第三篇【传奇开心果系列】Python的文本和语音相互转换库技术点案例示例:pyttsx3实现语音助手经典案例
传奇开心果短博文系列
- 系列短博文目录
- Python的文本和语音相互转换库技术点案例示例系列
- 短博文目录
- 一、项目背景和目标
- 二、雏形示例代码
- 三、扩展思路介绍
- 四、与其他库和API集成示例代码
- 五、自定义语音示例代码
- 六、多语言支持示例代码
- 七、语音控制应用程序示例代码
- 八、文本转语音通知示例代码
- 九、语音交互界面示例代码
- 十、实现更复杂交互界面示例代码
- 十一、归纳总结
系列短博文目录
Python的文本和语音相互转换库技术点案例示例系列
短博文目录
一、项目背景和目标
 当今社会人工智能机器学习在我国方兴未艾,语音助手无处不在大显神威。大到歼20战斗机语音辅助操控,中到家用小汽车语音辅助操控,小到智能家居语音操控、小爱同学操控音响设备等,可以说语音助手已经深入工作、生活和社会的各个方面。
当今社会人工智能机器学习在我国方兴未艾,语音助手无处不在大显神威。大到歼20战斗机语音辅助操控,中到家用小汽车语音辅助操控,小到智能家居语音操控、小爱同学操控音响设备等,可以说语音助手已经深入工作、生活和社会的各个方面。
pyttsx是一个Python库,用于实现文本到语音的转换。它提供了一个使用简单的API,可以很方便地让你的Python程序实现生成语音输出的语音助手。
二、雏形示例代码
 下面是一个简单的语音助手示例代码:
下面是一个简单的语音助手示例代码:
-
安装
pyttsx库:pip install pyttsx -
导入
pyttsx:import pyttsx -
创建
pyttsx的引擎对象:engine = pyttsx.init() -
设置语音助手的属性(可选):
engine.setProperty('rate', 150) # 设置语速(默认为200) engine.setProperty('volume', 0.8) # 设置音量(范围为0.0到1.0) -
将文本转换为语音并播放:
engine.say("你好,我是语音助手") engine.runAndWait()这段代码会将文本 “你好,我是语音助手” 转换为语音并播放出来。
-
如果你想将文本保存为音频文件,可以使用
save_to_file方法:engine.save_to_file("你好,我是语音助手", "output.mp3") engine.runAndWait()这段代码会将文本 “你好,我是语音助手” 转换为语音,并保存为名为 “output.mp3” 的音频文件。
这只是一个简单的示例,pyttsx 还提供了其他功能,如设置语言、获取可用的语音引擎等。你可以查看 pyttsx 的官方文档以获取更多详细信息和示例代码:https://pyttsx.readthedocs.io/
三、扩展思路介绍
 当你熟悉了基本的
当你熟悉了基本的 pyttsx 库的用法后,你可以进一步扩展你的语音助手的功能。以下是一些扩展思路:
-
与其他库和API集成:将
pyttsx与其他库和API结合使用,以增强语音助手的功能。例如,你可以使用speech_recognition库来实现语音识别,将用户的语音输入转换为文本,并使用pyttsx将回应转换为语音输出。 -
自定义语音:使用
pyttsx的setProperty方法来调整语音助手的属性,例如语速、音量和音调,以使语音更加自然和适合用户的喜好。 -
多语言支持:
pyttsx支持多种语言和语音引擎。你可以通过设置pyttsx的setProperty方法来切换语言,从而实现多语言支持的语音助手。 -
语音控制应用程序:结合其他库和框架,你可以创建一个可以通过语音控制的应用程序。例如,你可以使用
pyttsx和pyautogui库来实现语音控制鼠标和键盘,从而实现语音导航和操作。 -
文本转语音通知:使用
pyttsx将文本转换为语音,以实现通知功能。你可以将系统的提醒、日程安排、新闻等文本内容转换为语音,并通过语音播放给用户。 -
语音交互界面:创建一个交互式的语音界面,让用户可以通过语音与你的应用程序进行交互。你可以使用
pyttsx结合其他库和框架,例如pyaudio和speech_recognition,来实现语音输入和输出的交互式界面。
这些是一些扩展思路,你可以根据你的需求和兴趣进一步探索和扩展你的语音助手的功能。记得查阅相关文档和示例代码,以更好地理解和使用相关库和API。
四、与其他库和API集成示例代码
 当将
当将 pyttsx 与 speech_recognition 库结合使用时,你可以实现一个能够接收语音输入并以语音回应的语音助手。以下是一个示例代码:
import speech_recognition as sr
import pyttsx3# 创建语音识别器对象
recognizer = sr.Recognizer()# 创建语音合成引擎对象
engine = pyttsx3.init()# 定义语音助手的回应函数
def respond(text):print("助手:", text)engine.say(text)engine.runAndWait()# 语音助手的主循环
while True:try:# 使用麦克风录音with sr.Microphone() as source:print("请说话:")audio = recognizer.listen(source)# 识别语音输入text = recognizer.recognize_google(audio, language="zh-CN")print("用户:", text)# 根据用户输入作出回应if "你好" in text:respond("你好!我是语音助手。")elif "再见" in text:respond("再见!祝你有美好的一天!")breakelse:respond("抱歉,我不理解你的意思。")except sr.UnknownValueError:print("抱歉,无法识别你的语音。")except sr.RequestError:print("抱歉,无法连接到语音识别服务。")
这段代码使用 speech_recognition 库来监听麦克风输入,并使用 Google 语音识别服务将语音转换为文本。然后,根据用户的输入作出相应的回应,使用 pyttsx 将回应转换为语音输出。
在这个示例中,语音助手会回应"你好!我是语音助手。"当用户说"你好"时,回应"再见!祝你有美好的一天!“当用户说"再见"时,然后退出程序。对于其他用户输入,语音助手会回应"抱歉,我不理解你的意思。”
请确保已安装 speech_recognition 和 pyttsx3 库,并根据需要调整语音助手的回应逻辑。你还可以根据需要添加其他功能,例如语音控制、多语言支持等。
五、自定义语音示例代码

