大语言模型LLM中Transformer模型的调用过程与步骤
在LLM(Language Model)中,Transformer是一种用来处理自然语言任务的模型架构。下面是Transformer模型中的调用过程和步骤的简要介绍:
数据预处理:将原始文本转换为模型可以理解的数字形式。这通常包括分词、编码和填充等操作。
嵌入层(Embedding Layer):将输入的词索引转换为稠密的词向量。Transformer中,嵌入层有两个子层:位置编码和嵌入层。
编码器(Encoder):Transformer由多个编码器堆叠而成。每个编码器由两个子层组成:自注意力层(Self-Attention Layer)和前馈神经网络层(Feed-Forward Neural Network Layer)。
自注意力层:通过计算输入序列中单词之间的相互关系,为每个单词生成一个上下文相关的表示。自注意力层的输入是词嵌入和位置编码,输出是经过自注意力计算的编码。
前馈神经网络层:通过对自注意力层的输出进行一系列线性和非线性变换,得到最终的编码输出。
解码器(Decoder):与编码器类似,解码器也是多个堆叠的层,每个层由三个子层组成:自注意力层、编码器-解码器注意力层(Encoder-Decoder Attention Layer)和前馈神经网络层。
编码器-解码器注意力层:在解码器中,这一层用于获取编码器输出的信息,以帮助生成下一个单词的预测。
线性和softmax层:通过线性变换和softmax激活函数,将最终的解码器输出转换为预测的词序列。
下面是少量代码示例,展示如何在PyTorch中使用Transformer模型:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Transformerclass TransformerModel(nn.Module):def __init__(self, vocab_size, embed_dim, num_heads, num_layers):super(TransformerModel, self).__init__()self.embedding = nn.Embedding(vocab_size, embed_dim)self.transformer = nn.Transformer(d_model=embed_dim, nhead=num_heads, num_encoder_layers=num_layers)def forward(self, src):src_embed = self.embedding(src)output = self.transformer(src_embed)return output在LLM (Language Model) 中的Transformer模型中,通过以下步骤进行调用:
- 导入必要的库和模块:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
- 加载预训练模型和分词器:
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
在这个例子中,我们使用了gpt2预训练模型和对应的分词器。
- 处理输入文本:
input_text = "输入你想要生成的文本"
input_ids = tokenizer.encode(input_text, return_tensors='pt')
使用分词器的encode方法将输入文本编码为模型可接受的输入张量。
- 生成文本:
outputs = model.generate(input_ids, max_length=100, num_return_sequences=5)
使用模型的generate方法生成文本。input_ids是输入张量,max_length指定生成文本的最大长度,num_return_sequences指定生成的文本序列数量。
- 解码生成的文本:
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
使用分词器的decode方法将模型生成的输出张量解码为文本,并打印生成的文本。
在LLM中,有几个关键的概念需要理解:
- Logits:在生成文本时,模型会计算每个词的概率分布,这些概率分布被称为logits。模型生成的文本会基于这些logits进行采样。
- Tokenizer:分词器将输入的连续文本序列拆分为模型能够理解的词元(tokens)。它还提供了把模型的输出转化回文本的方法。
- Model:模型是一个神经网络,它经过预训练学习了大量的文本数据,并能够生成和理解文本。
Prompt是指在生成文本时提供给模型的初始提示。例如,给模型的输入文本是:“Once upon a time”,那么模型可能会继续生成:“there was a beautiful princess”. Prompt可以被用来引导模型生成特定的风格或内容的文本。
下面是一个完整的示例:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModeltokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')input_text = "Once upon a time"
input_ids = tokenizer.encode(input_text, return_tensors='pt')outputs = model.generate(input_ids, max_length=100, num_return_sequences=5)for output in outputs:generated_text = tokenizer.decode(output, skip_special_tokens=True)print(generated_text)
这个示例将生成以"Once upon a time"为初始提示的文本序列,并打印出5个生成的文本序列。
相关文章:
大语言模型LLM中Transformer模型的调用过程与步骤
在LLM(Language Model)中,Transformer是一种用来处理自然语言任务的模型架构。下面是Transformer模型中的调用过程和步骤的简要介绍: 数据预处理:将原始文本转换为模型可以理解的数字形式。这通常包括分词、编码和填充…...

