从零开始学习Netty - 学习笔记 - NIO基础 - ByteBuffer: 简介和基本操作
NIO基础
1.三大组件
1.1. Channel & Buffer

Channel
在Java NIO(New I/O)中,“Channel”(通道)是一个重要的概念,用于在非阻塞I/O操作中进行数据的传输。Java NIO提供了一种更为灵活和高效的I/O处理方式,相比于传统的I/O,它具有更好的性能和可扩展性。
常见的Java NIO中的通道类型:
- FileChannel(文件通道):
- 用于文件I/O操作的通道,可以在文件中进行读取、写入和操作。
- SocketChannel(套接字通道):
- 用于TCP协议的通道,可以在网络套接字连接中进行读取和写入数据。(客户端,服务器端都能用)
- ServerSocketChannel(服务器套接字通道):
- 监听新的TCP连接的通道,当有新的连接进来时,可以接受并创建对应的SocketChannel。(只能用于服务器端)
- DatagramChannel(数据报通道):
- 用于UDP协议的通道,可以在网络中发送和接收数据报。
通过使用这些通道,Java NIO可以提供非阻塞的I/O操作,允许程序在一个线程中管理多个I/O操作,提高了系统的并发处理能力和性能表现。通道和缓冲区(Buffer)结合使用,能够实现更灵活、高效的数据传输和处理。
Buffer
在Java NIO中,Buffer(缓冲区)是一个核心概念,用于在通道(Channel)和数据源之间进行数据交互。Buffer实际上是一个容器,用于存储特定类型的数据,并提供了方便的方法来读取和写入数据。
常见的Java NIO中的Buffer类型:
-
ByteBuffer:
- ByteBuffer是最基本的缓冲区类型,用于存储字节数据。
- MappedByteBuffer:
- MappedByteBuffer是ByteBuffer的一个子类,它通过文件通道直接映射到内存中,可以实现高效的文件I/O操作。
- MappedByteBuffer:
- ByteBuffer是最基本的缓冲区类型,用于存储字节数据。
-
CharBuffer:
- CharBuffer用于存储字符数据。
-
ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer:
- 这些是用于存储各种基本数据类型的缓冲区,分别用于存储short、int、long、float和double类型的数据。
这些缓冲区提供了一种灵活的方式来管理数据,可以在缓冲区和通道之间进行数据传输,也可以在缓冲区内部进行数据处理。通过缓冲区,Java NIO实现了高效的I/O操作,可以在同一线程内处理多个通道,提高了系统的并发性能。
1.2.Selector

当使用 Java NIO 进行非阻塞 I/O 操作时,Selector(选择器)是一种关键的组件。它允许单个线程有效地管理多个 Channel,监视它们的状态并且在
至少一个 Channel 准备好进行读取、写入或者连接时,唤醒线程。Selector 的作用是配置一个线程来管理多个 Channel,获取这些 Channel 上发生的事件。这些 Channel 通常工作在非阻塞模式下,因此不会让线程阻塞在一个 Channel 上。Selector 适用于连接数量特别多但流量低的场景,因为它可以有效地利用一个线程来处理多个连接,降低线程创建和上下文切换的开销。
- 非阻塞 I/O:
- Selector 允许程序使用单个线程处理多个 Channel,而不是为每个 Channel 都创建一个线程。这样可以显著减少线程的数量,提高系统的并发处理能力。
- Channel 注册:
- 在使用 Selector 之前,需要将每个 Channel 注册到 Selector 上,并指定感兴趣的事件类型,如读、写、连接等。
- 事件就绪集合:
- Selector 会不断轮询注册在其上的 Channel,当一个或多个 Channel 准备好进行 I/O 操作时,Selector 将返回一个就绪事件的集合。
- 事件驱动的编程模型:
- 应用程序通过监听就绪事件的方式,实现了一种事件驱动的编程模型,根据不同的事件类型执行相应的操作。
- 资源管理:
- 使用完 Selector 后,应及时关闭以释放资源,避免资源泄漏和性能问题。
通过 Selector,Java NIO 提供了一种高效的非阻塞 I/O 模型,使得应用程序能够更好地处理大量并发连接,提高系统的性能和可伸缩性。
2.ByteBuffer
ByteBuffer 是 Java NIO 中用于处理字节数据的缓冲区类之一。它提供了一种灵活的方式来处理字节数据,例如读取、写入、修改、复制等操作。
以下是关于 ByteBuffer 的一些重要特点和用法:
- 容量和位置:
- ByteBuffer 有一个固定的容量,表示它可以存储的最大字节数量。它还有一个位置(position),表示下一个读取或写入操作将要发生的位置。
- 读写操作:
- ByteBuffer 可以被用来进行读取和写入操作。它提供了诸如 put()、get()、putInt()、getInt() 等方法来读取和写入字节数据。
- 字节顺序(Byte Order):
- ByteBuffer 可以配置为使用不同的字节顺序,例如大端字节序(Big Endian)或小端字节序(Little Endian),以适应不同的数据格式。
- 直接缓冲区和非直接缓冲区:
- ByteBuffer 可以是直接缓冲区或非直接缓冲区。直接缓冲区使用操作系统的内存空间,通常性能更好,而非直接缓冲区使用 Java 虚拟机的堆内存。
- 清除、翻转和重绕:
- ByteBuffer 提供了一些方法来处理缓冲区的状态,例如 clear() 方法清除缓冲区中的数据(写模式)、flip() 方法翻转缓冲区以便读取已写入的数据(读模式)、rewind() 方法重绕缓冲区以便重新读取已读数据(写模式)。
- 其他操作:
- ByteBuffer 还提供了一些其他的操作,如 compact() 方法压缩缓冲区、slice() 方法创建一个新的缓冲区视图等。
ByteBuffer 在网络编程、文件 I/O、数据处理等领域广泛应用,它是 Java NIO 中处理字节数据的重要工具之一,提供了高效、灵活的字节数据处理方式。
2.1.案例1-读取文件内容
/*** ByteBuffer 测试测试读取文件* @author 13723* @version 1.0* 2024/2/19 21:30*/
public class ByteBufferTest {private static final Logger logger = LoggerFactory.getLogger(MethodHandles.lookup().lookupClass());@Test@DisplayName("测试读取文件")public void testReadFile() {// 1.读取文件try (FileChannel channel = new FileInputStream("data.txt").getChannel()) {while (true){// 1.1 创建一个缓冲区(划分一块内存作为缓冲区) 每次读取只取5个字节 5个字节读取完毕后再读取下一个5个字节ByteBuffer byteBuffer = ByteBuffer.allocate(5);// 1.2 读取数据到缓冲区int len = channel.read(byteBuffer);// 读取到文件末尾 len = -1 退出循环if (len == -1) {break;}// 1.3 打印缓冲区的内容// 切换到读模式byteBuffer.flip();while (byteBuffer.hasRemaining()){ // 检查是否存在未读取的数据byte b = byteBuffer.get();logger.error("读取到的字节为:{}", (char) b);}// 1.4 每次读取完成切换为写模式byteBuffer.clear();}} catch (IOException e) {}}
}

