大模型训练流程(三)奖励模型
为什么需要奖励模型
因为指令微调后的模型输出可能不符合人类偏好,所以需要利用强化学习优化模型,而奖励模型是强化学习的关键一步,所以需要训练奖励模型。
1.模型输出可能不符合人类偏好
上一篇讲的SFT只是将预训练模型中的知识给引导出来的一种手段,而在SFT 数据有限的情况下,我们对模型的引导能力就是有限的。这将导致预训练模型中原先错误或有害的知识没能在 SFT 数据中被纠正,从而出现「有害性」或「幻觉」的问题。
2.需要利用强化学习优化模型
一些让模型脱离昂贵标注数据,自我进行迭代的方法被提出,比如:RLHF,DPO,RLHF是直接告诉模型当前样本的(好坏)得分,DPO 是同时给模型一条好的样本和一条坏的样本。最终目的是告知模型什么是好的数据,什么是不好的数据,将大模型训练地更加符合人类偏好。
3.设计有效的奖励模型是强化学习的关键一步
- 设计有效的奖励模型是 RLHF 的关键一步,因为没有简单的数学或逻辑公式可以切实地定义人类的主观价值。
- 在进行RLHF时,需要奖励模型来评估语言大模型(actor model)回答的是好是坏,这个奖励模型通常比被评估的语言模型小一些(deepspeed的示例中,语言大模型66B,奖励模型只有350M)。奖励模型的输入是prompt+answer的形式,让模型学会对prompt+answer进行打分。
- 奖励模型的目标是构建一个文本质量对比模型,对于同一个提示词,SFT 模型给出的多个不同输出结果的质量进行排序。
训练奖励模型
1.训练数据(人工排好序的数据)
奖励模型的训练数据是人工对问题的每个答案进行排名,如下图所示:
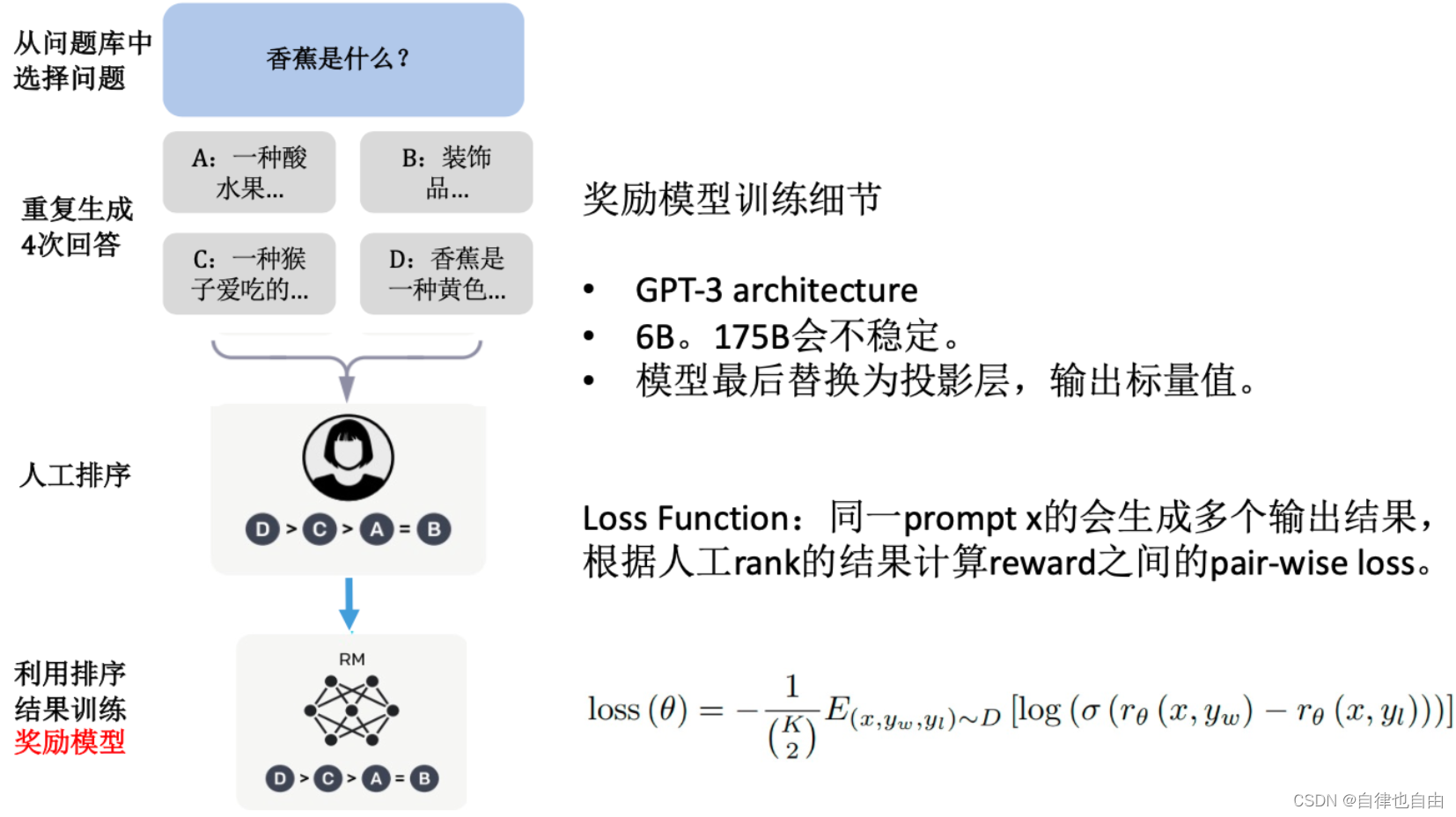
对于每个问题,给出若干答案,然后工人进行排序,而奖励模型就是利用排序的结果来进行反向传播训练。
问题:最终目的是训练一个句子打分模型,为什么不让人直接打分,而是去标排序序列呢?
直接给生成文本进行打分是一件非常难统一的事情。如果对于同样的生成答案,有的标注员打 5 分,但有的标注员打 3 分,模型在学习的时候就很难明确这句话究竟是好还是不好。
既然打绝对分数很难统一,那就转换成一个相对排序的任务能够更方便标注员打出统一的标注结果。
模型通过尝试最大化「好句子得分和坏句子得分之间的分差」,从而学会自动给每一个句子判分。
问题:使用多少数据能够训练好一个RM?
在 OpenAI Summarize 的任务中,使用了 6.4w 条]偏序对进行训练。
在 InstructGPT 任务中,使用了 3.2w 条 [4~9] 偏序对进行训练。
在 StackLlama]任务中,使用了 10w 条 Stack Exchange 偏序对进行训练。
从上述工作中,我们仍无法总结出一个稳定模型需要的最小量级,这取决于具体任务。
但至少看起来,5w 以上的偏序对可能是一个相对保险的量级。
2.模型架构
奖励模型(RM 模型)将 SFT 模型最后一层的 softmax 去掉,即最后一层不用 softmax,改成一个线性层。RM 模型的输入是问题和答案,输出是一个标量即分数。
由于模型太大不够稳定,损失值很难收敛且小模型成本较低,因此,RM 模型采用参数量为 6B 的模型,而不使用 175B 的模型。