mysql connect unblock with mysqladmin flush-hosts
原因 同一个ip在短时间内产生太多(超过max_connect_errors的最大值)中断的数据库连接而导致的阻塞。 查看 max_connect_errors show variables like max_connect_errors; 解决 前提:需要换一个IP地址连接 方法一 增大 max_connect_err…...

每日一练:前端js实现算法之两数之和
方法一:暴力法 function twoSum(nums, target) {for (let i 0; i < nums.length; i) {for (let j i 1; j < nums.length; j) {if (nums[i] nums[j] target) {return [i, j];}}}return null; }方法二:哈希表 function twoSum(nums, target) …...
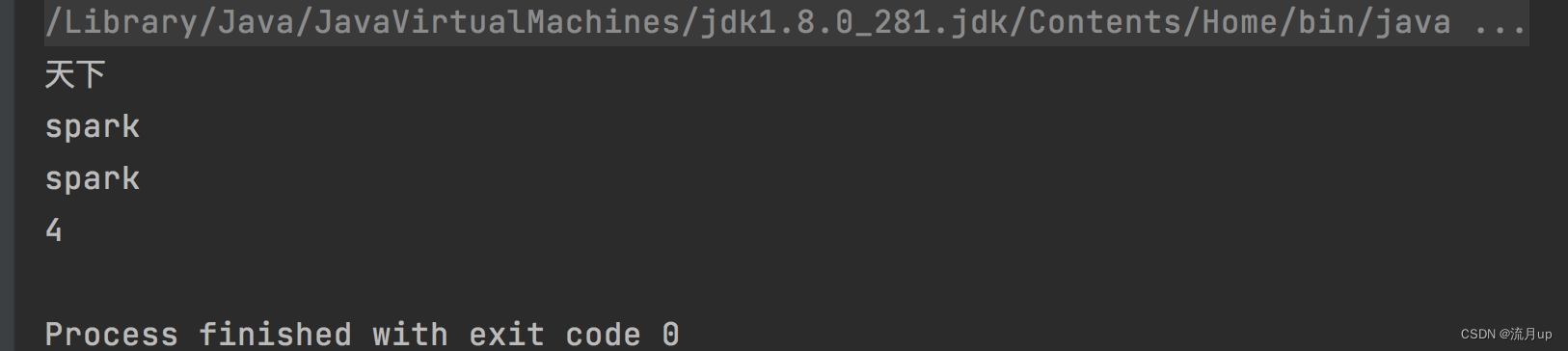
17.隐式参数的定义和使用
目录 概述实践代码执行 结束 概述 实践 代码 package com.fun.scalaobject ImplicitParamsApp {def main(args: Array[String]): Unit {say("天下")implicit val word "spark"// 多个报错 // implicit val word2 "flink"implicit val con…...