2.2.ByteBuffer结构
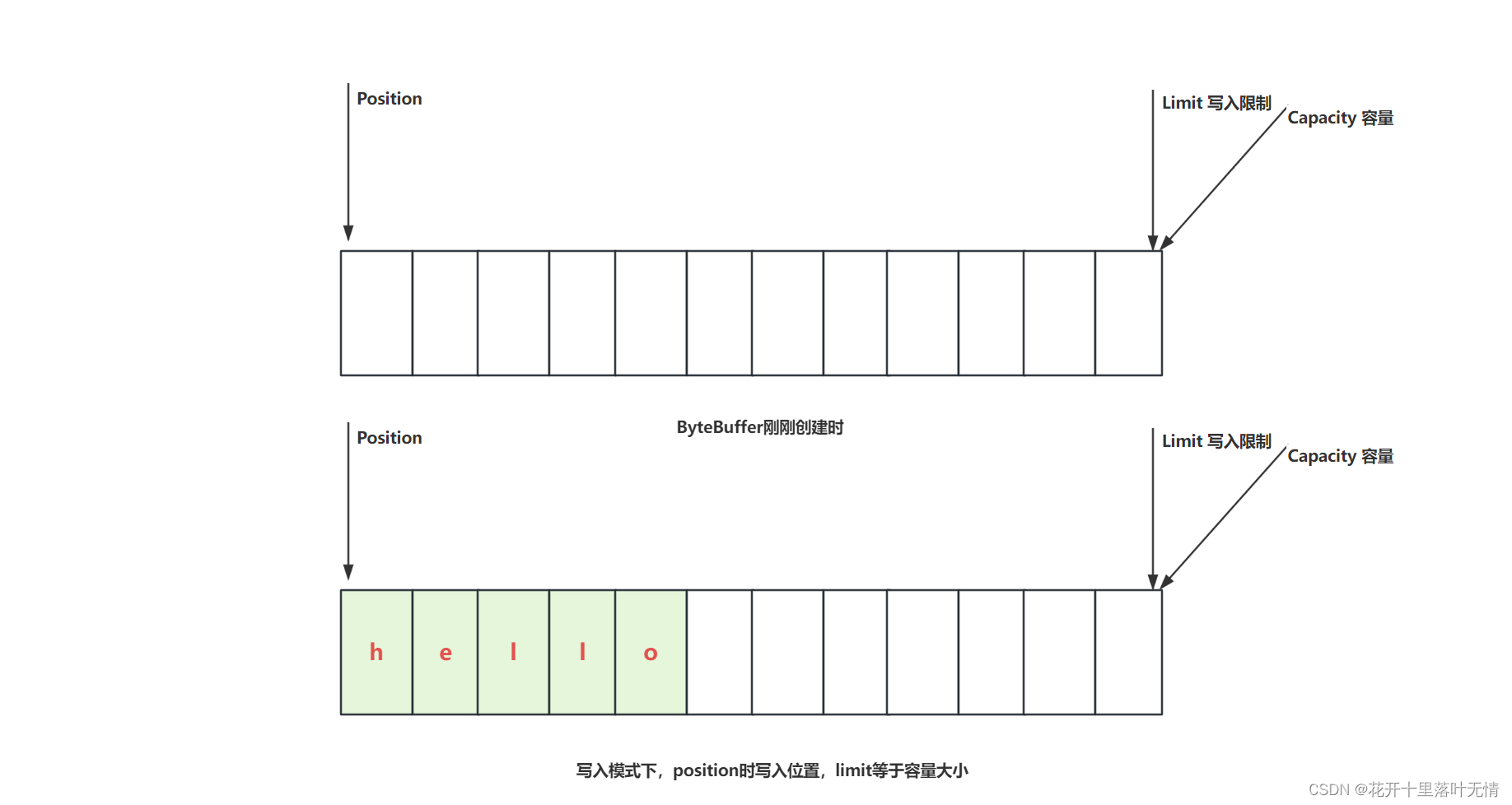
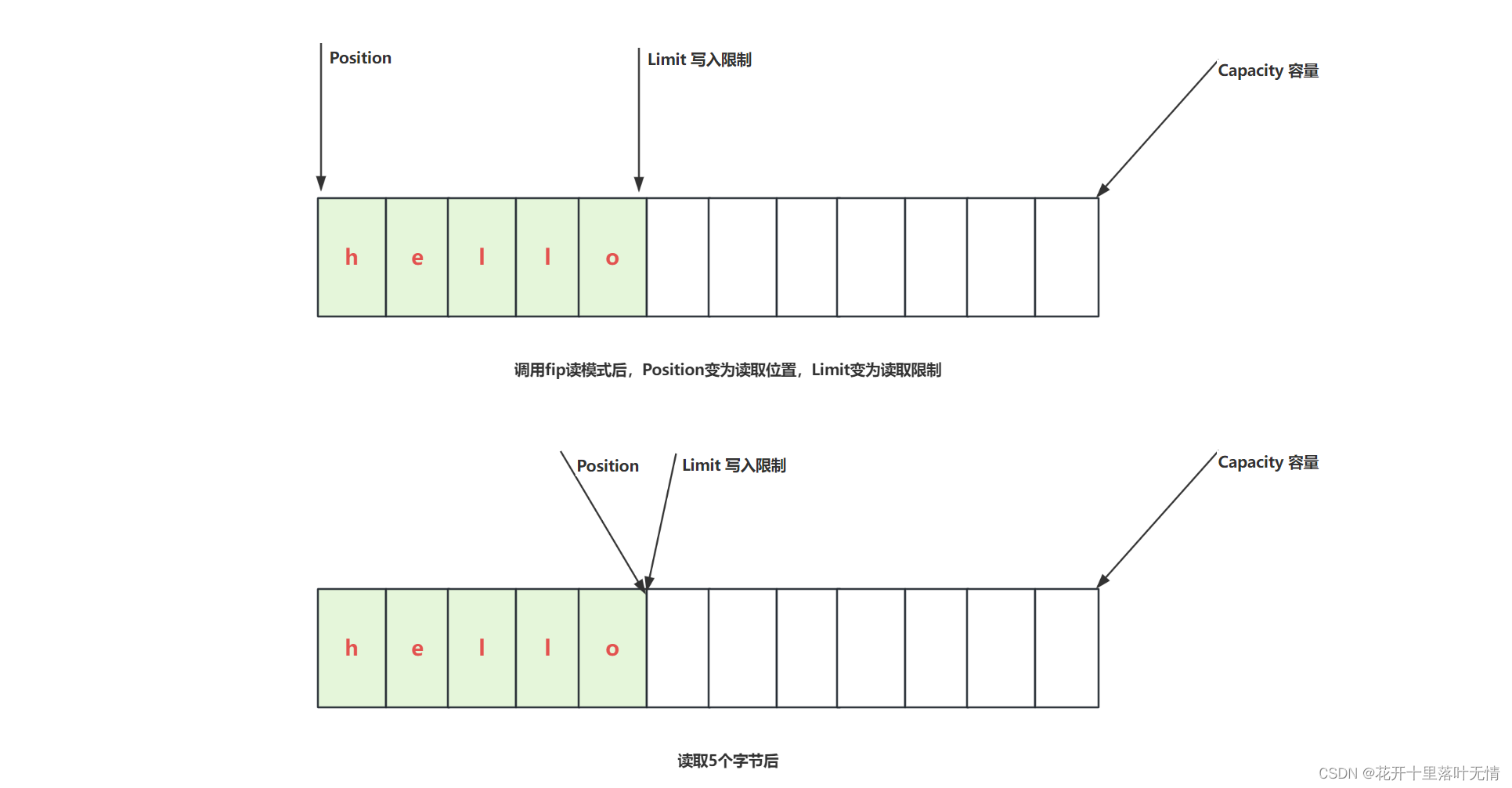
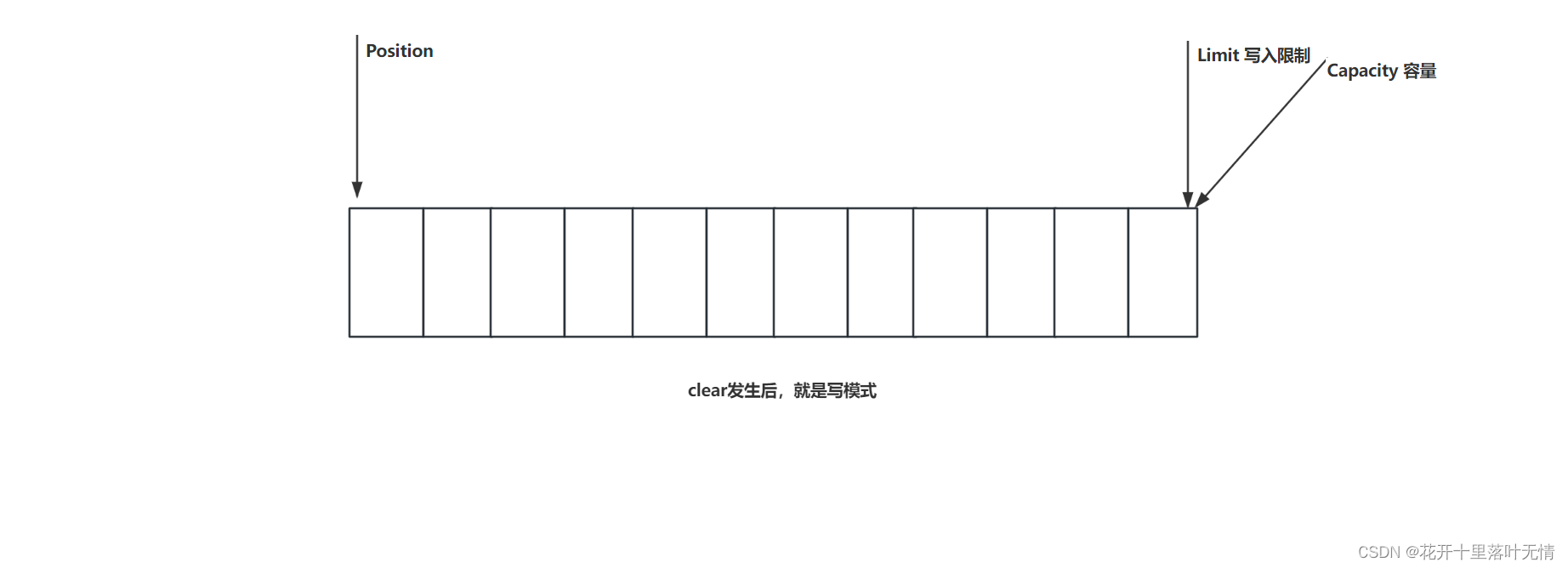
compact方法,就是把未读取完成的部分向前压缩,然后切换为写模式下次写入的位置,是从上次没有读完的位置开始的
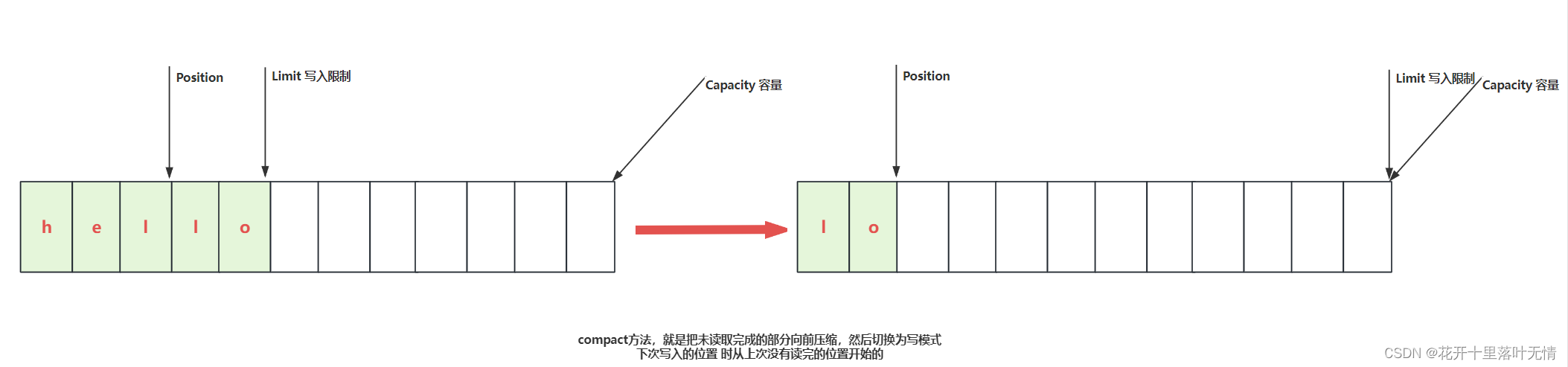
2.3.案例2-读取写入数据
@Test@DisplayName("测试ByteBuffer写入读取数据")public void test2(){ByteBuffer buffer = ByteBuffer.allocate(10);// 写入一个字节 ‘a’buffer.put((byte) 'a');// 打印字符debugAll(buffer);// 再写入两个字节buffer.put(new byte[]{'b', 'c'});debugAll(buffer);// 切换成模式,此时position = 0, limit = 3buffer.flip();byte b = buffer.get();System.out.println((char) b);debugRead(buffer);buffer.compact();debugAll(buffer);}

