分库分表面试必背

一,背景
随着互联网的普及,使用人数和场景爆炸式增长,现在随便一个应用系统都可能达到数百万千万甚至更大数量级的数据。大量的数据带来了新的挑战,怎么快速完成增删改查的业务,是应用服务开发者最头痛的问题。面对这个问题,分库分表是一个很好的思路,今天来聊聊分库分表。
二,概念
1,什么是分库分表?
分库分表是一种数据库架构优化技术,本质上就是一种分治思想。通过分库分表将数据分散到多个数据库或表中,来提高系统的性能和稳定性。分库分表可以分为以下几种策略:水平分库、水平分表、垂直分库、垂直分表。
下面以订单数据库db_order和订单表tb_order为例来说明。
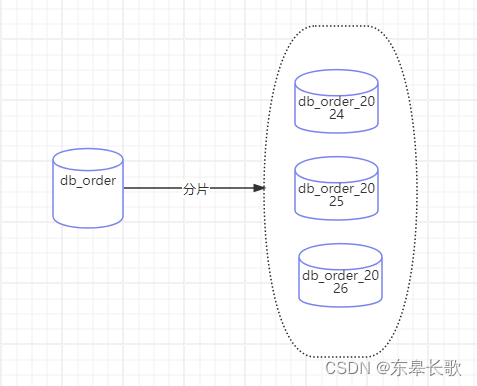
1.1 水平分库
按照某些规则,比如说按照年份,对订单数据库进行划分,一年一个数据库,如db_order_2024,db_order_2025,下面的表和表结构完全一致,但是存储的数据不一样,分别归属于不同年份的订单数据。
1.2 垂直分库
根据业务功能不同将数据分拆到不同的数据库中,比如订单、用户、商品、客户的数据分别存储到订单数据库、用户数据库、商品数据库和客户数据库中。
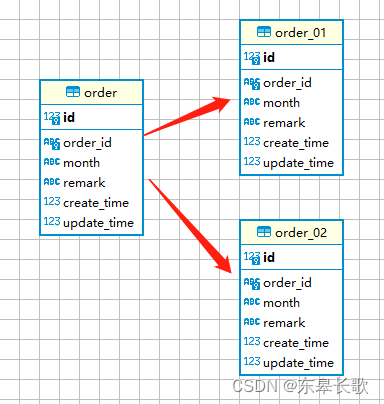
1.3 水平分表
对数据表中数据根据某个字段来做分表,比如根据订单创建月份来分表order_01和order_02, 各个表的结构完全一致,只是存储的数据分属于各个不同的月份。
1.4 垂直分表
按照业务和是否常用或者是否强关联来把宽表拆分,比如订单信息中的商品和下单人等信息可以拆分成子表,通过id来关联。
三,落地
具体可以看:看完这篇,别再说不会Spring 分库分表了_spring data jpa 分库分表-CSDN博客
可用的方案其实很多,比如常见的shardingsphere和mycat
四,问题
1,什么情况下需要分表?
根据阿里的规范,建议如下:

事实上,通常在实战中,一般按经验数据达到千万级,就需要分库分表。原因如下:
我们知道:InnoDB管理磁盘的最小单元:页,页大小16KB.
mysql> show global status like '%Innodb_page_size%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.00 sec)
在日常开发中,对于数据库性能优化,我们首先想到的是索引优化。索引的底层数据结构是B+树。其组织结构如图所示:
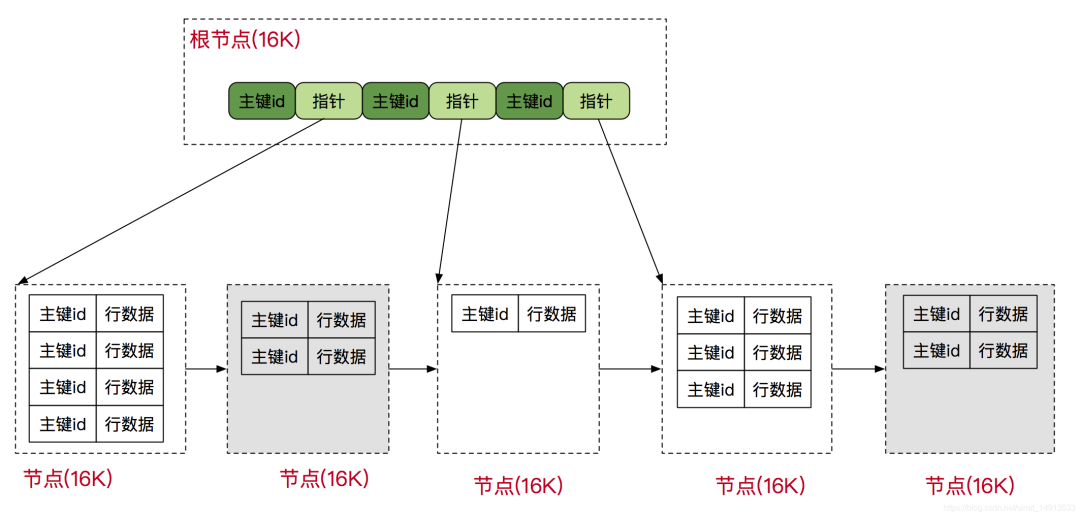
树高为3的B+树数据存储计算规则:
根节点计算:
假设数据类型是bigint,大小为8b。数据本身也需要一小块空间,用来存储下一层索引数据页的地址,大小为6b, 那么根节点是可以存储16*1024/(8+6) = 1170 个数据。
其它层节点计算:
第二层:因为每个节点数据结构和跟节点一样,而且在跟节点每个元素都会延伸出来一个节点,所以第二层的数据量是1170*1170=1368900
第三层:因为innodb的叶子节点,是直接包含整条mysql数据的,假设每条数据以1kb计算,那么第三层每个节点为16kb,那么每个节点是可以放16个数据的,所以最终mysql可以存储的总数据为
1170 * 1170 * 16 = 21902400 (千万级)
其实计算结果与我们平时的工作经验也是相符的,一般mysql一张表的数据超过了千万也是得进行分表操作了。
2,如何选择分片键?
例如,本节我们以订单表的分表为例,一般订单表中含有订单编号:order_id, 用户编号:user_id, 订单创建时间:order_date等。
对于订单表,通常我们可以考虑以下分片键选项:
2.1 订单编号
优点:订单编号通常是唯一的,可以确保每个订单都分散到不同的分片上。这对于保证数据均匀分布和避免热点数据非常有帮助。
2.2 用户编号
优点:用户编号通常也是唯一的,并且如果用户的订单量分布均匀,那么使用用户编号作为分片键可以确保每个用户的订单都在同一个分片上,这对于查询某个用户的所有订单非常高效。
缺点:如果用户的订单量差异很大,那么某些分片可能会存储大量的订单数据,而其他分片可能只有少量的数据。这会导致数据分布不均匀,进而影响查询性能。
2.3 订单创建时间
优点:适用于:按时间范围查询订单的场景。
缺点:可能出现热点数据倾斜问题(即在某个时段产生订单峰值)
3,如何选择数据库主键策略?
在选择主键策略时,需要注意以下几点:
-
唯一性:确保主键在
全局唯一,避免数据冲突。 -
性能:选择适合的主键类型和生成策略,以提高数据插入、查询和索引的性能。
-
扩展性:能够适应数据量和并发量增长。
-
兼容性:选择的主键策略要与使用的数据库兼容。
在 MySQL 中进行分库分表时,自增主键策略确实需要特别处理,因为传统的自增主键策略在分布式环境下会导致主键冲突。每个数据库实例或分片都会从相同的起始点开始自增,这会导致在不同的分片上生成相同的 ID,进而引发数据冲突。
4,几种常见的主键策略
-
UUID:UUID 是一个 128 位的值,具有全局唯一性,可以很好地解决分布式环境下的主键冲突问题。但是,UUID 字符串较长,存储和索引效率较低,而且是无序的,可能会影响查询性能。
-
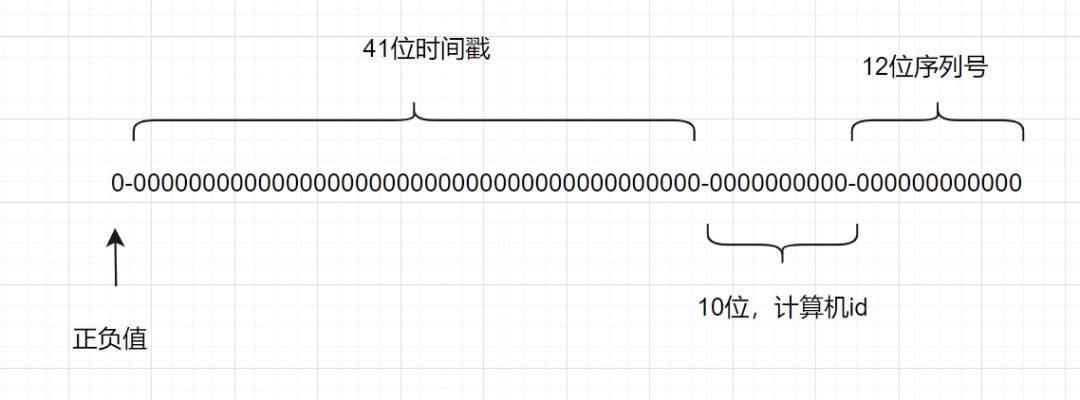
Snowflake 算法:雪花算法(SnowFlake)是一种分布式ID生成算法,由Twitter开源。其核心思想是使用64位long型数字作为全局唯一的ID,通过时间戳、工作机器ID和序列号等部分来确保ID的全局唯一性。
-
结构说明:
-
1位:未使用(因为二进制中最高位是符号位,正数是0,负数是1,一般生成的ID都是正数,所以这一位固定为0)。
-
41位:时间戳(毫秒级),用来记录时间截的差值(当前时间截 - 开始时间截)。
-
10位:工作机器ID,包括5位datacenterId(数据中心ID)和5位workerId(工作机器ID),用来表示工作机器的ID。
-
12位:序列号,用来记录同一毫秒内产生的不同ID,12位可以表示的最大整数为4095,用来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
-
通过这种结构,雪花算法可以保证生成的ID按时间递增,并且整个分布式系统中不会有重复的ID。
-
分布式自增 ID 生成器:使用像 Twitter 的 Snowflake、阿里巴巴的 Druid 等分布式 ID 生成器来生成全局唯一的自增 ID。这些生成器通过特定的算法和机制保证在不同实例间生成的 ID 是全局唯一的。
-
自增主键 + 分片策略:仍然使用自增主键,但是结合分片策略,确保每个分片上的主键值是唯一的。例如,可以预先为每个分片分配一个 ID 范围,确保在这个范围内的 ID 是唯一的。这种方法需要维护分片的 ID 范围,并在必要时进行调整。
-
使用数据库的自增 ID 特性:某些数据库支持在分表时自动处理自增 ID,避免冲突。例如,MySQL 8.0 引入了
AUTO_INCREMENT_INCREMENT和AUTO_INCREMENT_OFFSET这两个系统变量,用于在复制或分片环境中调整自增 ID 的步长和起始值,从而避免冲突。
总之,在分库分表时,自增主键策略需要进行特殊处理,以确保全局唯一性,并根据实际情况选择合适的方案。
