sentinel的资源数据指标是如何采集
资源数据采集
之前的NodeSelectorSlot和ClusterBuilderSlot已经完成了对资源调用树的构建, 现在则是要对资源进行收集, 核心点就是这些资源数据是如何统计
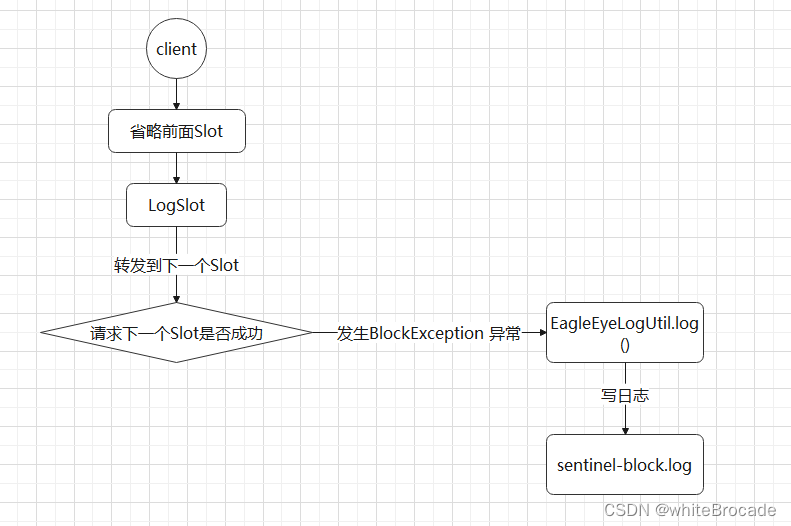
LogSlot
作用: 记录异常请求日志, 用于故障排查
public class LogSlot extends AbstractLinkedProcessorSlot<DefaultNode> {@Overridepublic void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode obj, int count, boolean prioritized, Object... args)throws Throwable {try {// 啥也没干, 直接调用下一个SlotfireEntry(context, resourceWrapper, obj, count, prioritized, args);} catch (BlockException e) {// 被流控或者熔断降级后直接打印logEagleEyeLogUtil.log(resourceWrapper.getName(), e.getClass().getSimpleName(), e.getRuleLimitApp(),context.getOrigin(), e.getRule().getId(), count);throw e;} catch (Throwable e) {RecordLog.warn("Unexpected entry exception", e);}}@Overridepublic void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {try {// 啥也没干,直接调用下一个 SlotfireExit(context, resourceWrapper, count, args);} catch (Throwable e) {RecordLog.warn("Unexpected entry exit exception", e);}}
}
LogSlot只做了一件事, 当出现BlockException 异常时, 记录log日志(EagleEyeLogUtil.log 会将日志写到 sentinel-block.log 文件中)
StatisticSlot
初始StatisticSlot
如果要设计一个 StatisticSlot,首先需要明确其需要实现的功能,即收集各种指标数据,如请求总数、请求成功数、请求失败数、响应时间等。
目前先把核心结构先列出来, 后续填充其他功能
public class StatisticSlot extends AbstractLinkedProcessorSlot<DefaultNode> {@Overridepublic void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,boolean prioritized, Object... args) throws Throwable {try {// 调用责任链下一个 SlotfireEntry(context, resourceWrapper, node, count, prioritized, args);} catch (Throwable e) {throw e;}}@Overridepublic void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {DefaultNode node = (DefaultNode)context.getCurNode();// 调用责任链下一个 SlotfireExit(context, resourceWrapper, count);}
}
错误信息和异常数统计
fireEntry()调用的是真正验证用于的Slot, 比如FlowSlot, DegradeSlot等, 如果后续验证不通过的话, 那么会抛出BlockException, 那么此时就可以使用try-catch捕获, 捕获后记录异常错误信息以及异常数
