PyTorch detach():深入解析与实战应用
PyTorch detach():深入解析与实战应用
🌵文章目录🌵
- 🌳引言🌳
- 🌳一、计算图与梯度传播🌳
- 🌳二、detach()函数的作用🌳
- 🌳三、detach()与requires_grad🌳
- 🌳四、使用detach()的示例🌳
- 🌳五、总结与启示🌳
- 🌳结尾🌳
🌳引言🌳
在PyTorch中,detach()函数是实现计算图灵活控制的关键。通过理解其背后的原理和应用场景,我们能够更有效地利用PyTorch进行深度学习模型的训练和优化。本文将深入探讨detach()函数的工作原理,并通过实战案例展示其在深度学习实践中的应用。
🌳一、计算图与梯度传播🌳
在PyTorch中,每个张量都是计算图上的一个节点,它们通过一系列操作相互连接。这些操作不仅定义了张量之间的关系,还构建了用于梯度传播的计算历史。梯度传播是深度学习模型训练的核心,它允许我们通过反向传播算法计算损失函数对模型参数的梯度,进而优化模型。然而,在某些情况下,我们可能需要从计算图中分离某些张量,以避免不必要的梯度计算或内存消耗。这就是detach()函数发挥作用的地方。
🌳二、detach()函数的作用🌳
detach()函数是PyTorch中一项强大的工具,它允许我们从计算图中分离出张量。当你对一个张量调用detach()方法时,它会创建一个新的张量,这个新张量与原始张量共享数据,但它不再参与计算图的任何操作 ⇒ 对分离后的张量进行的任何操作都不会影响原始张量,也不会在计算图中留下任何痕迹。
在某些场景中,分离张量非常实用。例如,在模型推理阶段,我们往往不需要计算梯度,因此可以通过detach()来降低内存消耗并提升计算效率。此外,当你想要获取一个张量的值,但又不想让这个值参与到后续的计算图中时,detach()函数也是你的理想选择。
🌳三、detach()与requires_grad🌳
detach()函数在PyTorch中用于从当前计算图中分离张量,这意味着该张量将不再参与梯度计算。然而,detach()函数并不会改变张量的requires_grad属性。这是因为requires_grad属性决定了张量是否需要在其上的操作被跟踪以计算梯度,而detach()仅仅是创建了一个新的张量,该张量是从原始计算图中分离出来的,而不是改变了原始张量的属性。
下面是一个代码示例,演示了detach()不会改变requires_grad属性:
import torch# 创建一个需要计算梯度的张量
x = torch.tensor([2.0], requires_grad=True)# 检查x的requires_grad属性
print("x.requires_grad:", x.requires_grad) # 输出: x.requires_grad: True# 对x进行一个操作
y = x * 2# 检查y的requires_grad属性
print("y.requires_grad:", y.requires_grad) # 输出: y.requires_grad: True# 使用detach()从计算图中分离y
y_detached = y.detach()# 检查y_detached的requires_grad属性
print("y_detached.requires_grad:", y_detached.requires_grad) # 输出: y_detached.requires_grad: False# 但是,检查原始张量y的requires_grad属性,它并没有改变
print("y.requires_grad:", y.requires_grad) # 输出: y.requires_grad: True# 这也说明了detach()返回了一个新的张量,而不是修改了原始张量
print("y is y_detached:", y is y_detached) # 输出: y is y_detached: False
运行结果如下所示:
x.requires_grad: True
y.requires_grad: True
y_detached.requires_grad: False
y.requires_grad: True
y is y_detached: False进程已结束,退出代码0
在这个示例中,我们创建了一个需要计算梯度的张量x,然后对其进行了一个乘法操作得到y,y也继承了requires_grad=True。接着,我们使用detach()创建了一个新的张量y_detached,它是从原始计算图中分离出来的。我们可以看到,y_detached的requires_grad属性是False,意味着它不会参与梯度计算。然而,原始的y张量的requires_grad属性仍然是True,说明detach()并没有改变它。这也证明了detach()是创建了一个新的张量对象,而不是在原始张量上进行了修改。
🌳四、使用detach()的示例🌳
为了更好地理解detach()的使用,让我们通过一个简单的例子来演示。
假设我们有一个简单的神经网络模型,它包含一个输入层、一个隐藏层和一个输出层。我们将使用PyTorch来构建这个模型,并使用detach()来分离某些张量。
import torch
import torch.nn as nn# 定义模型
class SimpleNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(SimpleNN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.fc2 = nn.Linear(hidden_size, output_size)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return x# 初始化模型
model = SimpleNN(input_size=10, hidden_size=5, output_size=1)# 创建随机输入数据
input_data = torch.randn(1, 10, requires_grad=True)# 执行前向传播
output = model(input_data)# 计算损失
loss = (output - torch.tensor([1.0])) ** 2# 执行反向传播
loss.backward()# 打印输入数据的梯度
print("Input data gradients:", input_data.grad)# 分离输入数据
detached_input = input_data.detach()# 使用分离后的输入数据执行前向传播
detached_output = model(detached_input)# 计算损失
detached_loss = (detached_output - torch.tensor([1.0])) ** 2# 执行反向传播
detached_loss.backward()# 打印分离后输入数据的梯度
# 由于detached_input不再参与计算图,因此它没有梯度
print("Detached input data gradients:", detached_input.grad)
运行结果如下所示:
Input data gradients: tensor([[-0.0049, 0.0097, -0.0471, -0.0635, 0.0078, -0.0407, -0.0066, 0.0353,0.0071, -0.0157]])
Detached input data gradients: None进程已结束,退出代码0
在上述示例中,我们首先创建了一个简单的神经网络模型,并使用随机生成的输入数据执行前向传播。然后,我们计算了损失并执行了反向传播,以获取输入数据的梯度。接下来,我们使用detach()从计算图中分离了输入数据,并使用分离后的数据执行前向传播和反向传播。最后,我们打印了分离后输入数据的梯度,发现它是None,因为分离后的数据没有梯度。
🌳五、总结与启示🌳
detach()函数在PyTorch中是一个关键工具,用于从计算图中分离张量,从而优化内存使用和计算速度。尽管这个函数不会改变张量的requires_grad属性,但结合requires_grad属性,我们可以更加细致地控制哪些张量需要参与梯度计算。
在深度学习模型的训练过程中,detach()提供了很大的灵活性。通过合理地使用detach(),我们可以在不影响模型训练的前提下,减少不必要的计算图构建,从而提高训练效率。此外,在模型推理阶段,detach()也能够帮助我们减少内存占用,加快计算速度。
为了更好地理解detach()的应用,我们可以考虑以下场景:在构建复杂的深度学习模型时,某些中间层的输出可能不需要参与梯度计算。这时,我们可以使用detach()来分离这些张量,从而优化计算图和内存使用。
总之,detach()是PyTorch中一个不可或缺的工具,它允许我们以更加精细的方式控制模型的训练过程。通过熟练掌握detach()的使用,我们可以更加高效地训练和部署深度学习模型。
🌳结尾🌳
亲爱的读者,首先感谢您抽出宝贵的时间来阅读我们的博客。我们真诚地欢迎您留下评论和意见💬。
俗话说,当局者迷,旁观者清。您的客观视角对于我们发现博文的不足、提升内容质量起着不可替代的作用。
如果博文给您带来了些许帮助,那么,希望您能为我们点个免费的赞👍👍/收藏👇👇,您的支持和鼓励👏👏是我们持续创作✍️✍️的动力。
我们会持续努力创作✍️✍️,并不断优化博文质量👨💻👨💻,只为给您带来更佳的阅读体验。
如果您有任何疑问或建议,请随时在评论区留言,我们将竭诚为你解答~
愿我们共同成长🌱🌳,共享智慧的果实🍎🍏!
万分感谢🙏🙏您的点赞👍👍、收藏⭐🌟、评论💬🗯️、关注❤️💚~
相关文章:
:深入解析与实战应用)
PyTorch detach():深入解析与实战应用
PyTorch detach():深入解析与实战应用 🌵文章目录🌵 🌳引言🌳🌳一、计算图与梯度传播🌳🌳二、detach()函数的作用🌳🌳三、detach()与requires_graddz…...