5,如何选择分表策略?
选择分库分表的策略时,确实需要根据具体的业务场景和数据特性来决定。例如订单表,以订单ID (order_id) 作为分表键。
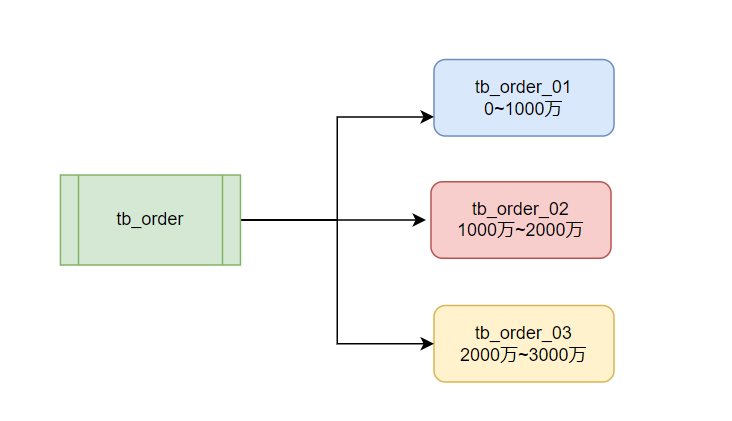
5.1 基于范围的策略
适用场景:当订单ID有明确的增长趋势,例如连续的自增ID,并且你知道未来可能的订单数量时,范围分表是一个好选择。
策略实现:可以将订单ID按照范围划分到不同的表中。例如,订单ID【1-1000万】 在表tb_order_01,【1000万-2000万】在表tb_order_02,以此类推。
优点:
查询效率较高,尤其是范围查询。数据迁移和维护相对简单。
缺点:
订单ID的分布必须均匀. 如果订单ID不是连续或可预测的,这种策略可能不适用。
5.2 基于哈希的策略
适用场景:当订单ID没有明确的增长趋势,哈希分表是一个好选择。
策略实现:使用哈希函数对订单ID进行哈希运算,然后根据哈希值的结果决定存储在哪个表中。
table_index = hash(order_id) % tables_num
优点:
负载均衡,每个表的数据分布相对均匀。
缺点:
不利于二次扩容。
5.3 映射表策略
适用场景:当订单ID的分布不均,或者需要灵活控制数据分布时,映射表分表可能是一个好选择。
策略实现:使用一个映射表来记录每个订单ID应该存储在哪个表中。这个映射表可以是内存中的数据结构,也可以是数据库中的一个表。
优点:
灵活,可以根据需要调整数据分布。
缺点:
查询时需要先查询映射表,可能影响性能。
5.4 一致性哈希策略
适用场景:当系统需要高可用性,并且希望在添加或删除节点时尽量减少数据迁移时,一致性哈希可能是一个好选择。
策略实现:使用一致性哈希算法将订单ID映射到哈希环上,然后根据哈希环上的节点(或表)来存储数据。
一致性哈希算法的核心思想是将哈希值空间表示为一个闭合的圆环(哈希环),每个节点负责维护圆环上一段连续的哈希值范围。
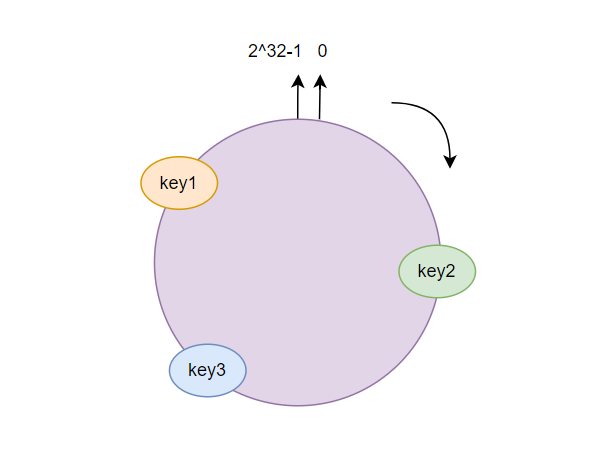
在分库分表的场景中,可以将每个数据库或表看作是一个节点,将这些节点均匀地分布在哈希环上。当插入或查询数据时,根据数据的哈希值将其映射到哈希环上,然后顺时针查找最近的节点(即负责该哈希值范围的数据库或表),将数据插入或查询该节点。
优点:
支持节点的动态扩容。
缺点:
当节点数量变化较大时,可能需要重新计算所有数据的哈希值并进行迁移,增加系统的开销,范围查询和顺序查询可能不如范围分表和哈希分表高效。
6,非分片键字段如何查询?
曾几何时,面试过程中遇到过这样一个问题:假设有一个用户表,你用ID做的分片键,那么有一个类似于name这样的字段如何查询?
这里提供几种常见的思路:
6.1.全局索引
全局索引是一个跨所有分片的索引,它包含了非分片键字段和对应的分片键信息。查询时,先通过全局索引找到相关的分片键,然后在相应的分片中查询详细数据。
适用场景:适用于查询频率高、数据量大的非分片键字段。
优点:查询效率高,可以快速定位到数据所在的分片。
缺点:全局索引维护成本较高,需要定期更新以保持与分片数据的一致性。
6.2. 数据冗余
在每个分片中存储部分非分片键字段的数据。这样,即使不直接查询分片键,也可以在分片内快速找到相关数据。
适用场景:适用于查询性能要求极高,且可以接受一定数据冗余的场景。
优点:查询性能高,无需跨分片查询。
缺点:数据冗余增加了存储成本和维护复杂性。
6.3. 应用层处理
在应用层实现复杂的查询逻辑,将多个分片中的查询结果汇总后进行处理。
适用场景:适用于查询频率不高,或者可以接受一定延迟的场景。
优点:灵活性高,可以根据业务需求定制查询逻辑。
缺点:查询性能可能受到网络延迟和分片数量的影响。
6.4. 使用Elasticsearch
将非分片键字段的数据同步到Elasticsearch中,利用Elasticsearch强大的搜索和查询能力进行查询。
适用场景:适用于非结构化数据、全文搜索、复杂查询等场景。
优点:支持复杂的查询操作,如全文搜索、模糊匹配等;查询性能高,支持分布式部署。
缺点:需要维护Elasticsearch集群,增加了系统的复杂性;数据同步可能引入一定的延迟。
6.5. 数据库中间件
使用数据库中间件(如ShardingSphere、MyCAT等)来管理分库分表,中间件可以自动处理非分片键字段的查询,将请求路由到正确的分片。
适用场景:适用于希望减少应用层复杂性的场景。
优点:简化了应用层的查询逻辑,减少了开发和维护的工作量。
缺点:需要配置和维护数据库中间件。
7,如何解决热点数据倾斜问题?
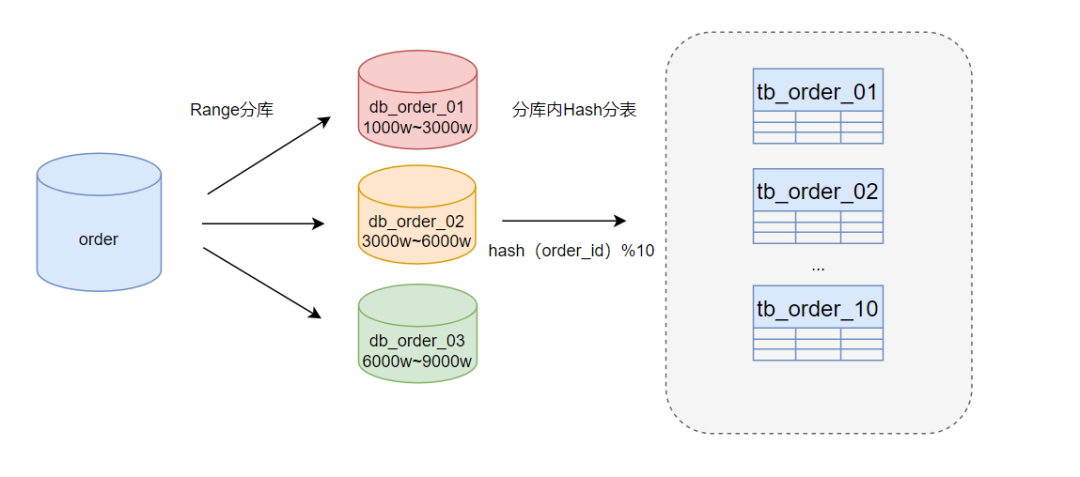
热点数据倾斜通常发生在某些特定的数据项(例如,用户激增、促销订单峰值等)等,导致这些数据的查询和更新操作集中在些某特定的数据库或表上,从而造成性能瓶颈。
解决方案:采用Range分库+Hash分表
8,如何解决跨库关联查询?
分库分表后,数据被分散到了不同的数据库或表中。跨库关联查询成为新的问题。为了解决这个问题,可以采取以下几种策略:
-
字段冗余:对于经常需要进行关联查询的字段,可以考虑将这些字段冗余到每个相关的表中。这样,在进行查询时就不需要跨库关联,可以直接在单个表内完成查询。例如,如果经常需要查询合同和客户的关联信息,可以在合同表中冗余一些客户的基础字段,这样查询时就不需要跨库关联客户表。
