ClickHouse--04--数据库引擎、Log 系列表引擎、 Special 系列表引擎
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 1.数据库引擎
- 1.1 Ordinary 默认数据库引擎
- 1.2 MySQL 数据库引擎
- MySQL 引擎语法
- 字段类型的映射
- 2.ClickHouse 表引擎
- 3.Log 系列表引擎
- 几种 Log 表引擎的共性是:
- 它们彼此之间的区别是:
- 3.1 TinyLog
- 3.2 StripeLog
- 3.3 Log
- 4.Special 系列表引擎
- 4.1 Memory
- 4.2 Merge
- 4.3 Distributed
1.数据库引擎

- ClickHouse 中支持在创建数据库时指定引擎,目前比较常用的两种引擎为默认引擎
和 MySQL 数据库引擎。
1.1 Ordinary 默认数据库引擎
Ordinary 就是 ClickHouse 中默认引擎,如果不指定数据库引擎创建的就是Ordinary 数据库引擎,在这种数据库下面可以使用任意表引擎。创建时需要注意,Ordinary 首字母需要大写,不然会抛出异常。

1.2 MySQL 数据库引擎
MySQL 引擎用于将远程的 MySQL 服务器中的表映射到 ClickHouse 中,并允许对表进行INSERT 插入和 SELECT 查询,方便在 ClickHouse 与 MySQL 之间进行数据交换。
- 这里不会将 MySQL 的数据同步到 ClickHouse 中,ClickHouse 就像一个壳子,可以将 MySQL 的表映射成ClickHouse 表,使用 ClickHouse 查询 MySQL 中的数据,在 MySQL 中进行的 CRUD 操作,可以同时映射到 ClickHouse 中。
- MySQL 数据库引擎会将对其的查询转换为 MySQL 语法并发送到 MySQL 服务器中,因此可以执行诸如 SHOW TABLES 或 SHOW CREATE TABLE 之类的操作,但是不允许创建表、修改表、删除数据、重命名操作
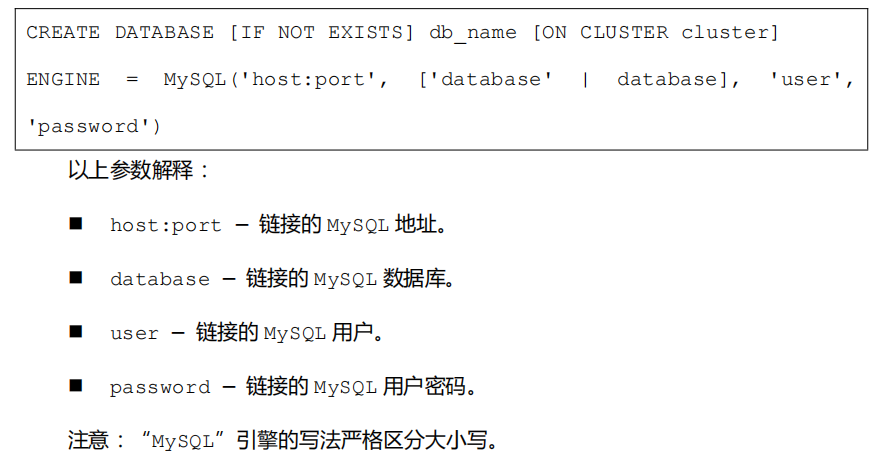
MySQL 引擎语法
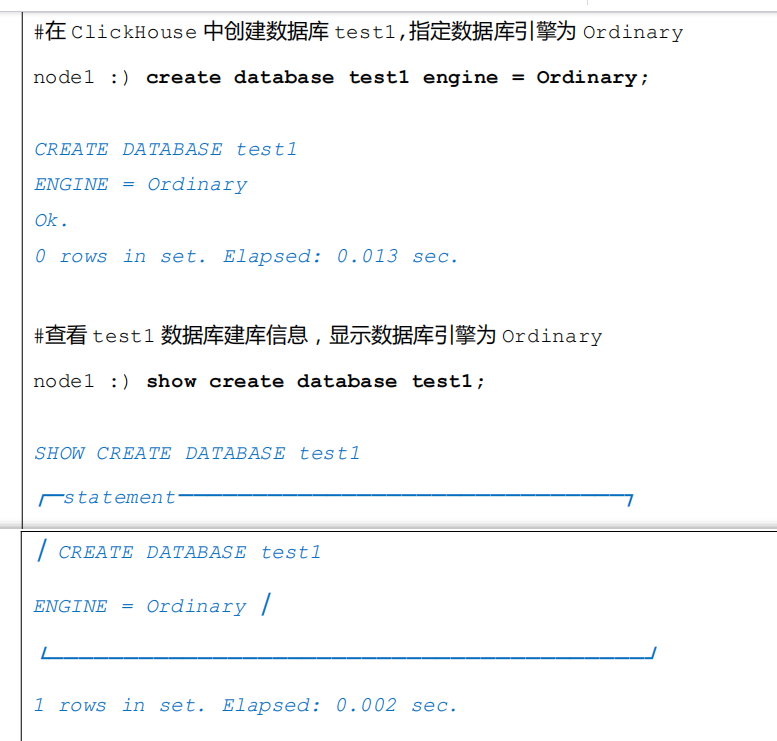
ClickHouse 中创建库使用 MySQL 引擎语法如下:

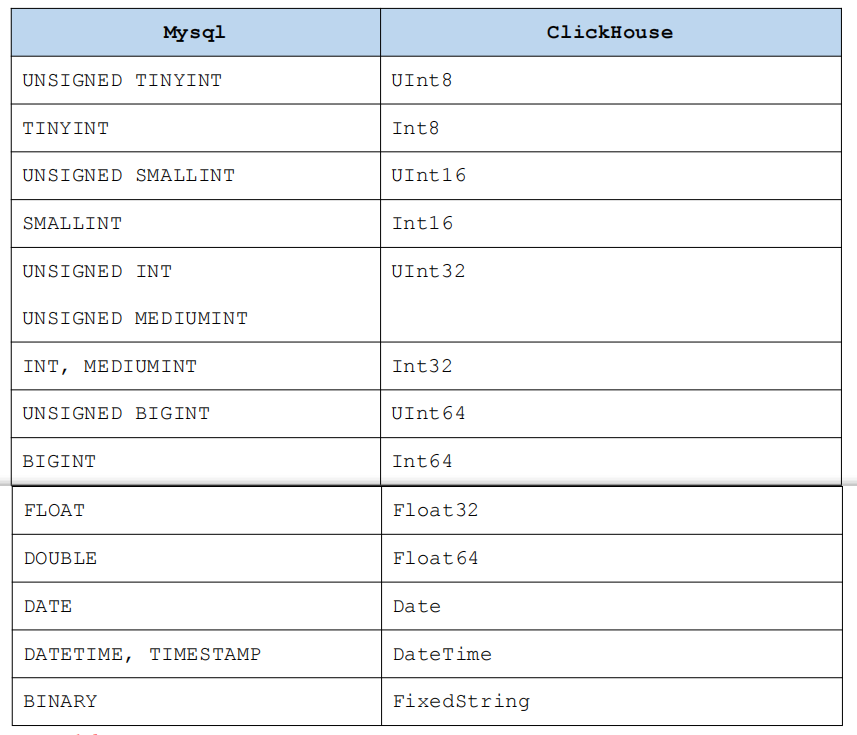
字段类型的映射
- 在 ClickHouse 中使用 MySQL 引擎建库,将 MySQL 库中数据映射到 ClickHouse中,mysql 库中表字段类型与 ClickHouse 表字段类型的映射如下,这里每种类型在ClickHouse 中都支持 Nullable,即可空。

