【Langchain】+ 【baichuan】实现领域知识库【RAG】问答系统
本项目使用Langchain 和 baichuan 大模型, 结合领域百科词条数据(用xlsx保存),简单地实现了领域百科问答实现。
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from langchain_community.embeddings import OpenAIEmbeddings, SentenceTransformerEmbeddings
from langchain_community.vectorstores import Chroma, FAISS
from langchain_community.llms import OpenAI, Baichuan
from langchain_community.chat_models import ChatOpenAI, ChatBaichuan
from langchain.memory import ConversationBufferWindowMemory
from langchain.chains import ConversationalRetrievalChain, RetrievalQA
#import langchain_community import chat_models
#print(chat_models.__all__)import streamlit as st
import pandas as pd
import os
import warnings
import time
warnings.filterwarnings('ignore')# 对存储了领域百科词条的xlsx文件进行解析
def get_xlsx_text(xlsx_file):df = pd.read_excel(xlsx_file, engine='openpyxl')text = ""for index, row in df.iterrows():text += row['title'].replace('\n', '')text += row['content'].replace('\n', '')text += '\n\n'return text# Splits a given text into smaller chunks based on specified conditions
def get_text_chunks(text):text_splitter = RecursiveCharacterTextSplitter(separators="\n\n",chunk_size=1000,chunk_overlap=200,length_function=len)chunks = text_splitter.split_text(text)return chunks# 对切分的文本块构建编码向量并存储到FASISS
# Generates embeddings for given text chunks and creates a vector store using FAISS
def get_vectorstore(text_chunks):# embeddings = OpenAIEmbeddings() #有经济条件的可以使用 opanaiembendingembeddings = SentenceTransformerEmbeddings(model_name='all-MiniLM-L6-v2')vectorstore = FAISS.from_texts(texts=text_chunks, embedding=embeddings)return vectorstore
# Initializes a conversation chain with a given vector store# 对切分的文本块构建编码向量并存储到Chroma
# Generates embeddings for given text chunks and creates a vector store using Chroma
def get_vectorstore_chroma(text_chunks):# embeddings = OpenAIEmbeddings()embeddings = SentenceTransformerEmbeddings(model_name='all-MiniLM-L6-v2')vectorstore = Chroma.from_texts(texts=text_chunks, embedding=embeddings)return vectorstoredef get_conversation_chain_baichuan(vectorstore):memory = ConversationBufferWindowMemory(memory_key='chat_history', return_message=True) # 设置记忆存储器conversation_chain = ConversationalRetrievalChain.from_llm(llm=Baichuan(temperature=temperature_input, model_name=model_select),retriever=vectorstore.as_retriever(),get_chat_history=lambda h: h,memory=memory)return conversation_chainos.environ["http_proxy"] = "http://127.0.0.1:7890"
os.environ["https_proxy"] = "http://127.0.0.1:7890"# langchain 可以通过设置环境变量来设置参数
os.environ['BAICHUAN_API_KEY'] = 'sk-88888888888888888888888888888888'
temperature_input = 0.7
model_select = 'Baichuan2-Turbo-192K'
raw_text = get_xlsx_text('领域文件/twiki百科问答.xlsx')text_chunks = get_text_chunks(raw_text)
vectorstore = get_vectorstore_chroma(text_chunks)
# Create conversation chain
qa = get_conversation_chain_baichuan(vectorstore)
questions = ["什么是森林经营项目?","风电项目开发过程中需要的主要资料?","什么是ESG"
]
for question in questions:result = qa(question)print(f"**Question**: {question} \n")print(f"**Answer__**: {result['answer']} \n")
相关文章:

【Langchain】+ 【baichuan】实现领域知识库【RAG】问答系统
本项目使用Langchain 和 baichuan 大模型, 结合领域百科词条数据(用xlsx保存),简单地实现了领域百科问答实现。 from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter from langchain_co…...