简单介绍一下WebRTC中NACK机制
WebRTC中的NACK(Negative Acknowledgement)是一种用于实时通信的网络协议,用于在传输过程中检测和纠正丢包。当接收方检测到数据包丢失时,它会发送一个NACK消息给发送方,请求重新发送丢失的数据包。 NACK的工作原理如…...
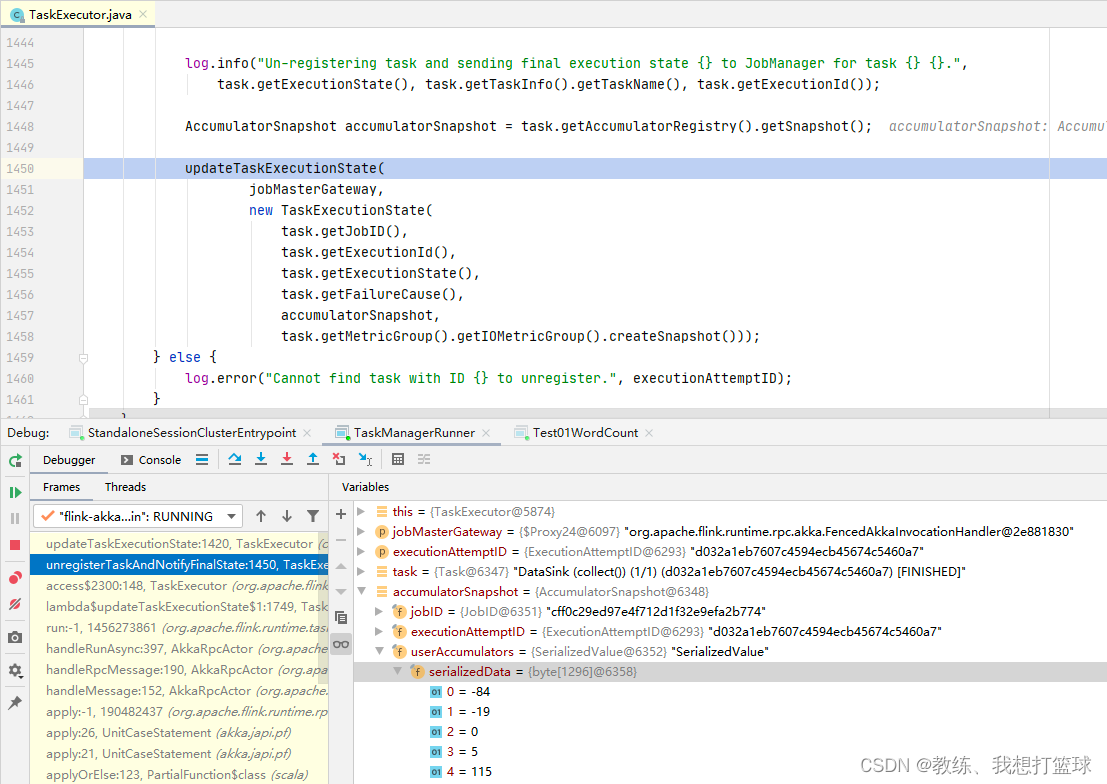
05 Flink 的 WordCount
前言 本文对应于 spark 系列的 Spark 的 WordCount 这里主要是 从宏观上面来看一下 flink 这边的几个角色, 以及其调度的整个流程 一个宏观 大局上的任务的处理, 执行 基于 一个本地的 flink 集群 测试用例 /*** com.hx.test.Test01WordCount** author Jerry.X.He* ver…...
2024云服务器ECS_云主机_服务器托管_e实例-阿里云
