人工智能学习与实训笔记(一):零基础理解神经网络
人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客
本篇目录
一、什么是神经网络模型
二、机器学习的类型
2.1 监督学习
2.2 无监督学习
2.3 半监督学习
2.4 强化学习
三、网络模型结构基础
3.1 单层网络
编辑
3.2 多层网络
3.3 非线性多层网络
四、 神经网络解决回归问题实操:使用Python和NumPy实现波士顿房价预测任务
一、什么是神经网络模型
简而言之:神经网络模型是拟合现实问题的函数方程,通过输入得到输出。
只不过这个函数是用神经网络的参数来拟合的,神经网络的参数是通过大量数据的训练获得,训练效果越好,则函数越逼近现实情况,就可以用来解决各种实际任务。
一个简单的网络模型函数如下:
y=w1*x1 + w2*x2 + w3*x3...
其中,y是函数值(模型输出的预测值),x1,x2, x3...是输入值(又叫特征值),w1, w2, w3...是网络参数。
机器学习最根本的目的在于训练出在某个问题上泛化能力强的模型。泛化能力强是指在某问题的所有数据上都能很好地反应输入和输出之间的关系,无论是训练数据,还是测试数据,还是任何属于该问题的未知数据
神经网络经常处理的问题包括:回归问题,图像分类问题,目标检测问题,自然语言处理,喜好推荐等等。
二、机器学习的类型
根据训练期间接受的监督数量和监督类型,可以将机器学习分为以下四种类型:监督学习、非监督学习、半监督学习和强化学习。
2.1 监督学习
在监督学习中,提供给算法的包含所需解决方案的训练数据,成为标签或标记。

简单地说,就是监督学习是包含自变量和因变量(有Y),同时可以用于分类和回归。下来常见的算法都是监督学习算法。
- K近邻算法
- 线性回归
- logistic回归
- 支持向量机(SVM)
- 决策树和随机森林
- 神经网络
2.2 无监督学习
无监督学习的训练数据都是未经标记的,算法会在没有指导的情况下自动学习。

简单地说,就是训练数据只有自变量没有因变量(就是没有Y)。
无监督学习的常见算法如下:
- 聚类算法
- K均值算法(K-means)
- 基于密度的聚类方法(DBSCAN)
- 最大期望算法
- 可视化和降维
- 主成分分析
- 核主成分分析
- 关联规则学习
- Apriori
- Eclat
比如说,我们有大量的购物访客的数据,包括一个月内的到达次数、购买次数、平均客单价、购物时长、购物种类、数量等,我们可以通过聚类算法,自动的把这些人分成几个类别,分类后,我们可以人工的把这些分类标记,如企业客户、家庭主妇等,也可以分成更细的分类。

另一种任务是降维,降维的目的在于不丢失太多的信息的情况下简化数据。方法之一就是讲多个特征合并为一个特征,特变是特征之间存在很大的相关性的变量。如汽车的里程和使用年限是存在很大的相关性的,所以降维算法可以将它们合并为一个表示汽车磨损的特征。这个过程就叫做特征提取。
另一个典型的无监督学习的是异常检测,如可以从检测信用卡交易中发现异常,并且这些异常我们实现没有标记的,算法可以自动发现异常。

2.3 半监督学习
有些算法可以处理部分标记的训练数据,通常是大量未标记的数据和少量标记的数据,这种成为半监督学习。
如照片识别就是很好的例子。在线相册可以指定识别同一个人的照片(无监督学习),当你把这些同一个人增加一个标签的后,新的有同一个人的照片就自动帮你加上标签了。
大多数半监督学习算法都是无监督和监督算法的结合。例如深度信念网络(DBN)基于一种相互堆叠的无监督式组件。
2.4 强化学习
强化学习是一个非常与众不同的算法,它的学习系统能够观测环境,做出选择,执行操作并获得回报,或者是以负面回报的形式获得惩罚。它必须自行学习什么是最好的策略,从而随着时间推移获得最大的回报。

