Spark编程实验五:Spark Structured Streaming编程
目录
一、目的与要求
二、实验内容
三、实验步骤
1、Syslog介绍
2、通过Socket传送Syslog到Spark
3、Syslog日志拆分为DateFrame
4、对Syslog进行查询
四、结果分析与实验体会
一、目的与要求
1、通过实验掌握Structured Streaming的基本编程方法;
2、掌握日志分析的常规操作,包括拆分日志方法和分析场景。
二、实验内容
1、通过Socket传送Syslog到Spark
日志分析是一个大数据分析中较为常见的场景。在Unix类操作系统里,Syslog广泛被应用于系统或者应用的日志记录中。Syslog通常被记录在本地文件内,也可以被发送给远程Syslog服务器。Syslog日志内一般包括产生日志的时间、主机名、程序模块、进程名、进程ID、严重性和日志内容。
日志一般会通过Kafka等有容错保障的源发送,本实验为了简化,直接将Syslog通过Socket源发送。新建一个终端,执行如下命令:
$ tail -n+1 -f /var/log/syslog | nc -lk 9988“tail -n+1 -f /var/log/syslog”表示从第一行开始打印文件syslog的内容。“-f”表示如果文件有增加则持续输出最新的内容。然后,通过管道把文件内容发送到nc程序(nc程序可以进一步把数据发送给Spark)。
如果/var/log/syslog内的内容增长速度较慢,可以再新开一个终端(计作“手动发送日志终端”),手动在终端输入如下内容来增加日志信息到/var/log/syslog内:
$ logger ‘I am a test error log message.’2、对Syslog进行查询
由Spark接收nc程序发送过来的日志信息,然后完成以下任务:
(1)统计CRON这个进程每小时生成的日志数,并以时间顺序排列,水印设置为1分钟。
(2)统计每小时的每个进程或者服务分别产生的日志总数,水印设置为1分钟。
(3)输出所有日志内容带error的日志。
三、实验步骤
1、Syslog介绍
分析日志是一个大数据分析中较为常见的场景。在Unix类操作系统里,Syslog广泛被应用于系统或者应用的日志记录中。Syslog通常被记录在本地文件内,也可以被发送给远程Syslog服务器。Syslog日志内一般包括产生日志的时间、主机名、程序模块、进程名、进程ID、严重性和日志内容。
2、通过Socket传送Syslog到Spark
日志一般会通过kafka等有容错保障的源发送,本实验为了简化,直接将syslog通过Socket源发送。新开一个终端,命令为“tail终端”,输入
tail -n+1 -f /var/log/syslog | nc -lk 9988 tail命令加-n+1代表从第一行开始打印文件内容。-f代表如果文件有增加则持续输出最新的内容。通过管道发送到nc命令起的在本地9988上的服务上。
如果/var/log/syslog内的内容增长速度较慢,可以再新开一个终端,命名为“手动发送log终端”,手动在终端输入
logger ‘I am a test error log message.’来增加日志信息到/var/log/syslog内。
3、Syslog日志拆分为DateFrame
Syslog每行的数据类似以下:
Nov 24 13:17:01 spark CRON[18455]: (root) CMD (cd / && run-parts --report /etc/cron.hourly)
最前面为时间,接着是主机名,进程名,可选的进程ID,冒号后是日志内容。在Spark内,可以使用正则表达式对syslog进行拆分成结构化字段,以下是示例代码:
# 定义一个偏应用函数,从固定的pattern获取日志内匹配的字段fields = partial(regexp_extract, str="value", pattern="^(\w{3}\s*\d{1,2} \d{2}:\d{2}:\d{2}) (.*?) (.*?)\[*\d*\]*: (.*)$")words = lines.select(to_timestamp(format_string('2019 %s', fields(idx=1)), 'yy MMM d H:m:s').alias("timestamp"),fields(idx=2).alias("hostname"),fields(idx=3).alias("tag"),fields(idx=4).alias("content"),)to_timestamp(format_string('2018 %s', fields(idx=1)), 'yy MMM d H:m:s').alias("timestamp"),这句是对Syslog格式的一个修正,因为系统默认的Syslog日期是没有年的字段,所以使用format_string函数强制把拆分出来的第一个字段前面加上2019年,再根据to_timestamp格式转换成timestamp字段。在接下来的查询应当以这个timestamp作为事件时间。
4、对Syslog进行查询
由Spark接收nc程序发送过来的日志信息,然后完成以下任务。
(1)统计CRON这个进程每小时生成的日志数,并以时间顺序排列,水印设置为1分钟。
在新开的终端内输入 vi spark_exercise_testsyslog1.py ,贴入如下代码并运行。运行之前需要关闭“tail终端”内的tail命令并重新运行tail命令,否则多次运行测试可能导致没有新数据生成。
#!/usr/bin/env python3from functools import partialfrom pyspark.sql import SparkSession
from pyspark.sql.functions import *if __name__ == "__main__":spark = SparkSession \.builder \.appName("StructuredSyslog") \.getOrCreate()lines = spark \.readStream \.format("socket") \.option("host", "localhost") \.option("port", 9988) \.load()# Nov 24 13:17:01 spark CRON[18455]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)# 定义一个偏应用函数,从固定的pattern获取日志内匹配的字段fields = partial(regexp_extract, str="value", pattern="^(\w{3}\s*\d{1,2} \d{2}:\d{2}:\d{2}) (.*?) (.*?)\[*\d*\]*: (.*)$")words = lines.select(to_timestamp(format_string('2019 %s', fields(idx=1)), 'yy MMM d H:m:s').alias("timestamp"),fields(idx=2).alias("hostname"),fields(idx=3).alias("tag"),fields(idx=4).alias("content"),)# (1). 统计CRON这个进程每小时生成的日志数,并以时间顺序排列,水印设置为1分钟。windowedCounts1 = words \.filter("tag = 'CRON'") \.withWatermark("timestamp", "1 minutes") \.groupBy(window('timestamp', "1 hour")) \.count() \.sort(asc('window'))# 开始运行查询并在控制台输出query = windowedCounts1 \.writeStream \.outputMode("complete") \.format("console") \.option('truncate', 'false')\.trigger(processingTime="3 seconds") \.start()query.awaitTermination()(2)统计每小时的每个进程或者服务分别产生的日志总数,水印设置为1分钟。
