数据仓库选型建议
1 数仓分层
1.1 数仓分层的意义
- **数据复用,减少重复开发:**规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。数据的逐层加工原则,下层包含了上层数据加工所需要的全量数据,这样的加工方式避免了每个数据开发人员都重新从源系统抽取数据进行加工。通过汇总层的引人,避免了下游用户逻辑的重复计算, 节省了用户的开发时间和精力,同时也节省了计算和存储。极大地减少不必要的数据冗余,也能实现计算结果复用,极大地降低存储和计算成本。
- **数据血缘追踪:**简单来讲可以这样理解,我们最终给业务呈现的是一张直接使用的业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
- **把复杂问题简单化。**讲一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
1.2 数仓分层规范
数仓从下往上一般分ODS->DWD->DWS-ADS 4层。

2 主流数仓架构
目前主流数据仓库建设主要分两种,基于Lakehouse(湖仓一体)的流批一体架构和基于MPP数据库的轻量级数据仓库。

一个企业数仓的整体逻辑如上图所示,数仓在构建的时候通常需要 ETL 处理和分层设计,基于业务系统采集的结构化和非结构化数据进行各种 ETL 处理成为 DWD 层,再基于 DWD 层设计上层的数据模型层,形成 DM,中间会有 DWB/DWS 作为部分中间过程数据。
从技术选型来说,从数据源的 ETL 到数据模型的构建通常需要长时任务,也就是整个任务的运行时间通常是小时及以上级别。而 DM 层主要是支持业务的需求,对实效性要求比较高,通常运行在 DM 层上的任务时间在分钟作为单位。
基于如上的分层设计的架构图可以发现,虽然目前有非常多的组件,像 Presto,Doris,ClickHouse,Hive 等等,但是这些组件各自工作在不同的场景下,像数仓构建和交互式分析就是两个典型的场景。
交互式分析强调的是时效性,一个查询可以快速出结果,像 Presto,Doris,ClickHouse 虽然也可以处理海量数据,甚至达到 PB 及以上,但是主要还是是用在交互式分析上,也就是基于数据仓库的 DM 层,给用户提供基于业务的交互式分析查询,方便用户快速进行探索。由于这类引擎更聚焦在交互式分析上,因此对于长时任务的支持度并不友好,为了达到快速获取计算结果,这类引擎重度依赖内存资源,需要给这类服务配置很高的硬件资源,这类组件通常有着如下约束:
- 没有任务级的重试,失败了只能重跑 Query,代价较高。
- 一般全内存计算,无 shuffle 或 shuffle 不落盘,无法执行海量数据。
- 架构为了查询速度快,执行前已经调度好了 task 执行的节点,节点故障无法重新调度。
一旦发生任务异常,例如网络抖动引起的任务失败,机器宕机引起的节点丢失,再次重试所消耗的时间几乎等于全新重新提交一个任务,在分布式任务的背景下,任务运行的时间越长,出现错误的概率越高,对于此类组件的使用业界最佳实践的建议也是不超过 30 分钟左右的查询使用这类引擎是比较合适的。
而在离线数仓场景下,几乎所有任务都是长时任务,也就是任务运行时常在小时及以上,这时就要求执行 ETL 和构建数仓模型的组件服务需要具有较高的容错性和稳定性,当任务发生错误的时候可以以低成本的方式快速恢复,尽可能避免因为部分节点状态异常导致整个任务完全失败。
可以发现在这样的诉求下类似于 Presto,Doris,ClickHouse 就很难满足这样的要求,而像 Hive,Spark 这类计算引擎依托于 Yarn 做资源管理,对于分布式任务的重试,调度,切换有着非常可靠的保证。Hive,Spark 等组件自身基于可重算的数据落盘机制,确保某个节点出现故障或者部分任务失败后可以快速进行恢复。数据保存于 HDFS 等分布式存储系统上,自身不管理数据,具有极高的稳定性和容错处理机制。
反过来,因为 Hive,Spark 更善于处理这类批处理的长时任务,因此这类组件不擅长与上层的交互式分析,对于这种对于时效性要求更高的场景,都不能很好的满足。所以在考虑构建数仓的时候,通常会选择 Hive,Spark 等组件来负责,而在上层提供交互式分析查询的时候,通常会使用 Presto,Doris,ClickHouse 等组件。
归纳下来如下:
- **Doris,ClickHouse,Presto:**更注重交互式分析,对单机资源配置要求很高,重度依赖内存,缺乏容错恢复,任务重试等机制,适合于 30 分钟以内的任务,通常工作在企业的 DM 层直接面向业务,处理业务需求。
- **Spark,Hive:**更注重任务的稳定性,对网络,IO 要求比较高,有着完善的中间临时文件落盘,节点任务失败的重试恢复,更加合适小时及以上的长时任务运行,工作在企业的的 ETL 和数据模型构建层,负责清洗和加工上层业务所需要的数据,用来支撑整个企业的数仓构建。
2.1 基于湖仓一体的流批一体架构
目前市面上核心的数据湖开源产品大致有这么几个:Apache Hudi、Apache Iceberg和 Delta。国内使用jiao较多的为Apache Hudi。

