(01)Hive的相关概念——架构、数据存储、读写文件机制
目录
一、架构及组件介绍
1.1 Hive整体架构
1.2 Hive组件
1.3 Hive数据模型(Data Model)
1.3.1 Databases
1.3.2 Tables
1.3.3 Partitions
1.3.4 Buckets
二、Hive读写文件机制
2.1 SerDe 作用
2.2 Hive读写文件流程
2.2.1 读取文件的过程
2.2.2 写入文件的过程
2.3 SerDe相关语法
2.3.1 LazySimpleSerDe分隔符指定
2.3.2 默认分隔符
2.4 Hive数据存储路径
2.4.1 默认存储路径
2.4.2 指定存储路径
一、架构及组件介绍
1.1 Hive整体架构
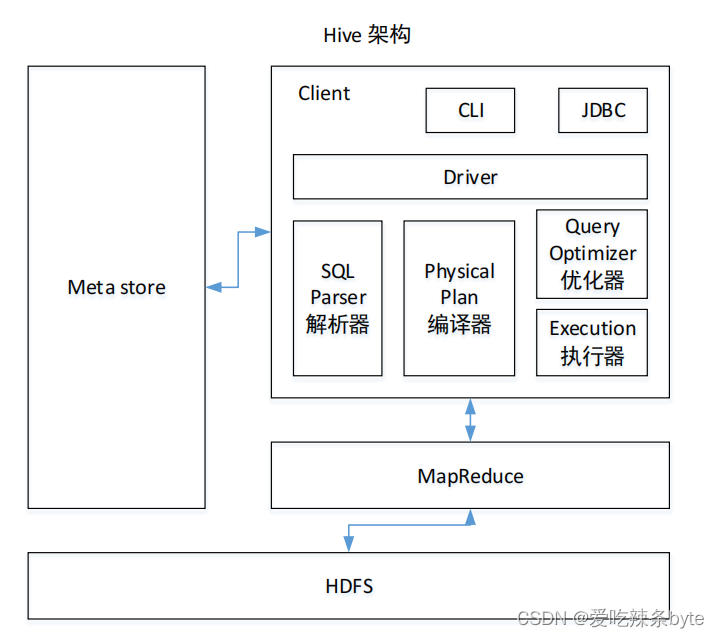
1.2 Hive组件
- 用户接口:Client
- CLI:shell命令行
- JDBC/ODBC:Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议
- WEBUI:通过浏览器访问Hive
- 元数据:Metastore
元数据通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- Hadoop
数据使用 HDFS 进行存储,使用 MapReduce 进行计算。
- 驱动器:Driver
- 解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第 三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
- 编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
- 优化器(Query Optimizer):对逻辑执行计划进行优化。
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。当下Hive支持MapReduce、Tez、Spark3种执行引擎
Driver驱动器总结:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,随后执行引擎调用执行。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
1.3 Hive数据模型(Data Model)
模型用来描述数据,组织数据和对数据进行操作。
Hive的数据模型类似于RDMS库表结构,此外它还有自己特有的模型。Hive中的数据可以在粒度级别分为三类:Table类、Partition分区、Bucket分桶。
