论文精读--对比学习论文综述
InstDisc
提出了个体判别任务,而且利用这个代理任务与NCE Loss去做对比学习从而得到了不错的无监督表征学习的结果;同时提出了别的数据结构——Memory Bank来存储大量负样本;解决如何对特征进行动量式的更新

翻译:
有监督学习的结果激励了我们的无监督学习方法。对于来自豹的图像,从已经训练过的神经网络分类器中获得最高响应的类都是视觉上相关的,例如,美洲虎和猎豹。无关语义标记,而是数据本身明显的相似性使一些类比其他类更接近。我们的无监督方法将这种按类判别的无监督信号发挥到了极致,并学习了区分单个实例的特征表示。
总结:
把每个实例(也就是图片)都看作一个类别,目标是学一种特征,从而让我们能把每一个图片都区分开来
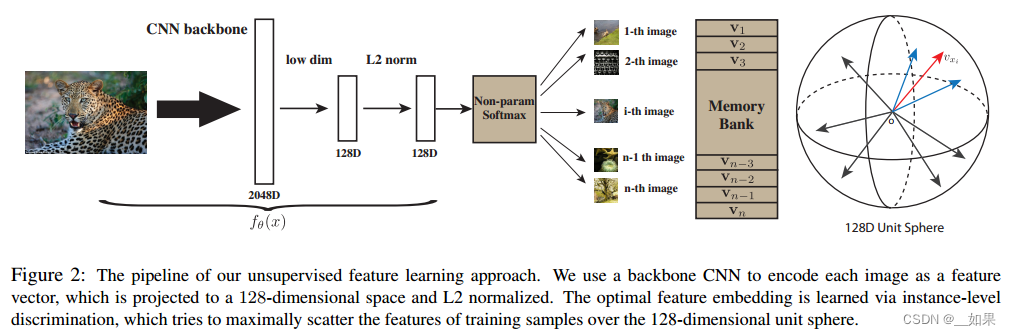
翻译:
这是无监督特征学习方法的整体流程。我们使用主干CNN将每张图像编码为特征向量,将其投影到128维空间并进行L2归一化。最优的特征嵌入是通过实例级判别来学习的,它试图最大限度地将训练样本的特征分散在128维单位球面上。
总结:
通过CNN把所有图片编码成特征,希望这些特征在最后的特征空间里能够尽可能的分开
利用对比学习训练CNN,正样本是图片本身(可能加一些数据增强),负样本则是数据集中其他图片
大量的负样本特征存在哪呢?运用Memory Bank的形式,把特征存进去,有多少特征就有多少行,因此特征的维度不能太大
Memory Bank随机初始化维单位向量
正样本利用CNN降低维度后,从Memory Bank中随机抽取负样本,然后可以用NCE Loss计算这个对比学习的目标函数,更新完网络后,可以把这些数据样本对应的特征放进Memory Bank更换掉
Proximal Regularization
给模型加了个约束,从而能让Memory Bank中的那些特征进行动量式的更新
Unlike typical classification settings where each class has many instances, we only have one instance per class.During each training epoch, each class is only visited once.
Therefore, the learning process oscillates a lot from random sampling fluctuation. We employ the proximal optimization method [29] and introduce an additional term to encourage the smoothness of the training dynamics. At current iteration t, the feature representation for data xi is computed from the network v (t) i = fθ(xi). The memory bank of all the representation are stored at previous iteration V = fv (t−1)g. The loss function for a positive sample from Pd is:
翻译:
与每个类有许多实例的典型分类设置不同,我们每个类只有一个实例。在每个训练阶段,每个类只访问一次。因此,学习过程在随机抽样波动中振荡很大。我们采用了最接近优化方法[29],并引入了一个额外的术语来鼓励训练动态的平滑性。在当前迭代t中,数据xi的特征表示是从网络v (t) i = fθ(xi)中计算出来的。所有表示的存储库都存储在前一次迭代V = fv (t−1)g。Pd阳性样本的损失函数为:
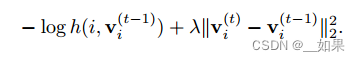
As learning converges, the difference between iterations, i.e. v (t) i − v (t−1) i , gradually vanishes, and the augmented loss is reduced to the original one. With proximal regularization, our final objective becomes:
翻译:
随着学习的收敛,迭代之间的差值即v (t) i - v (t - 1) i逐渐消失,增广损失减小到原始损失。通过近端正则化,我们的最终目标变成:
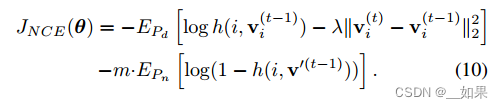
InvaSpreed
对于相似的图片,它的特征应该保持不变性;对不相似的图片,它的特征应该尽可能分散开
端到端;不需要借助外部数据结构去存储负样本
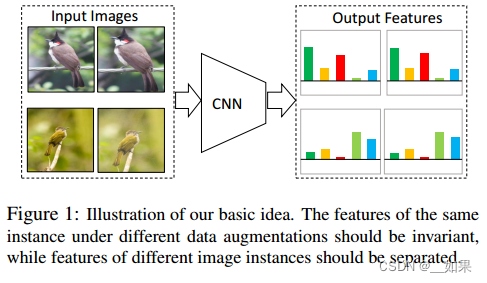