例如,许多机器人通过强化学习算法来学习如何行走。AlphaGo项目也是一个强化学习的好例子。
三、网络模型结构基础
3.1 单层网络
(输入层) --w--> (输出层)
3.2 多层网络
(输入层) --w--> (隐含层) --w--> (隐含层) ... --> (输出层)
3.3 非线性多层网络
单层网络和多层网络默认只能表达线性变换,加入非线性激活函数后,可以表达非线性函数:
(输入层) --w--> (隐含层) --> (激活函数) --w--> (隐含层) --> (激活函数) ... --> (输出层)

加入非线性激励函数后,神经网络就有可能学习到平滑的曲线来分割平面,而不是用复杂的线性组合逼近平滑曲线来分割平面,使神经网络的表示能力更强了,能够更好的拟合目标函数。 这就是为什么我们要有非线性的激活函数的原因。
关于激活函数,可以参考:卷积神经网络中的激活函数sigmoid、tanh、relu_卷积神经网络激活函数_chaiky的博客-CSDN博客
四、 神经网络解决回归问题实操:使用Python和NumPy实现波士顿房价预测任务
神经网络模型预测数据中比较常见的是回归问题,根据输入的数值得到输出的数值。使用Python来实现波士顿房价预测是AI课程里类似“hello world”的经典入门案例,主要有以下一些要点需注意:
1. 样本数据需要归一化,使得后续的神经网络模型参数可表征有效的权重。样本数据归一化是以列(特征值)为单位的。注意,在用测试集测试模型时,模型输出的函数预测值需要进行反归一化。
2. 数据集划分:80%用于训练,20%用于测试,训练和测试数据集必须分开,才能验证网络的有效性。
3. 影响波士顿房价的样本数据有13个特征值,每个特征值会有不同的权重,因此神经网络模型的可调参数为13个,分别代表不同特征值对最终房价影响的权重:y=w1*x1 + w2*x2 + ... +w13*x13
4. 损失函数是模型输出的值与样本数据中实际值偏差的一种表达函数,损失函数的选择既要考虑准确衡量问题的“合理性”,也还要考虑“易于优化求解”。
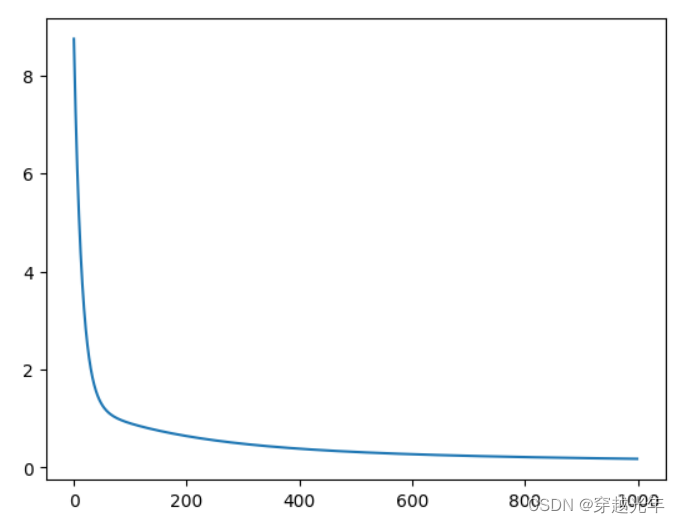
5. 训练过程就是通过不断调整网络模型参数,将损失函数的值降到最小(收敛)的过程, 损失函数的收敛需要通过梯度下降法来不断训练。以房价预测任务为例,影响房价的特征值有13个,因此我们需要调教的模型参数也是13个,这13个特征值和损失函数的值共同构成一个14维的空间,在这个空间中存在一个方向(13个参数构成向量决定这个方向)使得损失函数的值(预测值和实际值之偏差)下降最快。我们步进地将13个参数构成的向量朝此方向做出微调,再重新计算损失函数的值,如此往复,直到损失函数的值收敛趋于最小,则参数训练完成。
6. 数据集采用分批训练的方式,batch的取值会影响模型训练效果,batch过大,会增大内存消耗和计算时间,且训练效果并不会明显提升(每次参数只向梯度反方向移动一小步,因此方向没必要特别精确);batch过小,每个batch的样本数据没有统计意义,计算的梯度方向可能偏差较大。由于房价预测模型的训练数据集较小,因此将batch设置为10