uniapp 开发一个密码管理app
密码管理app 介绍 最近发现自己的账号密码真的是太多了,各种网站,系统,公司内网的,很多站点在登陆的时候都要重新设置密码或者通过短信或者邮箱重新设置密码,真的很麻烦 所以准备开发一个app用来记录这些站好和密码…...
Postman详细攻略
🍅 视频学习:文末有免费的配套视频可观看 🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、Postman背景介绍 用户在开发或者调试网络程序或者是网页B/S模式的程序的时候是需要一些方法…...
如何在本地服务器部署TeslaMate并远程查看特斯拉汽车数据无需公网ip
文章目录 1. Docker部署TeslaMate2. 本地访问TeslaMate3. Linux安装Cpolar4. 配置TeslaMate公网地址5. 远程访问TeslaMate6. 固定TeslaMate公网地址7. 固定地址访问TeslaMate TeslaMate是一个开源软件,可以通过连接特斯拉账号,记录行驶历史,统…...
如何在CentOS安装SQL Server数据库并实现无公网ip环境远程连接
文章目录 前言1. 安装sql server2. 局域网测试连接3. 安装cpolar内网穿透4. 将sqlserver映射到公网5. 公网远程连接6.固定连接公网地址7.使用固定公网地址连接 前言 简单几步实现在Linux centos环境下安装部署sql server数据库,并结合cpolar内网穿透工具࿰…...
备战蓝桥杯 Day5
1191:流感传染 【题目描述】 有一批易感人群住在网格状的宿舍区内,宿舍区为n*n的矩阵,每个格点为一个房间,房间里可能住人,也可能空着。在第一天,有些房间里的人得了流感,以后每天,得…...
爬虫学习笔记-scrapy爬取电影天堂(双层网址嵌套)
1.终端运行scrapy startproject movie,创建项目 2.接口查找 3.终端cd到spiders,cd scrapy_carhome/scrapy_movie/spiders,运行 scrapy genspider mv https://dy2018.com/ 4.打开mv,编写代码,爬取电影名和网址 5.用爬取的网址请求,使用meta属性传递name ,callback调用自定义的…...

