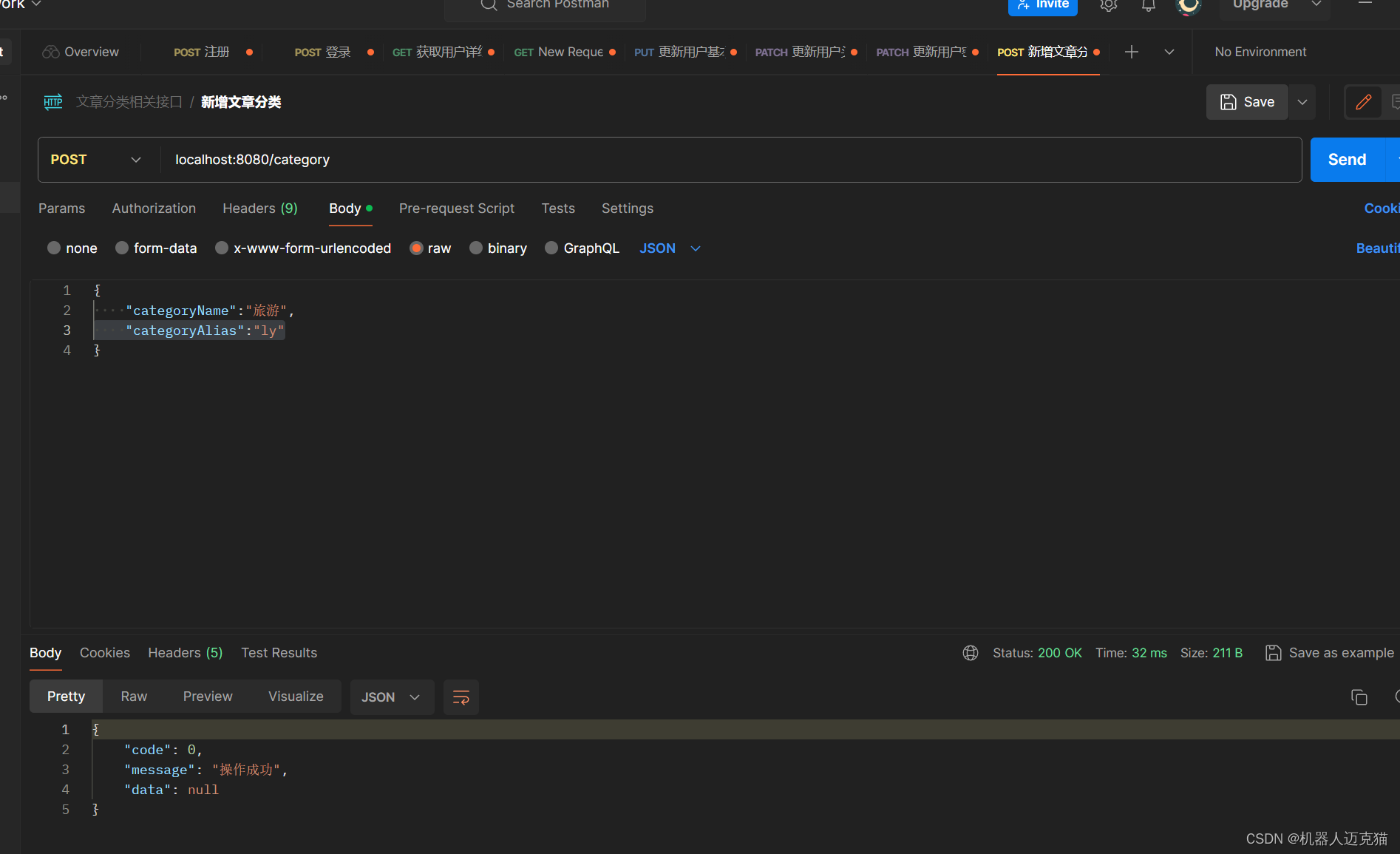
Spring Boot 笔记 012 创建接口_添加文章分类
1.1.1 实体类添加校验 package com.geji.pojo;import jakarta.validation.constraints.NotEmpty; import lombok.Data;import java.time.LocalDateTime;Data public class Category {private Integer id;//主键IDNotEmptyprivate String categoryName;//分类名称NotEmptypriva…...