同样的图片通过编码器后得到的特征应该很相似,而不同的则不相似
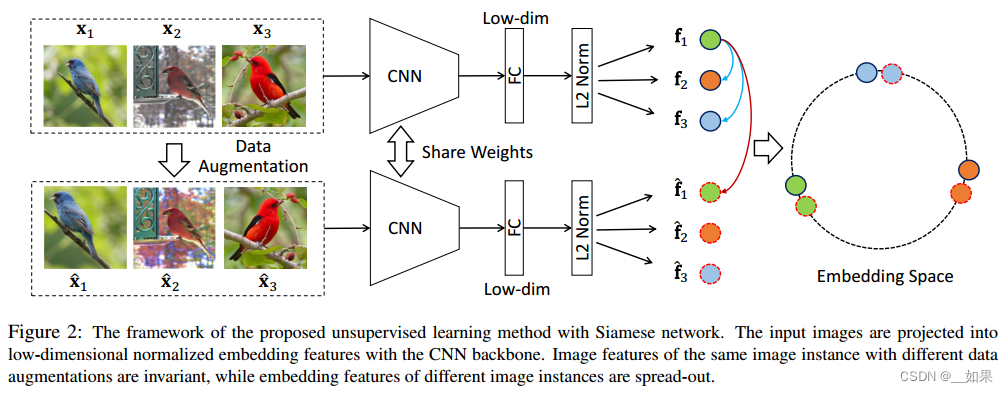
对X1来说,经过数据增强的X1‘就是它的正样本,负样本则是其他所有图片(包括数据增强后的)
为什么要从同一个mini-batch中选正负样本呢?这样就可以用一个编码器去做端到端的训练
图片过编码器再过全连接层,把特征维度降低,目标函数则使用NCE Loss的变体
之所以被SimCLR打败,是因为没有钞能力:mini-batch太小,导致负样本太少
CPC
以上两个都使用个体判别式的代理任务,CPC则是使用生成式的代理任务
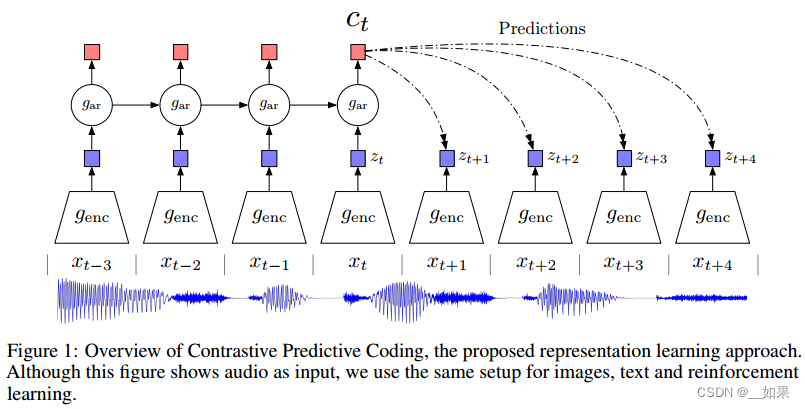
不光可以处理音频,还可以处理文字、图片、以及在强化学习中使用
我们有一个语音序列,从xt-3到xt代表过去到现在的输入,将其全扔给一个编码器,把编码器返回的特征喂给一个自回归模型gar(RNN或LSTM),得到ct(上下文的特征表示),如果ct足够好,那么认为它可以对未来的zt+1到zt+4做出合理预测
这里的正样本是未来的输入通过编码器得到的未来时刻的特征输出,也就是真正正确的zt+1到zt+4
负样本的定义倒是很广泛,任意输入通过编码器得到的特征输出都是负样本
CMC
定义正样本的方式更广泛:一个物体的很多视角都可以当作正样本
Abstract
Humans view the world through many sensory channels, e.g., the long-wavelength light channel, viewed by the left eye, or the high-frequency vibrations channel, heard by the right ear. Each view is noisy and incomplete, but important factors, such as physics, geometry, and semantics, tend to be shared between all views (e.g., a “dog” can be seen, heard, and felt). We investigate the classic hypothesis that a powerful representation is one that models view-invariant factors. We study this hypothesis under the framework of multiview contrastive learning, where we learn a representation that aims to maximize mutual information between different views of the same scene but is otherwise compact.
Our approach scales to any number of views, and is viewagnostic. We analyze key properties of the approach that make it work, finding that the contrastive loss outperforms a popular alternative based on cross-view prediction, and that the more views we learn from, the better the resulting representation captures underlying scene semantics. Our approach achieves state-of-the-art results on image and video unsupervised learning benchmarks.
翻译:
人类通过许多感官通道来观察世界,例如,左眼看到的长波长光通道,或右耳听到的高频振动通道。每个视图都是嘈杂和不完整的,但重要的因素,如物理,几何和语义,倾向于在所有视图之间共享(例如,可以看到、听到和感觉到“狗”)。我们研究了一个经典的假设,即一个强大的表示是一个模型的观点不变的因素。我们在多视图对比学习的框架下研究这一假设,在多视图对比学习中,我们学习的表征旨在最大化同一场景的不同视图之间的相互信息,但除此之外是紧凑的。
我们的方法适用于任意数量的视图,并且是视图不可知论的。我们分析了使其有效的方法的关键属性,发现对比损失优于基于交叉视图预测的流行替代方案,并且我们学习的视图越多,结果表示捕获底层场景语义的效果就越好。我们的方法在图像和视频无监督学习基准上取得了最先进的结果。
总结:
增大所有视觉间的互信息,从而学得一个能抓住不同视角下的关键因素的特征

