如何学习和规划类似ChatGPT这种人工智能(AI)相关技术
学习和规划类似ChatGPT这种人工智能(AI)相关技术的路径通常包括以下步骤:
-
学习基础知识:
- 学习编程:首先,你需要学习一种编程语言,例如Python,这是大多数人工智能项目的首选语言。
- 数学基础:深度学习和自然语言处理等领域需要一定的数学基础,包括线性代数、微积分和概率统计。
-
掌握机器学习和深度学习:
- 了解机器学习和深度学习的基本概念,例如神经网络、卷积神经网络(CNN)和递归神经网络(RNN)。
- 学习使用常见的深度学习框架,如TensorFlow或PyTorch。
-
掌握自然语言处理(NLP):
- 学习NLP的基础知识,包括词嵌入、词性标注、命名实体识别等。
- 熟悉常见的NLP任务和模型,如情感分析、命名实体识别和机器翻译。
-
了解生成式模型:
- 研究生成式模型,了解它们如何生成文本、图像或音频等内容。
- 学习使用生成式模型进行文本生成,如循环神经网络(RNN)或变换器模型(Transformer)。
-
实践项目和竞赛:
- 参与开源项目或竞赛,如Kaggle比赛,以应用所学知识并获得实践经验。
- 在构建自己的项目时,不断尝试解决现实世界中的问题,这将帮助你深入理解和应用所学概念。
-
持续学习和跟进:
- 人工智能领域发展迅速,持续学习和跟进最新的技术和研究成果至关重要。
- 阅读学术论文、关注领域内的顶尖会议和期刊,以及参与相关的在线社区和讨论。
记住,学习人工智能是一个持续的过程,需要不断地学习、实践和探索。通过坚持不懈地努力和充分利用资源,你将逐渐掌握类似ChatGPT这种AI相关技术。
制作一个简单的实例:
这里有一个简单的案例,展示了如何使用Python和TensorFlow来实现一个简单的文本生成器。
假设我们想要创建一个能够生成类似ChatGPT的简单文本生成器。我们可以使用基于循环神经网络(RNN)的字符级别语言模型来实现这个功能。
import tensorflow as tf
import numpy as np
import os
import time
# 读取文本文件
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')
# 读取并为 py2 compat 解码
text = open(path_to_file, 'rb').read().decode(encoding='utf-8')
# 文本长度是指文本中的字符个数
print ('文本长度: {} 个字符'.format(len(text)))
# 看一看文本中的前 250 个字符
print(text[:250])
# 文本中的非重复字符
vocab = sorted(set(text))
print ('{} 个独特的字符'.format(len(vocab)))
# 创建从非重复字符到索引的映射
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
text_as_int = np.array([char2idx[c] for c in text])
# 显示文本首 13 个字符的整数映射
print('{')
for char,_ in zip(char2idx, range(20)):
print(' {:4s}: {:3d},'.format(repr(char), char2idx[char]))
print(' ...\n}')
# 显示文本首 13 个字符的整数映射
print('{} ----字符映射为整数----> {}'.format(repr(text[:13]), text_as_int[:13]))
# 设定每个输入句子长度的最大值
seq_length = 100
examples_per_epoch = len(text)//(seq_length+1)
# 创建训练样本 / 目标
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
sequences = char_dataset.batch(seq_length+1, drop_remainder=True)
def split_input_target(chunk):
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
dataset = sequences.map(split_input_target)
# 批大小
BATCH_SIZE = 64
BUFFER_SIZE = 10000
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
# 字符集的长度
vocab_size = len(vocab)
# 嵌入的维度
embedding_dim = 256
# RNN 的单元数量
rnn_units = 1024
def build_model(vocab_size, embedding_dim, rnn_units, batch_size):
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim,
batch_input_shape=[batch_size, None]),
tf.keras.layers.GRU(rnn_units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'),
tf.keras.layers.Dense(vocab_size)
])
return model
model = build_model(
vocab_size=len(vocab),
embedding_dim=embedding_dim,
rnn_units=rnn_units,
batch_size=BATCH_SIZE)
for input_example_batch, target_example_batch in dataset.take(1):
example_batch_predictions = model(input_example_batch)
print(example_batch_predictions.shape, "# (batch_size, sequence_length, vocab_size)")
model.summary()
sampled_indices = tf.random.categorical(example_batch_predictions[0], num_samples=1)
sampled_indices = tf.squeeze(sampled_indices,axis=-1).numpy()
print("Input: \n", repr("".join(idx2char[input_example_batch[0]])))
print()
print("Next Char Predictions: \n", repr("".join(idx2char[sampled_indices ])))
def loss(labels, logits):
return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
example_batch_loss = loss(target_example_batch, example_batch_predictions)
print("Prediction shape: ", example_batch_predictions.shape, " # (batch_size, sequence_length, vocab_size)")
print("scalar_loss: ", example_batch_loss.numpy().mean())
model.compile(optimizer='adam', loss=loss)
# 检查点保存至的目录
checkpoint_dir = './training_checkpoints'
# 检查点的文件名
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True)
EPOCHS=10
history = model.fit(dataset, epochs=EPOCHS, callbacks=[checkpoint_callback])
这个示例使用了莎士比亚的一部分文本来训练模型。你可以根据自己的需求和兴趣来选择训练文本,并调整模型的参数以获取更好的结果。
抖动的声音:dilo_Abel
bilibili视频:dilo_Abel的个人空间-dilo_Abel个人主页-哔哩哔哩视频
相关文章:
相关技术)
如何学习和规划类似ChatGPT这种人工智能(AI)相关技术
学习和规划类似ChatGPT这种人工智能(AI)相关技术的路径通常包括以下步骤: 学习基础知识: 学习编程:首先,你需要学习一种编程语言,例如Python,这是大多数人工智能项目的首选语言。数学…...