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,boolean prioritized, Object... args) throws Throwable {try {// 调用下一个Slot, 如果验证不通过, 那就捕获异常fireEntry(context, resourceWrapper, node, count, prioritized, args);} catch (BlockException e) {// 捕获 BlockExceptionthrow e;} catch (Throwable e) {// .....throw e;}
}
QPS和线程数统计
QPS和线程数的统计应该在什么时候统计?
可以fireEntry()之后进行统计, 调用fireEntry()
- 如果没有报
BlockException, 则表示没有被流控或熔断降级- 将当前资源占用的线程数 + 1以及当前请求QPS + 1
- 如果报了
BlockException, 则表示被拦截了, 即请求失败- 将请求拒绝的QPS + 1
对于总的QPS则可以通过公式计算 总QPS = 成功QPS + 失败QPS
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,boolean prioritized, Object... args) throws Throwable {try {// 规则验证fireEntry(context, resourceWrapper, node, count, prioritized, args);// 如果能走到这里,则将当前资源占用的线程数 + 1 以及当前资源请求成功的 QPS 数 + 1node.increaseThreadNum();node.addPassRequest();} catch (BlockException e) { // 捕获 BlockException// 如果规则验证失败,则将 BlockQps + 1node.increaseBlockQps();throw e;} catch (Throwable e) {// .....throw e;}
}
响应时间统计
entry()是入口方法,相当于 AOP的before() 方法,那我们肯定会对应一个after() 方法,exit()是出口方法, 也就说可以在exit()中记录响应时间
@Override
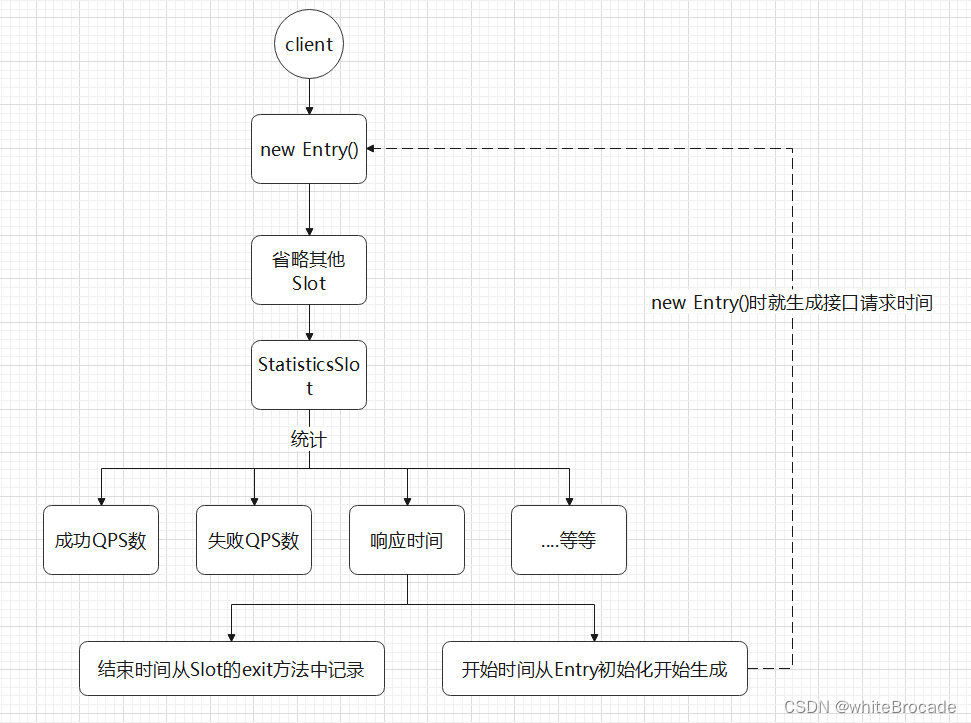
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {Node node = context.getCurNode();if (context.getCurEntry().getBlockError() == null) {// 获取系统当前时间long completeStatTime = TimeUtil.currentTimeMillis();context.getCurEntry().setCompleteTimestamp(completeStatTime);// 得到响应时间,这个时间是哪里来的呢?是我们最初最开始为资源创建Entry对象时记录的。long rt = completeStatTime - context.getCurEntry().getCreateTimestamp();// 记录响应时间等信息recordCompleteFor(node, count, rt, error);}fireExit(context, resourceWrapper, count, args);
}
结束时间是在 StatisticsSlot 里的exit方法记录的,那开始时间是在哪记录的呢?在entry方法里记录可以吗?显然不妥,因为StatisticsSlot不是第一个Slot,不能作为请求的起始时间,起始时间应该放到初始化Entry资源管理对象,也就是只要资源诞生就意味着此次请求开始了,而且我们在设计 Entry 类的时候也将开始时间和结束时间两个字段设计进去了,因此我们开始时间我们可以直接通过 context.getCurEntry().getCreateTimestamp() 获取
流程图如下
DefaltNode, EntranceNode和ClusterNode的指标如何统计
- DefaltNode:用于统计某个 Context 下某个资源的指标信息,维度是 Context + 资源
- EntranceNode:用于统计某个 Context 下全部资源的指标信息,维度是 Context