2.ClickHouse 表引擎
MySQL 的数据表有 InnoDB 和 MyISAM 存储引擎,不同的存储引擎提供不同的存储机制、索引方式等功能,也可以称之为表类型。在 ClickHouse 中也有表引擎。
表引擎在 ClickHouse 中的作用十分关键,直接决定了
- 数据如何存储和读取
- 是否支持并发读写
- 是否支持 index 索引
- 支持的 query 种类
- 是否支持主备复制
ClickHouse 提供了大约 28 种表引擎,各有各的用途 纷繁复杂。ClickHouse 表引擎一共分为四个系列,分别是 Log 系列、MergeTree 系列、Integration 系列、Special 系列。其中包含了两种特殊的表引擎 Replicated、Distributed,功能上与其他表引擎正交,根据场景组合使用
- Log 系列用来做小表数据分析
- MergeTree 系列用来做大数据量分析
- Integration 系列则多用于外表数据集成。
- 再考虑复制表 Replicated 系列
- 分布式表 Distributed 等,
3.Log 系列表引擎
Log 系列表引擎功能相对简单,主要用于快速写入小表(1 百万行左右的表),然后全部读出的场景,即一次写入,多次查询。
Log 系列表引擎包含:
- TinyLog、
- StripeLog、
- Log
几种 Log 表引擎的共性是:
-
数据被顺序 append 写到本地磁盘上。
-
不支持 delete、update 修改数据。
-
不支持 index(索引)。
-
不支持原子性写。如果某些操作(异常的服务器关闭)中断了写操作,则可能会获
得带有损坏数据的表。 -
insert 会阻塞 select 操作。当向表中写入数据时,针对这张表的查询会被阻塞,
直至写入动作结束。
它们彼此之间的区别是:
- TinyLog:不支持并发读取数据文件,查询性能较差;格式简单,适合用来暂存
中间数据。 - StripLog:支持并发读取数据文件,查询性能比 TinyLog 好;将所有列存储在
同一个大文件中,减少了文件个数。 - Log:支持并发读取数据文件,查询性能比 TinyLog 好;每个列会单独存储在一
个独立文件中。

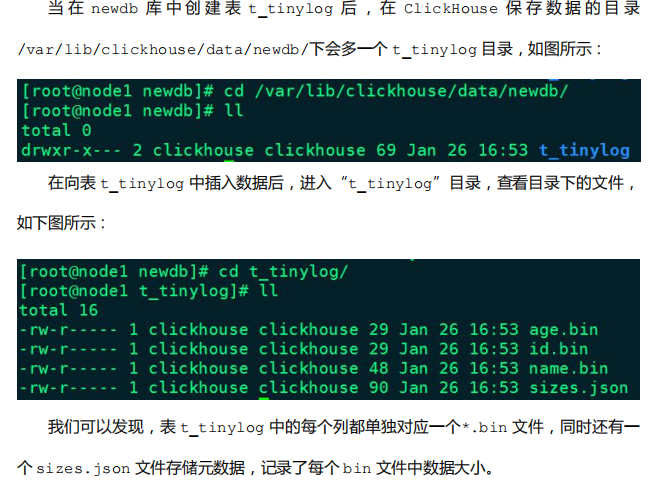
3.1 TinyLog
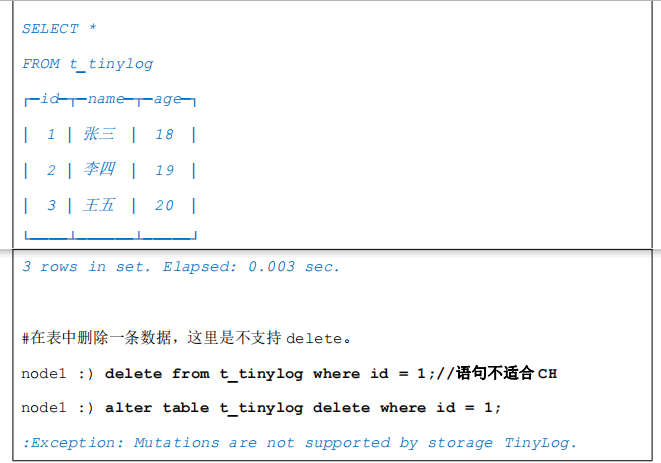
TinyLog 是 Log 系列引擎中功能简单、性能较低的引擎。
- 它的存储结构由数据文件和元数据两部分组成。其中,数据文件是按列独立存储的,也就是说每一个列字段都对应一个文件。
- 由于 TinyLog 数据存储不分块,所以不支持并发数据读取,该引擎适合一次写入,多次读取的场景,对于处理小批量中间表的数据可以使用该引擎,这种引擎会有大量小文件,性能会低。
示例:

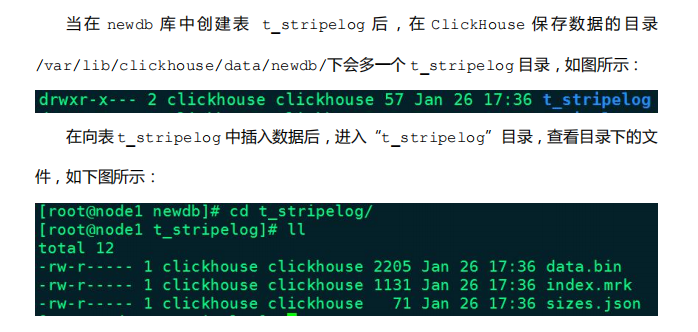
3.2 StripeLog
相比 TinyLog 而言,StripeLog 数据存储会划分块,每次插入对应一个数据块,拥有更高的查询性能(拥有.mrk 标记文件,支持并行查询)
- StripeLog 引擎将所有列存储在一个文件中,使用了更少的文件描述符。对每一次 Insert 请求,ClickHouse 将
数据块追加在表文件的末尾,逐列写入。 - StripeLog 引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作。
示例:


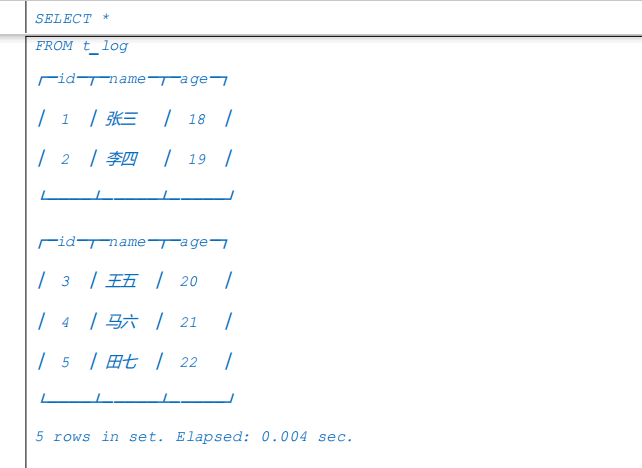
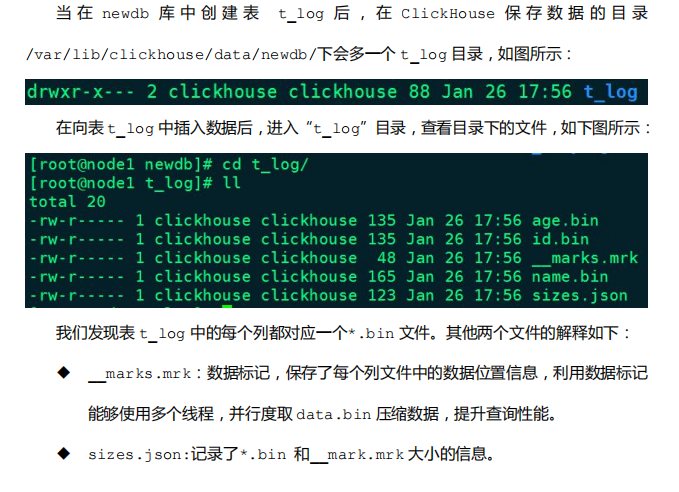
3.3 Log
Log 引擎表适用于临时数据,一次性写入、测试场景。Log 引擎结合了 TinyLog 表引擎和 StripeLog 表引擎的长处,是 Log 系列引擎中性能最高的表引擎。
- Log 表引擎会将每一列都存在一个文件中,对于每一次的 INSERT 操作,会生成数据块
- 经测试,数据块个数与当前节点的 core 数一致。
示例:

4.Special 系列表引擎

4.1 Memory
Memory 表引擎直接将数据保存在内存中,ClickHouse 中的 Memory 表引擎具有以下特点:
- Memory 引擎以未压缩的形式将数据存储在 RAM 中,数据完全以读取时获得的形式存储。
- 并发数据访问是同步的,锁范围小,读写操作不会相互阻塞。
- 不支持索引。
- 查询是并行化的,在简单查询上达到最大速率(超过 10 GB /秒),在相对较少的行(最多约 100,000,000)上有高性能的查询。
- 没有磁盘读取,不需要解压缩或反序列化数据,速度更快(在许多情况下,与MergeTree 引擎的性能几乎一样高)。
- 重新启动服务器时,表存在,但是表中数据全部清空。
- Memory 引擎多用于测试。
示例:


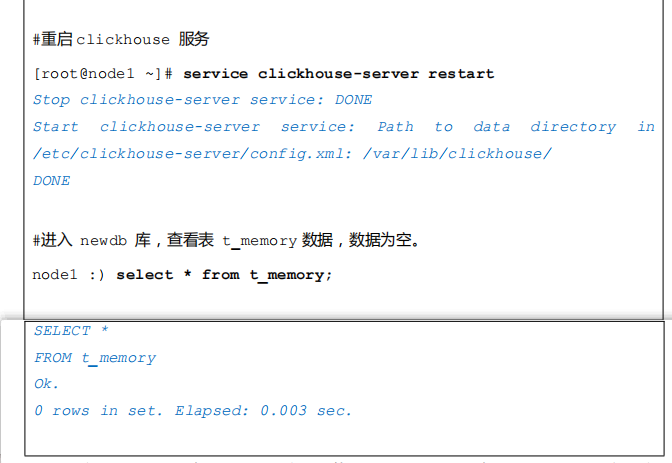
注意:”Memory”表引擎写法固定,不能小写。同时创建好表 t_memory 后,在对应的磁盘目录/var/lib/clickhouse/data/newdb 下没有“t_memory”目录,基于内存存储,当重启 ClickHouse 服务后,表 t_memory 存在,但是表中数据全部清空。
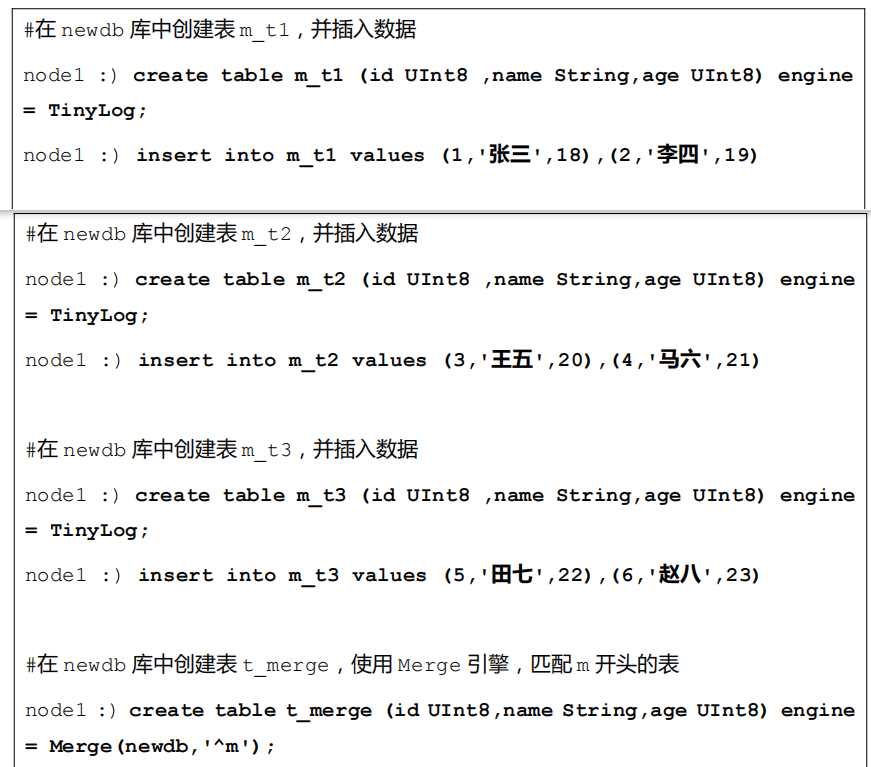
4.2 Merge
Merge 引擎 (不要跟 MergeTree 引擎混淆) 本身不存储数据,但可用于同时从任意多个其他的表中读取数据,这里需要多个表的结构相同,并且创建的 Merge 引擎表的结构也需要和这些表结构相同才能读取。
- 读是自动并行的,不支持写入
- 读取时,那些被真正读取到数据的表如果设置了索引,索引也会被使用。

示例:

4.3 Distributed
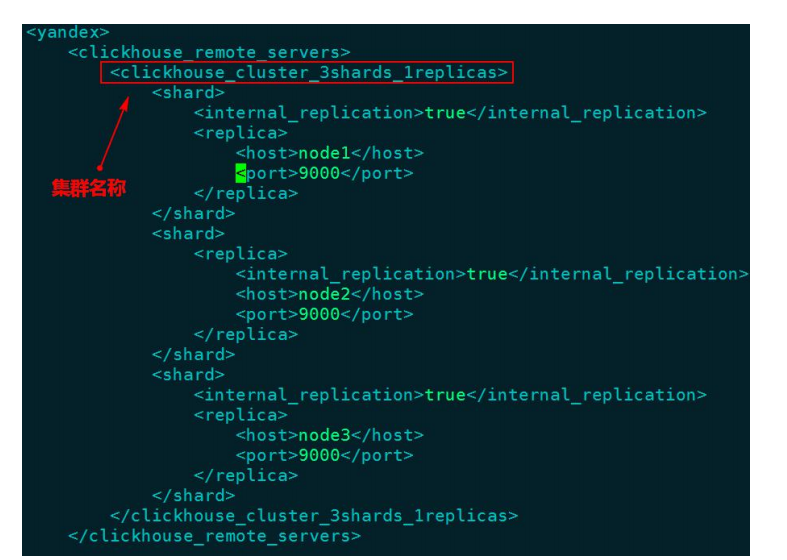
Distributed 是== ClickHouse 中 分 布 式 引 擎== , 之 前 所 有 的 操 作 虽 然 说 是 在ClickHouse 集群中进行的,但是实际上是在 node1 节点中单独操作的,与 node2、node3无关,使用分布式引擎声明的表才可以在其他节点访问与操作。
Distributed 引擎和 Merge 引擎类似,本身不存放数据,功能是在不同的 server上把多张相同结构的物理表合并为一张逻辑表。


示例:



上面的语句中使用了 ON CLUSTER 分布式 DDL(数据库定义语言),这意味着在集群的每个分片节点上,都会创建一张 Distributed 表,这样便可以从其中任意一端发起对所有分片的读、写请求。
相关文章:
ClickHouse--04--数据库引擎、Log 系列表引擎、 Special 系列表引擎
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 1.数据库引擎1.1 Ordinary 默认数据库引擎1.2 MySQL 数据库引擎MySQL 引擎语法字段类型的映射 2.ClickHouse 表引擎3.Log 系列表引擎几种 Log 表引擎的共性是&#…...

docker的底层原理
概述:Docker的底层原理基于容器化技术,通过使用命名空间和控制组等技术实现资源的隔离与管理。 底层原理: 客户端-服务器架构:Docker采用的是Client-Server架构,其中Docker守护进程(daemon)运…...

有关光猫、路由器、交换机、网关的理解
前提 在了解计算机网络的过程中,出现了这四个名词:光猫、路由器、交换机、网络。有点模糊,查阅互联网相关资料,进行整理。如有错误,欢迎大家批评指正。 光猫 首先光猫是物理存在的,大家在家里应该都可以…...

图像旋转翻转变换
题目描述 给定m行n列的图像各像素点灰度值,对其依次进行一系列操作后,求最终图像。 其中,可能的操作及对应字符有如下四种: A:顺时针旋转90度; B:逆时针旋转90度; C:…...
网站常见的反爬手段及反反爬思路
摘要:介绍常见的反爬手段和反反爬思路,内容详细具体,明晰解释每一步,非常适合小白和初学者学习!!! 目录 一、明确几个概念 二、常见的反爬手段及反反爬思路 1、检测user-agent 2、ip 访问频率的限制 …...

GUI—— 从的可执行exe文件中提取jar包并反编译成Java
从exe4j生成的可执行文件中提取嵌入的jar包并反编译成Java代码,可以按照以下步骤操作: 步骤1:提取jar包 1.运行exe程序:首先启动exe4j生成的.exe可执行文件。当它运行时,通常会将内部包含的jar文件解压到临时目录下。…...
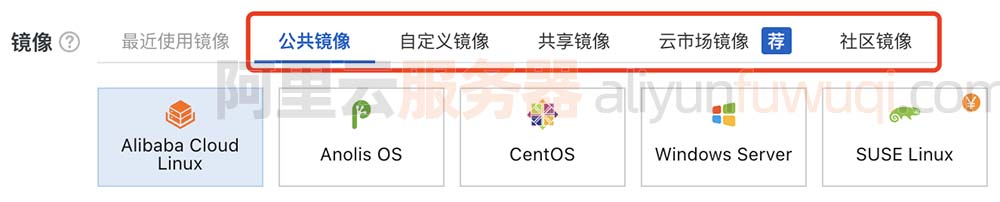
阿里云服务器镜像是什么?如何选择镜像?
阿里云服务器镜像怎么选择?云服务器操作系统镜像分为Linux和Windows两大类,Linux可以选择Alibaba Cloud Linux,Windows可以选择Windows Server 2022数据中心版64位中文版,阿里云服务器网aliyunfuwuqi.com来详细说下阿里云服务器操…...