 当使用
当使用 pyttsx3 的 setProperty 方法来自定义语音属性时,你可以调整语音助手的语速、音量和音调等属性,以使语音更加自然和符合用户的喜好。以下是一个示例代码:
import pyttsx3# 创建语音合成引擎对象
engine = pyttsx3.init()# 获取当前语音属性
rate = engine.getProperty('rate') # 语速
volume = engine.getProperty('volume') # 音量
pitch = engine.getProperty('pitch') # 音调# 设置新的语音属性
engine.setProperty('rate', 150) # 设置语速为150
engine.setProperty('volume', 0.8) # 设置音量为0.8
engine.setProperty('pitch', 1.2) # 设置音调为1.2# 定义语音助手的回应函数
def respond(text):print("助手:", text)engine.say(text)engine.runAndWait()# 测试自定义语音属性
respond("你好!我是语音助手。")# 恢复默认语音属性
engine.setProperty('rate', rate) # 恢复默认语速
engine.setProperty('volume', volume) # 恢复默认音量
engine.setProperty('pitch', pitch) # 恢复默认音调# 测试恢复默认语音属性
respond("你好!我是语音助手。")
在这个示例中,我们首先创建了一个 pyttsx3 的语音合成引擎对象。然后,通过 getProperty 方法获取当前的语音属性,包括语速、音量和音调。接下来,使用 setProperty 方法设置新的语音属性,例如将语速设置为150,音量设置为0.8,音调设置为1.2。然后,定义了一个回应函数 respond,该函数会打印回应文本并使用语音合成引擎进行语音输出。
在示例中,我们先测试了使用自定义语音属性的回应,然后恢复了默认的语音属性,并再次进行了回应测试。
你可以根据需要调整语音属性的值,以使语音更加自然和适合用户的喜好。请注意,具体的语音属性值可能因系统和语音引擎而异。你可以尝试不同的值来找到最适合的设置。
六、多语言支持示例代码
pyttsx3 支持多种语言和语音引擎,你可以通过设置 setProperty 方法来切换语言,从而实现多语言支持的语音助手。以下是一个示例代码:
import pyttsx3# 创建语音合成引擎对象
engine = pyttsx3.init()# 获取当前语音属性
voices = engine.getProperty('voices')# 打印可用的语音列表
print("可用的语音列表:")
for voice in voices:print("名称:", voice.name)print("ID:", voice.id)print("语言:", voice.languages)print("性别:", voice.gender)print("")# 设置新的语音属性(切换语言)
engine.setProperty('voice', voices[1].id) # 设置语音为第二个可用语音# 定义语音助手的回应函数
def respond(text):print("助手:", text)engine.say(text)engine.runAndWait()# 测试多语言支持
respond("Hello! I am a multilingual voice assistant.")
respond("你好!我是一个多语言语音助手。")# 恢复默认语音属性(切换回默认语言)
engine.setProperty('voice', voices[0].id) # 设置语音为第一个可用语音# 测试恢复默认语音属性
respond("Hello! I am a multilingual voice assistant.")
respond("你好!我是一个多语言语音助手。")