Anaconda、conda、pip、virtualenv的区别
① Anaconda Anaconda是一个包含180的科学包及其依赖项的发行版本。其包含的科学包包括:conda, numpy, scipy, ipython notebook等。 Anaconda具有如下特点: ▪ 开源 ▪ 安装过程简单 ▪ 高性能使用Python和R语言 ▪ 免费的社区支持 其特点的实现…...
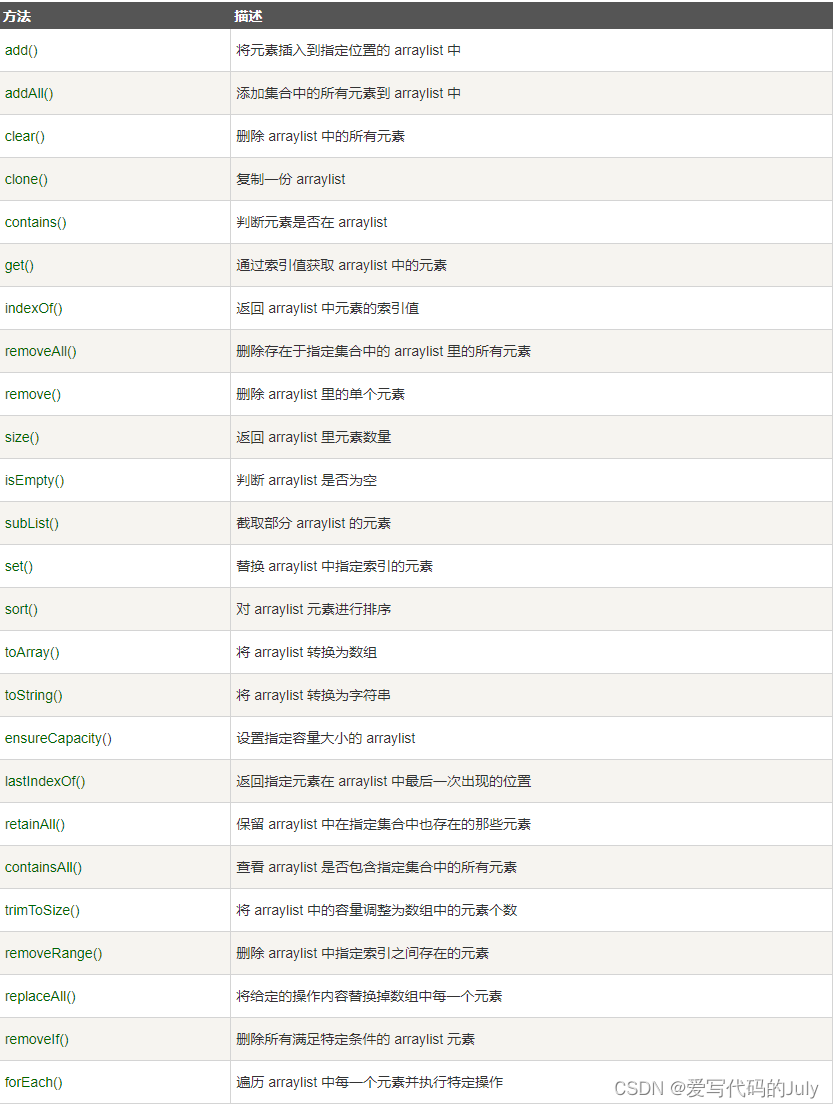
【数据结构】每天五分钟,快速入门数据结构(一)——数组
目录 一.初始化语法 二.特点 三.数组中的元素默认值 四.时间复杂度 五.Java中的ArrayList类 可变长度数组 1 使用 2 注意事项 3 实现原理 4 ArrayList源码 5 ArrayList方法 一.初始化语法 // 数组动态初始化(先定义数组,指定数组长度…...
NBlog个人博客部署维护过程记录 -- 后端springboot + 前端vue
