[杂记]mmdetection3.x中的数据流与基本流程详解(数据集读取, 数据增强, 训练)
之前跑了一下mmdetection 3.x自带的一些算法, 但是具体的代码细节总是看了就忘, 所以想做一些笔记, 方便初学者参考. 其实比较不能忍的是, 官网的文档还是空的…
这次想写其中的数据流是如何运作的, 包括从读取数据集的样本与真值, 到数据增强, 再到模型的forward当中.
0. MMDetection整体组成部分
让我们首先回顾一下C++的标准模板库(STL)是怎样设计的. STL的三个核心组件是容器, 算法与迭代器. 容器, 例如vector, queue等等, 他们是负责存储数据的, 算法是负责进行一些操作, 例如排序, 查找等等. 而迭代器是容器与算法之间的桥梁, 也就是算法可以通过迭代器去访问容器, 使得算法可以独立于容器的类型进行操作. 三个部分相辅相成, 就达到了泛型编程的理念.
再让我们回顾一下一套深度学习的代码包含什么部分. 从大的方面来说, 需要有数据的读取与增强(DataLoader), 模型的定义, 损失函数的计算, 负责梯度传播的优化器, 在验证(测试)集上的评估等. 同理, MMDetection也是按照这种方式来的, 并且每个部分接口相通, 就可以实现更广义的模型定义和训练方式.
在mmengine/registry/__init__.py中, 我们可以看到, MMEngine(或者说MMDetection)总体有这些类型的模块:
from .root import (DATA_SAMPLERS, DATASETS, EVALUATOR, FUNCTIONS, HOOKS,INFERENCERS, LOG_PROCESSORS, LOOPS, METRICS, MODEL_WRAPPERS,MODELS, OPTIM_WRAPPER_CONSTRUCTORS, OPTIM_WRAPPERS,OPTIMIZERS, PARAM_SCHEDULERS, RUNNER_CONSTRUCTORS, RUNNERS,TASK_UTILS, TRANSFORMS, VISBACKENDS, VISUALIZERS,WEIGHT_INITIALIZERS)
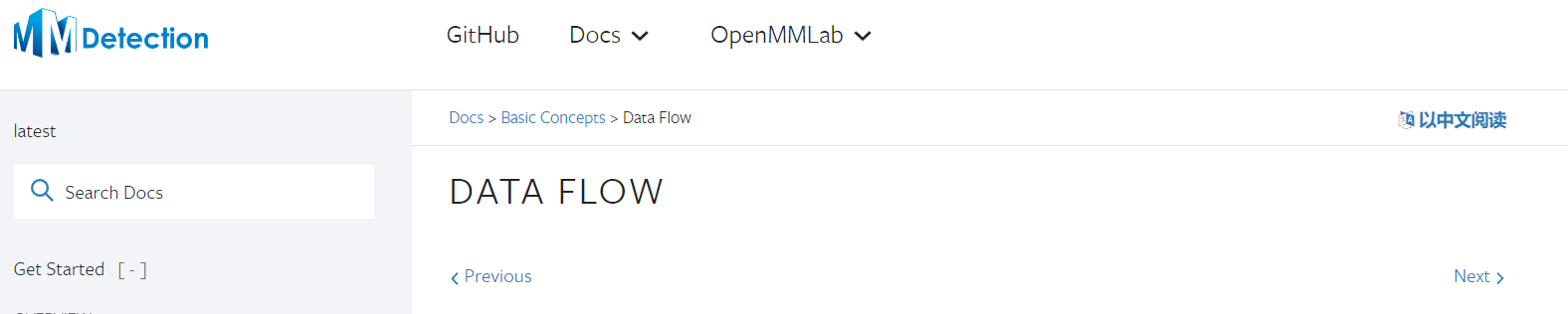
那么以上这么多模块可以分成几类, 分别负责什么呢? 按照我个人的理解, MMDetection的整体组成部分可以表示为下图:
为了节省空间, 优化器相关并未画出
1. 认识config文件
mmdetection设计的核心思想是通过字典来配置整个的训练过程和模型定义, 这些字典放在一个.py的config文件中. 一般来说,config文件最重要的就是数据加载(train_dataloader, val_dataloader和test_dataloader), 模型定义(model)和训练与测试过程(train_pipeline, test_pipeline). 除此之外, 还有一些训练, 测试配置(train_cfg, test_cfg)等等. 具体config的例子可以参照官网Learn about configs.
需要注意的是, mmdetection中字典定义class的方式, 往往是键type表示类的名字, 之后的其他键都是类初始化需要的参数. 例如, 如果我想自定义一个模型, 叫做MyModel, 定义在当前目录下的./models/my_model.py中, 定义方式如下:
from mmdet.registry import MODELS # 自定义模型, 需要在模型库中"注册", 初始化时才能找到定义
from mmdet.models.mot.base import BaseMOTModel # 一个模型基类@MODELS.register_module() # 装饰器 在模型库中"注册"
class MyModel(BaseMOTModel):def __init__(self, arg1=..., arg2=..., arg3=...):...def loss(self, inputs, data_samples): # 前向传播, inputs是输入tensor, data_samples是包含标签的列表...
如果按上述方式定义了模型, 那么在我们的配置文件中, 就是这个样子:
# 必须将自定义类的py文件导入 这样可以自动register自定义模型 否则模型初始化时找不到custom_imports = dict(imports=['models.my_model'],allow_failed_imports=False)# 现在就可以愉快的传参了
models=dict(type='MyModel', arg1=1, arg2=[16, 128], arg3=dict(channel=256), ...
)
同样, 我们可以自定义DataLoader, Loss, 等等.
此外, dict是可以嵌套的, 例如mmdetection将检测模型分成了backbone, neck和head三部分, 那么如果我们又自定义了一个Head, 叫MyHead:
from mmdet.registry import MODELS # 自定义模型, 需要在模型库中"注册", 初始化时才能找到定义
from mmengine.model import BaseModule # 一个模型基类@MODELS.register_module() # 装饰器 在模型库中"注册"
class MyHead(BaseModule):def __init__(self, arg4=...):...这样, 如果MyModel的前向传播过程中需要一个head, 则代码大致是这个样子:
from mmdet.registry import MODELS # 自定义模型, 需要在模型库中"注册", 初始化时才能找到定义
from mmdet.models.mot.base import BaseMOTModel # 一个模型基类@MODELS.register_module() # 装饰器 在模型库中"注册"
class MyModel(BaseMOTModel):def __init__(self, arg1=..., arg2=..., arg3=...,head=...):self.head = MODELS.build(head) # 建立Head的模型, 类型是nn.Module...def loss(self, inputs, data_samples): # 前向传播, inputs是输入tensor, data_samples是包含标签的列表... # 一些其他过程ret = self.head(inputs) # forward... # 后处理配置文件中对应更改为:
如果按上述方式定义了模型, 那么在我们的配置文件中, 就是这个样子:
custom_imports = dict(imports=['models.my_model', '自定义HEAD所在的py文件'],allow_failed_imports=False)models=dict(type='MyModel', arg1=1, arg2=[16, 128], arg3=dict(channel=256), head=dict( # 定义headtype='MyHead',arg4=256,...)...
)
篇幅所限, 自定义损失函数, 数据增强之类的就不一一列举了.
2. 数据流
我们接下来以检测与跟踪任务为例, 看看数据到底是如何被读入的. 我们以训练过程说明.
在训练过程中, 我们会初始化一个RUNNER类, 其读入我们的config文件并依次完成各种(模型, 数据加载, 优化器, 钩子等等)的初始化. 我们以官方提供的train.py为例:
runner = Runner.from_cfg(cfg)
from_cfg()是一个类方法(classmethod), 在其中我们实例化了Runner类.
随后, 我们调用Runner的train()方法进行训练. 首先, 我们实例化训练循环:
self._train_loop = self.build_train_loop(self._train_loop) # type: ignore训练循环就属于LOOP类型.
在这里, 我们以最常用的EpochBasedTrainLoop为例. 在EpochBasedTrainLoop的初始化函数中, 根据config文件中的train_dataloader字典实例化出torch的DataLoader类():

