【Linux笔记】进程间通信之管道
一、匿名管道
我们在之前学习进程的时候就知道了一个概念,就是进程间是互相独立的,所以就算是两个进程是父子关系,其中一个进程退出了也不会影响另一个进程。
也因为进程间是互相独立的,所以两个进程间就不能直接的传递信息或者互相访问各自的资源,而如果想要让两个进程之间进行信息传递,就需要用到我们今天要讲的“进程间通信”。
实现进程间通信其实有很多种方法,我们今天讲的“管道”其实是一种早期的进程间通信方式,但是对于我们学习后面的进程间通信具有指导作用。
1.1、进程间通信的本质
进程间不能直接通信,但是我们知道操作系统是进程的管理者,如果我们想要让两个进程传递信息,我们可以让操作系统作为“中间人”啊。
所以一个进程想要和另一个进程传递信息,可以先将要传递的信息交给操作系统,再由操作系统将信息传递给另一个进程。
那么这个资源就必定会让两个进程都能访问到,所以进程间通信的本质是:让两个进程看到同一份资源!
而这份资源,通常是由操作系统提供的,而我们进程要讲的“管道”其实就是这一份资源,管道其实是一个文件。
1.2、匿名管道的原理
上面说到,管道其实是一个文件,那么想要通过匿名管道进程进程间通信就一定是要让两个进程同时打开这个匿名管道文件,所以一个进程想要个另一个进程进行信息传递,就可以先将信息写入到匿名管道文件中,另一个进程则是从这个匿名管道文件中读取。
而我们也知道,操作系统会为每一个被打开的文件创建一个文件缓冲区,所有向该文件中写入的内容都不是直接写入磁盘中,而是先存储在文件缓冲区中,所以匿名管道文件实际上只是通过缓冲区来实现信息的传递。事实上匿名管道文件也只能通过缓冲区来实现信息传递,而且匿名管道文件也并不需要在磁盘中存储。
此外,匿名管道文件还有一些特点:
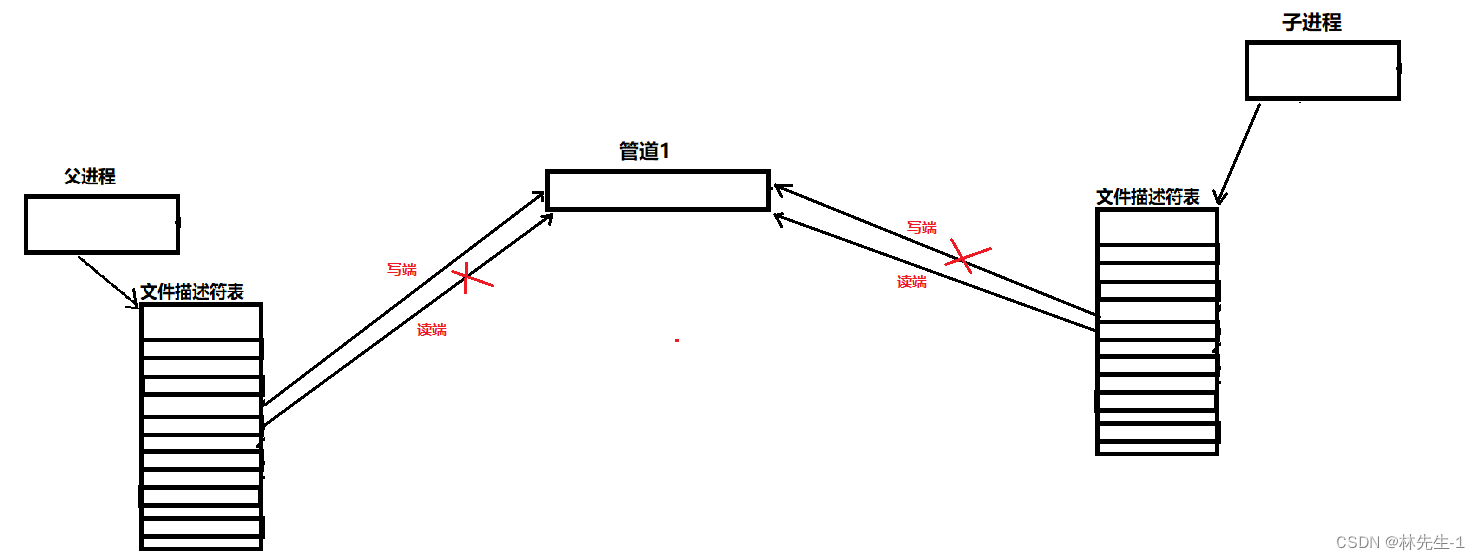
1、匿名管道文件是可以被同一个进程打开两次的文件
匿名管道文件打开两次其实并不是同一个匿名管道文件在内存中被加载两次,而是同一个匿名管道文件会有两个struct file结构体对象,一个用来读、一个用来写,分别是读端和写端。
如下图所示:
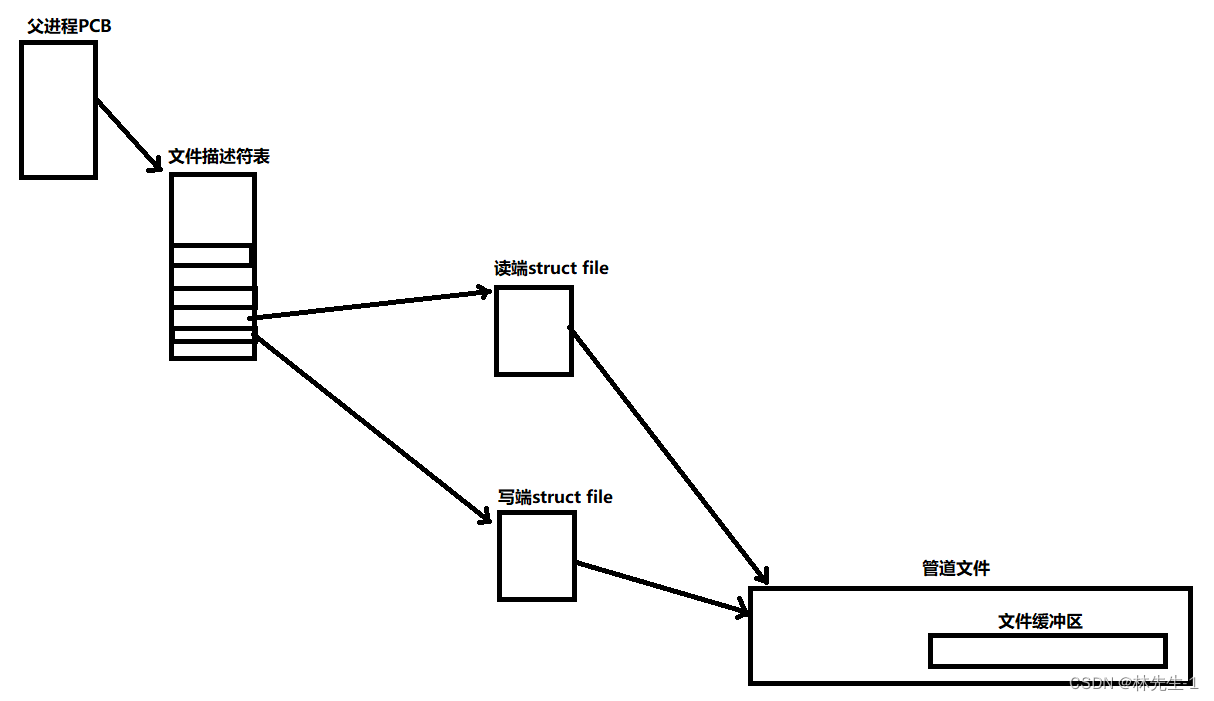
2、匿名管道只能完成具有亲缘关系的进程间的通信
这个特性其实是由匿名管道的“设计”而决定的,因为“匿名”管道其实也就是没有名字也没有路径的管道文件,因为这个文件没有名字也没有路径,这也就注定了其他进程不可能通过名字和路径找到该文件,再结合我们之前学过的文件描述符,我们也只能通过父进程创建子进程,然后子进程继承父进程的文件描述符表的方式让其他进程(子进程)拿到该文件的文件描述符,也就相当于找到了这个文件。
如下图所示:
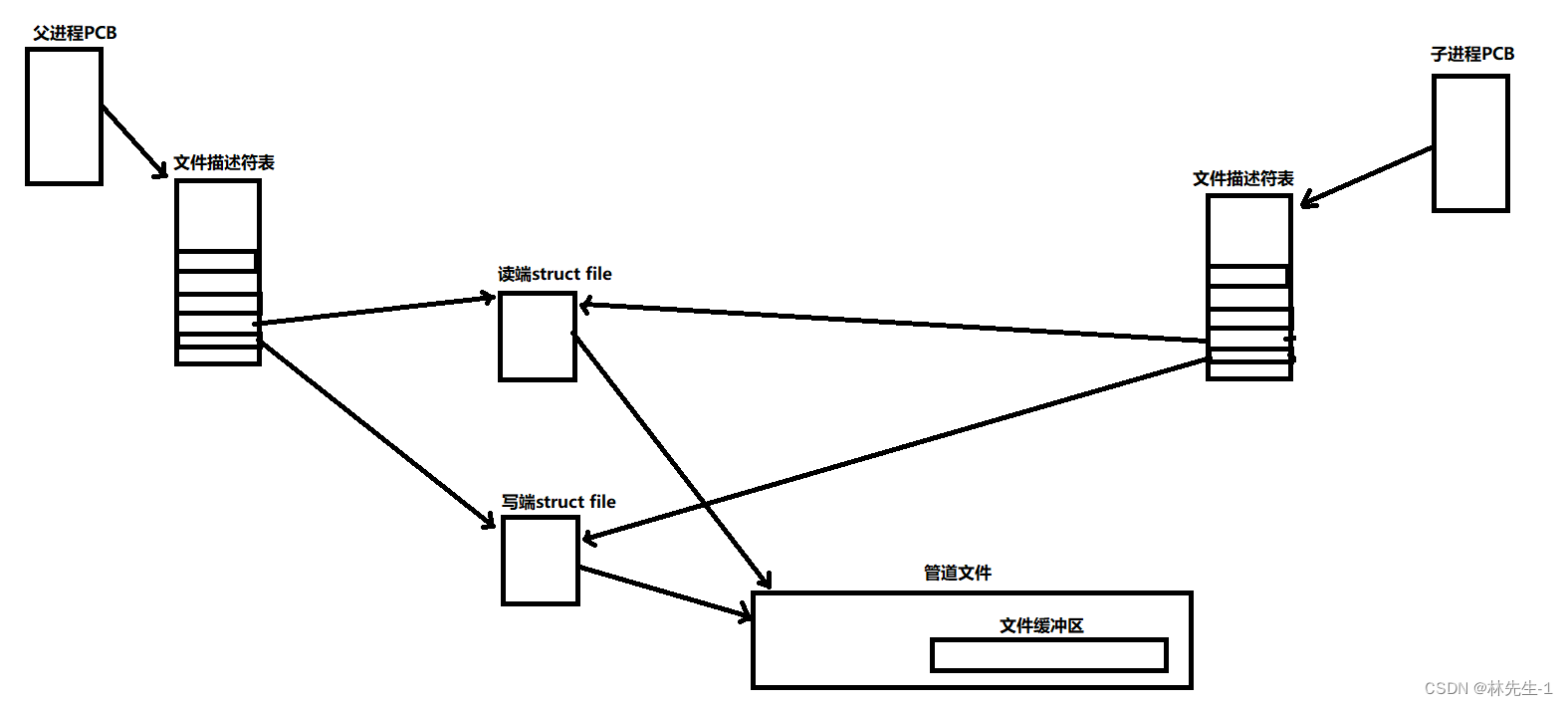
2、匿名管道文件只能实现单向通信
其实无论是匿名管道或命名管道都是只支持单向通信的,这样设计是为了更方便。
所以一旦确定了数据传输的方向,为了保险,我们就需要将父子进程多余的不需要的文件描述符关闭,比如我们进程想要让父进程向管道里写,让子进程从管道中读。那我们就需要将父进程的读端关闭,将子进程的写端关闭:
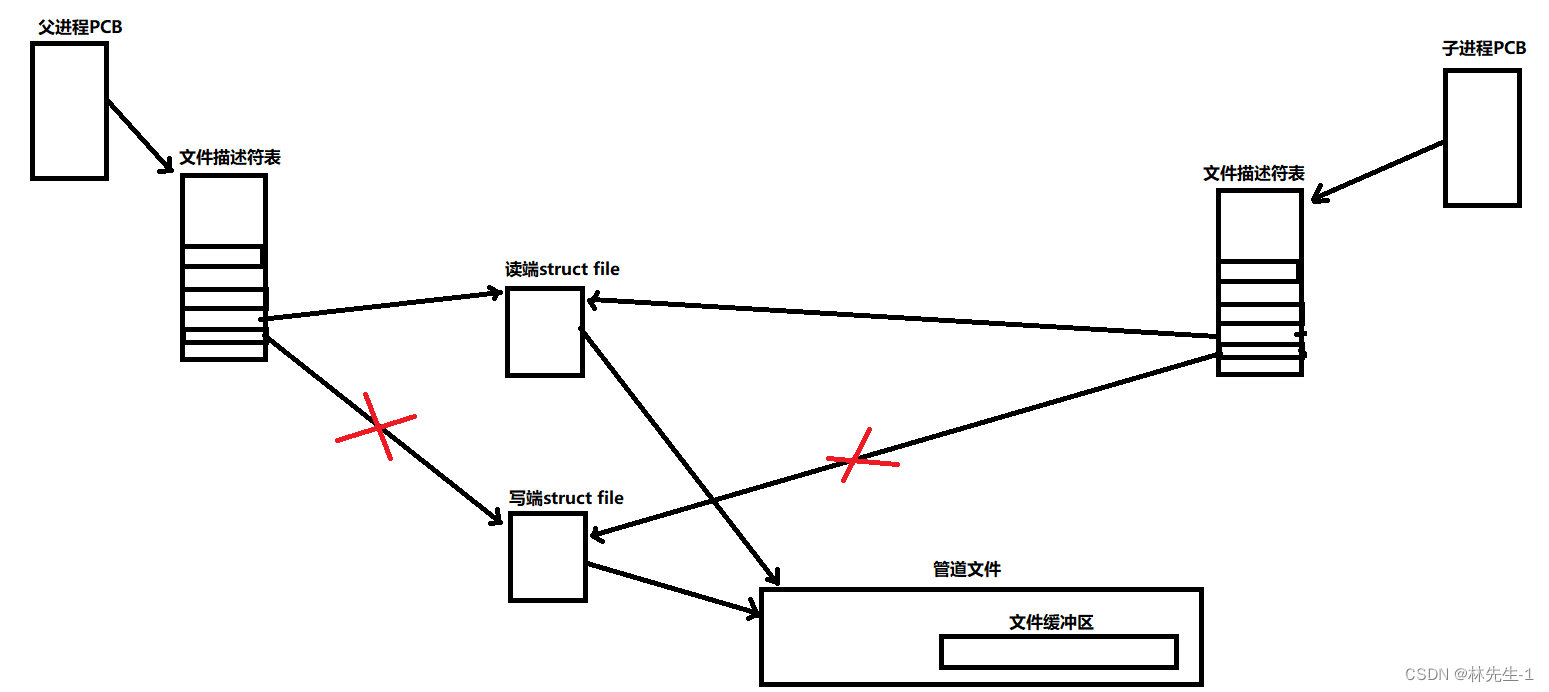
所以这也就是为什么一个匿名管道文件被打开的时候会将读端和写端都打开,因为只有这样我们才能让子进程也继承到读端和写端,后面也就能选择性的关闭相应的文件描述符从而形成特定方向的信道了。
1.3、匿名管道的使用与特性
想要在我们的程序中打开一个匿名管道文件,我们首先要认识一个系统调用接口:
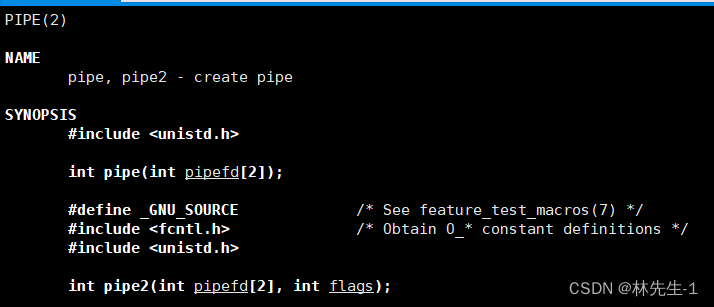

