Paddlepaddle使用自己的VOC数据集训练目标检测(0废话简易教程)
一 安装paddlepaddle和paddledection(略)
笔者使用的是自己的数据集
二 在dataset目录下新建自己的数据集文件,如下:
其中
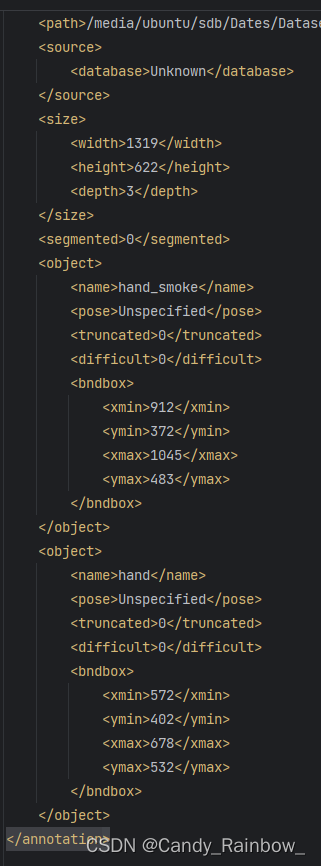
xml文件内容如下:
另外新建一个createList.py文件:
# -- coding: UTF-8 --
import os
import os.path as osp
import re
import randomdevkit_dir = '../smoke/'
years = ['2007', '2012']def get_dir(devkit_dir, type):return osp.join(devkit_dir, type)def walk_dir(devkit_dir):filelist_dir = get_dir(devkit_dir, 'ImageSets/Main')annotation_dir = get_dir(devkit_dir, 'annotations')img_dir = get_dir(devkit_dir, 'images')trainval_list = []test_list = []added = set()for _, _, files in os.walk(filelist_dir):for fname in files:img_ann_list = []if re.match('train\.txt', fname):img_ann_list = trainval_listelif re.match('val\.txt', fname):img_ann_list = test_listelse:continuefpath = osp.join(filelist_dir, fname)for line in open(fpath):name_prefix = line.strip().split()[0]if name_prefix in added:continueadded.add(name_prefix)ann_path = osp.join(annotation_dir, name_prefix + '.xml')img_path = osp.join(img_dir, name_prefix + '.jpg')assert os.path.isfile(ann_path), 'file %s not found.' % ann_pathassert os.path.isfile(img_path), 'file %s not found.' % img_pathimg_ann_list.append((img_path, ann_path))return trainval_list, test_listdef prepare_filelist(devkit_dir, output_dir):trainval_list = []test_list = []trainval, test = walk_dir(devkit_dir)trainval_list.extend(trainval)test_list.extend(test)random.shuffle(trainval_list)with open(osp.join(output_dir, 'trainval.txt'), 'w') as ftrainval:for item in trainval_list:ftrainval.write(item[0] + ' ' + item[1] + '\n')with open(osp.join(output_dir, 'test.txt'), 'w') as ftest:for item in test_list:ftest.write(item[0] + ' ' + item[1] + '\n')if __name__ == '__main__':prepare_filelist(devkit_dir, '../smoke')
一个data2tarin.py文件:
# -- coding: UTF-8 --
import os
import randomtrainval_percent = 0.9
train_percent = 0.9
xml = r"D:\Coding\PaddleDetection-release-2.7\dataset\smoke\annotations"
save_path = r"D:\Coding\PaddleDetection-release-2.7\dataset\smoke\ImageSets\Main"if not os.path.exists(save_path):os.makedirs(save_path)total_xml = os.listdir(xml)num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)print("train and val size", tv)
print("traub size", tr)
ftrainval = open(os.path.join(save_path, 'trainval.txt'), 'w')
ftest = open(os.path.join(save_path, 'test.txt'), 'w')
ftrain = open(os.path.join(save_path, 'train.txt'), 'w')
fval = open(os.path.join(save_path, 'val.txt'), 'w')for i in list:name = total_xml[i][:-4]+'\n'if i in trainval:ftrainval.write(name)if i in train:ftrain.write(name)else:fval.write(name)else:ftest.write(name)ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
运行以上两个脚本,结果如图:
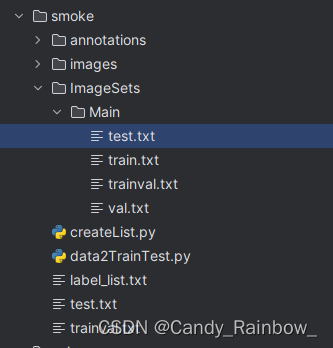
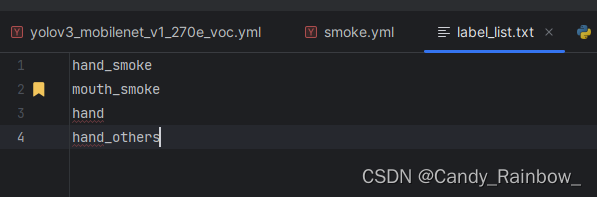
新建label_list.txt文件,内容如下,为标签文件:
三 新建smoke.yml文件
内容如下:
metric: VOC
map_type: 11point
num_classes: 4TrainDataset:name: VOCDataSetdataset_dir: dataset/smokeanno_path: trainval.txtlabel_list: label_list.txtdata_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']EvalDataset:name: VOCDataSetdataset_dir: dataset/smokeanno_path: test.txtlabel_list: label_list.txtdata_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']TestDataset:name: ImageFolderanno_path: dataset/smoke/label_list.txt
主要修改num_classes以及dataset_dir和anno_path
四 修改yolov3.yml文件,内容如下:

主要修改第一行
五 运行
![]()
六 大功告成

相关文章:
Paddlepaddle使用自己的VOC数据集训练目标检测(0废话简易教程)
一 安装paddlepaddle和paddledection(略) 笔者使用的是自己的数据集 二 在dataset目录下新建自己的数据集文件,如下: 其中 xml文件内容如下: 另外新建一个createList.py文件: # -- coding: UTF-8 -- imp…...

【解析】C语言两个实例
例一: 下面程序输出什么? int main() { int i 43; int n printf("%d\n",i); printf("%d\n",n); return 0; } 大家深入考虑一下为什么返回是3这背后有什么鲜为人知的秘密到底是C语言离奇的规定还是深思熟…...
Review on image-stitching techniques)
阅读笔记(Multimedia Systems2020)Review on image-stitching techniques
Wang Z, Yang Z. Review on image-stitching techniques[J]. Multimedia Systems, 2020, 26: 413-430. DOI https://doi.org/10.1007/s00530-020-00651-y...
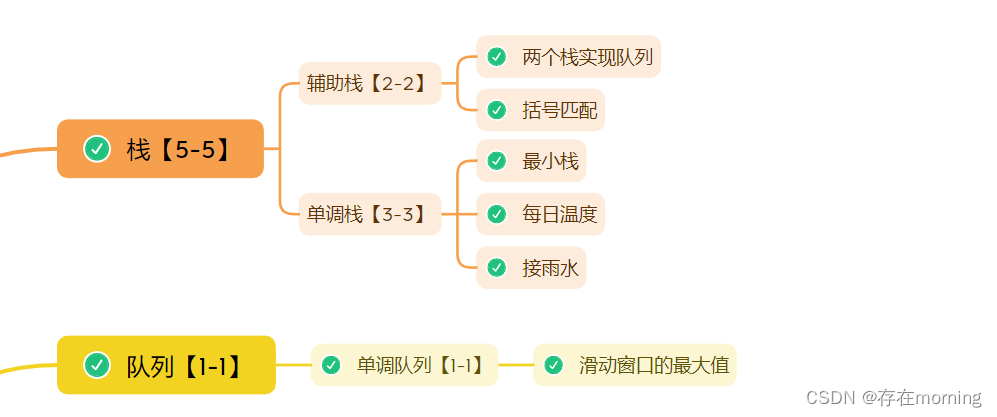
【Java程序员面试专栏 数据结构】三 高频面试算法题:栈和队列
一轮的算法训练完成后,对相关的题目有了一个初步理解了,接下来进行专题训练,以下这些题目就是汇总的高频题目,因为栈和队列这两哥们结构特性比较向对应,所以放到一篇Blog中集中练习 题目题干直接给出对应博客链接,这里只给出简单思路、代码实现、复杂度分析 题目关键字…...