4 月 9 日至 4 月 10 日,Hack.Summit() 2024 首聚香江
Hack.Summit() 是一系列 Web3 开发者大会。2024 年的活动将于 2024 年 4 月 9 日至 4 月 10 日在香港数码港举行。自十年前首次举办以来,此次会议标志着 Hack.Summit() 首次在亚洲举办,香港被选为首次亚洲主办城市,这对 Hack VC 和该地区都具…...
[力扣 Hot100]Day29 删除链表的倒数第 N 个结点
题目描述 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 出处 思路 两个指针间隔n,一趟遍历解决。 代码 class Solution { public:ListNode* removeNthFromEnd(ListNode* head, int n) {ListNode* phead;ListNode* …...
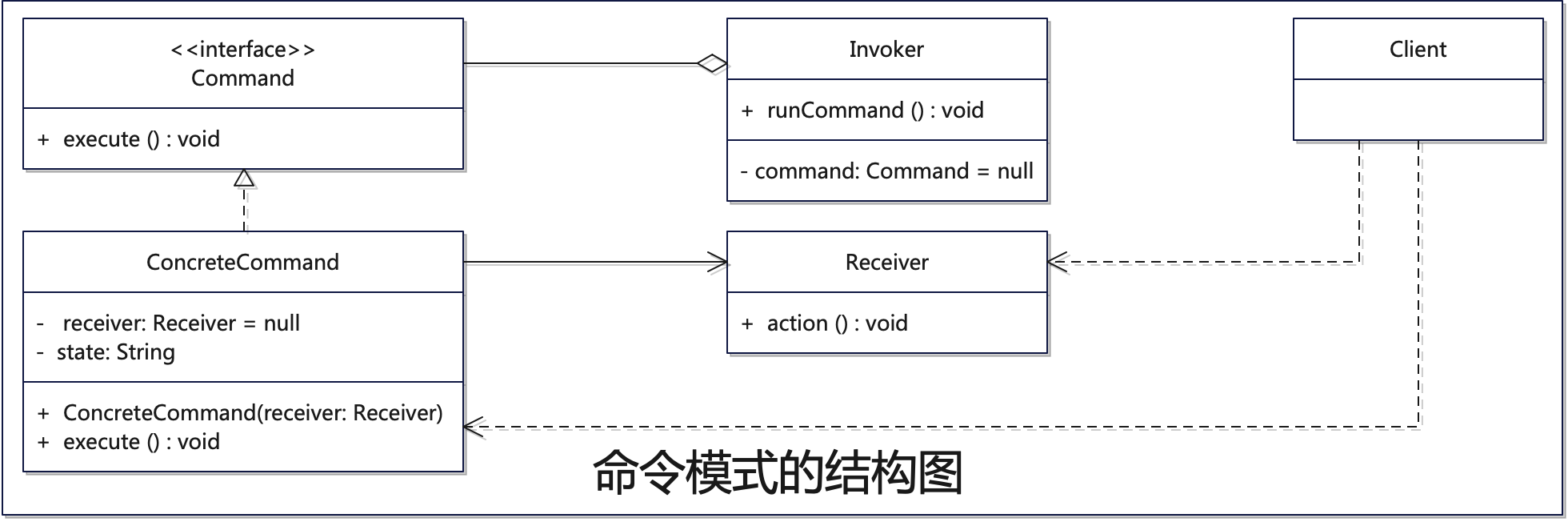
探索设计模式的魅力:掌握命令模式-解锁软件设计的‘遥控器’
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》 💪🏻 制定明确可量化的目标,并且坚持默默的做事。 引言:探索命令模式的奥秘 软件设计领域充满挑战与机遇,命令模式…...
LNMP搭建discuz论坛
discuz论坛是一种网络论坛软件,也称bbs,它是一种用于在互联网上建立论坛社区的程序系统。只哟中功能强大的论坛软件,可以帮助用户建立一个专业、完善的论坛社区,并且可以实现多种功能,如搭建用户注册、登录、查看主题、…...
)
257.【华为OD机试真题】幼儿园篮球游戏(贪心算法-JavaPythonC++JS实现)
🚀点击这里可直接跳转到本专栏,可查阅顶置最新的华为OD机试宝典~ 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目二.解题思路三.题解代码Python题解代码JAVA题解…...

