四、案例 - Oracle数据迁移至MySQL
Oracle数据迁移至MySQL
- 一、生成测试数据表和数据
- 1.在Oracle创建数据表和数据
- 2.在MySQL创建数据表
- 二、生成模板文件
- 1.模板文件内容
- 2.模板文件参数详解
- 2.1 全局设置
- 2.2 数据读取(Reader)
- 2.3 数据写入(Writer)
- 2.4 性能设置
- 三、案例
- 1.全量数据迁移
- 1.1 配置迁移模板
- 1.2.运行迁移命令
- 2.增量数据迁移
- 2.1 配置迁移模板
- 2.2 运行迁移命令
一、生成测试数据表和数据
1.在Oracle创建数据表和数据
- 部署Oracle教程
# 创建数据库查看上面的部署教程
# 1.创建表
CREATE TABLE student (id INTEGER,name VARCHAR2(20),create_time TIMESTAMP DEFAULT SYSTIMESTAMP,update_time TIMESTAMP DEFAULT SYSTIMESTAMP
);
# 2.插入测试数据
INSERT INTO student (id, name)
SELECT level, 'Name ' || level
FROM dual
CONNECT BY level <= 10;
2.在MySQL创建数据表
- 部署MySQL教程
# 1.创建数据库
CREATE DATABASE oracle_test charset=utf8mb4;
# 2.创建数据库表
use oracle_test;
CREATE TABLE student (id INT,name VARCHAR(20),create_time DATETIME DEFAULT CURRENT_TIMESTAMP,update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
二、生成模板文件
- 当前安装DataX的目录为:/data/datax
# 1.进入datax的工具目录
cd /data/datax/bin/
# 2.生成模板
python datax.py -r oraclereader -w mysqlwriter > ../job/oracle_to_mysql.json
1.模板文件内容
{"job": {"content": [{"reader": {"name": "oraclereader", "parameter": {"column": [], "connection": [{"jdbcUrl": ["jdbc:oracle:thin:@[HOST_NAME]:PORT:[DATABASE_NAME]"], "table": []}], "password": "", "username": "","where": ""}}, "writer": {"name": "mysqlwriter", "parameter": {"column": [], "connection": [{"jdbcUrl": "", "table": []}], "password": "", "preSql": [], "session": [], "username": "", "writeMode": ""}}}], "setting": {"speed": {"channel": ""}}}
}2.模板文件参数详解
2.1 全局设置
- job: 定义了整个数据迁移作业的配置。
- content: 包含了一个或多个数据同步任务的列表。
2.2 数据读取(Reader)
- reader: 定义了数据来源的相关配置。
- name: 使用的读取插件名称,这里是oraclereader,表示从Oracle数据库读取数据。
- parameter: 读取数据时的参数配置。
- column: 需要读取的列名列表。
- connection: 数据库连接信息。
- jdbcUrl: 数据库的JDBC连接URL。需要替换[HOST_NAME], [PORT], [DATABASE_NAME]为实际的服务器地址、端口和数据库名。
- table: 指定要读取数据的表名列表。
- password: 用于连接Oracle数据库的密码。
- username: 用于连接Oracle数据库的用户名。
- where: 可以指定一个WHERE条件来过滤读取的数据,这里留空表示不过滤,读取所有数据。
2.3 数据写入(Writer)
- writer: 定义了数据目的地的相关配置。
- name: 使用的写入插件名称,这里是mysqlwriter,表示数据将被写入到MySQL数据库。
- parameter: 写入数据时的参数配置。
- column: 指定写入到目标表的列名。应与读取的列对应。
- connection: 目标数据库的连接信息。
- jdbcUrl: MySQL的JDBC连接URL。
- table: 指定要写入数据的表名。
- password: 用于连接MYSQL数据库的密码。
- postSql: 在数据写入完成后执行的SQL语句列表,这里留空。
- preSql: 在数据写入前执行的SQL语句列表,这里留空。