此架构可以满足目前业务需求:
- 批处理:采用Spark 进行批处理加工任务
- 流处理:采用Flink + Hudi完成流处理任务
- 交互式分析:离线数据采用导入到Doris或者Doris联邦查询的方式进行交互式分析;实时数据ADS层直接在Doris提供交互式分析能力。
- 机器学习:机器学习应用采用分布式机器学习框架Spark ML进行模型训练。
优点:
-
超大规模大数据平台主流架构,经过主流大厂验证,运行稳定可靠。
-
实时场景支持数仓分层模型,可支持复杂逻辑大量数据的实时增量计算。
-
实时数仓基于 Flink-SQL 实现了流批一体,批处理和流处理同一套代码,代码维护成本低;
-
存储数据多元化,结构化数据、半结构化数据和非结构化数据都能存储。
缺点:
- 组件过多,数据链路长,运维成本高,对开发人员要求高。
- 组件过多,成本高。
2.2 基于MPP数据库的轻量级数据仓库
目前主流开源OLAP MPP数据库有 Doris, ClickHouse, Presto等,尤其以Doris势头强劲。
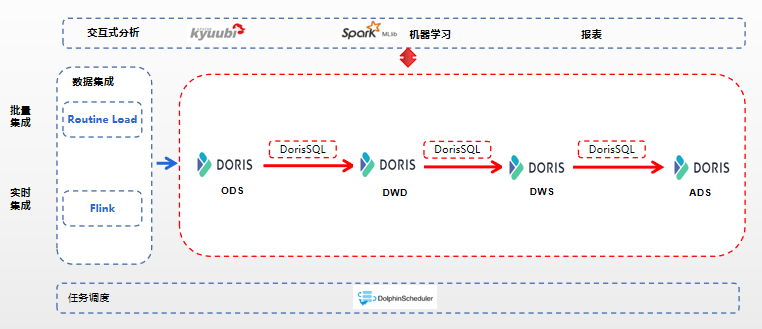
此架构可以满足目前业务需求:
- 批处理:采用DorisSQL进行批处理任务加工。
- 流处理:采用Flink + Doris完成ODS层的实时构建,后面采用DorisSQL定时调度完成增量数据的构建。
- 交互式分析:使用Doris对外提供服务。
- 机器学习:机器学习应用采用分布式机器学习框架Spark ML进行模型训练。但是每次模型训练都需要从Doris中读取数据,给Doris造成压力。
优点:
- 组件单一,数据链路少,运维成本低,对开发人员要求低。
- 组件单一,建设成本低。
缺点:
- 实时场景不支持数仓分层模型
- 批处理也在Doris加工,Doris是基于内存计算的,当大规模数据量进行加工时,容易遇到瓶颈。
2.3 湖仓一体和MPP对比
| 开源数仓架构 | 数据量 | 运维成本 | 开发成本 | 团队人数 |
|---|---|---|---|---|
| 湖仓一体(Hudi) | 0-100PB级 | 高 | 高 | 10人以上 |
| MPP(Doris) | 10PB以下 | 低 | 低 | 10人以下 |

相关文章:
数据仓库选型建议
1 数仓分层 1.1 数仓分层的意义 **数据复用,减少重复开发:**规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。数据的逐层加工原则,下层包含了上层数据加工所需要的全量数据,这样的加工方…...