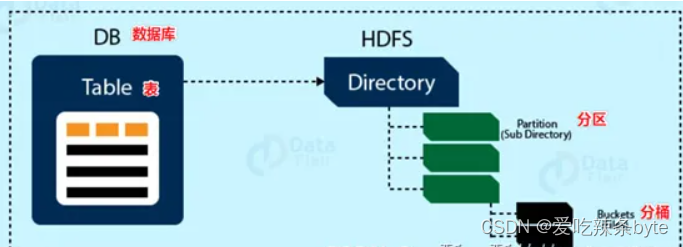
1.3.1 Databases
Hive的数据存储在HDFS上的,默认有一个根目录,在hive-site.xml配置文件中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse。
Hive中的数据库在HDFS上的存储路径为:${hive.metastore.warehouse.dir}/databasename.db
比如,名为test的数据库存储路径为:/user/hive/warehouse/test.db
1.3.2 Tables
Hive表与关系数据库中的表相同,Hive中的表所对应的数据是存储在Hadoop的文件系统中,而表相关的元数据是存储在RDBMS中。Hive有两种类型的表,分别是Managed Table内部表、External Table外部表。创建表时,默是内部表。
Hive中的表的数据在HDFS上的存储路径为:${hive.metastore.warehouse.dir}/databasename.db/tablename
比如,test的数据库下t_user表存储路径为:/user/hive/warehouse/test.db/t_user
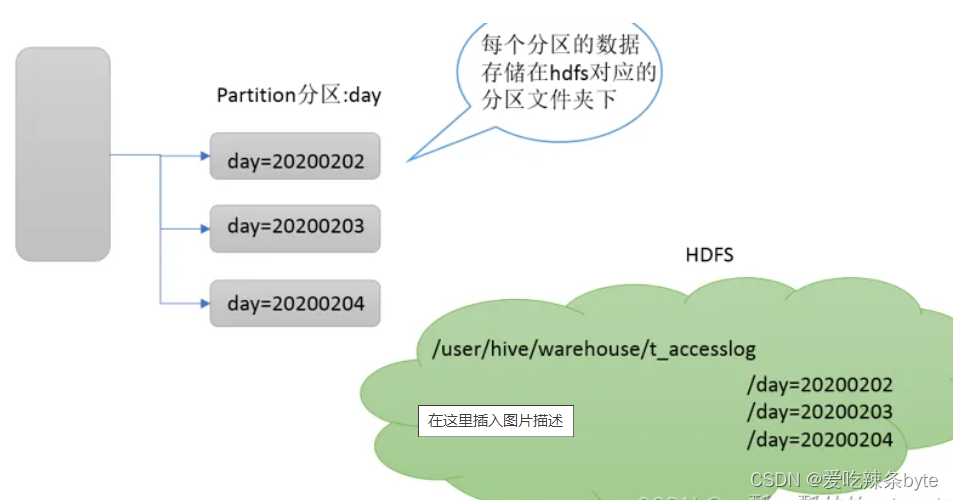
1.3.3 Partitions
Partition分区表是hive的一种优化手段表,当Hive表数据量大,查询时通过 where子句筛选指定的分区,这样的查询效率会提高很多,避免全表扫描。
Hive支持根据指定的字段进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。分区在存储层面上的表现是table表目录下以子文件夹形式存在。一个文件夹表示一个分区。子文件命名标准:分区列=分区值,Hive还支持分区下继续创建分区,所谓的多重分区。
1.3.4 Buckets
Bucket分桶表是hive的一种优化手段表。分桶是指数据表中某字段的值,经过hash计算规则将数据分为指定的若干小文件。Bucket分桶表在hdfs中表现为同一个表目录下的数据根据hash散列之后变成多个文件。分区针对的是数据的存储路径;分桶针对的是数据文件(数据粒度更细)。
分桶默认规则是:分桶编号Bucket number = hash_function(分桶字段) % 桶数量。桶编号相同的数据会被分到同一个桶当中。
ps:hash_function函数取决于分桶字段的数据类型,如果是int类型,hash_function(int) == int; 如果是其他数据类型,比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值。



