logback实践
1:日志区分环境
2:debug info warn error日志文件不一样
3: 文件滚动日志
4:启动可带参数 --spring.profiles.active=dev --log.level=info
5:可从配置文件中获取上下文参数
logback-spring.xml 放在 classpath 下面
<configuration scan="false" scanPeriod="30 seconds" debug="true"><springProperty scope="context" name="LOG_ROOT" source="log.path" defaultValue="/usr/log"/><springProperty scope="context" name="APP_NAME" source="spring.application.name" defaultValue="default"/><springProperty scope="context" name="LOG_LEVEL" source="log.level" defaultValue="INFO"/><!-- 设置日志格式 --><property name="LOG_PATTERN" value="[%date{ISO8601}] [%-5level] [%thread] [%X{ltid}] [%logger{0}.%M-%L] - %msg%n"/><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><target>System.out</target><encoder><pattern>${LOG_PATTERN}</pattern><charset>UTF-8</charset></encoder></appender><appender name="debug" class="ch.qos.logback.core.rolling.RollingFileAppender"><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><pattern>${LOG_PATTERN}</pattern><charset>UTF-8</charset></encoder><file>${LOG_ROOT}/${APP_NAME}/debug.log</file><!-- 滚动日志策略: SizeAndTimeBasedRollingPolicy 根据文件大小和时间进行分割归档--><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 指定滚动文件名称的生成规则 --><fileNamePattern>${LOG_ROOT}/${APP_NAME}/debug.%d{yyyy-MM-dd}.%i.log</fileNamePattern><!-- 超过最大磁盘限制后是否删除归档文件 --><cleanHistoryOnStart>true</cleanHistoryOnStart><!-- 单个日志文件大小 --><maxFileSize>20MB</maxFileSize><!-- <maxFileSize>1KB</maxFileSize>--><!-- 归档文件占用磁盘总大小,超过后会根据cleanHistoryOnStart实行,决定是否删除 --><totalSizeCap>1GB</totalSizeCap><!-- <totalSizeCap>10KB</totalSizeCap>--><!-- 保留的历史归档日志文件天数--><maxHistory>30</maxHistory></rollingPolicy><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>DEBUG</level><onMatch>ACCEPT</onMatch><onMismatch>DENY</onMismatch></filter></appender><appender name="info" class="ch.qos.logback.core.rolling.RollingFileAppender"><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><pattern>[%date{ISO8601}] [%-5level] [%thread] [%X{ltid}] [%logger-%L] - %msg%n</pattern><charset>UTF-8</charset></encoder><file>${LOG_ROOT}/${APP_NAME}/info.log</file><!-- 滚动日志策略: SizeAndTimeBasedRollingPolicy 根据文件大小和时间进行分割归档--><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 指定滚动文件名称的生成规则 --><fileNamePattern>${LOG_ROOT}/${APP_NAME}/info.%d{yyyy-MM-dd}.%i.log</fileNamePattern><!-- 超过最大磁盘限制后是否删除归档文件 --><cleanHistoryOnStart>true</cleanHistoryOnStart><!-- 单个日志文件大小 --><maxFileSize>20MB</maxFileSize><!-- <maxFileSize>1KB</maxFileSize>--><!-- 归档文件占用磁盘总大小,超过后会根据cleanHistoryOnStart实行,决定是否删除 --><totalSizeCap>1GB</totalSizeCap><!-- <totalSizeCap>10KB</totalSizeCap>--><!-- 保留的历史归档日志文件天数--><maxHistory>30</maxHistory></rollingPolicy><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>INFO</level><onMatch>ACCEPT</onMatch><onMismatch>DENY</onMismatch></filter></appender><appender name="warn" class="ch.qos.logback.core.rolling.RollingFileAppender"><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><pattern>[%date{ISO8601}] [%-5level] [%thread] [%X{ltid}] [%logger-%L] - %msg%n</pattern><charset>UTF-8</charset></encoder><file>${LOG_ROOT}/${APP_NAME}/warn.log</file><!