- username: 用于连接MYSQL数据库的用户名。
- writeMode: 写入模式,这里设置为insert,表示通过INSERT语句进行数据写入。
2.4 性能设置
- setting: 定义了作业的全局设置。
- speed: 控制数据同步的速度。
- channel: 指定并发通道的数量,这里设置为4,意味着数据迁移任务将并行执行,使用4个并发通道。
- speed: 控制数据同步的速度。
三、案例
1.全量数据迁移
1.1 配置迁移模板
{"job": {"content": [{"reader": {"name": "oraclereader", "parameter": {"column": ["id", "name", "create_time", "update_time"], "connection": [{"jdbcUrl": ["jdbc:oracle:thin:@192.168.86.128:1521/helowin"], "table": ["student"]}], "password": "***", "username": "ora_user"}}, "writer": {"name": "mysqlwriter", "parameter": {"column": ["id", "name", "create_time", "update_time"], "connection": [{"jdbcUrl": "jdbc:mysql://192.168.86.128:3306/oracle_test?useUnicode=true&characterEncoding=utf-8", "table": ["student"]}], "password": "****", "preSql": [], "username": "root", "writeMode": "insert"}}}], "setting": {"speed": {"channel": "1"}}}
}
1.2.运行迁移命令
python /data/datax/bin/datax.py /data/datax/job/mysql_to_clickhouse.json
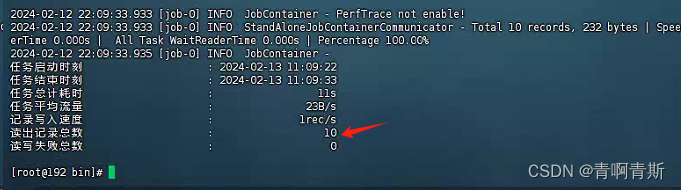
2.增量数据迁移
- 主要差别在于,需要有一个createTime字段,代表源数据的创建时间,那么更新的时候,只迁移过滤这个时间段的数据,达到增量数据迁移
2.1 配置迁移模板
{"job": {"content": [{"reader": {"name": "oraclereader", "parameter": {"column": ["id", "name", "create_time", "update_time"], "connection": [{"jdbcUrl": ["jdbc:oracle:thin:@192.168.86.128:1521/helowin"], "table": ["student"]}], "password": "***", "username": "ora_user","where":"CREATE_TIME >= TO_TIMESTAMP('2024-02-14 00:00:00', 'YYYY-MM-DD HH24:MI:SS') AND CREATE_TIME <= TO_TIMESTAMP('2024-02-14 23:59:59', 'YYYY-MM-DD HH24:MI:SS')"}}, "writer": {"name": "mysqlwriter", "parameter": {"column": ["id", "name", "create_time", "update_time"], "connection": [{"jdbcUrl": "jdbc:mysql://192.168.86.128:3306/oracle_test?useUnicode=true&characterEncoding=utf-8", "table": ["student"]}], "password": "****", "preSql": [], "username": "root", "writeMode": "insert"}}}], "setting": {"speed": {"channel": "1"}}}
}
2.2 运行迁移命令
- 注意:指定参数的话,参数名称面前需要加:
-D
python /data/datax/bin/datax.py /data/datax/job/oracle_to_mysql.json -p "-DstartDatetime=2024-02-14 -DendDatetime=2024-02-14"
相关文章:
四、案例 - Oracle数据迁移至MySQL
Oracle数据迁移至MySQL 一、生成测试数据表和数据1.在Oracle创建数据表和数据2.在MySQL创建数据表 二、生成模板文件1.模板文件内容2.模板文件参数详解2.1 全局设置2.2 数据读取(Reader)2.3 数据写入(Writer)2.4 性能设置 三、案例…...