Python源码 - 波士顿房价模型训练及测试:
# 导入需要用到的package
import numpy as np
import json
import matplotlib.pyplot as pltdef load_data():# 从文件导入数据datafile = './work/housing.data'data = np.fromfile(datafile, sep=' ')# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio)training_data = data[:offset]# 计算训练集的最大值,最小值(找的是每一列的极值)global maximums, minimums#maximums, minimums = data.max(axis=0), data.min(axis=0)maximums, minimums = training_data.max(axis=0), training_data.min(axis=0)#print("max:", maximums, "min:", minimums)# 对数据进行归一化处理,按列归一化处理for i in range(feature_num):data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])#print("归一化后的数据:\n", data)# 训练集和测试集的划分比例training_data = data[:offset]test_data = data[offset:]return training_data, test_data# 获取数据
training_data, test_data = load_data()
x = training_data[:, :-1] #所有行+所有列(除了最后一列)
y = training_data[:, -1:] #所有行+最后一列#w = [1, 2, 3] #shape = (3,)
#w = [[1], [2], [3]] #shape = (3,1)
#w = [[1,1], [2,2], [3,3]] #shape = (3,2)
#x = np.array(w)
# 查看数据
#print(x.shape)
#print(y.shape)class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,# 此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)#print("init self.w", self.w)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.b #x是[404,13]的矩阵(404行,13列), w是[13, 1]的矩阵(13行,1列),做点乘return zdef loss(self, z, y):error = z - y#print(error.shape)cost = error * errorcost = np.mean(cost)return costdef gradient(self, x, y):z = self.forward(x)gradient_w = (z-y)*x #梯度公式gradient_w = np.mean(gradient_w, axis=0) #对各列求均值gradient_w = gradient_w[:, np.newaxis]gradient_b = (z - y)gradient_b = np.mean(gradient_b) return gradient_w, gradient_bdef update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_bdef train(self, x, y, iterations=100, eta=0.01):losses = []for i in range(iterations):z = self.forward(x)L = self.loss(z, y)gradient_w, gradient_b = self.gradient(x, y)self.update(gradient_w, gradient_b, eta)losses.append(L)if (i+1) % 10000 == 0:print('iter {}, loss {}'.format(i, L))return losses# 运行模式一:每次用所有数据进行训练
train_data, test_data = load_data()
x = train_data[:, :-1]
#print("x.shape:", x.shape)
y = train_data[:, -1:]
# 创建网络
net = Network(13)
num_iterations=100000
# 启动训练
losses = net.train(x,y, iterations=num_iterations, eta=0.01)# 画出损失函数的变化趋势
"""
plot_x = np.arange(num_iterations)
plot_y = np.array(losses)
plt.plot(plot_x, plot_y)
plt.show()
"""#对数据做反归一化处理
def restore_data(d):d = d* (maximums[-1] - minimums[-1]) + minimums[-1]return round(d,2)#用测试集做测试
print("测试集测试结果:")
x = test_data[:, :-1]
y = test_data[:, -1:]
z = net.forward(x)
print("样本数据", "\t", "预测数据")
print("-------------------------")
for i in range(x.shape[0]):print(restore_data(y[i][0]), "\t\t", restore_data(z[i][0]))相关文章:
人工智能学习与实训笔记(一):零基础理解神经网络
人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客 本篇目录 一、什么是神经网络模型 二、机器学习的类型 2.1 监督学习 2.2 无监督学习 2.3 半监督学习 2.4 强化学习 三、网络模型结构基础 3.1 单层网络 编辑 3.2 多层网络 3.3 非线性多层网络…...