[计算机网络]深度学习传输层TCP协议
💓 博客主页:从零开始的-CodeNinja之路 ⏩ 收录专栏:深度学习传输层TCP协议 🎉欢迎大家点赞👍评论📝收藏⭐文章 [计算机网络]深度学习传输层TCP协议 前提概括一: TCP协议段格式二:确认应答三:超时重传四:…...

动态头部:统一目标检测头部与注意力
摘要 在目标检测中,定位与分类相结合的复杂性导致了各种方法的蓬勃发展。以前的工作试图提高在不同的目标检测头的性能,但未能呈现一个统一的视图。在本文中,我们提出了一种新的动态头部框架来统一目标检测头部和注意力。通过在尺度感知的特…...
)
【状态估计】深度传感器与深度估计算法(1/3)
深度传感器与深度估计算法 深度传感器概念 获得空间中目标位置或距离的传感器,按接收的媒介波来源可分为主动式和被动式两大范畴,主动式包括激光雷达、雷达、超声波传感器等,被动式主要为单目、多目相机等,同时两大类可组合为混…...
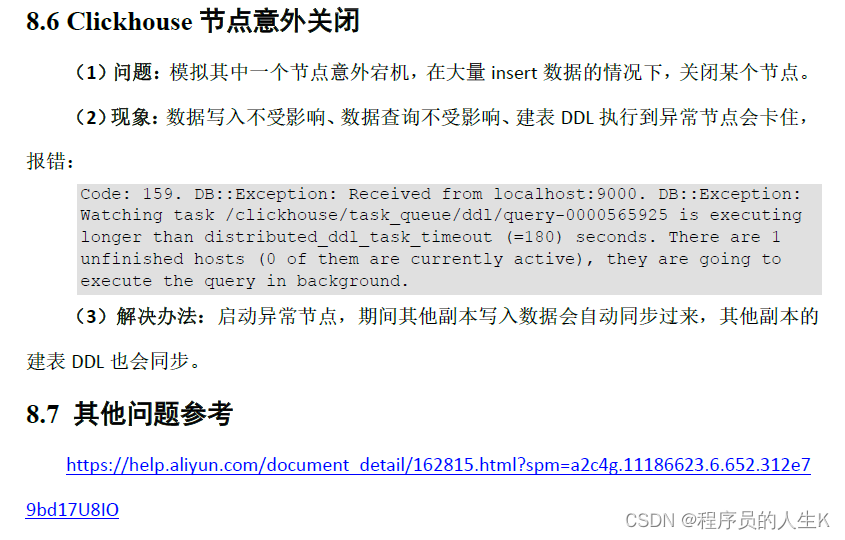
ClickHouse从入门到精通(高级)
第1章 Explain查看执行计划 第2章 建表优化 第3章 ClickHouse语法优化规则 第4章 查询优化 第5章 数据一致性(重点) 第6章 物化视图 第7章 MaterializeMySQL引擎 第8章 常见问题排查...