ABC340 A-F题解
文章目录 A题目AC Code: B题目AC Code: C题目AC Code: D题目AC Code: E题目思路做法时间复杂度AC Code: F题目思路AC Code: A 题目 模拟即可,会循环都能写。 AC Code: #include …...

微软 CMU - Tag-LLM:将通用大语言模型改用于专业领域
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 论文地址:https://arxiv.org/abs/2402.05140 Github 地址:https://github.com/sjunhongshen/Tag-LLM 大语言模型(…...

Kafka集群安装与部署
集群规划 准备工作 安装 安装包下载:链接:https://pan.baidu.com/s/1BtSiaf1ptLKdJiA36CyxJg?pwd6666 Kafka安装与配置 1、上传并解压安装包 tar -zxvf kafka_2.12-3.3.1.tgz -C /opt/moudle/2、修改解压后的文件名称 mv kafka_2.12-3.3.1/ kafka…...
C++初阶(十一) list
一、list的介绍及使用 1.1 list的介绍 list的文档介绍 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点…...
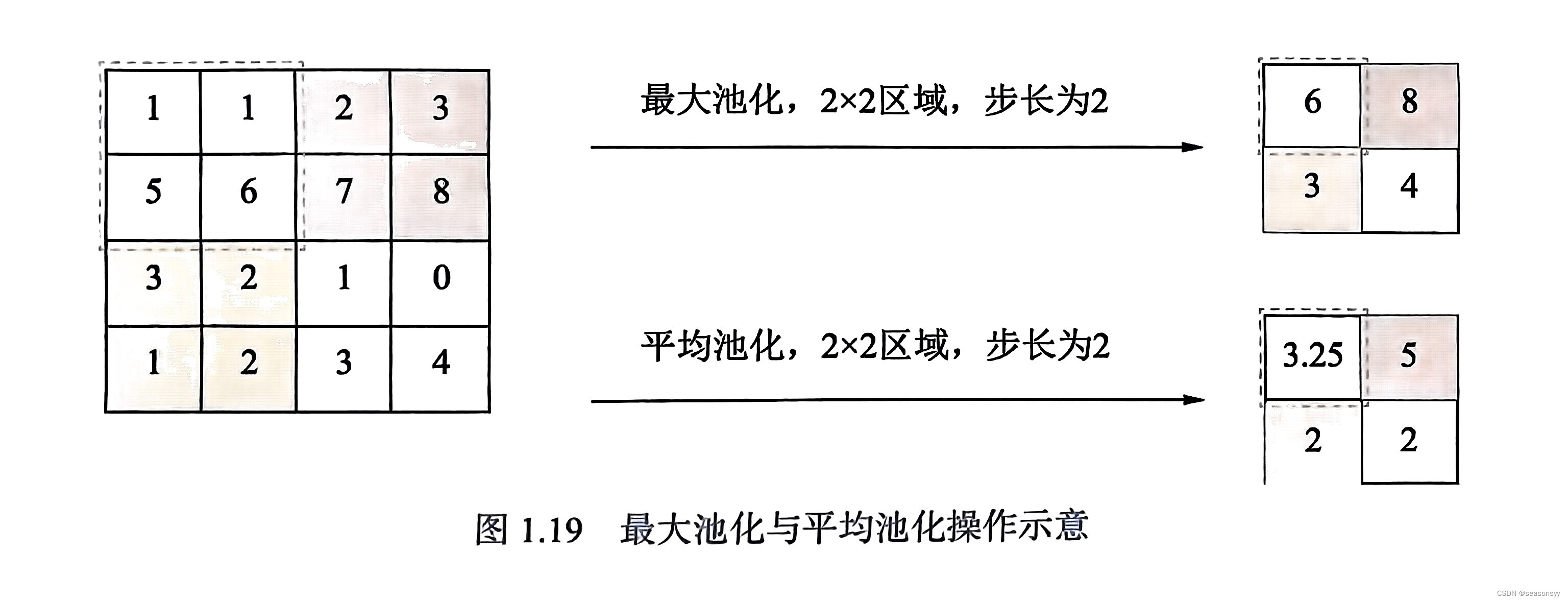
图像卷积、步长、填充、特征图、多通道卷积、权重共享、感受野、池化
图像卷积、步长、填充、特征图、多通道卷积、权重共享、感受野、池化 卷积神经网络的一些基本概念:图像卷积、步长、填充、特征图、多通道卷积、权重共享、感受野、池化 1.图像卷积、步长、填充 图像卷积:卷积核矩阵在一个原始图像矩阵上 “从上往下、…...
CMake进行C/C++与汇编混合编程
1. 前提 这篇文章记录一下怎么用CMake进行项目管理, 并用C/C和汇编进行混合编程, 为了使用这项技术, 必须在VS的环境中安装好cmake组件 由于大部分人不会使用C/C与汇编进行混合编程的情况。所以这篇文章并不适用于绝大部分人不会对其中具体细节进行过多叙述。只是做一些简单的…...