Python | Conda常用命令
一、介绍 1、Anaconda工具 Anaconda是一个用于数据科学和机器学习的开源软件包管理器和环境管理器。它包含了许多流行的数据科学工具和库,如Python、Jupyter Notebook、numpy、pandas、scikit-learn等,可以帮助用户轻松地管理和安装这些工具和库。Anaco…...

Linux 驱动开发基础知识——APP 怎么读取按键值(十二)
个人名片: 🦁作者简介:学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:Vir2021GKBS 🐼本文由…...
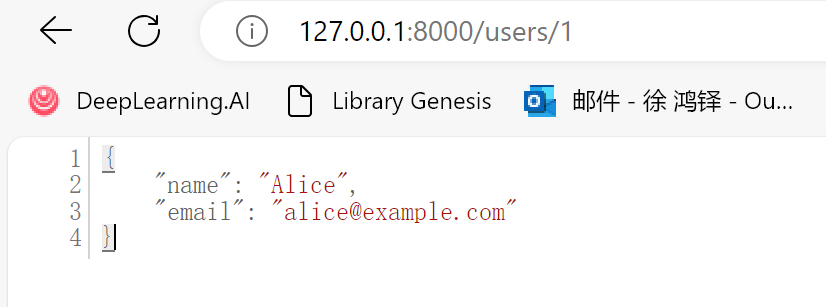
【FastAPI】P3 请求与响应
目录 请求路径参数查询参数 响应JSON 响应文本响应返回 Pydantic 模型 在网络通讯中,请求(Request) 与 响应(Response) 扮演着至关重要的角色,它们构成了客户端与服务器间互动的根本理念。 请求࿰…...
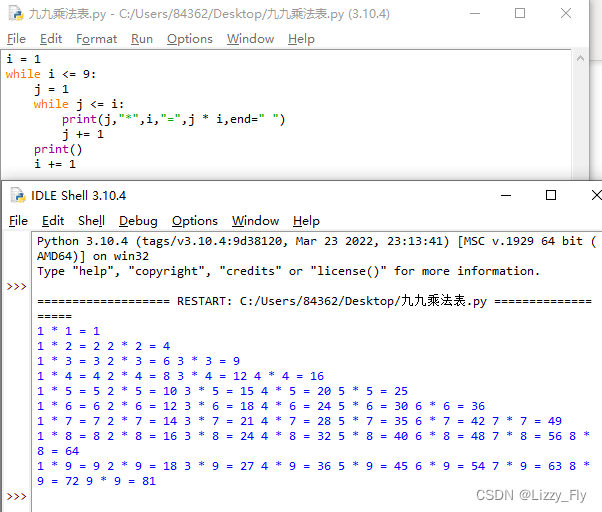
Python学习-流程图、分支与循环(branch and loop)
十、流程图 1、流程图(Flowchart) 流程图是一种用于表示算法或代码流程的框图组合,它以不同类型的框框代表不同种类的程序步骤,每两个步骤之间以箭头连接起来。 好处: 1)代码的指导文档 2)有助…...