在这个示例中,我们首先创建了一个 pyttsx3 的语音合成引擎对象,并使用 getProperty 方法获取当前可用的语音列表。然后,我们打印了每个语音的名称、ID、语言和性别等信息。
接下来,使用 setProperty 方法将语音属性设置为第二个可用语音,以切换语言。你可以根据需要选择其他可用的语音。
然后,定义了一个回应函数 respond,该函数会打印回应文本并使用语音合成引擎进行语音输出。
在示例中,我们先测试了使用第二个可用语音的回应,然后恢复了默认的语音属性,再次进行了回应测试。
你可以根据需要选择合适的语音,以实现多语言支持的语音助手。请注意,可用的语音和语言取决于你的系统和安装的语音引擎。
七、语音控制应用程序示例代码
 要创建一个可以通过语音控制的应用程序,你可以结合使用
要创建一个可以通过语音控制的应用程序,你可以结合使用 pyttsx3 和其他库和框架来实现不同的功能。下面是一个示例代码,演示了如何使用 pyttsx3 和 pyautogui 库来实现语音控制鼠标和键盘:
import pyttsx3
import speech_recognition as sr
import pyautogui# 创建语音合成引擎对象
engine = pyttsx3.init()# 创建语音识别器对象
recognizer = sr.Recognizer()# 定义语音助手的回应函数
def respond(text):print("助手:", text)engine.say(text)engine.runAndWait()# 定义语音控制函数
def voice_control():with sr.Microphone() as source:print("请说话...")audio = recognizer.listen(source)try:# 使用语音识别器将语音转换为文本text = recognizer.recognize_google(audio, language='zh-CN')print("你说:", text)# 根据识别到的文本执行相应的操作if "向上" in text:pyautogui.move(0, -100, duration=0.5) # 向上移动鼠标elif "向下" in text:pyautogui.move(0, 100, duration=0.5) # 向下移动鼠标elif "向左" in text:pyautogui.move(-100, 0, duration=0.5) # 向左移动鼠标elif "向右" in text:pyautogui.move(100, 0, duration=0.5) # 向右移动鼠标elif "点击" in text:pyautogui.click() # 点击鼠标左键elif "退出" in text:respond("再见!")returnelse:respond("抱歉,我无法理解你的指令。")except sr.UnknownValueError:respond("抱歉,无法识别你说的话。")except sr.RequestError:respond("抱歉,无法连接到语音识别服务。")# 继续监听语音输入voice_control()# 启动语音控制
respond("你好!我是语音助手。请告诉我你想要做什么。")
voice_control()
在这个示例中,我们首先创建了一个 pyttsx3 的语音合成引擎对象和一个 speech_recognition 的语音识别器对象。然后,定义了一个回应函数 respond,该函数会打印回应文本并使用语音合成引擎进行语音输出。
接下来,定义了一个语音控制函数 voice_control,该函数使用语音识别器监听麦克风输入,并将语音转换为文本。根据识别到的文本,执行相应的操作,例如移动鼠标、点击鼠标等。
在示例中,我们定义了一些简单的指令,如 “向上”、“向下”、“向左”、“向右”、“点击” 等。你可以根据需要扩展指令和相应的操作。
最后,启动语音控制,语音助手会打招呼并等待你的指令。你可以说出相应的指令,语音助手会执行对应的操作。
请注意,此示例仅演示了如何结合 pyttsx3 和 pyautogui 库实现语音控制鼠标和键盘的功能。根据你的需求,你可以结合其他库和框架来实现更复杂的语音控制应用程序。
八、文本转语音通知示例代码