在新开的终端内输入 vi spark_exercise_testsyslog2.py ,贴入如下代码并运行。运行之前需要关闭“tail终端”内的tail命令并重新运行tail命令,否则多次运行测试可能导致没有新数据生成。
#!/usr/bin/env python3from functools import partialfrom pyspark.sql import SparkSession
from pyspark.sql.functions import *if __name__ == "__main__":spark = SparkSession \.builder \.appName("StructuredSyslog") \.getOrCreate()lines = spark \.readStream \.format("socket") \.option("host", "localhost") \.option("port", 9988) \.load()# Nov 24 13:17:01 spark CRON[18455]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)# 定义一个偏应用函数,从固定的pattern获取日志内匹配的字段fields = partial(regexp_extract, str="value", pattern="^(\w{3}\s*\d{1,2} \d{2}:\d{2}:\d{2}) (.*?) (.*?)\[*\d*\]*: (.*)$")words = lines.select(to_timestamp(format_string('2019 %s', fields(idx=1)), 'yy MMM d H:m:s').alias("timestamp"),fields(idx=2).alias("hostname"),fields(idx=3).alias("tag"),fields(idx=4).alias("content"),)# (2). 统计每小时的每个进程或者服务分别产生的日志总数,水印设置为1分钟。windowedCounts2 = words \.withWatermark("timestamp", "1 minutes") \.groupBy('tag', window('timestamp', "1 hour")) \.count() \.sort(asc('window'))# 开始运行查询并在控制台输出query = windowedCounts2 \.writeStream \.outputMode("complete") \.format("console") \.option('truncate', 'false')\.trigger(processingTime="3 seconds") \.start()query.awaitTermination()(3)输出所有日志内容带error的日志。
在新开的终端内输入 vi spark_exercise_testsyslog3.py ,贴入如下代码并运行。运行之前需要关闭“tail终端”内的tail命令并重新运行tail命令,否则多次运行测试可能导致没有新数据生成。
#!/usr/bin/env python3from functools import partialfrom pyspark.sql import SparkSession
from pyspark.sql.functions import *if __name__ == "__main__":spark = SparkSession \.builder \.appName("StructuredSyslog") \.getOrCreate()lines = spark \.readStream \.format("socket") \.option("host", "localhost") \.option("port", 9988) \.load()# Nov 24 13:17:01 spark CRON[18455]: (root) CMD ( cd / && run-parts --report /etc/cron.hourly)# 定义一个偏应用函数,从固定的pattern获取日志内匹配的字段fields = partial(regexp_extract, str="value", pattern="^(\w{3}\s*\d{1,2} \d{2}:\d{2}:\d{2}) (.*?) (.*?)\[*\d*\]*: (.*)$")words = lines.select(to_timestamp(format_string('2019 %s', fields(idx=1)), 'yy MMM d H:m:s').alias("timestamp"),fields(idx=2).alias("hostname"),fields(idx=3).alias("tag"),fields(idx=4).alias("content"),)# (3). 输出所有日志内容带error的日志。windowedCounts3 = words \.filter("content like '%error%'")# 开始运行查询并在控制台输出query = windowedCounts3 \.writeStream \.outputMode("update") \.format("console") \.option('truncate', 'false')\.trigger(processingTime="3 seconds") \.start()query.awaitTermination()四、结果分析与实验体会
Spark Structured Streaming 是 Spark 提供的用于实时流处理的 API,它提供了一种统一的编程模型,使得批处理和流处理可以共享相同的代码逻辑,让开发者更容易地实现复杂的实时流处理任务。通过对 Structured Streaming 的实验,有以下体会:
-
简单易用: Structured Streaming 提供了高级抽象的 DataFrame 和 Dataset API,使得流处理变得类似于静态数据处理,降低了学习成本和编程复杂度。
-
容错性强大: Structured Streaming 内置了端到端的 Exactly-Once 语义,能够保证在发生故障时数据处理的准确性,给开发者提供了更可靠的数据处理保障。
-
灵活性和扩展性: Structured Streaming 支持丰富的数据源和数据接收器,可以方便地与其他数据存储和处理系统集成,同时也支持自定义数据源和输出操作,满足各种不同场景的需求。
-
优化性能: Structured Streaming 内置了优化器和调度器,能够根据任务的特性自动优化执行计划,提升处理性能,同时还可以通过调整配置参数和优化代码来进一步提高性能。
-
监控和调试: Structured Streaming 提供了丰富的监控指标和集成的调试工具,帮助开发者实时监控作业运行状态、诊断问题,并进行性能调优。
通过实验和实践,更深入地理解 Structured Streaming 的特性和工作原理,掌握实时流处理的开发技巧和最佳实践,为构建稳健可靠的实时流处理应用打下坚实基础。
Syslog 是一种常用的日志标准,它定义了一个网络协议,用于在计算机系统和网络设备之间传递事件消息和警报。通过对 Syslog 的实验,有以下体会:
-
灵活性: Syslog 可以用于收集各种类型的事件和日志信息,包括系统日志、安全事件、应用程序消息等等,具有很高的灵活性和可扩展性。
-
可靠性: Syslog 提供了可靠的传输和存储机制,确保事件和日志信息不会丢失或损坏,在故障恢复和安全审计方面非常重要。
-
标准化: Syslog 是一种通用的日志标准,已经被广泛采用和支持,可以与各种操作系统、应用程序、设备和服务集成,提供了统一的数据格式和接口。
-
安全性: Syslog 支持基于 TLS 和 SSL 的加密和身份认证机制,确保传输的信息不会被窃听或篡改,保证了日志传输的安全性。
-
可视化: 通过将 Syslog 收集到集中式的日志管理系统中,可以方便地进行搜索、分析和可视化,使日志信息变得更加易于理解和利用。
通过实验和实践,更深入地了解 Syslog 的工作原理和应用场景,学会如何配置和使用 Syslog,掌握日志收集、存储、分析和可视化的技巧和最佳实践,为构建高效、可靠、安全的日志管理系统打下坚实基础。
相关文章:

Spark编程实验五:Spark Structured Streaming编程
目录 一、目的与要求 二、实验内容 三、实验步骤 1、Syslog介绍 2、通过Socket传送Syslog到Spark 3、Syslog日志拆分为DateFrame 4、对Syslog进行查询 四、结果分析与实验体会 一、目的与要求 1、通过实验掌握Structured Streaming的基本编程方法; 2、掌握…...
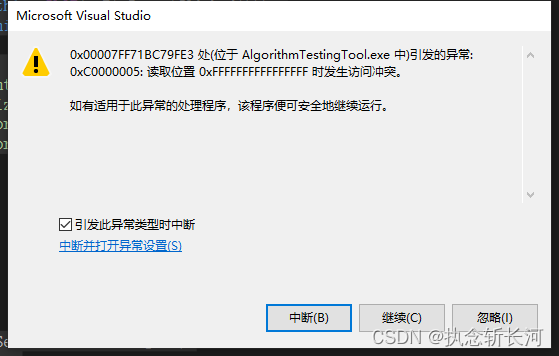
【已解决】引发的异常: 0xC0000005: 读取位置 0xFFFFFFFFFFFFFFFF 时发生访问冲突。
这种问题产生一般都会手足无措,包括笔者,但是不要慌,这种问题一般都是内存泄漏引起的。例如读者要访问一个已经被析构或者释放的变量,当然访问不了,导致存在问题。这时候读者应该从哪里产生内存泄漏这方面进行考虑&…...