Python Flask Web 框架学习笔记+完整项目
Flask是一个轻量级的基于Python的web框架。 我们建议使用最新版本的 Python。Flask 支持 Python 3.8 及更高版本。 官网:欢迎使用 Flask — Flask 文档 (3.0.x) (palletsprojects.com) RESTFul API:Python Flask高级编程之REST…...
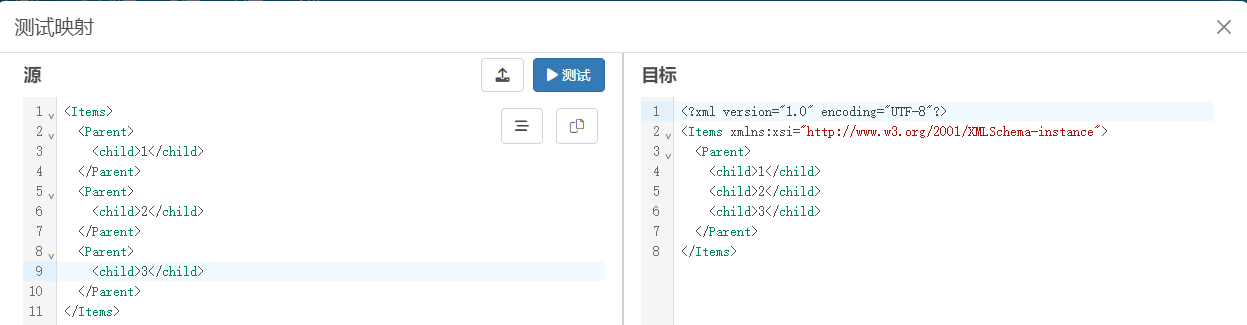
XML Map 端口进阶篇——常用关键字和格式化器详解
XML Map 端口是用于在不同XML之间建立关系映射的工具,允许通过拖拽操作实现源XML和目标 XML之间的数据字段映射,除此之外,XML Map 端口还提供了其它丰富多彩的功能,使用户能够更加灵活和高效的处理XML 数据映射任务,让…...
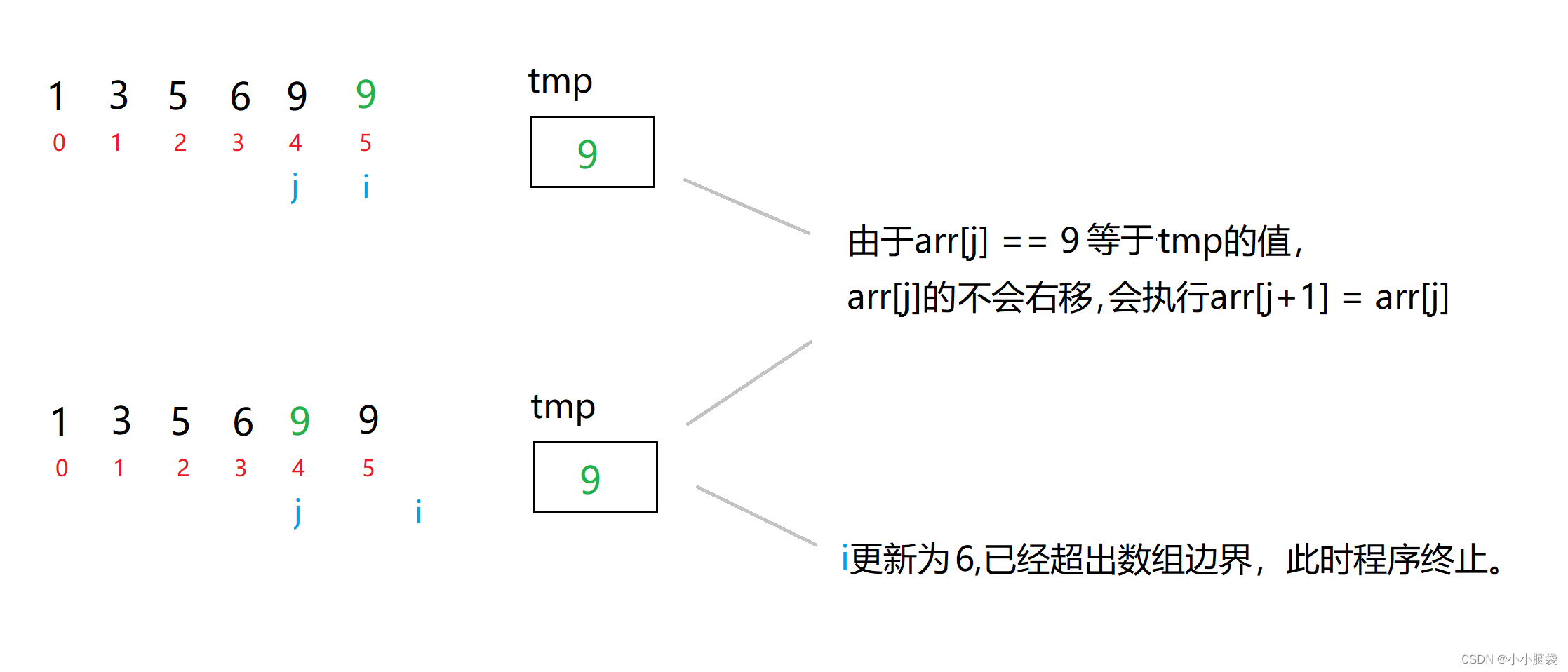
排序算法之——直接插入排序