问题:RM 模型的大小限制?
Reward Model 的作用本质是给生成模型的生成内容进行打分,所以 Reward Model 只要能理解生成内容即可。
关于 RM 的规模选择上,目前没有一个明确的限制:
Summarize 使用了 6B 的 RM,6B 的 LM。
InstructGPT 使用了 6B 的 RM,175B 的 LM。
DeepMind 使用了 70B 的 RM,70B LM。
不过,一种直觉的理解是:判分任务要比生成认为简单一些,因此可以用稍小一点的模型来作为 RM。
3.损失函数(最大化差值)
假定现在有一个排好的序列:A > B > C >D。
我们需要训练一个打分模型,模型给四句话打出来的分要满足 r(A) > r(B) > r(C) > r(D)。
那么,我们可以使用下面这个损失函数:
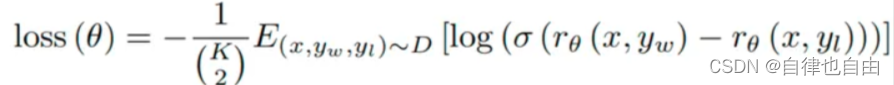
其中,yw 代表排序排在 yl 的所有句子。
用上述例子(A > B > C > D)来讲,loss 等于:
loss = r(A) - r(B) + r(A) - r(C) + r(A) - r(D) + r(B) - r(C) + ... + r(C) - r(D)
loss = -loss
为了更好的归一化差值,我们对每两项差值都过一个 sigmoid 函数将值拉到 0 ~ 1 之间。
可以看到,loss 的值等于排序列表中所有排在前面项的reward减去排在后面项的reward的和。
而我们希望模型能够最大化这个好句子得分和坏句子得分差值,而梯度下降是做的最小化操作。因此,我们需要对 loss 取负数,就能实现最大化差值的效果了。
问题:奖励模型的损失函数为什么会比较答案的排序,而不是去对每一个答案的具体分数做一个回归?
每个人对问题的答案评分都不一样,无法使用一个统一的数值对每个答案进行打分,训练标签不好构建。如果采用对答案具体得分回归的方式来训练模型,会造成很大的误差。但是,每个人对答案的好坏排序是基本一致的。通过排序的方式避免了人为的误差。
问题:奖励模型中每个问题对应的答案数量即K值为什么选 9 更合适,而不是选择 4 呢?
- 进行标注的时候,需要花很多时间去理解问题,但答案之间比较相近,假设 4 个答案进行排序要 30 秒时间,那么 9 个答案排序可能就 40 秒就够了。9 个答案与 4 个答案相比生成的问答对多了 5 倍,从效率上来看非常划算;
- K=9时,每次计算 loss 都有 36 项rθ(x,y)需要计算,RM 模型的计算所花时间较多,但可以通过重复利用之前算过的值(也就是只需要计算 9 次即可),能节约很多时间。
总结
奖励模型通过与人类专家进行交互,获得对于生成响应质量的反馈信号,从而进一步提升大语言模型的生成能力和自然度。与监督模型不同的是,奖励模型通过打分的形式使得生成的文本更加自然逼真,让大语言模型的生成能力更进一步。
相关文章:
大模型训练流程(三)奖励模型
为什么需要奖励模型 因为指令微调后的模型输出可能不符合人类偏好,所以需要利用强化学习优化模型,而奖励模型是强化学习的关键一步,所以需要训练奖励模型。 1.模型输出可能不符合人类偏好 上一篇讲的SFT只是将预训练模型中的知识给引导出来…...

