MySQL 基础知识(六)之数据查询(二)
目录
6 数值型函数
7 字符串函数
8 流程控制函数
9 聚合函数
10 分组查询 (group by)
11 分组过滤 (having)
12 限定查询 (limit)
13 多表查询
13.1 连接条件关键词 (on、using)
13.2 连接算法
13.3 交叉连接 (cross join)
13.4 内连接 (inner join)
13.5 外连接 (left join、right join)
14 子查询
14.1 select 子查询 (只需了解)
14.2 from 子查询
14.3 where 子查询
15 查询顺序总结
6 数值型函数
|

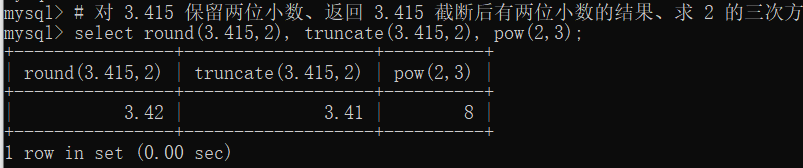
7 字符串函数
|




8 流程控制函数
|

9 聚合函数
|
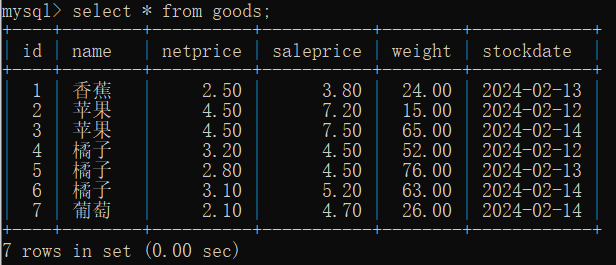

10 分组查询 (group by)
|

11 分组过滤 (having)
|
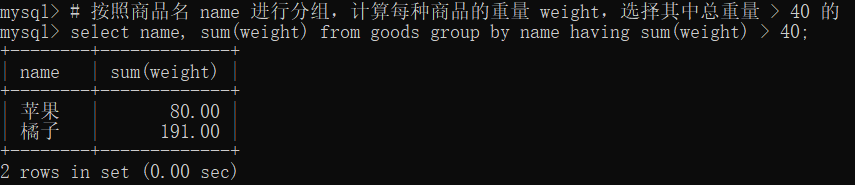
12 限定查询 (limit)
|

13 多表查询
sales 表
drop table if exists sales;
create table sales (
id int primary key auto_increment,
name varchar(20),
saleprice float(7,2)
)charset=utf8;insert into sales(id, name, saleprice) values
(1, '香蕉', 3.8),
(3, '苹果', 7.5),
(4, '橘子', 4.5),
(7, '葡萄', 4.7);
- 交叉连接:cross join (,)
- 内连接:(inner) join
- 外连接:left (outer) join、right (outer) join、union
MySQL join 语法官方文档:
MySQL 5.7 Reference Manual / ... / JOIN Clause
https://dev.mysql.com/doc/refman/5.7/en/join.html
13.1 连接条件关键词 (on、using)
| 执行顺序:
|
13.2 连接算法
| 参考文档: MySQL 连接查询超全详解
补充 left join | right join 连接算法,瞎编的伪代码,具体可以看官方文档: MySQL 5.7 Reference Manual / ... / Nested Join Optimization
注:MySQL 8.0 版本提供了 hash join 连接算法,其他版本仍是 nested loop join 连接算法,尽量少用 join,不同时连接三张表 |