选取的NYU RGBD数据集有四个视角,分别是原始的图像、图像对于的深度信息、surface normal(表面法线)、物体的分割图像
虽然输入来自于不同的视角,但都属于一张图片,因此这四个特征在特征空间中应该尽可能靠近,互为正样本;不配对的视角应该尽可能远离
相关文章:
论文精读--对比学习论文综述
InstDisc 提出了个体判别任务,而且利用这个代理任务与NCE Loss去做对比学习从而得到了不错的无监督表征学习的结果;同时提出了别的数据结构——Memory Bank来存储大量负样本;解决如何对特征进行动量式的更新 翻译: 有监督学习的…...
文章复现 | 差异分析和PPI网络构建
原文链接:差异分析和PPI网路图绘制教程 写在前面 在原文中,作者获得285个DEG,在此推文中共获得601个DEG。小杜的猜想是标准化的水段不同的原因吧,或是其他的原因。此外,惊奇的发现发表医学类的文章在附件中都不提供相…...

入门级10寸加固行业平板—EM-I10J
亿道信息以其坚固耐用的智能终端设备而闻名,近日发布了一款理想入门级 10 英寸加固平板电脑—I10J。 EM-I10J 这是一款 10 英寸的平板电脑,主要运行 Windows 10操作系统,带有硬化塑料外壳,具有 IP65 防水防尘功能和 MIL-STD 8…...