替换if...else的锦囊妙计
目录 前言 一、又臭又长的if...else 二、消除if...else的锦囊妙计 1、使用注解 2、动态拼接名称 3、模板方法判断 4.策略工厂模式 5.责任链模式 6、其他的消除if...else的方法 1.根据不同的数字返回不同的字符串 2.集合中的判断 3.简单的判断 4.spring中的判断 原文…...

新建一个flask项目
在Flask中创建一个新的项目,您可以遵循以下步骤: 确保您已经安装了Python环境。如果还未安装Flask,可以通过pip来安装: pip install flask创建一个新的文件夹作为您的项目文件夹,例如myflaskapp: mkdir …...

【Linux 内核源码分析】物理内存组织结构
多处理器系统两种体系结构: 非一致内存访问(Non-Uniform Memory Access,NUMA):这种体系结构下,内存被划分成多个内存节点,每个节点由不同的处理器访问。访问一个内存节点所需的时间取决于处理器…...

力扣日记2.21-【回溯算法篇】46. 全排列
力扣日记:【回溯算法篇】46. 全排列 日期:2023.2.21 参考:代码随想录、力扣 46. 全排列 题目描述 难度:中等 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1&…...

[AIGC] Kafka 消费者的实现原理
在 Kafka 中,消费者通过订阅主题来消费数据。每个消费者都属于一个消费者组,消费者组中的多个消费者可以共同消费一个主题,实现分布式消费。每个消费者都会维护自己的偏移量,用于记录已经读取到的消息位置。消费者可以选择手动提交…...
Dubbo框架admin搭建
Dubbo服务监控平台,dubbo-admin是图形化的服务管理界面,从服务注册中心获取所有的提供者和消费者的配置。 dubbo-admin是前后端分离的项目,前端使用Vue,后端使用springboot。因此,前端需要nodejs环境,后端需…...