Python Flask高级编程之RESTFul API前后端分离(学习笔记)
Flask-RESTful是一个强大的Python库,用于构建RESTful APIs。它建立在Flask框架之上,提供了一套简单易用的工具,可以帮助你快速地创建API接口。Flask-RESTful遵循REST原则,支持常见的HTTP请求方法,如GET、POST、PUT和DE…...

Windows如何打开投影到此电脑
1.首先点开设置 找到系统 点击投影到此电脑,如果这3行都显示灰色说明没有开启。 2.如何开启投影到此电脑 ①回到设置,点击应用 ②点击可选应用 ③ 安装无线显示器 投影设置可以和我一样...

【BUG】段错误
1. 问题 8核工程,核4在运行了20分钟以上,发生了段错误。 [C66xx_4] A00x53 A10x53 A20x4 A30x167e A40x1600 A50x850e2e A60x845097 A70xbad9f5e0 A80x0 A90x33 A100x53535353 A110x0 A120x0 A130x0 A140x0 A150x0 A160x36312e35 A170x20 A180x844df0 …...
深入理解指针(3)
目录 一、 字符指针变量二、 数组指针变量1.数组指针变量是什么?2.数组指针变量怎么初始化? 三、 二维数组传参的本质四、 函数指针变量1. 函数指针变量的创建2.函数指针变量的使用3.typedef关键字 五、 函数指针数组六、 转移表 一、 字符指针变量 在指针的类型中…...

ssm在线学习平台-计算机毕业设计源码09650
目 录 摘要 1 绪论 1.1 选题背景及意义 1.2国内外现状分析 1.3论文结构与章节安排 2 在线学习平台系统分析 2.1 可行性分析 2.2 系统业务流程分析 2.3 系统功能分析 2.3.1 功能性分析 2.3.2 非功能性分析 2.4 系统用例分析 2.5本章小结 3 在线学习平台总体设计 …...
机制原理)
【Linux 内核源码分析】内存映射(mmap)机制原理
内存映射(mmap)是 Linux 内核的一个重要机制,它为程序提供了一种将文件内容直接映射到进程虚拟地址空间的方式。同时内存映射也是虚拟内存管理和文件 IO 的重要组成部分。 在 Linux 中,虚拟内存管理是基于内存映射来实现的。在调用 mmap 函数时…...

贪心算法之合并区间
“任世界多宽广,停泊在这港口~” 区间问题,涉及到最多的就是 取交集 和 并集的概念。我们使用C排序算法后,其默认规则就是按照 “左排序”进行的。因而,我们实质上注意的是每一个区间的 右端点,根据题目要求ÿ…...