直接插入排序——以升序排列为例 1.1基本思想1.2动态图示感知1.3静态图示详解1.4代码实现1.5时间复杂度1.5.1最好情况1.5.2最差情况 1.6空间复杂度1.7稳定性1.7.1一个小问题 1.1基本思想 把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直…...
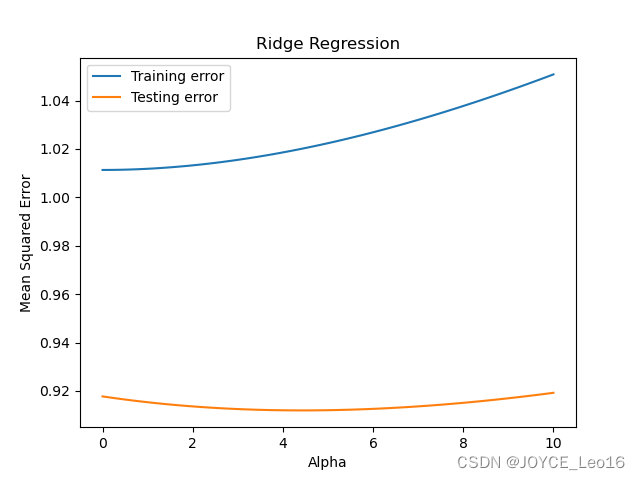
突出最强算法模型——回归算法 !!
文章目录 1、特征工程的重要性 2、缺失值和异常值的处理 (1)处理缺失值 (2)处理异常值 3、回归模型的诊断 (1)残差分析 (2)检查回归假设 (3)Cooks 距离 4、学…...
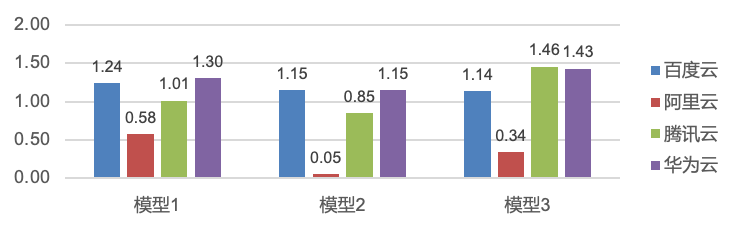
云数据库 Redis 性能深度评测(阿里云、华为云、腾讯云、百度智能云)
在当今的云服务市场中,阿里云、腾讯云、华为云和百度智能云都是领先的云服务提供商,他们都提供了全套的云数据库服务,其中 Redis属于RDS 之后第二被广泛应用的服务,本次测试旨在深入比较这四家云服务巨头在Redis云数据库性能方面的…...