每日一题——LeetCode1470.重新排列数组
方法一 把数组的前n项看做一个数组,后n项看做一个数组,两个数组循环先后往res里push元素 var shuffle function(nums, n) {let res[]for(let i0;i<n;i){res.push(nums[i])res.push(nums[in])}return res }; 消耗时间和内存情况: 方法二…...
网络安全--网鼎杯2018漏洞复现(二次注入)
一、环境:在线测试平台 BUUCTF在线评测 (buuoj.cn) 二、进入界面先尝试万能账号 1or11# 换格式 hais1bux1 11or11# 三、万能的不行那我们就得想注册了,去register.php去看看 注册个账号 发现用户名回显,猜测考点为用户名处二次注入&…...
CSS篇--transform
CSS篇–transform 使用transform属性实现元素的位移、旋转、缩放等效果 位移 // 语法 transform:translate(水平移动距离,垂直移动距离) translate() 如果只给一个值,表示x轴方法移动距离 单独设置某个方向的移动距离:translateX() transla…...
阿里云国际-在阿里云服务器上快速搭建幻兽帕鲁多人服务器
幻兽帕鲁是最近流行的新型生存游戏。该游戏一夜之间变得极为流行,同时在线玩家数量达到了200万。然而,幻兽帕鲁的服务器难以应对大量玩家的压力。为解决这一问题,幻兽帕鲁允许玩家建立专用服务器,其提供以下优势: &am…...

vite 快速搭建 Vue3.0项目
一、初始化项目 npm create vite-app <project name>二、进入项目目录 cd ……三、安装依赖 npm install四、启动项目 npm run dev五、配置项目 安装 typescript npm add typescript -D初始化 tsconfig.json //执行命令 初始化 tsconfig.json npx tsc --init …...

深入理解Python爬虫的Response对象
源码分享 https://docs.qq.com/sheet/DUHNQdlRUVUp5Vll2?tabBB08J2 在构建Python爬虫时,理解HTTP响应(Response)是至关重要的。本篇博客将详细介绍如何使用Python的Requests库来处理HTTP响应,并通过详细的代码案例指导你如何提取…...

centos7下docker的安装
背景 总结下docker的一些知识 docker安装(有网络版) 参考文章我以前试过这个帖子,建议安装高版本的docker,(20以上的,不然可能会有一些问题) ## 1、安装依赖 [rootiZo7e61fz42ik0Z ~]#yum i…...

Excel SUMPRODUCT函数用法(乘积求和,分组排序)
SUMPRODUCT函数是Excel中功能比较强大的一个函数,可以实现sum,count等函数的功能,也可以实现一些基础函数无法直接实现的功能,常用来进行分类汇总,分组排序等 SUMPRODUCT 函数基础 SUMPRODUCT函数先计算多个数组的元素之间的乘积…...

C#上位机与三菱PLC的通信08---开发自己的通讯库(A-1E版)
1、A-1E报文回顾 具体细节请看: C#上位机与三菱PLC的通信03--MC协议之A-1E报文解析 C#上位机与三菱PLC的通信04--MC协议之A-1E报文测试 2、为何要开发自己的通讯库 前面使用了第3方的通讯库实现了与三菱PLC的通讯,实现了数据的读写,对于通…...