二、Hive读写文件机制
2.1 SerDe 作用
SerDe是Serializer、Deserializer的简称,目的是用于序列化和反序列化。序列化是对象转化为字节码的过程(写);而反序列化是字节码转换为对象(读)的过程。
# 读过程:反序列化
HDFS files --> InputFileFormat --> <key,value> --> Deserializer(反序列化) --> Row Object
# 写过程: 序列化
Row Object --> serializer(序列化) --> <key,value> --> OutputFileFormat --> HDFS files通过desc formatted tablename 查看表的相关SerDe信息,SerDe默认:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
例如以t_order 为例:
---建表
CREATE TABLE t_order (oid int ,uid int ,otime string,oamount int)
ROW format delimited FIELDS TERMINATED BY ",";---插入数据
load data local inpath "/opt/module/hive_data/t_order.txt" into table t_order;#== 查看t_order表的详细信息
desc formatted t_order;
2.2 Hive读写文件流程
DeveloperGuide - Apache Hive - Apache Software Foundation![]() https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide#DeveloperGuide-HiveSerDe
https://cwiki.apache.org/confluence/display/Hive/DeveloperGuide#DeveloperGuide-HiveSerDe
2.2.1 读取文件的过程
- 流程:
HDFS files --> InputFileFormat --> <key,value> --> Deserializer(反序列化) --> Row Object
- 机制:
首先调用InputFormat(默认TextInputFormat)进行一行一行的读取,返回kv键值对记录(默认是一行对应一条记录)。然后调用SerDe(默认LazySimpleSerDe)的Deserializer,将一条记录中的value根据分隔符切分为各个字段。
2.2.2 写入文件的过程
- 流程:
Row Object --> serializer(序列化) --> <key,value> --> OutputFileFormat --> HDFS files
- 机制:
将Row写入文件时,首先调用SerDe(默认LazySimpleSerDe)的Serializer将对象转换成字节序列。然后调用OutputFormat将数据写入HDFS文件中。
2.3 SerDe相关语法
SerDe语法指路:
LanguageManual DDL - Apache Hive - Apache Software Foundation![]() https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-RowFormats&SerDe在Hive建表语句中,和 SerDe相关的语法:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-RowFormats&SerDe在Hive建表语句中,和 SerDe相关的语法:
- hive的建表语法
# 建表语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]- 字段解释说明
(7) ROW FORMAT:ROW FORMAT是语法关键字,以下的DELIMITED和SERDE二选其一。
- DELIMITED [FIELDS TERMINATED BY char]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
- SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe 。如果没有指定 ROWFORMAT 或者 ROW FORMAT DELIMITED ,将会使用自带的 SerDe 。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe , Hive 通过 SerDe 确定表 的具体的列的数据。SerDe 是 Serialize/Deserilize 的简称, hive 使用 Serde 进行行对象的序列与反序列化。
#==== 例如:支付表的建表语句
DROP TABLE IF EXISTS ods_payment_info_inc;
CREATE EXTERNAL TABLE ods_payment_info_inc
(`type` STRING COMMENT '变动类型',`ts` BIGINT COMMENT '变动时间',`data` STRUCT<id :STRING,out_trade_no :STRING,order_id :STRING,user_id :STRING,payment_type :STRING,trade_no:STRING,total_amount :DECIMAL(16, 2),subject :STRING,payment_status :STRING,create_time :STRING,callback_time:STRING,callback_content :STRING> COMMENT '数据',`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '支付表'PARTITIONED BY (`dt` STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe'LOCATION '/warehouse/gmall/ods/ods_payment_info_inc/';
2.3.1 LazySimpleSerDe分隔符指定
LazySimpleSerDe是Hive默认的序列化类,包含4种子语法,分别用于指定字段之间、集合元素之间、map映射 kv之间、换行的分隔符号。在建表的时候可以根据数据的特点灵活搭配使用。
DELIMITED [FIELDS TERMINATED BY char] --- 字段之间的分隔符[COLLECTION ITEMS TERMINATED BY char] --- 集群元素之间的分隔符[MAP KEYS TERMINATED BY char] --- map映射kv之间的分隔符[LINES TERMINATED BY char] --- 行数据之间的分隔符2.3.2 默认分隔符
hive建表时如果没有row format语法。此时字段之间默认的分割符是’\001’
2.4 Hive数据存储路径
2.4.1 默认存储路径
Hive表默认存储路径是由 ${HIVE_HOME}/conf/hive-site.xml配置文件的hive.metastore.warehouse.dir属性指定,默认值是:/user/hive/warehouse。在该路径下,文件将根据所属的库、表,有规律的存储在对应的文件夹下。

