浅谈基于中台模式的大数据生态体系的理解
这篇文章主要浅谈一下我对大数据生态体系建设的理解。
大数据生态系统为高并发,高吞吐,高峰值,高堆积等大规模数据的采集,处理,计算,存储,服务提供了完善的处理体系,致力于打造核心数据中台建设,实现整个生态的高可扩展和高弹性,对数据熵的聚变提供基础数据处理支撑,贯穿整个阿里大数据生态体系和应用场景,对外暴露数据应用层采用适配原则可以和各类集团内应用提供统一的访问和回调接口,对于接受到的数据处理和计算请求会交给数据服务层进行数据清洗,转换和预处理,然后会把数据交由数据计算层来进行数据分拣,计算,提炼出最有价值的数据来实现业务场景最佳适配,数据计算层主要采用流批一体的处理思想,结合各类离线和实时计算平台等自研发的大数据和云计算处理服务来实现大规模高精准的数据计算,挖掘出最有价值的数据,提炼数据价值,同时集成了数据整合和管理体系和工具来进行最终的数据萃取。数据采集层则主要负责增全一体从各类关系型/非关系型数据库,大数据存储引擎,中间件容器中借助各类自研发日志采集服务实现实时/离线采集日志/增全量数据,使用drc等实时数据流基础设施实现数据同步,结合动态表,流表对偶性等实时计算核心概念实现流表数据同步和转换,支持各类数据溯源。数据采集层和数据计算层通过各类自研发消息中间件/数据传输中间件实现数据同步,同时对于数据计算层引入了数据仓库和模型的概念,采集到的数据经过提炼和萃取后会保留有意义的数据到各类数据仓库中,并基于元数据存储引擎对数据进行建模,对外统一暴露调度运行态的数据模型进行业务处理,内部封装了所有的大数据采集,计算和存储服务。
实时计算平台也叫做开放流计算服务,核心API是AntPL SQL,弃用了DataStreamAPI,原因是SQL具有很多特性,比如声明式,自动调优,易于理解,扩展性强,运行稳定,流批一体。比如很多人知道的Apache Flink就是一个面相集团的开放流计算服务,它的底层runtime就是一个统一了流和批的底层处理引擎,而SQL恰好可以在API层面实现流和批的统一。Flink最大的特点就是流批一体的高性能,高效率,面向大数据的实时数据计算引擎,可以随着时间变化和数据变化不断更新结果,始终处于运行状态,对于运行期数据源数据的增量变更会采取增量监听,抓取和实时计算的方式生成新的动态表流,新的动态表流又会作为下一个连续查询的输入源继续参与计算,以此类推,最终会形成一个完整的数据流。在实时计算中,动态表可以理解为随着时间变化不断更新的表,流可以理解为是一个具有输入输出的数据通道,流和动态表是可以通过changelog进行相互转换的,那么我们就把这种特性叫做流表的对偶性,因为我们传统sql都是批处理,是不支持流处理的,无论是概念上还是语法上,都不方便,无法在批流之间建立映射关系,因此如果我们要定义流sql就需要结合Flink SQL的核心概念连续查询来实现,Flink SQL流批一体可以通过一套SQL定义同时实现批流处理,并且对接了绝大多数数据源进行输入输出,比如各类RDB Cluster,Random,AntQ,MetaQ,DataHub,TimeTunnel,TDDL,SLS,DRC,融合队列,HBase,Exploer,ODPS等等,连续查询往上走,还可以上升到维度的概念啊,分层的概念啊,数据分层,多流关联,维表关系等等,再此先不再深入讨论流式SQL的衍变。
Flink SQL核心功能莫过于DataHub,MetaQ(RocketMQ),OTS进行数据分层和流表,维表关联读写,往深点说,还有很多高级特性,比如双流JOIN,维表JOIN,TopN,窗口计算和水位,多路输入输出,MiniBatch,Retraction等机制实现early-fire,支持各类语言的数据计算任务研发,质量管理,整合,运维保障,已经实现了跨语言,跨数据源,跨地域的实时计算开发和管理。兼容T-SQL,PL/SQL,Java,C++,Python,Spark-Jar,Golang等等,内置各类大数据处理引擎如Spark,ODPS,Kepler,Flink,结合大数据存储引擎HBase,Explorer,ODPS,RDS Cluster等等实现数据从数据采集,数据处理,数据计算,数据服务,数据应用的全产业链高效稳定发展,必将为DT时代大数据发展注入更多技术支持,能够兼容更多的大数据业务场景,因此数据中台建设是所有基础设施建设中非常重要的一环。
相关文章:

浅谈基于中台模式的大数据生态体系的理解
这篇文章主要浅谈一下我对大数据生态体系建设的理解。 大数据生态系统为高并发,高吞吐,高峰值,高堆积等大规模数据的采集,处理,计算,存储,服务提供了完善的处理体系,致力于打造核心数…...

MySQL的锁机制
一:概述 锁是计算机协调多个进程或线程并发访问某一资源的机制(避免争抢); 在数据库中,除传统的计算资源(如CPU,RAM,I/O等)的争用以外,数据也是一种供许多用…...

已解决ImportError: cannot import name ‘PILLOW_VERSION‘异常的正确解决方法,亲测有效!!!
已解决ImportError: cannot import name PILLOW_VERSION异常的正确解决方法,亲测有效!!! 文章目录 问题分析 报错原因 解决思路 解决方法 总结 在Python项目开发中,依赖管理是保证项目正常运行的关键环节。然而&…...

力扣:300. 最长递增子序列
动态规划: 1. 先定义dp数组来表示在下标为i时最长递增子序列,先初始化一下每个下标的值为dp【i】1。同时我们要判断在下标i之前的最长的递增子序列为多少,在判断当前的下标i是否满足递增的条件满足的话就进行dp【i】的重新赋值。之后要更新接受的最长递…...
Swing程序设计(10)列表框,文本框,文本域,密码框
文章目录 前言一、列表框二、文本框(域) 1.文本框2.文本域三、密码框总结 前言 该篇文章简单介绍了Java中Swing组件里的列表框、文本框、密码框。 一、列表框 列表框(JList)相比下拉框,自身只是在窗体上占据固定的大小…...
【Java八股面试系列】JVM-常见参数设置
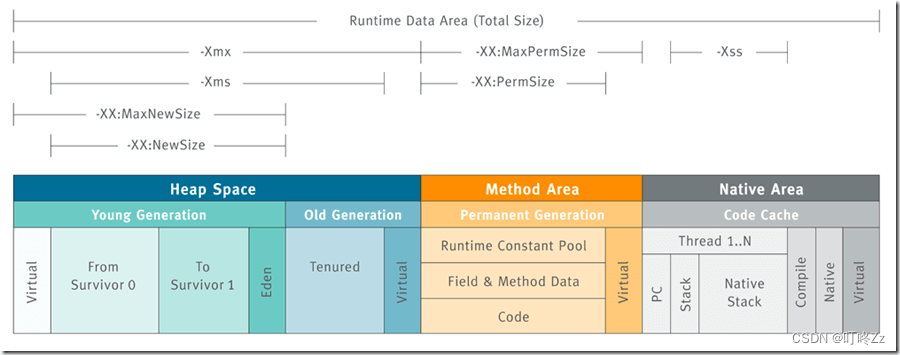
目录 堆内存相关 显式指定堆内存–Xms和-Xmx 显式新生代内存(Young Generation) 显式指定永久代/元空间的大小 垃圾收集相关 垃圾回收器 GC 日志记录 处理 OOM JDK监控和故障处理工具总结 堆内存相关 Java 虚拟机所管理的内存中最大的一块,Java 堆是所有线…...

【Python--Web应用框架大比较】
🚀 作者 :“码上有前” 🚀 文章简介 :Python 🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬 Django Django太重了,除了web框架,自带ORM和模板引擎,灵活和自由度不…...