Android---Retrofit实现网络请求:Java 版
简介 在 Android 开发中,网络请求是一个极为关键的部分。Retrofit 作为一个强大的网络请求库,能够简化开发流程,提供高效的网络请求能力。 Retrofit 是一个建立在 OkHttp 基础之上的网络请求库,能够将我们定义的 Java 接口转化为…...

使用静态CRLSP配置MPLS TE隧道
正文共:1591 字 13 图,预估阅读时间:4 分钟 静态CRLSP(Constraint-based Routed Label Switched Paths,基于约束路由的LSP)是指在报文经过的每一跳设备上(包括Ingress、Transit和Egress…...

gentoo安装笔记
最近比较闲,所以挑战一下自己,在自己的台式电脑上安装gentoo 下面记录了我亲自安装的步骤,作为以后我再次安装时参考所用。 整体步骤 一般来将一个linux发行版的安装步骤其实大体上都差不多,基本分为一下几步: 1. …...

Git如何使用 五分钟快速入门
Git如何使用 五分钟快速入门 Git是一个分布式版本控制系统,它可以帮助开发人员跟踪和管理项目的代码变更。与传统的集中式版本控制系统(如SVN)不同,Git允许开发人员在本地存储完整的代码仓库,并且可以独立地进行代码修…...

FreeRTOS学习笔记——(FreeRTOS临界段代码保护及调度器挂起与恢复)
这里写目录标题 1,临界段代码保护简介(熟悉)2,临界段代码保护函数介绍(掌握)3,任务调度器的挂起和恢复(熟悉) 1,临界段代码保护简介(熟悉…...
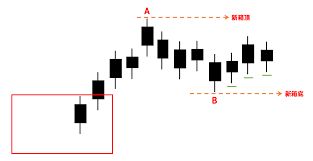
箱形理论在交易策略中的实战应用与优化
箱形理论,简单来说,就是将价格波动分成一段一段的方框,研究这些方框的高点和低点,来推测价格的趋势。 在上升行情中,价格每突破新高价后,由于群众惧高心理,可能会回跌一段,然后再上升…...
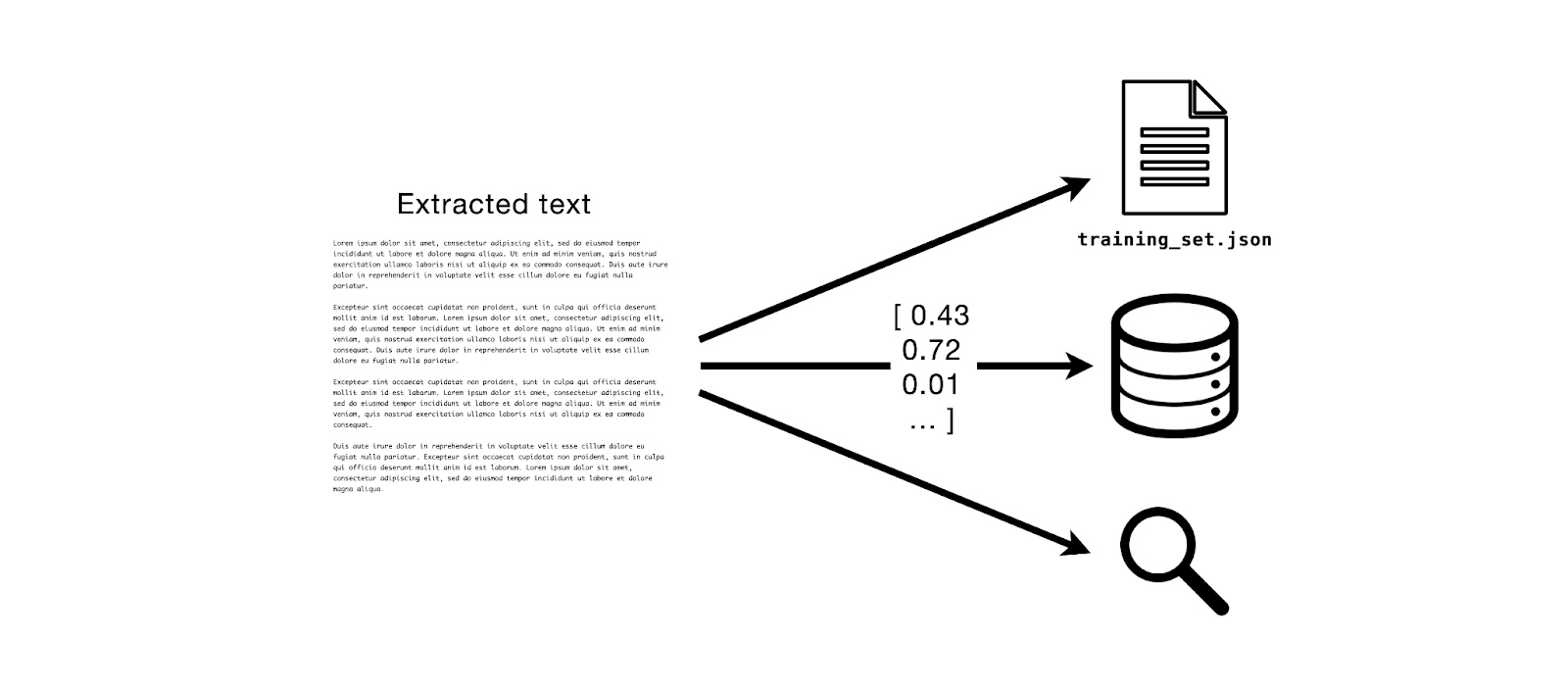
MinIO 和 Apache Tika:文本提取模式
Tl;dr: 在这篇文章中,我们将使用 MinIO Bucket Notifications 和 Apache Tika 进行文档文本提取,这是大型语言模型训练和检索增强生成 LLM和RAG 等关键下游任务的核心。 前提 假设我想构建一个文本数据集,然后我可以用它来微调 LLM.为了做…...