LeetCode刷题小记 一、【数组】
LeetCode刷题小记 一、【数组】 文章目录 LeetCode刷题小记 一、【数组】写在前面1. 数组1.1 理论基础1.2 二分查找1.3 移除元素1.4 有序数组的平方1.5 长度最小的子数组1.6 螺旋矩阵II Reference 写在前面 本系列笔记主要作为笔者刷题的题解,所用的语言为Python3&…...

iOS总体框架介绍和详尽说明
iOS是由苹果公司开发的移动操作系统,为iPhone、iPad、iPod Touch等设备提供支持。iOS采用了基于Unix的核心(称为Darwin),并采用了类似于Mac OS X的图形用户界面。以下是iOS的总体框架介绍和详尽说明: UIKit框架&#…...

【C++】const与constexpr详解
1. constexpr:常量表达式 所谓常量表达式,指的就是由多个(≥1)常量组成的表达式。换句话说,如果表达式中的成员都是常量,那么该表达式就是一个常量表达式。这也意味着,常量表达式一旦确定,其值将无法修改。 实际开发中,我们经常会…...
)
蓝桥杯:日期统计讲解(C++)
日期统计 本题来自于:2023年十四届省赛大学B组真题 主要考察:暴力。 代码放在下面,代码中重要的细节全都写了注释,非常清晰明了: #include <bits/stdc.h> //万能头文件 using namespace std;int main() {…...
中的正则表达式包含多个括号时的返回值——包含元组的列表)
Python re.findall()中的正则表达式包含多个括号时的返回值——包含元组的列表
当re.findall()中的正则表达式包含多个括号时,返回值是一个列表,其中每个元素都是一个元组。这个元组的长度与正则表达式中括号的数量相同,元组中的每个元素都是与相应括号中的模式匹配的文本。 import re # 定义一个包含三个括号的正则表达…...
Python——列表
一、列表的特性介绍 列表和字符串⼀样也是序列类型的数据 列表内的元素直接⽤英⽂的逗号隔开,元素是可变的,所以列表是可变的数据类型,⽽字符串不是。 列表的元素可以是 Python 中的任何类型的数据对象。如:字符串、…...

无人机图像识别技术研究及应用,无人机AI算法技术理论,无人机飞行控制识别算法详解
在现代科技领域中,无人机技术是一个备受瞩目的领域。随着人们对无人机应用的需求在不断增加,无人机技术也在不断发展和改进。在众多的无人机技术中,无人机图像识别技术是其中之一。 无人机图像识别技术是利用计算机视觉技术对无人机拍摄的图像…...