- ClusterNode:用于统计某个资源在全部 Context 下的指标信息,维度是资源,与 Context 无关
收集指标信息也就是每次请求就记录一下, 问题就是在哪里出发记录的动作?
即下述三个问题
- 如何统计某个资源在某个Context下的指标?
- 如何统计某个Context下所有资源的指标?
- 如何统计某个资源在全部Context中的指标?
如何统计某个资源在某个Context下的指标?
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,boolean prioritized, Object... args) throws Throwable {try {fireEntry(context, resourceWrapper, node, count, prioritized, args);// 数据统计node.increaseThreadNum();node.addPassRequest(count);}
}
可以发现 increaseThreadNum() 和 addPassRequest() 方法都是node调用的,那node是什么呢?
node是DefaultNode类型的方法参数,我们还知道 entry() 方法是通过上一个责任链:ClusterSlot调用的,也就是说node这个参数是前面Slot传过来的,其实,我们回溯回去,会发现这个node就是DefaultNode本身,并不是它的子类EntranceNode。因此,我们得出一个结论:StatisticSlot直接调用DefaultNode里的方法进行指标收集,我们又知道DefaultNode的维度是Context + 资源
public class DefaultNode extends StatisticNode {// 和资源绑定private ResourceWrapper id;private ClusterNode clusterNode;// 增加线程数@Overridepublic void increaseThreadNum() {super.increaseThreadNum();this.clusterNode.increaseThreadNum();}// 增加请求成功数@Overridepublic void addPassRequest(int count) {super.addPassRequest(count);this.clusterNode.addPassRequest(count);}
}
DefaultNode核心源码
public class DefaultNode extends StatisticNode {// 和资源绑定private ResourceWrapper id;private ClusterNode clusterNode;// 增加线程数@Overridepublic void increaseThreadNum() {super.increaseThreadNum();this.clusterNode.increaseThreadNum();}// 增加请求成功数@Overridepublic void addPassRequest(int count) {super.addPassRequest(count);this.clusterNode.addPassRequest(count);}
}
DefaultNode 的维度是 Context + 资源,DefaultNode源码里只看到了资源 ResourceWrapper,没有看到Context呢?在NodeSelectorSlot的entry()方法里我们会初始化DefaultNode 且与Context进行绑定(Key-Value形式),核心代码
public class NodeSelectorSlot extends AbstractLinkedProcessorSlot<Object> {// Context#name与DefaultNode 进行绑定private volatile Map<String, DefaultNode> map = new HashMap<String, DefaultNode>(10);public void entry(...) {DefaultNode node = new DefaultNode(resourceWrapper, null);map.put(context.getName(), node);}