gem5 garnet 合成流量: packet注入流程
代码流程 下图就是全部. 剩下文字部分是细节补充,但是内容不变: bash调用python,用python配置好configuration, 一个cpu每个tick运行一次,requestport发出pkt. bash 启动 python文件并配置 ./build/NULL/gem5.debug configs/example/garnet_synth_traffic.py \--num-cpus…...
java实现排序算法(上)
排序算法 冒泡排序 时间和空间复杂度 要点 每轮冒泡不断地比较比较相邻的两个元素,如果它们是逆序的,则需要交换它们的位置下一轮冒泡,可以调整未排序的右边界,减少不必要比较 代码 public static int[] test(int[] array) {// 外层循环控制遍历次数for (int i 0; i <…...
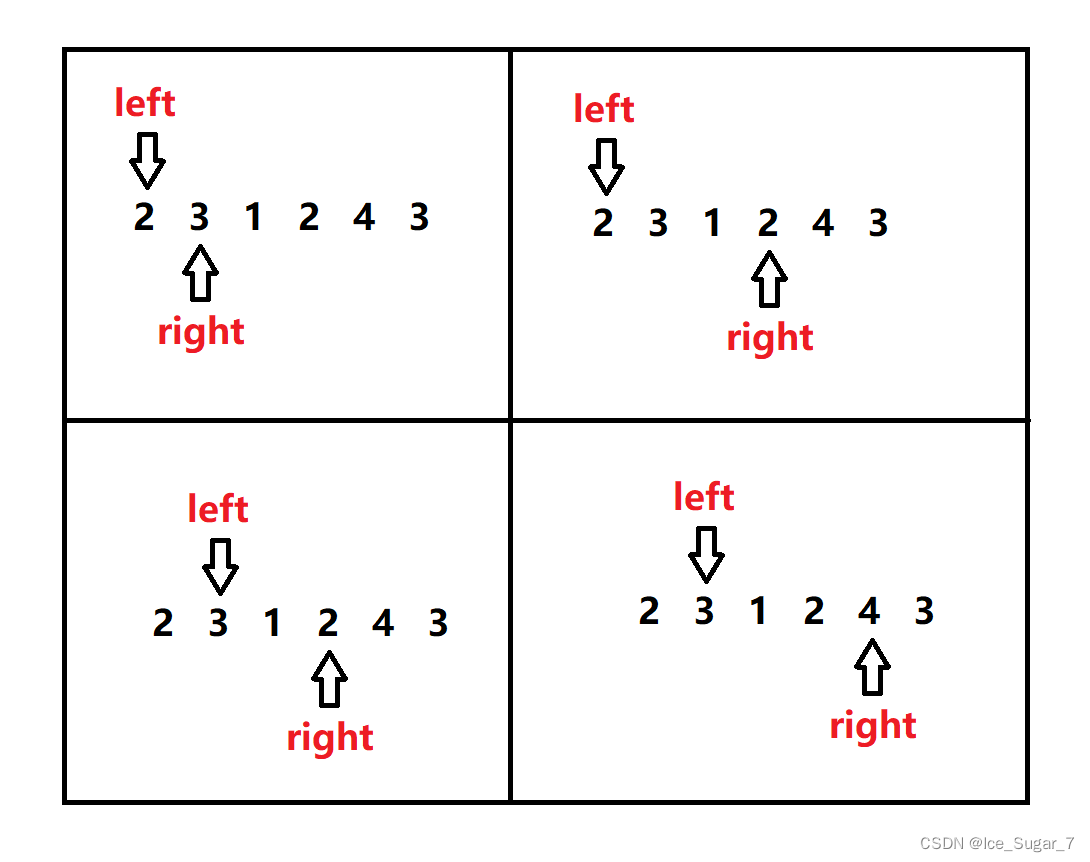
「算法」滑动窗口
前言 算法需要多刷题积累经验,所以我行文重心在于分析解题思路,理论知识部分会相对简略一些 正文 滑动窗口属于双指针,这两个指针是同向前行,它们所夹的区间就称为“窗口” 啥时候用滑动窗口? 题目涉及到“子序列…...

