CentOS7安装InfluxDB2简易教程
InfluxDB是一个开源的时间序列数据库,它专门用于处理大规模的时间序列数据。时间序列数据是在特定时间点上收集的数据,例如传感器数据、监控数据、应用程序日志等。
InfluxDB设计用于高效地存储、查询和分析大量的时间序列数据。它具有高性能、可扩展性和灵活性的特点。它支持快速的写入和读取操作,并提供强大的时间序列数据查询功能。
InfluxDB提供了一种灵活的数据模型,可以轻松地存储和查询不同种类的时间序列数据。它支持标签(tags)和字段(fields)的概念,用于对时间序列数据进行标识和分类。标签可以用于快速筛选和聚合数据,而字段则用于存储实际的测量值。
InfluxDB还提供了一套丰富的API和工具,用于数据的导入、导出和可视化。它与许多常见的数据处理和可视化工具(如Grafana)集成良好,方便用户使用。
总之,InfluxDB是一个用于存储和查询时间序列数据的强大工具,适用于各种应用场景,包括监控、物联网、日志分析等。
InfluxDB和InfluxDB2是两个不同版本的时序数据库,它们有以下区别:
-
数据存储结构:InfluxDB1采用的是基于TSM(The Storage Machine)的存储引擎,而InfluxDB2则采用了新的存储引擎,称为InfluxDB IOx。InfluxDB IOx引擎支持更高的写入和查询性能,以及更高的数据压缩比。
-
数据模型:InfluxDB1采用的是tag和field的模型,tag用于标识数据的维度,field用于存储数据的值。而InfluxDB2引入了新的概念,如bucket、measurement和tag。Bucket类似于数据库的概念,Measurement类似于表,Tag和Field的概念与InfluxDB1相同。
-
查询语言:InfluxDB1使用的查询语言是InfluxQL,而InfluxDB2引入了新的查询语言,称为Flux。Flux具有更强大和灵活的查询功能,支持更复杂的数据操作和分析。
-
可扩展性:InfluxDB2在可扩展性方面进行了改进,支持更大规模的数据集和更多的并发查询。它使用了分布式计算模型,可以水平扩展,提高系统的性能和容错性。
综上所述,InfluxDB2相对于InfluxDB1具有更好的性能、更灵活的数据模型和查询语言,更适合处理大规模的时序数据,下面我们来介绍下载并安装最新版本的InfluxDB2。
一、下载安装InfluxDB2
- 下载InfluxDB2安装包 https://github.com/influxdata/influxdb/releases ,这里选择rpm安装包 influxdb2-2.7.3-1.x86_64.rpm ,可以直接在服务器执行 :
wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.7.3-1.x86_64.rpm

2. 在服务器,切换到influxdb2-2.7.3-1.x86_64.rpm文件所在目录,执行安装命令
yum localinstall -y ./influxdb2-2.7.3-1.x86_64.rpm
执行结果如下,Complete!表示安装成功。
Loaded plugins: fastestmirror
Examining ./influxdb2-2.7.3-1.x86_64.rpm: influxdb2-2.7.3-1.x86_64
Marking ./influxdb2-2.7.3-1.x86_64.rpm to be installed
Resolving Dependencies
--> Running transaction check
---> Package influxdb2.x86_64 0:2.7.3-1 will be installed
--> Finished Dependency ResolutionDependencies Resolved=================================================================================================================================================================================================================================================Package Arch Version Repository Size
=================================================================================================================================================================================================================================================
Installing:influxdb2 x86_64 2.7.3-1 /influxdb2-2.7.3-1.x86_64 99 MTransaction Summary
=================================================================================================================================================================================================================================================
Install 1 PackageTotal size: 99 M
Installed size: 99 M
Downloading packages:
Running transaction check
Running transaction test
Transaction test succeeded
Running transactionInstalling : influxdb2-2.7.3-1.x86_64 1/1
Created symlink from /etc/systemd/system/influxd.service to /usr/lib/systemd/system/influxdb.service.
Created symlink from /etc/systemd/system/multi-user.target.wants/influxdb.service to /usr/lib/systemd/system/influxdb.service.Verifying : influxdb2-2.7.3-1.x86_64 1/1 Installed:influxdb2.x86_64 0:2.7.3-1 Complete!
- 启动influxdb服务
sudo systemctl start influxdb
- 查看influxdb服务启动状态,结果显示Active: active (running)表示正在运行,服务启动成功。
sudo systemctl status influxdb