Unity笔记:数据持久化的几种方式
正文 主要方法: ScriptableObjectPlayerPrefsJSONXML数据库(如Sqlite) 1. PlayerPerfs PlayerPrefs 存储的数据是全局共享的,它们存储在用户设备的本地存储中,并且可以被应用程序的所有部分访问。这意味着…...
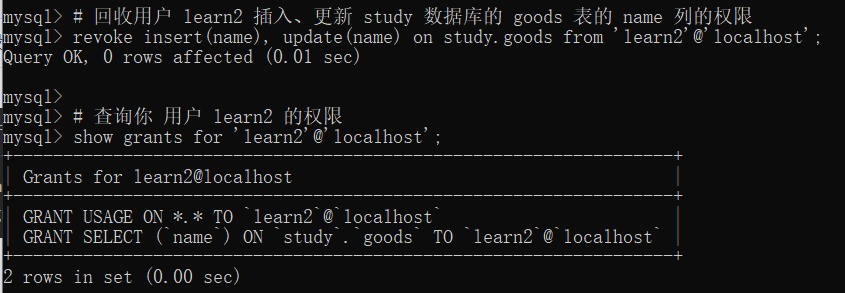
MySQL 基础知识(八)之用户权限管理
目录 1 MySQL 权限管理概念 2 用户管理 2.1 创建用户 2.2 查看当前登录用户 2.3 修改用户名 2.4 删除用户 3 授予权限 3.1 授予用户管理员权限 3.2 授予用户数据库权限 3.3 授予用户表权限 3.4 授予用户列权限 4 查询权限 5 回收权限 1 MySQL 权限管理概念 关于 M…...
QT编写工具基本流程(自用)
以后有人让你写工具的时候,可以方便用这个模版及时提高工作效率,可以争取早点下班。包含库目录,头文件目录,输出目录以及翻译和部署,基本上都全了,也可以做收藏用用。 文章目录 1、创建项目Dialog Widget都…...
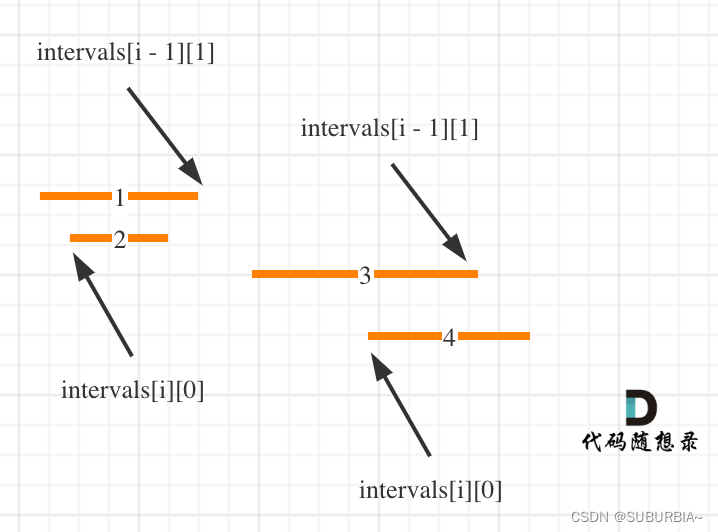
代码随想录算法训练营第三六天 | 无重叠区间、划分字母区间、合并区间
目录 无重叠区间划分字母区间合并区间 LeetCode 435. 无重叠区间 LeetCode 763.划分字母区间 LeetCode 56. 合并区间 无重叠区间 给定一个区间的集合 intervals ,其中 intervals[i] [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠…...