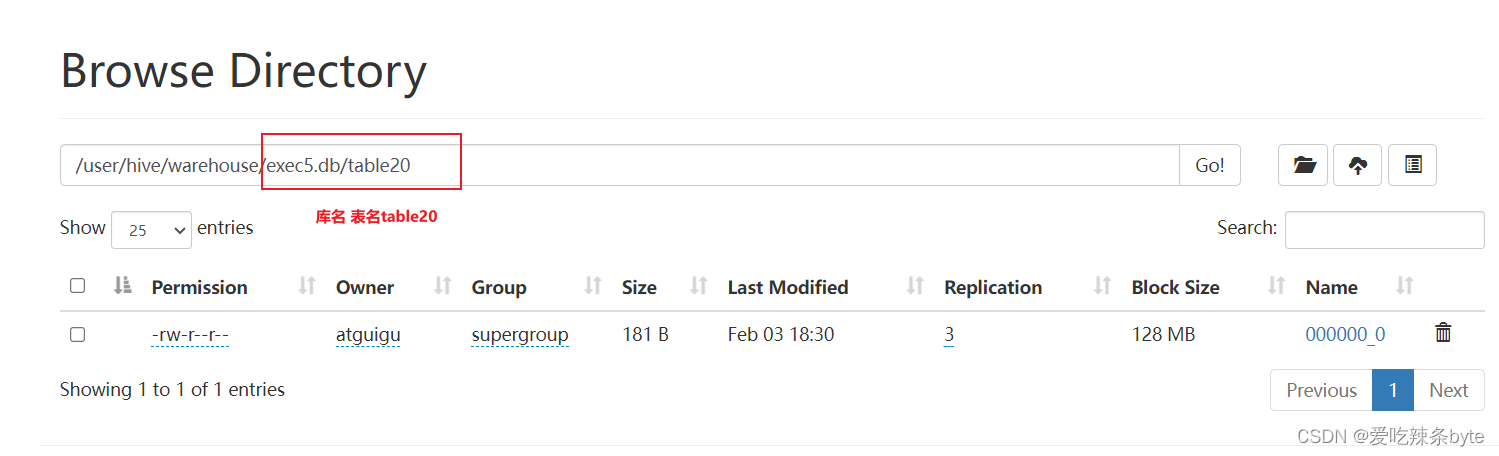
2.4.2 指定存储路径
在Hive建表的时候,可以通过location语法来更改数据在HDFS上的存储路径,使得建表加载数据更加灵活方便,语法为:LOCATION ‘<hdfs_location>’
# 建表语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path] # ===指定表在 HDFS 上的存储位置。
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]# ====例如:退单表的建表语句
DROP TABLE IF EXISTS ods_order_refund_info_inc;
CREATE EXTERNAL TABLE ods_order_refund_info_inc
(`type` STRING COMMENT '变动类型',`ts` BIGINT COMMENT '变动时间',`data` STRUCT<id :STRING,user_id :STRING,order_id :STRING,sku_id :STRING,refund_type :STRING,refund_num :BIGINT,refund_amount:DECIMAL(16, 2),refund_reason_type :STRING,refund_reason_txt :STRING,refund_status :STRING,create_time:STRING> COMMENT '数据',`old` MAP<STRING,STRING> COMMENT '旧值'
) COMMENT '退单表'PARTITIONED BY (`dt` STRING)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.JsonSerDe' --指定serDELOCATION '/warehouse/gmall/ods/ods_order_refund_info_inc/'; -- 指定在hdfs上存储位置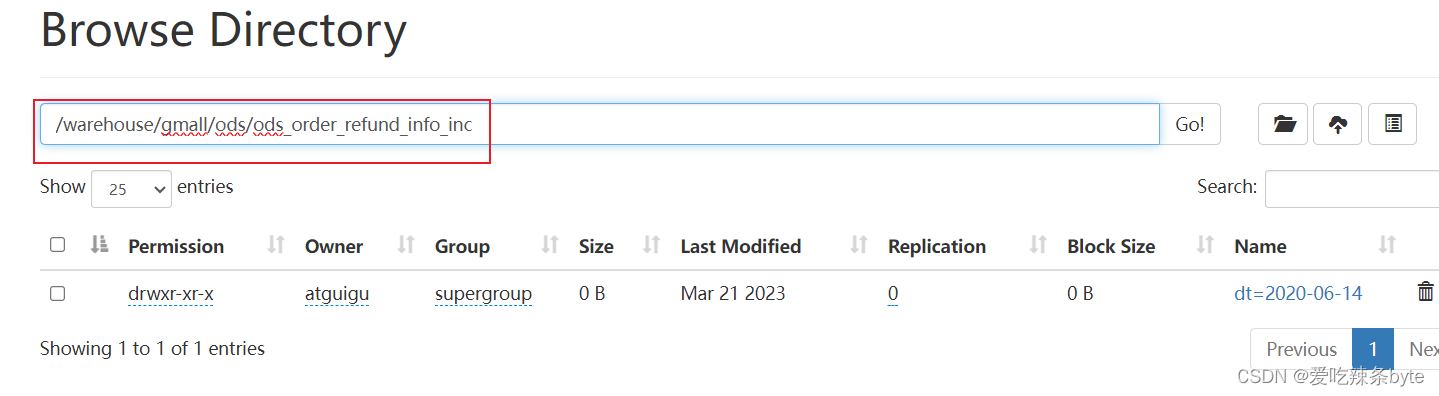
相关文章:
(01)Hive的相关概念——架构、数据存储、读写文件机制
目录 一、架构及组件介绍 1.1 Hive整体架构 1.2 Hive组件 1.3 Hive数据模型(Data Model) 1.3.1 Databases 1.3.2 Tables 1.3.3 Partitions 1.3.4 Buckets 二、Hive读写文件机制 2.1 SerDe 作用 2.2 Hive读写文件流程 2.2.1 读取文件的过程 …...
二维码扫码登录原理,其实比你想的要简单的多
二维码,大家再熟悉不过了 购物扫个码,吃饭扫个码,坐公交也扫个码 在扫码的过程中,大家可能会有疑问:这二维码安全吗? 会不会泄漏我的个人信息? 更深度的用户还会考虑:我的系统是不…...
)
Java 实现 Awaitable(多线程并行等待,类似 AutoEventReset 的作用)
AutoEventReset、ManualEventReset,是我们在多线程并行编程之中常常需要涉及的,但是 ManualEventReset 可能用的并没有那么多,这个多用于实现读写锁的,当然 Java 自己库提供了官方实现,就没必要自己去整了。 C/C 里面…...