- 设置开机启动
sudo systemctl enable influxdb
- 停止influxdb服务
sudo systemctl stop influxdb
二、配置InfluxDB2
第一步我们安装并启动好Influxdb数据库之后,接下来就是配置数据库,默认是没有用户名密码的,我们可以通过配置界面进行初始化配置。
- 访问InfluxDB2管理界面,ip:8086 ,将会出现以下界面:

- 点击 GET STARTED按钮进入到用户配置界面,填写用户名/密码,Organization Name(工作区组织名称),填写Bucket Name,Bucket相当于Mysql数据库的库名。

- 点击 CONTINUE按钮之后会出现一个api token记住这个token,在api调用时需要用到。

- 点击 QUICK START 按钮,就可以进入到Influxdb后台管理界面了。

请注意,InfluxDB2的高可用集群功能是收费的。在InfluxDB1中,可以借助使用influxdb-proxy的功能来实现集群及负载均衡。
InfluxDB Proxy 是一个用于 InfluxDB 的代理服务器,它能够处理代理读写请求,并将请求转发到 InfluxDB 服务器。
InfluxDB Proxy 提供了以下功能:
-
负载均衡:能够将读写请求分发到多个 InfluxDB 服务器上,实现负载均衡,提高系统的容错性和性能。
-
缓存:能够缓存查询结果,减轻 InfluxDB 服务器的负载,并提高查询性能。
-
查询优化:能够对查询进行优化,例如聚合、剪裁和压缩数据,提供更高效的查询结果。
-
安全性:提供用户身份验证和授权功能,确保只有经过授权的用户才能访问 InfluxDB 服务器。
总之,InfluxDB Proxy 是一个非常有用的工具,可以提高 InfluxDB 的性能和可用性,并提供额外的安全和查询优化功能。
相关文章:
CentOS7安装InfluxDB2简易教程
InfluxDB是一个开源的时间序列数据库,它专门用于处理大规模的时间序列数据。时间序列数据是在特定时间点上收集的数据,例如传感器数据、监控数据、应用程序日志等。 InfluxDB设计用于高效地存储、查询和分析大量的时间序列数据。它具有高性能、可扩展性和…...

数据库:信息存储与管理的关键
数据库:信息存储与管理的关键 数据库是现代信息系统中不可或缺的组成部分,它承担着存储、管理和检索数据的重要任务。本文将详细介绍数据库的定义、分类、作用以及特点。 1. 数据库的介绍 数据库是一个有组织的数据集合,用于存储和管理大量…...

极智芯 | 解读NVIDIA RTX5090 又是一波被禁售的节奏
欢迎关注我的公众号「极智视界」,获取我的更多技术分享 大家好,我是极智视界,本文分享一下 解读NVIDIA RTX5090 又是一波被禁售的节奏。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码和资源下载,链接:https://t.zsxq.com/0aiNxERDq 按 NVIDIA GPU …...

rtt的io设备框架面向对象学习-硬件rtc设备
目录 1.硬件rtc设备基类2.硬件rtc设备基类的子类3.初始化/构造流程3.1设备驱动层3.2 设备驱动框架层3.3 设备io管理层 4.总结5.使用 硬件rtc和软件rtc设备是互斥的。因为它们的名字都叫"rtc",在对象容器中不允许重名。 1.硬件rtc设备基类 此层处于设备驱…...
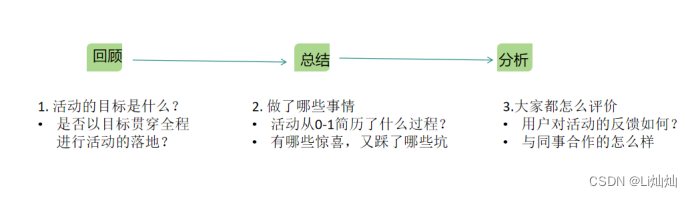
产品经理学习-产品运营《流程管理》
如何进行流程管理 信息可视化 甘特图-流程管理思维导图-方案讨论原型图-活动文档 明确责任制 分工明确,关键环境有主负责人通过时间倒推督促管理 沟通技巧 明确共同利益以结果激励做好信息同步 如何进行监控活动效果 监控活动的效果是要监控数据 活动每个环境的…...