DP读书:《openEuler操作系统》(十)套接字 Socket 数据传输的基本模型
10min速通Socket 套接字简介数据传输基本模型1.TCP/IP模型2.UDP模型 套接字类型套接字(Socket)编程Socket 的连接1.连接概述(1)基本概念(2)连接状态(3)连接队列 2.建立连接3.关闭连接 socket 编程接口介绍数据的传输1. 阻塞与非阻塞2. I/O复用 数据的传输…...
抓住母亲节销售机会:Shopee 平台选品策略大揭秘
母亲节,作为一个重要的购物节日,为卖家带来了巨大的销售机会。在Shopee这样的电商平台上,如何通过有效的选品策略吸引消费者、提高销量呢?下面将介绍一些关键策略,帮助卖家在母亲节期间实现销售突破。 先给大家推荐一…...

Mysql如何优化数据查询方案
mysql做读写分离 读写分离是提高mysql并发的首选方案。 Mysql主从复制的原理 mysql的主从复制依赖于binlog,也就是记录mysql上的所有变化并以二进制的形式保存在磁盘上,复制的过程就是将binlog中的数据从主库传输到从库上。 主从复制过程详细分为3个阶段…...

SwiftUI 更自然地向自定义视图传递参数的“另类”方式
概览 在 SwiftUI 中,正是自定义视图让我们的 App 变得与众不同!然而,除了传统的视图接口定义方式以外,我们其实还可以有更“银杏化”的选择。 如上图所示:对于 SubView 子视图所需的参数我们一开始并没有操之过急&…...

Word第一课
文章目录 1. 文件格式1.1 如何显示文件扩展名1.2 Word文档格式的演变1.3 常见的Word文档格式 3. 文档属性理解文档属性查看文档属性 1. 文件格式 1.1 如何显示文件扩展名 文档格式指的是文件的扩展名,例如下图 对于该文件,.docx就是文件扩展名&#x…...