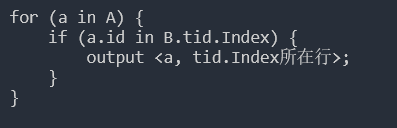

13.3 交叉连接 (cross join)
|
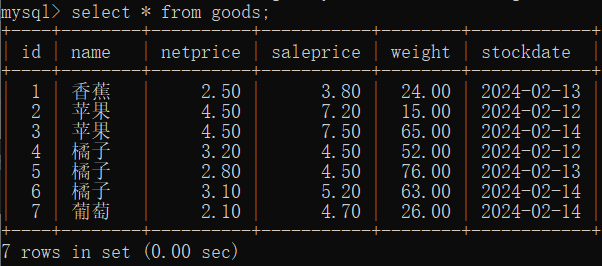

13.4 内连接 (inner join)
|

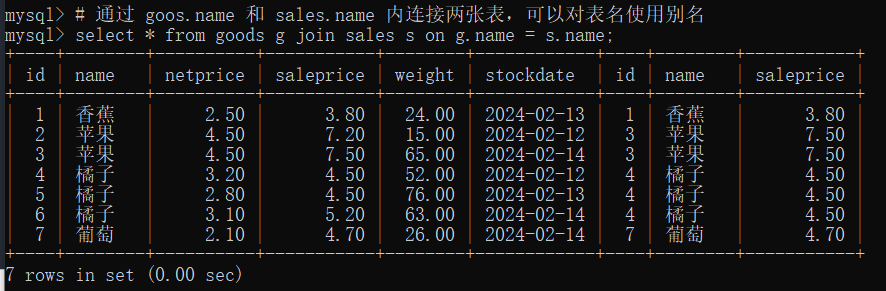
13.5 外连接 (left join、right join)
|




14 子查询
|
14.1 select 子查询 (只需了解)
|

14.2 from 子查询
|
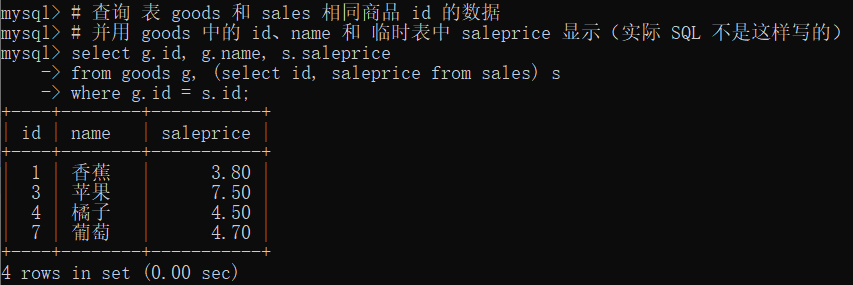
14.3 where 子查询
|

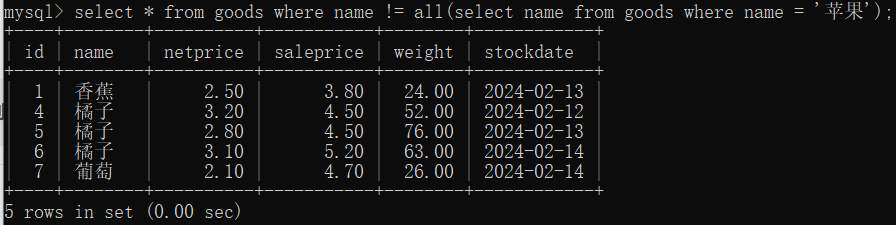
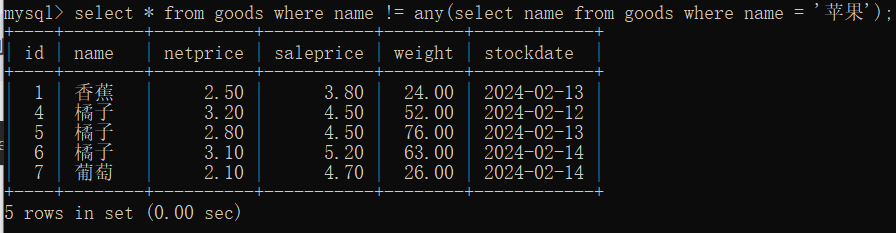

