【感知机】感知机(perceptron)学习算法知识点汇总
机器学习——感知机
感知机(perceptron)是一种二分类的线性模型,属于判别模型,也称为线性二分类器。输入为实例的特征向量,输出为实例的类别(取+1和-1)。可以视为一种使用阶梯函数激活的人工神经元,例如通过梅尔频率倒谱系数(MFCC)对语音进行分类或通过图像的像素值对图像进行分类。
目录
感知机模型
感知机的几何解释
数据集的线性可分性
感知机学习策略
感知机学习算法
感知机学习算法的原始形式
感知机学习算法的对偶形式
算法的收敛性
感知机算法例题
感知机优缺点
感知机模型
定义 设输入空间(特征空间),输出空间
。输入
表示实例的特征向量,对应于输入空间的点,输出
表示实例的类别,由输入空间到输出空间的函数
称为感知机。
w,b为参数。叫做权值或权值向量(weight vector),b叫作偏置(bias)
符号函数sign的功能是取某个数的符号
感知机模型的假设空间是定义在特征空间中的所有线性分类模型或线性分类器,即函数集合
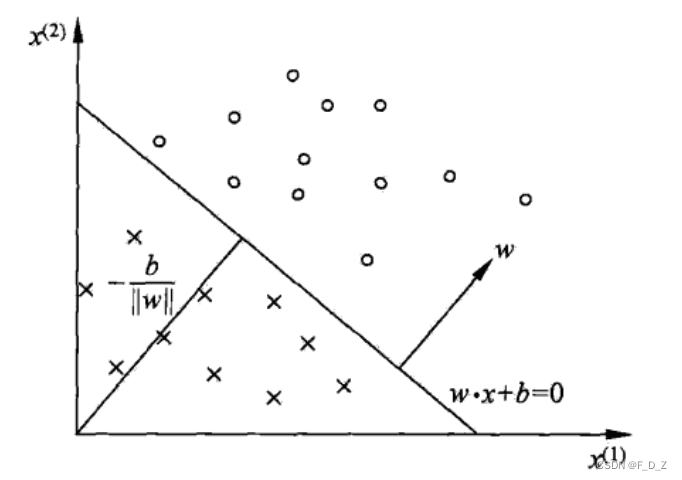
感知机的几何解释
:对应特征空间
中的一个超平面
,这个超平面将特征空间划分为两个部分,称为分离超平面(separating hyperplane)
b:超平面的截距
w:超平面的法向量
数据集的线性可分性
给定一个数据集,其中
,
,如果存在一个超平面
,能够正确地划分所有正负实例点,则称数据集
为线性可分数据集(linearky separable data set),否则称其线性不可分.
感知机学习策略
假设训练数据集线性可分
学习目标:求得正确划分训练集中所有正负实例点的分离超平面
学习策略:1、确定一个损失函数。2、选取使损失函数最小的参数。
损失函数的选择:误分类点到分离超平面的距离
任一点到超平面的距离公式:
,其中
是
的
范数,
向量的
范数:向量各元素平方和的平方根
定理1:对于误分类数据,有
从而由距离公式和定理1,得
误分类点到超平面的距离公式:
实现了去掉绝对值的工作
所有误分类点到超平面的总距离: ,
为误分类点集合
不必考虑,最终得到损失函数
损失函数:
一 个特定的样本点的损失函数:在误分类时是参数
的线性函数;在正确分类时是0。
因此,
给定训练数据集时,损失函数是
的连续可导函数
感知机学习算法
感知机学习算法的原始形式
输入:训练数据集,其中
,
,学习率
1.任意选取初值
2.任意顺序遍历,计算
,当
,转到步骤3;若对任意
,
,转到输出
3. ,
,转到步骤2.
输出:;感知机
算法采用随机梯度下降法(stochastic gradient descent):
首先任意选取一个超平面,然后用梯度下降法极小化损失函数。极小化过程不是一次使所有误分类点的梯度下降,而是每次随机选取一个误分类点使其梯度下降。
设误分类点集合M固定,损失函数
的梯度为:
对某点
,
的梯度
是增大的方向,故
使损失函数减少。
算法理解:当一个实例点被误分类时,则调整w,b的值,使分类超平面向该误分类点的一侧移动,减少该误分类点与超平面的距离,直至超平面越过该误分类点使其被正确分类
感知机学习算法的对偶形式
感知机学习算法的原始形式和对偶形式与支特向量机学习算法的原始形式和对偶形式相对应
输入:训练数据集,其中
,
,学习率
1.其中
2.任意顺序遍历,计算
,当
,转到步骤3;若对任意
,
,转到输出
3. ,
,转到步骤2
输出:;感知机
对偶形式的基本想法:将
表示为实例
和标记
的线性组合的形式,通过求解其系数来求解
基于原始形式,可设
,则迭代n次后,设第
个实例点由于误分而更新的次数为
,令
,有
,
。
注意:实例点更新次数越多,意味着它离分离超平面越近,意味着越难分类。这样的实例点对于学习结果的影响最大。
Gram矩阵:对偶形式中的训练实例仅以内积的形式出现,将实例间的内积计算出来并以矩阵的形式储存,
,称为Gram矩阵
算法的收敛性
算法原始形式收敛:意味着经过有限次迭代可得到一个将训练数据集完全正确划分的分离超平面
为便于推导,记,扩充输入向量,记
,则有
,
,
(Novikoff)定理 设训练集线性可分,其中
,
,则:
(1)存在满足的超平面
将训练数据集完全正确分开,且存在
,对所有
,
(2)令,则感知机学习算法在训练数据集上的误分类次数k满足不等式
定理表明,当训练数据集线性可分时,经过有限次搜索可以找到将训练数据集完全正确分开的超平面,即算法的原始形式收敛。
感知机算法例题
例1 训练数据集如图所示,正实例点为,
,负实例点为
,试用感知机算法原始形式求感知机模型,令
,