Linux 内存top命令详解
通过top命令可以监控当前机器的内存实时使用情况,该命令的参数解释如下: 第一行 15:30:14 —— 当前系统时间 up 1167 days, 5:02 —— 系统已经运行的时长,格式为时:分 1 users ——当前有1个用户登录系统 load average: 0.00, 0.01, 0.05…...

OCP使用CLI创建和构建应用
文章目录 环境登录创建project赋予查看权限部署第一个image创建route检查pod扩展应用 部署一个Python应用连接数据库创建secret加载数据并显示国家公园地图 清理参考 环境 RHEL 9.3Red Hat OpenShift Local 2.32 登录 通过 crc console --credentials 可以查看登录信息&…...
Chrome关闭时出现弹窗runtime error c++R6052,且无法关闭
环境: Chrome 版本121 Win10专业版 问题描述: Chrome关闭时出现弹窗runtime error cR6052,且无法关闭 解决方案: 1.任务管理器打开,强制结束进程 2.再次打开谷歌浏览器,打开设置关于Chrome࿰…...
【动态规划专栏】专题二:路径问题--------6.地下城游戏
本专栏内容为:算法学习专栏,分为优选算法专栏,贪心算法专栏,动态规划专栏以及递归,搜索与回溯算法专栏四部分。 通过本专栏的深入学习,你可以了解并掌握算法。 💓博主csdn个人主页:小…...