Eclipse - Colors and Fonts
Eclipse - Colors and Fonts References 编码最好使用等宽字体,Ubuntu 下自带的 Ubuntu Mono 可以使用。更换字体时看到名字里面带有 Mono 的基本都是等宽字体。 Window -> Preferences -> General -> Appearance -> Colors and Fonts -> C/C ->…...
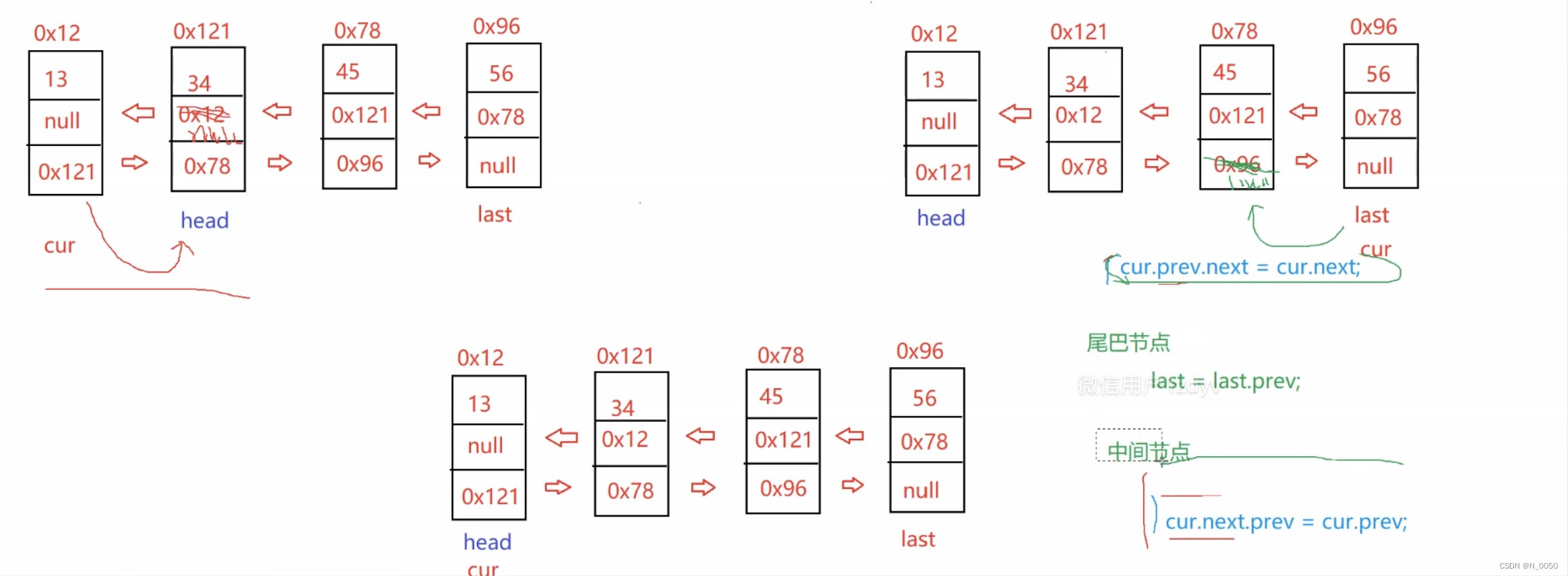
java 数据结构LinkedList类
目录 什么是LinkedList 链表的概念及结构 链表的结构 无头单向非循环链表 addFirst方法(头插法) addLast方法(尾插法) addIndex方法 contains方法 removeAllKey方法 size和clear方法 链表oj题 无头双向非循环链表 ad…...

第五次作业(防御安全)
需求: 1.办公区设备可以通过电信链路和移动链路上网(多对多的NAT,并且需要保留一个公网IP 不能用来转换) 2.分公司设备可以通过总公司的移动链路和电信链路访问到DMZ区的http服务器 3.分公司内部的客户端可以通过公网地址访问到内部的服务…...

阿里云香港轻量应用服务器是什么线路?
阿里云香港轻量应用服务器是什么线路?不是cn2。 阿里云香港轻量服务器是cn2吗?香港轻量服务器不是cn2。阿腾云atengyun.com正好有一台阿里云轻量应用服务器,通过mtr traceroute测试了一下,最后一跳是202.97开头的ip,1…...

C# Winform .net6自绘的圆形进度条
using System; using System.Drawing; using System.Drawing.Drawing2D; using System.Windows.Forms;namespace Net6_GeneralUiWinFrm {public class CircularProgressBar : Control{private int progress 0;private int borderWidth 20; // 增加的边框宽度public int Progr…...

Git基本操作(超详细)
文章目录 创建Git本地仓库配置Git配置命令查看是否配置成功重置配置 工作区、暂存区、版本库添加文件--场景一概述实例操作 查看.git文件添加文件--场景二修改文件版本回退撤销修改情况⼀:对于工作区的代码,还没有 add情况⼆:已经 add &#…...

【AGI视频】Sora的奇幻之旅:未来影视创作的无限可能
在五年后的未来,科技的发展为影视创作带来了翻天覆地的变化。其中,Sora视频生成软件成为了行业的翘楚,引领着全新的创作潮流。Sora基于先进的Transformer架构,将AI与人类的创造力完美结合,为观众带来了前所未有的视听盛…...

Docker部署nginx
搜索镜像 docker search nginx 下载拉取nginx镜像 docker pull nginx 查看镜像 docker images 启动容器 docker run -d --name nginx01 -p 3344:80 nginx 外部端口需要在服务器安全组中设置,使用docker镜像nginx以后台模式启动一个容器,并将容器…...