阿里云服务器ECS英文全程Elastic Compute Service,云服务器ECS是一种安全可靠、弹性可伸缩的云计算服务,阿里云提供多种云服务器ECS实例规格,如ECS经济型e实例、通用算力型u1、ECS计算型c7、通用型g7、GPU实例等,阿里云服务器网al…...
掌握这8大工具,自媒体ai写作之路畅通无阻! #经验分享#科技#媒体
这些宝藏AI 写作神器,我不允许你还不知道~国内外免费付费都有,还有AI写作小程序分享,大幅度提高写文章、写报告的效率,快来一起试试吧! 1.元芳写作 这是一个微信公众号 面向专业写作领域的ai写作工具,写作…...
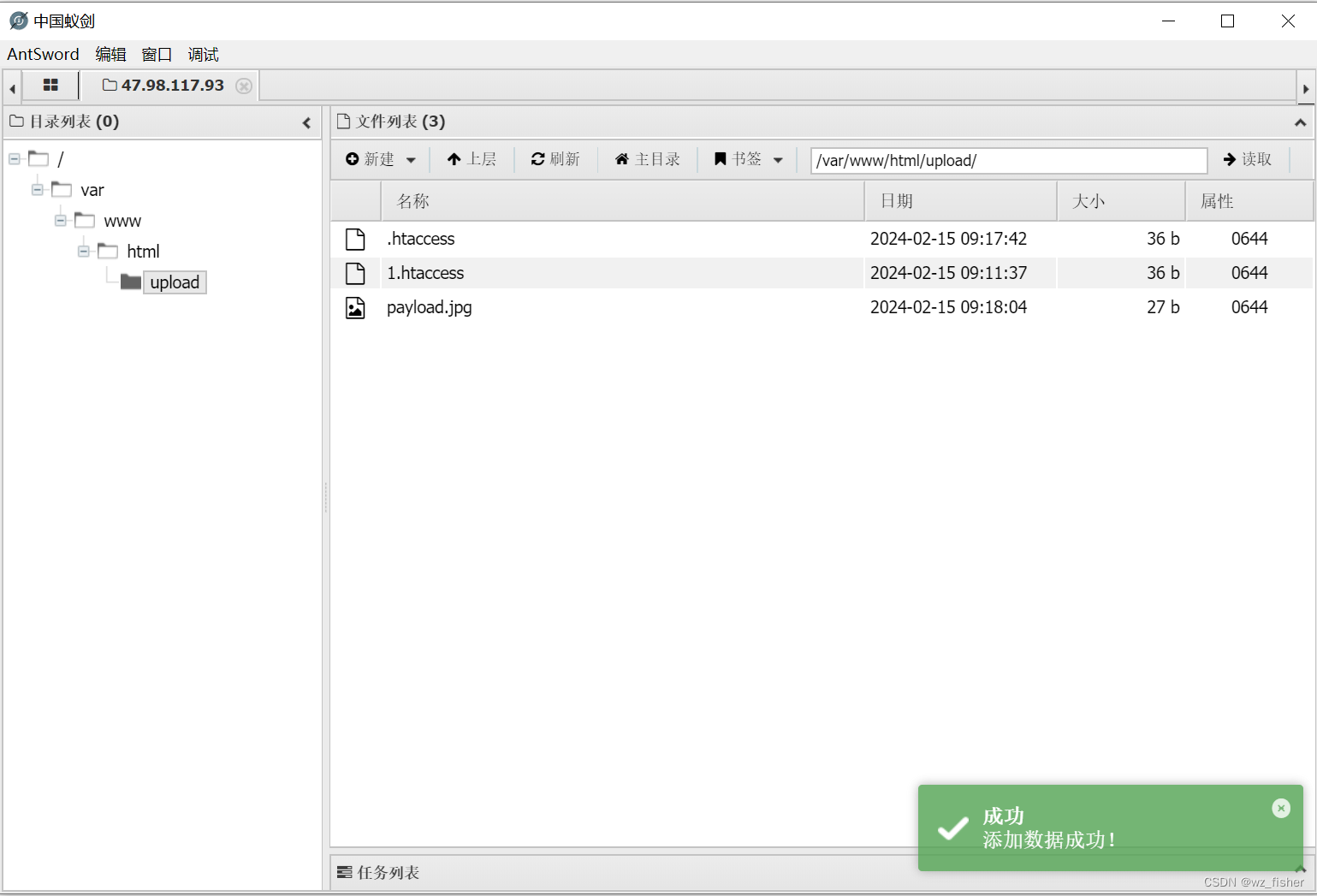
CTFHub技能树web之文件上传(一)
一.前置知识 文件上传漏洞:文件上传功能是许多Web应用程序的常见功能之一,但在实施不当的情况下,可能会导致安全漏洞。文件上传漏洞的出现可能会使攻击者能够上传恶意文件,执行远程代码,绕过访问控制等。 文件类型验证…...