15 查询顺序总结
|
相关文章:
MySQL 基础知识(六)之数据查询(二)
目录 6 数值型函数 7 字符串函数 8 流程控制函数 9 聚合函数 10 分组查询 (group by) 11 分组过滤 (having) 12 限定查询 (limit) 13 多表查询 13.1 连接条件关键词 (on、using) 13.2 连接算法 13.3 交叉连接 (cross join) 13.4 内连接 (inner join) 13.5 外连接 …...
蓝桥杯嵌入式STM32G431RBT6知识点(主观题部分)
目录 1 前置准备 1.1 Keil 1.1.1 编译器版本及微库 1.1.2 添加官方提供的LCD及I2C文件 1.2 CubeMX 1.2.1 时钟树 1.2.2 其他 1.2.3 明确CubeMX路径,放置芯片包 2 GPIO 2.1 实验1:LED1-LED8循环亮灭 编辑 2.2 实验2:…...
ELAdmin 部署
后端部署 按需修改 application-prod.yml 例如验证码方式、登录状态到期时间等等。 修改完成后打好 Jar 包 执行完成后会生成最终可执行的 jar。JPA版本是 2.6,MyBatis 版本是 1.1。 启动命令 nohup java -jar eladmin-system-2.6.jar --spring.profiles.active…...
计算机功能简介:EC, NVMe, SCSI/ISCSI与块存储接口 RBD,NUMA
一 EC是指Embedded Controller 主要应用于移动计算机系统和嵌入式计算机系统中,为此类计算机提供系统管理功能。EC的主要功能是控制计算机主板上电时序、管理电池充电和放电,提供键盘矩阵接口、智能风扇接口、串口、GPIO、PS/2等常规IO功能,…...
linux上安装bluesky的步骤
1、设备上安装的操作系统如下: orangepiorangepi5b:~$ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 22.04.2 LTS Release: 22.04 Codename: jammy 2、在用户家目录下创建一个目录miniconda3目录&a…...
视频监控需求八问:视频智能分析/视频汇聚平台EasyCVR有何特性?