-- 滚动日志策略: SizeAndTimeBasedRollingPolicy 根据文件大小和时间进行分割归档--><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 指定滚动文件名称的生成规则 --><fileNamePattern>${LOG_ROOT}/${APP_NAME}/warn.%d{yyyy-MM-dd}.%i.log</fileNamePattern><!-- 超过最大磁盘限制后是否删除归档文件 --><cleanHistoryOnStart>true</cleanHistoryOnStart><!-- 单个日志文件大小 --><maxFileSize>20MB</maxFileSize><!-- <maxFileSize>1KB</maxFileSize>--><!-- 归档文件占用磁盘总大小,超过后会根据cleanHistoryOnStart实行,决定是否删除 --><totalSizeCap>1GB</totalSizeCap><!-- <totalSizeCap>10KB</totalSizeCap>--><!-- 保留的历史归档日志文件天数--><maxHistory>30</maxHistory></rollingPolicy><filter class="ch.qos.logback.classic.filter.LevelFilter"><level>WARN</level><onMatch>ACCEPT</onMatch><onMismatch>DENY</onMismatch></filter></appender><appender name="error" class="ch.qos.logback.core.rolling.RollingFileAppender"><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><pattern>${LOG_PATTERN}</pattern><charset>UTF-8</charset></encoder><file>${LOG_ROOT}/${APP_NAME}/error.log</file><!-- 滚动日志策略: SizeAndTimeBasedRollingPolicy 根据文件大小和时间进行分割归档--><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!-- 指定滚动文件名称的生成规则 --><fileNamePattern>${LOG_ROOT}/${APP_NAME}/error.%d{yyyy-MM-dd}.%i.log</fileNamePattern><!-- 超过最大磁盘限制后是否删除归档文件 --><cleanHistoryOnStart>true</cleanHistoryOnStart><!-- 单个日志文件大小 --><maxFileSize>20MB</maxFileSize><!-- <maxFileSize>1KB</maxFileSize>--><!-- 归档文件占用磁盘总大小,超过后会根据cleanHistoryOnStart实行,决定是否删除 --><totalSizeCap>1GB</totalSizeCap><!-- <totalSizeCap>10KB</totalSizeCap>--><!-- 保留的历史归档日志文件天数--><maxHistory>30</maxHistory></rollingPolicy><filter class="ch.qos.logback.classic.filter.ThresholdFilter"><level>ERROR</level></filter></appender><!-- 级别依次为【从高到低】:FATAL > ERROR > WARN > INFO > DEBUG > TRACE --><springProfile name="txtest,txprod,prod,test"><root level="${LOG_LEVEL}"><!--日志输出到文件--><appender-ref ref="debug"/><appender-ref ref="info"/><appender-ref ref="warn"/><appender-ref ref="error"/></root></springProfile><!-- 本地、开发环境,日志配置 可以写logback支持的所有节点 --><springProfile name="local,dev"><root level="${LOG_LEVEL}"><!--控制台日志:生产环境建议关掉--><appender-ref ref="STDOUT"/><appender-ref ref="debug"/><appender-ref ref="info"/><appender-ref ref="warn"/><appender-ref ref="error"/></root><!-- 一般dao操作被项目封装可以设置项目上的封装路径--><logger name="com.ikeeper.mapper.base" level="debug"/></springProfile><!--打印SQL--><!-- <logger name="java.sql.Connection" level="DEBUG"/>--><!-- <logger name="java.sql.Statement" level="DEBUG"/>--><!-- <logger name="java.sql.PreparedStatement" level="DEBUG"/>--><!-- 一般dao操作被项目封装可以设置项目上的封装路径--><!-- <logger name="com.ikeeper.mapper.base" level="debug"/>--></configuration>
相关文章:

logback实践
1:日志区分环境 2:debug info warn error日志文件不一样 3: 文件滚动日志 4:启动可带参数 --spring.profiles.activedev --log.levelinfo 5:可从配置文件中获取上下文参数 logback-spring.xml 放在 classpath 下面 <configuration scan"false" scanPer…...

深入理解java虚拟机---自动内存管理
2.2 运行时数据区域 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而一直存在,有些区域则是依赖用户线程的启动和结束而建立和销…...
)
粉笔规范词积累(文化发展)
活态保护/活态传承 基本释义 是在文化遗产生成发展的环境当中进行保护和传承,在人民群众生产生活过程中进行传承与发展。 应用场景 当资料中出现“让文化遗产不仅‘活’在历史中,更‘活’在人们的生产生活中”等类似表述,可概括为“活态保…...
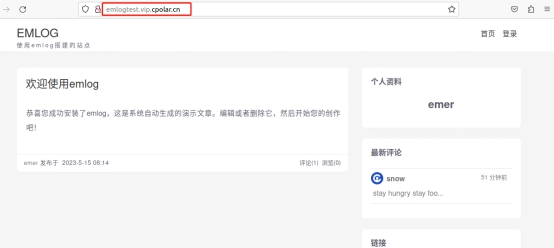
如何在Ubuntu部署Emlog,并将本地博客发布至公网可远程访问
文章目录 前言1. 网站搭建1.1 Emolog网页下载和安装1.2 网页测试1.3 cpolar的安装和注册 2. 本地网页发布2.1 Cpolar临时数据隧道2.2.Cpolar稳定隧道(云端设置)2.3.Cpolar稳定隧道(本地设置) 3. 公网访问测试总结 前言 博客作为使…...

Axios
Axios简介 axios框架全称(ajax – I/O – system): 基于promise用于浏览器和node.js的http客户端,因此可以使用Promise API 一、axios是干啥的 说到axios我们就不得不说下Ajax。在旧浏览器页面在向服务器请求数据时࿰…...

数据仓库选型建议
1 数仓分层 1.1 数仓分层的意义 **数据复用,减少重复开发:**规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。数据的逐层加工原则,下层包含了上层数据加工所需要的全量数据,这样的加工方…...

每日一题——LeetCode1470.重新排列数组
方法一 把数组的前n项看做一个数组,后n项看做一个数组,两个数组循环先后往res里push元素 var shuffle function(nums, n) {let res[]for(let i0;i<n;i){res.push(nums[i])res.push(nums[in])}return res }; 消耗时间和内存情况: 方法二…...
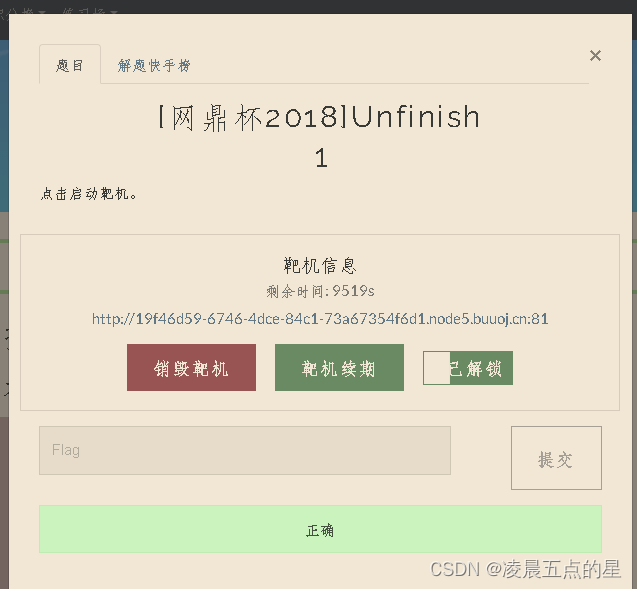
网络安全--网鼎杯2018漏洞复现(二次注入)
一、环境:在线测试平台 BUUCTF在线评测 (buuoj.cn) 二、进入界面先尝试万能账号 1or11# 换格式 hais1bux1 11or11# 三、万能的不行那我们就得想注册了,去register.php去看看 注册个账号 发现用户名回显,猜测考点为用户名处二次注入&…...
CSS篇--transform
CSS篇–transform 使用transform属性实现元素的位移、旋转、缩放等效果 位移 // 语法 transform:translate(水平移动距离,垂直移动距离) translate() 如果只给一个值,表示x轴方法移动距离 单独设置某个方向的移动距离:translateX() transla…...
阿里云国际-在阿里云服务器上快速搭建幻兽帕鲁多人服务器
幻兽帕鲁是最近流行的新型生存游戏。该游戏一夜之间变得极为流行,同时在线玩家数量达到了200万。然而,幻兽帕鲁的服务器难以应对大量玩家的压力。为解决这一问题,幻兽帕鲁允许玩家建立专用服务器,其提供以下优势: &am…...