【Vue3】路由传参的几种方式
路由导航有两种方式,分别是:声明式导航 和 编程式导航 参数分为query参数和params参数两种 声明式导航 query参数 一、路径字符串拼接(不推荐) 1.传参 在路由路径后直接拼接?参数名:参数值 ,多组参数间使用&分隔。 <RouterLink …...
))
突破编程_C++_面试(高级特性(1))
面试题1:什么是线程以及它在并发编程中的作用是什么 线程( Thread )是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进…...
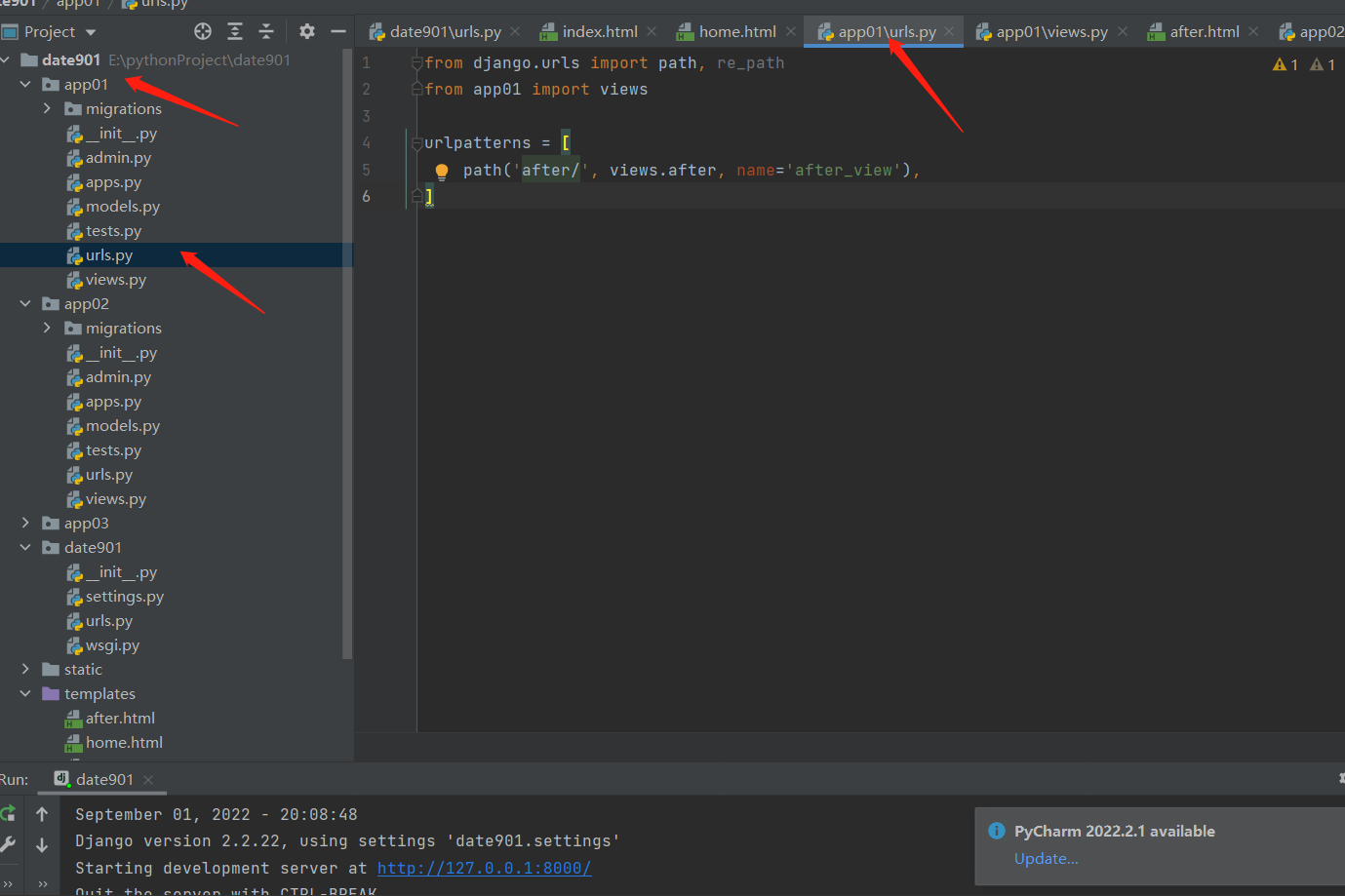
django请求生命周期流程图,路由匹配,路由有名无名反向解析,路由分发,名称空间
django请求生命周期流程图 浏览器发起请求。 先经过网关接口,Django自带的是wsgiref,请求来的时候解析封装,响应走的时候打包处理,这个wsgiref模块本身能够支持的并发量很少,最多1000左右,上线之后会换成u…...
|Day54(动态规划))
@ 代码随想录算法训练营第8周(C语言)|Day54(动态规划)
代码随想录算法训练营第8周(C语言)|Day54(动态规划) Day53、动态规划(包含题目 ● 123.买卖股票的最佳时机III ● 188.买卖股票的最佳时机IV ) 123.买卖股票的最佳时机III 题目描述 给定一个数组&#…...