蔚来面试解答
你的问题包含了多个方面,我会尽力逐一回答: 锁机制及锁膨胀过程: 锁机制是并发编程中用于控制多线程对共享资源访问的一种机制,以避免资源冲突导致的数据不一致问题。锁膨胀是指锁在运行时根据竞争情况可以升级的过程,…...

Springboot 中使用 Redisson+AOP+自定义注解 实现访问限流与黑名单拦截
🏷️个人主页:牵着猫散步的鼠鼠 🏷️系列专栏:Java全栈-专栏 🏷️个人学习笔记,若有缺误,欢迎评论区指正 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默&…...
Java使用企业邮箱发送预警邮件
前言:最近接到一个需求,需要根据所监控设备的信息,在出现问题时发送企业微信进行预警。 POM依赖 <!-- 邮件 --> <dependency><groupId>com.sun.mail</groupId><artifactId>jakarta.mail</artifactId>…...
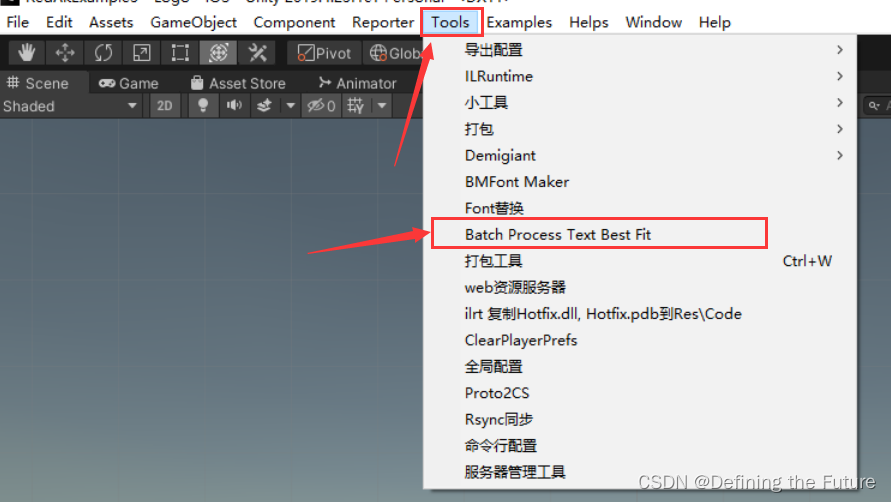
Unity编辑器扩展之是否勾选Text组件BestFit选项工具(此篇教程也可以操作其他组件的属性)
想要批量化是否勾选项目预制体资源中Text组件BestFit属性(此篇教程也可以操作其他组件的属性,只不过需要修改其中对应的代码),可以采用以下步骤。 1、在项目的Editor文件中,新建一个名为TextBestFitBatchProcessor的…...

分布式场景怎么Join | 京东云技术团队
背景 最近在阅读查询优化器的论文,发现System R中对于Join操作的定义一般分为了两种,即嵌套循环、排序-合并联接。在原文中,更倾向使用排序-合并联接逻辑。 考虑到我的领域是在处理分库分表或者其他的分区模式,这让我开始不由得…...