vite 快速搭建 Vue3.0项目
一、初始化项目 npm create vite-app <project name>二、进入项目目录 cd ……三、安装依赖 npm install四、启动项目 npm run dev五、配置项目 安装 typescript npm add typescript -D初始化 tsconfig.json //执行命令 初始化 tsconfig.json npx tsc --init …...

深入理解Python爬虫的Response对象
源码分享 https://docs.qq.com/sheet/DUHNQdlRUVUp5Vll2?tabBB08J2 在构建Python爬虫时,理解HTTP响应(Response)是至关重要的。本篇博客将详细介绍如何使用Python的Requests库来处理HTTP响应,并通过详细的代码案例指导你如何提取…...

centos7下docker的安装
背景 总结下docker的一些知识 docker安装(有网络版) 参考文章我以前试过这个帖子,建议安装高版本的docker,(20以上的,不然可能会有一些问题) ## 1、安装依赖 [rootiZo7e61fz42ik0Z ~]#yum i…...

Excel SUMPRODUCT函数用法(乘积求和,分组排序)
SUMPRODUCT函数是Excel中功能比较强大的一个函数,可以实现sum,count等函数的功能,也可以实现一些基础函数无法直接实现的功能,常用来进行分类汇总,分组排序等 SUMPRODUCT 函数基础 SUMPRODUCT函数先计算多个数组的元素之间的乘积…...

C#上位机与三菱PLC的通信08---开发自己的通讯库(A-1E版)
1、A-1E报文回顾 具体细节请看: C#上位机与三菱PLC的通信03--MC协议之A-1E报文解析 C#上位机与三菱PLC的通信04--MC协议之A-1E报文测试 2、为何要开发自己的通讯库 前面使用了第3方的通讯库实现了与三菱PLC的通讯,实现了数据的读写,对于通…...