# 我花了一天,给 AI Coding Agent 搭了一个 Mini Harness
最近在折腾 AI Coding Agent(Claude Code / Cursor / 自定义 Agent)时,我发现一个很常见的问题:**模型会写代码,但不一定会“按流程工作”。**它可能:- 需求还没对齐,直接开始改代码 - 改着改着…...

我用了半年只留下这1个!2026年录音怎么转换成文字亲测准确率真的超高
我前后用了大半年录音转文字工具,试了免费小工具、大厂办公套件自带功能、好几个专门做转写的产品,踩了一堆坑之后最终只留了一个——听脑AI。作为常年要整理课堂录音、调研访谈的学生党,我可以负责任说,2026年做录音转文字&#…...

收藏!揭秘高薪职业:AI大模型训练师,小白也能入门的AI时代新机遇!
本文介绍了AI大模型训练师这一新兴职业,旨在解决AI与人类沟通的障碍。训练师通过拆解人类模糊需求,教AI识别信号,输出精准回应。随着AI技术普及,该岗位需求激增,薪资可达3w。工作内容包括数据管理、模型训练、评估迭代…...

高通量细胞因子/生物因子检测技术介绍
高通量细胞因子/生物因子检测技术介绍—多维免疫分析技术,赋能精准医学与转化研究 导语 伴随精准医学领域持续深耕与转化医学研究的高速推进,细胞因子、趋化因子、生长因子等各类可溶性生物标志物的动态表达变化,成为解析疾病发病机制、研判…...

剪映专业版教程:制作堆排序算法原理演示视频
前言 今天教大家用剪映制作堆排序算法的原理演示视频。堆排序的原理是:先将无序序列构建成一个小根堆(堆顶元素是整个堆中最小的),然后反复取出堆顶元素放到有序序列末尾,再将剩余元素重新调整成小根堆,重…...

萨科微宋仕强“华强北山寨手机”研究
萨科微宋仕强“华强北山寨手机”研究(十六),手机的灰色产业链。华强北每个手机柜台背后都有灰色供应链支撑。如香港手机比华强北便宜,就通过各种渠道从香港走私过来。沙头角的中英街两边分属于香港和深圳,香港一侧的走…...

Burp Suite客户端证书不生效的三大底层原因与排错指南
1. 这不是证书问题,是信任链断裂的错觉 你刚在Burp Suite里导入了Client SSL Certificate,勾选了“Use client certificate for all requests”,点下Send,结果服务器返回400 Bad Request或直接断连;换一台机器重装Burp…...

MASA模组汉化包技术解析:构建高效中文游戏体验的技术解决方案
MASA模组汉化包技术解析:构建高效中文游戏体验的技术解决方案 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 在Minecraft模组生态系统中,MASA系列模组以其强大的…...

大型SaaS系统数据范围权限设计:从RBAC到动态数据域的实战解析
1. 项目概述:为什么数据范围权限是SaaS的“命门”在SaaS(软件即服务)领域摸爬滚打十几年,我见过太多项目因为早期忽略了数据范围权限这个“小”问题,最终导致架构重构、客户流失甚至数据泄露的“大”事故。一个面向企业…...

DOM 基础全面解析
系列文章目录 《JavaScript 基础与进阶笔记》(前期偏基础巩固与常见面试点,后续进入闭包、异步、工程化等进阶主题) 第 01 篇:数据类型与类型判断第 02 篇:变量声明与作用域第 03 篇:闭包与高阶函数第 04…...