-
数据同步:如果某个系统经常需要查询另一个系统的数据,可以在当前系统中创建一张对应的表,并通过ETL或其他数据同步工具定时同步所需的数据。这样,查询时就可以直接在本地表中完成,避免了跨库关联查询。
-
全局表(广播表):对于某些基础数据,如行名行号信息等,如果它们被多个业务系统频繁使用,可以考虑在所有的数据库中都存储这些基础数据。这样,无论哪个系统需要这些数据,都不需要进行跨库关联查询。
-
ER表(绑定表):对于存在逻辑主外键关系的表,如订单表和订单明细表,可以考虑将它们的数据物理上存储在一起,形成一个绑定表。这样,查询时就可以在一个表中完成主表和明细表的关联查询,避免了跨库关联。
-
使用分布式中间件:分布式中间件如Sharding-JDBC、MyCAT等,可以将多个物理数据库视为一个逻辑数据库。这些中间件能够处理复杂的联合查询、排序、聚合等SQL操作,并根据分片规则指导SQL语句的执行。它们能够解决分库分表后的通过程序聚合汇总结果,解决跨库关联查询问题。
-
应用层数据聚合:在应用层,可以编写逻辑来聚合来自不同数据库或表的数据。这通常涉及发起多个数据库查询,然后在应用层将结果集合并成所需的结构。
需要注意的是,虽然上述方法可以解决跨库关联查询的问题,但它们也会带来一些额外的复杂性。在设计分库分表方案时,需要综合考虑业务需求、数据量、查询频率等因素,选择合适的策略来平衡性能和可维护性。同时,随着业务的发展和数据量的增长,可能需要对分库分表方案进行调整和优化。
9,如何解决分库分表后排序问题?
分库分表后,排序和分页问题变得相对复杂,因为数据不再集中在一个单一的数据库或表中。解决这些问题需要综合考虑多种因素,包括数据量、查询频率、业务需求等。以下是一些解决分库分表后排序和分页问题的策略:
-
全局排序字段:在分库分表时,可以引入一个全局排序字段,所有分片都基于这个字段进行排序。这样,即使数据分布在不同的分片中,也可以保证整体排序的一致性。
-
数据同步与合并:在查询时,从各个分片中分别获取数据,然后在应用层将这些数据按照排序规则进行合并。这种方式需要处理大量的数据传输和合并逻辑,可能对性能有一定影响。
-
中间件支持:使用支持分库分表的中间件,如ShardingSphere、MyCAT等。这些中间件通常提供了强大的排序功能,能够处理分库分表后的排序问题。
-
预算与缓存:对于某些固定的排序需求,可以预先计算排序结果并缓存起来,减少实时计算的压力。
10,如何解决分库分表后分页问题?
10.1 分页参数调整: 在分库分表的情况下,传统的LIMIT OFFSET分页方式可能不再适用。可以考虑调整分页参数,比如使用基于游标(cursor)的分页方式,或者基于时间戳、ID等排序字段的范围查询来实现分页。
10.2 数据聚合: 类似于排序问题的解决方式,从各个分片中分别获取数据,然后在应用层进行数据聚合,实现分页功能。
10.3 中间件支持:使用支持分库分表的中间件,这些中间件通常也提供了分页功能的支持,能够简化分页查询的处理。
10.4 限制分页:对于深度分页的需求,可以考虑限制分页的深度,避免查询大量的数据。例如,只支持查询前100页的数据。
10.5 预加载与缓存:对于经常访问的分页数据,可以考虑预加载并缓存起来,减少实时查询的开销。
11,分库分表如何扩容?
当数据量逐渐增加,需要进行分库分表的扩容时,可以从以下几个方面来考虑和制定策略:
11.1. 数据增长评估: 要对数据的增长趋势进行准确的评估,通过分析历史数据、业务发展趋势以及用户增长情况,可以预测未来的数据量增长情况。一般预估未来3~5年的数据增长。
11.2. 选择合适的分片键: 选择一个合适的分片键是分库分表的关键。分片键应该能够均匀分布数据,避免某些数据库或表过载。同时,分片键的选择也要考虑到查询性能和数据一致性等因素。
11.3. 实施扩容: 基于数据增长趋势和分片键的选择,制定详细的扩容计划。这包括确定扩容的时间点、扩容的目标规模、数据迁移和重新分配的策略等。确保扩容过程能够顺利进行,尽可能减少对业务的影响。
11.4. 数据迁移与重新分配: 在扩容过程中,需要进行数据迁移和重新分配。这通常涉及到将现有数据从旧的数据库或表迁移到新的数据库或表中。可以使用数据迁移工具或自动化脚本来完成这个过程,确保数据的完整性和一致性。
11.5. 负载均衡: 在扩容后,需要确保数据在新旧数据库或表之间均匀分布,以实现负载均衡。可以使用负载均衡器或支持分库分表的中间件来动态分配请求,确保系统的性能和稳定性。
11.6. 监控与调优: 在扩容过程中和扩容后,需要对系统进行持续的监控和调优。通过监控数据库或表的负载情况、查询性能等指标,及时发现并解决性能瓶颈和故障。同时,根据实际需求进行调优,如调整索引、优化查询语句等,以提升系统的整体性能。
相关文章:
分库分表面试必背
一,背景 随着互联网的普及,使用人数和场景爆炸式增长,现在随便一个应用系统都可能达到数百万千万甚至更大数量级的数据。大量的数据带来了新的挑战,怎么快速完成增删改查的业务,是应用服务开发者最头痛的问题。面对这个…...
)
14个常见的Java课程设计/毕业设计合集(源码+文档)
从网上整理收集了14个常见的java系统设计源码,可以用于课程作业或者毕业设计。 1.基于java的家政预约网站系统 平台采用B/S结构,后端采用主流的Springboot框架进行开发,前端采用主流的Vue.js进行开发。 整个平台包括前台和后台两个部分。 …...