项目是fork的Naccl大佬NBlog项目,页面做的相当漂亮,所以选择了这个。可以参考2.3的效果图 惭愧,工作两年了也没个自己的博客系统,趁着过年时间,开始搭建一下. NBlog原项目的github链接:Naccl/NBlog: &#…...
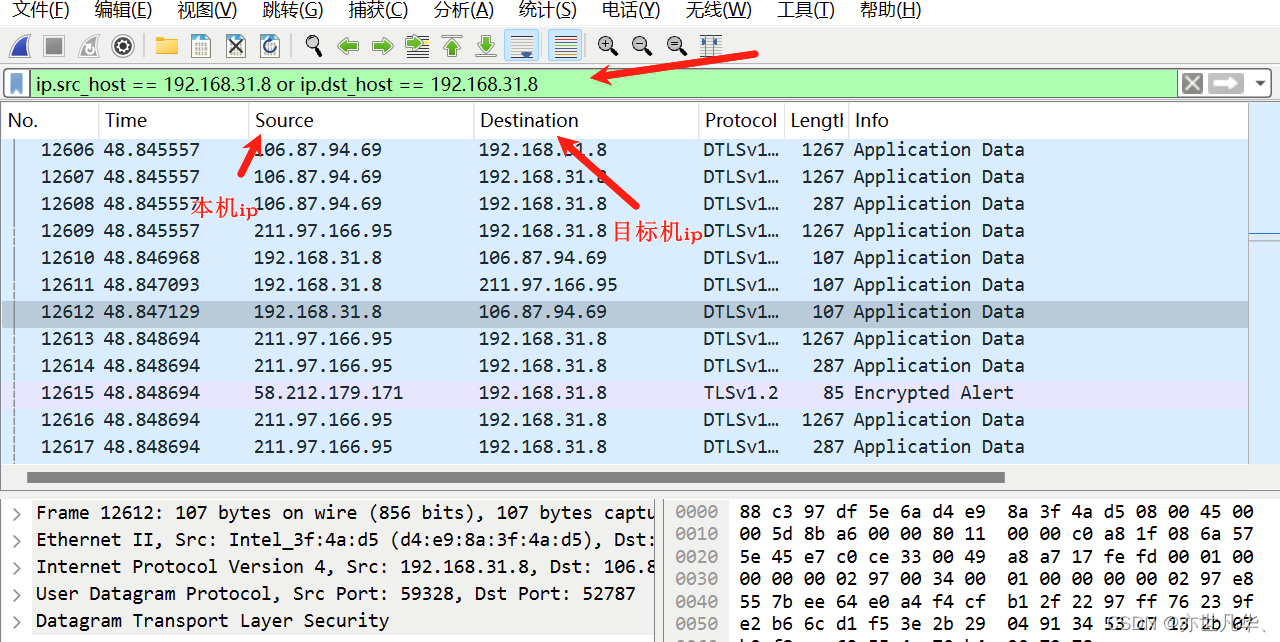
WireShark 安装指南:详细安装步骤和使用技巧
Wireshark是一个开源的网络协议分析工具,它能够捕获和分析网络数据包,并以用户友好的方式呈现这些数据包的内容。Wireshark 被广泛应用于网络故障排查、安全审计、教育及软件开发等领域。接下将讲解Wireshark的安装与简单使用。 目录 Wireshark安装步骤…...
:深入解析与实战应用)
PyTorch detach():深入解析与实战应用
PyTorch detach():深入解析与实战应用 🌵文章目录🌵 🌳引言🌳🌳一、计算图与梯度传播🌳🌳二、detach()函数的作用🌳🌳三、detach()与requires_graddz…...