什么是Docker的容器编排工具,它们之间有何不同?
随着Docker容器技术的广泛应用,容器编排工具成为了自动化部署、扩展和管理容器化应用程序的关键组件。这些工具提供了一种抽象层,帮助开发者和管理员更高效地管理大量的Docker容器,确保它们在不同的主机和环境中能够可靠地运行。目前…...

qml之Control类型布局讲解,padding属性和Inset属性细讲
1、Control布局图 2、如何理解? *padding和*Inset参数如何理解呢? //main.qml import QtQuick 2.0 import QtQuick.Controls 2.12 import QtQuick.Layouts 1.12 import QtQuick.Controls 1.4 import QtQml 2.12ApplicationWindow {id: windowvisible: …...
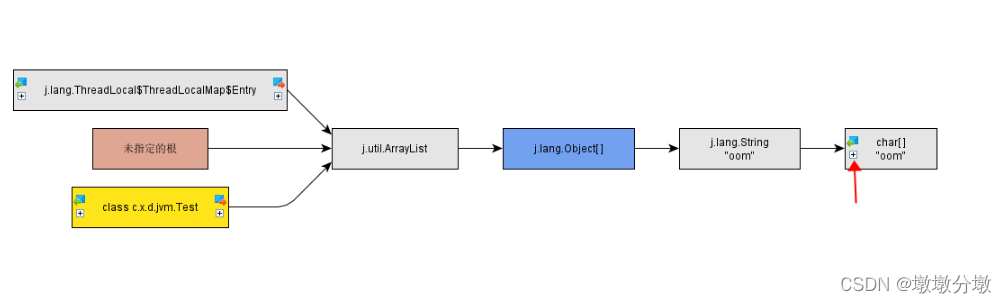
【Jvm】性能调优(拓展)Jprofiler如何监控和解决死锁、内存泄露问题
文章目录 Jprofiler简介1.安装及IDEA集成Jprofiler2.如何监控并解决死锁3.如何监控及解决内存泄露(重点)4.总结5.后话 Jprofiler简介 Jprofilers是针对Java开发的性能分析工具(免费试用10天), 可以对Java程序的内存,CPU,线程,GC,锁等进行监控和分析, 1.安装及IDEA集成Jprofil…...

运行错误(竞赛遇到的问题)
在代码提交时会遇见这样的错误: 此处运行错误不同于编译错误和答案错误,运行错误是指是由于在代码运行时发生错误,运行错误可能是由于逻辑错误、数据问题、资源问题等原因引起的。这些错误可能导致程序在运行时出现异常、崩溃。 导致不会显示…...

nodename nor servname provided, or not known
异常信息 在 Maven 打包过程中出现的 nodename nor servname provided, or not known 异常通常是由于 Maven 无法解析某个域名,这可能是因为网络问题、DNS 解析失败或者 Maven 配置中指定的仓库地址错误导致的。这个问题通常出现在 Maven 试图从远程仓库下载依赖时 …...