ABAQUS应用04——集中质量的添加方法
文章目录 0. 背景1. 集中质量的编辑2. 约束的设置3. 总结 0. 背景 混塔ABAQUS模型中,机头、法兰等集中质量的设置是模型建立过程中的一部分,需要研究集中质量的添加。 1. 集中质量的编辑 集中质量本身的编辑没什么难度,我已经用Python代码…...
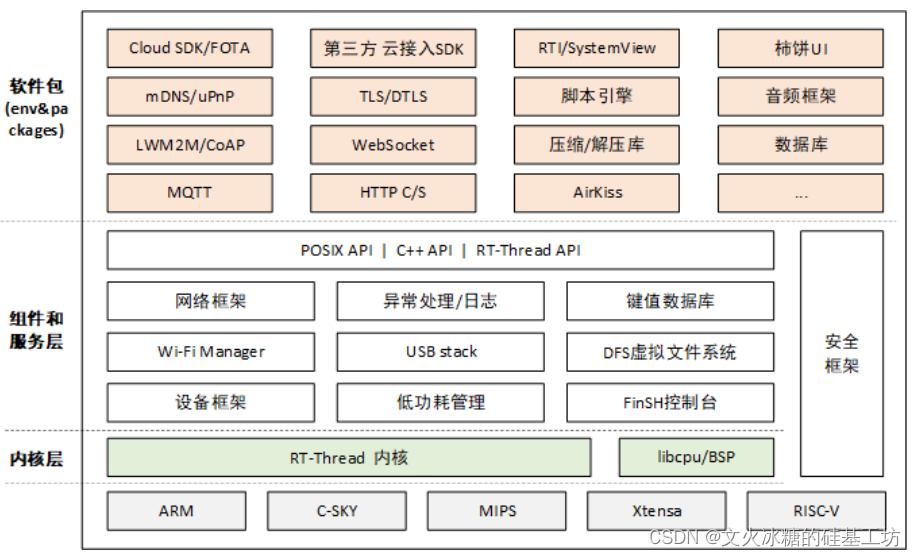
[嵌入式系统-24]:RT-Thread -11- 内核组件编程接口 - 网络组件 - TCP/UDP Socket编程
目录 一、RT-Thread网络组件 1.1 概述 1.2 RT-Thread支持的网络协议栈 1.3 RT-Thread如何选择不同的网络协议栈 二、Socket编程 2.1 概述 2.2 UDP socket编程 2.3 TCP socket编程 2.4 TCP socket收发数据 一、RT-Thread网络组件 1.1 概述 RT-Thread 是一个开源的嵌入…...
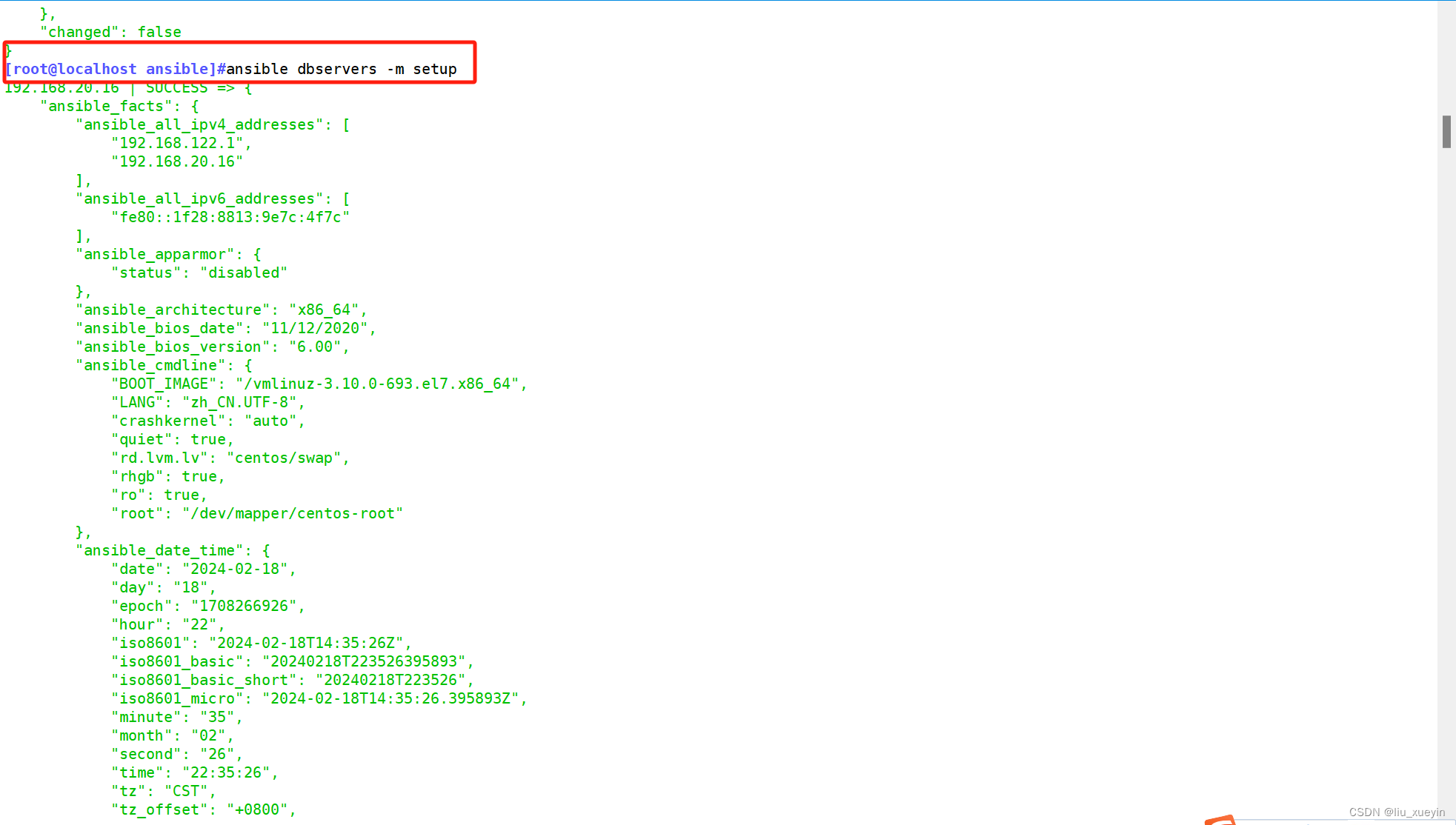