压缩感知——革新数据采集的科学魔法
引言: 在数字时代,数据以及数据的收集和处理无处不在。压缩感知(Compressed Sensing, CS)是一种新兴的数学框架,它挑战了我们传统上对数据采集和压缩的看法,给医学图像、天文观测、环境监测等领域带来了颠覆性的影响。但到底什么…...
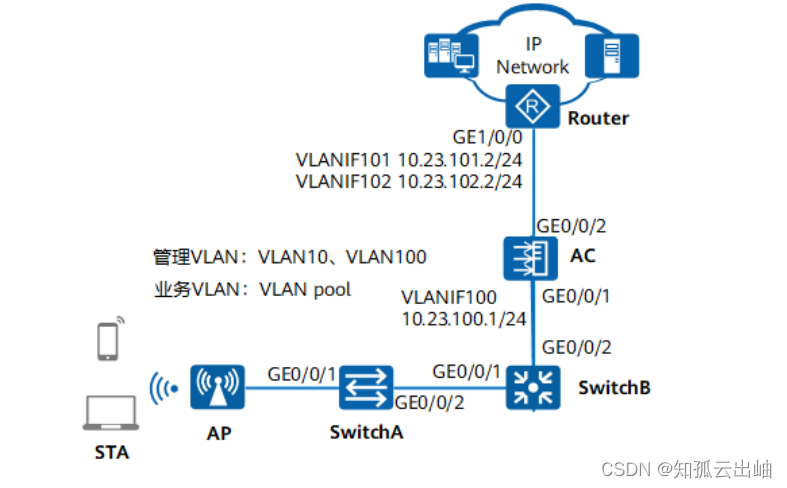
华为配置直连三层组网直接转发示例
华为配置直连三层组网直接转发示例 组网图形 图1 配置直连三层组网直接转发示例组网图 业务需求组网需求数据规划配置思路配置注意事项操作步骤配置文件扩展阅读 业务需求 企业用户接入WLAN网络,以满足移动办公的最基本需求。且在覆盖区域内移动发生漫游时ÿ…...
:TC275如何通过EB-Tresos配置实现硬件触发ADC同步采样(电机控制器三相电流同步采样))
MCAL知识点(二十八):TC275如何通过EB-Tresos配置实现硬件触发ADC同步采样(电机控制器三相电流同步采样)
目录 1、概述 2、实现目标 3、EB-Tresos配置 3.1、AdcGeneral 3.2、AdcGlobInputClass 3.3、AdcHwUnit_X...

proteus8.15图文安装教程
proteus8.15版本可以用STM32系列单片机来进行仿真设计,比7.8版本方便多了,有需要的朋友们可以在公众号后台回复 proteus8.15 获取软件包。 1、下载好软件包,解压如下,右键proteus8.15.sp1以管理员身份运行。 2、第一次安装&#x…...

ACP科普:敏捷开发之kanban
Q1: Kanban是什么? A1:敏捷开发中的Kanban是一种项目管理方法,其核心理念是通过可视化管理来提高生产效率和任务交付速度。Kanban来自日本,意为“看板”,最初是由丰田汽车公司引入生产线上的生产控制系统,后来被引入到…...
)
代理模式(Proxy模式)
所谓的代理,就是一个人或者一个机构代替另一个人或者另一个机构去做一些事情(类似于中介或者代理商)。 代理的种类 远程代理:为一个位于不同的地址空间的对象提供一个局域代表对象。 虚拟代理:根据需要创建一个资源消…...