uniapp 开发一个密码管理app
密码管理app 介绍 最近发现自己的账号密码真的是太多了,各种网站,系统,公司内网的,很多站点在登陆的时候都要重新设置密码或者通过短信或者邮箱重新设置密码,真的很麻烦 所以准备开发一个app用来记录这些站好和密码…...
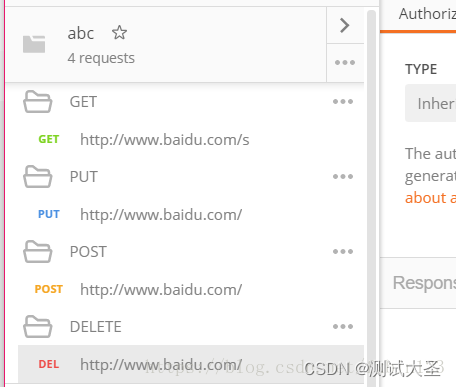
Postman详细攻略
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、Postman背景介绍 用户在开发或者调试网络程序或者是网页B/S模式的程序的时候是需要一些方法…...
如何在本地服务器部署TeslaMate并远程查看特斯拉汽车数据无需公网ip
文章目录 1. Docker部署TeslaMate2. 本地访问TeslaMate3. Linux安装Cpolar4. 配置TeslaMate公网地址5. 远程访问TeslaMate6. 固定TeslaMate公网地址7. 固定地址访问TeslaMate TeslaMate是一个开源软件,可以通过连接特斯拉账号,记录行驶历史,统…...
如何在CentOS安装SQL Server数据库并实现无公网ip环境远程连接