Windows11(非WSL)安装Installing llama-cpp-python with GPU Support
直接安装,只支持CPU。想支持GPU,麻烦一些。 1. 安装CUDA Toolkit (NVIDIA CUDA Toolkit (available at https://developer.nvidia.com/cuda-downloads) 2. 安装如下物件: gitpythoncmakeVisual Studio Community (make sure you install t…...

rtt设备io框架面向对象学习-脉冲编码器设备
目录 1.脉冲编码器设备基类2.脉冲编码器设备基类的子类3.初始化/构造流程3.1设备驱动层3.2 设备驱动框架层3.3 设备io管理层 4.总结5.使用 1.脉冲编码器设备基类 此层处于设备驱动框架层。也是抽象类。 在/ components / drivers / include / drivers 下的pulse_encoder.h定义…...
)
华为OD机试真题- 攀登者2-2024年OD统一考试(C卷)
题目描述: 攀登者喜欢寻找各种地图,并且尝试攀登到最高的山峰。地图表示为一维数组,数组的索引代表水平位置,数组的高度代表相对海拔高度。其中数组元素0代表地面。例如[0,1,4,3,1,0,0,1,2,3,1,2,1,0], 代表如下图所示的地图,地图中有两个山脉位置分别为 1,2,3,4,5和8,9,1…...
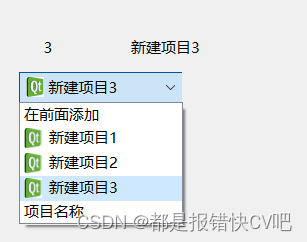
19.Qt 组合框的实现和应用
目录 前言: 技能: 内容: 1. 界面 2.槽 3.样式表 参考: 前言: 学习QCombox控件的使用 技能: 简单实现组合框效果 内容: 1. 界面 在ui编辑界面找到input widget里面的comboBoxÿ…...