- 调用compact方法

2.4.ByteBuffer常见方法
2.4.1.分配空间
可以使用 allocate 方法为 ByteBuffer 分配空间,其他 Buffer 类也有该方法 不能动态调整容量 netty对ByteBuffer这里做了增强,可以动态调整
它使用的是 Java 堆内存(Heap Memory)。allocate 方法分配的是一个非直接缓冲区,即缓冲区的数据存储在 Java 虚拟机的堆内存中。
堆内存的优势在于它的管理由 Java 虚拟机负责,而且垃圾回收器可以有效地回收不再使用的对象,但是在进行 I/O 操作时,需要将数据从堆内存复制到内核空间,存在额外的拷贝开销。
读写效率低
ByteBuffer buffer = ByteBuffer.allocate(10);allocateDirect(10),它使用的是直接缓冲区(Direct Buffer),可以通过 ByteBuffer.allocateDirect() 方法来创建。直接缓冲区的数据存储在操作系统的内存中(不会受到垃圾回收的影响),减少了数据在 Java 堆和本地堆之间的拷贝操作,提高了 I/O 操作的效率。但是,直接缓冲区的分配和释放通常更昂贵,可能导致内存泄漏问题。、
读写效率高(少一次拷贝)
ByteBuffer buffer1 = ByteBuffer.allocateDirect(10);
2.4.2.包装现有数组
如果有现有的字节数组,可以使用 wrap 方法将其包装成 ByteBuffer
byte[] byteArray = new byte[10];
ByteBuffer buffer = ByteBuffer.wrap(byteArray);
2.4.3.获取和设置容量
获取 ByteBuffer 的容量(capacity)
int capacity = buffer.capacity();
设置 ByteBuffer 的容量(慎用,可能导致数据丢失)
buffer.capacity(20);
2.4.4.获取和设置位置
获取 ByteBuffer 的位置(position)
int position = buffer.position();
设置 ByteBuffer 的位置(position),用于读取或写入数据
buffer.position(5);
2.4.5.获取限制和设置限制
获取 ByteBuffer 的限制(limit),即可以读取或写入的最大位置
int limit = buffer.limit();
设置 ByteBuffer 的限制(limit)
buffer.limit(8);
2.4.6.读取和写入数据
从 ByteBuffer 中读取字节数据
也可也调用
channel的wirte方法
byte b = buffer.get();
int r = channel.wite(buffer);
向 ByteBuffer 中写入字节数据
int read = channel.read();
也可也调用
channel的read方法
buffer.put((byte) 10);
channel.read(buffer);
2.4.7.翻转缓冲区
将 ByteBuffer 从写模式切换到读模式,通常在写入数据后调用
buffer.flip();
2.4.8.清空缓冲区
清空 ByteBuffer 中的数据,通常在读取数据后调用
buffer.clear();
2.4.9.倒带缓冲区
将 ByteBuffer 的位置设置为 0,通常在重新读取数据时调用
buffer.rewind();
2.4.10.压缩缓冲区
将未读取的数据复制到缓冲区的开始处,然后将位置设置为复制的数据末尾,通常在写入部分数据后调用
buffer.compact();
2.4.11.标记和重置位置
标记当前的位置,通常与 reset 方法一起使用,用于返回到之前标记的位置,,比如中间某些数据重要需要返回读取
buffer.mark();
重置位置到之前标记的位置
buffer.reset();
相关文章:
从零开始学习Netty - 学习笔记 - NIO基础 - ByteBuffer: 简介和基本操作
NIO基础 1.三大组件 1.1. Channel & Buffer Channel 在Java NIO(New I/O)中,“Channel”(通道)是一个重要的概念,用于在非阻塞I/O操作中进行数据的传输。Java NIO提供了一种更为灵活和高效的I/O处理方…...

Chatgpt润色文章“咒语”
文章目录 前言一、汉译英二、语法校正三、润色英文段落结构和句子逻辑 前言 一些Chatgpt润色文章常用的命令。 一、汉译英 I am a researcher studying Aerospace Manufacturing and now trying to revise my manuscript which will be submitted to the journal of Nature.I…...
【OpenGL教程2】 简单案例介绍Python 中的 OpenGL
目录 一、介绍二、安装三、编码练习四、结论 一、介绍 在本教程中,我们将学习如何在 Python 中使用PyOpenGL库。OpenGL是一个图形库,受Windows、Linux和MacOS等多个平台支持,也可用于多种其他语言;然而,这篇文章的范围…...

评估方法:CMMI/能力成熟度模型集成
一、什么是CMMI CMMI,全称为Capability Maturity Model Integration,即能力成熟度模型集成。它是由美国卡内基梅隆大学软件工程研究所研发的过程改进模型,也是国际上用于评价软件企业能力成熟度的一项重要标准。 CMMI的目的是帮助软件企业对…...
Gin框架: HTML模板渲染之配置与语法详解
Gin的HTML模板配置 1 )单一目录的配置 配置模板目录,在与main.go同级下, 新建目录,下面二选一,仅作举例, 这里选择 tpls templatestpls 在 tpls 目录下新建 news.html <!-- 最简单的 --> <h1>News Page</h1>&l…...
.NET Core WebAPI中使用Log4net 日志级别分类并记录到数据库
一、效果 记录日志为文档 记录日志到数据库 二、添加NuGet包 三、log4net.config代码配置 <?xml version"1.0" encoding"utf-8" ?> <log4net><!-- Debug日志 --><appender name"RollingFileDebug" type"log4net…...