pyttsx3 库可以将文本转换为语音,实现通知功能。下面是一个示例代码,演示了如何使用 pyttsx3 将文本内容转换为语音并进行播放:
import pyttsx3# 创建语音合成引擎对象
engine = pyttsx3.init()# 定义文本转语音函数
def text_to_speech(text):engine.say(text)engine.runAndWait()# 定义通知函数
def notify(message):print("通知:", message)text_to_speech(message)# 示例用法
notify("这是一条通知消息。")
notify("你的日程安排已更新。")
notify("以下是今天的新闻摘要:")
notify("这是一条很长的通知消息,可以包含多个句子和段落。")# 关闭语音合成引擎
engine.stop()
在这个示例中,我们首先创建了一个 pyttsx3 的语音合成引擎对象。然后,定义了一个文本转语音函数 text_to_speech,该函数使用语音合成引擎将文本转换为语音并进行播放。
接下来,定义了一个通知函数 notify,该函数接受一个文本消息作为参数,并打印通知消息并通过语音播放。
在示例中,我们使用 notify 函数演示了几个通知消息的例子。你可以根据需要调用 notify 函数,将不同的文本内容转换为语音进行通知。
最后,我们通过调用 engine.stop() 来关闭语音合成引擎。
请注意,使用 pyttsx3 进行文本转语音时,可以根据需要设置语音的属性,如语速、音量等。你可以使用 engine.setProperty 方法来设置这些属性。例如,engine.setProperty('rate', 150) 可以设置语速为 150 字符每分钟。
九、语音交互界面示例代码
 要创建一个交互式的语音界面,可以结合使用
要创建一个交互式的语音界面,可以结合使用 pyttsx3、pyaudio 和 speech_recognition 等库来实现语音输入和输出的功能。下面是一个示例代码,演示了如何创建一个简单的语音交互界面:
import pyttsx3
import speech_recognition as sr# 创建语音合成引擎对象
engine = pyttsx3.init()# 创建语音识别器对象
recognizer = sr.Recognizer()# 定义语音助手的回应函数
def respond(text):print("助手:", text)engine.say(text)engine.runAndWait()# 定义语音交互函数
def voice_interaction():with sr.Microphone() as source:print("请说话...")audio = recognizer.listen(source)try:# 使用语音识别器将语音转换为文本text = recognizer.recognize_google(audio, language='zh-CN')print("你说:", text)# 根据用户输入的文本进行相应的回应if "你好" in text:respond("你好!有什么我可以帮助你的吗?")elif "时间" in text:# 这里可以调用其他库或函数获取当前时间并进行回应respond("现在是晚上8点。")elif "退出" in text:respond("再见!")returnelse:respond("抱歉,我无法理解你的指令。")except sr.UnknownValueError:respond("抱歉,无法识别你说的话。")except sr.RequestError:respond("抱歉,无法连接到语音识别服务。")# 继续语音交互voice_interaction()# 启动语音交互
respond("你好!我是语音助手。有什么我可以帮助你的吗?")
voice_interaction()
在这个示例中,我们首先创建了一个 pyttsx3 的语音合成引擎对象和一个 speech_recognition 的语音识别器对象。然后,定义了一个回应函数 respond,该函数会打印回应文本并使用语音合成引擎进行语音输出。
接下来,定义了一个语音交互函数 voice_interaction,该函数使用语音识别器监听麦克风输入,并将语音转换为文本。根据用户输入的文本,执行相应的回应。
在示例中,我们定义了一些简单的指令,如 “你好” 和 “时间”。根据用户的指令,语音助手会进行相应的回应。你可以根据需要扩展指令和相应的操作。
最后,启动语音交互,语音助手会打招呼并等待用户的指令。你可以通过语音与语音助手进行交互。
请注意,这个示例代码只是一个简单的交互式语音界面的演示。你可以根据自己的需求和应用场景,扩展和定制这个代码,结合其他库和框架实现更复杂的语音交互功能。
十、实现更复杂交互界面示例代码
 当扩展和定制语音交互功能时,你可以根据自己的需求和应用场景,结合其他库和框架来实现更复杂的功能。以下是一个示例代码,展示了如何使用
当扩展和定制语音交互功能时,你可以根据自己的需求和应用场景,结合其他库和框架来实现更复杂的功能。以下是一个示例代码,展示了如何使用 pyttsx3、speech_recognition 和 wikipedia 库来创建一个语音交互的维基百科助手:
import pyttsx3
import speech_recognition as sr
import wikipedia# 创建语音合成引擎对象
engine = pyttsx3.init()# 创建语音识别器对象
recognizer = sr.Recognizer()# 定义语音助手的回应函数
def respond(text):print("助手:", text)engine.say(text)engine.runAndWait()# 定义语音交互函数
def voice_interaction():with sr.Microphone() as source:print("请说话...")audio = recognizer.listen(source)try:# 使用语音识别器将语音转换为文本text = recognizer.recognize_google(audio, language='zh-CN')print("你说:", text)# 根据用户输入的文本进行相应的回应if "你好" in text:respond("你好!有什么我可以帮助你的吗?")elif "维基百科" in text:query = text.replace("维基百科", "").strip()try:# 使用维基百科库获取相关信息summary = wikipedia.summary(query, sentences=2)respond(summary)except wikipedia.exceptions.DisambiguationError as e:respond("请提供更具体的查询内容。")except wikipedia.exceptions.PageError as e:respond("抱歉,找不到相关信息。")elif "退出" in text:respond("再见!")returnelse:respond("抱歉,我无法理解你的指令。")except sr.UnknownValueError:respond("抱歉,无法识别你说的话。")except sr.RequestError:respond("抱歉,无法连接到语音识别服务。")# 继续语音交互voice_interaction()# 启动语音交互
respond("你好!我是维基百科助手。有什么我可以帮助你的吗?")
voice_interaction()
在这个示例中,我们引入了 wikipedia 库,以便通过维基百科获取相关信息。当用户输入包含 “维基百科” 的指令时,我们使用 wikipedia.summary 函数来获取相关信息的摘要,并将其作为回应进行语音输出。
你可以根据自己的需求和应用场景,扩展和定制这个代码。例如,你可以使用其他库来获取天气信息、新闻摘要等,并根据用户的指令进行相应的回应。
请注意,使用维基百科库时,可能会遇到一些异常情况,如歧义性错误或页面错误。在示例中,我们使用了 try-except 块来处理这些异常情况,并作出相应的回应。
希望这个示例代码能够帮助你扩展和定制语音交互功能!
十一、归纳总结
 当使用
当使用 pyttsx3 库实现语音助手时,以下是一些关键的知识点:
-
安装
pyttsx3库:可以使用pip命令来安装pyttsx3库,例如pip install pyttsx3。 -
初始化语音合成引擎:使用
pyttsx3.init()函数来创建一个语音合成引擎对象。可以通过调用该对象的方法来进行语音合成。 -
设置语音合成属性:可以使用
engine.setProperty(property, value)方法来设置语音合成的属性。例如,可以设置语速、音量等属性。 -
语音合成和播放:使用
engine.say(text)方法将文本转换为语音。然后,使用engine.runAndWait()方法来播放语音。 -
支持多种语音引擎:
pyttsx3支持多种语音合成引擎,如 SAPI5、nsss、espeak 等。可以通过pyttsx3.init(driverName)指定要使用的语音引擎。 -
获取可用的语音引擎列表:可以使用
pyttsx3.init()函数的engine.getProperty('voices')方法来获取可用的语音引擎列表。可以根据需要选择合适的语音引擎。 -
设置语音引擎:可以使用
engine.setProperty('voice', voice_id)方法来设置要使用的语音引擎。可以将voice_id设置为语音引擎列表中的一个元素。 -
控制语音合成的事件和回调:
pyttsx3提供了一些事件和回调函数,可以用于控制语音合成的过程。例如,可以使用engine.connect('started', callback_function)方法来注册一个回调函数,在语音合成开始时触发。 -
异步语音合成:
pyttsx3支持异步语音合成,可以使用engine.startLoop()和engine.endLoop()方法来控制异步合成的循环。 -
关闭语音合成引擎:在程序结束时,可以使用
engine.stop()和engine.shutdown()方法来关闭语音合成引擎。