C++Qt——自定义信号与槽
自定义信号与槽 自定义信号与槽是实现对象间通信的一种机制,比如按钮和窗口间的通信。 一、定义信号 Signal关键字声明的类成员函数。不需要实现,只需要声明。 signals:void mySignals();//定义信号,不用实现二、定义槽 可以使任何普通成员函数&…...

提高项目的性能和响应速度的方法
目录 引言 一、代码优化 二、数据库优化 三、缓存技术: 四、异步处理 1. 将耗时的操作改为异步处理 1.1 文件上传 1.2 邮件发送 2. 使用消息队列实现异步处理 2.1 配置消息队列 2.2 发送消息 2.3 接收消息并处理 五、负载均衡和集群 1. 负载均衡 1.1 …...

QT学习事件
一、事件处理过程 众所周知 Qt 是一个基于 C 的框架,主要用来开发带窗口的应用程序(不带窗口的也行,但不是主流)。 我们使用的基于窗口的应用程序都是基于事件,其目的主要是用来实现回调(因为只有这样程序…...

3步快速实现Android Studio完整汉化:告别英文困扰,提升开发效率
3步快速实现Android Studio完整汉化:告别英文困扰,提升开发效率 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack…...

HS2-HF Patch:为HoneySelect2打造的全能增强解决方案
HS2-HF Patch:为HoneySelect2打造的全能增强解决方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 如果你正在寻找一种简单高效的方式来提升Honey…...
)
终极指南:如何将STL文件快速转换为STEP格式(免费工具完整教程)
终极指南:如何将STL文件快速转换为STEP格式(免费工具完整教程) 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在现代3D设计与制造流程中,STL到S…...

UnityExplorer终极调试指南:如何用游戏内UI工具提升开发效率
UnityExplorer终极调试指南:如何用游戏内UI工具提升开发效率 【免费下载链接】UnityExplorer An in-game UI for exploring, debugging and modifying IL2CPP and Mono Unity games. 项目地址: https://gitcode.com/gh_mirrors/un/UnityExplorer UnityExplor…...

Postman与JMeter协同实战:接口功能验证与性能压测一体化方案
1. 这不是工具组合秀,而是接口测试工程师的生存现场你有没有过这样的经历:开发刚提测,接口文档还没写完,测试环境连基础鉴权都配不齐,但上线时间表已经钉死在下周三?这时候打开Postman点几下,发…...

终极免Root解决方案:Nrfr工具实战指南,轻松修改SIM卡国家码解锁全球应用
终极免Root解决方案:Nrfr工具实战指南,轻松修改SIM卡国家码解锁全球应用 【免费下载链接】Nrfr 🌍 免 Root 的 SIM 卡国家码修改工具 | 解决国际漫游时的兼容性问题,帮助使用海外 SIM 卡获得更好的本地化体验,解锁运营…...

如何快速掌握开源笔记工具:Xournal++ 终极使用指南
如何快速掌握开源笔记工具:Xournal 终极使用指南 【免费下载链接】xournalpp Xournal is a handwriting notetaking software with PDF annotation support. Written in C with GTK3, supporting Linux (e.g. Ubuntu, Debian, Arch, SUSE), macOS and Windows 10. S…...
)
Claude学术写作辅助应用:如何规避AI检测雷区?3步合规化润色法(含Turnitin 2024最新阈值对照表)
更多请点击: https://intelliparadigm.com 第一章:Claude学术写作辅助应用 Claude 系列大模型凭借其长上下文理解能力、严谨的逻辑推理与出色的文本生成质量,正逐步成为科研人员在文献综述、论文润色、实验描述撰写及学术表达规范化过程中的…...

终极指南:如何快速重置JetBrains IDE试用期并延长30天评估时间
终极指南:如何快速重置JetBrains IDE试用期并延长30天评估时间 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否正在使用IntelliJ IDEA、PyCharm或WebStorm等JetBrains开发工具,却因为…...

AI与机器学习在软件测试中的实战应用与工具选型指南
1. 项目概述:当AI遇见软件测试,一场效率革命正在发生干了十几年软件测试,从最初的手动点点点,到后来的脚本录制回放,再到现在的持续集成流水线,我亲眼见证了测试这个行当的变迁。但说实话,最近几…...