Day36 贪心算法 part05
划分字母区间 一个字母区间仅有几个字母前一个字母区间有的字母后面都没有 合并区间 天才举一反三写出来了...
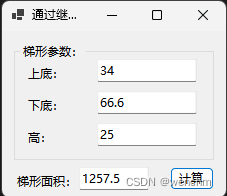
C#计算矩形面积:通过定义结构 vs 通过继承类
目录 一、涉及到的知识点 1.结构 2.结构和类的区别 3.继承 4.使用类继承提高程序的开发效率 5.属性 (1)属性定义 (2)get访问器 (3)set访问器 6. 属性和字段的区别 二、实例:通过定义…...
【复现】Panalog大数据日志审计系统 RCE漏洞_51
目录 一.概述 二 .漏洞影响 三.漏洞复现 1. 漏洞一: 四.修复建议: 五. 搜索语法: 六.免责声明 一.概述 Panalog大数据日志审计系统定位于将大数据产品应用于高校、 公安、 政企、 医疗、 金融、 能源等行业之中,针对网络流…...

react【五】redux/reduxToolkit/手写connext
文章目录 1、回顾纯函数2、redux2.1 redux的基本使用2.2 通过action修改store的数值2.3 订阅state的变化2.4 目录结构2.5 Redux的使用过程2.6 redux的三大原则2.7 Redux官方图 3、redux在React中的使用4、react-redux使用4.1 react-redux的基本使用4.2 异步请求 redux-thunk4.3…...

.NET开源的一个小而快并且功能强大的 Windows 动态桌面软件 - DreamScene2
前言 很多同学都不愿给电脑设动态壁纸,其中有个重要原因就是嫌它占资源过多。今天大姚分享一个.NET开源、免费(MIT license)的一个小而快并且功能强大的 Windows 动态桌面软件,支持视频和网页动画播放:DreamScene2。 …...
jsp计算机线上教学系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 JSP 计算机线上教学系统是一套完善的java web信息管理系统,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为 TOMCAT7.0,Myeclipse8.5开发,数据库为Mysql5…...

RabbitMQ的高可用机制
RabbitMQ通过多种机制提供高可用性(HA)支持,以确保消息系统的稳定性和可靠性。下面将详细介绍这些机制,并提供代码示例。 集群(Clustering) RabbitMQ的集群提供了高可用性和负载均衡。集群中的节点共享同一个Erlang分布式数据库…...

