突破性创新:OpenAI推出Sora视频模型,预示视频制作技术的未来已到来!
一、前言
此页面上的所有视频均由 Sora 直接生成,未经修改。
OpenAI - Sora is an AI model that can create realistic and imaginative scenes from text instructions.

2024 年 2 月 16 日,OpenAI 发布 AI 视频模型 Sora,60 秒的一镜到底,惊艳的效果生成。AI 视频生成可能要变天?
二、主要内容
能力
OpenAI 正在教授 AI 理解和模拟运动中的物理世界,目标是训练出能帮助人们解决需要与现实世界互动的问题的模型。目前的成果是 Sora,OpenAI 最新发布的从文本生成视频模型。Sora 能够生成长达一分钟的视频,同时保持视觉品质和对用户提示的遵循。
2024 年 2 月 26 日,Sora 即将向红队人员开放,以评估关键领域的潜在危害或风险。OpenAI 还允许一些视觉艺术家、设计师和电影制作人使用,以便获得反馈,进一步优化模型,使其对创意专业人士更有帮助。OpenAI 提早分享他们的研究进展,以便开始与 OpenAI 之外的人们合作并从他们那里获取反馈,同时让公众对即将到来的 AI 能力有所了解。
Sora 能够生成包含多个角色、特定类型的运动以及主题和背景的准确细节的复杂场景。这个模型不仅理解用户在提示中请求的内容,还理解这些事物在物理世界中的存在方式。该模型对语言有着深刻的理解,使其能够准确解读提示并生成表情丰富的引人入胜的角色。Sora 还能在单个生成的视频中创造出多个画面,准确地保持角色和视觉风格的一致性。
当前模型有缺陷。它可能在准确模拟复杂场景的物理现象方面遇到困难,也可能无法理解特定的因果关系。例如,一个人可能会咬一口饼干,但之后,饼干可能不会留下咬痕。该模型也可能会混淆提示的空间细节,例如,将左和右搞混,而且可能难以准确描述随时间发生的事件,比如遵循特定的摄像机轨迹。
安全
在将 Sora 应用于 OpenAI 产品之前,OpenAI 将采取几个重要的安全措施。OpenAI 正在与红队人员(错误信息、仇恨内容和偏见等领域的专家)合作,他们将对模型进行对抗性测试。OpenAI 还在开发一些工具来帮助检测误导性内容,例如检测分类器,它可以分辨出视频是由 Sora 生成的。如果在 OpenAI 产品中部署该模型,OpenAI 计划在未来加入 C2PA 元数据。
除了开发新技术为部署做准备外,OpenAI 还在利用现有的安全方法,这些方法是 OpenAI 为使用 DALL-E 3 的产品建立的,也适用于 Sora。例如,一旦进入 OpenAI 产品,OpenAI 的文本分类器就会检查并拒绝违反 OpenAI 使用政策的文本输入提示,例如要求输入极端暴力、性内容、仇恨图像、名人肖像或他人知识产权的内容。OpenAI 还开发了强大的图像分类器,用于审查生成的每段视频的帧数,以帮助确保视频在播放给用户之前符合使用政策。
OpenAI 将与世界各地的政策制定者、教育工作者和艺术家接触,以了解他们的担忧,并确定这项新技术的积极应用案例。尽管进行了广泛的研究和测试,但 OpenAI 无法预测人们使用这项技术的所有有益方式,也无法预测人们滥用技术的所有方式。这就是为什么 OpenAI 相信,从现实世界的使用中学习,是随着时间的推移创建和发布越来越安全的人工智能系统的重要组成部分。