data_loader = DataLoader(dataset=dataset,sampler=sampler if batch_sampler is None else None,batch_sampler=batch_sampler,collate_fn=collate_fn,worker_init_fn=init_fn,**dataloader_cfg)return data_loader当然, 我们知道torch的DataLoader类在调用的时候, 会调用到dataset(类别是torch.utils.data.Dataset)的__getitem__方法. 因此, 我们从__getitem__入手来探索数据流.
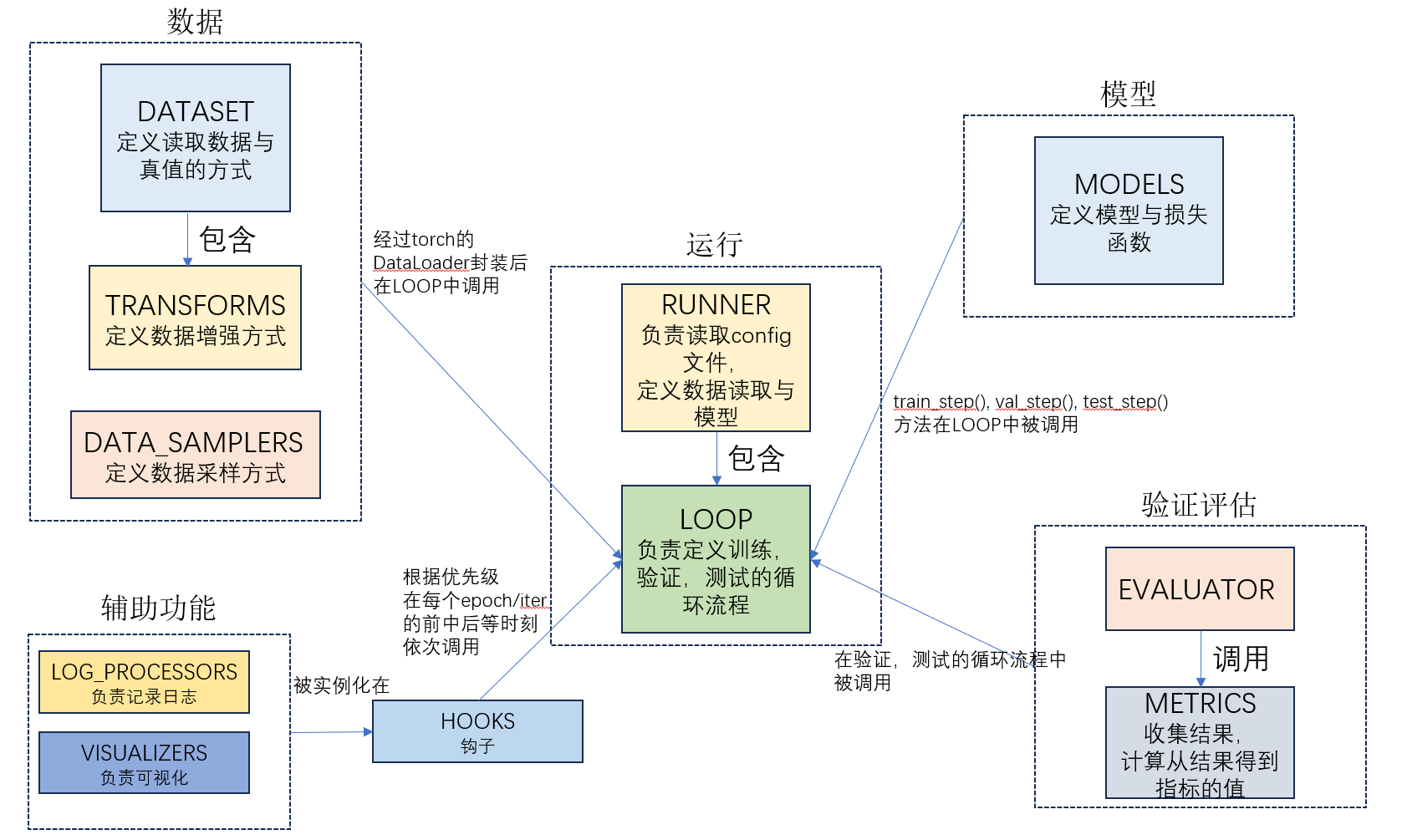
在MMDetection的设计中, 数据集的类都是继承于MMengine中的BaseDataset, 其中的__getitem__是这样写的:

def __getitem__(self, idx: int) -> dict:if not self._fully_initialized:print_log('Please call `full_init()` method manually to accelerate ''the speed.',logger='current',level=logging.WARNING)self.full_init()if self.test_mode:data = self.prepare_data(idx)if data is None:raise Exception('Test time pipline should not get `None` ''data_sample')return datafor _ in range(self.max_refetch + 1):data = self.prepare_data(idx)# Broken images or random augmentations may cause the returned data# to be Noneif data is None:idx = self._rand_another()continuereturn dataraise Exception(f'Cannot find valid image after {self.max_refetch}! ''Please check your image path and pipeline')我们可以看到, 在__getitem__中最核心的是self.prepare_data(idx). 按照这种思路一级一级向上查找, 我们就可以总结出如下图的数据读取流程:
其中, 数据增强pipeline是一系列类型为TRANSFORMS类的列表, 再每经过一次数据增强时, 字典都会被更新.
我们以较为常用的随机便宜(RandomShift)来说, 其是这样定义的:
@TRANSFORMS.register_module()
class RandomShift(BaseTransform):def __init__(self,...@autocast_box_type()def transform(self, results: dict) -> dict: # transform方法, 更新字典, 图像与对应的边界框等都需要被更新"""Transform function to random shift images, bounding boxes.Args:results (dict): Result dict from loading pipeline.Returns:dict: Shift results."""if self._random_prob() < self.prob:img_shape = results['img'].shape[:2]random_shift_x = random.randint(-self.max_shift_px,self.max_shift_px)random_shift_y = random.randint(-self.max_shift_px,self.max_shift_px)new_x = max(0, random_shift_x)ori_x = max(0, -random_shift_x)new_y = max(0, random_shift_y)ori_y = max(0, -random_shift_y)# TODO: support mask and semantic segmentation maps.bboxes = results['gt_bboxes'].clone()bboxes.translate_([random_shift_x, random_shift_y])# clip borderbboxes.clip_(img_shape)# remove invalid bboxesvalid_inds = (bboxes.widths > self.filter_thr_px).numpy() & (bboxes.heights > self.filter_thr_px).numpy()# If the shift does not contain any gt-bbox area, skip this# image.if not valid_inds.any():return resultsbboxes = bboxes[valid_inds]results['gt_bboxes'] = bboxesresults['gt_bboxes_labels'] = results['gt_bboxes_labels'][valid_inds]if results.get('gt_ignore_flags', None) is not None:results['gt_ignore_flags'] = \results['gt_ignore_flags'][valid_inds]# shift imgimg = results['img']new_img = np.zeros_like(img)img_h, img_w = img.shape[:2]new_h = img_h - np.abs(random_shift_y)new_w = img_w - np.abs(random_shift_x)new_img[new_y:new_y + new_h, new_x:new_x + new_w] \= img[ori_y:ori_y + new_h, ori_x:ori_x + new_w]results['img'] = new_imgreturn results
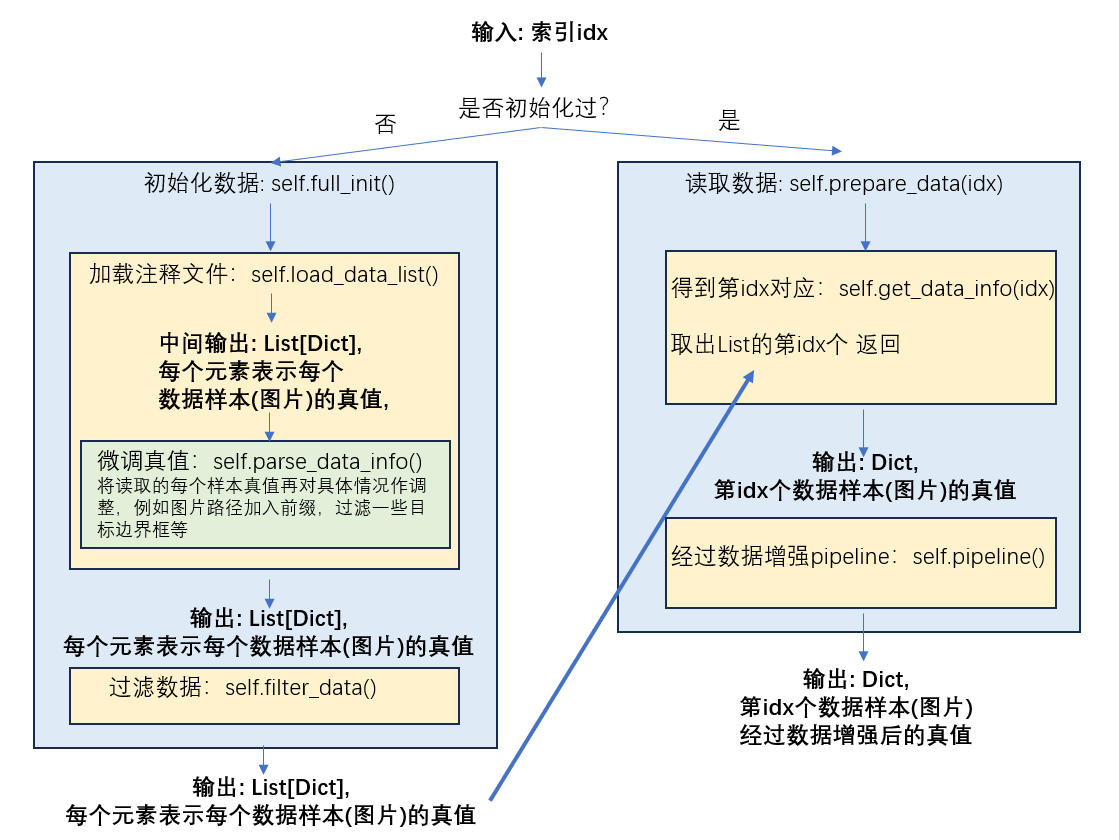
需要注意的是, 经过pipeline后, 字典最终会被更新成如下形式:
dict = {'inputs': torch.Tensor, 'data_samples': DetDataSample或TrackDataSample等}其中'inputs'键对应的值就是转换为tensor的图片, 而'data_samples'键对应的值是表示样本的类, 在检测任务中, 是DetDataSample, 跟踪任务中, 是TrackDataSample. DetDataSample类有许多成员, 包括该样本(图片)的目标的边界框真值, 分割真值等:

class DetDataSample(BaseDataElement):"""A data structure interface of MMDetection. They are used as interfacesbetween different components.The attributes in ``DetDataSample`` are divided into several parts:- ``proposals``(InstanceData): Region proposals used in two-stagedetectors.- ``gt_instances``(InstanceData): Ground truth of instance annotations.- ``pred_instances``(InstanceData): Instances of detection predictions.- ``pred_track_instances``(InstanceData): Instances of trackingpredictions.- ``ignored_instances``(InstanceData): Instances to be ignored duringtraining/testing.- ``gt_panoptic_seg``(PixelData): Ground truth of panopticsegmentation.- ``pred_panoptic_seg``(PixelData): Prediction of panopticsegmentation.- ``gt_sem_seg``(PixelData): Ground truth of semantic segmentation.- ``pred_sem_seg``(PixelData): Prediction of semantic segmentation.以上过程可以借用MMEngine文档里的一个图说明:
最终, 模型的forward, loss, predict等方法都是接收inputs: torch.Tensor与data_samples作为输入, 例如:

def loss(self, inputs: Tensor, data_samples: TrackSampleList,**kwargs) -> Union[dict, tuple]:相关文章:
[杂记]mmdetection3.x中的数据流与基本流程详解(数据集读取, 数据增强, 训练)
之前跑了一下mmdetection 3.x自带的一些算法, 但是具体的代码细节总是看了就忘, 所以想做一些笔记, 方便初学者参考. 其实比较不能忍的是, 官网的文档还是空的… 这次想写其中的数据流是如何运作的, 包括从读取数据集的样本与真值, 到数据增强, 再到模型的forward当中. 0. MMDe…...
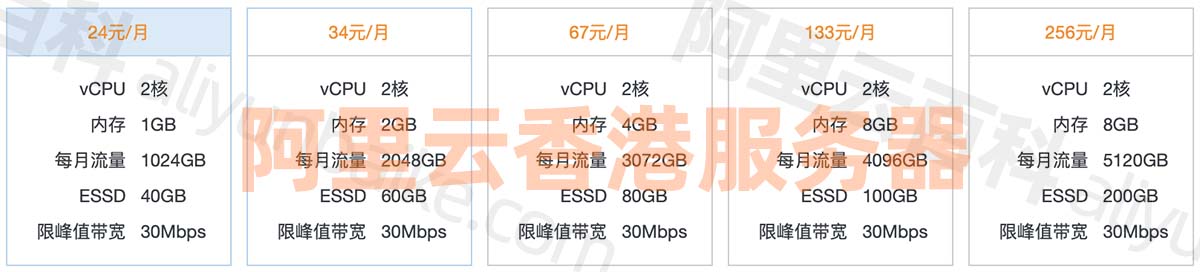
阿里云香港轻量应用服务器怎么样,建站速度快吗?
阿里云香港服务器中国香港数据中心网络线路类型BGP多线精品,中国电信CN2高速网络高质量、大规格BGP带宽,运营商精品公网直连中国内地,时延更低,优化海外回中国内地流量的公网线路,可以提高国际业务访问质量。阿里云服务…...

事务及在SpringBoot项目中使用的两种方式
1.事务简介 事务(transaction)是访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。 事物的四大特性: 原子性(Atomicity)…...

stm32--笔记
一、引脚与变量 二、STM32时钟 [STM32-时钟系统详解_stm32时钟_KevinFlyn的博客-CSDN博客] 三、定时器中断实验 1、定时器中断实验 stm32关于通用定时器的周期、频率计算公式_stm32tim频率计算_胶囊咖啡的博客-CSDN博客 【STM32】通用…...
)
2024前端面试准备之CSS篇(二)
全文链接 1. 什么是伪类和伪元素 伪类(Pseudo-class): 伪类是选择器的一种,用于选择特定状态或条件下的元素。它们以冒号(:)开头,用于向选择器添加额外的特定条件。例如,:hover伪类用于选择鼠标悬停在元素上的状态,:nth-child(n)伪类用于选择父元素下的第n个子元素等。…...

轨道交通信号增强与覆盖解决方案——经济高效,灵活应用于各类轨道交通场景!
方案背景 我国是世界上轨道交通里程最长的国家,轨道交通也为我们的日常出行带来极大的便利。伴随着无线通信技术的快速发展将我们带入电子时代,出行的过程中对无线通信的依赖程度越来越高,无论是车站还是车内都需要强大、高质量的解决方案以…...

学习数据接构和算法的第10天
题目讲解 尾插 #include <stdio.h> #include <stdlib.h> // 定义顺序表结构 #define MAX_SIZE 100 struct ArrayList {int array[MAX_SIZE];int size; // 当前元素个数 }; // 初始化顺序表 void init(struct ArrayList *list) {list->size 0; // 初始时元素个…...

初识KMP算法
目录 1.KMP算法的介绍 2.next数组 3.总结 1.KMP算法的介绍 首先我们会疑惑,什么是KMP算法?这个算法是用来干什么的? KMP(Knuth-Morris-Pratt)算法是一种用于字符串匹配的经典算法,它的目标是在一个主文本…...

Javaweb之SpringBootWeb案例之AOP概述及入门的详细解析
2.1 AOP概述 什么是AOP? AOP英文全称:Aspect Oriented Programming(面向切面编程、面向方面编程),其实说白了,面向切面编程就是面向特定方法编程。 那什么又是面向方法编程呢,为什么又需要面向…...