如何用 docker 部署程序?
如何用 docker 部署程序?这个问题有点笼统。 如果是MySQL、Redis这些,只需要拉取镜像,然后设置必要的配置,最终创建并运行实例即可。 如果你的应用是一个Java应用程序,使用Docker来部署它会涉及到Java特有的一些考虑…...
)
5G固定无线接入(FWA)
固定无线接入(FWA) 固定无线接入(Fixed Wireless Access)是使用两个固定点之间的无线电链路提供无线宽带的过程。换句话说,固定无线是一种为家庭或企业提供无线互联网接入的方式,无需铺设光纤和电缆来提供最…...
Unity ScreenPointToRay 获取到的坐标不准确
👾奇奇怪怪的 🥙问题描述🥪解决方案🍿验证代码 🥙问题描述 使用:Camera.main.ScreenPointToRay 将鼠标坐标转换成射线,然后通过:Physics.Raycast 获取到射线碰撞到的坐标࿰…...
AJAXJSON入门篇
AJAX&JSON 概念:AJAX(Asynchronous JavaScript And XML):异步的JavaScript和XML AJAX作用: 与服务器进行数据交换:通过AJAX可以给服务器发送请求,并获取服务器响应的数据 使用了AJAX和服务器进行通信,就可以使用H…...

代码随想录算法训练营29期|day54 任务以及具体安排
第九章 动态规划part11 123.买卖股票的最佳时机III // 版本一 class Solution {public int maxProfit(int[] prices) {int len prices.length;// 边界判断, 题目中 length > 1, 所以可省去if (prices.length 0) return 0;/** 定义 5 种状态:* 0: 没有操作, 1: 第一次买入…...