AI之Sora:Sora(文本指令生成视频的里程碑模型)的简介(能力/安全性/技术细节)、使用方法、案例应用之详细攻略
AI之Sora:Sora(文本指令生成视频的里程碑模型)的简介(能力/安全性/技术细节)、使用方法、案例应用之详细攻略 导读:Sora 是OpenAI研发的一个可以根据文字描述生成视频的AI模型。它的主要特性、功能以及OpenAI在安全和应用方面的策略的核心要点如下所示&a…...

IListManger feeds流
目的:将feeds的分页加载和下拉刷新,与网络请求关联起来 ListLibRecyclerViewProxy 在this.getRecyclerView().addOnScrollListener中记录事件 recyclerView.computeVerticalScrollOffset() // 已经向下滚动的距离,为0时表示已处于顶部。 recyclerView.computeVerticalScro…...
视频推拉流EasyDSS视频直播点播平台授权出现激活码无效并报错400是什么原因?
视频推拉流EasyDSS视频直播点播平台集视频直播、点播、转码、管理、录像、检索、时移回看等功能于一体,可提供音视频采集、视频推拉流、播放H.265编码视频、存储、分发等视频能力服务,在应用场景上,平台可以运用在互联网教育、在线课堂、游戏…...

设计模式三:工厂模式
工厂模式包括简单工厂模式、工厂方法模式和抽象工厂模式,其中后两者属于23中设计模式 各种模式中共同用到的实体对象类: //汽车类:宝马X3/X5/X7;发动机类:B48TU、B48//宝马汽车接口 public interface BMWCar {void s…...
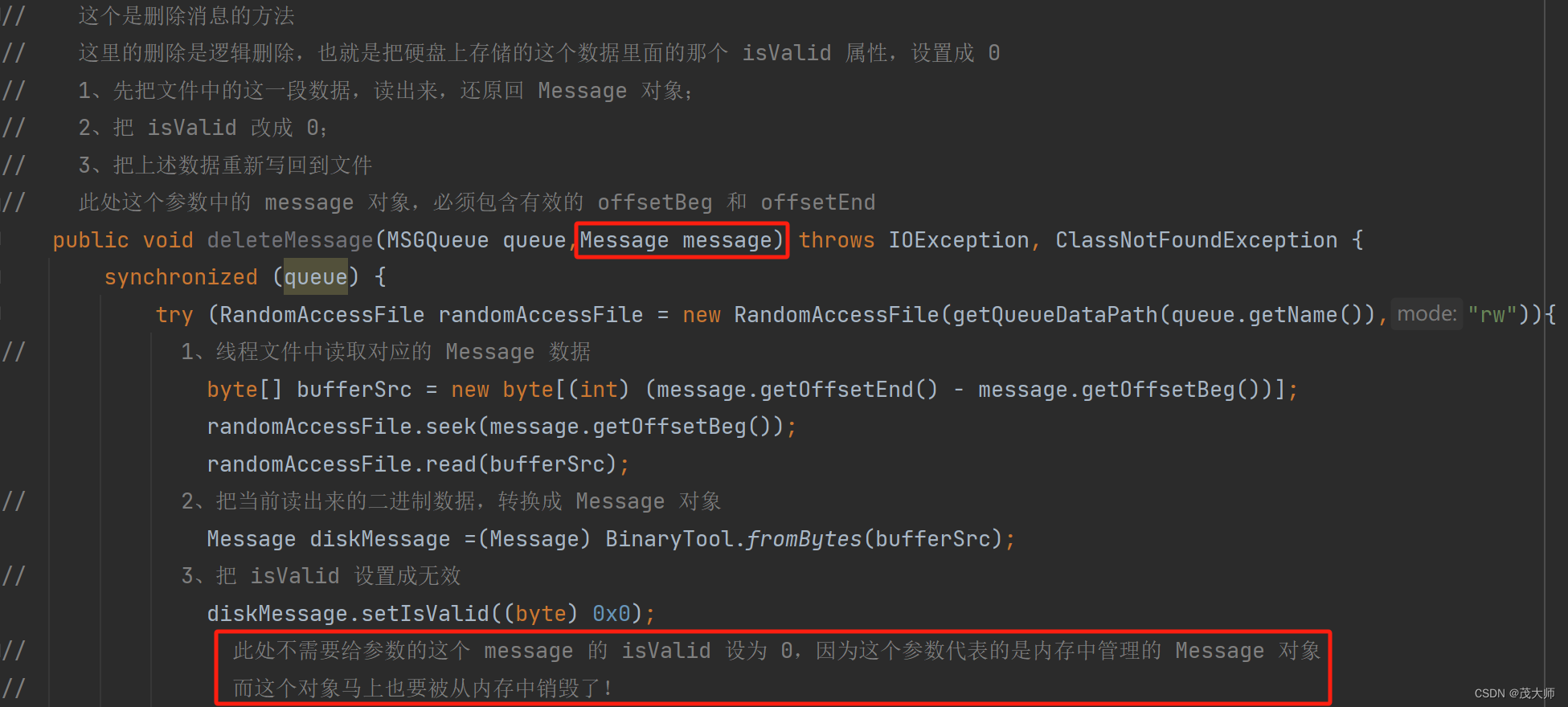
2024.2.15 模拟实现 RabbitMQ —— 消息持久化
目录 引言 约定存储方式 消息序列化 重点理解 针对 MessageFileManager 单元测试 小结 统一硬盘操作 引言 问题: 关于 Message(消息)为啥在硬盘上存储? 回答: 消息操作并不涉及到复杂的增删查改消…...