flink operator 1.7 更换日志框架log4j 到logback
更换日志框架 flink 1.18 1 消除基础flink框架log4j 添加logback jar 1-1 log4j log4j-1.2-api-2.17.1.jar log4j-api-2.17.1.jar log4j-core-2.17.1.jar log4j-slf4j-impl-2.17.1.jar 1-2 logback logback-core-1.2.3.jar logback-classic-1.2.3.jar slf4j-api-1.7.25.jar2 …...
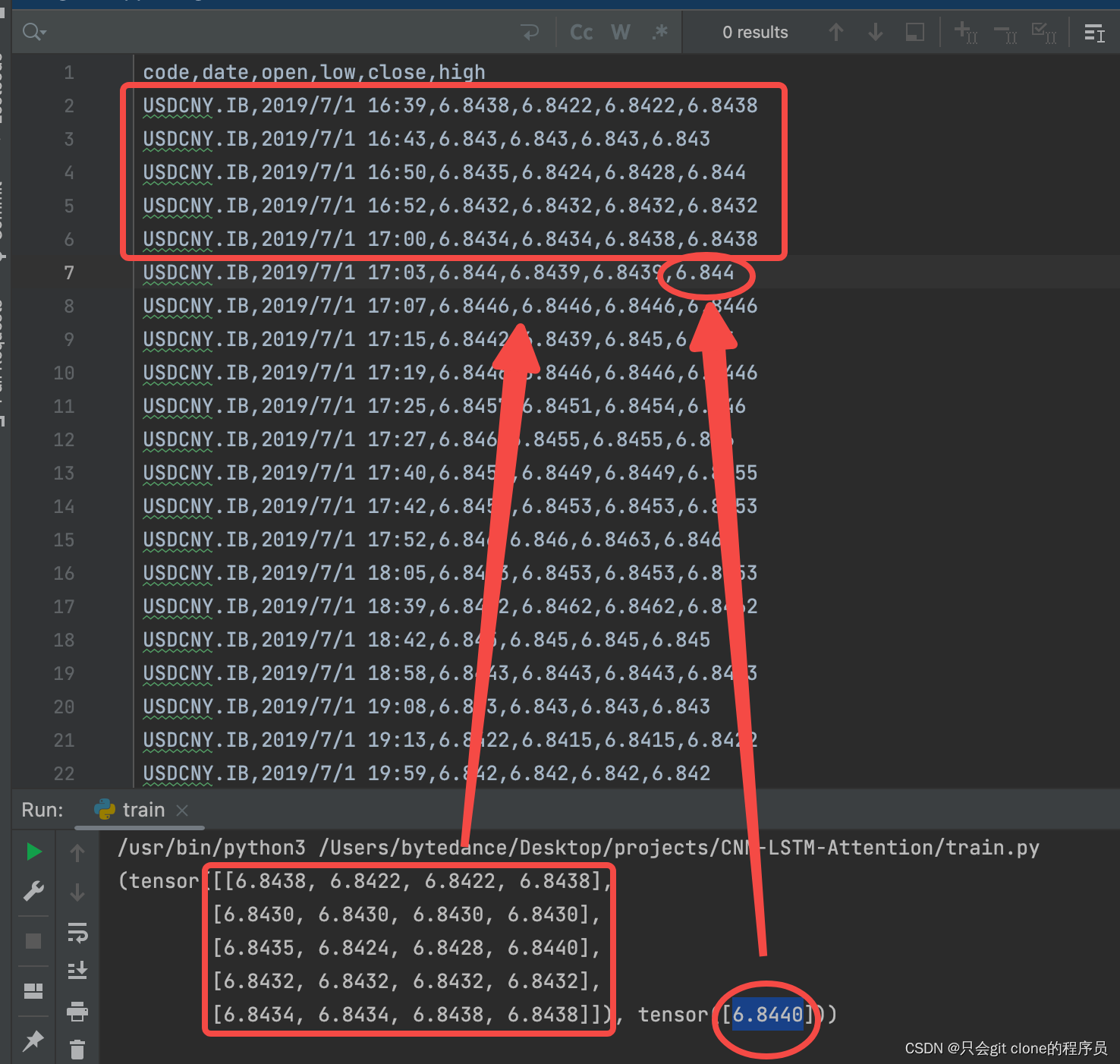
算法项目(1)—— LSTM+CNN+四种注意力对比的股票预测
本文包含什么? 项目运行的方式(包教会)项目代码(在线运行免环境配置)不通注意力的模型指标对比一些效果图运行有问题? csdn上后台随时售后.项目说明 本项目实现了基于CNN+LSTM构建模型,然后对比不同的注意力机制预测股票走势的效果。首先看一下模型结果的对比: 模型MS…...
Qt C++春晚刘谦魔术约瑟夫环问题的模拟程序
什么是约瑟夫环问题? 约瑟夫问题是个有名的问题:N个人围成一圈,从第一个开始报数,第M个将被杀掉,最后剩下一个,其余人都将被杀掉。例如N6,M5,被杀掉的顺序是:5ÿ…...
Typora+PicGO+腾讯云COS做图床
文章目录 Typora+PicGO+腾讯云COS做图床一、为什么使用图床二、Typora、PicGO和腾讯云COS介绍三、下载Typora和PicGOTyporaPicGO 四、配置Typora、PicGO和腾讯云COS腾讯云COS配置PicGO配置Typora配置 Typora+PicGO+腾讯云COS做图床…...