C语言------一种思路解决实际问题
1.比赛名次问题 ABCDE参加比赛,那么每个人的名次都有5种可能,即1,2,3,4,5; int main() {int a 0;int b 0;int c 0;int d 0;int e 0;for (a 1; a < 5; a){for (b 1; b < 5; b){for…...

前端判断对象为空
一.使用JSON.stringify()方法: JSON.stringify() 是将一个JavaScript对象或值转换为JSON格式字符串,如果最终只得到一个{},就说明他是一个空对象 let obj1 {}; console.log(JSON.stringify(obj1) "{}"); //true 表示为空对象l…...
DS:栈和队列的相互实现
创作不易,感谢友友们三连!! 一、前言 栈和队列的相互实现是用两个栈去实现队列或者是用两个队列去实现栈,这样其实是把问题复杂化的,实际中没有什么应用价值,但是通过他们的相互实现可以让我们更加深入地理…...
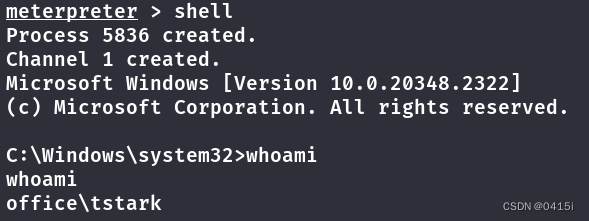
Hack The Box-Office
端口扫描&信息收集 使用nmap对靶机进行扫描 nmap -sC -sV 10.10.11.3开放了80端口,并且注意到该ip对应的域名为office.htb,将其加入到hosts文件中访问之 注意到扫描出来的还有robots文件,经过尝试后只有administrator界面是可以访问的 …...

android aidl进程间通信封装通用实现
接上一篇的分析,今天继续 aidl复杂流程封装-CSDN博客 今天的任务就是将代码梳理下放进来 1 项目gradle配置: 需要将对应的代码放到各自的目录下,这里仅贴下关键内容,细节可以下载代码慢慢看 sourceSets { main { manifest.srcFile src/main/And…...
FL Studio 21.2.3.4004 All Plugins Edition Win/Mac音乐软件
FL Studio 21.2.3.4004 All Plugins Edition 是一款功能强大的音乐制作软件,提供了丰富的音频处理工具和插件,适用于专业音乐制作人和爱好者。该软件具有直观的用户界面,支持多轨道录音、混音和编辑,以及各种音频效果和虚拟乐器。…...

vivado RAM HDL Coding Guidelines
从编码示例下载编码示例文件。 块RAM读/写同步模式 您可以配置块RAM资源,为提供以下同步模式给定的读/写端口: •先读取:在加载新内容之前先读取旧内容。 •先写:新内容立即可供阅读先写也是众所周知的如通读。 •无变化&…...

springboot/ssm甘肃旅游服务平台Java在线旅游规划管理系统
springboot/ssm甘肃旅游服务平台Java在线旅游规划管理系统 开发语言:Java 框架:springboot(可改ssm) vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7&am…...

第三百五十四回
文章目录 1. 概念介绍2. 使用方法2.1 获取所有时区2.2 转换时区时间 3. 示例代码4. 内容总结 我们在上一章回中介绍了"分享一些好的Flutter站点"相关的内容,本章回中将介绍timezone包.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我们在…...

【Funny Game】 吃豆人
目录 【Funny Game】 吃豆人 吃豆人 文章所属专区 Funny Game 吃豆人 吃豆人,这款经典游戏如今依旧魅力四射。玩家需操控小精灵,在迷宫内吞噬所有豆子,同时避开狡猾的鬼怪。当吃完所有豆子后,便可消灭鬼怪,赢得胜利。…...

PyCharm - Run Debug 程序安全执行步骤
PyCharm - Run & Debug 程序安全执行步骤 1. Run2. DebugReferences 1. Run right click -> Run ‘simulation_data_gene…’ or Ctrl Shift F10 2. Debug right click -> Debug ‘simulation_data_gene…’ 在一个 PyCharm 工程下,存在多个 Pytho…...