这些是使用 pyttsx3 库实现语音助手时的一些重要知识点。通过了解和掌握这些知识点,你可以更好地使用 pyttsx3 库来实现语音合成的功能。
相关文章:
第三篇【传奇开心果系列】Python的文本和语音相互转换库技术点案例示例:pyttsx3实现语音助手经典案例
传奇开心果短博文系列 系列短博文目录Python的文本和语音相互转换库技术点案例示例系列 短博文目录一、项目背景和目标二、雏形示例代码三、扩展思路介绍四、与其他库和API集成示例代码五、自定义语音示例代码六、多语言支持示例代码七、语音控制应用程序示例代码八、文本转语音…...

JS中数组的常用方法
concat() 连接两个或更多的数组,并返回结果。 let array1 [1, 2, 3]; let array2 [4, 5, 6]; let concatenatedArray array1.concat(array2); console.log(concatenatedArray); // [1, 2, 3, 4, 5, 6]join() 把数组的所有元素放入一个字符串。元素通过指定…...

最好用的论文检索网站
网站展示: 网站链接 sci-hub文献检索 用途: 可以用文章的DOI来检索并下载文章...

AI专题:AI巨轮滚滚向前
今天分享的是电子系列深度研究报告:《AI专题:AI巨轮滚滚向前》。 (报告出品方:方正证券) 报告共计:65页 来源:人工智能学派 Gemini 1.5 Pro 性能显著增强,长上下文理解取得突破 …...

SpringBoot常见问题
1 引言 Spring Boot是一个基于Spring框架的快速开发脚手架,它简化了Spring应用的初始化和搭建过程,提供了众多便利的功能和特性,比如自动配置、嵌入式Tomcat等,让开发人员可以更加专注于业务逻辑的实现。 Spring Boot还提供了…...
五种多目标优化算法(MOAHA、MOGWO、NSWOA、MOPSO、NSGA2)性能对比,包含6种评价指标,9个测试函数(提供MATLAB代码)
一、5种多目标优化算法简介 1.1MOAHA 1.2MOGWO 1.3NSWOA 1.4MOPSO 1.5NSGA2 二、5种多目标优化算法性能对比 为了测试5种算法的性能将其求解9个多目标测试函数(zdt1、zdt2 、zdt3、 zdt4、 zdt6 、Schaffer、 Kursawe 、Viennet2、 Viennet3)ÿ…...
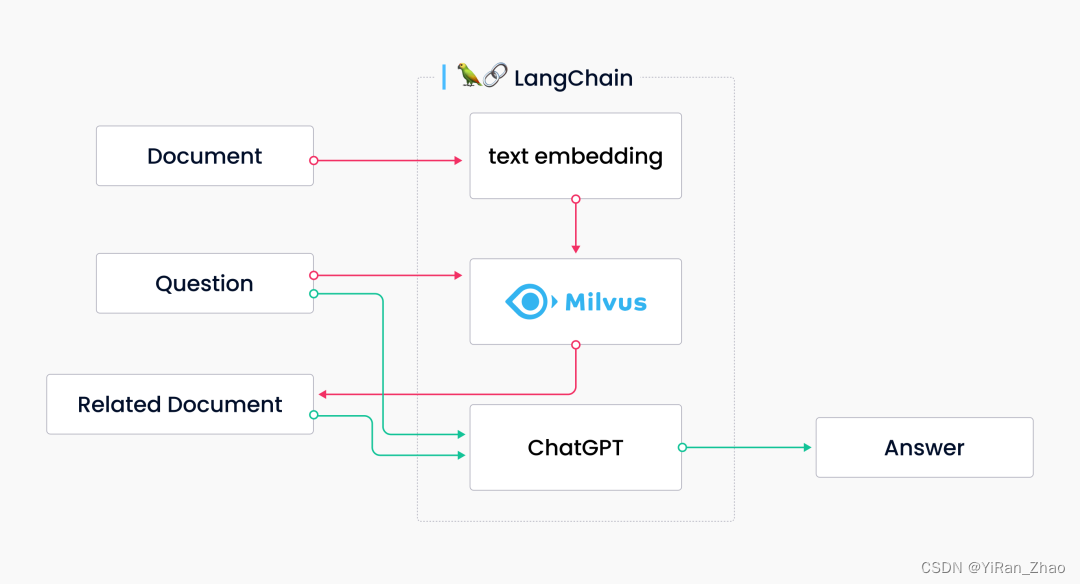
用 LangChain 和 Milvus 从零搭建 LLM 应用
如何从零搭建一个 LLM 应用?不妨试试 LangChain Milvus 的组合拳。 作为开发 LLM 应用的框架,LangChain 内部不仅包含诸多模块,而且支持外部集成;Milvus 同样可以支持诸多 LLM 集成,二者结合除了可以轻松搭建一个 LL…...
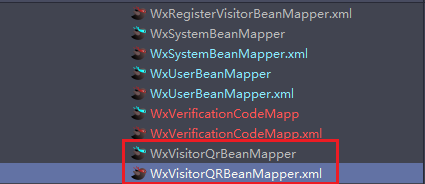
[Bug解决] Invalid bound statement (not found)出现原因和解决方法
1、问题描述 在写了一个很普通的查询语句之后,出现了下面的报错信息 org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): com.xxx.oauth.mapper.WxVisitorQrBeanMapper.selectByComIdAndEmpId at org.apache.ibatis.binding.Mappe…...
Qt:Qt3个窗口类的区别、VS与QT项目转换
一、Qt3个窗口类的区别 QMainWindow:包含菜单栏、工具栏、状态栏 QWidget:普通的一个窗口,什么也不包括 QDialog:对话框,常用来做登录窗口、弹出窗口(例如设置页面) QDialog实现简易登录界面…...