【技巧】金融企业在搭建服务器时,选择私有云方案还是全栈专属云?
金融企业在搭建服务器时,选择私有云方案还是全栈专属云,需要根据企业的具体需求和情况进行综合考虑。Cloud Ace云一作为谷歌云全球战略合作伙伴,专注于企业级出海云服务 ,为大家带来两种方案的优劣势比较: 私有云 优势…...
模型评测)
【大厂AI课学习笔记】【2.2机器学习开发任务实例】(10)模型评测
目录 一、模型评测的定义 二、模型评测的方法 三、模型评测的原理 四、涉及的关键技术 五、实例阐述 今天是2.2机器学习开发任务实例的最后一个部分——模型评测。 不同的模型计算出的MSE值会有差异,通过模型的选择,参数的变换,可以比较…...
【C++游戏开发-03】贪吃蛇
文章目录 前言一、工具准备1.1游戏开发框架1.2visual studio2022下载1.3easyX下载1.4图片素材 二、逻辑分析2.1数据结构2.2蛇的移动2.3吃食物2.4游戏失败 三、DEMO代码实现四、完整源代码总结 🐱🚀个人博客https://blog.csdn.net/qq_51000584?typeblo…...
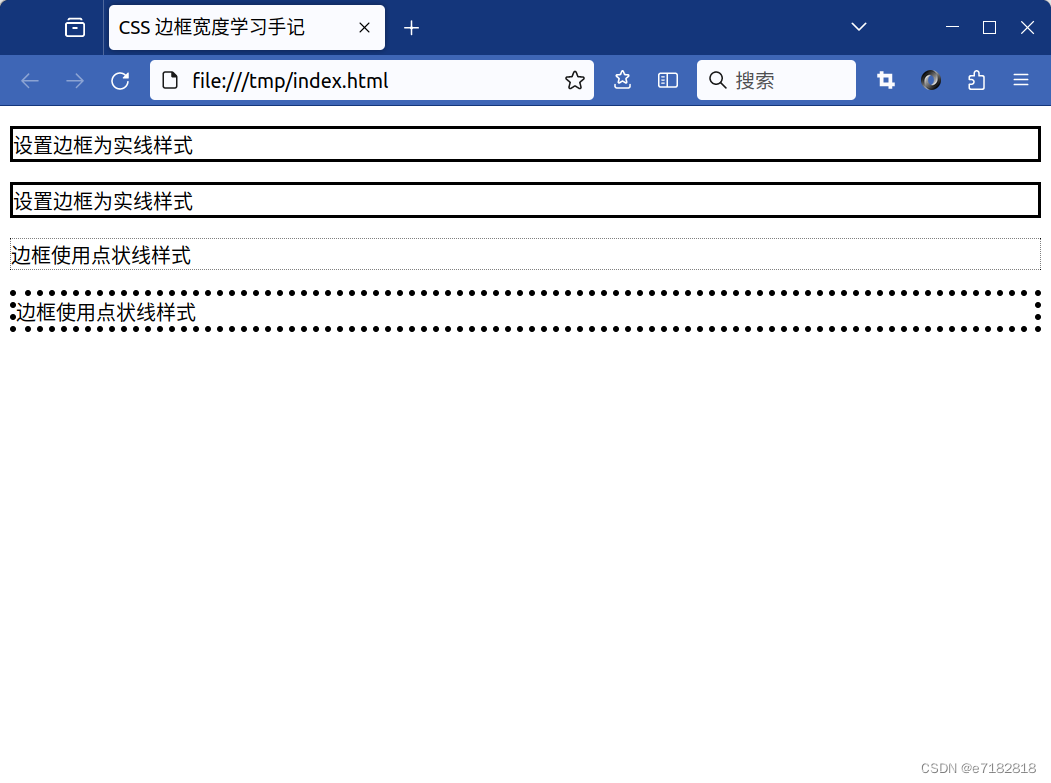
如何理解CSS的边框宽度?
CSS 边框宽度学习手记 CSS 边框宽度小概念 在CSS的世界里,border-width这个属性真的很实用,它能帮我指定HTML元素四周边框的宽度。这个宽度嘛,可以用像素px、点pt、厘米cm、相对单位em这些来表示,很方便吧!还有呢&am…...