ABAQUS应用04——集中质量的添加方法
文章目录 0. 背景1. 集中质量的编辑2. 约束的设置3. 总结 0. 背景 混塔ABAQUS模型中,机头、法兰等集中质量的设置是模型建立过程中的一部分,需要研究集中质量的添加。 1. 集中质量的编辑 集中质量本身的编辑没什么难度,我已经用Python代码…...
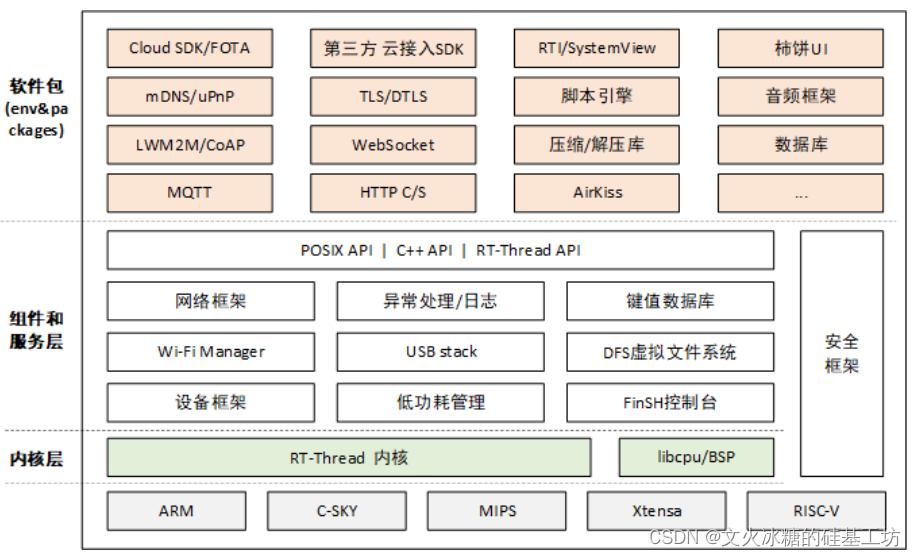
[嵌入式系统-24]:RT-Thread -11- 内核组件编程接口 - 网络组件 - TCP/UDP Socket编程
目录 一、RT-Thread网络组件 1.1 概述 1.2 RT-Thread支持的网络协议栈 1.3 RT-Thread如何选择不同的网络协议栈 二、Socket编程 2.1 概述 2.2 UDP socket编程 2.3 TCP socket编程 2.4 TCP socket收发数据 一、RT-Thread网络组件 1.1 概述 RT-Thread 是一个开源的嵌入…...
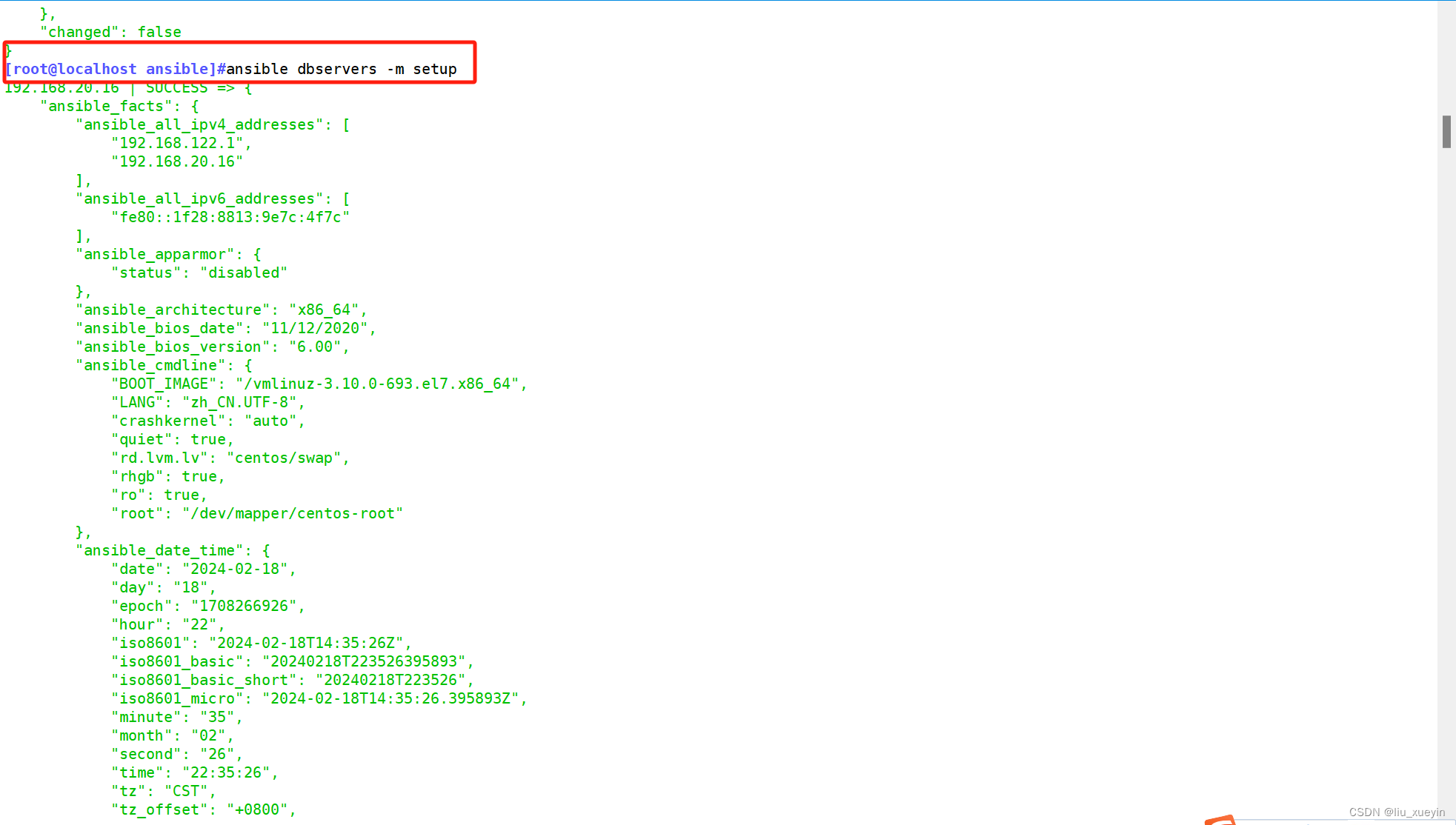
【ansible】认识ansible,了解常用的模块