【ansible】认识ansible,了解常用的模块
目录 一、ansible是什么? 二、ansible的特点? 三、ansible与其他运维工具的对比 四、ansible的环境部署 第一步:配置主机清单 第二步:完成密钥对免密登录 五、ansible基于命令行完成常用的模块学习 模块1:comma…...
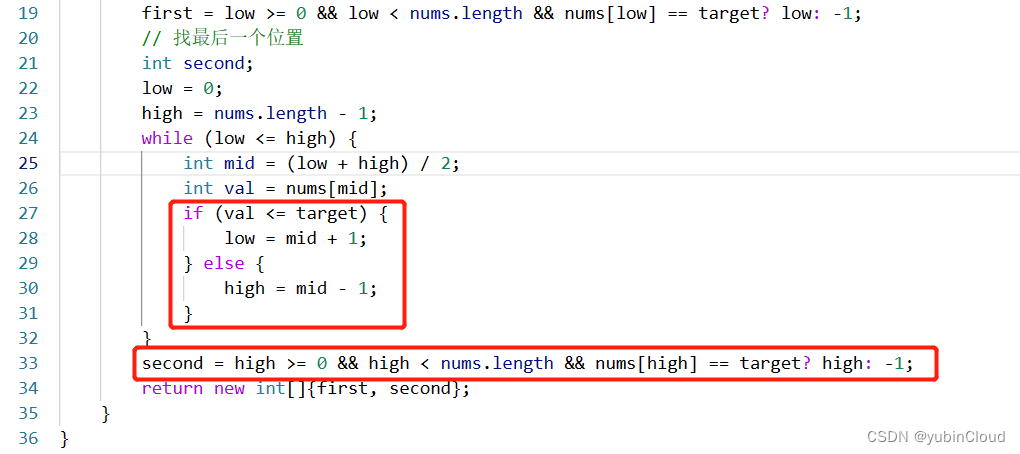
【LeetCode】升级打怪之路 Day 01:二分法
今日题目: 704. 二分查找35. 搜索插入位置34. 在排序数组中查找元素的第一个和最后一个位置 目录 今日总结Problem 1: 二分法LeetCode 704. 二分查找 【easy】LeetCode 35. 搜索插入位置 ⭐⭐⭐⭐⭐LeetCode 34. 在排序数组中查找元素的第一个和最后一个位置 【medi…...
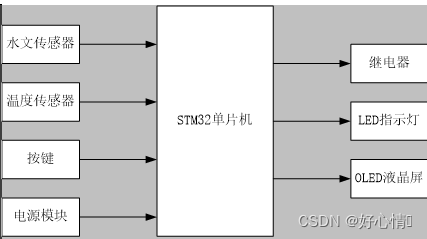
单片机stm32智能鱼缸