人机协同中的贝叶斯和马尔可夫
人机协同中的马尔可夫链是指在人与机器之间协同工作过程中,可能涉及到的状态转移概率模型。马尔可夫链是一种数学模型,描述了在给定当前状态下,未来状态的概率分布只依赖于当前状态,而与过去状态无关的随机过程。在人机协同工作中…...
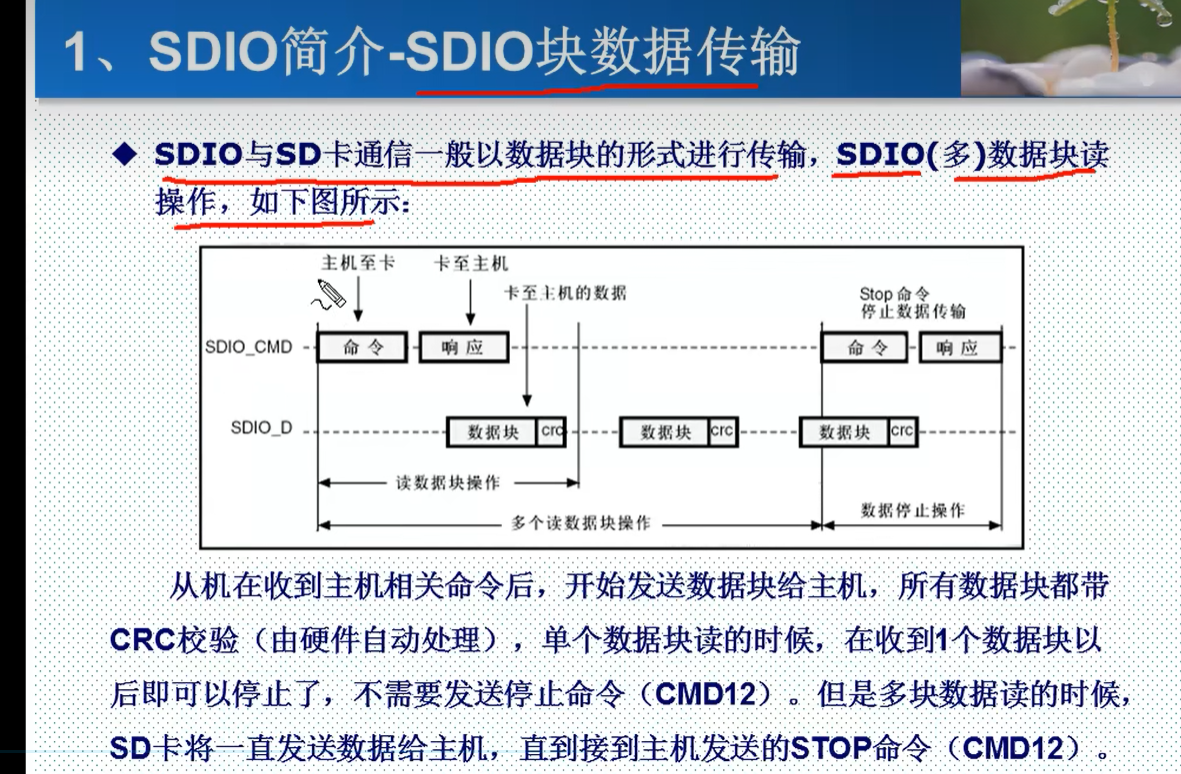
STM32的SDIO
一.SDIO简介 SDIO,全称Secure Digital Input/Output,是一种用于在移动设备和嵌入式系统中实现输入/输出功能的接口标准。它结合了SD卡的存储功能和I/O功能,允许设备通过SD卡槽进行数据输入输出和外围设备连接。 SDIO接口通常被用于连接各种…...
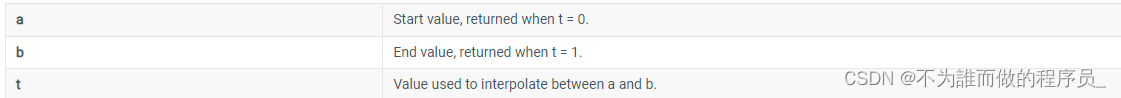
Unity中的Lerp插值的使用
Unity中的Lerp插值使用 前言Lerp是什么如何使用Lerp 前言 平时在做项目中插值的使用避免不了,之前一直在插值中使用存在误区,在这里浅浅记录一下。之前看的博客或者教程还多都存在一个“永远到达不了,只能无限接近”的一个概念。可能是之前脑…...
年后上来面了一个来字节要求月薪23K,明显感觉他背了很多面试题...
最近有朋友去字节面试,面试前后进行了20天左右,包含4轮电话面试、1轮笔试、1轮主管视频面试、1轮hr视频面试。 据他所说,80%的人都会栽在第一轮面试,要不是他面试前做足准备,估计都坚持不完后面几轮面试。 其实&…...