解答:
(1)建模最优化问题:
(2)取初值,
(3)按顺序,对
,
,则
为误分类点。更新
:
,
得到线性模型:
(4)重新选取,对,
,则均为正确分类点,不更新
;
对,
,则
为误分类点,更新
:
,
得到线性模型:
(5)由此不断迭代
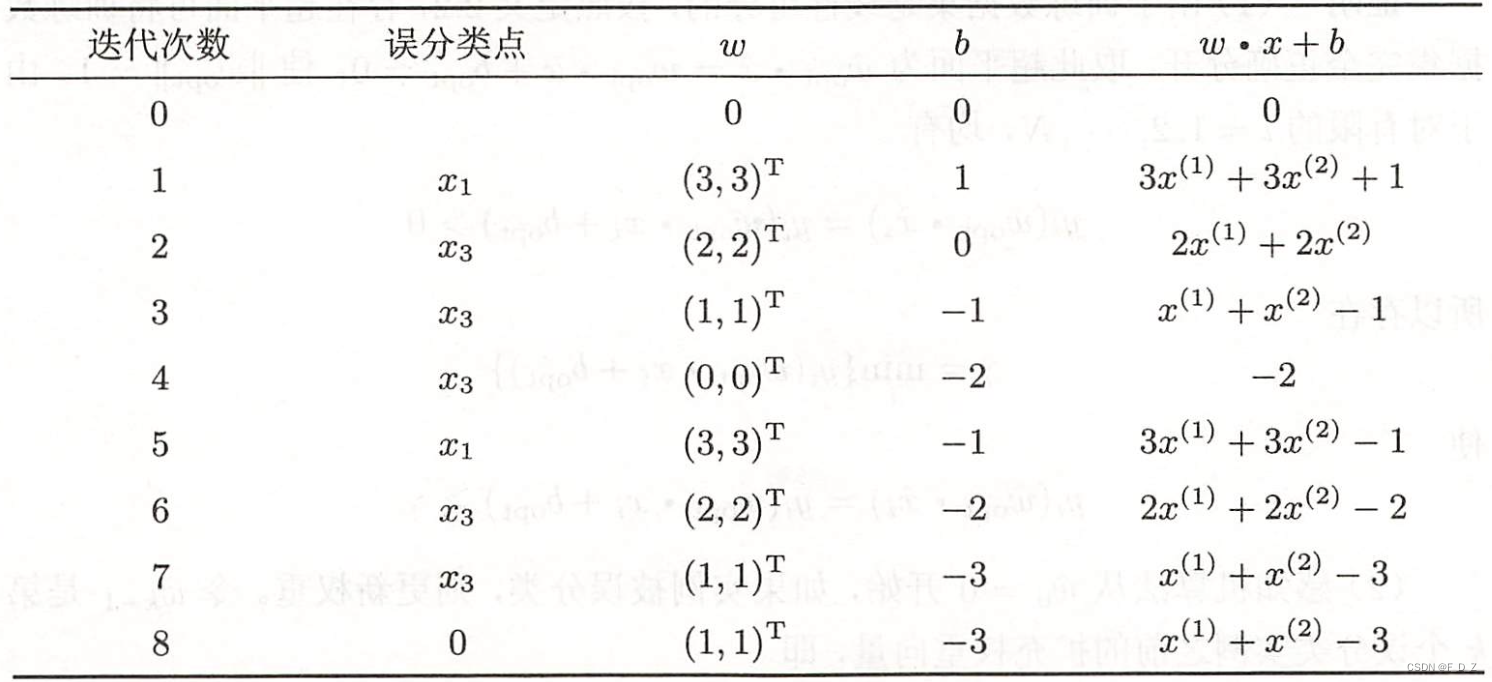
(6)直到,
线性模型:
对所有数据点,则确定分离超平面:
感知机模型
分离超平面
是按照
的取点顺序得到的
例1如果更换取点顺序为
,得到的分离超平面为:
由此,可知结论:感知机算法采用不同的初值或选取不同的误分类点顺序,解可以不同
例2 训练数据集如图所示,正实例点为,
,负实例点为
,试用感知机算法对偶形式求感知机模型,令
,
解答:
(1)取;
(2)计算Gram矩阵
(3)误分条件
(4)参数更新
(5)迭代
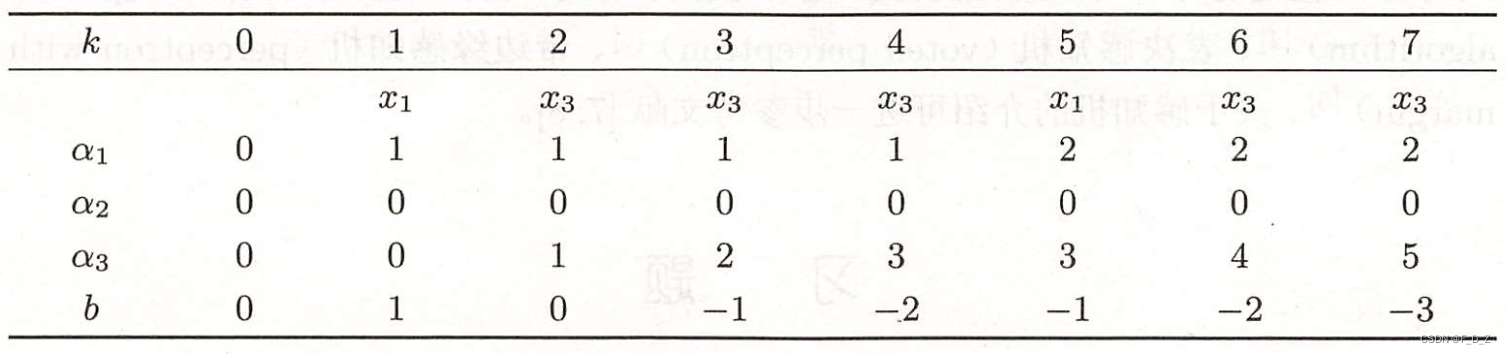
(6)最终得到
则,分离超平面:
感知机模型:
与原始形式一致,感知机学习算法的对偶形式迭代收敛,且存在多个解
感知机优缺点
优点:简单、易于实现、运行速度快
缺点:仅处理线性可分问题,面对多类别多分类问题需要多个分类器导致训练成本增加
在例题的实际操作中可以发现,感知机学习算法存在许多解,这些解既依赖于初值的选择,也依赖于选代过程中误分类点的选择顺序。而为了得到唯一的超平面,需要对分离超平面增加约束条件,这就涉及到了线性支持向量机的想法。
相关文章:
【感知机】感知机(perceptron)学习算法知识点汇总
机器学习——感知机 感知机(perceptron)是一种二分类的线性模型,属于判别模型,也称为线性二分类器。输入为实例的特征向量,输出为实例的类别(取1和-1)。可以视为一种使用阶梯函数激活的人工神经元,例如通过梅尔频率倒谱系数(MFCC…...