文章目录 前言1. 安装sql server2. 局域网测试连接3. 安装cpolar内网穿透4. 将sqlserver映射到公网5. 公网远程连接6.固定连接公网地址7.使用固定公网地址连接 前言 简单几步实现在Linux centos环境下安装部署sql server数据库,并结合cpolar内网穿透工具࿰…...
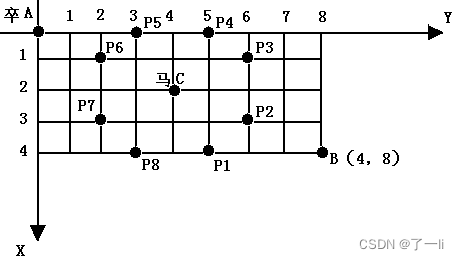
备战蓝桥杯 Day5
1191:流感传染 【题目描述】 有一批易感人群住在网格状的宿舍区内,宿舍区为n*n的矩阵,每个格点为一个房间,房间里可能住人,也可能空着。在第一天,有些房间里的人得了流感,以后每天,得…...
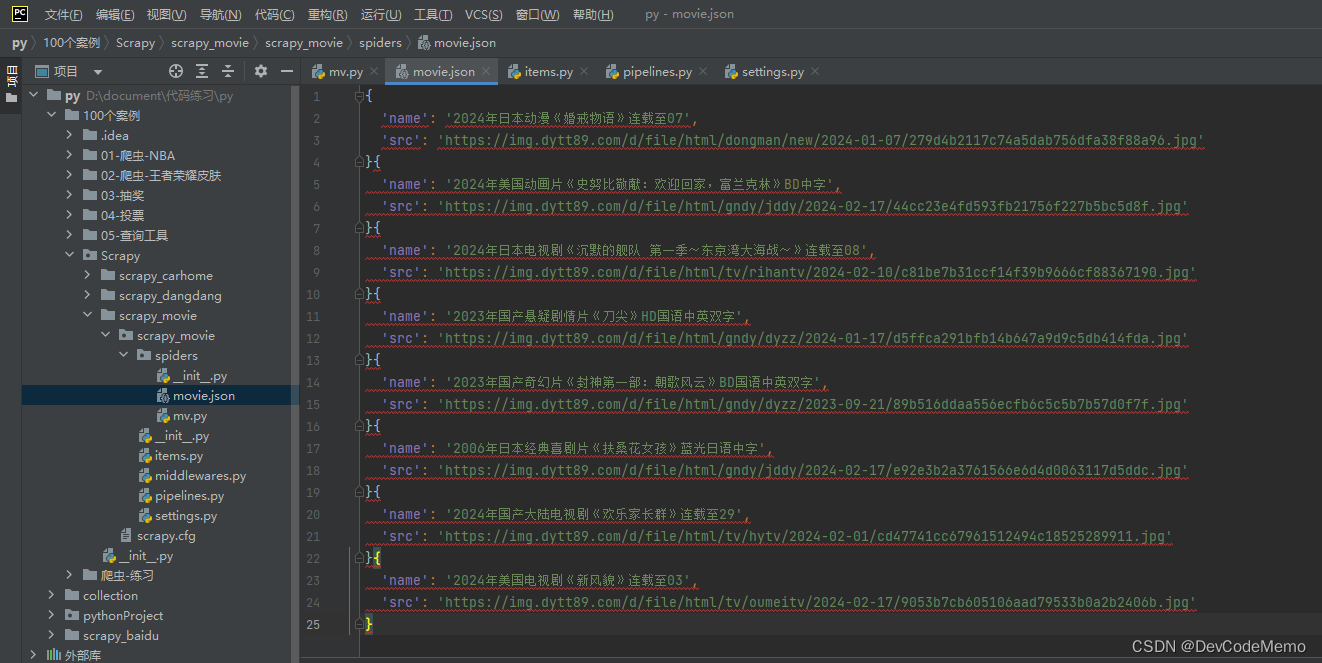
爬虫学习笔记-scrapy爬取电影天堂(双层网址嵌套)
1.终端运行scrapy startproject movie,创建项目 2.接口查找 3.终端cd到spiders,cd scrapy_carhome/scrapy_movie/spiders,运行 scrapy genspider mv https://dy2018.com/ 4.打开mv,编写代码,爬取电影名和网址 5.用爬取的网址请求,使用meta属性传递name ,callback调用自定义的…...