前端vue金额用逗号分隔
实现效果 代码 template部分 <el-input v-model"state.val"></el-input><div>{{ priceFor(state.val) }}</div> js部分 const state reactive({ val: });const priceFor (val)> {if(!val){return }else if(val.length<4){return…...
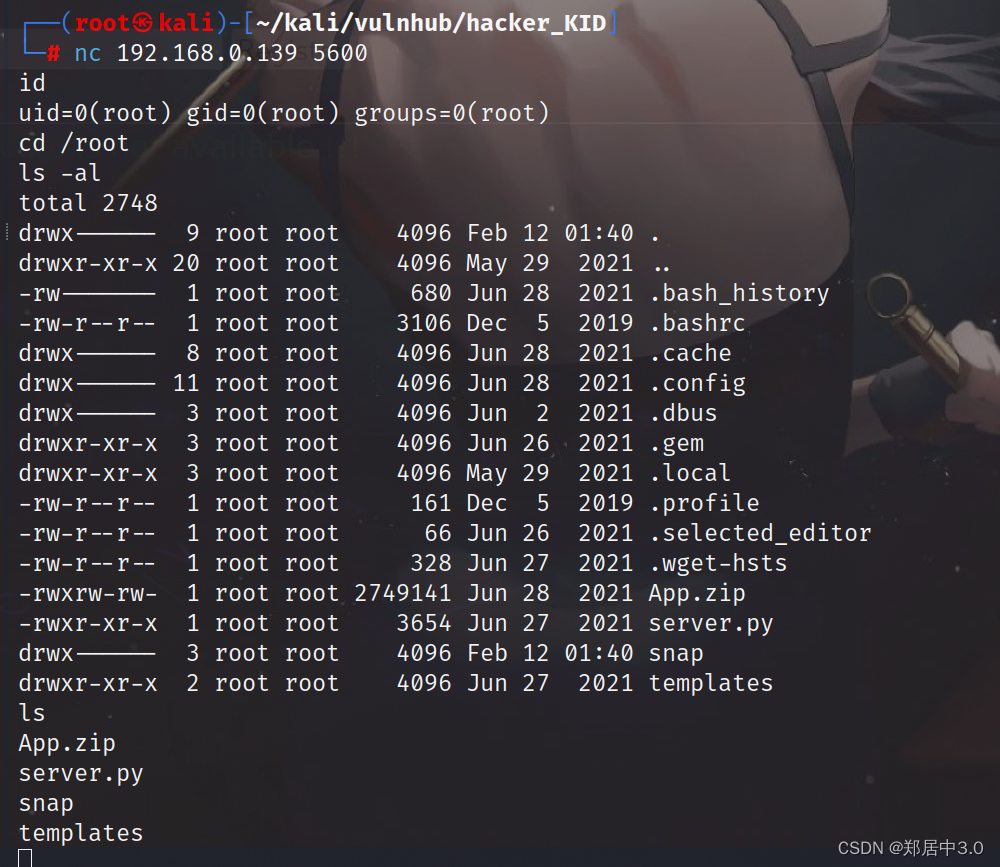
vulvhub-----Hacker-KID靶机