最近TSINGSEE青犀视频在与业内伙伴进行项目合作的过程中,针对安防监控可视化视频管理系统EasyCVR视频融合平台在电信运营商项目中的应用,进行了多方面的项目需求沟通。今天我们就该项目沟通为案例,来具体了解一下用户关心度较高的关于视频智能…...

django rest framework 学习笔记2
注意:该文章部分摘抄之百度,仅当做学习笔记供小白使用,若侵权请联系删除! 显示关联表的数据,本示例会显示所有的关联的数据信息 from rest_framework import serializers from .models import Student class StudentM…...

第四篇【传奇开心果系列】Python文本和语音相互转换库技术点案例示例:pyttsx3自动化脚本经典案例
传奇开心果短博文系列 系列短博文目录Python文本和语音相互转换库技术点案例示例系列 短博文目录前言一、雏形示例代码二、扩展思路介绍三、批量处理文本示例代码四、自定义语音设置示例代码五、结合其他库和API示例代码六、语音交互系统示例代码七、多语言支持示例代码八、添加…...
和model.eval()两种模式的原理)
model.train()和model.eval()两种模式的原理
1. model.train() 在使用 pytorch 构建神经网络的时候,训练过程中会在程序上方添加一句model.train(),作用是 启用 batch normalization 和 dropout 。 如果模型中有BN层(Batch Normalization)和 Dropout ,需要在 训练…...
)
docker的底层原理六: 联合文件系统(UnionFS)
Docker的底层存储原理基于联合文件系统(UnionFS)。 联合文件系统(UnionFS)是一种特殊的文件系统,它允许独立地叠加多个目录层,呈现给用户的是这些目录层的联合视图。这种结构使得在Docker中,不…...
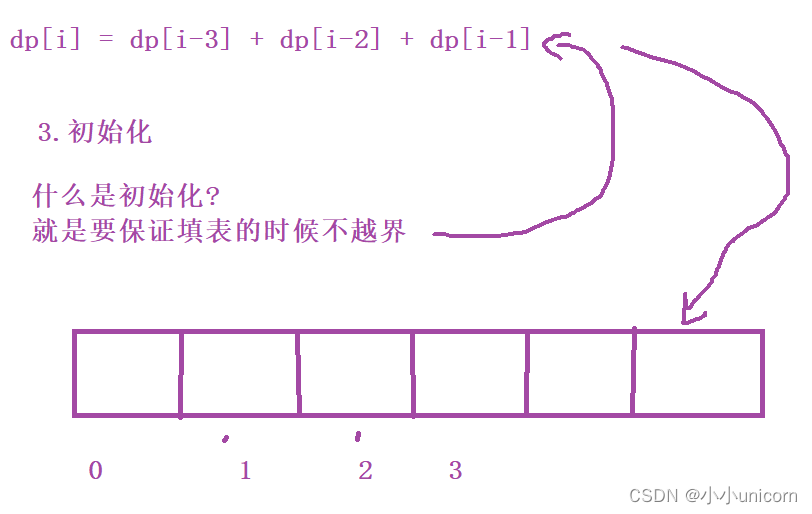
【动态规划专栏】专题一:斐波那契数列模型--------1.第N个泰波那契数
本专栏内容为:算法学习专栏,分为优选算法专栏,贪心算法专栏,动态规划专栏以及递归,搜索与回溯算法专栏四部分。 通过本专栏的深入学习,你可以了解并掌握算法。 💓博主csdn个人主页:小…...