Unity笔记:数据持久化的几种方式
正文 主要方法: ScriptableObjectPlayerPrefsJSONXML数据库(如Sqlite) 1. PlayerPerfs PlayerPrefs 存储的数据是全局共享的,它们存储在用户设备的本地存储中,并且可以被应用程序的所有部分访问。这意味着…...
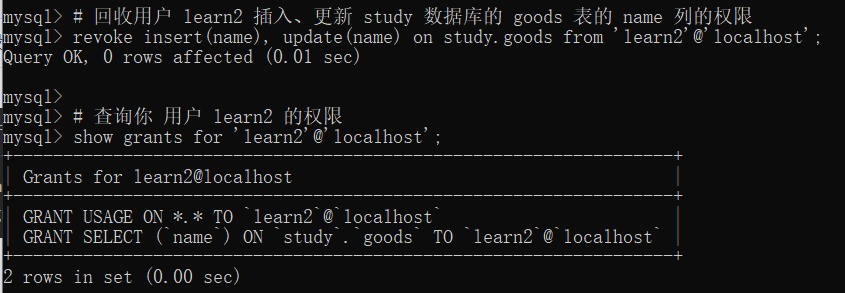
MySQL 基础知识(八)之用户权限管理
目录 1 MySQL 权限管理概念 2 用户管理 2.1 创建用户 2.2 查看当前登录用户 2.3 修改用户名 2.4 删除用户 3 授予权限 3.1 授予用户管理员权限 3.2 授予用户数据库权限 3.3 授予用户表权限 3.4 授予用户列权限 4 查询权限 5 回收权限 1 MySQL 权限管理概念 关于 M…...
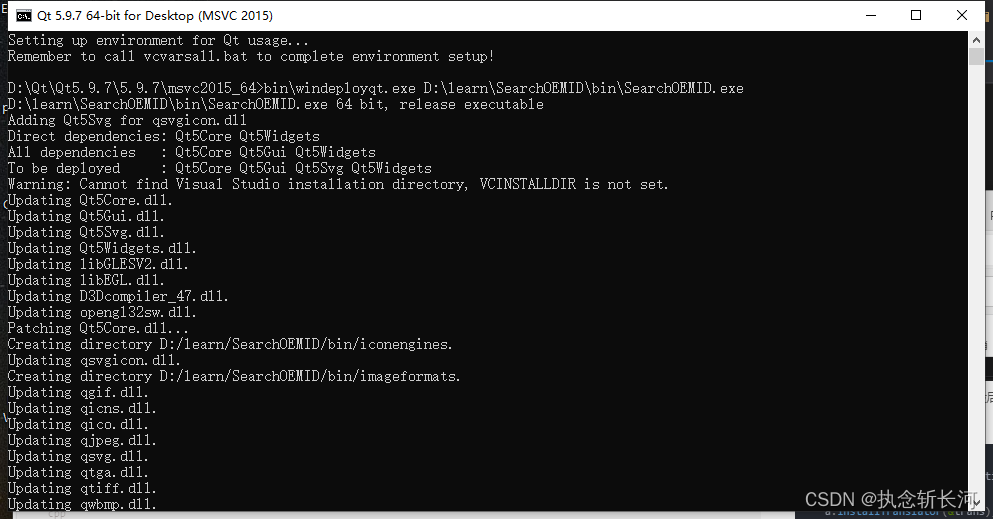
QT编写工具基本流程(自用)
以后有人让你写工具的时候,可以方便用这个模版及时提高工作效率,可以争取早点下班。包含库目录,头文件目录,输出目录以及翻译和部署,基本上都全了,也可以做收藏用用。 文章目录 1、创建项目Dialog Widget都…...
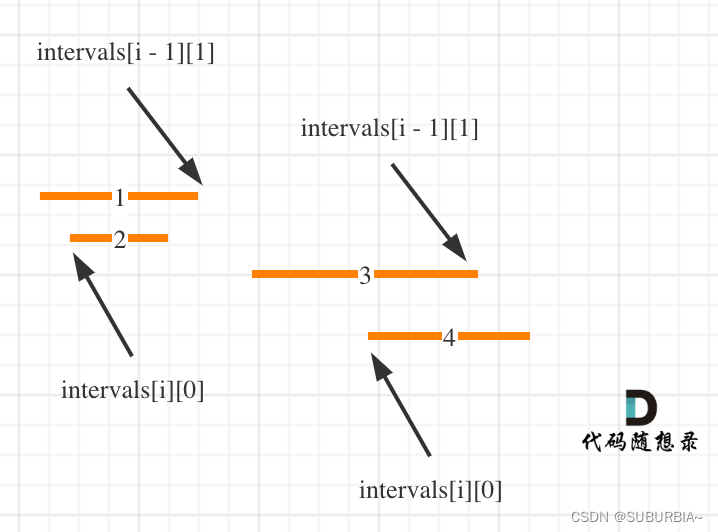
代码随想录算法训练营第三六天 | 无重叠区间、划分字母区间、合并区间
目录 无重叠区间划分字母区间合并区间 LeetCode 435. 无重叠区间 LeetCode 763.划分字母区间 LeetCode 56. 合并区间 无重叠区间 给定一个区间的集合 intervals ,其中 intervals[i] [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠…...