【Java代码洁癖】NO.2 单元测试mock显式赋值,不能忍
反例 RunWith(MockitoJunitRunner.class) public class Test {Mockpublic SomeBean someBean new SomeBean(); } 正例 RunWith(MockitoJunitRunner.class) public class Test {Mockpublic SomeBean someBean ; } 解读 使用Mock注解的对象不应该被显式赋值,应当…...
2024.2.19
使用fread和fwrite完成两个文件的拷贝 #include<stdio.h> #include<stdlib.h> #include<string.h> int main(int argc, const char *argv[]) {FILE *fpNULL;if((fpfopen("./tset.txt","w"))NULL){perror("open error");retur…...
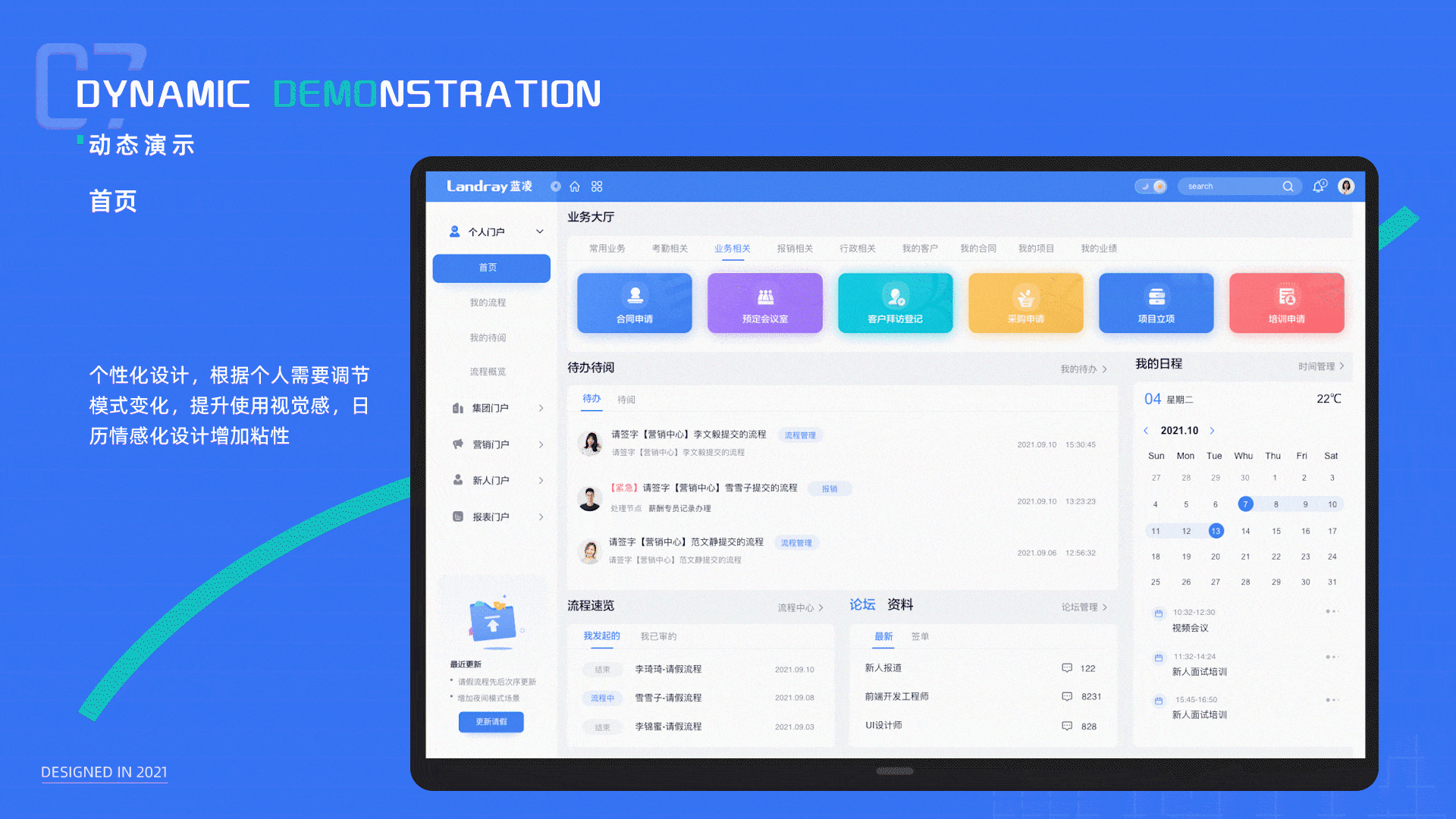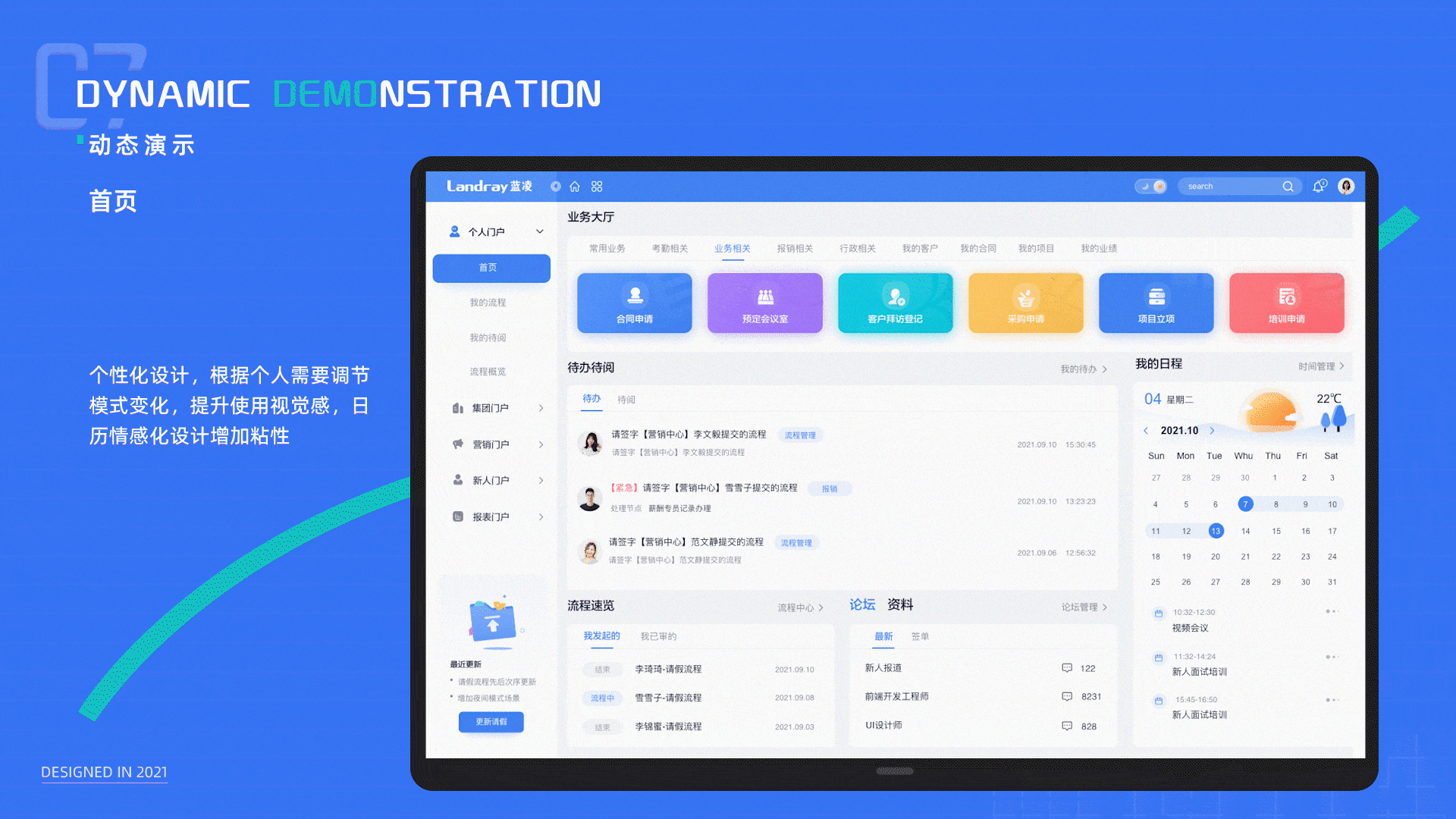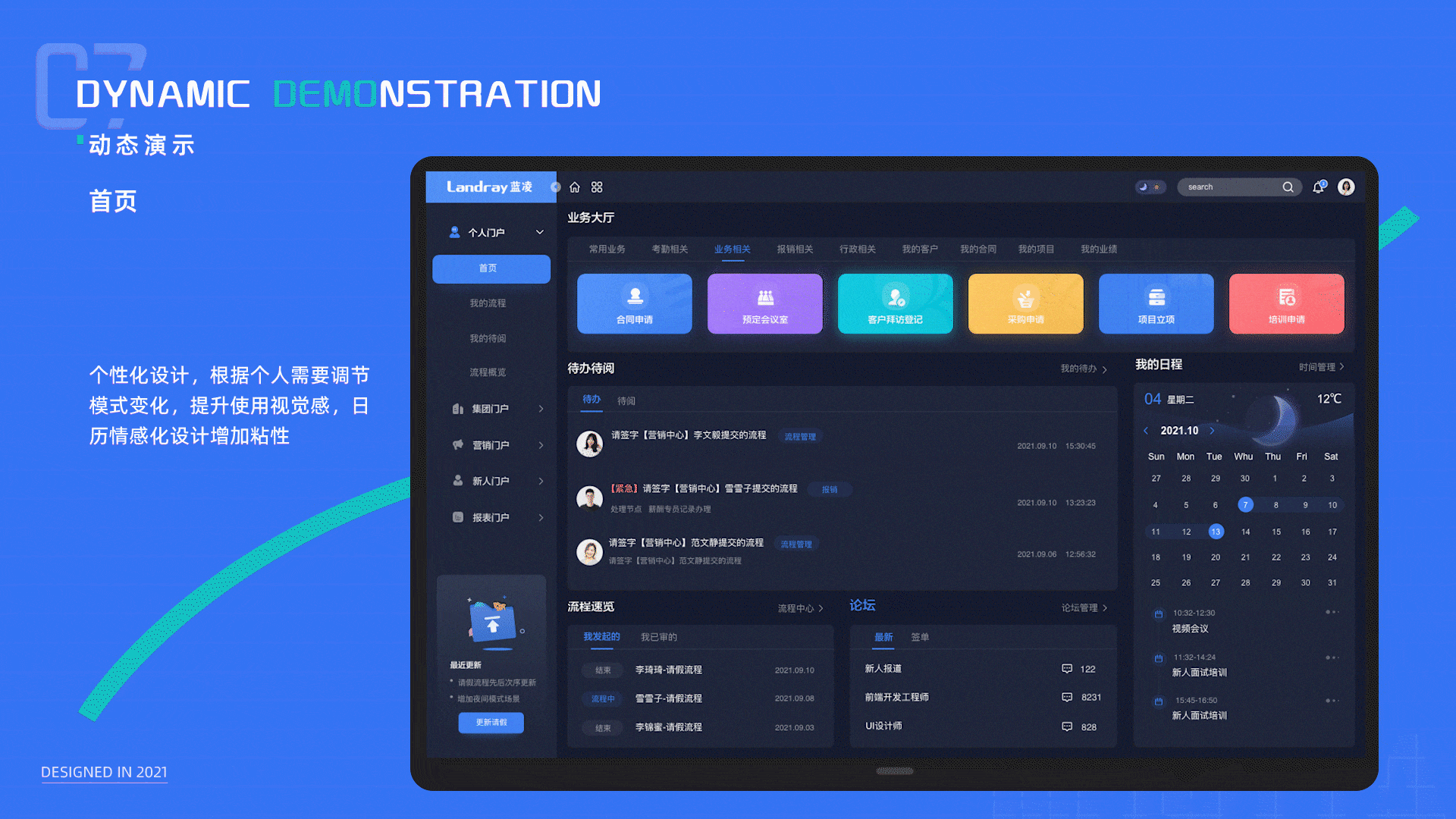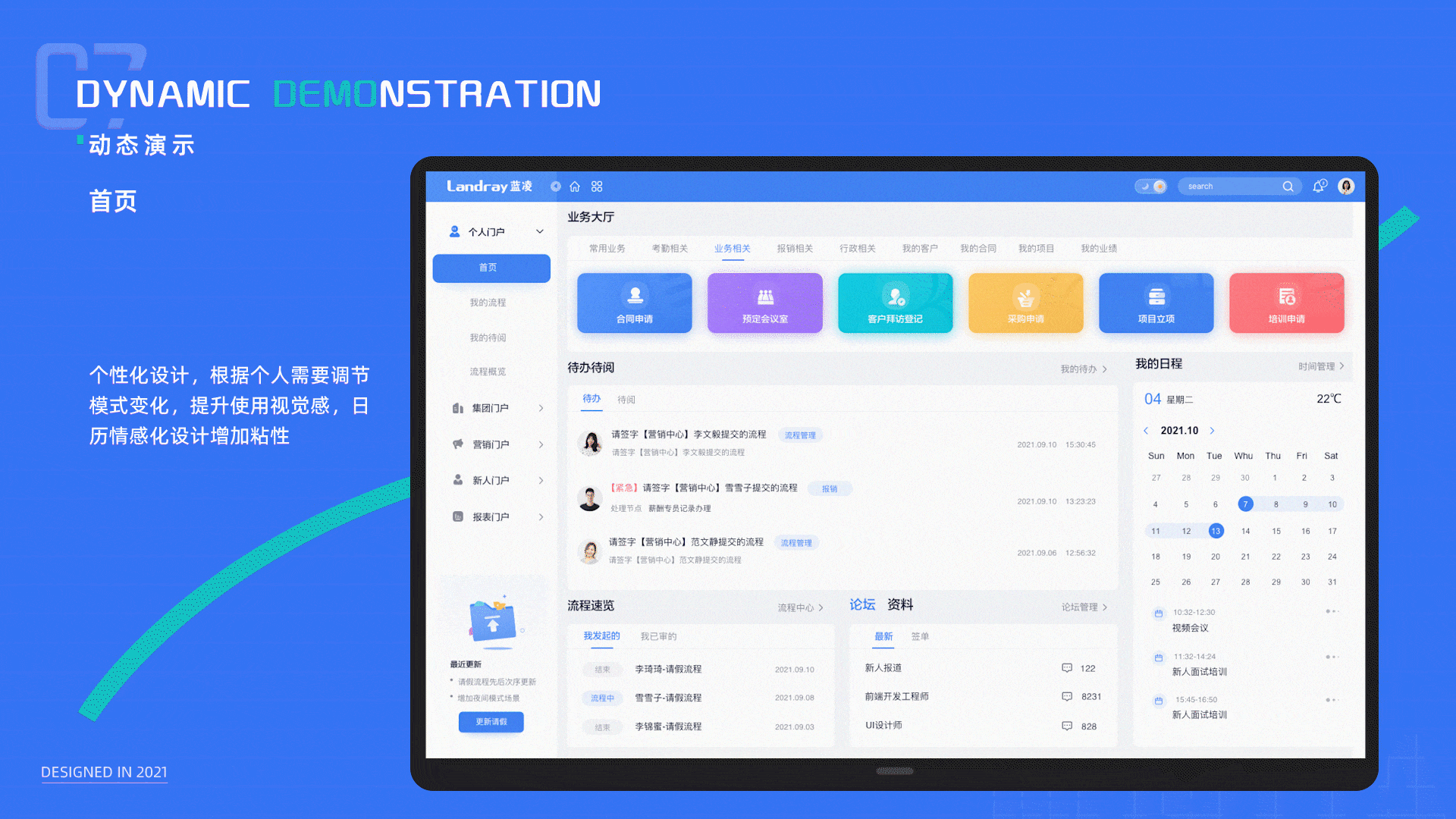
B端系统升级方案模板:针对美观性和体验性升级(总体方案)
大家好,我是大美B端工场,专注于前端开发和UI设计,有需求可以私信。本篇从全局分享如何升级B端系统,搞B端系统升级的有个整体思维,不是说美化几个图标,修改几个页面就能解决的,这个方案模板&…...