研究技术
Sora 是一种扩散模型,它从一个看起来像静态噪音的视频开始生成视频,然后通过多个步骤去除噪音,逐渐转换视频。Sora 能够一次性生成整个视频,或延长生成的视频,使其更长。通过让模型一次预见多帧画面,OpenAI 解决了一个具有挑战性的问题,那就是即使主体暂时离开视线,也要确保主体保持不变。
与 GPT 模型类似,Sora 也采用了 Transformer 架构,释放了卓越的扩展性能。OpenAI 将视频和图像表示为更小的数据单元集合,称为 “补丁”(patches),每个补丁类似于 GPT 中的令牌(token)。通过统一数据表示方式,我们可以在比以往更广泛的视觉数据上训练 diffusion transformers,包括不同的持续时间、分辨率和宽高比。
Sora 建立在过去对 DALL-E 和 GPT 模型的研究基础之上。它采用了 DALL-E 3 中的重述技术,即为视觉训练数据生成高度描述性的字幕。因此,该模型能够在生成的视频中更忠实地遵循用户的文字说明。该模型不仅能根据文字说明生成视频,还能根据现有的静止图像生成视频,并能准确、细致地对图像内容进行动画处理。该模型还能提取现有视频,并对其进行扩展或填充缺失的帧。更多信息,请参阅 OpenAI 的技术报告。
Sora 是能够理解和模拟现实世界的模型的基础,我们相信这种能力将是实现 AGI 的重要里程碑。
三、总结
OpenAI 发布其首个 AI 视频生成模型 Sora:这是一个能够根据文本指令生成逼真而富有想象力的视频的模型,它使用了扩散模型和 Transformer 架构,能够生成长达一分钟的超长视频,还能保持多镜头的一致性。
Sora 展现了对世界的理解和模拟:这个模型能够学习到关于 3D 几何、物理规律、语义理解和故事叙述的知识,它甚至能够创造出类似皮克斯作品的动画效果,有着世界模型的雏形。
Sora 颠覆了视频生成领域:这个模型的效果远超过了目前的 AI 视频工具,如 Runway Gen 2 和 Pika,它能够实现视频和现实的无缝对接,让普通人也能在社交媒体上制作出高质量的视频内容。
Sora 可能为实现 AGI 奠定了基础:这个模型是对真实世界和虚构世界的模拟,是通用人工智能的重要步骤,也是 OpenAI 的核心使命。
最新消息:本文是设想的方式,但 Sora 目前还未正式对外上线。后续预计先在 ChatGPT Plus 会员覆盖。
如果你想体验 ChatGPT4 服务,可以查看这篇文章:ChatGPT4.0升级教程
相关文章:
突破性创新:OpenAI推出Sora视频模型,预示视频制作技术的未来已到来!
一、前言 此页面上的所有视频均由 Sora 直接生成,未经修改。 OpenAI - Sora is an AI model that can create realistic and imaginative scenes from text instructions. 2024 年 2 月 16 日,OpenAI 发布 AI 视频模型 Sora,60 秒的一镜到底…...
【Web前端笔记10】CSS3新特性
10 CSS3新特性 1、圆角 2、阴影 (1)盒阴影 3、背景渐变 (1)线性渐变(主要掌握这种就可) (2)径向渐变 &…...