}
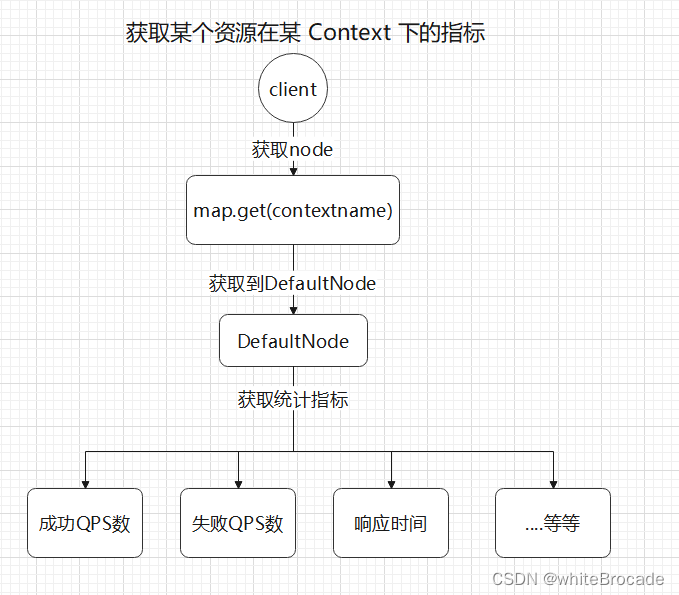
要想获取某个资源在某 Context 下的指标时
- 从map中获取DefaultNode
- 从DefaultNode获取资源Id
流程图如下
如何统计某个Context下所有资源的指标?
也就是不细分资源,直接统计Context
如何找到当前Context下的全部资源呢?
- 一个资源肯定对应一个DefaultNode
- EntranceNode相当于树干,它有很多树枝 DefaultNode 挂到其下面
public class EntranceNode extends DefaultNode {// 树枝private volatile Set<Node> childList = new HashSet<>();
}
有了这个 childList 事情就变得简单了,直接 for 循环遍历即可,获取到的是每个 DefaultNode,然后调用每个 DefaultNode 的统计方法进行求和即可,如下所示:
public class EntranceNode extends DefaultNode {@Overridepublic int curThreadNum() {int r = 0;// 遍历 DefaultNode 子集for (Node node : getChildList()) {// += 操作求和r += node.curThreadNum();}return r;}@Overridepublic double passQps() {double r = 0;for (Node node : getChildList()) {r += node.passQps();}return r;}
}
如何统计某个资源在全部Context中的指标?
我们知道 ClusterNode 是在 DefaultNode 下的,一个资源至少对应一个 DefaultNode 以及会对应唯一一个 ClusterNode (因为 ClusterNode 的维度是资源,所以不管资源在哪几个 Context 下,都只会对应唯一一个 ClusterNode)
上边的DefaultNode 的时候不管是 increaseThreadNum() 还是 addPassRequest() 都会调用一个方法叫:this.clusterNode.increaseXxx(),其实这就是用于统计某个资源在所有 Context 下的指标信息的
public void increaseThreadNum() {super.increaseThreadNum();// clusterNode.xxxthis.clusterNode.increaseThreadNum();
}
public void addPassRequest(int count) {super.addPassRequest(count);// clusterNode.xxxthis.clusterNode.addPassRequest(count);
}
总结
StatisticSlot只负责指标统计, 调用相关的统计方法进行实现, Sentinel底层采用滑动窗口, 令牌桶, 漏桶三个算法
参考资料
通关 Sentinel 流量治理框架 - 编程界的小學生
相关文章:
sentinel的资源数据指标是如何采集
资源数据采集 之前的NodeSelectorSlot和ClusterBuilderSlot已经完成了对资源调用树的构建, 现在则是要对资源进行收集, 核心点就是这些资源数据是如何统计 LogSlot 作用: 记录异常请求日志, 用于故障排查 public class LogSlot extends AbstractLinkedProcessorSlot<Def…...
算法刷题:找到字符串中所有的字母异位词
找到字符串中所有的字母异位词 .题目链接题目详情题目解析算法原理滑动窗口流程图定义指针及变量进窗口判断出窗口更新结果 我的答案 . 题目链接 找到字符串中所有的字母异位词 题目详情 题目解析 所谓的异位词,就是一个单词中的字母,打乱顺序,重新排列得到的单词 如:abc-&g…...
【Java EE初阶十九】网络原理(四)
4. 数据链路层 数据链路层也有很多种协议,其中一个比较常见常用的,就是“以太网协议”(通过网线/光纤, 来通信所使用的协议叫做以太网协议,以太网是横跨数据链路层 物理层); 4.1 以太网数据帧格式 帧头 载荷(IP 数据…...