Effective Objective-C 学习第三周
理解引用计数 Objective-C 使用引用计数来管理内存:每个对象都有个可以递增或递减的计数器。如果想使某个对象继续存活,那就递增其引用计数:用完了之后,就递减其计数。计数变为 0时,就可以把它销毁。 在ARC中…...
人工智能学习与实训笔记(四):神经网络之NLP基础—词向量
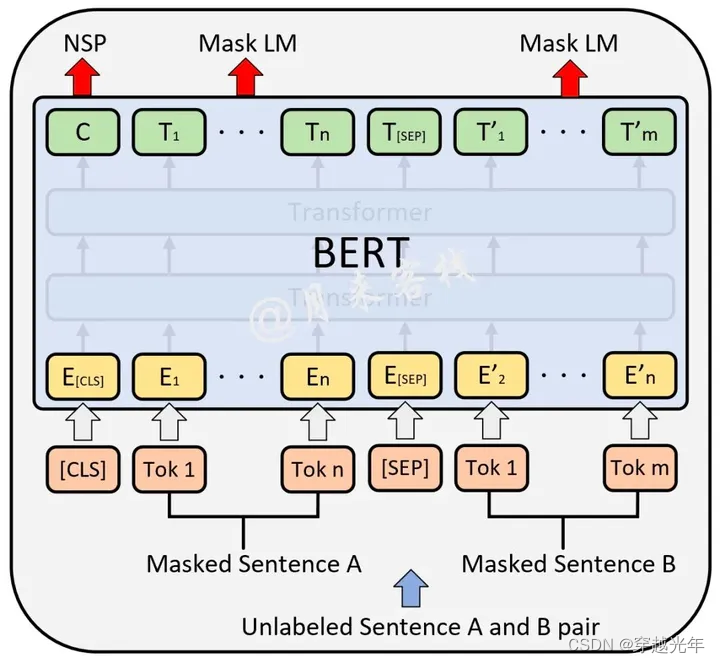
人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客 本篇目录 四、自然语言处理 4.1 词向量 (Word Embedding) 4.1.1 词向量的生成过程 4.1.2 word2vec介绍 4.1.3 word2vec:skip-gram算法的实现 4.2 句向量 - 情感分析 4.2.1 LSTM (Long S…...

【教程】Kotlin语言学习笔记(一)——认识Kotlin(持续更新)
写在前面: 如果文章对你有帮助,记得点赞关注加收藏一波,利于以后需要的时候复习,多谢支持! 【Kotlin语言学习】系列文章 第一章 《认识Kotlin》 文章目录 【Kotlin语言学习】系列文章一、Kotlin介绍二、学习路径 一、…...
MySQL性能分析1
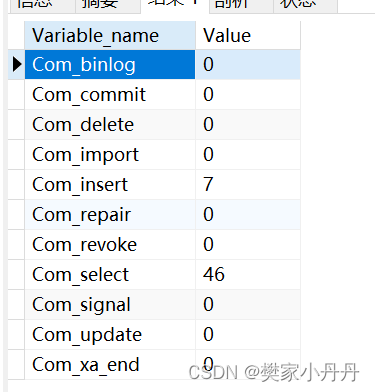
1、查看执行频次 查看当前数据库的INSERT,UPDATE,DELETE,SELECT的访问频次,得到当前数据库是以插入,更新和删除为主还是以查询为主,如果是以插入,更新和删除为主的话,那么优化比重可以轻一点儿。 语法: …...
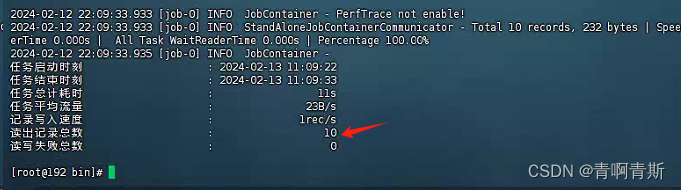
四、案例 - Oracle数据迁移至MySQL
Oracle数据迁移至MySQL 一、生成测试数据表和数据1.在Oracle创建数据表和数据2.在MySQL创建数据表 二、生成模板文件1.模板文件内容2.模板文件参数详解2.1 全局设置2.2 数据读取(Reader)2.3 数据写入(Writer)2.4 性能设置 三、案例…...

ABC340 A-F题解
文章目录 A题目AC Code: B题目AC Code: C题目AC Code: D题目AC Code: E题目思路做法时间复杂度AC Code: F题目思路AC Code: A 题目 模拟即可,会循环都能写。 AC Code: #include …...

微软 CMU - Tag-LLM:将通用大语言模型改用于专业领域
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 论文地址:https://arxiv.org/abs/2402.05140 Github 地址:https://github.com/sjunhongshen/Tag-LLM 大语言模型(…...