WebStorm | 如何修改webstorm中新建html文件默认生成模板中title的初始值
在近期的JS的学习中,使用webstorm,总是要先新建一个html文件,然后再到里面书写<script>标签,真是麻烦,而且标题也是默认的title,想改成文件名还总是需要手动去改 经过小小的研究,找到了修…...
大厂的数据质量中心系统设计
日常工作中,数据开发上线完一个任务后并不是就可以高枕无忧,时常因上游链路数据异常或者自身处理逻辑的 BUG 导致产出的数据结果不可信。而问题发现可经历较长周期(尤其离线场景),往往是业务方通过上层数据报表发现数据…...
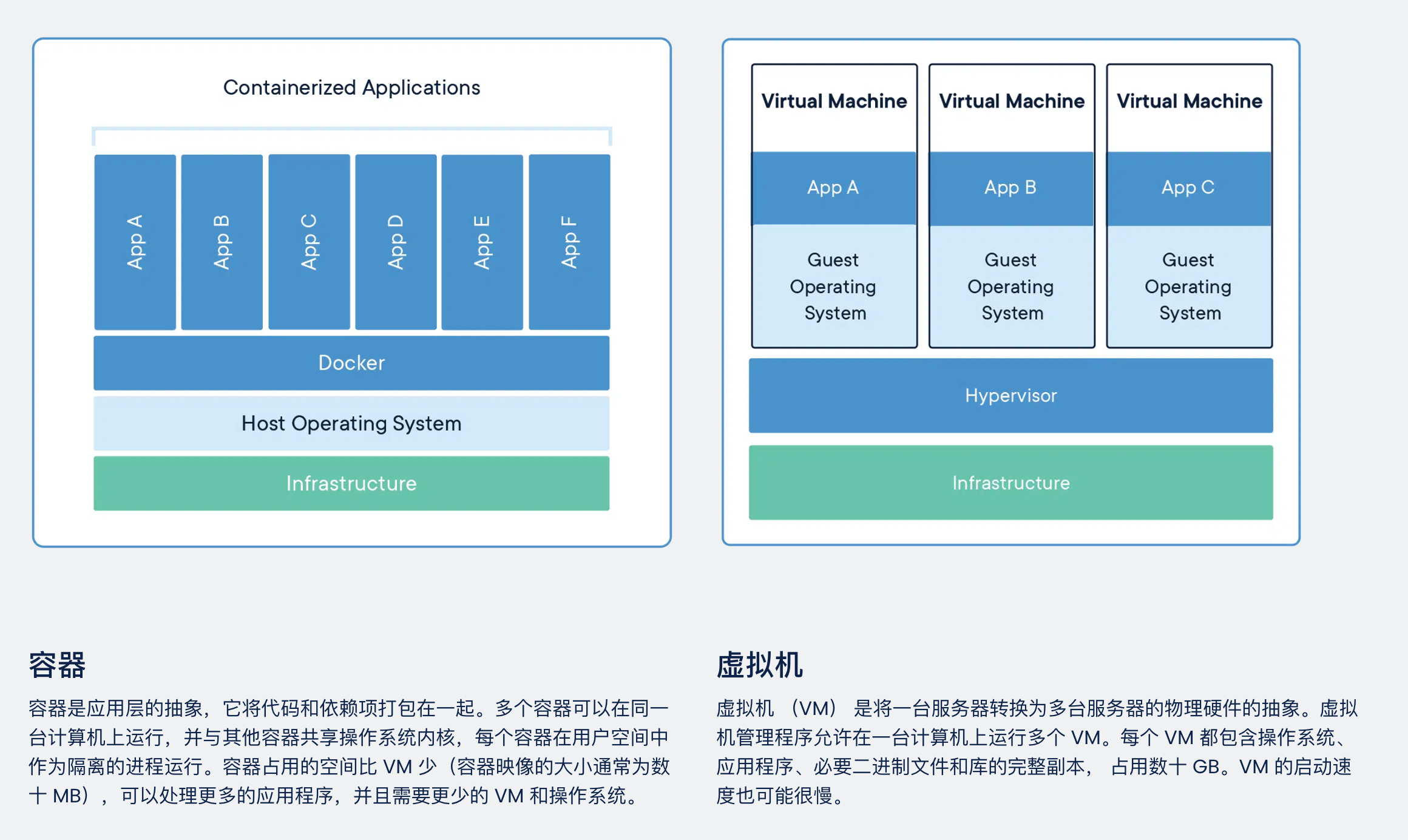
docker (一)-简介
1.什么是docker Docker 是一个开源的应用容器引擎,由于docker影响巨大,今天也用"Docker" 指代容器化技术。 2.docker的优势 一键部署,开箱即用 容器使用基于image镜像的部署模式,image中包含了运行应用程序所需的一…...