uni-app判断不同端
大家好,今天给大家分享的知识是在uni-app中如何区分是在什么端操作的程序 话不多说直接上代码: // #ifdef APP-PLUS<view>APP端</view>// #endif// #ifdef H5<view>H5端</view>// #endif// #ifdef MP<view>小程序端</v…...

计算机网络-网络设备防火墙是什么?
一、防火墙基本概念 前面我们学习了交换机、路由器是网络中常用的设备,现实中还有一个很重要的设备-防火墙。防火墙这一设备通常用于两个网络之间有针对性的、逻辑意义上的隔离。在网络通信领域,防火墙是一种安全设备。它用于保护一个网络区域免受来自另…...

Code Composer Studio (CCS) - Breakpoint (断点)
Code Composer Studio [CCS] - Breakpoint [断点] 1. BreakpointReferences 1. Breakpoint 选中断点右键 -> Breakpoint Properties… Skip Count:跳过断点总数,在断点执行之前设置总数 Current Count:当前跳过断电累计值 References […...
人工智能_普通服务器CPU_安装清华开源人工智能AI大模型ChatGlm-6B_001---人工智能工作笔记0096
使用centos安装,注意安装之前,保证系统可以联网,然后执行yum update 先去更新一下系统,可以省掉很多麻烦 20240219_150031 这里我们使用centos系统吧,使用习惯了. ChatGlm首先需要一台个人计算机,或者服务器, 要的算力,训练最多,微调次之,推理需要算力最少 其实很多都支持C…...

分层钱包HD钱包
bc1 开头的通常指的是比特币(Bitcoin)的地址,这种格式遵循了比特币改进提案BIP 0173中定义的Bech32编码格式。Bech32地址也被称为"SegWit"地址,它们支持Segregated Witness功能,这是比特币网络为了提高区块链…...

基于python+mysql的宠物领养网站系统
功能介绍 平台采用B/S结构,后端采用主流的Python语言进行开发,前端采用主流的Vue.js进行开发。 整个平台包括前台和后台两个部分。 前台功能包括:首页、宠物详情页、用户中心模块。后台功能包括:总览、领养管理、宠物管理、分类…...

机器学习入门--门控循环单元(GRU)原理与实践
GRU模型 随着深度学习领域的快速发展,循环神经网络(RNN)已成为自然语言处理(NLP)等领域中常用的模型之一。但是,在RNN中,如果时间步数较大,会导致梯度消失或爆炸的问题,…...

GitHub Actions
GitHub Actions GitHub Actions 是 GitHub 提供的一种持续集成(CI)和持续部署(CD)解决方案。它可以让你在 GitHub 仓库中直接自动化、定制化和执行软件开发工作流程。 比如,当有新的推送到仓库或者新的 Pull Request…...
harmony 鸿蒙系统学习 安装ohpm报错 ohpm install failed
一. 安装配置 DevEco Studio 安装包时报错 execute ohpm install failed. Install task failed: ArkTS 3.2.12.5. Install ArkTS dependencies failed. 解决办法 找原因,首先,我的电脑中之前安装过node,也许是因为这个。(其实…...
MySQL Replication
0 序言 MySQL Replication 是 MySQL 中的一个功能,允许从一个 MySQL 数据库服务器(称为主服务器或 master)复制数据和数据库结构到另一个服务器(称为从服务器或 slave)。这种复制是异步的,意味着从服务器不…...

redis分布式锁redisson
文章目录 1. 分布式锁1.1 基本原理和实现方式对比synchronized锁在集群模式下的问题多jvm使用同一个锁监视器分布式锁概念分布式锁须满足的条件分布式锁的实现 1.2 基于Redis的分布式锁获取锁&释放锁操作示例 基于Redis实现分布式锁初级版本ILock接口SimpleRedisLock使用示…...