文件操作相关工具类
目录 1. 文件上传工具类 -- FileUploadUtils 2. 文件处理工具类 -- FileUtils 3. 媒体类型工具类 -- MimeTypeUtils 1. 文件上传工具类 -- FileUploadUtils /*** 文件上传工具类**/ public class FileUploadUtils {private static final Logger log LoggerFactory.ge…...
Spring源码:手写SpringIOC
文章目录 一、分析二、实现1、版本1:实现Bean注入IOC容器,并从容器中获取1)定义BeanDefinition2)定义BeanDefinition实现类3)定义BeanDefinitionRegistry4)定义Beanfactory5)定义默认Beanfactor…...
【软件设计师】程序猿需掌握的技能——数据流图
作为一个程序员,不仅要具备高水平的程序编码能力,还要是熟练掌握软件设计的方法和技术,具有一定的软件设计能力,一般包括软件分析设计图(常见的有数据流图,程序流程图,系统流程图,E-…...

17.3.1 像素处理
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 17.3.1 像素处理 C#处理图像,主要使用到Bitmap 类的 GetPixel方法和SetPixel方法。 Bitmap.GetPixel 方法:…...

白话微机:8.解释FPGA以及一些考研面试问题
一. 前言(更新世界观) 在“微机世界”,普通的城市(单片机)里,人又有一个别的名字叫做“数据”,人有0有1;人们也有住房,这些住房在这个世界叫做“存储器”;地上有路,这些路…...
-k8s存储对象Persistent Volume)
Kubernetes基础(十八)-k8s存储对象Persistent Volume
1 什么是Persistent Volume? 在容器化应用中,Pod的生命周期是短暂的,当Pod终止时,其中的数据通常也会被销毁。为了解决这个问题,Kubernetes引入了Persistent Volume(PV)的概念。PV是集群中的一…...

用linux命令将文本格式文件转换为csv文件
文章目录 前言例: 总结 前言 用到linux命令awk 使用 awk 命令来将文本文件转换为 CSV 格式。假设你有一个以空格或制表符分隔的文本文件,以下是将其转换为 CSV 格式的命令: awk BEGIN { OFS"," } { print $1, $2, $3 } input.txt > outpu…...