12.23 校招 实习 内推 面经
绿*泡*泡VX: neituijunsir 交流*裙 ,内推/实习/校招汇总表格 1、社招&校招 | 轻舟智航 社招 & 2024校招 社招&校招 | 轻舟智航 社招 & 2024校招 2、校招 | 成都精灵云科技2024校园招聘补录 校招 | 成都精灵云科技2024校园招聘补录 …...

FPGA转行ISP的探索之一:行业概览
ISP的行业位置 最近看到一个分析,说FPGA的从业者将来转向ISP(Image Signal Process图像信号处理)是个不错的选择,可以适应智能汽车、AI等领域。故而我查了一下ISP,对它大致有个概念。 传统的ISP对应的是相机公司&…...

Linux系统之部署网页小游戏合集网站
Linux系统之部署网页游戏合集网站 一、项目介绍1.1 项目介绍1.2 自定义配置方法二、本次实践介绍2.1 环境规划2.2 本次实践介绍三、检查本地环境3.1 检查操作系统版本3.2 检查当前yum仓库四、安装httpd软件4.1 检查yum仓库4.2 安装httpd软件4.3 启动httpd服务4.4 查看httpd服务…...

【白嫖8k买的机构vip教程】python(2):python_re模块
python之re模块 一、正则表达式 re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用。注意…...
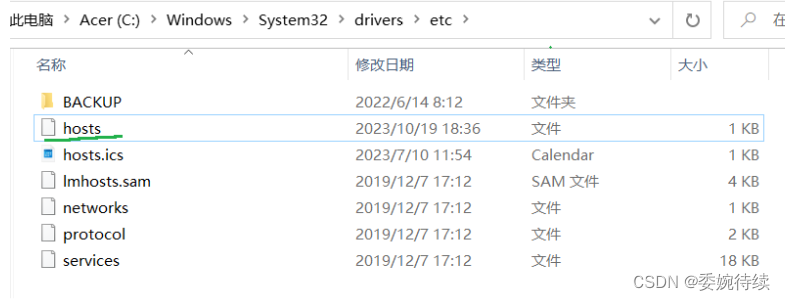
【CSS】display:flex和display: inline-flex区别
flex:将对象作为弹性伸缩盒显示 inline-flex:将对象作为内联块级弹性伸缩盒显示 DOM结构 <div class"main"><div></div><div></div><div></div><div></div></div>flex .main{…...

rpm安装gitlab
1.1 下载gitlab安装包 使用rpm包安装命令安装gitlab的rpm包,下载地址为https://packages.gitlab.com/gitlab/gitlab-ce社区版本; 推荐使用清华大学镜像:https://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el7/gitlab安装包详见࿱…...
图论之dfs与bfs的练习
dfs--深度优选搜索 bfs--广度优先搜索 迷宫问题--dfs 问题: 给定一个n*m的二维迷宫数组其中S是起点,T是终点,*是墙壁(无法通过), .是道路 问从起点S出发沿着上下左右四个方向走,能否走到T点&a…...

Vue练习5:图片的引入
后续会补充 1.require引入 src -> asstes <template><img :src"url"> </template><script> export default {name: App,data(){return{url: require("./assets/logo.png"),}} } </script> 2.import引入 src…...

SpringBoot+Kafka
文章目录 一、依赖二、配置文件三、API1、生产者2、消费者 一、依赖 <!-- spring-kafka(与kafka的版本一致) --> <dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>…...

世界顶级名校计算机专业,都在用哪些书当教材?(文末送书)
目录 01《深入理解计算机系统》02《算法导论》03《计算机程序的构造和解释》04《数据库系统概念》05《计算机组成与设计:硬件/软件接口》06《离散数学及其应用》07《组合数学》08《斯坦福算法博弈论二十讲》参与规则 清华、北大、MIT、CMU、斯坦福的学霸们在新学期里…...
)
蓝桥杯刷题--python-8(2023 填空题)
0幸运数 - 蓝桥云课 (lanqiao.cn) res=0 for i in range (1,100000000):l_n=[]for j in str(i):l_n.append(int(j))if len(l_n) % 2 ==0:cur =len(l_n)>>1if sum(l_n[:cur])==sum(l_n[cur:]):res+=1 print(res) 0有奖问答 - 蓝桥云课 (lanqiao.cn) dfs def bfs(score, q…...

Eclipse - Reset Perspective
Eclipse - Reset Perspective 1. Window -> Perspective -> Reset Perspective2. Reset Perspective -> YesReferences 1. Window -> Perspective -> Reset Perspective 2. Reset Perspective -> Yes References [1] Yongqiang Cheng, https://yo…...

1.5v的电池电压低于多少v等于没电
对于1.5V的电池,电压低于一定值时就不再适合使用了。具体的电压值取决于电池的类型和使用设备的需求。一般来说, 对于接收设备(如收音机、BB机、遥控机等),每节电池电压一般到1.2V以下就认为没电了。有些电动玩具、剃…...
LabVIEW智能监测系统
LabVIEW智能监测系统 设计与实现一个基于LabVIEW的智能监测系统,通过高效的数据采集和处理能力,提高监测精度和响应速度。系统通过集成传感器技术与虚拟仪器软件,实现对环境参数的实时监测与分析,进而优化监控过程,提…...