代码随想录算法训练营DAY20 | 二叉树 (8)
一、LeetCode 701 二叉搜索树中的插入操作 题目链接: 701.二叉搜索树中的插入操作https://leetcode.cn/problems/insert-into-a-binary-search-tree/description/ 思路:见缝插针罢辽。 class Solution {public TreeNode insertIntoBST(TreeNode root, i…...

2023年全球软件开发大会(QCon北京站2023)2月:核心内容与学习收获(附大会核心PPT下载)
本次峰会是一个汇集了最新技术趋势、最佳实践和创新思维的盛会。对于从事软件开发和相关领域的专业人士来说,参加这样的大会将有助于他们了解行业动态、提升技能水平、拓展职业视野,并与同行建立联系和合作。 本次峰会包含:AI基础架构、DevO…...
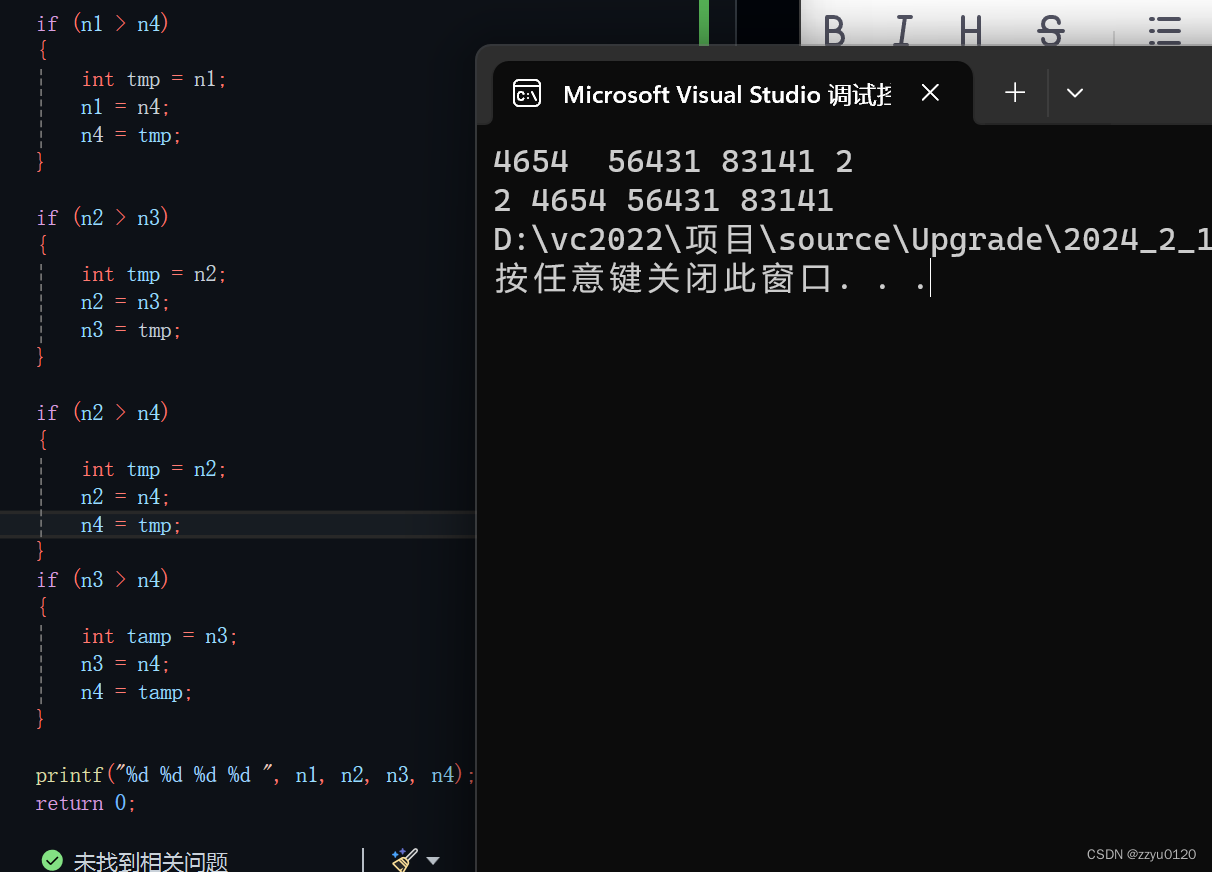
键盘输入4个数,从小到大排序
题目 键盘输入4个整数,从小到大排序 思路 代码 #define _CRT_SECURE_NO_WARNINGS 1 #include<stdio.h>//键盘输入4个整数,从小到大排序 int main() {int n1, n2, n3, n4;scanf_s("%d %d %d %d", &n1, &n2, &n3, &n4);…...