Android使用shape定义带渐变色的背景
在drawable目录下创建文件bg_gradient.xml 文件内的内容如下: <?xml version"1.0" encoding"utf-8"?> <shape android:shape"rectangle" xmlns:android"http://schemas.android.com/apk/res/android"> <…...

轻松搞定Makefile
编译:将源文件(.cpp)编译生成目标文件(.o) gcc -c main.cpp -o main.o 链接:将目标文件(.o)生成可执行文件 gcc main.o -o main 合并: gcc main.cpp -o main -lstdc -I 指定头文件目录 -L 指定库文件依赖路径 -l 指明库文件名 查看版本 m…...

【C++之类和对象篇002】
C学习笔记---005 C知识类和对象篇1、类的6个默认成员函数2、构造函数2.1、构造函数的特性2.2、内置类型和自定义类型2.3、什么是默认构造函数? 3、析构函数3.1、什么是析构函数?3.2、析构函数的特性3.3、析构函数的释放顺序 4、拷贝构造函数4.1、什么是拷…...

k8s学习(RKE+k8s+rancher2.x)成长系列之简配版环境搭建(三)
3.19.切换RKE用户,并做免密登录(三台机器相互免密) su rke cd~ ssh-keygen[rkemaster.ssh]$ssh-copy-id rkeslaver2 [rkemaster.ssh]$ssh-copy-id rkeslaver1 [rkemaster.ssh]$ssh-copy-id rkemaster3.20.搭建RKE集群 为了方便理解&#…...

基于SSM的疫情期间学生信息管理平台的设计与实现(有报告)。Javaee项目。ssm项目。
演示视频: 基于SSM的疫情期间学生信息管理平台的设计与实现(有报告)。Javaee项目。ssm项目。 项目介绍: 采用M(model)V(view)C(controller)三层体系结构&…...