自养号测评低成本高效率推广,安全可控
测评的作用在于让用户更真实、清晰、快捷地了解产品以及产品的使用方法和体验。通过买家对产品的测评,也可以帮助厂商和卖家优化产品缺陷,提高用户的使用体验。这进而帮助他们获得更好的销量,并更深入地了解市场需求。因此,测评在…...

ubuntu22.04@laptop OpenCV Get Started: 015_deep_learning_with_opencv_dnn_module
ubuntu22.04laptop OpenCV Get Started: 015_deep_learning_with_opencv_dnn_module 1. 源由2. 应用Demo2.1 C应用Demo2.2 Python应用Demo 3. 使用 OpenCV DNN 模块进行图像分类3.1 导入模块并加载类名文本文件3.2 从磁盘加载预训练 DenseNet121 模型3.3 读取图像并准备为模型输…...
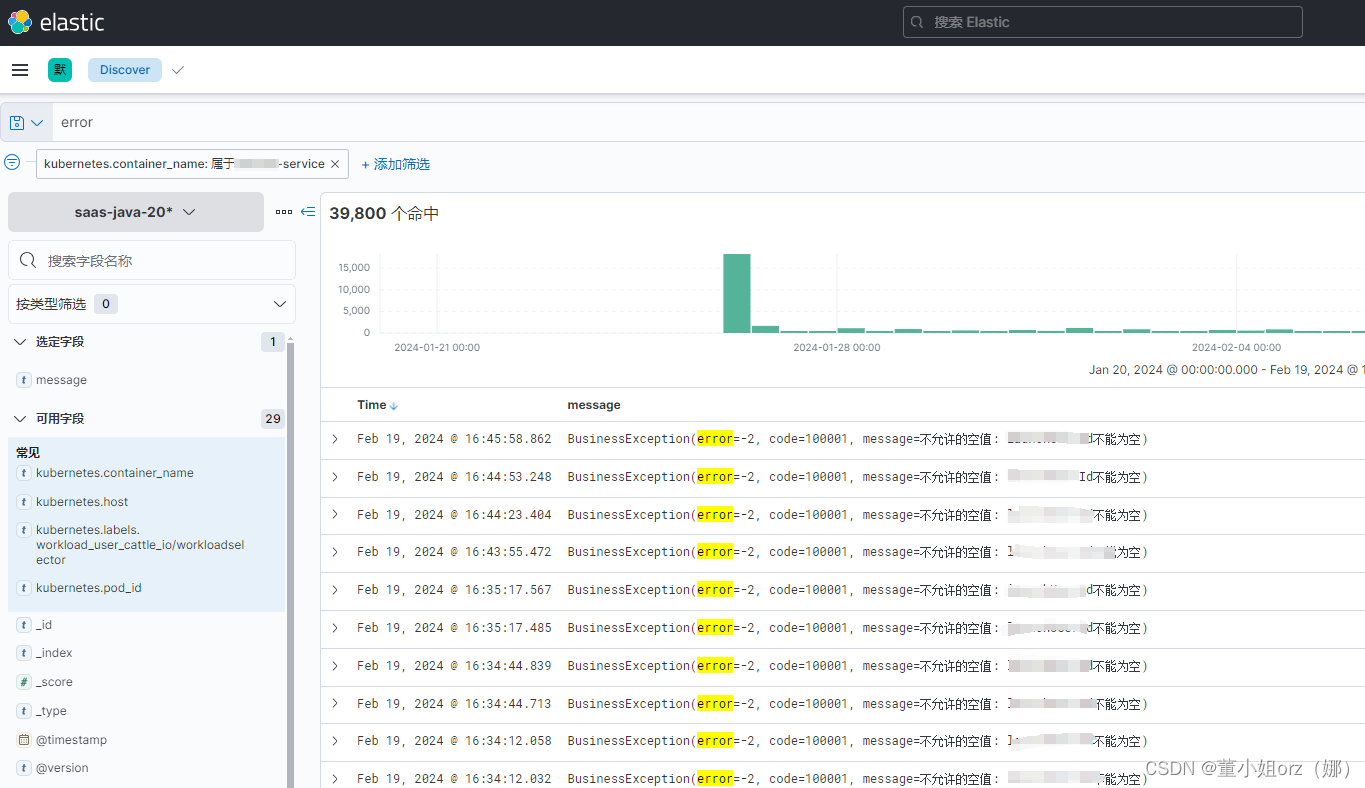
【elk查日志 elastic(kibana)】
文章目录 概要具体的使用方式一:查找接口调用历史二:查找自己的打印日志三:查找错误日志 概要 每次查日志,我都需要别人帮我,时间长了总觉得不好意思,所以这次下定决心好好的梳理一下,怎么查日…...
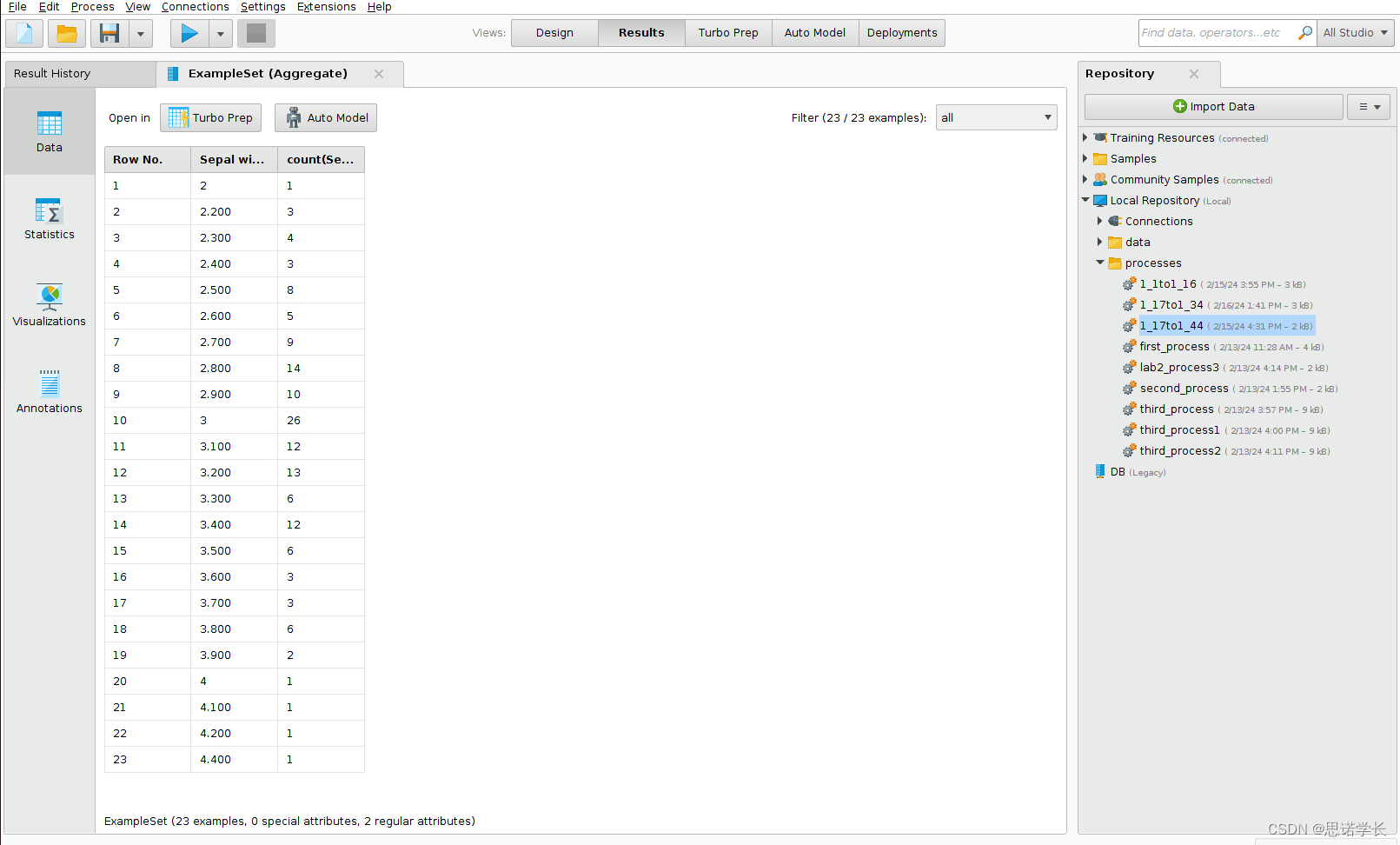
RapidMiner数据挖掘2 —— 初识RapidMiner
本节由一系列练习与问题组成,这些练习与问题有助于理解多个基本概念。它侧重于各种特定步骤,以进行直接的探索性数据分析。因此,其主要目标是测试一些检查初步数据特征的方法。大多数练习都是关于图表技术,通常用于数据挖掘。 为此…...