java 写入写出 zip
package com.su.test.aaaTest.ioTest; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.util.zip.ZipEntry; import java.util.zip.ZipOutputStream; /** 将文件压缩到 zip 中 */ public c…...
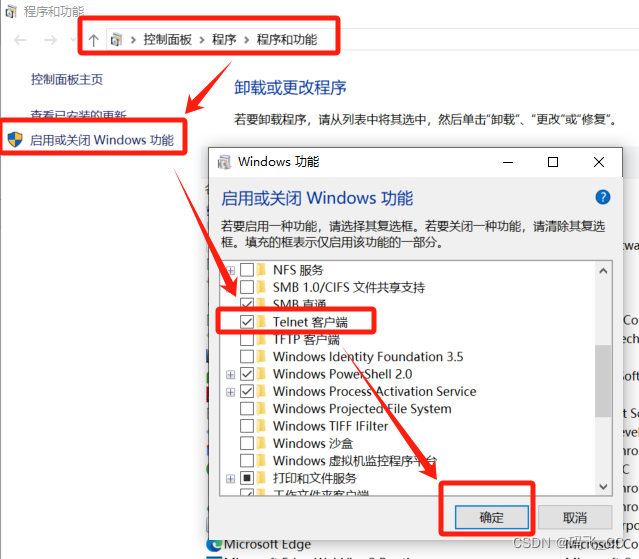
问题解决:‘telnet‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件
当在windows终端中运行telnet指令的时候,发现指令不可用,原因在于系统没安装telnet功能。 解决方法: 打开控制面板–》程序–》启用或关闭windows功能–》勾选Telnet客户端,点击确定即可。...

从基础到高级:Linux用户与用户组权限设置详解
目录 博客前言: 一.简介 1.用户的定义 用户账户分类 2.用户组的定义 二.用户的相关linux语法 1.创建用户(useradd) 2.删除用户(userdel) 3.修改用户(usermod) 4.修改用户密码 5.su切…...
【感知机】感知机(perceptron)学习算法知识点汇总
机器学习——感知机 感知机(perceptron)是一种二分类的线性模型,属于判别模型,也称为线性二分类器。输入为实例的特征向量,输出为实例的类别(取1和-1)。可以视为一种使用阶梯函数激活的人工神经元,例如通过梅尔频率倒谱系数(MFCC…...

蓝桥杯:C++二分算法
在基本算法中,二分法的应用非常广泛,它是一种思路简单、编程容易、效率极高的算法。蓝桥杯软件类大赛中需要应用二分法的题目很常见。 二分法有整数二分和实数二分两种应用场景 二分法的概念 二分法的概念很简单,每次把搜索范围缩小为上一…...