LeetCode_20_简单_有效的括号
文章目录 1. 题目2. 思路及代码实现(Python)2.1 栈 1. 题目 给定一个只包括 (,),{,},[,] 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型…...
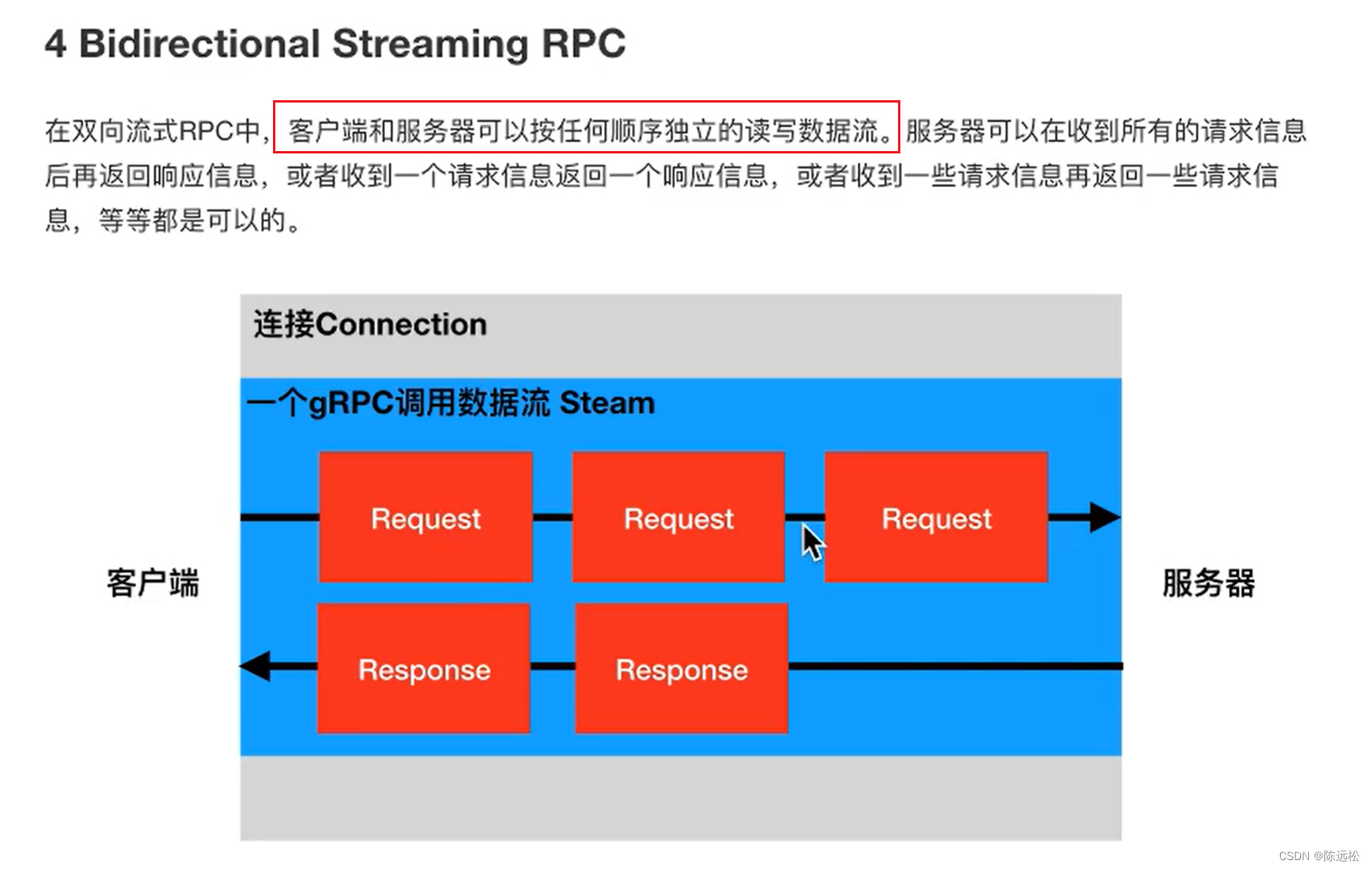
gRPC 备查
简介 HTTP/2 HTTP/2 的三个概念 架构 使用流程 gRPC 的接口类型 1.单一RPC 2.服务器流式RPC 3.客户端式流式RPC 4.双向流式RPC...
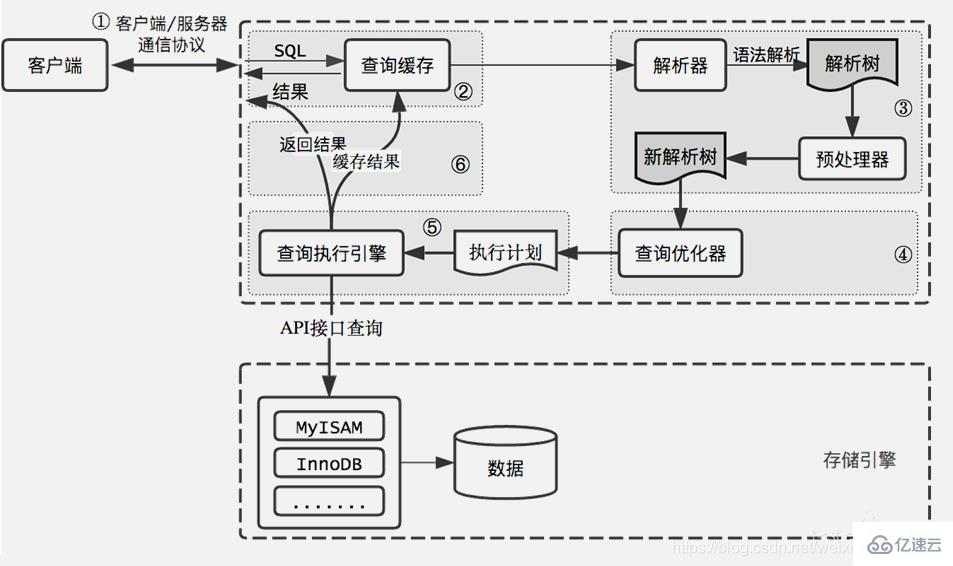
MySQL 基础知识(十)之 MySQL 架构
目录 1 MySQL 架构说明 2 连接层 3 核心业务层 3.1 查询缓存 3.2 解析器 3.3 优化器 3.4 执行器 4 存储引擎层 5 参考文档 1 MySQL 架构说明 下图是 MySQL 5.7 及其之前版本的逻辑架构示意图 MySQL 架构大致可分为以下三层: 连接层:负责跟客户…...