打靶详细教程 1.网段探测2.端口服务扫描3.目录扫描4.收集信息burp suite抓包 5.dig命令6.XXE漏洞读取.bashrc文件 7.SSTI漏洞8.提权1.查看python是否具备这个能力2.使用python执行exp.py脚本,如果提权成功,靶机则会开放5600端口 1.网段探测 ┌──(root…...
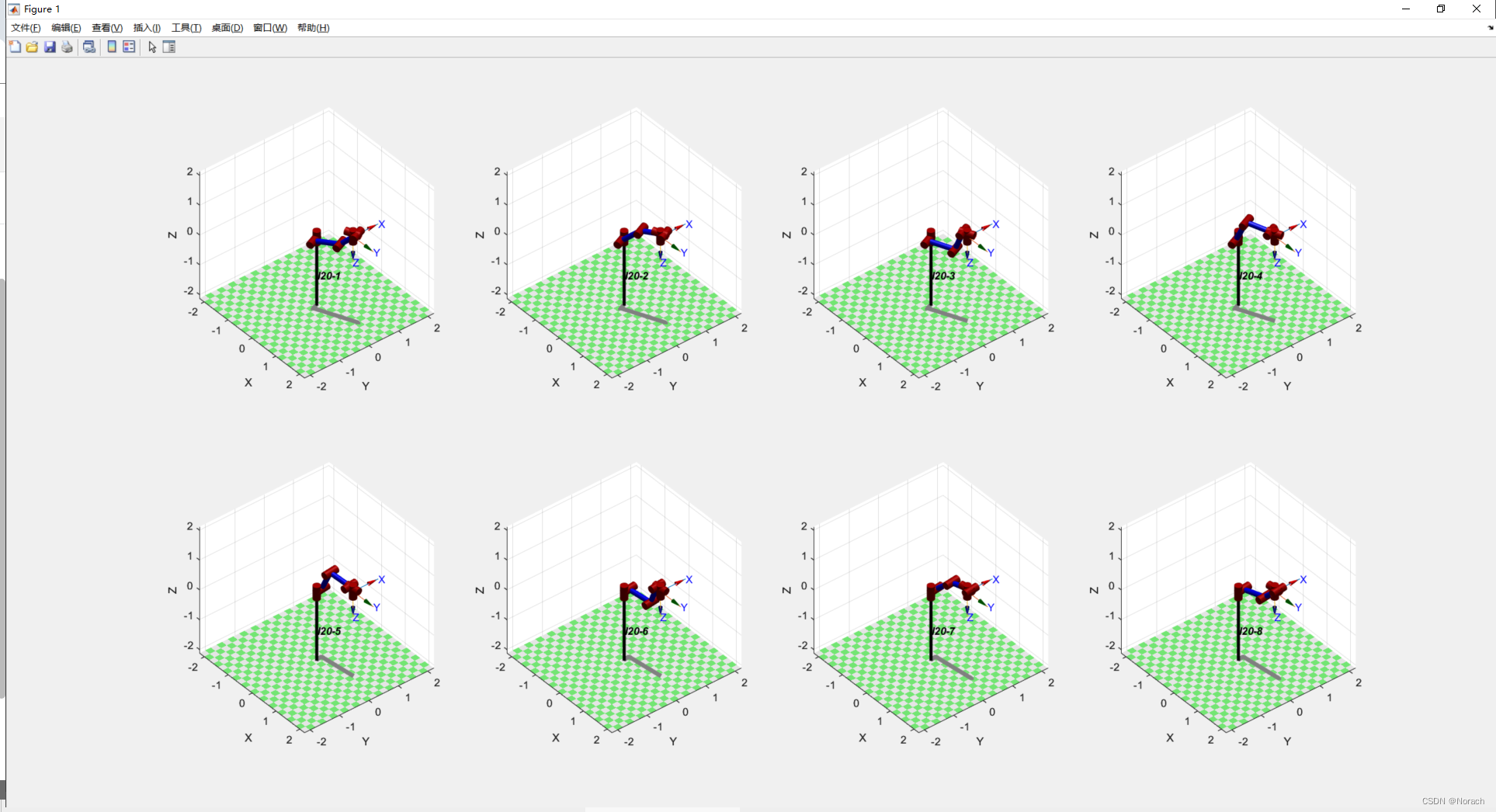
遨博I20协作臂关节逆解组Matlab可视化
AUBO I20协作臂关节逆解组Matlab可视化 前言1、RTB使用注意点2、代码与效果2.1、完整代码2.2、运行效果 总结 前言 注意:请预先配置好Matlab和RTB机器人工具箱环境,本文使用matlab2022b和RTB10.04版本 工作需要,使用matlab实现对六轴机械臂…...