代码随想录刷题第34天
第一题是柠檬水找零https://leetcode.cn/problems/lemonade-change/,感觉并没有特别靠近贪心算法,可供讨论的情况非常少,5元收下,10元返5元,20元返15元,对各种找零情况讨论一下即可。 class Solution { pu…...

AMD FPGA设计优化宝典笔记(5)低频全局复位与高扇出
亚军老师的这本书《AMD FPGA设计优化宝典》,他主要讲了两个东西: 第一个东西是代码的良好风格; 第二个是设计收敛等的本质。 这个书的结构是一个总论,加上另外的9个优化,包含的有:时钟网络、组合逻辑、触发…...
14. Qt 程序菜单实现,基于QMainWindow
目录 前言: 技能: 内容: 一、ui中直接添加控件实现 二、 完全通过代码实现菜单 参考: 前言: 基于QMainWindow,两种方式实现菜单:通过直接添加ui控件快速添加菜单和完全通过代码实现菜单&a…...

次梯度优化与最优传输:实现公平系统辨识的算法框架
1. 项目概述与核心问题系统辨识,简单来说,就是“教会”计算机理解一个物理或抽象系统的运作规律。比如,我们有一台复杂的工业反应釜,输入是原料的流速和温度,输出是最终产品的浓度。系统辨识的目标,就是通过…...

MAA明日方舟助手:一键解放双手的智能游戏伴侣终极指南
MAA明日方舟助手:一键解放双手的智能游戏伴侣终极指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://git…...

如何彻底解决QQ音乐加密格式的播放限制?
如何彻底解决QQ音乐加密格式的播放限制? 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 还在为下载的QQ音乐文件无法在其他设备上播放而烦恼吗?你是…...

Thorium浏览器:面向企业级部署的技术选型与架构决策指南
Thorium浏览器:面向企业级部署的技术选型与架构决策指南 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards the top of t…...
)
保姆级教程:在CentOS 7/8上从源码编译安装最新版ProxyChains-ng(含systemd服务配置)
CentOS 7/8源码编译ProxyChains-ng全指南:从构建到系统服务集成对于追求极致控制力的技术爱好者来说,预编译软件包就像黑箱操作——你永远不知道里面被加入了什么。本文将带你深入ProxyChains-ng的构建过程,从源码编译到系统服务集成…...

保险精算AutoML实战:超参数优化与集成学习提升模型效率
1. 项目概述:当AutoML遇上保险精算在保险行业干了十几年,我亲眼见证了精算师们从抱着厚重的费率手册和GLM(广义线性模型)公式,到如今开始尝试用Python脚本跑几个机器学习模型。但一个普遍的现象是:很多精算…...

多重样本分割:提升异质性处理效应估计稳定性的关键技术
1. 项目概述:为什么我们需要更稳定的异质性处理效应估计?在政策评估、药物临床试验或者互联网产品的A/B测试中,我们常常想知道一个干预措施(比如一项新政策、一种新药、一个产品功能)对不同人群的效果是否一样。这个“…...

别急着重启!深入理解Ubuntu 22.04的needrestart:守护进程、库文件与系统更新背后的原理
别急着重启!深入理解Ubuntu 22.04的needrestart:守护进程、库文件与系统更新背后的原理在Ubuntu 22.04 LTS的系统维护中,许多管理员都曾遇到过这样的场景:执行apt upgrade后,终端突然弹出"Daemons using outdated…...

RTX51实时系统任务抢占与邮箱机制深度解析
1. RTX51实时系统中的任务抢占与邮箱机制解析在嵌入式实时操作系统领域,任务间通信与优先级调度是核心机制。RTX51作为Keil C51开发环境中的经典实时内核,其抢占行为与邮箱通信的交互方式直接影响系统实时性表现。本文将深入剖析当低优先级任务向高优先级…...
 | 距考试仅剩7天(5月23-26日)**)
软考软件设计师每日备考资料 2026年5月16日(周六) | 距考试仅剩7天(5月23-26日)**
📚 软考软件设计师每日备考资料📅 2026年5月16日(周六) | 距考试仅剩7天(5月23-26日) 🎯 今日主题:考前7天全真模拟卷 答题节奏训练 新考纲AI终极速记 考前一周冲刺计划一、&…...