这个pipe会为我们打开一个匿名管道文件并返回读端和写端的文件描述符,只不过返回的文件描述符我们需要使用一个长度为2的文件描述符数组接收,也就是上面的pipefd[2],这个pipefd其实是一个输出型参数,并且规定,pipdfd[0]存储的是读端的文件描述符,pipefd[1]存储的是写端的文件描述符。
所以,有了上面这个接口和前面的理论,我们就可以在我们的程序中创建一个单向通讯的信道了,今天我们规定这个信道的方向是父进程读取,子进程写入:
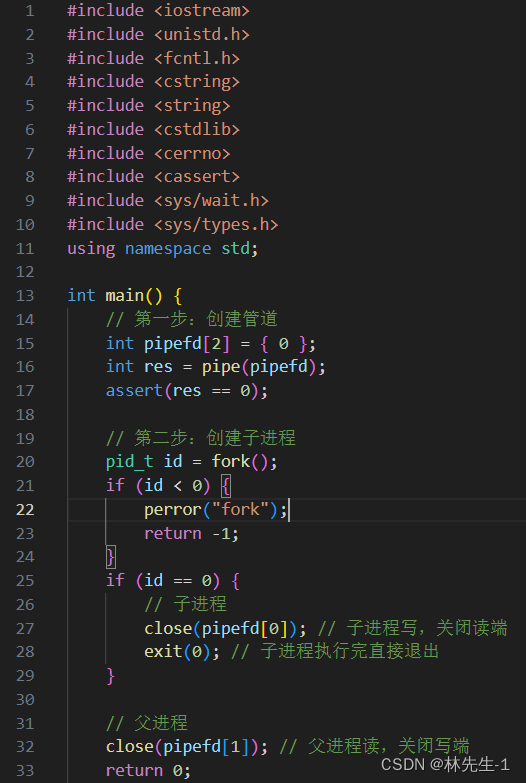
至此,我们就创建好了一个单向通信的信道,然后就可以进行进程间通信了。
我们先写一个简单的例子,让子进程一直向父进程发送动态的数据,并且让父进程读取并打印出来:

我们先运行一下试试:

但是运行后我们会发现打印出来的信息非常的乱,这是因为我们现在的写端写的太快了,一下自救把信息给写完了,所以读端一读就一下子将所有的信息都读了出来。
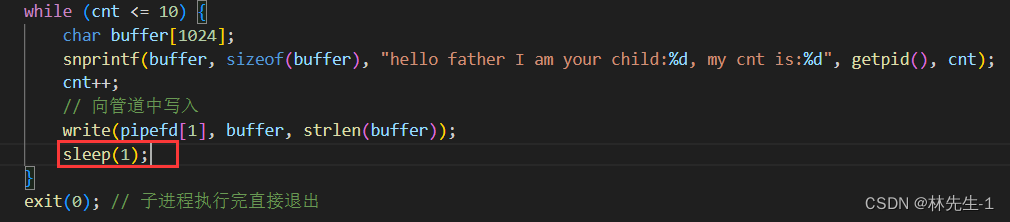
所以我们可以让写端写的慢一点,让它写完后暂停一秒:
我们再次运行:
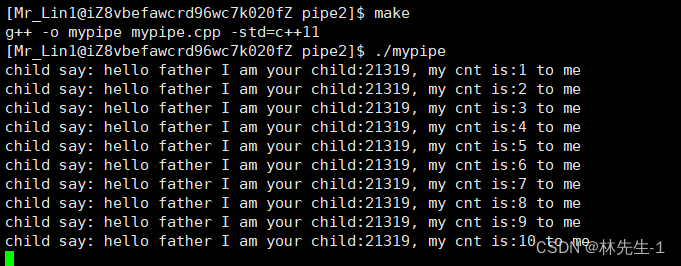
我们看到这次的运行就打印得好多了,但是后面确卡死了。
我们先不想为什么会卡死,大家难道没发现一个问题吗?
我们上面只是让子进程在写的时候暂停了,而并没有让父进程也暂停,按理说父进程也在一直打印啊,但为什么父进程也只打印了10次呢?
这是因为操作系统会默认给写端提供“同步”机制,也就是说当管道中没有数据时,读端必须等待,直到管道中有数据为止。
上面的读端虽然一直在读,但是我们现在的数据量很小,读端一读就将管道中所有的数据全都读完了,读完管道也就“清空”了,再次读的时候写端还没向管道中写数据,所以读端就只能等待。
注意是只有写端哦,也就是说只有读端会等待写端,而写端不会等待读端,就比如我们接下来让写端写的很快,而读端读得很慢:
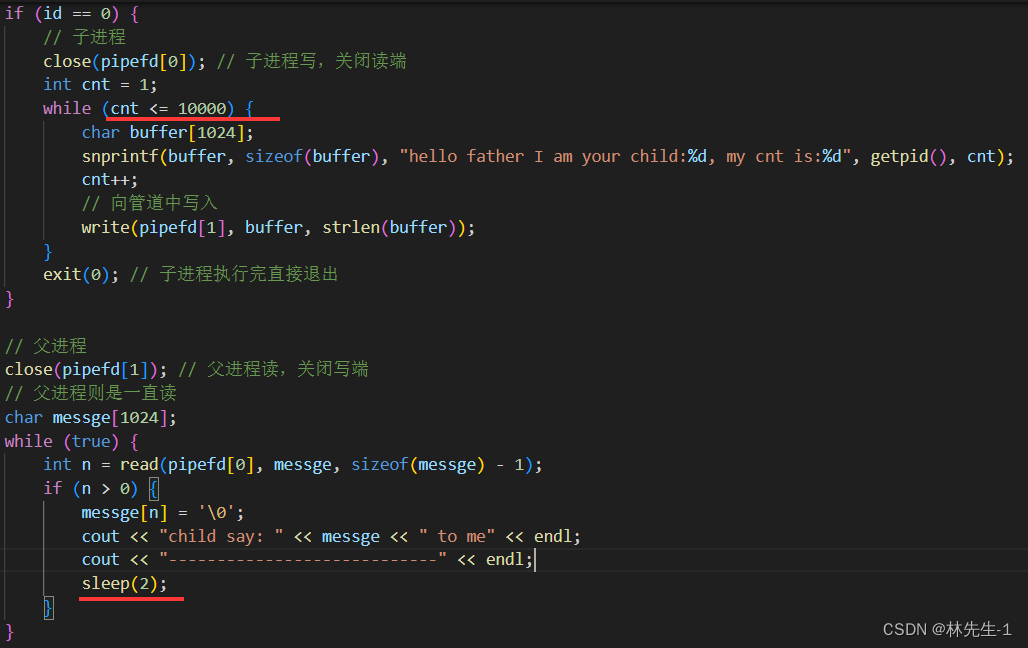
那么结果就会打印的非常乱了:

这就说明了,写端并不会等待读端,虽然你读端并没有在读,但我写端却一直在写。
那最后为什么又会卡住呢?
这是因为,正常情况下如果写端关闭,读端一直在读,read就会返回0,表示读到文件结尾。
而我们现在没有多返回值为0做判断,所以也就卡住了,我们多加一个判断即可:

这样进程就能正常退出了:

上面是写端关闭的情况,那我们让读端中途关闭又会发生什么呢?
我们干脆就只让读端只读一次,就直接关闭:

我们会发现读端在读了一次之后整个进程就直接退出了:

这样不好看出是为什么会出退,我们可以让父进程在关闭读端后暂停一会,然后通过监控脚本来看看子进程的情况:
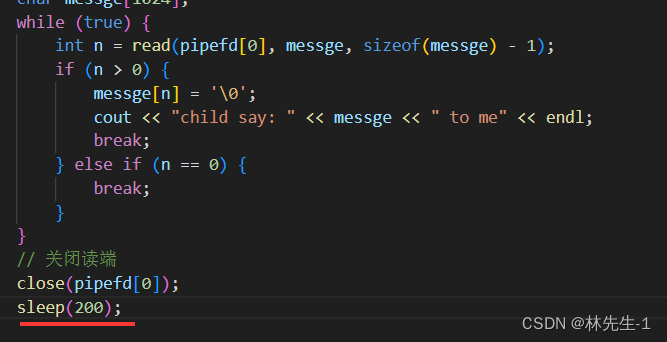


从结果从结果中我们可以看到,子进程在父进程关闭读端后直接就崩溃了。
这是因为,读端关闭,写端一直写。操作系统会直接杀掉写端进程,方法是通过向写端发送SIGPIPE(13)信号终止进程。

那么如何证明呢?
很简单,就是用我们以前学过的进程等待接口waitpid的第二个参数接收进程退出的退出信号:


以上就是匿名管道的几个重要的特性,讲完了这些之后我们再来理解一下我们操作系统指令中的一个‘|’匿名管道:

‘|’管道相信大家都用过,但是可能都不知道原理,其实它的原理其实就是我们上面所说到的匿名管道的原理,只是多加了一个重定向。
上面的这些指令本质其实都是创建了几个进程,然后通过管道进行进程间通信,只不过这几个进程都是命令行解释器bash创建的,上面的例子不好看出来,因为是一执行就退出的,使用下面这个例子就会看的清楚一点:

同时,bash在创建这进程和管道的同时,还对这几个进程做了输入输出重定向,就拿比较简单的echo | cat来说,其结构如下图所示:

bash在底层其实是将echo的标准输出和管道的写端进行交换,所以此后进程echo所执行的一切输出到显示器中的信息就都会写入到管道文件中,而在另一端则是将进程cat的标准输入和管道的读端进行交换,所以此后进程cat执行的一切从标准输入中读取数据的工作就都会从管道文件中读取。
所以我们才能看到原本要由echo输出到显示器上的内容反而是被cat打印到了显示器上的:

所以我们也就能知道了为什么grep指令能从管道前面执行的结果中过滤出相关信息:

二、使用匿名管道实现一个简易的“进程池”
既然我们已经了解了匿名管道的原理,那当然也要来做一些实践,只有原理和实践结合起来,我们才能加深对匿名管道的理解。
其实管道的应用中有一个非常好的例子,那就是实现一个“进程池”。
2.1、什么是进程池?
大家在学习C++的时候可能听说过空间配置器,也可能听说过进程池,但可能并不真正理解这些到底是个什么东西。
通俗的理解,我们可以将进程池理解成一个内存储备库。
我们在学习C语言的时候用过malloc,学习C++的时候用过new,它们两个的作用都是申请一块内存空间供用户使用。
而且我们也知道操作系统是内存的管理者,所以分配内存资源的工作只能有操作系统来做,而我们要访问操作系统只能通过系统调用。
那么如果我们要频繁使用malloc或new来申请空间,难道是每次都要调用系统调用吗?
其实用我们目前的知识来分析,可以推断出如果是这样做,效率其实是不太高的,因为调用系统调用也是有消耗的,可能单次的影响不是很大,但是多次的话就会有一点影响了。
那再结合我们之前学过的缓冲区的知识,我们的内存是否也可以像缓冲区一样,先申请好一部分资源,到用到的时候再分配。
其实是可以的,事实上进程池的原理和缓冲区确实很类似,比如说我们今天有很多的任务要执行,要将这些任务分配给不同的进程去执行,那我们就可以事先先创建好一批进程,然后从这里进程中选择一些进程执行某些任务,没有收到任务的进程就一直等待任务的到来。这样岂不是比需要一个进程再创建一个进程好多了。
而这就是进程池。
那我们今天要怎样实现一个进程池呢?我们可以先将图画出来:
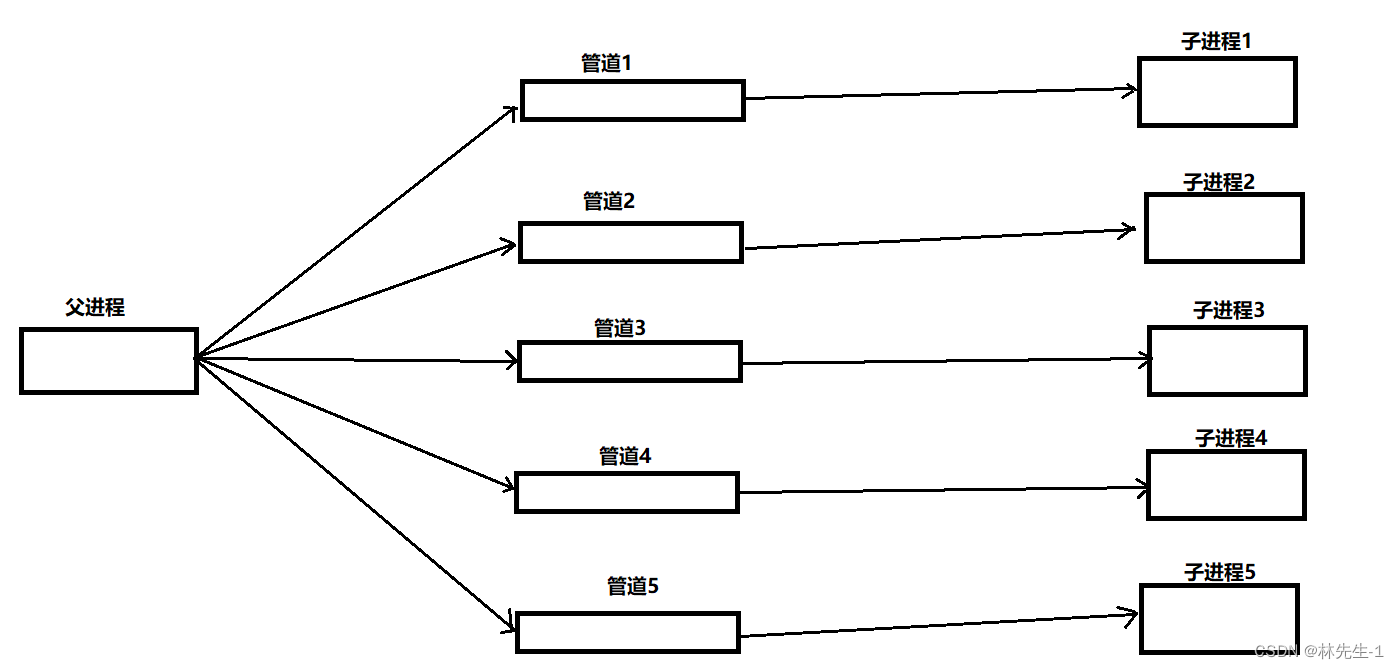
如上图,进程池的创建其实都是由父进程来完成的,让父进程一次创建一个管道,在创建完一个管道之后立即创建一个子进程,然后做好相应的链接工作。
而我们往后要做的是让父进程给子进程派发任务,那当然是父进程往管道里写信息,然后让子进程来读了,所以对于每一个新创建的管道,父进程要关闭它的读端,子进程要关闭它的读端。
2.2、进程池的模拟实现
2.2.1、创建管道创建进程形成单向信道
第一步我们先要吧管道和子进程先创建出来,经过上面的描述,完成这一步也不是什么难事:

2.2.2、管理管道管理任务
我们上面已经好了管道和进程并形成了单向通信的信道,而我们的目标是让父进程可以选择子进程发送任务并让子进程执行,那我们就必须将这些管道和子进程管理起来,这样将来也好让父进程找到。
所以我们可以设计一个结构体channel,在这个结构体中记录一个管道和进程的相关信息,然后我们每创建一个管道和子进程就创建一个channel结构体对象。最后再将这些结构体对象统一管理起来,比如放到一个数组里面。
我们先来创建这样一个channel结构体类型:
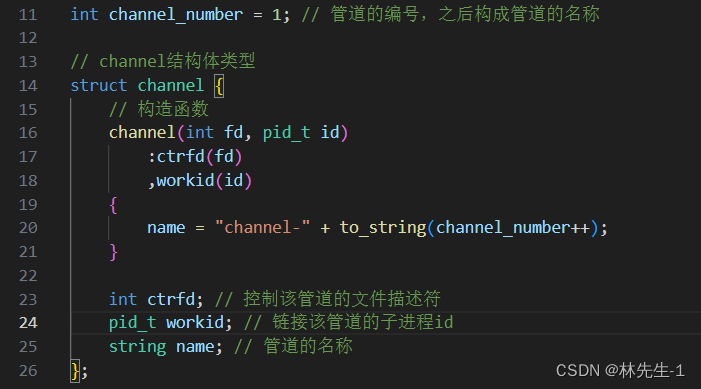
可能有的朋友会不知道上面结构体中这个ctrfd具体应该存的是什么,那么我在这里做一些解释。
这是因为父进程是需要创建多个管道的,而每创建一个管道都会占用父进程的文件描述符表,所以之前的图如果画得更详细一点,应该是这样的:

而父进程往后是要向管道中写入数据,那么那么父进程就需要找到每个管道对应的写端文件描述符,所以channel结构体中的ctrfd存的就是该管道的写端文件描述符(在父进程中)。
所以我们就可以创建一个管道数组,在每次父进程创建完子进程之后就向该数组中加入一个管道对象:
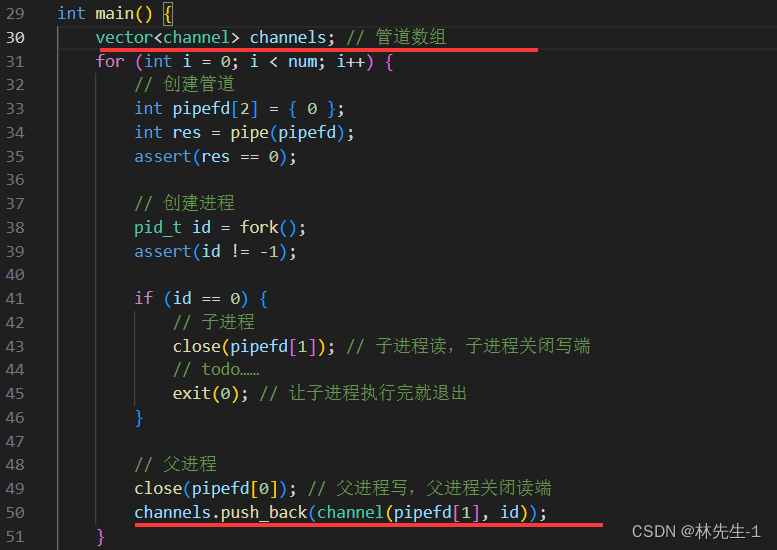
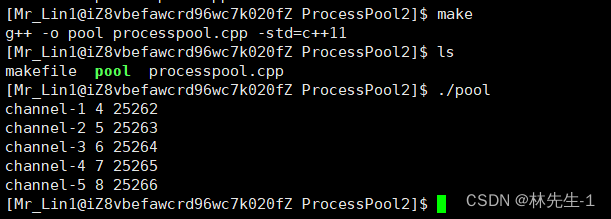
完成之后,我们可以试着将这个数组打印出来检查:

那下一步就是要创建出一些”任务“来让子进程执行,对于”任务”呢我们今天就实现得简单一些,让子进程输出一些信息就行了,例如:

不要搞得太复杂,意思意思就行了。
而这些任务将来也是需要被父进程找到的,所以我们可以顶一个包装器,定义一个包装器数组,然后将这些任务全都放到这个数组中,这样我们以后就可以直接使用数组下标来选择对应的任务了:

2.2.3、分配任务
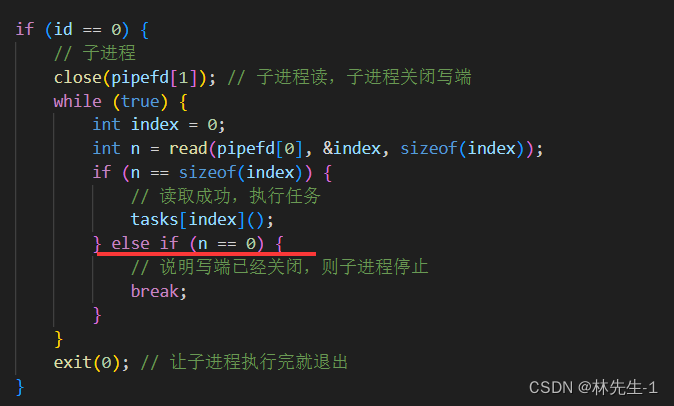
再分配任务给子进程之前,我们必须先让子进程一直等待任务的到来,而我们之前在说管道的特性的时候说过,如果管道中没有数据,那么读端就必须等待,直到管道中有数据为止,所以我们就让子进程一直从管道中读取就行了。
而父进程最终一定是要先选择某一个管道,然后再向管道中发送信息,让对应的子进程执行某一个任务,而我们刚才又已经将任务以数组的方式组织起来了,所以子进程需要读的就只是某一个任务对应的下标即可:
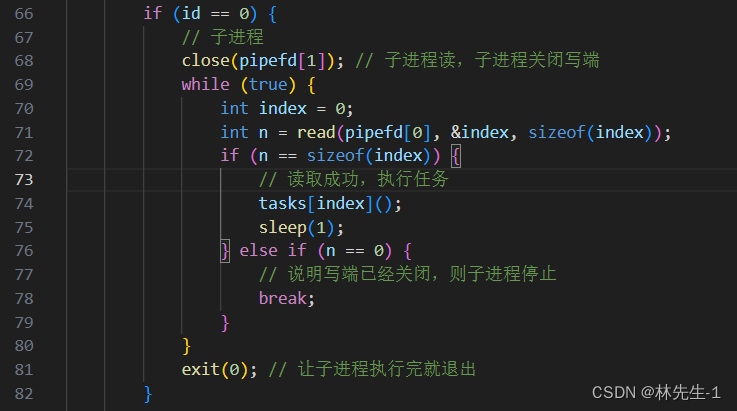
而如果,再读的过程中写端关闭了,根据之前总结的特性,读端会读到0,那既然写端都关闭了,那我们就不需要再读了,直接让子进程跳出循环然后退出即可。
而我们父进程需要做的就是选择管道,选择任务,最后只需要向对应的管道中发送任务的下标即可。
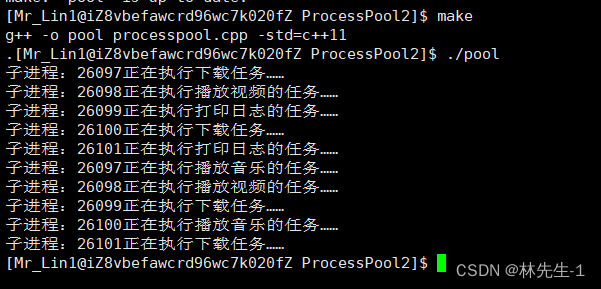
选择的方式有很多种,我们可以随机的选择,也可以以轮询的方式选择,我们今天以为轮询的方式选择管道,然后以随机的方式选择任务:

运行结果:
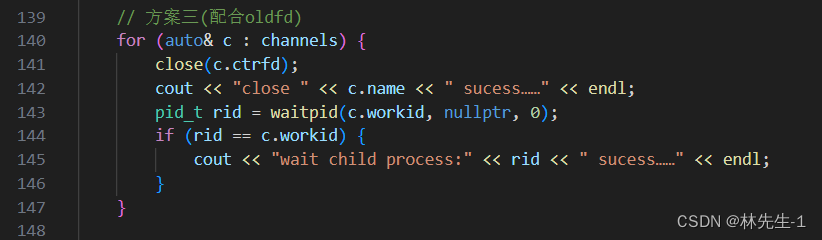
当然,我们差最后一步,那就是在进程退出之前,将所有的管道关闭和所有的子进程回收,而我们已经将进程和管道的信息都保存在了,channels数组中了,所以只需要遍历一遍channels数组即可:
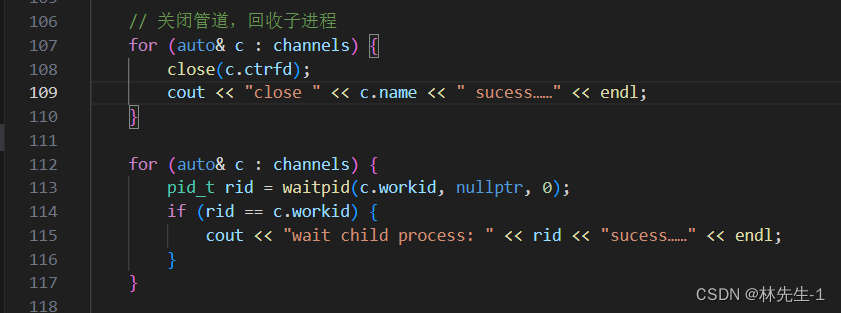
运行结果:

而上面我为什么要遍历两次channels数组,而不是只遍历了一遍,以及为什么需要先关闭管道再回收进程,这就得好好说一下了,因为这里面还藏着一个隐藏的非常深的bug。
2.2.4、处理一个比较“深”的bug
如果我们现在先回收子进程,再关闭管道,我们就能看到这个bug了:

我们会发现最后程序卡住了:

同样的,如果我们将回收子进程和关闭管道放在同一个循环内也会出现这样的问题:
那这个bug到底出在哪呢?
很多朋友可能会以为bug处在我们回收进程和关闭管道这里,但却并不是,事实上bug是出在了我们最开始创建管道和进程的地方:
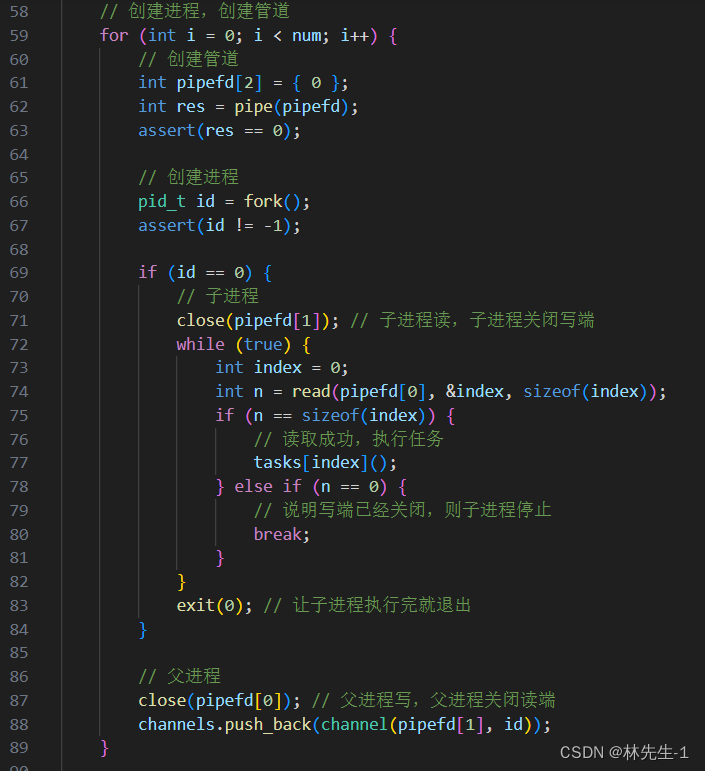
想要弄清楚这个bug,那可得好好的画图分析了:
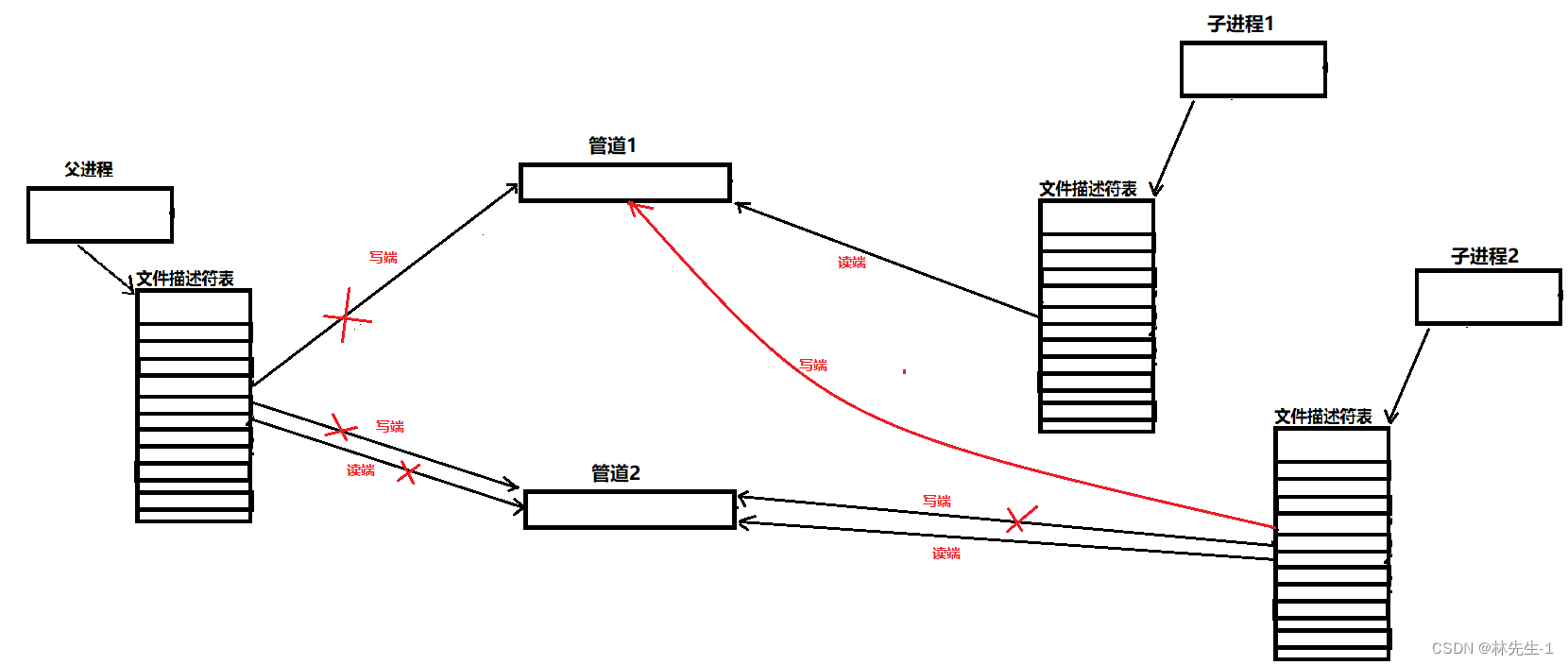
我们知道父进程再创建一个子进程的时候,子进程会继承父进程的文件描述符表:
如上图,父进程创建出子进程,子进程会继承下来父进程的文件描述符表,只是后来父进程和子进程会关闭对应的读写端。
那么这第一个管道是没什么问题的,但是到第二个管道就会出问题了:

如上图,进程2除了会继承到管道2的读端和写端文件描述符,同时还会多继承一个管道1的文件描述符。
同理类推,如果还有进程3,那进程3除了继承管道3的读写端,还会额外的继承下来管道1和管道2的写端文件描述符。
以此类推,往后每一个新进程都会继承前面创建的所有管道的写端。
那这又会造成什么后果呢?根据我们之前总结的匿名管道的特性:如果写端关闭,读端会一直读,读端0表示读到文件结尾,但是就拿上面的情况来说,如果我们是吧关闭文件描述符和回收子进程的工作放在同一个循环中:

那么:

就相当于只是关闭了管道1的一个写端(在父进程的文件描述符表),但其实还有一个写端是子进程2还没有关闭,所以子进程1的读端就不会读到0,也就不会退出:
那要怎么解决这个问题呢?
其实我们上面写的先循环关闭管道,再循环回收进程的方法就是一种解决方案:

这是因为,无论我们有多少个管道被创建出来,最后一个管道都是只有一个写端指向它,那么虽然我们现在是从前往后关闭父进程的写端,但最终都是会关闭最后一个管道的写端:
如上图,管道2的唯一写端被关闭了,子进程2就会从管道中读到0,那么子进程就退出了:

而子进程2退出了,子进程2的所有文件描述夫也就关闭了,也就导致了管道1的写端也全关闭了,那么子进程1也就读到0退出。
所以这是一个”从前往后“再从后往前的过程,以此类推,以后我们有十个八个管道也是这样子。
而经过以上分析,我们的第二种方案也就出来了,就是从后往前遍历channels数组,然后在一个循环中先关闭文件描述符,再等待子进程:

运行结果:

但是不知道大家有没有感觉到别扭,就是我们新建的子进程为什么要继承这些额外的,没有必要的文件描述符呢?为什么不能把多余的文件描述符都关闭呢?
那就要引出我们的第三种方案了,这也是我觉得最优的一种方案,那就是将每个子进程多余的文件描述符都管掉!
具体做法:
因为父进程的文件描述符表中是保存着所有的管道的写端文件描述符的,所以我们可以将父进程中所有的管道写端文件文件描述符拷贝到一个数组中,那么在每创建一个一个子进程之后就将该数组中旧的文件描述符关掉即可,最后再由父进程将新管道的写端文件描述符加入到这个数组中:

这样,就算我们吧关闭和回收放在一个循环中也是OK的:

完整代码:
#include <iostream>
#include <vector>
#include <cstring>
#include <string>
#include <unistd.h>
#include <fcntl.h>
#include <cassert>
#include <functional>
#include <ctime>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
const int num = 5;
int channel_number = 1; // 管道的编号,之后构成管道的名称
typedef function<void()> task;// 任务
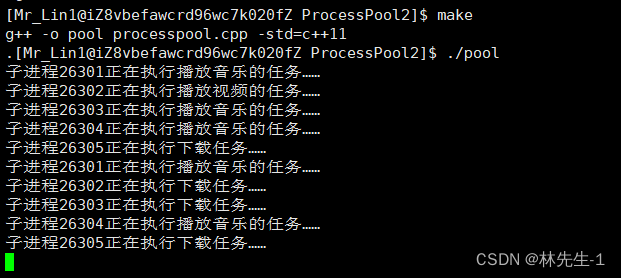
void Play_Music() {cout << "子进程" << getpid() << "正在执行播放音乐的任务……" << endl;
}
void Play_Video() {cout << "子进程" << getpid() << "正在执行播放视频的任务……" << endl;
}void Print_Log() {cout << "子进程" << getpid() << "正在执行打印日志的任务……" << endl;
}void Download() {cout << "子进程" << getpid() << "正在执行下载任务……" << endl;
}// channel结构体类型
struct channel {// 构造函数channel(int fd, pid_t id) :ctrfd(fd),workid(id){name = "channel-" + to_string(channel_number++);}int ctrfd; // 控制该管道的文件描述符pid_t workid; // 链接该管道的子进程idstring name; // 管道的名称
};int main() {vector<channel> channels; // 管道数组vector<task> tasks; // 任务数组// 初始化任务数组tasks.push_back(Play_Music);tasks.push_back(Play_Video);tasks.push_back(Print_Log);tasks.push_back(Download);vector<pid_t> oldfd; // 保存旧的文件描述符// 创建进程,创建管道for (int i = 0; i < num; i++) {// 创建管道int pipefd[2] = { 0 };int res = pipe(pipefd);assert(res == 0);// 创建进程pid_t id = fork();assert(id != -1);if (id == 0) {// 先关闭所有旧的文件描述符if (!oldfd.empty()) {for (auto fd : oldfd) {close(fd);}}// 子进程close(pipefd[1]); // 子进程读,子进程关闭写端while (true) {int index = 0;int n = read(pipefd[0], &index, sizeof(index));if (n == sizeof(index)) {// 读取成功,执行任务tasks[index]();} else if (n == 0) {// 说明写端已经关闭,则子进程停止break;}}exit(0); // 让子进程执行完就退出}// 父进程close(pipefd[0]); // 父进程写,父进程关闭读端channels.push_back(channel(pipefd[1], id));oldfd.push_back(pipefd[1]);}// 种一颗随机数种子srand(time(NULL) * getpid());const int T = 10; // 让父进程选择T次for (int i = 0; i < T; i++) {int channeli = i % num; // 管道下标int taski = rand() % tasks.size(); // 任务下标channel& c = channels[channeli];// 向管道发送下标write(c.ctrfd, &taski, sizeof(taski));sleep(1);}// 关闭管道,回收子进程// 方案一// for (auto& c : channels) {// close(c.ctrfd);// cout << "close " << c.name << " sucess……" << endl;// }// for (auto& c : channels) {// pid_t rid = waitpid(c.workid, nullptr, 0);// if (rid == c.workid) {// cout << "wait child process:" << rid << " sucess……" << endl;// }// }// // 方案二// for (int i = channels.size() - 1; i >= 0; i--) {// close(channels[i].ctrfd);// cout << "close " << channels[i].name << " sucess……" << endl;// pid_t rid = waitpid(channels[i].workid, nullptr, 0);// if (rid == channels[i].workid) {// cout << "wait child process:" << rid << " sucess……" << endl;// }// }// 方案三(配合oldfd)for (auto& c : channels) {close(c.ctrfd);cout << "close " << c.name << " sucess……" << endl;pid_t rid = waitpid(c.workid, nullptr, 0);if (rid == c.workid) {cout << "wait child process:" << rid << " sucess……" << endl;} }return 0;
}三、命名管道
讲完了匿名管道,命名管道其实就很好理解了,因为与原理都是一样的,事实上命名管道的操作也确实比匿名管道要简单。
3.1、指令级的命名管道
所谓命名管道,也就是有名字的管道,前面说过管道其实就是个文件,那么命名管道就是一个有文件名的文件。
我们首先来看看指令级级的命名管道,在系统中有一个mdfifo的指令,它可以用来创建一个命名管道:
用它就可以来创建一个命名管道文件:

前面说过,匿名管道只能实现具有亲缘关系的进程之间的通信,但是命名管道可以实现两个毫不相关的进程之间的通信,究其原因就是因为命名管道它有文件名和路径,而有了文件名和路径其实就可以唯一确定一个文件。所以命名管道并不像匿名管道一样只能通过继承文件描述符的方式来让两个进程看到同一个文件。
所以我们可以开两个终端来试验命名管道:

再结合我们前面的理论,进程间通信的本质是让两个进程看到同一份资源,所以我们要做的就是让两个终端同时打开这个fifo。

然后让一个终端写入,一个终端读取,就完成了两个毫不相关的进程间通信了。
但是当我们查看这个命名管道文件的时候,却会发现这个文件的大小并没有改变:

这是因为命名管道和匿名管道一样,并不用再磁盘中存储,他们都只是通过文件缓冲区来传输数据而已。
3.2、代码级的命名管道
然后我们再来聊聊代码级的命名管道,操作系统其实还给我们提供了一个系统调用,接口名也是mkfifo,它可以在我们的代码中创建一个命名管道文件:


而在代码上,既然要是两个毫不相关的进程,那我们就要创建两个独立的可执行文件,我们分别命名为sever和cilent,即服务端和客户端,然后我们让server端从管道中读取,让client端向管道中写入。
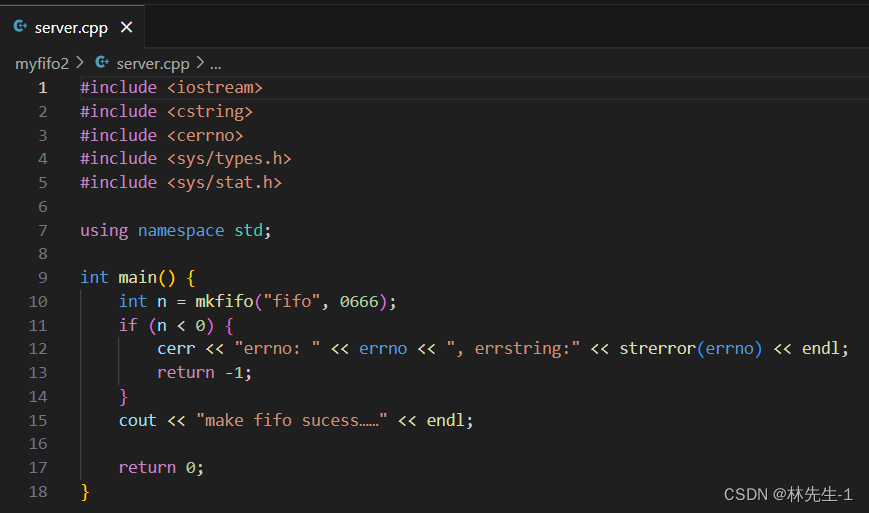
我们先让server端来创建这个命名管道文件:
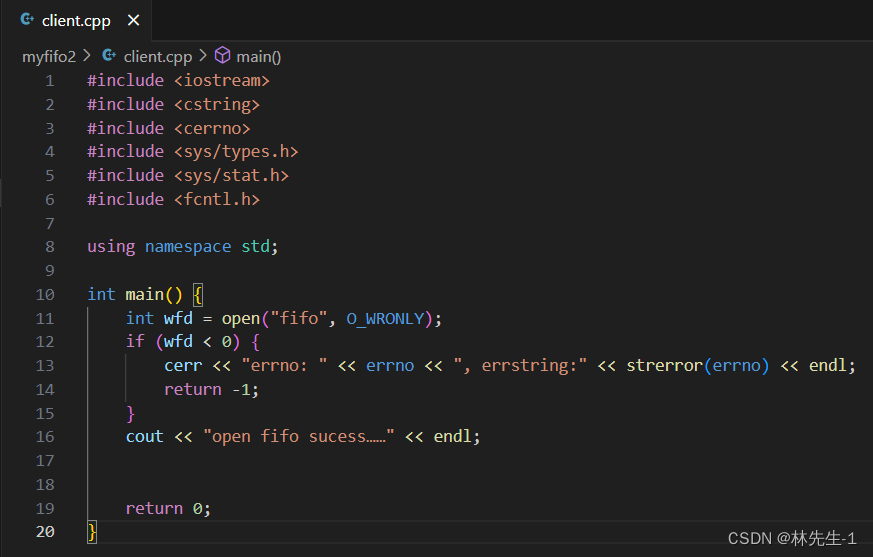
然后client端就只需要打开这个文件即可:
同样的,server也需要以只读方式打开这个文件:

然后我们运行一下试试,因为是server端创建的管道文件,所以我们需要先运行server端:

但是我们会发现,只运行server端,只会打印出创建管道文件成功,后面的打开文件的信息就没有打印了,而当我们再运行client端后就成功打开了:

这很好地说明了,命名管道也是需要同步的,两端都打开了才能进程通信,如果其中一端没有打开,另一端也不会打开。
然后我们就可以来进行进程间通信了,我们今天想要实现一个两个窗口互发信息的场景,所以我们让client端从键盘中读入,然后在写到管道中:

然后server端只需要从管道中读出数据,并打印出来就行了:
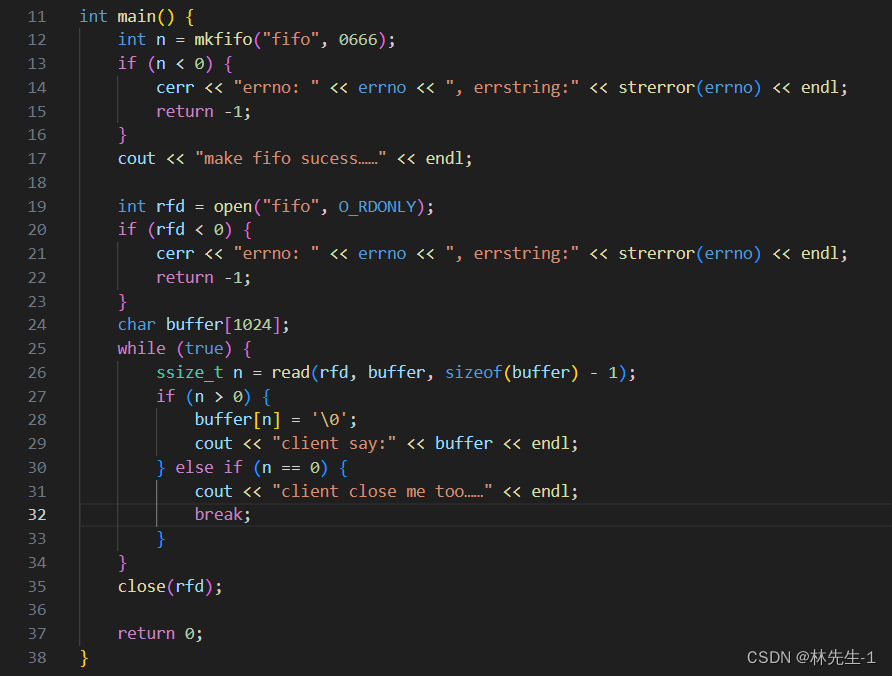
运行结果:

做完实验后我们就会发现,命名管道和匿名管道除了一个没名字一个有名字之外,其实都一样,包括读端会等待写端,写端关闭读端会读端到0这些……所以代码也几乎是老代码。
相关文章:
【Linux笔记】进程间通信之管道
一、匿名管道 我们在之前学习进程的时候就知道了一个概念,就是进程间是互相独立的,所以就算是两个进程是父子关系,其中一个进程退出了也不会影响另一个进程。 也因为进程间是互相独立的,所以两个进程间就不能直接的传递信息或者…...
【Node-RED】安全登陆时,账号密码设置
【Node-RED】安全登陆时,账号密码设置 前言实现步骤密码生成setting.js 文件修改 安全权限 前言 Node-RED 在初始下载完成时,登录是无账号密码的。基于安全性考虑,本期博文介绍在安全登陆时,如何进行账号密码设置。当然ÿ…...
-k8s的服务发现机制)
Kubernetes基础(二十一)-k8s的服务发现机制
1 概述 Kubernetes(K8s)是一个强大的容器编排平台,提供了丰富的功能来简化容器化应用的管理。其中之一重要的特性就是服务发现机制,它使得应用程序能够在K8s集群中动态地发现和访问其他服务。本文将深入研究K8s中的服务发现机制&…...

华纳云:docker更新容器镜像的常用方法
更新 Docker 容器镜像可以通过以下几种方法实现: 1. 使用 docker pull 命令手动拉取更新的镜像: docker pull <镜像名>:<标签> 这会拉取指定镜像的最新版本或者指定标签的版本到本地。然后您可以停止并删除现有的容器,使用新的镜…...

什么时候会触发FullGC?描述一下JVM加载class文件的原理机制?
什么时候会触发 FullGC? 除直接调用 System.gc 外,触发 Full GC 执行的情况有如下四种。 1. 旧生代空间不足 旧生代空间只有 在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行 Full GC 后空间仍然不 足,则…...
HCIP-MGRE实验配置、PPP的PAP认证与CHAP认证、MGRE、GRE网络搭建、NAT
实验要求 R5为ISP,只能进行IP地址配素,其所有地址均为公有IP地址R1和R5间使用PPP的PAP认证,R5为主认证方 R2与R5之间使用PPP的chap认证,R5为主认证方 R3与R5之间使用HDLC封装。R1/R2/R3构建一个MGRE环境,R1为中心站点;R1、R4间为…...
react【四】css
文章目录 1、css1.1 react和vue css的对比1.2 内联样式1.3 普通的css1.4 css modules1.5 在react中使用less1.6 CSS in JS1.6.1 模板字符串的基本使用1.6.2 styled-components的基本使用1.6.3 接受传参1.6.4 使用变量1.6.5 继承样式 避免代码冗余1.6.6 设置主题色 1.7 React中添…...

SpringIOC之support模块SimpleThreadScope
博主介绍:✌全网粉丝5W+,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建与毕业项目实战,博主也曾写过优秀论文,查重率极低,在这方面有丰富的经验✌ 博主作品:《Java项目案例》主要基于SpringBoot+MyBatis/MyBatis-plus+…...

气味是否能通过光缆、信号传播?
搜索资料,有一点点眉目, 参考:未来网络可以传送气味 如何产生并被感知--双鸭山新闻网...
安装部署k8s集群
系统: CentOS Linux release 7.9.2009 (Core) 准备3台主机 192.168.44.148k8s-master92.168.44.154k8s-worker01192.168.44.155k8s-worker02 3台主机准备工作 关闭防火墙和selinux systemctl disable firewalld --nowsetenforce 0sed -i s/SELINUXenforcing/SELI…...

曲线生成 | 图解B样条曲线生成原理(基本概念与节点生成算法)
目录 0 专栏介绍1 什么是B样条曲线?2 基函数的de Boor递推式3 B样条曲线基本概念图解4 节点生成公式 0 专栏介绍 🔥附C/Python/Matlab全套代码🔥课程设计、毕业设计、创新竞赛必备!详细介绍全局规划(图搜索、采样法、智能算法等)…...

CyberDAO:web3时代的引领者
Web3.0正在改写着世界运行的规则,AGI将为人类未来的生产效率、工作方式与目标带来改变,区块链经过十余年发展开启了去中心化新格局,带来生产关系的变革。人类正在从过往以时间换取收入、听命完成工作,转变为以个性化、自主追求人生…...
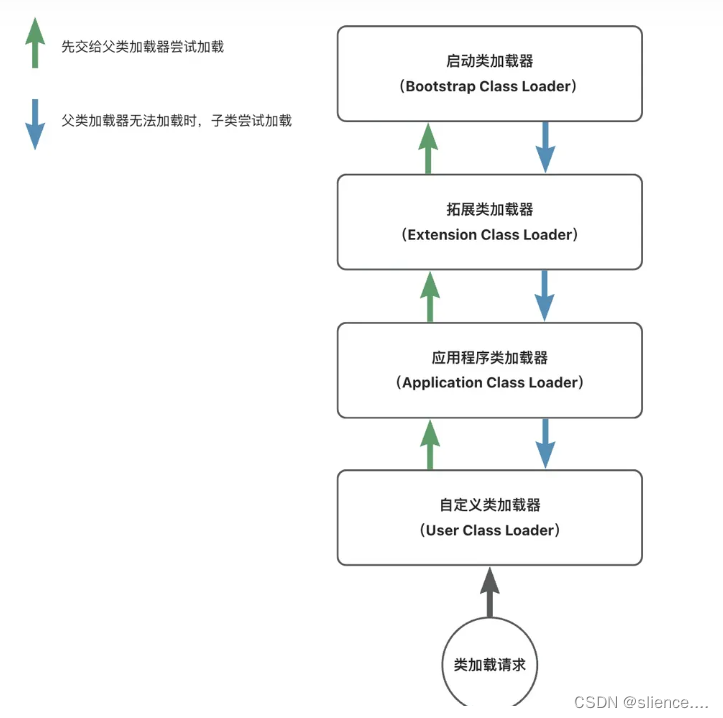
java以及android类加载机制
类加载机制 一、Java类加载机制 java中,每一个类或者接口,在编译后,都会生成一个.class文件。 类加载机制指的是将这些.class文件中的二进制数据读入到内存中并对数据进行校验,解析和初始化。最终,每一个类都会在方…...