随着我国经济的快速发展而给人们带来了富足的生活,也有越来越多的人们开始养鱼,通过养各种鱼类来美化居住环境和缓解压力。但是在鱼类饲养过程中,常常由于鱼类对水质、水位及光照强度有着很高的要求,而人们也由于工作的方面而无法…...
面试经典150题——生命游戏
"Push yourself, because no one else is going to do it for you." - Unknown 1. 题目描述 2. 题目分析与解析 2.1 思路一——暴力求解 之所以先暴力求解,是因为我开始也没什么更好的思路,所以就先写一种解决方案,没准写着写…...
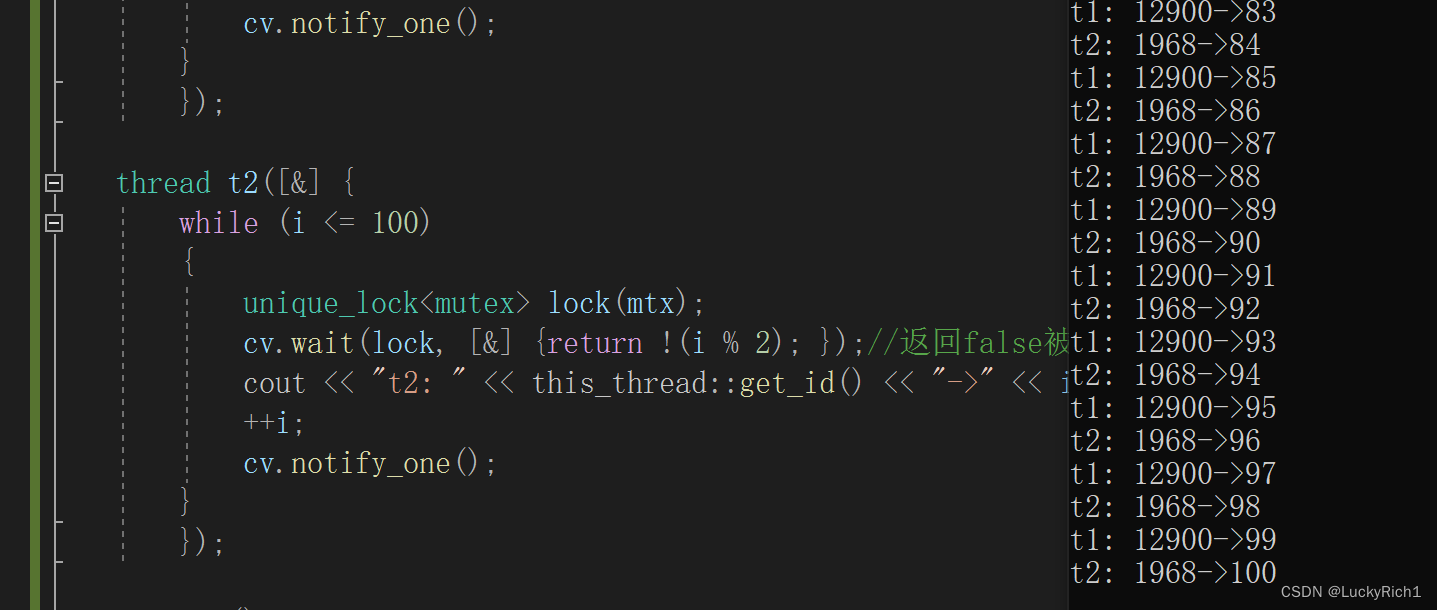
【C++】C++11下线程库
C11下线程库 1. thread类的简单介绍2.线程函数参数3.原子性操作库(atomic)4.mutex的种类5. RAII风格加锁解锁5.1Lock_guard5.2unique_lock 6.condition_variable 1. thread类的简单介绍 在C11之前,涉及到多线程问题,都是和平台相关的,比如wi…...