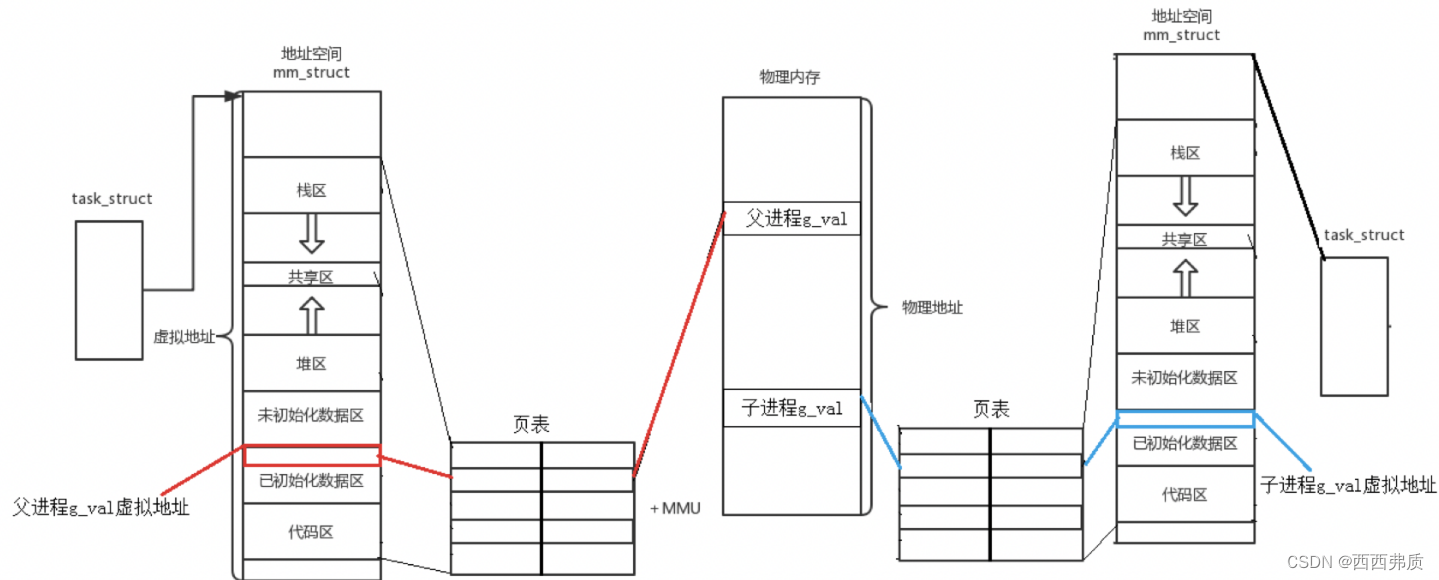
【Linux】进程地址空间的理解
进程地址空间的理解 一,什么是程序地址空间二,页表和虚拟地址空间三,为什么要有进程地址空间 一,什么是程序地址空间 在我们写程序时,都会有这样下面的内存结构,来存放变量和代码等数据。 一个进程要执行…...
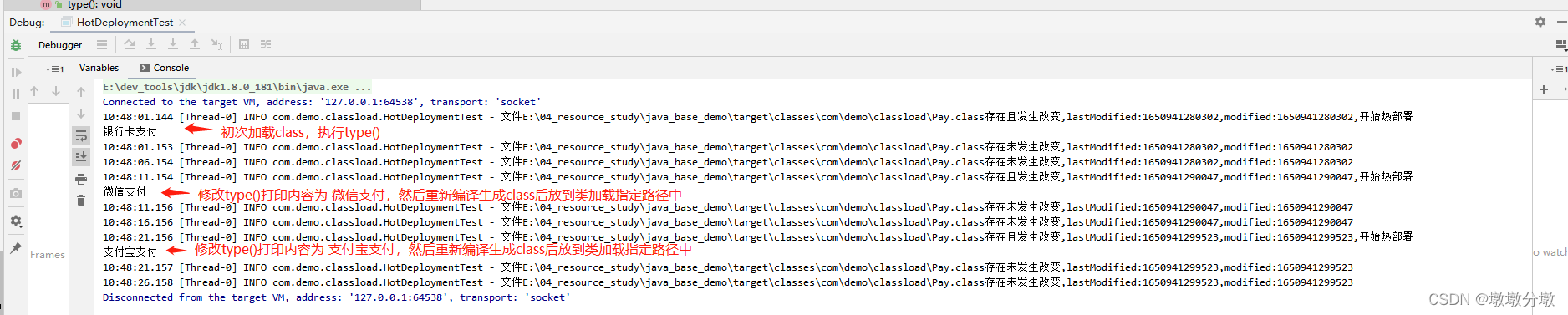
【Jvm】类加载机制(Class Loading Mechanism)原理及应用场景
文章目录 Jvm基本组成一.什么是JVM类的加载二.类的生命周期阶段1:加载阶段2:验证阶段3:准备阶段4:解析阶段5:初始化 三.类初始化时机四.类加载器1.引导类加载器(Bootstrap Class Loader)2.拓展类…...
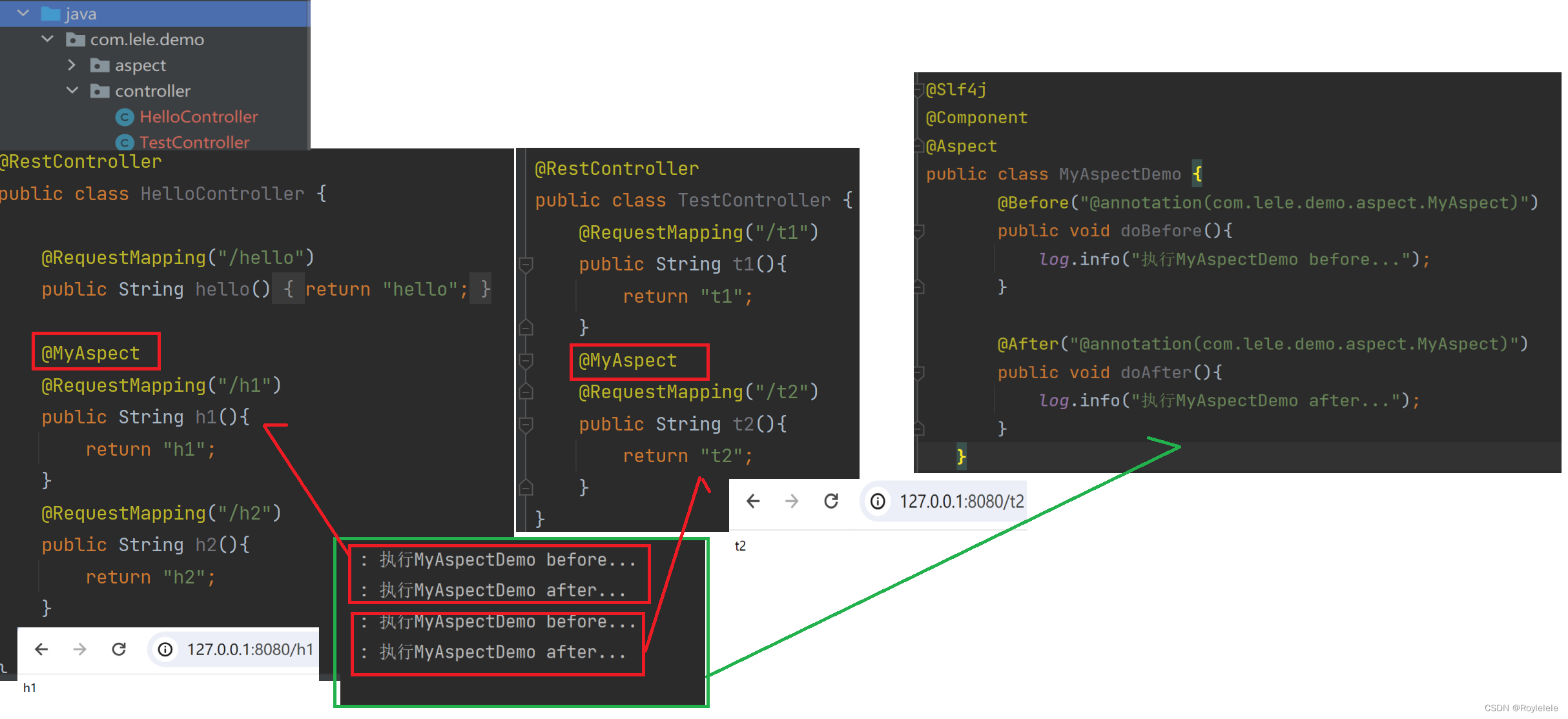
Spring AOP的实现方式
AOP基本概念 Spring框架的两大核心:IoC和AOP AOP:Aspect Oriented Programming(面向切面编程) AOP是一种思想,是对某一类事情的集中处理 面向切面编程:切面就是指某一类特定的问题,所以AOP可…...
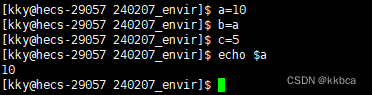
Linux------环境变量
目录 前言 一、环境变量 二、添加PATH环境变量 三、HOME环境变量 四、查看所有环境变量 1.指令获取 2.代码获取 2.1 getenv 2.2main函数的第三个参数 2.3 全局变量environ 五、环境变量存放地点 六、添加自命名环境变量 七、系统环境变量具有全局属性 八、环境变…...