C++中的binary_search函数详解
C中的std::binary_search函数详解 在C标准模板库(STL)中,std::binary_search是一个非常有用的函数,它可以在一个已排序的序列中查找一个特定的元素。这个函数的使用非常直观,但是了解其工作原理和一些注意事项可以帮助…...

程序员为什么不喜欢关电脑?我来回答
程序员为什么不喜欢关电脑? 主题: 你是否注意到,程序员们似乎从不关电脑?别以为他们是电脑上瘾,实则是有他们自己的原因!让我们一起揭秘背后的原因,看看程序员们真正的“英雄”本色!…...
波奇学Linux:动静态库
创建静态库 Makefile文件 mymath.c文件 mymath.h文件 编译main.c文件 gcc 编译时会把在系统目录中寻找头文件和库文件,文件不在系统目录中用参数 -I 头文件所在文件夹/ -L 库的地址文件夹 -l除去lib和后缀。 拷贝文件到系统目录即可不用参数 库的安装类似于把头文件…...

1723. 完成所有工作的最短时间
文章目录 题意思路代码 题意 题目链接 K个工人,一共jobs个任务,问怎样分配任务,最短的最长工人完成任务完成时间。 思路 DFS剪枝(最大单个工人jobs时间超过ans时间;有限空闲工人拿任务)模拟退火dp 代码…...
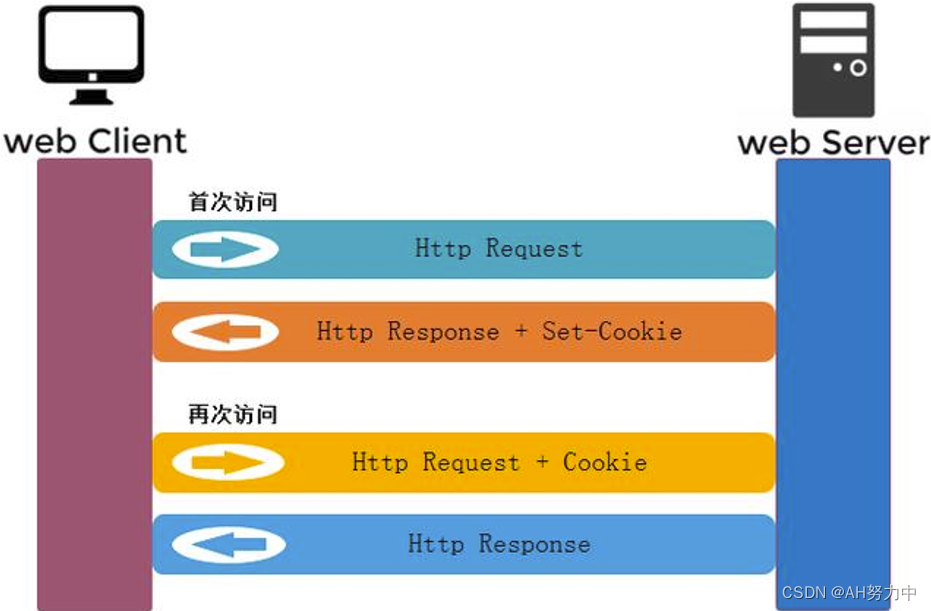
初始HTTP协议
一、http协议 1、http相关概念 互联网:是网络的网络,是所有类型网络的母集因特网:世界上最大的互联网网络。即因特网概念从属于互联网概念。习惯上,大家把连接在因特网上的计算机都成为主机。万维网:WWW(…...
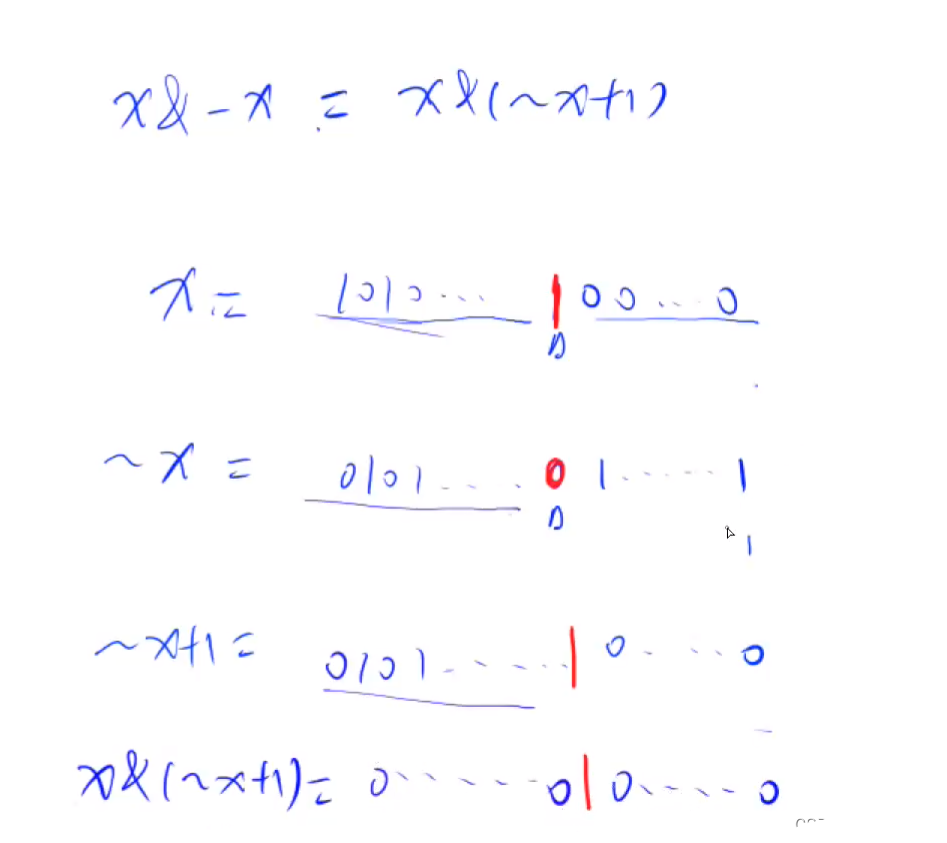
C++ 位运算常用操作 二进制中1的个数
给定一个长度为 n 的数列,请你求出数列中每个数的二进制表示中 1 的个数。 输入格式 第一行包含整数 n 。 第二行包含 n 个整数,表示整个数列。 输出格式 共一行,包含 n 个整数,其中的第 i 个数表示数列中的第 i 个数的二进制表…...