ViGEmBus虚拟游戏控制器驱动:Windows游戏输入终极解决方案
ViGEmBus虚拟游戏控制器驱动:Windows游戏输入终极解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 想要在Windows系统上获得完美的游戏控…...

嵌入式开发为何首选C语言?深入解析其核心优势与实战应用
1. 项目概述:嵌入式世界的“通用语”如果你刚踏入嵌入式开发的大门,或者正从其他编程领域转过来,可能会有一个疑问:为什么满世界都在用C语言?从你手上那块小小的单片机,到家里的智能路由器,再到…...

为什么AI终于能进车间了?从聊天工具到生产力,这三件事正在发生
中石化车间里的AI 2026年5月,中石化发布了"烽火"工业智能体。 这个智能体不是用来聊天的,而是能直接操作工业软件、分析生产数据、跑仿真。它是石油化工行业第一个真正能进车间的数字专家。 在这之前,AI在工业场景里的应用,大多停留在"数据分析"层面…...

Vibe Vibe 未来展望:Vibe Coding 如何彻底改变编程教育生态
Vibe Vibe 未来展望:Vibe Coding 如何彻底改变编程教育生态 【免费下载链接】vibe-vibe The First Systematic Vibe Coding Open-Source Tutorial | From Zero to Full-Stack, Empowering Everyone to Build Products with AI | Live at: www.vibevibe.cn ÿ…...

国家数据局印发《2026年数字经济发展工作要点》:八项任务背后的数据治理信号
大家好,我是独孤风。5月19日,国家数据局印发《2026年数字经济发展工作要点》。这不是一份泛泛谈数字经济的文件,而是对 2026 年数字经济工作的重点部署。从文件内容看,2026 年数字经济工作的关键词并不只是“上云、用数、用 AI”&…...

深耕 Harness 工程,解锁 AI Agent 开发之路
2026三掌柜赠书活动第三十一期 Harness工程:从上下文管理到Agent系统构建 目录 前言 详解Harness工程核心价值与独特优势 关于《Harness工程:从上下文管理到Agent系统构建》 编辑推荐 内容简介 作者简介 图书目录 《Harness工程:从上…...

k-Mode聚类算法原理与手写实现:专治分类数据的无监督学习利器
1. 项目概述:为什么k-Mode不是k-Means的“换皮版”,而是一把专治分类数据的手术刀你有没有遇到过这样的场景:手头有一批客户数据,字段全是“性别:男/女”、“城市:北京/上海/广州”、“会员等级:…...

2026年,IP地理位置精准查询的几个硬核技术变化
关于IP定位相关最近和几个同行交流,发现大家对IP定位的理解还停留在之前,想把自己这段时间的一些实践整理出来,希望能给同样在搞网络或风控的同行一些参考。 IPv6流量超过IPv4、住宅代理攻击泛滥、CGNAT覆盖越来越广……这些变化正在悄悄改变…...

Midjourney V6玻璃渲染失效?深度解析--noharsh、--style raw与refine prompt的黄金配比公式
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6玻璃渲染失效现象全景透视 Midjourney V6 在发布后显著提升了材质真实感与光照建模能力,但大量用户反馈其对玻璃、水晶、液态透明体等高折射率材质的渲染出现系统性失真&#…...

【教程】全流程基于最新导则下的生态环境影响评价技术方法及图件制作与案例实践技术应用
专题一:生态环境影响评价框架及流程 以某既包含陆域、又包含水域的项目为主要案例,兼顾其它类型项目,主要内容包括: 1、生态环境影响评价基本思路与要求:工作程序、报告编制技术要求与规范 2、资料收集与初步踏勘&a…...