计算机视觉所需要的数学基础
计算机视觉领域中使用的数学知识广泛而深入,以下是一些关键知识点及其在计算机视觉中的应用: 线性代数: - 矩阵运算:用于图像的表示和处理,如图像旋转、缩放、裁剪等。 - 向量空间:用于描述图像中的…...
ChatGPT魔法1: 背后的原理
1. AI的三个阶段 1) 上世纪50~60年代,计算机刚刚产生 2) Machine learning 3) Deep learning, 有神经网络, 最有代表性的是ChatGPT, GPT(Generative Pre-Trained Transformer) 2. 深度神经网络 llya Suts…...

【c/c++】获取时间
在一些应用的编写中我们有时候需要用到时间,或者需要一个“锚点”来确定一些数的值。在c/c中有两个用来确定时间的函数:time/gettimeofday 一、time time_t time(time_t *timer);time 函数返回当前时间的时间戳(自 1970 年 1 月 1 日以来经…...
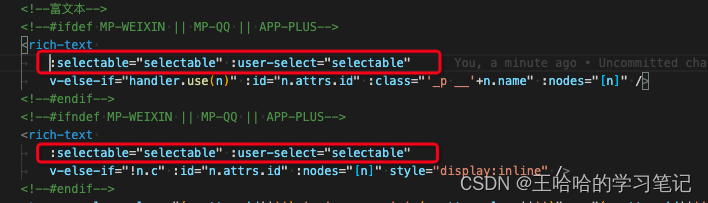
uniapp富文本文字长按选中(用于复制,兼容H5、APP、小程序三端)
方案:使用u-parse的selectable属性 <u-parse :selectable"true" :html"content"></u-parse> 注意:u-parse直接使用是不兼容小程序的,需要对u-parse进行改造: 1. 查看u-parse源码发现小程序走到以…...