蓝桥杯:C++二分算法
在基本算法中,二分法的应用非常广泛,它是一种思路简单、编程容易、效率极高的算法。蓝桥杯软件类大赛中需要应用二分法的题目很常见。 二分法有整数二分和实数二分两种应用场景 二分法的概念 二分法的概念很简单,每次把搜索范围缩小为上一…...

Leetcode刷题笔记题解(C++):83. 删除排序链表中的重复元素
思路:链表相关的问题建议就是画图去解决,虽然理解起来很容易,但就是写代码写不出来有时候,依次去遍历第二节点如果与前一个节点相等则跳过,不相等则遍历第三个节点 /*** Definition for singly-linked list.* struct …...
|Day56(动态规划))
@ 代码随想录算法训练营第8周(C语言)|Day56(动态规划)
代码随想录算法训练营第8周(C语言)|Day56(动态规划) Day56、动态规划(包含题目 ● 300.最长递增子序列 ● 674. 最长连续递增序列 ● 718. 最长重复子数组 ) 300.最长递增子序列 题目描述 给你一个整数…...
C# OpenCvSharp DNN Image Retouching
目录 介绍 模型 项目 效果 代码 下载 C# OpenCvSharp DNN Image Retouching 介绍 github地址:https://github.com/hejingwenhejingwen/CSRNet (ECCV 2020) Conditional Sequential Modulation for Efficient Global Image Retouching 模型 Model Properti…...

通过Docker Compose的方式在Docker中安装Maven环境
目前可以说 Docker 已经是在开发部署中成为主流,所以我们很多环境和工具都会安装在 Docker 容器中,Maven 环境是 SpringBoot 项目中最常用的依赖管理工具。当我们使用自动运维工具如 Ansible、Chef 、Puppet、Walle、Spug等)管理和部署 Maven…...
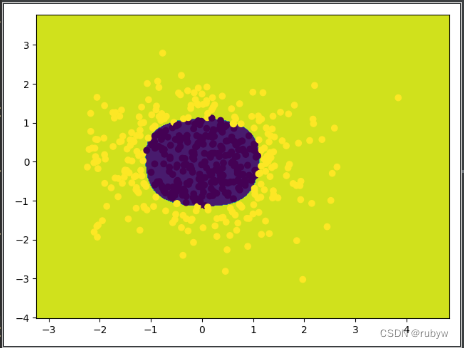
Python实现线性逻辑回归和非线性逻辑回归
线性逻辑回归 # -*- coding: utf-8 -*- """ Created on 2024.2.20author: rubyw """import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import classification_report from sklearn import preprocessing from sklearn…...

【软考】软件维护
目录 一、说明二、正确性维护三、适应性维护四、完善性维护五、预防性维护 一、说明 1.软件维护主要是根据需求变化或硬件环境的变化对应用程序进行部分或全部修改 2.修改时应充分利用源程序,修改后要填写程序修改登记表,并在程度变更通知书上写明新旧程…...

突破性创新:OpenAI推出Sora视频模型,预示视频制作技术的未来已到来!
一、前言 此页面上的所有视频均由 Sora 直接生成,未经修改。 OpenAI - Sora is an AI model that can create realistic and imaginative scenes from text instructions. 2024 年 2 月 16 日,OpenAI 发布 AI 视频模型 Sora,60 秒的一镜到底…...
【Web前端笔记10】CSS3新特性
10 CSS3新特性 1、圆角 2、阴影 (1)盒阴影 3、背景渐变 (1)线性渐变(主要掌握这种就可) (2)径向渐变 &…...

LabVIEW荧光显微镜下微管运动仿真系统开发
LabVIEW荧光显微镜下微管运动仿真系统开发 在生物医学研究中,对微管运动的观察和分析至关重要。介绍了一个基于LabVIEW的仿真系统,模拟荧光显微镜下微管的运动过程。该系统提供了一个高效、可靠的工具,用于研究微管与运动蛋白(如…...