清华AutoGPT:掀起AI新浪潮,与GPT4.0一较高下
引言: 随着人工智能技术的飞速发展,自然语言处理(NLP)领域迎来了一个又一个突破。最近,清华大学研发的AutoGPT成为了业界的焦点。这款AI模型以其出色的性能,展现了中国在AI领域的强大实力。 目录 引言&…...
人工智能学习与实训笔记(二):神经网络之图像分类问题
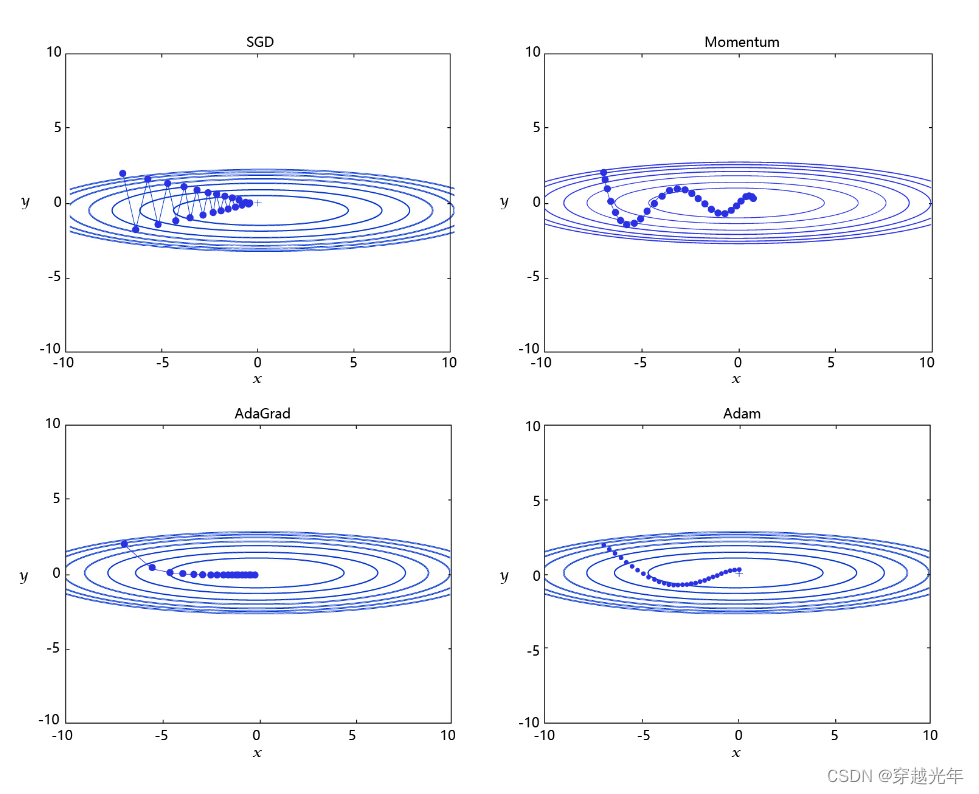
人工智能专栏文章汇总:人工智能学习专栏文章汇总-CSDN博客 目录 二、图像分类问题 2.1 尝试使用全连接神经网络 2.2 引入卷积神经网络 2.3 分类函数Softmax 2.4 交叉熵损失函数 2.5 学习率优化算法 2.6 图像预处理算法 2.6.1 随机改变亮暗、对比度和颜色等 …...
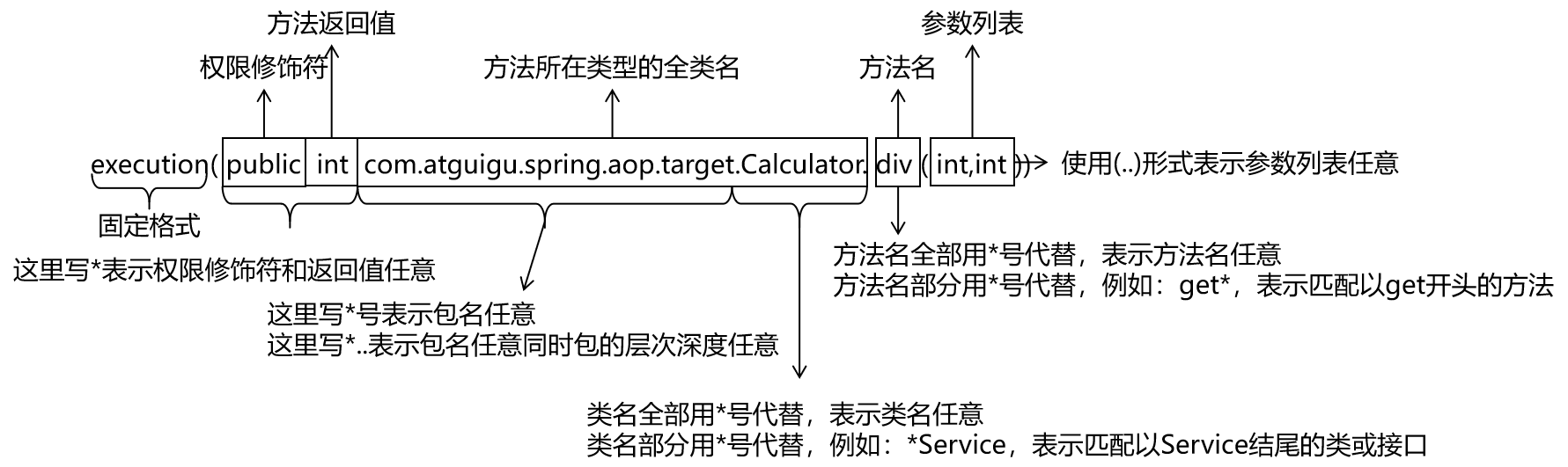
SSM框架,spring-aop的学习
代理模式 二十三种设计模式中的一种,属于结构型模式。它的作用就是通过提供一个代理类,让我们在调用目标方法的时候,不再是直接对目标方法进行调用,而是通过代理类间接调用。让不属于目标方法核心逻辑的代码从目标方法中剥离出来…...