第九篇:node静态文件服务(中间件)
🎬 江城开朗的豌豆:个人主页 🔥 个人专栏 :《 VUE 》 《 javaScript 》 📝 个人网站 :《 江城开朗的豌豆🫛 》 ⛺️ 生活的理想,就是为了理想的生活 ! 📘 引言: 当今互联网时代&am…...

软件测试-功能测试-测试流程-如何进行需求评审?对于测试人员来讲,如何从测试的角度评审需求文档?
导言 产品人员编写的需求文档,无疑是一个项目或者一项新功能的开端。需求文档的优劣,直接影响开发人员的代码质量,更会影响到后续的测试工作。所以,我认为,需求评审对于开发质量以及测试质量至关重要,那么…...

无刷电机驱动详解
无刷电机驱动详解 有刷电机和无刷电机字面上理解最大的区别就是有无电刷,实际上区别还有换向器,电刷和换向器的作用是什么?电刷负责在旋转部件与静止部件之间传导电流,换向器则利用旋转惯性周期性的改变线圈中电流的方向。 所以…...
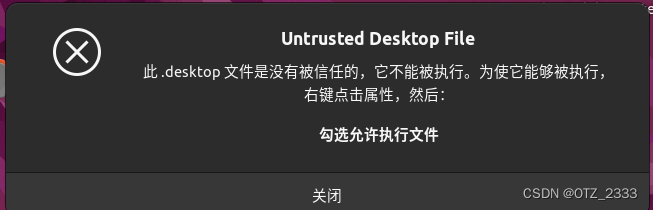
Linux+Win双系统远程重启到Win
背景 电脑安装了双系统(ubuntu 22.04 win11),默认进入ubuntu系统。给电脑设置了WoL(Wake-on-LAN),方便远程开机远程控制。 但是ubuntu的引导程序grub无法远程控制,远程开机会默认进入ubuntu。 虽然说可以进入ubuntu后…...
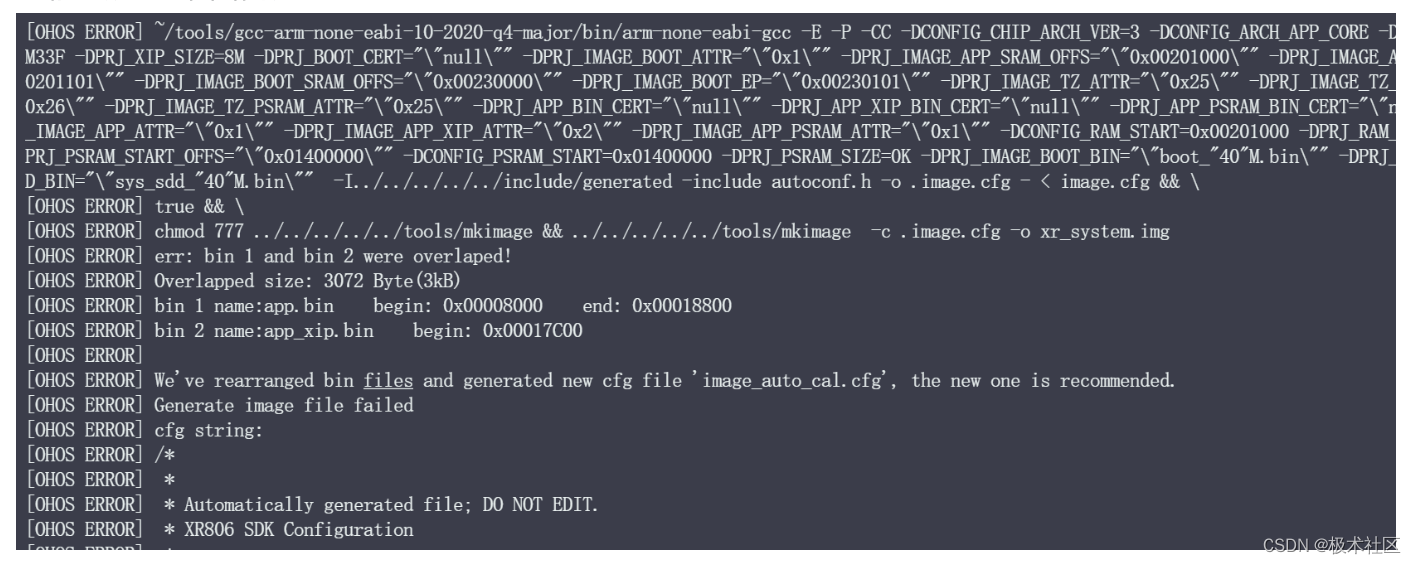
【XR806开发板试用】+移植rosserial到XR806
1 XR806简介 板子来源于极术社区的试用,XR806的在线网址 其主要参数: 主控XR806AF2LDDRSIP 288KB SRAM存储SIP 160KB Code ROM. SIP 16Mbit Flash.天线板载WiFi/BT双天线,可共存按键reboot按键 1,功能按键 1灯红色电源指示灯 1…...

JSON协议详解、语法及应用
文章目录 一、什么是JSON二、JSON协议结构协议结构包括要素JSON语法规则JSON的协议结构示例 三、JSON的特点四、JSON常见应用场景 一、什么是JSON JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它以易于阅读和编写的文本格式…...