缓存预热!真香
预热一般指缓存预热,一般用在高并发系统中,为了提升系统在高并发情况下的稳定性的一种手段。 缓存预热是指在系统启动之前或系统达到高峰期之前,通过预先将常用数据加载到缓存中,以提高缓存命中率和系统性能的过程。缓存预热的目…...

VS中设置#define _CRT_SECURE_NO_WARNINGS的原因和设置方式
原因: 在编译老的用C语言的开源项目的时候,可能因为一些老的.c文件使用了strcpy,scanf等不安全的函数,而报警告和错误,而导致无法编译通过。 解决方案: 我们有两种解决方案: 1、在指定的源文件的开头定…...
【网站项目】155在线考试与学习交流网页平台
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...
解决IDEA的Project无法正常显示的问题
一、问题描述 打开IDEA,结果发现项目结构显示有问题: 二、解决办法 File -> Project Structure… -> Project Settings (选Modules),然后导入Module 结果: 补充: IDEA提示“The imported module settings a…...

CDF和PDF的比较
以下内容来自ChatGPT,科技改变生活 Cumulative Distribution Function (CDF)(累积分布函数)和 Probability Density Function (PDF)(概率密度函数)是统计学和概率论中两个重要的概念,用于描述随机变量的性…...

编译基本过程 预处理器
编译基本过程 源代码(main.c)->预处理器(cpp)->编译器(gcc/clang/msvc)->汇编器(as)->链接器(ld)->可执行文件(main.exe) 预处理器 C语言中预处理器:执行预处理命令(文件包含、宏替换、条件编译)处理注释(将所有注释替换为空格)处理续行符(将所有…...

模拟算法.
1.什么是模拟 在信息奥赛中,有一类问题是模拟一个游戏的对弈过程或者模拟一项任务的操作过程.比如乒乓球在比赛中模拟统计记分最终判断输赢的过程等等,这些问题通常很难通过建立数学模型用特定的算法来解决因为它没有一种固定的解法,需要深刻理解出题者对过程的解释一般只能采…...

ClickHouse--10--临时表、视图、向表中导入导出数据
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1.临时表1.1 特征1.2 创建一个临时表 2.视图2.1 普通视图2.2 物化视图 3.向表中导入导出数据3.1 案例 1.临时表 1.1 特征 ClickHouse 支持临时表,临时表…...

Python一些可能用的到的函数系列124 GlobalFunc
说明 GlobalFunc是算网的下一代核心数据处理基础。 算网是一个分布式网络,为了能够实现真的分布式计算(加快大规模任务执行效率),以及能够在很长的时间内维护不同版本的计算方法,需要这样一个对象/服务来支撑。Globa…...

python中线程/线程池,进程/进程池的创建
创建子线程 # 创建子线程t1 threading.Thread(targetjob,args(1,))# 执行子线程t1.start()# 等待子线程执行print("waiting threading")t1.join()print("threading done")创建子进程 # 创建子进程p1 multiprocessing.Process(targetjob,args(1,),name&qu…...

【c++】vector的增删查改
1.先定义一个类对象vector 为了防止和库里面发生冲突,定义一个命名空间,将类对象放在命名空间 里面 #include<iostream> using namespace std; namespace zjw {class vector {public:private:}; }2.定义变量,需要一个迭代器ÿ…...
【研究生复试】计算机软件工程人工智能研究生复试——资料整理(速记版)——JAVA
1、JAVA 2、计算机网络 3、计算机体系结构 4、数据库 5、计算机租场原理 6、软件工程 7、大数据 8、英文 自我介绍 1. Java 1. 和 equals的区别 比较基本数据类型是比较的值,引用数据类型是比较两个是不是同一个对象,也就是引用是否指向同 一个对象&…...