Kafka集群安装与部署
集群规划 准备工作 安装 安装包下载:链接:https://pan.baidu.com/s/1BtSiaf1ptLKdJiA36CyxJg?pwd6666 Kafka安装与配置 1、上传并解压安装包 tar -zxvf kafka_2.12-3.3.1.tgz -C /opt/moudle/2、修改解压后的文件名称 mv kafka_2.12-3.3.1/ kafka…...
C++初阶(十一) list
一、list的介绍及使用 1.1 list的介绍 list的文档介绍 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。 2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点…...
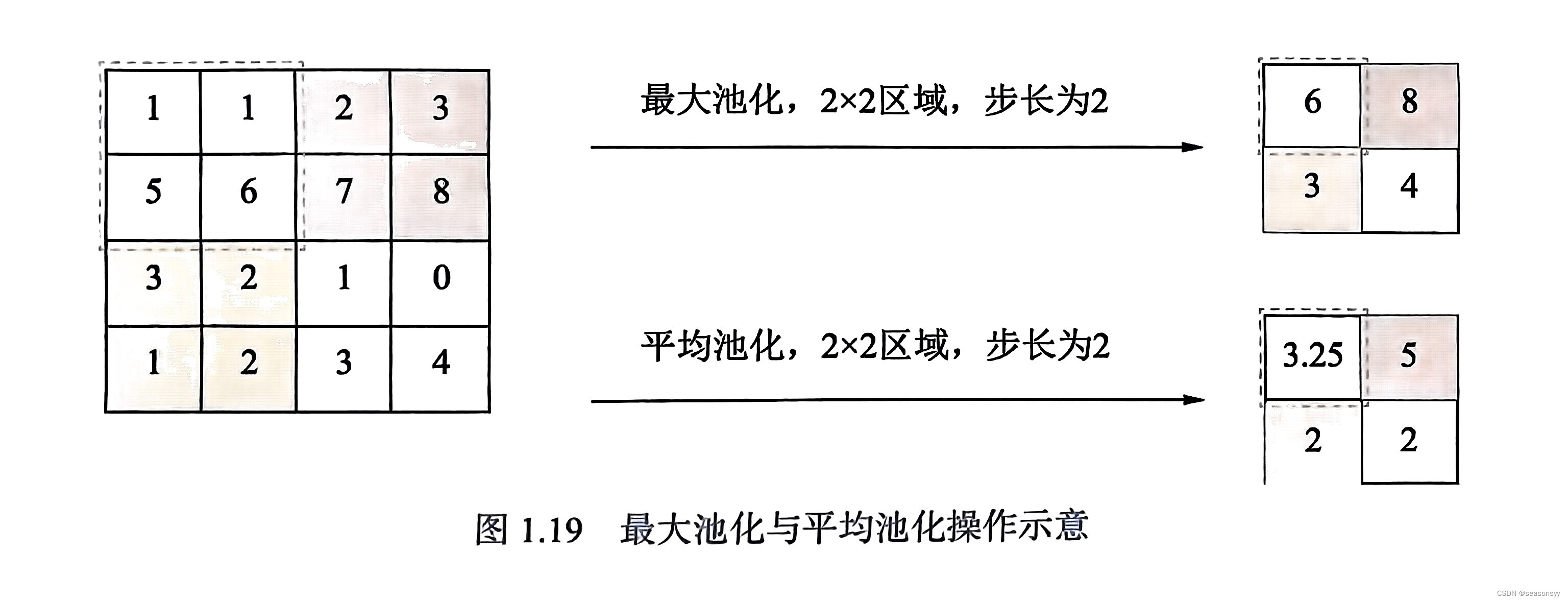
图像卷积、步长、填充、特征图、多通道卷积、权重共享、感受野、池化
图像卷积、步长、填充、特征图、多通道卷积、权重共享、感受野、池化 卷积神经网络的一些基本概念:图像卷积、步长、填充、特征图、多通道卷积、权重共享、感受野、池化 1.图像卷积、步长、填充 图像卷积:卷积核矩阵在一个原始图像矩阵上 “从上往下、…...
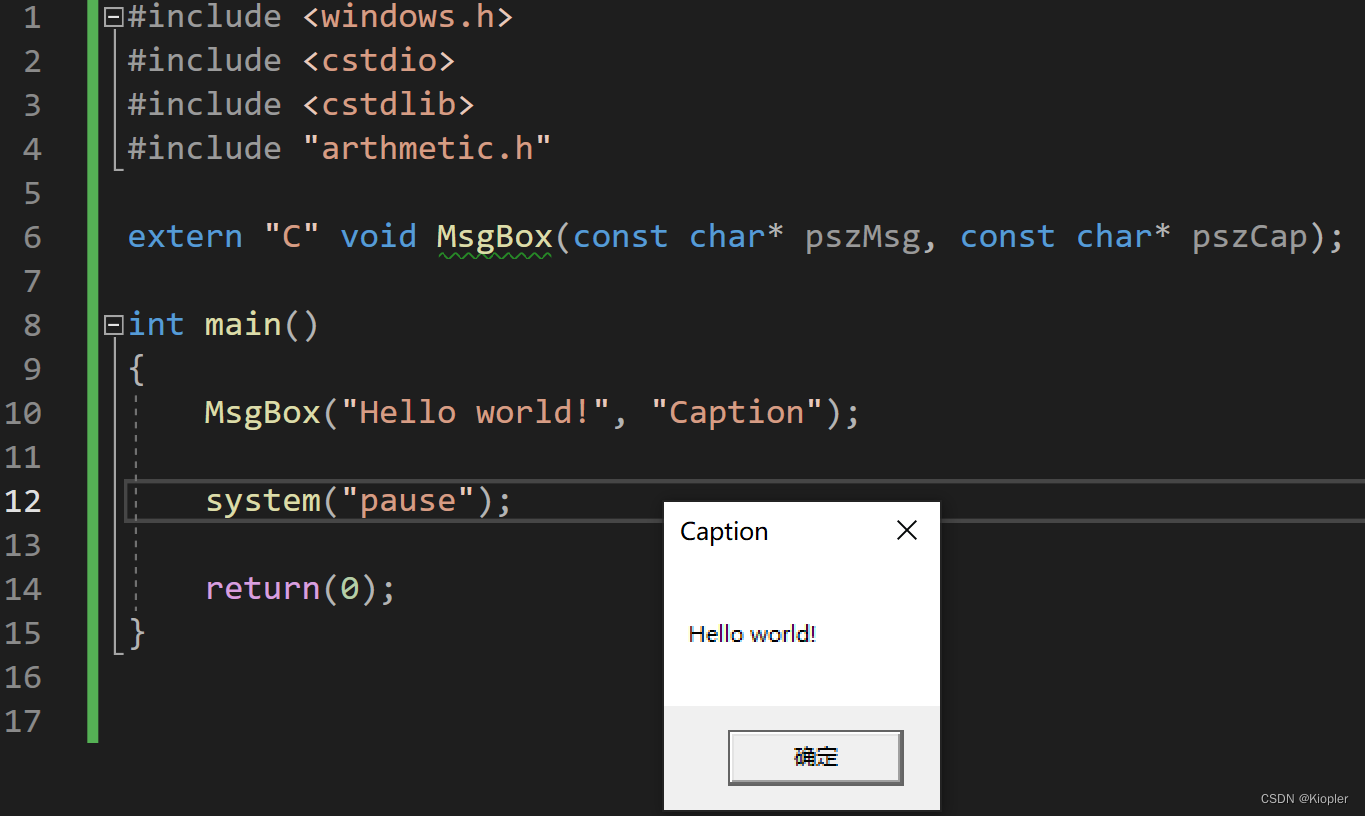
CMake进行C/C++与汇编混合编程
1. 前提 这篇文章记录一下怎么用CMake进行项目管理, 并用C/C和汇编进行混合编程, 为了使用这项技术, 必须在VS的环境中安装好cmake组件 由于大部分人不会使用C/C与汇编进行混合编程的情况。所以这篇文章并不适用于绝大部分人不会对其中具体细节进行过多叙述。只是做一些简单的…...