DP读书:《openEuler操作系统》(十)套接字 Socket 数据传输的基本模型
10min速通Socket 套接字简介数据传输基本模型1.TCP/IP模型2.UDP模型 套接字类型套接字(Socket)编程Socket 的连接1.连接概述(1)基本概念(2)连接状态(3)连接队列 2.建立连接3.关闭连接 socket 编程接口介绍数据的传输1. 阻塞与非阻塞2. I/O复用 数据的传输…...
抓住母亲节销售机会:Shopee 平台选品策略大揭秘
母亲节,作为一个重要的购物节日,为卖家带来了巨大的销售机会。在Shopee这样的电商平台上,如何通过有效的选品策略吸引消费者、提高销量呢?下面将介绍一些关键策略,帮助卖家在母亲节期间实现销售突破。 先给大家推荐一…...

Mysql如何优化数据查询方案
mysql做读写分离 读写分离是提高mysql并发的首选方案。 Mysql主从复制的原理 mysql的主从复制依赖于binlog,也就是记录mysql上的所有变化并以二进制的形式保存在磁盘上,复制的过程就是将binlog中的数据从主库传输到从库上。 主从复制过程详细分为3个阶段…...

SwiftUI 更自然地向自定义视图传递参数的“另类”方式
概览 在 SwiftUI 中,正是自定义视图让我们的 App 变得与众不同!然而,除了传统的视图接口定义方式以外,我们其实还可以有更“银杏化”的选择。 如上图所示:对于 SubView 子视图所需的参数我们一开始并没有操之过急&…...
)
SAP财务实操:FBV0/FB08凭证冲销与FBV1预制凭证的完整流程(附BADI增强代码)
SAP财务凭证处理实战:从冲销到增强的全链路解决方案 月末关账前发现凭证金额错误怎么办?批量处理上百张供应商发票如何避免手工录入?这些场景恰恰是SAP财务模块中FBV0、FBV1、FB08等事务代码的核心战场。本文将带您穿透事务代码的表层操作&am…...

Shader Graph边缘光原理与实战:从菲涅尔效应到世界空间法线
1. 为什么边缘光不是“加个描边”那么简单——从美术需求到Shader本质的错位“给模型加个边缘光”,听起来像Unity编辑器里拖个组件、点几下鼠标就能搞定的事。我第一次接到这个需求时,美术同学在评审会上甩出一张《原神》角色截图,指着雷电将…...

【NotebookLM显著性判断实战指南】:20年AI架构师亲授5大误判陷阱与3步精准验证法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM显著性判断的核心概念与本质认知 NotebookLM 是 Google 推出的基于用户上传文档进行语义理解与对话生成的实验性 AI 工具,其“显著性判断”并非传统统计学中的 p 值检验ÿ…...

C#与Unity 3D构建100ms级工业数字孪生系统
1. 这不是“3D大屏”,而是产线工控级实时映射“数字孪生监控”这六个字,现在被贴在太多PPT封面上了——三维建模、粒子特效、旋转飞入的UI动效,配上“智能决策”“预测性维护”的标语,看起来很美。但真正跑在车间里的产线监控系统…...

Keil MDK C166工具链Watch窗口数组显示异常解决方案
1. 问题现象与影响范围解析在Keil MDK开发环境中使用C166工具链时,开发者可能会遇到一个棘手的调试器显示问题:Watch窗口中的数组和指针数值显示异常。具体表现为数组地址计算错误,进而导致所有数组成员的数值显示都不正确。这个问题不仅影响…...

收藏!揭秘高薪职业:AI大模型训练师,小白也能入门的AI时代新机遇!
本文介绍了AI大模型训练师这一新兴职业,旨在解决AI与人类沟通的障碍。训练师通过拆解人类模糊需求,教AI识别信号,输出精准回应。随着AI技术普及,该岗位需求激增,薪资可达3w。工作内容包括数据管理、模型训练、评估迭代…...

Gemini3.1Pro构建神经符号系统实战
用 Gemini 3.1 Pro 构建神经符号系统的可行性探讨:从“会推理”到“能落地执行”在大模型时代,大家越来越关心的不只是“模型会不会回答”,而是能不能把推理可靠地用到复杂任务里:比如自动化规划、合规决策、工具调用、甚至半自动…...

B/S架构模式在校园管理系统中的应用研究
随着校园信息化建设的不断普及,各类校园管理系统层出不穷,系统架构模式直接决定系统的使用便捷性、运维难度与适配场景。传统C/S架构即客户端/服务器架构,需要用户下载安装专属客户端,存在部署繁琐、升级困难、跨终端适配差、运维…...

鸿蒙同城兴趣圈页面构建:附近社群与兴趣标签模块详解
鸿蒙同城兴趣圈页面构建:附近社群与兴趣标签模块详解 前言 在 HarmonyOS 6.0 应用开发中,社交类页面的核心挑战在于如何高效展示附近社群、兴趣标签和活动信息。本文将以“同城兴趣圈”应用的主页面为例,深入解析如何在鸿蒙平台上构建社交发现…...

React Starter Kit 团队协作:如何建立统一的开发规范
React Starter Kit 团队协作:如何建立统一的开发规范 【免费下载链接】react-starter-kit Start your first React App. By using React, Redux, and React-Router. 项目地址: https://gitcode.com/gh_mirrors/reac/react-starter-kit React Starter Kit 是一…...