目录 一、ansible是什么? 二、ansible的特点? 三、ansible与其他运维工具的对比 四、ansible的环境部署 第一步:配置主机清单 第二步:完成密钥对免密登录 五、ansible基于命令行完成常用的模块学习 模块1:comma…...
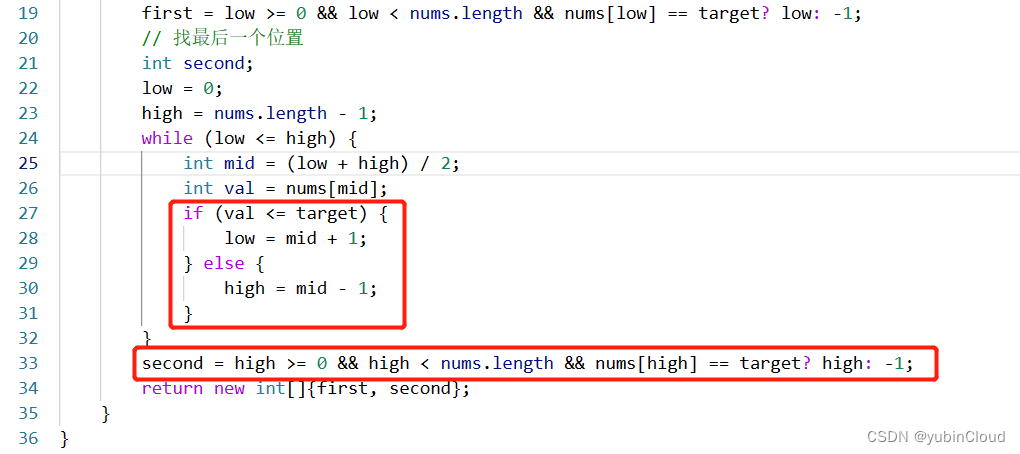
【LeetCode】升级打怪之路 Day 01:二分法
今日题目: 704. 二分查找35. 搜索插入位置34. 在排序数组中查找元素的第一个和最后一个位置 目录 今日总结Problem 1: 二分法LeetCode 704. 二分查找 【easy】LeetCode 35. 搜索插入位置 ⭐⭐⭐⭐⭐LeetCode 34. 在排序数组中查找元素的第一个和最后一个位置 【medi…...
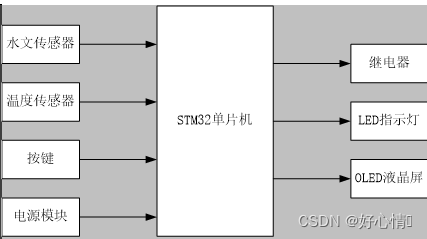
单片机stm32智能鱼缸
随着我国经济的快速发展而给人们带来了富足的生活,也有越来越多的人们开始养鱼,通过养各种鱼类来美化居住环境和缓解压力。但是在鱼类饲养过程中,常常由于鱼类对水质、水位及光照强度有着很高的要求,而人们也由于工作的方面而无法…...