【Go】四、rpc跨语言编程基础与rpc的调用基础原理
Go管理工具 早期 Go 语言不使用 go module 进行包管理,而是使用 go path 进行包管理,这种管理方式十分老旧,两者最显著的区别就是:Go Path 创建之后没有 go.mod 文件被创建出来,而 go module 模式会创建出一个 go.mod…...

Linux CentOS系统安装SQL Server并结合内网穿透实现公网访问本地数据
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《C》 《Linux》 《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默&…...
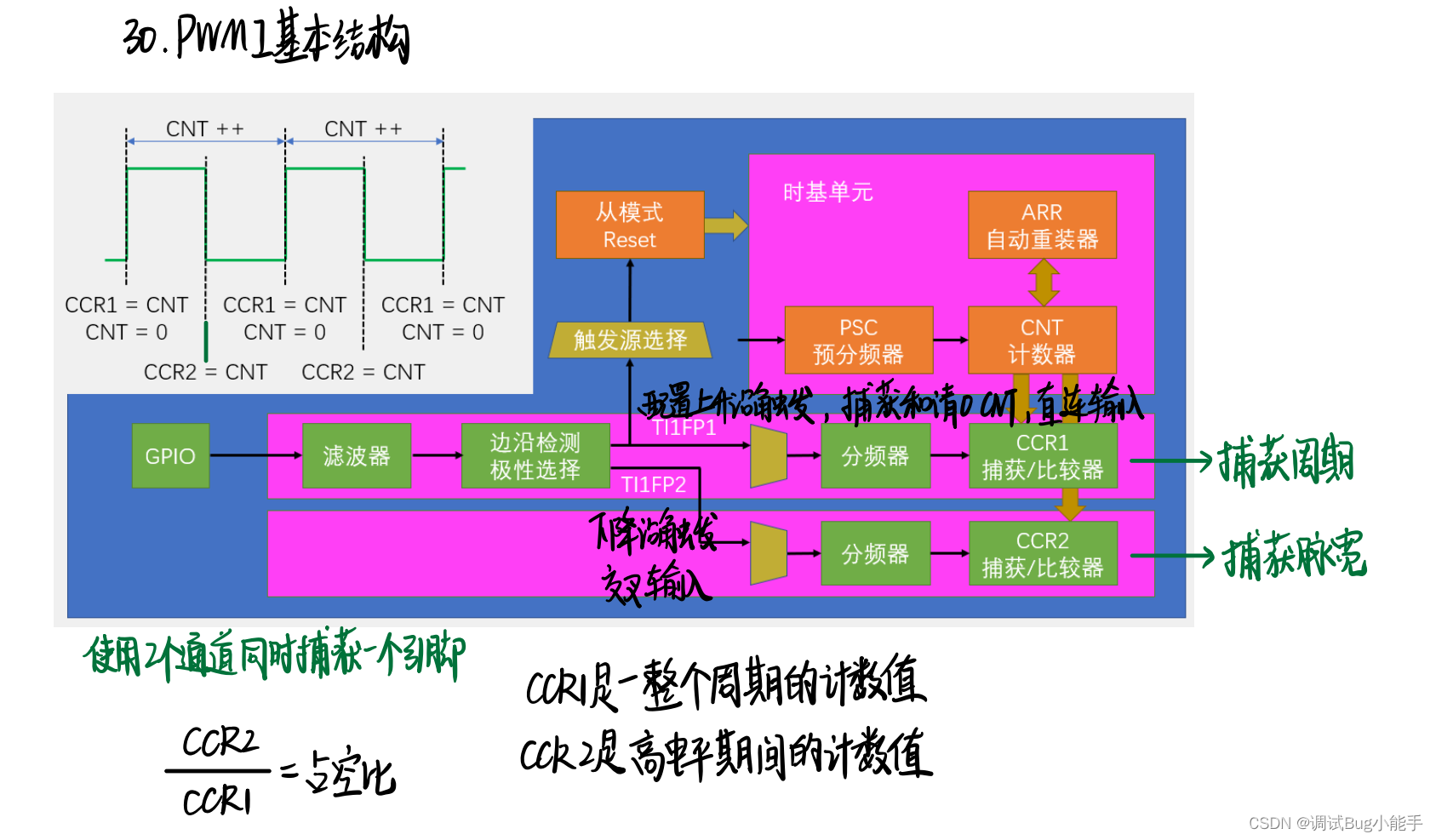
输入捕获模式测频率PWM输入模式(PWMI)测占空比
一、概念介绍 输出比较: 比较电路输入的CNT、CCR大小关系 ,在通道引脚输出高低电平 二、*频率知识、测量方法补充 * N/fc得到标准频率的时长,也就是待测频率的周期 测频法代码实现:修改对射式红外传感器计次(上升沿…...

解锁VIP会员漫画:用Python爬虫轻松实现高清漫画下载
嗨喽~大家好呀,这里是魔王呐 ❤ ~! python更多源码/资料/解答/教程等 点击此处跳转文末名片免费获取 环境使用: Python 3.10 Pycharm 模块使用: requests >>> pip install requests 数据请求模块 parsel >>> pip install parsel 数据解析模块…...

备战蓝桥杯---动态规划(入门3之子串问题)
本专题再介绍几种经典的字串问题。 这是一个两个不重叠字串和的问题,我们只要去枚举分界点c即可,我们不妨让c作为右区间的左边界,然后求[1,c)上的单个字串和并用max数组维护。对于右边,我们只要反向求单个字串和然后选左边界为c的…...

JavaScript:隐式类型转换与显式类型转换
文章目录 隐式类型转换(Implicit Type Conversion)1、字符串与数字的转换2、非布尔值到布尔值的转换3、在相等性比较中的转换4、对象到基础类型的转换5、在算术运算符中的其他转换 显式类型转换(Explicit Type Conversion)1、Numb…...

【电路笔记】-LR串联电路
LR串联电路 文章目录 LR串联电路1、概述2、示例1所有线圈、电感器、扼流圈和变压器都会在其周围产生磁场,由电感与电阻串联组成,形成 LR 串联电路。 1、概述 在本节有关电感器的第一个文章中,我们简要介绍了电感器的时间常数,指出流过电感器的电流不会瞬时变化,而是会以恒…...

Windows电脑安装安卓应用终极指南:APK安装器完整教程
Windows电脑安装安卓应用终极指南:APK安装器完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上直接运行安卓应用&#x…...

FlashMLA:把 KV Cache 压缩到原来的八分之一
标准 MHA 的 KV Cache 是推理显存的第一大户。LLaMA-7B,32 层,每层 32 头,HeadDim128,SeqLen128K——KV Cache 吃 40GB。MLA(Multi-head Latent Attention)用低秩分解把 KV 映射到一个远小于 HeadDim 的潜在…...

3大绝技:Gifsicle如何让命令行成为GIF动画的终极编辑器?
3大绝技:Gifsicle如何让命令行成为GIF动画的终极编辑器? 【免费下载链接】giflossy Merged into Gifsicle! 项目地址: https://gitcode.com/gh_mirrors/gi/giflossy 在数字内容创作的世界里,GIF动画一直占据着特殊地位——它轻量、兼容…...

5个AI音频处理神器:用OpenVINO插件让Audacity变身专业音频工作站
5个AI音频处理神器:用OpenVINO插件让Audacity变身专业音频工作站 【免费下载链接】openvino-plugins-ai-audacity A set of AI-enabled effects, generators, and analyzers for Audacity. 项目地址: https://gitcode.com/gh_mirrors/op/openvino-plugins-ai-auda…...

GoldenCheetah:从数据迷雾到训练洞察的专业运动分析平台
GoldenCheetah:从数据迷雾到训练洞察的专业运动分析平台 【免费下载链接】GoldenCheetah Performance Software for Cyclists, Runners, Triathletes and Coaches 项目地址: https://gitcode.com/gh_mirrors/go/GoldenCheetah 你是否曾面对一堆运动数据却不知…...

ChatGPT账号被封怎么办?20年合规架构师给出终极答案:1套可审计的账号生命周期管理SOP
更多请点击: https://codechina.net 第一章:ChatGPT账号被封怎么办 当您的ChatGPT账号突然无法登录、提示“Account suspended”或跳转至封禁通知页时,需冷静判断原因并采取合规应对措施。OpenAI官方明确指出,封禁通常源于违反《…...

HS2-HF Patch:为HoneySelect2打造的全能增强解决方案
HS2-HF Patch:为HoneySelect2打造的全能增强解决方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 如果你正在寻找一种简单高效的方式来提升Honey…...

如何快速掌握Poppins字体:免费开源的多语言设计终极指南
如何快速掌握Poppins字体:免费开源的多语言设计终极指南 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 还在为多语言项目寻找完美的字体解决方案而烦恼吗ÿ…...

VMware装Linux避坑大全:从CentOS 7网络连接到Ubuntu 22.04 VMware Tools安装一条龙
VMware虚拟机Linux系统实战避坑指南:网络配置与工具安装全解析刚装好Linux虚拟机的兴奋感,往往会被"ping不通百度"或"无法拖拽文件"的现实浇灭。这不是你的问题——超过60%的VMware新手都会在网络连接和工具安装环节卡壳。本文将用工…...

如何实现离线语音识别:Vosk API终极实战指南
如何实现离线语音识别:Vosk API终极实战指南 【免费下载链接】vosk-api Offline speech recognition API for Android, iOS, Raspberry Pi and servers with Python, Java, C# and Node 项目地址: https://gitcode.com/GitHub_Trending/vo/vosk-api 想要为你…...