力扣题目训练(15)
2024年2月8日力扣题目训练 2024年2月8日力扣题目训练507. 完美数520. 检测大写字母521. 最长特殊序列 Ⅰ221. 最大正方形237. 删除链表中的节点115. 不同的子序列 2024年2月8日力扣题目训练 2024年2月8日第十五天编程训练,今天主要是进行一些题训练,包括…...

PCB差模辐射是如何产生的
在电路应用中,高频时钟信号往往会采用差分线传输模式,其优点是在提高速率的同时减小功耗和提高抗扰度,因此,差模辐射就成为电路正常工作的结果,是电流流过导体形成的环路所产生,差模辐射模型可以被模拟为一个小环形天线,对于一个面积为A的小环路,载有电流Idm,在远场中…...

3大核心功能解析:LilToon如何让Unity卡通渲染变得简单又专业
3大核心功能解析:LilToon如何让Unity卡通渲染变得简单又专业 【免费下载链接】lilToon Feature-rich shaders for avatars 项目地址: https://gitcode.com/gh_mirrors/li/lilToon 如果你正在Unity中寻找一个既能满足专业需求又容易上手的卡通渲染解决方案&am…...

铸件去毛刺,伯朗特机器人带气动打磨头,恒力去除浇口残余
在铸造行业,无论是金属还是非金属铸件,脱模后都会不可避免地产生飞边、毛刺及浇口残余。这些瑕疵不仅影响产品外观,更可能妨碍后续装配,甚至在部件受力时成为应力集中点,影响产品使用寿命与安全性。传统的人工去毛刺作…...

Captain AI助力Ozon大卖店群高效管理,实现规模化运营
随着Ozon商家运营规模的扩大,多店铺运营(店群)成为很多资深大卖的选择,通过多店铺布局,可扩大市场覆盖、分散运营风险、提升整体销量。但店群运营过程中,商家常常面临“管理繁琐、数据混乱、效率低下”的问…...

告别假进度条!UE5蓝图实战:用自定义AssetManager实现真实关卡加载进度
UE5蓝图实战:打造真实关卡加载进度系统 在虚幻引擎5(UE5)游戏开发中,流畅的关卡加载体验对玩家沉浸感至关重要。许多开发者会遇到"假进度条"问题——进度条看似在动,实则与真实加载进度无关。本文将手把手教…...

ComfyUI Segment Anything:零门槛实现智能图像分割的完整指南
ComfyUI Segment Anything:零门槛实现智能图像分割的完整指南 【免费下载链接】comfyui_segment_anything Based on GroundingDino and SAM, use semantic strings to segment any element in an image. The comfyui version of sd-webui-segment-anything. 项目地…...
)
ArcGIS老用户看过来:手把手教你为ArcMap 10.x定制专属Word报告插件(基于AddIN开发)
ArcGIS老用户进阶指南:打造智能Word报告生成插件 在GIS行业深耕多年的专业人士都清楚,ArcMap 10.x系列依然是许多企业和机构的核心生产力工具。尽管Esri已经将重心转向ArcGIS Pro,但大量历史项目、定制化工作流和团队使用习惯使得ArcMap仍然活…...

QQ音乐解析工具终极指南:如何轻松获取全网音乐资源
QQ音乐解析工具终极指南:如何轻松获取全网音乐资源 【免费下载链接】MCQTSS_QQMusic QQ音乐解析 项目地址: https://gitcode.com/gh_mirrors/mc/MCQTSS_QQMusic 你是否厌倦了音乐平台的层层限制?想要畅听所有歌曲却不想支付高昂的会员费ÿ…...

C++ inline函数深度解析:从链接属性到性能优化的实战指南
1. 项目概述:为什么我们需要关注inline函数?在C项目里,尤其是那些对性能有极致追求的系统、游戏引擎或者高频交易框架中,你经常会看到代码里散落着inline关键字。新手可能会觉得它只是个“建议编译器内联”的提示符,有…...
)
从‘看’到‘穿透’:用Python实战解析不同SAR波段影像(以哨兵1号和林火监测为例)
从‘看’到‘穿透’:用Python实战解析不同SAR波段影像(以哨兵1号和林火监测为例) 当卫星划过天际,它携带的"眼睛"并非普通光学镜头,而是能穿透云层和黑暗的微波雷达。这种被称为合成孔径雷达(SAR…...

WaveTools深度解析:鸣潮性能调优与数据统计的技术实现
WaveTools深度解析:鸣潮性能调优与数据统计的技术实现 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 为什么传统游戏优化方法在鸣潮中失效? 我们在实际测试中发现,鸣潮…...