缓存预热!真香
预热一般指缓存预热,一般用在高并发系统中,为了提升系统在高并发情况下的稳定性的一种手段。 缓存预热是指在系统启动之前或系统达到高峰期之前,通过预先将常用数据加载到缓存中,以提高缓存命中率和系统性能的过程。缓存预热的目…...

VS中设置#define _CRT_SECURE_NO_WARNINGS的原因和设置方式
原因: 在编译老的用C语言的开源项目的时候,可能因为一些老的.c文件使用了strcpy,scanf等不安全的函数,而报警告和错误,而导致无法编译通过。 解决方案: 我们有两种解决方案: 1、在指定的源文件的开头定…...

RK3566安卓11开发板千兆网卡RTL8211F移植避坑指南:从原理图到DTS配置全流程
RK3566安卓11平台RTL8211F千兆网卡移植实战:硬件原理到DTS配置的深度解析 当开发者需要在RK3566安卓11平台上实现千兆以太网功能时,RTL8211F PHY芯片的移植往往成为关键挑战。不同于简单的驱动加载,实际项目中常会遇到"软件配置看似正常…...

Nintendo Switch游戏备份终极指南:用nxdumptool轻松提取你的游戏收藏
Nintendo Switch游戏备份终极指南:用nxdumptool轻松提取你的游戏收藏 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/…...

FPGA硬解 vs 软件模拟:实测MiSTer在延迟和画质上到底强在哪?
FPGA硬解 vs 软件模拟:实测MiSTer在延迟和画质上到底强在哪? 在复古游戏的世界里,每一帧的延迟都可能决定《拳皇97》中一个连招的成败,每一像素的偏差都会影响《魂斗罗》子弹轨迹的判断。当硬核玩家们争论FPGA方案与软件模拟孰优孰…...

用FPGA驱动TDC-GPX2做高精度时间测量:一个基于XC7A35T的完整Verilog状态机实现
基于XC7A35T的TDC-GPX2高精度时间测量系统:状态机设计与工程实践 在精密时间测量领域,TDC-GPX2作为一款高分辨率时间数字转换芯片,配合FPGA的灵活控制能力,能够实现皮秒级的时间间隔测量。本文将深入探讨如何利用Xilinx Artix-7系…...

别再只跑仿真了!用Vivado 2023.1给你的FPGA图像处理项目做个“硬件体检”
从仿真到硬件的跨越:FPGA图像处理项目实战验证指南 在实验室里看着仿真波形完美无缺,却在开发板上遭遇各种"灵异事件"——这可能是每个FPGA开发者都经历过的成长仪式。仿真环境就像飞行模拟器,能教会你基本操作,但真正的…...

AntiDupl.NET:你的数字相册管家,如何智能清理重复图片?
AntiDupl.NET:你的数字相册管家,如何智能清理重复图片? 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾面对电脑中堆积如山…...

别再只会用pandas了!用openpyxl的load_workbook处理Excel,这些坑我帮你踩过了
别再只会用pandas了!用openpyxl的load_workbook处理Excel,这些坑我帮你踩过了 当Python开发者需要处理Excel文件时,pandas往往是首选工具——它简单、高效,能快速完成数据导入导出。但当你面对复杂格式的Excel文件,比…...

InfluxDB-从时序数据模型到实战:核心原理与Web UI高效入门
1. 时序数据库与InfluxDB初探 第一次接触时序数据库时,我盯着监控大屏上跳动的曲线发愣——这些每秒产生数万条记录的传感器数据,传统数据库根本扛不住。直到同事推荐了InfluxDB,这个专门为时间序列数据设计的数据库,才真正解决了…...
)
别再手动reshape了!用einops.rearrange优雅处理PyTorch张量维度(附实战代码)
用einops.rearrange重塑PyTorch张量:告别混乱的维度操作 深度学习开发中最令人头疼的莫过于张量维度的变换。你是否曾在凌晨三点盯着屏幕,试图理解自己昨天写的permute和reshape组合到底在做什么?或者花费半小时调试一个维度不匹配的错误&…...

为什么选择Hydrogen:对比传统电商平台的5大优势 [特殊字符]
为什么选择Hydrogen:对比传统电商平台的5大优势 🚀 【免费下载链接】hydrogen Hydrogen lets you build faster headless storefronts in less time, on Shopify. 项目地址: https://gitcode.com/gh_mirrors/hyd/hydrogen 在当今快速发展的电商领…...