全国乙卷高考理科数学近年真题的选择题练一练和解析
虽然很多中小学才陆陆续续开学,但是高三的学子们一定是过年的时候也在抓紧备考,毕竟,距离2024年高考只剩下不到四个月了。 如何在最后四个月的时间提高成绩?以高考真题为抓手是一个不错的方法,因为真题都是严格遵循考试…...
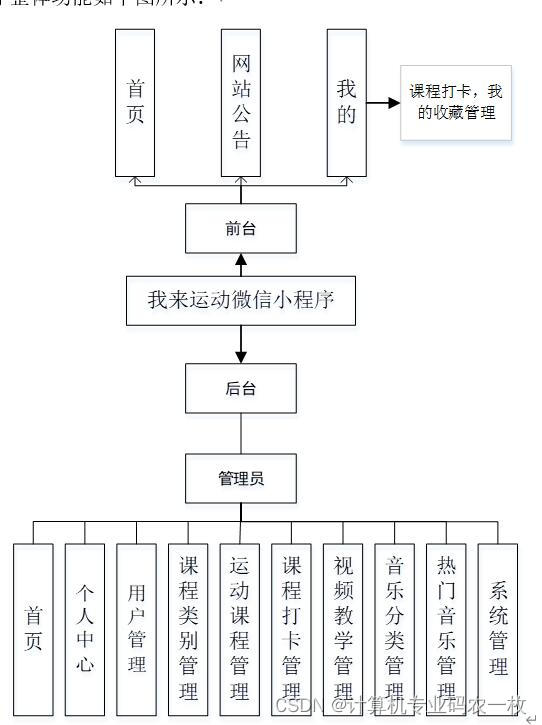
uniapp运动课程健身打卡系统微信小程序
考虑到实际生活中在我来运动管理方面的需要以及对该系统认真的分析,将系统分为小程序端模块和后台管理员模块,权限按管理员和用户这两类涉及用户划分。 (a) 管理员;管理员使用本系统涉到的功能主要有:首页、个人中心、用户管理、课程类别管理…...

Java智能地址解析终极指南:企业级架构设计与高性能实现方案
Java智能地址解析终极指南:企业级架构设计与高性能实现方案 【免费下载链接】address-parse Java 版智能解析收货地址 项目地址: https://gitcode.com/gh_mirrors/addr/address-parse 面对电商、物流、外卖等系统中复杂多变的地址输入格式,传统的…...

双榜第一!文心5.1登顶中文创意写作综合实力评测
【大力财经】5月18日,全球权威ICT领域市场研究机构Omdia发布《2026 年基础模型中文创意写作能力评估》报告,围绕中文创意写作七大核心维度,对 DeepSeek V4、文心5.1(ERNIE 5.1)、GPT 5.5 等 8大国内外主流顶级文本模型…...

如何打破闭源代码智能模型的垄断?DeepSeek-Coder-V2的技术突围与实践指南
如何打破闭源代码智能模型的垄断?DeepSeek-Coder-V2的技术突围与实践指南 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSe…...

水下叶轮脉动压力测试:Kulite压力传感器强在哪?安装门槛怎么破?
水下叶轮脉动压力测试这事,干过的朋友都懂——看着挺简单,上手哪一步都可能翻车。传感器防水、空间狭小、叶轮旋转、信号采集困难——随便拎出一个,都够让人头疼的。折腾了一圈,有一个型号被反复验证为绕不开的经典:Ku…...
终极免费实时屏幕翻译工具:Translumo完全使用指南
终极免费实时屏幕翻译工具:Translumo完全使用指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾经因…...

极域电子教室破解终极指南:如何重获电脑控制权而不被老师发现
极域电子教室破解终极指南:如何重获电脑控制权而不被老师发现 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在学校机房上课时,面对老师全屏广播…...
)
【ElevenLabs方言语音工程实战】:山东话TTS落地全流程(含音色克隆、韵律校准、鲁南/胶东口音适配)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs山东话语音工程全景概览 ElevenLabs 作为全球领先的AI语音合成平台,原生支持英语、西班牙语、法语等数十种主流语言,但对中文方言(如山东话)暂…...

为什么你需要ZeroOmega:重新定义浏览器代理管理的新范式
为什么你需要ZeroOmega:重新定义浏览器代理管理的新范式 【免费下载链接】ZeroOmega Manage and switch between multiple proxies quickly & easily. 项目地址: https://gitcode.com/gh_mirrors/ze/ZeroOmega 在现代网络环境中,频繁切换代理…...

毕业论文难写?2026年AI写作辅助网站排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!🏆…...

Qt 高级开发 009: C++ Lambda 表达式
Qt 高级开发 009: C Lambda 表达式Bilibili 同步视频🔎 一、Lambda 表达式:到底是什么?🧩 二、Lambda 完整结构:六大核心组件1. 捕获列表 [ ] 🎫2. 参数列表 ( ) 📥3. mutable 关键字…...