基于STM32的光照检测系统设计
基于STM32的光照检测系统设计 摘要: 随着物联网和智能家居的快速发展,光照检测系统在智能环境控制中扮演着越来越重要的角色。本文设计了一种基于STM32的光照检测系统,该系统能够实时检测环境光强度,并根据光强度调节照明设备,实现智能照明控制。本文首先介绍了系统的总体…...
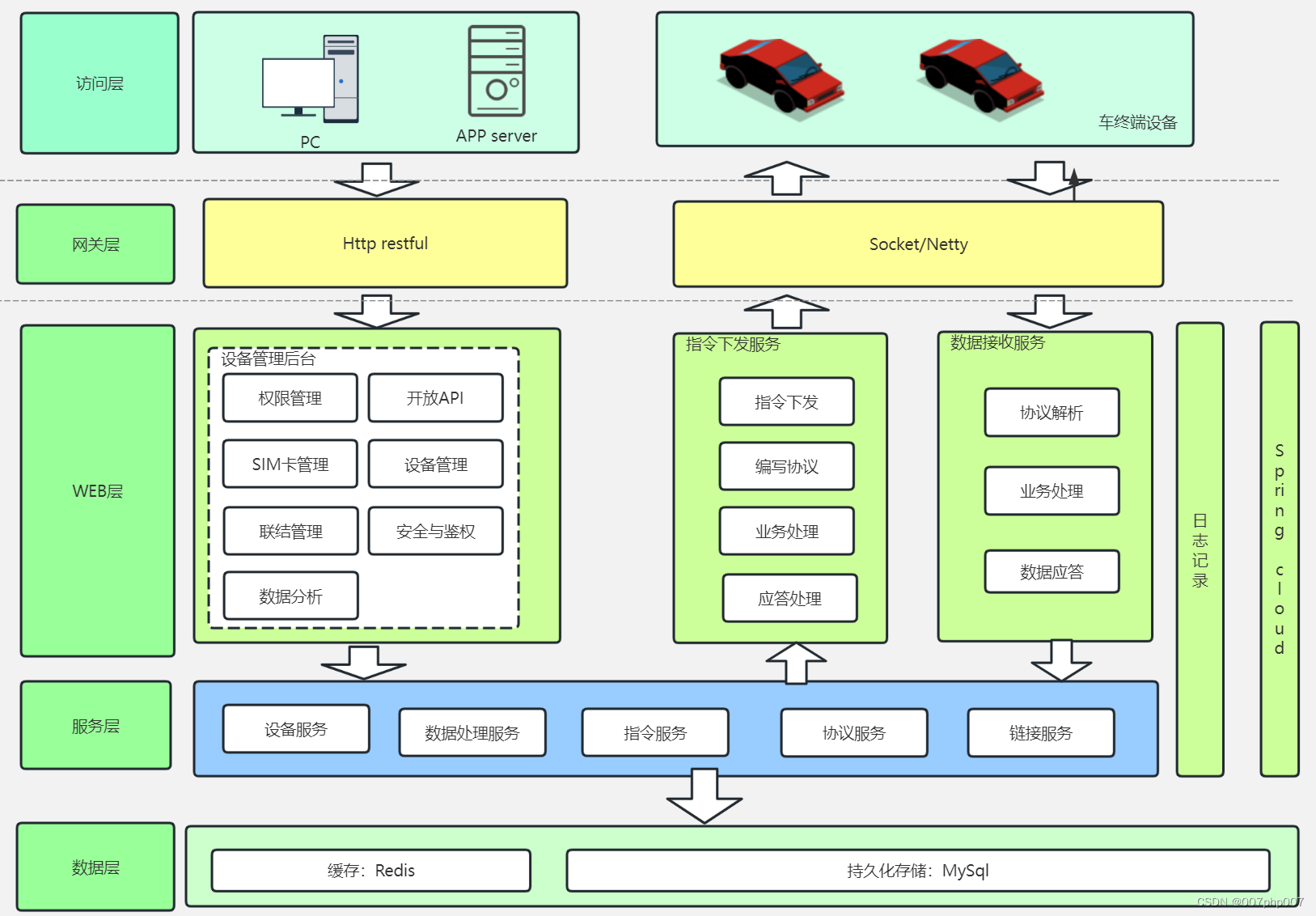
车辆管理系统设计与实践
车辆管理系统是针对车辆信息、行驶记录、维护保养等进行全面管理的系统。本文将介绍车辆管理系统的设计原则、技术架构以及实践经验,帮助读者了解如何构建一个高效、稳定的车辆管理系统。 1. 系统设计原则 在设计车辆管理系统时,需要遵循以下设计原则&…...
板块一 Servlet编程:第四节 HttpServletResponse对象全解与重定向 来自【汤米尼克的JAVAEE全套教程专栏】
板块一 Servlet编程:第四节 HttpServletResponse对象全解与重定向 一、什么是HttpServletResponse二、响应数据的常用方法三、响应乱码问题字符流乱码字节流乱码 四、重定向:sendRedirect请求转发和重定向的区别 在上一节中,我们系统的学习了…...