Leetcode刷题笔记题解(C++):83. 删除排序链表中的重复元素
思路:链表相关的问题建议就是画图去解决,虽然理解起来很容易,但就是写代码写不出来有时候,依次去遍历第二节点如果与前一个节点相等则跳过,不相等则遍历第三个节点 /*** Definition for singly-linked list.* struct …...
|Day56(动态规划))
@ 代码随想录算法训练营第8周(C语言)|Day56(动态规划)
代码随想录算法训练营第8周(C语言)|Day56(动态规划) Day56、动态规划(包含题目 ● 300.最长递增子序列 ● 674. 最长连续递增序列 ● 718. 最长重复子数组 ) 300.最长递增子序列 题目描述 给你一个整数…...
C# OpenCvSharp DNN Image Retouching
目录 介绍 模型 项目 效果 代码 下载 C# OpenCvSharp DNN Image Retouching 介绍 github地址:https://github.com/hejingwenhejingwen/CSRNet (ECCV 2020) Conditional Sequential Modulation for Efficient Global Image Retouching 模型 Model Properti…...

剪映专业版教程:制作数据结构快速排序算法原理演示视频
前言 今天教大家用剪映制作数据结构快速排序算法的原理演示视频。一趟冒泡排序只能使一个元素排序到位,而快速排序在一趟操作后不仅能使某个元素排序到位,还能将序列划分为两个子序列——所有比该元素小的都在左边,所有比该元素大的都在右边…...

如何在脑电信号处理的星辰大海中,找到你的开源坐标?[特殊字符]
如何在脑电信号处理的星辰大海中,找到你的开源坐标?🚀 【免费下载链接】eeglab EEGLAB is an open source signal processing environment for electrophysiological signals running on Matlab and developed at the SCCN/UCSD 项目地址: …...

如何打破闭源代码智能模型的垄断?DeepSeek-Coder-V2的技术突围与实践指南
如何打破闭源代码智能模型的垄断?DeepSeek-Coder-V2的技术突围与实践指南 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSe…...
)
告别命令行!用mqtt-spy这个开源神器,5分钟搞定MQTT消息调试(附保姆级配置流程)
可视化MQTT调试革命:mqtt-spy如何让物联网开发效率提升300% 在智能家居和工业物联网项目开发中,MQTT协议因其轻量级和高效性成为设备通信的首选方案。然而,传统的命令行调试方式往往让开发者陷入重复输入命令、难以直观查看消息流的困境。一…...

泛微发布300+可落地AI应用 让组织业务数智升级
5月20日,泛微300AI应用场景体验大会在上海举办。大会以“组织的AI范式数字员工与业务流程AI新生”为主题, 展示泛微全场景AI应用。泛微搭载五大智能引擎,提供300可快速落地的AI应用场景,覆盖市场、销售、项目、合同、采购、财务、…...

“文章同步助手” Wechatsync 连接到WordPress独立站
“文章同步助手” Wechatsync 浏览器插件,可以将文章一键分发到包括WordPress在内的二十多个内容平台- 。这连接逻辑本质上都是调用WordPress的REST API来建立连接。 🔌 连接独立站 WordPress 的操作流程 要实现同步,你需要在浏览器插件中配置…...

从SEO到GEO的技术跃迁:如何利用本地化RAG架构解决企业私域数据的“幻觉”难题?
在2026年的今天,传统的SEO(搜索引擎优化)正在经历一场前所未有的降维打击。当用户习惯从百度跳转至豆包、DeepSeek或Kimi等生成式AI提问时,流量的分发逻辑已经从“点击网页”变成了“AI直接生成答案”。这就是我们常说的 GEO&…...

终极指南:119,376个英语单词发音MP3音频一键下载完整教程 [特殊字符]
终极指南:119,376个英语单词发音MP3音频一键下载完整教程 🎧 【免费下载链接】English-words-pronunciation-mp3-audio-download Download the pronunciation mp3 audio for 119,376 unique English words/terms 项目地址: https://gitcode.com/gh_mir…...

RPC 核心概念 05:超时、重试、熔断与限流
RPC 核心概念 05:超时、重试、熔断与限流 如果说服务发现是 RPC 的"基础设施",那么超时、重试、熔断、限流就是 RPC 的安全气囊——决定了系统在故障来临时还能否站立。本篇讲清楚这四件套的边界、配合与陷阱。 一、为什么需要这些?…...

ElevenLabs广东话语音商用避坑清单:92%开发者忽略的版权边界、方言标注规范与GDPR合规红线
更多请点击: https://kaifayun.com 第一章:ElevenLabs广东话语音商用落地的现实困局 ElevenLabs 作为全球领先的AI语音生成平台,其英语、西班牙语等主流语言模型已广泛应用于客服、播客与教育场景。然而,当尝试将其语音合成能力延…...