Web渗透测试全流程实战指南:从侦察到报告的结构化方法
1. 这不是“黑客速成班”,而是一张能真正带你进渗透测试实战现场的路线图很多人点开“Web渗透测试学习流程图”时,心里想的是:学完这个,我是不是就能黑进某个网站?能不能接单赚钱?甚至幻想自己坐在咖啡馆里…...

Playwright 浏览器自动化完全指南:从入门到实战
目录 一、什么是 Playwright二、Playwright vs Selenium:为什么选择 Playwright三、支持的语言与浏览器四、核心架构与执行流程五、环境安装与验证六、第一个程序:打开网页并截图七、常用操作速查八、元素定位详解九、自动等待机制深度解析十、浏览器上…...

rk3566 配置HDMI的屏的流程
一、确认硬件与固件硬件:RK3566 板载 Micro HDMI → 接 HDMI 显示器(用转接头 / 线)。固件:优先用官方带 HDMI 配置的镜像(如 hdmi 专用 img),避免默认关闭 HDMI 的版本。二、设备树(…...

固件逆向实战指南:从熵值分析到函数重建的七步法
1. 这不是“刷机教程”,而是一份固件逆向的实战切片很多人第一次听说“固件逆向”,脑子里浮现的是路由器刷OpenWrt、智能摄像头换壳跑Home Assistant,或者某款老式NAS突然不支持新硬盘,只好翻出U-Boot命令硬怼。这些确实是固件逆向…...
)
TVA驱动智能家居的视觉范式革命(11)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

FairyGUI GLoader动效动态接管与运行时替换实战
1. 这不是简单的“换图”,而是动效资源的动态接管机制在 FairyGUI for Unity 项目里,当你看到GLoader组件上挂着一个.png或.jpg,心里默认它就是张静态图——但一旦你给它赋值一个MovieClip、GAnimation,甚至是一段从 AssetBundle …...

Spring Boot + MyBatis服务启动流程,新增代码跑通流程,映射规则,常见问题定位
一、服务启动流程 零代码(仅需配置文件和依赖)。 顺序固定,由框架保证。 一旦某个步骤失败(如 XML 解析错误),整个启动失败。 二、新增代码跑通流程 全手动,需熟悉 MyBatis 映射规则、Spring…...

Keil中sprintf和自定义Serial_Printf,哪个更适合你的串口打印需求?
Keil开发中的串口打印方案:sprintf与自定义Serial_Printf深度对比 在嵌入式开发中,串口打印是调试和日志记录的重要手段。Keil MDK作为广泛使用的嵌入式开发工具链,提供了多种实现串口打印的方案。对于已经了解printf重定向基础概念的开发者…...

内网离线部署RPA:打包EXE+本地激活+数据零上云方案
领导给了一周,我前三天全耗在这个报错上:无法连接到 activation.xxx.com 请检查网络连接后重试2024年5月,我用的蓝印RPA物理隔离内网部,处理核心业务数据,要求"数据不出本机,流程不外传,审…...

HermesAgent工具如何快速对接Taotoken的多模型服务提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 HermesAgent工具如何快速对接Taotoken的多模型服务提供商 基础教程类,本文将指导使用HermesAgent工具的开发者…...