24-k8s的附件组件-Metrics-server组件与hpa资源pod水平伸缩
一、概述 Metrics-Server组件目的:获取集群中pod、节点等负载信息; hpa资源目的:通过metrics-server获取的pod负载信息,自动伸缩创建pod; 参考链接: 资源指标管道 | Kubernetes https://github.com/kuberne…...
)
Spring RabbitMQ 配置多个虚拟主机(vhost)
文章目录 前言一、相关文章二、相关代码1.yml文件配置2.RabbitMq配置类3.接收MQ消息前言 在日常开发中,同时需要用到RabbitMQ多个虚拟机(vhost)。应用场景:需要接收多个交换机的数据,而交换机都在不同的虚拟机(vhost) 一、相关文章 Docker安装RabbitMQ 【SpringCloud…...
「Qt Widget中文示例指南」如何实现文档查看器?(一)
Qt 是目前最先进、最完整的跨平台C开发工具。它不仅完全实现了一次编写,所有平台无差别运行,更提供了几乎所有开发过程中需要用到的工具。如今,Qt已被运用于超过70个行业、数千家企业,支持数百万设备及应用。 文档查看器是一个显…...
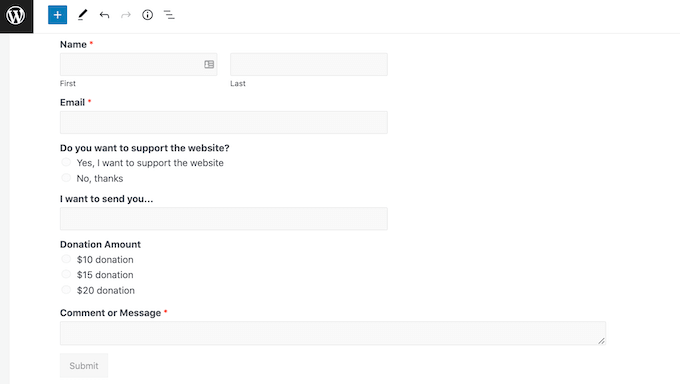
如何创建WordPress付款表单(简单方法)
您是否正在寻找一种简单的方法来创建付款功能WordPress表单? 小企业主通常需要创建一种简单的方法来在其网站上接受付款,而无需设置复杂的购物车。简单的付款表格使您可以轻松接受自定义付款金额、设置定期付款并收集自定义详细信息。 在本文中&#x…...
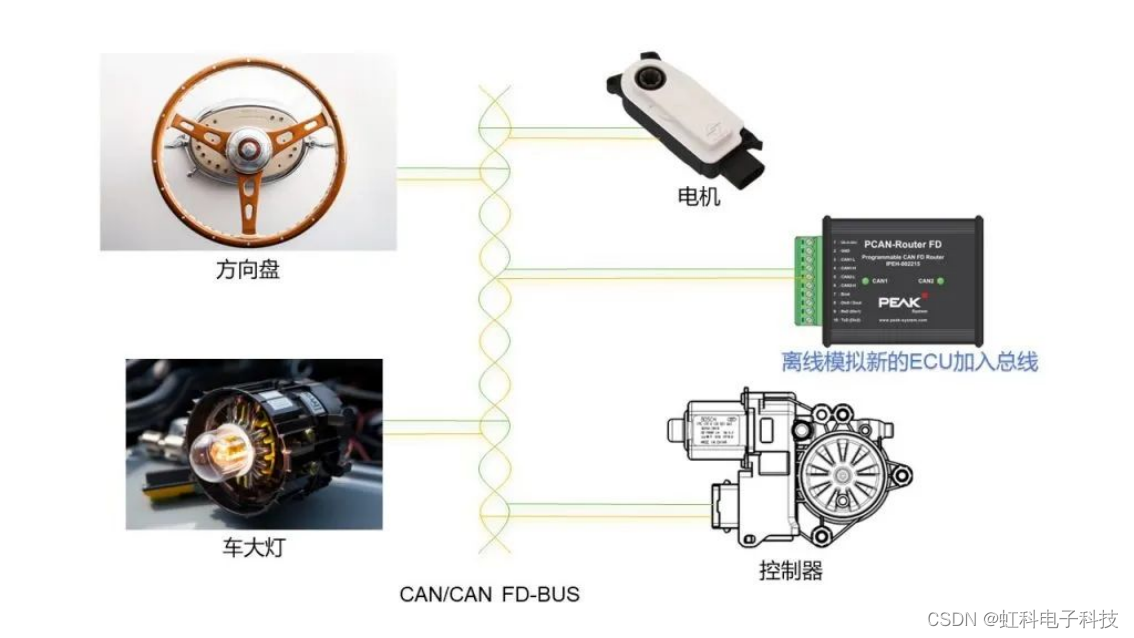
虹科方案 | 释放总线潜力:汽车总线离线模拟解决方案
来源:虹科汽车智能互联 虹科方案 | 释放总线潜力:汽车总线离线模拟解决方案 原文链接:https://mp.weixin.qq.com/s/KGv2ZOuQMLIXlOiivvY6aQ 欢迎关注虹科,为您提供最新资讯! #汽车总线 #ECU #汽车网关 导读 传统的…...