[晓理紫]每日论文分享(有中文摘要,源码或项目地址)--大模型、扩散模型
专属领域论文订阅 VX关注{晓理紫},每日更新论文,如感兴趣,请转发给有需要的同学,谢谢支持 如果你感觉对你有所帮助,请关注我,每日准时为你推送最新论文。 为了答谢各位网友的支持,从今日起免费为300名读者提供订阅主题论文服务,只需VX关注公号并回复{邮箱+论文主题}(如…...

为什么你的AI搜索总不准?2026年5款高精度免费工具底层架构拆解:向量引擎、重排序模块与Query理解差异全曝光
更多请点击: https://intelliparadigm.com 第一章:为什么你的AI搜索总不准?——2026年免费高精度AI搜索工具全景洞察 AI搜索不准,根源常被误判为“模型不够大”,实则多源于查询理解失焦、上下文截断、知识新鲜度缺失与…...

甲言Jiayan:5分钟掌握古汉语NLP终极解决方案
甲言Jiayan:5分钟掌握古汉语NLP终极解决方案 【免费下载链接】Jiayan 甲言,专注于古代汉语(古汉语/古文/文言文/文言)处理的NLP工具包,支持文言词库构建、分词、词性标注、断句和标点。Jiayan, the 1st NLP toolkit designed for Classical C…...

Python简单算法题
1.字符串中的第一个唯一字符def first_uniq_char(s: str) -> int:from collections import Countercount Counter(s)for i, ch in enumerate(s):if count[ch] 1:return ireturn -12. 合并两个有序数组(双指针,in-place)题目:…...

AI开始替人跑任务后,真正决定体验的不是模型,而是向量引擎
AI开始替人跑任务后,真正决定体验的不是模型,而是向量引擎为什么这篇文章值得你现在看 过去一年,很多人聊AI,张口就是哪个模型更强。 有人追Gemini 3.5 Flash。 有人追Qwen新模型。 有人追OpenAI的Responses API和Agent工具链。 也…...

别再死记硬背了!用Multisim仿真软件,5分钟搞懂三极管放大电路的静态工作点设置与失真分析
用Multisim玩转三极管放大电路:静态工作点设置与失真分析实战指南 刚接触模拟电路时,三极管放大电路就像一道难以逾越的门槛。那些密密麻麻的公式、抽象的特性曲线,让多少电子工程专业的学生在深夜实验室里抓耳挠腮。但今天,我要告…...

BilibiliDown:简单三步掌握B站视频下载的终极指南
BilibiliDown:简单三步掌握B站视频下载的终极指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bi…...

JetBrains IDE试用重置终极指南:如何快速解决开发工具到期问题
JetBrains IDE试用重置终极指南:如何快速解决开发工具到期问题 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 还在为IntelliJ IDEA、PyCharm等JetBrains IDE试用期到期而烦恼吗?当你的开发…...

CAP 与 BASE:分布式系统取舍原则
CAP 和 BASE 不是为了背概念,而是为了指导分布式系统在网络异常、数据同步和服务可用之间怎么取舍。尤其是分布式事务,最终都绕不开强一致和最终一致的选择。 一句话概括:分布式系统里 P 几乎无法避免,所以真正的取舍通常发生在 C…...
)
SEED-Lab7 XSS攻击实验(Elgg)
SEED-Lab7 XSS攻击实验(Elgg) 文章目录 SEED-Lab7 XSS攻击实验(Elgg)文章目录实验环境实验内容实验步骤DNS SetupTask 1: Posting a Malicious Message to Display an Alert WindowTask 2: Posting a Malicious Message to Display CookiesTask 3: Stealing Cookies from the…...

如何在macOS上轻松运行Windows应用:Whisky终极使用指南
如何在macOS上轻松运行Windows应用:Whisky终极使用指南 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想在Apple Silicon Mac上运行Windows软件,又不想安装笨…...