并发数据结构设计与无锁编程实践
1. 并发数据结构的设计挑战与解决方案在现代多线程编程中,并发数据结构的设计一直是个棘手的问题。想象一下,你正在管理一个繁忙的机场控制塔,多架飞机同时请求降落许可,而你必须确保每架飞机都能安全降落,不会发生冲突…...
)
手把手教你用Mosquitto + PowerShell玩转MQTT消息订阅与发布(实战测试篇)
手把手教你用Mosquitto PowerShell玩转MQTT消息订阅与发布(实战测试篇) MQTT协议作为物联网领域的核心通信标准,其轻量级和发布/订阅模式为设备互联提供了高效解决方案。本文将带您通过Windows PowerShell与Mosquitto搭建完整的MQTT测试环境…...

美股软件股反弹:AI 重塑软件未来,谁能成为时代赢家?
美股软件股遭遇“集体误杀”去年 10 月底开始,美股软件股经历罕见“集体误杀”。以软件 ETF——IGV 为代表,软件板块从高位显著回撤,跌幅接近 40%。曾经的高质量成长资产软件公司,沦为 AI 浪潮下的“旧世界遗产”。恐慌源于 DeepS…...

山东甲亢专治医院哪个好
近年来,甲状腺疾病发病率呈上升趋势,甲亢因其症状多样、影响广泛,成为困扰许多人的健康问题。面对这一状况,如何在山东地区选择一家专业、可靠的医院进行诊治,是众多患者及家属关心的核心问题。专业的诊疗不仅关乎症状…...

医疗学术会议直播,和你想的不一样
从大学阶梯教室到五星级酒店宴会厅,从脊柱外科到肿瘤学术年会,VideoTV团队这3年做了30场医疗学术会议直播。有些坑踩过一次就不会再踩,有些坑每次都能遇到新花样。这篇文章不讲大道理,直接说我们在执行层面踩过哪些坑、怎么解决的…...

实战测试10款降AIGC软件:只选真正管用的那一款!
随着AI写作工具的普及,论文撰写和内容创作变得前所未有的高效,许多学生和职场人都从中受益。然而,随着AIGC检测技术的不断升级,越来越多的人开始面临新的挑战:原本流畅自然的AI生成内容,如今很容易被系统识…...
3PEAK思瑞浦 TP321-DF0R DFN1X1-4 运算放大器
特性 通用型,低成本: 增益带宽积:1MHz 低静态电流:45A/放大器 偏移电压:最大5.0毫伏 偏移电压温度漂移:2uV/C 输入偏置电流:10pA 共模抑制比/电源抑制比:90dB 单位增益稳定 轨到轨输入和输出 过驱动输入无相位反转 供电电压范围: TP321-DFOR: 2.1V 至 5.5V 其他部分…...

Unity本地化工作流:基于ULP的可维护多语言工程实践
1. 这不是“加个插件就完事”的翻译方案,而是Unity项目里真正能落地的本地化工作流 “Unity游戏自动翻译插件”——光看标题,很多人第一反应是:拖进Project窗口、点几下按钮、导出Excel、等AI吐出译文、再一键回填……然后就上线多语言了&…...
-透射(TEM)-原子力(AFM)的比较)
扫描(SEM)-透射(TEM)-原子力(AFM)的比较
SEM: 扫描电子显微镜扫描电镜成像是利用细聚焦高能电子束在样件表面激发各种物理信号,如二次电子、背散射电子等,通过相应的检测器来检测这些信号,信号的强度与样品表面形貌有一定的对应关系,因此,可将其转…...

SQL 模糊查询 + NULL 空值。LIKE 通配符 % 和_、IS NULL
前言学会精准条件查询后,工作中又会遇到新难题:需要按关键词模糊搜索,比如搜姓张、名字带 “明” 的用户,不会写 LIKE;分不清 % 和 _ 两个通配符到底有什么区别,经常用错;数据表有空值 NULL&…...