Spring-面试题
一、Spring 1、Spring的优势 通过IOC、AOP简化java开发 IOC减低业务对象替换的复杂性,降低耦合AOP允许将一些通用的事务、日志进行集中处理,从而提高更好的复用性Spring生态圈低嵌入式涉及,代码污染小高度开放性,用的人多2、Spring的核心 IOC控制反转: Spring容器为我们创…...
Flink理论—容错之状态
Flink理论—容错之状态 在 Flink 的框架中,进行有状态的计算是 Flink 最重要的特性之一。所谓的状态,其实指的是 Flink 程序的中间计算结果。Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。 Flink 使用…...

MSP430单片机低功耗设计实战:从架构到代码的灵活性解析
1. 项目概述:为什么是MSP430?如果你在嵌入式领域摸爬滚打了一段时间,尤其是在对功耗极其敏感的应用场景里,比如智能穿戴、便携医疗设备、无线传感器网络或者那些需要电池供电数年的工业传感器,那么“MSP430”这个名字对…...

CircuitJS1:浏览器中的电子电路仿真神器完全指南
CircuitJS1:浏览器中的电子电路仿真神器完全指南 【免费下载链接】circuitjs1 Electronic Circuit Simulator in the Browser 项目地址: https://gitcode.com/gh_mirrors/ci/circuitjs1 想要学习电子电路却苦于没有实验设备?需要验证电路设计却不…...
)
别再折腾LaTeX了!用Jupyter Notebook自带功能搞定ipynb转PDF(完美支持中文和公式)
告别复杂工具链:Jupyter Notebook原生方案实现ipynb完美转PDF 在数据分析和学术研究的日常工作中,我们经常需要将Jupyter Notebook(.ipynb文件)转换为PDF格式以便分享或提交报告。传统方法往往依赖pandoc、LaTeX等复杂工具链&…...

飞凌嵌入式i.MX 95xx核心板:高性能边缘计算与安全开发的硬件平台解析
1. 项目概述:一颗新旗舰的落地与嵌入式开发者的新选择最近,NXP(恩智浦)新一代的i.MX 95系列应用处理器正式进入量产阶段,而作为其重要的生态合作伙伴,飞凌嵌入式也同步发布了基于该系列芯片的全新核心板。这…...

Adams新手避坑指南:从几何点、Marker坐标系到立方体,这些基础元素你真的用对了吗?
Adams新手避坑指南:几何元素背后的工程逻辑与实战陷阱 刚接触Adams的工程师常会陷入一个误区——把软件操作手册当作圣经,却忽略了每个几何元素背后的物理意义和工程逻辑。这种"知其然不知其所以然"的学习方式,往往会导致仿真结果失…...

GitLab团队协作实战:从分支策略到CI/CD流水线优化指南
1. 项目概述:为什么需要一个专属的GitLab使用指导?在团队协作开发中,版本控制系统是基石,而GitLab作为集代码托管、CI/CD、项目管理于一体的DevOps平台,其重要性不言而喻。然而,对于许多新加入团队的开发者…...

计算机数值型数据表示:从二进制到浮点数与字符编码的底层原理
1. 项目概述:从“0”和“1”到万千世界我们每天都在和计算机打交道,无论是刷短视频、处理文档,还是运行复杂的科学计算。你有没有想过,屏幕上那些生动的图像、动听的音乐、精确的数值,在计算机的“大脑”——CPU和内存…...

unrpa:当Ren‘Py游戏资源被锁定时,你的万能钥匙是什么?
unrpa:当RenPy游戏资源被锁定时,你的万能钥匙是什么? 【免费下载链接】unrpa A program to extract files from the RPA archive format. 项目地址: https://gitcode.com/gh_mirrors/un/unrpa 你是否曾面对一个RenPy游戏的RPA档案文件…...

从LCD屏幕到车载摄像头:聊聊LVDS接口在你身边那些‘看不见’的应用
从LCD屏幕到车载摄像头:聊聊LVDS接口在你身边那些‘看不见’的应用 走在科技产品琳琅满目的商场里,你可能不会注意到,那些让你眼前一亮的4K显示屏、流畅的触控体验,甚至自动驾驶汽车里的"眼睛",背后都藏着一…...

TDengine数据迁移与备份实战:使用taosdump将2.x数据安全升级到3.0
TDengine 2.x到3.0数据迁移完全指南:从备份策略到避坑实践 时序数据库的版本升级往往伴随着数据迁移的挑战。当企业决定将TDengine从2.x升级到3.0时,如何确保数据安全迁移成为技术团队面临的首要问题。本文将深入解析使用taosdump工具进行数据迁移的全流…...