【设计模式】4、策略模式
文章目录 一、问题二、解决方案2.1 真实世界的类比2.2 策略模式结构2.3 适用场景2.4 实现方式2.5 优缺点2.6 与其他模式的关系 三、示例代码3.1 go3.2 rust 策略模式是一种行为设计模式,它能定义一系列算法,把每种算法分别放入独立的类中,以是…...

【C++学习手札】多态:掌握面向对象编程的动态绑定与继承机制(深入)
🎬慕斯主页:修仙—别有洞天 ♈️今日夜电波:世界上的另一个我 1:02━━━━━━️💟──────── 3:58 🔄 ◀️ ⏸ ▶️ ☰ &am…...

【机构vip教程】Android SDK手机测试环境搭建
Android SDK 的安装和环境变量的配置 前置条件:需已安装 jdk1.8及 以上版本 1、下载Android SDK,解压后即可(全英文路径);下载地址:http://tools.android-studio.org/index.php/sdk 2、新建一个环境变量&…...
2024.2.18
使用fgets统计给定文件的行数 #include<stdio.h> #include<string.h> int main(int argc, const char *argv[]) {FILE *fpNULL;if((fpfopen("./test.txt","w"))NULL){perror("open err");return -1;}fputc(h,fp);fputc(\n,fp);fput…...

Haproxy实验
环境: servera(Haproxy):192.168.233.132 serverb(web1):192.168.233.144 serverc(web2):192.168.233.140 serverd(客户端):192.168.233.141 servera(Haproxy): yum install haproxy -y vim /etc/haproxy/haproxy.cfg(配置文件) # 设置日志&#…...
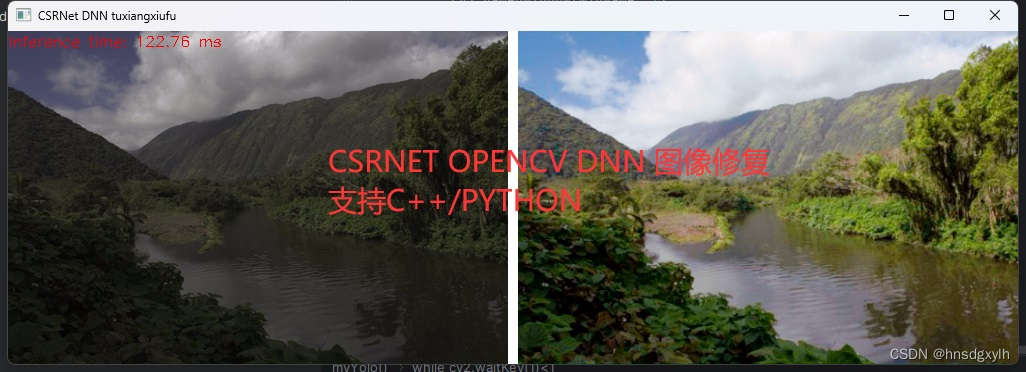
CSRNET图像修复,DNN
CSRNET图像修复 CSRNET图像修复,只需要OPENCV的DNN...
004 - Hugo, 分类
004 - Hugo, 分类content文件夹 004 - Hugo, 分类 content文件夹 ├─.obsidian ├─categories │ ├─Python │ └─Test ├─page │ ├─about │ ├─archives │ ├─links │ └─search └─post├─chinese-test├─emoji-support├─Git教程├─Hugo分类├─…...