常见的几种Web安全问题测试简介
Web项目比较常见的安全问题 1.XSS(CrossSite Script)跨站脚本攻击 XSS(CrossSite Script)跨站脚本攻击。它指的是恶意攻击者往Web 页面里插入恶意html代码,当用户浏览该页之时,嵌入其中Web 里面的html 代码会被执行,从而达到恶意用户的特殊…...
linux信号机制[一]
目录 信号量 时序问题 原子性 什么是信号 信号如何产生 引入 信号的处理方法 常见信号 如何理解组合键变成信号呢? 如何理解信号被进程保存以及信号发送的本质? 为什么要有信号 信号怎么用? 样例代码 core文件有什么用呢&#…...

机器学习_03_线性回归
线性回归一、概念与定位类型:监督学习、回归任务定义:用于建模【特征 X】与【连续标签 y】之间的【线性关系】核心思想:找一条直线(或超平面),让预测值 ŷ 与真实值 y 的【误差最小】二、模型形式一元线性回…...

Zotero期刊标签:从数据映射到视觉呈现的自动化实践
1. 科研文献管理的视觉化革命 作为一名常年泡在文献堆里的科研狗,我最头疼的就是面对几百篇PDF时那种无从下手的窒息感。直到三年前偶然发现Zotero的标签染色功能,才真正体会到什么叫"一眼定位关键文献"。想象一下:当你打开文献库&…...

从OBD到功能安全:聊聊Autosar Dem模块里故障数据的‘生老病死’与内存管理策略
从OBD到功能安全:Autosar Dem模块中故障数据的生命周期与内存博弈 当一辆现代汽车在道路上飞驰时,它的电子控制单元(ECU)内部正上演着无数微观的"生存游戏"。在Autosar Dem模块的内存空间中,每一个故障数据都如同有生命的个体&…...

CentOS 8.5最小化安装实战:为什么我只选Minimal Install,以及后续必装的10个软件包
CentOS 8.5最小化安装实战:为什么我只选Minimal Install,以及后续必装的10个软件包 当你面对CentOS 8.5安装界面中那个看似简单的"Software Selection"选项时,是否曾犹豫过该选择哪个?作为一个经历过无数次系统安装的老…...

终极指南:如何用Python实现手机号反查QQ号的3种高效方法
终极指南:如何用Python实现手机号反查QQ号的3种高效方法 【免费下载链接】phone2qq 项目地址: https://gitcode.com/gh_mirrors/ph/phone2qq 在数字身份管理日益复杂的今天,你是否遇到过忘记某个手机号绑定了哪个QQ账号的困扰?或者需…...

如何用N_m3u8DL-RE破解加密流媒体:跨平台下载的终极指南
如何用N_m3u8DL-RE破解加密流媒体:跨平台下载的终极指南 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

让旧款iPhone/iPad重获新生:Legacy-iOS-Kit终极使用指南
让旧款iPhone/iPad重获新生:Legacy-iOS-Kit终极使用指南 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...

KLayout 0.30.0:如何用这款专业版图工具提升你的集成电路设计效率
KLayout 0.30.0:如何用这款专业版图工具提升你的集成电路设计效率 【免费下载链接】klayout KLayout Main Sources 项目地址: https://gitcode.com/gh_mirrors/kl/klayout 如果你正在寻找一款既强大又灵活的开源集成电路版图查看与编辑工具,KLayo…...

3步掌握LRC歌词制作:开源工具的终极实践指南
3步掌握LRC歌词制作:开源工具的终极实践指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为制作精准同步的歌词文件而烦恼吗?传统歌词…...

STM32H743实战:用SN65HVD230驱动14个伺服电机,1M波特率稳如老狗
STM32H743与SN65HVD230构建高密度CANopen伺服控制系统的工程实践 在工业自动化与机器人控制领域,多轴协同运动控制对总线系统的实时性和稳定性提出了严苛要求。本文将深入剖析基于STM32H743微控制器与SN65HVD230 CAN收发器搭建的高密度伺服控制系统,分享…...