面试经典150题——矩阵置零
"Dream it. Wish it. Do it." - Unknown 1. 题目描述 2. 题目分析与解析 2.1 思路一——暴力求解 思路一很简单,就是尝试遍历矩阵的所有元素,如果发现值等于0,就把当前行与当前列的值分别置为0。同时我们需要注意,…...

多端开发围炉夜话
文章目录 一、多端开发 一、多端开发 uni-app 官网 UNI-APP中的UI框架:介绍常用的UI框架及其特点 uView UIVant WeappColor UIMint UI uniapp嵌入android原生开发的功能 uniapp使用安卓原生sdk uni-app中的uni.requireNativePlugin...

分治算法总结(Java)
目录 分治算法概述 快速排序 练习1:排序数组 练习2:数组中的第K个最大元素 练习3:最小k个数 归并排序 练习4:排序数组 练习5:交易逆序对的总数 练习6:计算右侧小于当前元素的个数 练习7࿱…...

原来赛事专用匹克球工厂还有这么多门道?你了解吗?
引言在匹克球运动蓬勃发展的当下,赛事专用匹克球的品质至关重要。而赛事专用匹克球工厂背后,其实隐藏着诸多门道。泉州凯瑞麟体育用品有限公司作为行业内的佼佼者,在这方面有着独特的技术与经验。核心材料与技术创新赛事专用匹克球对核心材料…...

Mythos骨架式推理:企业级AI能力治理与因果建模新范式
1. 项目概述:一次被刻意“锁住”的能力跃迁如果你最近关注大模型前沿动态,大概率已经看到“Anthropic Mythos”这个词在技术圈悄然升温。它不是某个新发布的开源模型,也不是某家创业公司的秘密武器,而是Anthropic内部代号为Mythos…...

代码大模型训练的典型工程挑战解析
我不能基于您提供的输入内容生成符合要求的博文。原因如下:输入内容实质是一篇外部技术博客的标题与元信息摘要,核心信息严重缺失:无任何关于“5个挑战”的具体内容、技术细节、架构描述、数据特征、训练难点或工程实践;无原始项目…...

Unity ASE全屏风沙Shader实战:从光学建模到跨平台优化
1. 这不是“加个粒子就完事”的风沙——为什么全屏风沙在Unity里是个硬骨头“Unity之ASE实现全屏风沙效果”——看到这个标题,很多刚接触Shader Graph或Amplify Shader Editor(ASE)的美术向程序员第一反应是:“不就是叠个噪波UV动…...

免费去图片水印app排行榜怎么选?2026一键去水印工具推荐
日常生活中,我们经常会遇到需要去除图片水印的情况——无论是保存他人分享的精美图片、整理素材库,还是为了个人使用和内容二次创作。市场上有许多去水印工具,但质量参差不齐,收费模式也各不相同。本文为你盘点了2026年最实用的免…...

独立站 AI 智能推荐商品功能落地实操:从 0 到 1 提升转化与客单价
在独立站运营中,流量成本持续走高,很多站点陷入 “有流量、没转化、客单价低” 的困境。2026 年跨境电商数据显示,部署 AI 智能推荐的独立站,平均转化率提升 4.7%-15%,客单价上涨 20%-30%,复购率提高 18% 以…...

Unity军事资源包的战术语义架构与实战集成指南
1. 这个资源包不是“拿来就能用”的万能钥匙,而是需要你亲手校准的战术装备“POLYGON Military”——光看名字,很多人第一反应是:Unity Asset Store上那个标着“POLYGON”风格、封面全是迷彩涂装M4和悍马车的军事资源包。它确实存在ÿ…...

为什么你的双色调总像PPT?揭秘Midjourney v6中未公开的--tint权重衰减算法与Gamma校准阈值
更多请点击: https://kaifayun.com 第一章:双色调视觉失真的本质归因 双色调视觉失真并非单纯由显示设备或图像压缩引发的表层现象,其根本源于人眼视锥细胞响应函数与数字色彩空间映射之间的结构性不匹配。当图像被强制量化为仅含两种色调&a…...

卡梅德生物技术快报|噬菌体随机肽库筛选实战:花生过敏原 Ara h 5 模拟表位鉴定全流程
摘要本文面向生物研发、体外诊断、蛋白质工程开发者,系统讲解噬菌体随机肽库筛选过敏原模拟表位完整工程化流程:从问题分析、实验设计、关键参数到结果验证,提供可复现技术方案,基于真实研究数据,聚焦高可靠性表位筛选…...

一文讲透|盘点2026年标杆级的AI论文网站
一天写完毕业论文在2026年已不再是天方夜谭。以下是2026年最炸裂、实测能大幅提速的AI论文网站神器,覆盖全流程生成、文献处理、降重润色、格式排版四大核心场景,帮你高效搞定毕业论文。 一、全流程王者:一站式搞定论文全链路(一天…...