欲速则不达,慢就是快!
引言 随着生活水平的提高,不少人的目标从原先的解决温饱转变为追求内心充实,但由于现在的时间过得越来越快以及其他外部因素,我们对很多东西的获取越来越没耐心,例如书店经常会看到《7天精通Java》、《3天掌握XXX》等等之类的书籍…...
如何快速实现Windows任务栏透明化:TranslucentTB终极美化指南
如何快速实现Windows任务栏透明化:TranslucentTB终极美化指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB TranslucentTB是…...

企业AI知识库搭建实战:从文件管理到智能检索的完整方案
2025年我们团队做过一个调研,找了37家用了AI知识库的企业,发现一个有意思的规律:真正用起来的不到1/3,剩下2/3基本都卡在同一个地方——知识库和文件管理系统是割裂的。 你让员工把文件再上传一遍到知识库?没人干。你让…...

如何快速解锁QQ音乐加密音频的完整指南:QMCDecode工具终极解决方案
如何快速解锁QQ音乐加密音频的完整指南:QMCDecode工具终极解决方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录&…...
)
AI实时翻译实现BurpSuite中文界面(无需修改源码)
1. 这不是简单的“改个语言”,而是BurpSuite中文生态的破冰点你有没有在刚打开BurpSuite时,面对满屏英文菜单、弹窗提示和错误日志,下意识地去翻找Settings → User Interface → Language,却发现下拉框里只有English、Franais、D…...

Unity UGUI三大Layout Group核心原理与工程实践
1. 为什么这三个Layout Group是Unity UI开发的“地基级”组件,而不是可有可无的装饰品?在Unity里做UI,很多人第一反应是拖控件、调锚点、手动改RectTransform——这就像盖房子不打地基,先砌墙再想承重。我带过十几期新人训练营&am…...

2026年企业AI落地新趋势!RAG知识库实战指南:环境搭建到生产部署全解析
本文介绍了RAG(检索增强生成)技术在企业知识库中的应用,通过从环境搭建到生产部署的完整实战指南,阐述如何利用RAG提升大语言模型回答的准确性、可追溯性和时效性。文章涵盖了基础环境配置、技术选型、数据准备、知识库构建、RAG系…...

别再手动Cherry-pick了!用IDEA的Squash功能,3步合并Git提交历史
告别零碎Commit:IDEA交互式变基实战指南 在团队协作开发中,每个开发者都经历过这样的场景:为了修复一个看似简单的Bug,你在本地分支上提交了五六个"WIP"(Work in Progress)或"fix typo"…...
)
告别ifconfig!用ip命令和ethtool搞定Linux网卡状态排查(附实战案例)
告别ifconfig!用ip命令和ethtool搞定Linux网卡状态排查(附实战案例) 在Linux服务器运维中,网络故障排查是最常见的任务之一。记得去年深夜处理一次线上事故时,面对一台突然失联的数据库服务器,我习惯性地敲…...

从MySQL分区到OceanBase分区:迁移老手教你平滑过渡与性能调优
从MySQL分区到OceanBase分区:迁移老手教你平滑过渡与性能调优 当MySQL分区表遇上OceanBase分布式架构,传统设计思维往往成为性能瓶颈的源头。本文将揭示两种数据库分区机制的本质差异,并提供一套经过生产验证的迁移方法论,帮助您避…...

FARM问答系统调优终极指南:置信度校准与答案排序策略详解
FARM问答系统调优终极指南:置信度校准与答案排序策略详解 【免费下载链接】FARM :house_with_garden: Fast & easy transfer learning for NLP. Harvesting language models for the industry. Focus on Question Answering. 项目地址: https://gitcode.com/g…...