Heavy Fighter动画包:Unity战斗系统根运动与状态机深度解析
1. 这套动画包不是“拿来就能用”的资源,而是需要你亲手校准的战斗系统骨架我在2021年接手一个横版ARPG项目时,美术总监甩给我三套Mecanim动画包,其中一套就是Heavy Fighter Mecanim Animation Pack。当时我第一反应是“终于不用手调IK了”&a…...

MPV_lazy终极指南:如何用懒人包快速提升视频播放体验?
MPV_lazy终极指南:如何用懒人包快速提升视频播放体验? 【免费下载链接】mpv_PlayKit 🔄 mpv player 播放器折腾记录 Windows conf | 中文注释配置 汉化文档 快速帮助入门 | mpv-lazy 懒人包 Win11 x64 config | 着色器 shader 滤镜 filter 整…...

一文搞懂:Git分支管理与团队协作规范——从GitFlow到GitHub Flow,从rebase到merge,打造高效协作流
📌 写在前面以前自己一个人写项目的时候,Git对我来说就是个“高级另存为”:一个master分支从头走到尾,写完就git push,从没觉得分支管理有什么难的。直到最近和朋友一起开发一个项目,问题来了:他…...
)
大型房地产集团战略规划数字化转型PMO项目进度管理解决方案(PPT)
导读 有一个问题值得认真想一想:一家布局全国、同时管理几十个楼盘的大型地产集团,它的"项目管理"问题,究竟出在哪里? 不是因为缺人,也不是因为团队不努力。事实上,大多数地产集团在规模扩张到一…...

剪映专业版教程:制作数据结构快速排序算法原理演示视频
前言 今天教大家用剪映制作数据结构快速排序算法的原理演示视频。一趟冒泡排序只能使一个元素排序到位,而快速排序在一趟操作后不仅能使某个元素排序到位,还能将序列划分为两个子序列——所有比该元素小的都在左边,所有比该元素大的都在右边…...
”)
超自动化运维,您需要的是“可信执行平台(TEP)”
在AI智能体与自动化工具蓬勃发展的今天,各类开源框架与轻量工具层出不穷。它们让“用自然语言驱动电脑做事”的愿景触手可及——文件操作、脚本执行、浏览器控制,一切看似高效便捷。然而,当我们将视线从个人桌面转向企业的数据中心、核心生产…...

Claude Citations API 实战:让模型自动标注引用来源,RAG 准确率提升 15%
Claude Citations API 实战:让模型自动标注引用来源,RAG 准确率提升 15% 做 RAG(检索增强生成)的工程师都遇到过这种灵魂提问: “你这个回答到底是从哪段文档里得出来的?” 这个问题之所以致命,…...

如何快速掌握ComfyUI_InstantID:从零到一的AI人脸编辑完整实战指南
如何快速掌握ComfyUI_InstantID:从零到一的AI人脸编辑完整实战指南 【免费下载链接】ComfyUI_InstantID 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_InstantID 在AI图像生成领域,保持特定人物身份的同时实现风格转换一直是个技术挑战…...

影刀RPA跨境店群运营架构:TikTok Shop多节点高并发调度与Python环境隔离实战
大家好,我是林焱。 太有意思了,刚刷朋友圈,看到一个在跨境圈子里被疯狂转发的消息。 有几个当年和我一样,在南充念工程测量技术出身的 00 后学弟,最近跑回母校干了件特别硬核的事。 他们没有像传统的成功校友那样&a…...
:当 Agent 拥有了物理世界的身体)
具身智能(Embodied AI):当 Agent 拥有了物理世界的身体
具身智能(Embodied AI):当Agent拥有了物理世界的身体,下一个十年的科技革命? 一、引言 (Introduction) 钩子 (The Hook) 你有没有过这样的幻想:下班回家推开门,AI机器人已经做好了你爱吃的糖醋排骨,把换下来的脏衣服扔进了洗衣机,甚至还帮你把刚到的快递拆好了?过去…...