kubeasz部署k8s:v1.27.5集群
安装k8s集群相关系统及组件的详细版本号 Ubuntu 22.04.3 LTS k8s: v1.27.5 containerd: 1.6.23 etcd: v3.5.9 coredns: 1.11.1 calico: v3.24.6 安装步骤清单: 1.deploy机器做好对所有k8s node节点的免密登陆操作 2.deploy机器安装好python2版本以及pip,…...
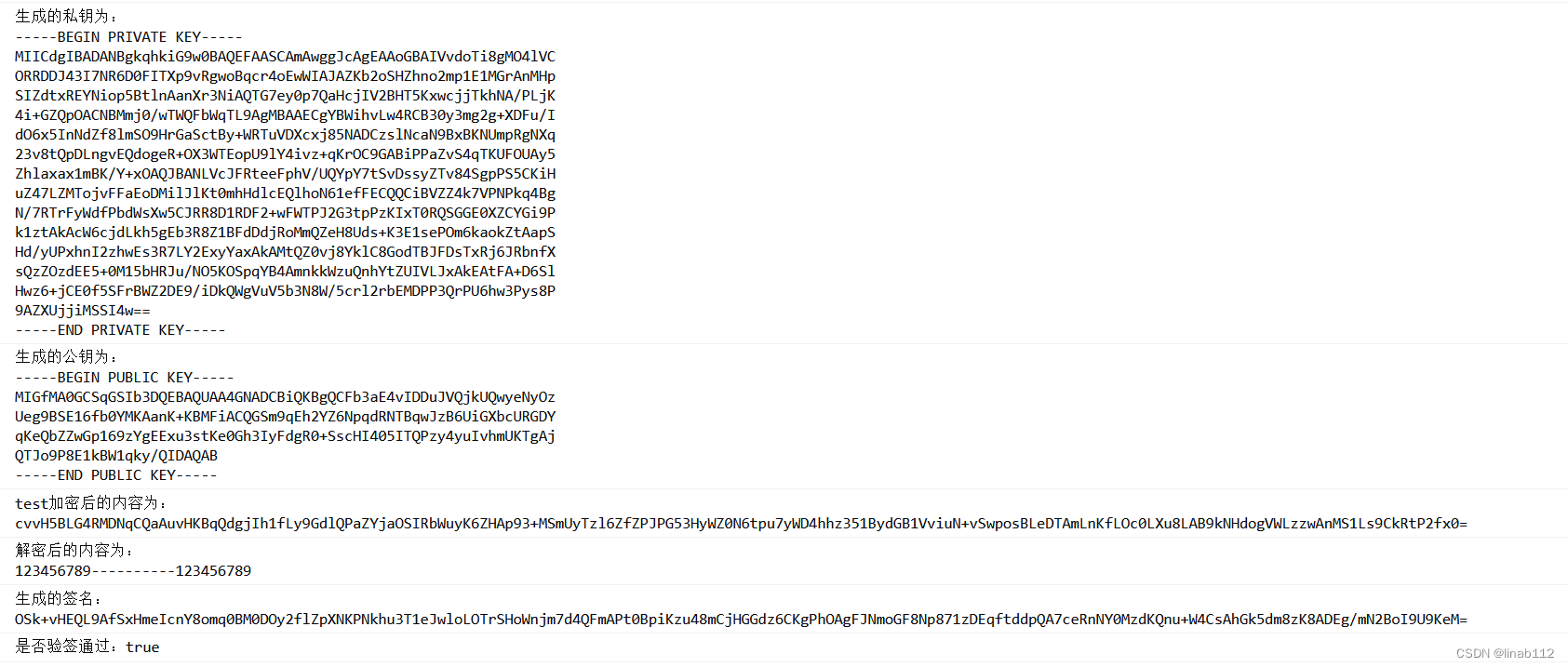
RSA加密,解密,加签及验签
目录 1.说明 2.加密和加签的区别 3.后端加密,解密,加签及验签示例 4.前端加密,解密,加签及验签示例 5.前端加密,后端解密,前端加签,后端验签 6.注意事项 1.说明 RSA算法是一种非对称加密…...

Windows 11硬件限制绕过终极指南:3种实用方法让老电脑轻松升级
Windows 11硬件限制绕过终极指南:3种实用方法让老电脑轻松升级 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

别再死记硬背EM算法了!用Python手写一个硬币实验,5分钟搞懂E步和M步
用Python实现EM算法:从硬币实验到高斯混合模型实战 很多人在学习EM算法时,都会被复杂的数学推导劝退。但今天我要带你用Python手写一个硬币实验,通过不到50行代码直观理解E步和M步的奥妙。我们不仅会复现经典的双硬币问题,还会延伸…...

AI提示词工程实战:从入门到精通
本文深入讲解了提示词工程的重要性及其在AI应用中的核心作用。文章首先通过对比数据强调了会与不会使用提示词的人在AI效果上的巨大差异。接着,详细介绍了RISE提示词框架,包括角色、指令、场景和期望四个要素,以及高级技巧如Few-shot提示词和…...

别再乱删文件了!详解CentOS LVM动态调整分区:从理解PV、VG、LV到实战给根目录扩容
深入掌握LVM:从核心概念到实战扩容的完整指南在Linux系统管理中,磁盘空间管理一直是运维工程师的必修课。想象一下这样的场景:你的服务器根分区空间告急,而/home分区却闲置了大量空间,传统的分区方式让你束手无策——这…...

物理信息机器学习在声场估计中的应用:原理、实践与前沿
1. 物理信息机器学习:当声学物理遇上数据智能 如果你在声学、音频信号处理或者空间音频领域工作,那么“声场估计”这个词对你来说一定不陌生。简单来说,它就像是用有限的几个“耳朵”(传声器)去“猜”出整个空间里每一…...

破解特征相关性难题:MVIM与CVIM如何提供更稳健的变量重要性评估
1. 项目概述:从“黑盒”到“可解释”的桥梁在数据科学和机器学习的日常工作中,我们常常面临一个核心矛盾:一方面,以XGBoost、深度神经网络为代表的复杂模型因其卓越的预测性能而备受青睐;另一方面,这些模型…...

差分隐私矩阵机制与FFT优化:保护多轮迭代计算的高效方法
1. 差分隐私矩阵分解:从理论到工程实践在联邦学习、推荐系统这些需要频繁进行多轮迭代计算的场景里,我们常常面临一个核心矛盾:既要利用全体参与者的数据来训练一个高质量的全局模型,又要确保任何单个参与者的敏感信息不会在训练过…...

量子多体系统模拟:MPS与DMRG算法实践
1. 量子多体系统模拟基础框架在量子多体系统的研究中,矩阵乘积态(MPS)已成为描述一维强关联系统的标准工具。这种表示方法的核心思想是将一个N体量子态分解为N个局部张量的收缩形式,每个张量对应一个物理位点。具体数学表达为: [ |ψ⟩ \sum…...

市面上靠谱的ERP/MES/定制开发/APP开发/软件开发公司
在数字化浪潮下,80%的实体企业都想通过ERP、MES或定制软件实现降本增效,但选对服务商比“买系统”更重要——用模板化系统的企业,70%会因为流程适配差、运维跟不上而半途而废;找外包开发的企业,又面临“开发完就甩手”…...

为什么你的 Agent 总是“偷懒”?大模型惰性与激励提示词研究
为什么你的 Agent 总是“偷懒”?大模型惰性与激励提示词研究 各位知识工作者、AI 产品经理、大模型开发者、编程爱好者——如果你正在开发或使用基于大语言模型(LLMs)的智能体(Agent),或者只是在日常用 ChatGPT、Claude、文心一言这类工具时,肯定遇到过这类令人抓狂的场…...