【Java面试】MQ(Message Queue)消息队列
目录 一、MQ介绍二、MQ的使用1应用解耦2异步处理3流量削峰4日志处理5消息通讯三、使用 MQ 的缺陷1.系统可用性降低:2.系统复杂性变高3.一致性问题四、常用的 MQActiveMQ:RabbitMQ:RocketMQ:Kafka:五、如何保证MQ的高可用?ActiveMQ:RabbitMQ:RocketMQ:Kafka:六、如何保…...
【安卓基础1】初识Android
🏆作者简介:|康有为| ,大四在读,目前在小米安卓实习,毕业入职。 🏆安卓学习资料推荐: 视频:b站搜动脑学院 视频链接 (他们的视频后面一部分没再更新,看看前面…...
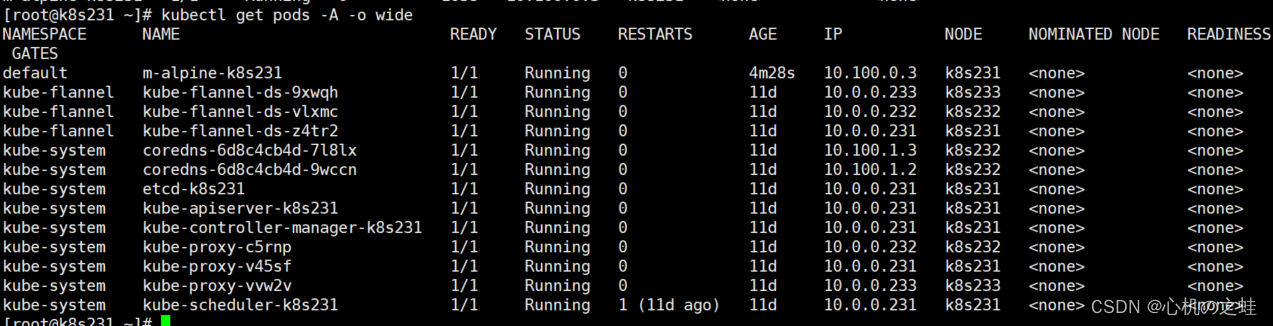
08-静态pod(了解即可,不重要)
我们都知道,pod是kubelet创建的,那么创建的流程是什么呐? 此时我们需要了解我们k8s中config.yaml配置文件了; 他的存放路径:【/var/lib/kubelet/config.yaml】 一、查看静态pod的路径 [rootk8s231 ~]# vim /var/lib…...
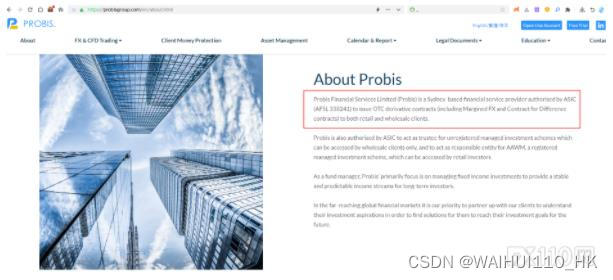
PROBIS铂思金融破产后续:ASIC牌照已注销
2024年1月31日,PROBIS铂思金融的澳大利亚ASIC牌照 (AFSL 338241) 被注销《差价合约经纪商PROBIS宣布破产,澳大利亚金融服务牌照遭暂停》,这也就意味着,PROBIS铂思金融目前已经没有任何金融牌照。 值得注意的是,时至今日…...

数字世界的探索者:计算机相关专业电影精选推荐
目录 推荐计算机专业必看的几部电影 《黑客帝国》 《社交网络》 《乔布斯传》 《心灵捕手》 《源代码》 《盗梦空间》 《头号玩家》 《我是谁:没有绝对安全的系统》 《战争游戏》(WarGames) 《模仿游戏》(The Imitation Game) 《硅谷》(Silicon Valley) …...

Spring Boot项目中TaskDecorator的应用实践
一、前言 TaskDecorator是一个执行回调方法的装饰器,主要应用于传递上下文,或者提供任务的监控/统计信息,可以用于处理子线程与主线程间数据传递的问题。 二、开发示例 1.自定义TaskDecorator import org.springframework.core.task.Task…...