知识图谱与语义网技术栈:从RDF/SPARQL到图神经网络与LLM融合实战
1. 项目概述:从数据孤岛到智能互联的桥梁在数据爆炸的时代,我们每天都被海量的信息包围。然而,这些信息往往像一座座孤岛,彼此隔绝,难以形成有效的知识网络。你是否曾想过,如果能让机器像人一样,…...
)
不只是安装:用Carla+Win11快速搭建你的第一个自动驾驶测试场景(手把手教程)
从零到一:用Carla在Win11上构建自动驾驶测试场景的实战指南当你第一次启动Carla仿真环境,看到那个空荡荡的数字化城市时,是否感到既兴奋又迷茫?作为一款开源的自动驾驶仿真平台,Carla的真正价值不在于安装过程…...
)
Windows11下Detectron2安装避坑指南:从CUDA版本匹配到源码修改(附常见错误解决方案)
Windows 11下Detectron2深度安装指南:从环境配置到源码级问题解决 在计算机视觉领域,Detectron2作为Facebook Research推出的开源框架,凭借其模块化设计和出色的性能表现,已成为目标检测、实例分割等任务的首选工具之一。然而&…...

CoQMoE:面向FPGA的MoE-ViT量化与硬件协同设计实践
1. 项目概述:当视觉Transformer遇上FPGA,为何需要“协同设计”?最近几年,视觉Transformer(ViT)在图像识别、目标检测等任务上展现出了不输甚至超越传统卷积神经网络(CNN)的性能。但随…...

使用C#代码重新排列PDF页面的操作代码
引言对于页面顺序混乱的 PDF 文档,重新排列页面可以避免读者产生困惑,同时也能让文档结构更加清晰有序。本文将演示如何使用 Spire.PDF for .NET 以编程方式重新排列现有 PDF 文档中的页面。安装 Spire.PDF for .NET首先,需要将 Spire.PDF fo…...

AI企业参与国防采购的挑战、机遇与实操路线图
1. 项目概述:当AI遇见国防采购,一场静默的“双向奔赴”在硅谷的咖啡厅和五角大楼的简报室之间,正上演着一场深刻而复杂的对话。话题的核心,是人工智能这项被誉为“新时代电力”的技术,如何融入世界上最庞大、最严谨的采…...

Agent 的知识更新:如何避免过期信息导致决策错误
《Agent 知识更新全指南:从根上解决过期信息导致的决策灾难》 关键词 智能Agent、知识更新、时效性推理、决策可靠性、时间感知RAG、过期信息检测、知识生命周期管理 摘要 你有没有遇到过这种情况:问2024年巴黎奥运会的举办时间,GPT4还一本正经告诉你「2020年东京奥运会…...

为什么92%的Lindy自动化项目在第90天遭遇断崖式停滞?资深架构师紧急披露3个临界预警信号
更多请点击: https://intelliparadigm.com 第一章:为什么92%的Lindy自动化项目在第90天遭遇断崖式停滞?资深架构师紧急披露3个临界预警信号 当Lindy自动化项目运行至第90天左右,系统吞吐量骤降40%、任务积压率突破68%、人工干预频…...

Unity XLua调试Could not load source问题根因与四层排查法
1. 为什么UnityXLua调试总在“Could not load source”上卡死三年?做Unity热更的开发者,大概率都见过这个红色报错:Could not load source xxx.lua。它不崩溃、不闪退,但断点永远进不去,Lua调用栈里全是问号࿰…...

痛苦本身没有价值,从痛苦中提炼出的原则才有价值
如何打破"好了伤疤忘了疼"的人性循环 目录 如何打破"好了伤疤忘了疼"的人性循环 为什么我们天生就"好了伤疤忘了疼" 真正有效的解决方法:把"感性记忆"转化为"理性制度" 第一级:痛苦发生时——立刻"固化"教训,…...