JVM-JVM中对象的生命周期
申明:文章内容是本人学习极客时间课程所写,文字和图片基本来源于课程资料,在某些地方会插入一点自己的理解,未用于商业用途,侵删。 原资料地址:课程资料 对象的创建 常量池检查:检查new指令是否能在常量池…...

混合AI路由器架构:实现高效智能任务分发
1. 混合AI路由器架构解析 在当今AI技术快速发展的背景下,超级代理系统正逐渐从理论走向实践。这类系统面临的核心挑战是如何在保证响应质量的同时,实现高效、低成本的规模化部署。混合AI路由器架构通过分层决策机制,巧妙地解决了这一难题。 …...

AIGC 检测‘信息密度‘到底是什么?嘎嘎降 AI 帮你 AI 率从 65% 降到 8%
AIGC 检测"信息密度"到底是什么?嘎嘎降 AI 帮你 AI 率从 65% 降到 8% AIGC 检测算法 4.0 版本看的 5 项底层指标里——信息密度权重排第二(约 25%)。理解了这一项你才知道为什么"工整学术风"也会被判 AI。这篇文章把&quo…...

Typora LaTeX主题:学术论文写作的终极解决方案
Typora LaTeX主题:学术论文写作的终极解决方案 【免费下载链接】typora-latex-theme 将Typora伪装成LaTeX的中文样式主题,本科生轻量级课程论文撰写的好帮手。This is a theme disguising Typora into Chinese LaTeX style. 项目地址: https://gitcode…...

告别传统编程:用AI语音命令5倍速开发Godot游戏
告别传统编程:用AI语音命令5倍速开发Godot游戏 【免费下载链接】Godot-MCP An MCP for Godot that lets you create and edit games in the Godot game engine with tools like Claude 项目地址: https://gitcode.com/gh_mirrors/god/Godot-MCP 还在为复杂的…...

Node.js 服务端应用接入 Taotoken 实现异步对话补全的完整步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Node.js 服务端应用接入 Taotoken 实现异步对话补全的完整步骤 在 Node.js 服务端应用中集成大模型能力,通常需要处理密…...

量子安全与后量子密码学:awesome-quantum-software中的加密工具
量子安全与后量子密码学:awesome-quantum-software中的加密工具 【免费下载链接】awesome-quantum-software Curated list of open-source quantum software projects. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-quantum-software 在后量子计算时…...
和MSB8020错误的根治方法)
别再只改项目属性了!彻底搞懂Visual Studio平台工具集(Platform Toolset)和MSB8020错误的根治方法
深入解析Visual Studio平台工具集:从MSB8020错误到构建系统精要 当你在Visual Studio中打开一个历史项目时,是否曾被突如其来的MSB8020错误打断工作流程?这个看似简单的"找不到生成工具"提示背后,隐藏着Visual Studio构…...

群晖Docker部署iptv-m3u-maker保姆级教程:自动检测直播源,告别失效频道
群晖NAS上打造智能IPTV系统:Docker容器化部署与自动化直播源管理实战 在家庭媒体中心搭建领域,群晖NAS凭借其出色的硬件性能和灵活的软件生态,已成为众多技术爱好者的首选平台。而将IPTV服务整合进NAS系统,不仅能实现传统电视节目…...

生物医学论文降AI工具免费推荐:2026年生物医学毕业论文知网AIGC超标免费4.8元一次过完整方案
生物医学论文降AI工具免费推荐:2026年生物医学毕业论文知网AIGC超标免费4.8元一次过完整方案 整理了一份生物医学论文降AI的完整选购指南,按性价比排序。 首推嘎嘎降AI(www.aigcleaner.com),4.8元,99.26%…...

NCM解密终极指南:3步解锁网易云音乐加密文件
NCM解密终极指南:3步解锁网易云音乐加密文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在官方客户端播放,无法在其他设备或播放器上欣赏&…...