漫谈:C/C++ char 和 unsigned char 的用途
C/C的字符默认是有符号的,这一点非常的不爽,因为很少有人用单字节表达有符号数,毕竟,ASCII码是无符号的,对字符的绝大多数处理都是基于无符号的。 这一点在其它编程语言上就好很多,基本上都提供了byte这种类…...

安全保护制度
安全保护制度 第九条 计算机信息系统实行安全等级保护。安全等级的划分标准和安全等级保护的具体办法,由公安部会同有关部门制定。 第十条 计算机机房应当符合国家标准和国家有关规定。 在计算机机房附近施工,不得危害计算机信息系统的安全。 第十一条 进行国际联网的计算…...

跨境社媒运营真正难的 不是内容不够而是账号越来越没有“主线感”
很多团队做跨境社媒时,前期最容易把注意力放在内容数量上。 今天发没发,明天补几条,哪个平台还没铺,哪种形式最近更容易起量。 这些当然重要,因为账号在起步阶段,首先得先“动起来”。但真正做一段时间之后…...

Dark Reader终极指南:轻松为任何网站开启完美深色模式
Dark Reader终极指南:轻松为任何网站开启完美深色模式 【免费下载链接】darkreader Dark Reader Chrome and Firefox extension 项目地址: https://gitcode.com/gh_mirrors/da/darkreader Dark Reader是一款广受欢迎的浏览器扩展,它能智能分析网页…...

《信息学奥赛一本通 编程启蒙C++版》适合小学生学习吗
适合小学生学习,尤其适合小学低年级作为C启蒙入门使用,可以按照以下方式安排阅读学习: 一、适配性说明 这本书是专门针对低龄学习者设计的C编程启蒙内容,整体难度较低、循序渐进: 1、对于小学1-4年级的孩子&#x…...

Godot RE Tools深度解析:游戏逆向工程的全栈解决方案
Godot RE Tools深度解析:游戏逆向工程的全栈解决方案 【免费下载链接】gdsdecomp Godot reverse engineering tools 项目地址: https://gitcode.com/GitHub_Trending/gd/gdsdecomp 在游戏开发与逆向工程领域,Godot引擎的二进制资源格式一直是一个…...

Hermes Agent 自定义供应商配置指向 Taotoken 的步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 自定义供应商配置指向 Taotoken 的步骤 对于使用 Hermes Agent 进行 AI 应用开发的团队而言,统一管理模型…...

轨迹在线识别导向的3D折线焊缝机器人摆动GMAW实时跟踪系统【附程序】
✨ 长期致力于3D折线焊缝、机器人、GMAW、轨迹在线识别、焊缝跟踪研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于激光位移传感与密度聚类点云在线…...

新唐NuEzAI-M55M1开发板:基于Cortex-M55与Ethos-U55的终端AI部署实战
1. 项目概述:当AI遇见微控制器,一场边缘计算的“瘦身革命” 最近,新唐科技(Nuvoton)发布了一款名为NuEzAI-M55M1的开发板,在嵌入式圈子和AI应用开发者中激起了不小的水花。这玩意儿乍一看,又是一…...

2022年AI工程实战指南:从H100到Chinchilla的十大关键技术落地
1. 这不是一份“新闻简报”,而是一份2022年4月AI技术演进的实操解剖报告 如果你在2022年春天打开过任何一家AI实验室的内部通讯、技术周会纪要,或者翻过几篇刚上线的arXiv论文,你大概率会看到一连串让人头皮发麻的名词:H100、PaLM…...

Monocle投票系统实现原理:构建高效的帖子排名算法
Monocle投票系统实现原理:构建高效的帖子排名算法 【免费下载链接】monocle Link and news sharing 项目地址: https://gitcode.com/gh_mirrors/mon/monocle Monocle是一个功能强大的链接和新闻聚合平台,其核心功能之一就是智能投票排名系统。这篇…...

Unity碰撞器性能优化:从幽灵Collider到物理契约治理
1. 为什么一个“看不见”的碰撞器,能让60帧的游戏掉到20帧?在Unity项目上线前的性能压测阶段,我接手过一个看似普通的横版跳跃游戏——美术资源干净,逻辑简单,主角只有3个动画状态,连粒子特效都控制在5个以…...