作为一个程序员,最少要看过这几部电影吧?
计算机专业必看的几部电影 计算机专业必看的几部电影,就像一场精彩的编程盛宴!《黑客帝国》让你穿越虚拟世界,感受高科技的魅力;《社交网络》揭示了互联网巨头的创业之路,《源代码》带你穿越时间解救世界,…...

备战蓝桥杯 Day4
目录 注意:递推开long long 1140:验证子串 1131:基因相关性 1176:谁考了第k名 1177:奇数单增序列 1180:分数线划定 1184:明明的随机数 1185:单词排序 1186:出现…...

知识图谱与语义网技术栈:从RDF/SPARQL到图神经网络与LLM融合实战
1. 项目概述:从数据孤岛到智能互联的桥梁在数据爆炸的时代,我们每天都被海量的信息包围。然而,这些信息往往像一座座孤岛,彼此隔绝,难以形成有效的知识网络。你是否曾想过,如果能让机器像人一样,…...

经典通信赋能分布式量子机器学习:NISQ时代的实用化路径探索
1. 项目概述:当量子机器学习遇上分布式架构量子机器学习(QML)这几年火得不行,它背后的逻辑其实挺吸引人的:利用量子态的叠加和纠缠特性,把数据映射到指数级庞大的希尔伯特空间里进行处理。理论上࿰…...

Qwen模型 LeetCode 2577. 在网格图中访问一个格子的最少时间 Java实现
哎呀,这道题我可太熟啦!2577. 在网格图中访问一个格子的最少时间,听起来就很有挑战性对不对?让我跟你聊聊我的解法思路~这其实是个典型的最短路径问题呢。想象一下我们站在一个神奇的网格世界里,每个格子都有自己的&qu…...

字节Seed基座GR3机器人的专属控制内核,具备柔性物体操控、人体姿态复刻、工业闭环作业等功能
全称:Gesture Real-Time Reinforcement Learning 全域实时姿态强化学习具身控制框架 内部代号:GR-RL V5.9.2 稳态正式版 隶属体系:字节Seed基座GR3机器人专属控制内核 核心用途:全品类柔性物体操控、人体仿生姿态复刻、工业高精度…...

【Midjourney饱和度调控黄金法则】:20年AI视觉调校专家亲授3类典型过曝/灰暗场景的7步精准校正流程
更多请点击: https://codechina.net 第一章:Midjourney饱和度调控的核心原理与认知重构 Midjourney 的饱和度(Saturation)并非独立控制的图像参数,而是嵌套于其隐式色彩空间映射与扩散过程中的动态响应变量。它由模型…...

根据lab1.pdf总结的知识点
第一题:简单的应用程序(Hello.java)类与主方法:Java程序入口必须是public static void main(String args[]),public表示该方法能被JVM访问,static表示无需创建对象即可调用,void表示无返回值&am…...

瑞数6代JSVMP逆向实战:Node.js复现可信字节码运行时
1. 这不是“绕过验证码”,而是和瑞数6代打一场精密的JavaScript攻防战你肯定见过那个页面:刚点开目标网站,还没输入账号,浏览器就卡住半秒,接着弹出一个412 Precondition Failed——不是403,不是500&#x…...

Lovable不是UI美化!揭秘神经科学验证的4层用户依恋模型与落地SDK架构
更多请点击: https://intelliparadigm.com 第一章:Lovable不是UI美化!揭秘神经科学验证的4层用户依恋模型与落地SDK架构 Lovable并非视觉动效堆砌,而是基于fMRI与眼动追踪实验验证的神经认知路径——当用户在300ms内完成「感知→…...

2026数字营销专业学数据分析的职业优势
一、数字营销与数据分析的融合趋势2026年数字营销领域将进一步依赖数据驱动决策。随着消费者行为数字化程度加深,企业需通过数据分析实现个性化营销、动态定价和实时优化。复合型人才需同时掌握营销策略与数据建模能力,以应对跨渠道归因、隐私安全等复杂…...

如何快速清理Windows右键菜单:终极管理工具完整指南
如何快速清理Windows右键菜单:终极管理工具完整指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是不是也遇到过这样的烦恼?安装的软…...