Vue3之ElementPlus中Table选中数据的获取与清空方法
Vue3之ElementPlus中Table选中数据的获取与清空方法 文章目录 Vue3之ElementPlus中Table选中数据的获取与清空方法1. 点击按钮获取与清空选中表格的数据1. 用到ElementPlus中Table的两个方法2. 业务场景3. 操作案例 1. 点击按钮获取与清空选中表格的数据 1. 用到ElementPlus中…...

Leetcode 516.最长回文子序列
题意理解: 给你一个字符串 s ,找出其中最长的回文子序列,并返回该序列的长度。 子序列定义为:不改变剩余字符顺序的情况下,删除某些字符或者不删除任何字符形成的一个序列。 回文理解为元素对称的字串,这里…...

【亲测免费】 Zebra打印机中文转ZPL指令的.NET实现
Zebra打印机中文转ZPL指令的.NET实现 【下载地址】Zebra打印机中文转ZPL指令的.NET实现 本项目提供了一个用于将中文文本转换为ZPL指令的.NET实现,旨在替代Zebra官方提供的非托管组件FNTHEX32.DLL。该组件在托管环境下需要额外的封装,并且缺乏64位程序的…...

基于Unity的地牢游戏开发
1.数字字符串转数字System.Globalization.NumberStyles hexNum; // 专门的枚举成员,解析16进制字符串 hexNum System.Globalization.NumberStyles.HexNumber;int.Parse(tileNums[i], hexNum);2.注意:文件读取是从上到下,而 Unity y轴 …...

S32K3开发板三色LED点灯实战:从引脚配置到代码烧录的保姆级避坑指南
S32K3开发板三色LED点灯实战:从引脚配置到代码烧录的保姆级避坑指南 当一块崭新的S32K3开发板摆在面前,闪烁的LED往往是开发者与之对话的第一个"Hello World"。本文将带你用最直观的方式——控制RGB三色灯,快速建立对NXP这款车规级…...

模力方舟与口袋龙虾:开源中国的AI云端与端侧协同生态解析
本文解析开源中国通过“模力方舟”与“口袋龙虾”平台构建的AI协同生态。该生态旨在解决AI开发与落地中的资源分散与端侧部署难题,为开发者、企业及终端用户提供从云端资源调用到边缘智能部署的一站式通路。核心结论是,这种“云-边-端”协同模式降低了技…...

如何通过QuickLookVideo实现Mac视频预览效率革命:终极工具深度解析
如何通过QuickLookVideo实现Mac视频预览效率革命:终极工具深度解析 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: ht…...

27考研er必备的那些学习工具!
对2027考研人来说,备考不是简单地“埋头刷题”,而是一场关于信息筛选、资源整合、时间管理和学习效率的长期战役。面对公共课、专业课、院校信息、经验帖、课程资源等海量内容,选对工具往往能让复习少走弯路。 以下这些平台和网站,…...

如何用BilibiliDown轻松搞定B站视频下载:新手到高手的完整指南
如何用BilibiliDown轻松搞定B站视频下载:新手到高手的完整指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_m…...

从平面到立体:用ImageToSTL将照片变为可触摸的3D模型
从平面到立体:用ImageToSTL将照片变为可触摸的3D模型 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from the left side. …...

别再只盯着RRT了!关节空间六次多项式规划,可能是更简单的机械臂避障方案
关节空间六次多项式规划:机械臂避障的优雅解法 在工业机器人领域,路径规划一直是核心挑战之一。当机械臂需要在充满障碍物的环境中工作时,传统基于笛卡尔空间的规划方法常常面临逆运动学奇异、轨迹不平滑等问题。而基于关节空间的六次多项式规…...

抖音批量下载神器:一键保存多个创作者的所有视频作品
抖音批量下载神器:一键保存多个创作者的所有视频作品 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 在当前短视频内容爆炸的时代,抖音汇聚了无数创意视频和优质内容。无论是学习舞蹈…...