511. 游戏玩法分析 I
文章目录 题意思路代码 题意 题目链接 统计每个用户第一次登陆平台时间 思路 代码 select player_id, min(event_date) as first_login from Activity group by player_id;...
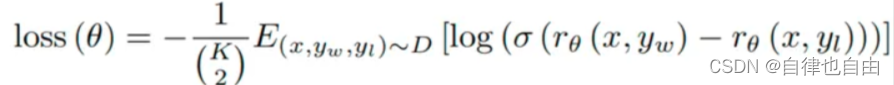
大模型训练流程(三)奖励模型
为什么需要奖励模型 因为指令微调后的模型输出可能不符合人类偏好,所以需要利用强化学习优化模型,而奖励模型是强化学习的关键一步,所以需要训练奖励模型。 1.模型输出可能不符合人类偏好 上一篇讲的SFT只是将预训练模型中的知识给引导出来…...

替换if...else的锦囊妙计
目录 前言 一、又臭又长的if...else 二、消除if...else的锦囊妙计 1、使用注解 2、动态拼接名称 3、模板方法判断 4.策略工厂模式 5.责任链模式 6、其他的消除if...else的方法 1.根据不同的数字返回不同的字符串 2.集合中的判断 3.简单的判断 4.spring中的判断 原文…...

为OpenClaw智能体工作流配置Taotoken作为稳定的模型供应后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw智能体工作流配置Taotoken作为稳定的模型供应后端 在构建基于OpenClaw的复杂自动化工作流时,一个稳定且模型…...

如何彻底解决游戏键盘冲突:Hitboxer SOCD Cleaner完整指南
如何彻底解决游戏键盘冲突:Hitboxer SOCD Cleaner完整指南 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对战中遇到过这样的困扰?同时按下W和S键时角色突然卡顿&…...
)
今日算法(构造二叉搜索树)
题目描述给你一个整数数组 nums,其中元素已经按 升序 排列,请你将其转换为一棵 平衡 二叉搜索树(BST)。平衡二叉搜索树:左右两个子树的高度差的绝对值不超过 1每个节点的左右子树都是平衡二叉树二叉搜索树的中序遍历结…...

三步掌握免费文档下载神器:kill-doc浏览器脚本完全指南
三步掌握免费文档下载神器:kill-doc浏览器脚本完全指南 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为了…...
)
算法高频难题——链表环检测(快慢指针核心实现)
链表操作是算法面试的重中之重,而“检测链表中是否存在环”更是高频考题,字节、阿里等大厂面试中多次出现,热度稳居算法类难题TOP3。很多开发者会陷入“遍历存节点”的误区,导致空间复杂度过高,无法通过面试优化要求。…...

跨境漫游通信解析:全球漫游物联网卡的适配逻辑与行业应用
在跨境物联网行业中,除固定单一国家投放的设备外,有大量终端设备存在跨区域流动、多国家部署、不定向出海的使用需求。车载定位、跨境物流终端、移动式工控、巡回检测设备,这类硬件无法限定单一运营商网络,对多国网络切换、信号漫…...

[QA]插件式测试用例生成工具:LLM Test Case Tool 的设计与实现
一句话介绍:QA 在需求分析和测试设计中常用的能力沉淀到浏览器插件里:用户在阅读 PRD 时,可以直接在页面右下角调用 Workee,完成摘要、大纲、疑点、测试点、测试用例、UAT 用例和多页面分析。 1. 背景:为什么还需要这个…...

系统内存报告
used_mem$(free | grep Mem | tr -s ""|cut -d "" -f3) total_mem$(free | grep Mem | tr -s ""|cut -d "" -f2) percent$(($used_mem * 100 / $total_mem)) [[ $percet -gt 50 ]] && echo "内存告警" ||echo "…...

PaddleOCR训练集制作避坑指南:从text_renderer合成到roLabelImg标注的全链路解析
PaddleOCR训练集制作全流程实战:从数据合成到模型调优的完整方法论 在工业级OCR项目落地过程中,数据集质量往往比模型架构更能决定最终效果上限。不同于学术界的标准benchmark竞赛,真实业务场景面临字体缺失、背景干扰、版式多变等复杂挑战。…...

ZYNQ启动全解析:从BootROM到你的App,SD卡与QSPI Flash烧录究竟差在哪?
ZYNQ启动全解析:从BootROM到你的App,SD卡与QSPI Flash烧录究竟差在哪? 当一块ZYNQ开发板静静躺在桌面上,按下电源键的瞬间,芯片内部究竟发生了什么?为什么有的工程师选择SD卡启动,而另一些则坚…...