LabVIEW荧光显微镜下微管运动仿真系统开发
LabVIEW荧光显微镜下微管运动仿真系统开发 在生物医学研究中,对微管运动的观察和分析至关重要。介绍了一个基于LabVIEW的仿真系统,模拟荧光显微镜下微管的运动过程。该系统提供了一个高效、可靠的工具,用于研究微管与运动蛋白(如…...

【Java面试】MQ(Message Queue)消息队列
目录 一、MQ介绍二、MQ的使用1应用解耦2异步处理3流量削峰4日志处理5消息通讯三、使用 MQ 的缺陷1.系统可用性降低:2.系统复杂性变高3.一致性问题四、常用的 MQActiveMQ:RabbitMQ:RocketMQ:Kafka:五、如何保证MQ的高可用?ActiveMQ:RabbitMQ:RocketMQ:Kafka:六、如何保…...
【安卓基础1】初识Android
🏆作者简介:|康有为| ,大四在读,目前在小米安卓实习,毕业入职。 🏆安卓学习资料推荐: 视频:b站搜动脑学院 视频链接 (他们的视频后面一部分没再更新,看看前面…...
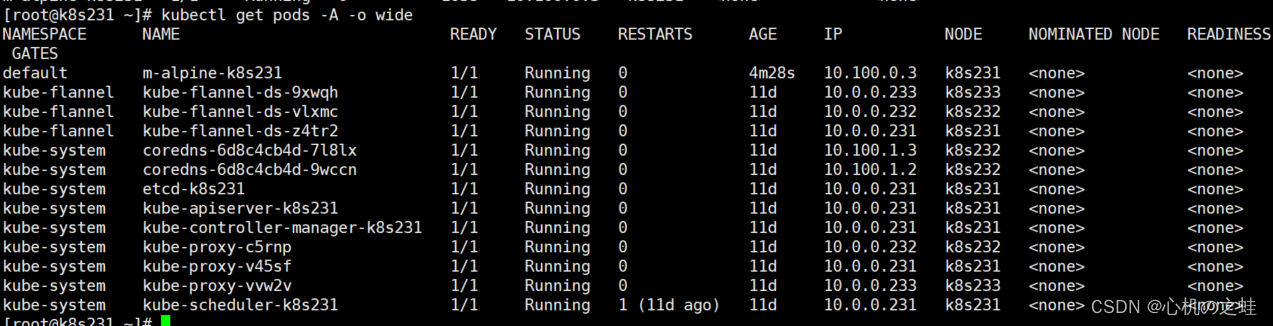
08-静态pod(了解即可,不重要)
我们都知道,pod是kubelet创建的,那么创建的流程是什么呐? 此时我们需要了解我们k8s中config.yaml配置文件了; 他的存放路径:【/var/lib/kubelet/config.yaml】 一、查看静态pod的路径 [rootk8s231 ~]# vim /var/lib…...
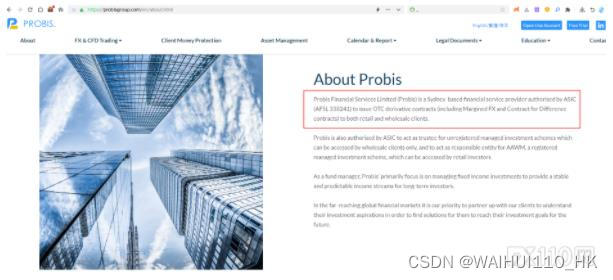
PROBIS铂思金融破产后续:ASIC牌照已注销
2024年1月31日,PROBIS铂思金融的澳大利亚ASIC牌照 (AFSL 338241) 被注销《差价合约经纪商PROBIS宣布破产,澳大利亚金融服务牌照遭暂停》,这也就意味着,PROBIS铂思金融目前已经没有任何金融牌照。 值得注意的是,时至今日…...

数字世界的探索者:计算机相关专业电影精选推荐
目录 推荐计算机专业必看的几部电影 《黑客帝国》 《社交网络》 《乔布斯传》 《心灵捕手》 《源代码》 《盗梦空间》 《头号玩家》 《我是谁:没有绝对安全的系统》 《战争游戏》(WarGames) 《模仿游戏》(The Imitation Game) 《硅谷》(Silicon Valley) …...

Spring Boot项目中TaskDecorator的应用实践
一、前言 TaskDecorator是一个执行回调方法的装饰器,主要应用于传递上下文,或者提供任务的监控/统计信息,可以用于处理子线程与主线程间数据传递的问题。 二、开发示例 1.自定义TaskDecorator import org.springframework.core.task.Task…...

511. 游戏玩法分析 I
文章目录 题意思路代码 题意 题目链接 统计每个用户第一次登陆平台时间 思路 代码 select player_id, min(event_date) as first_login from Activity group by player_id;...
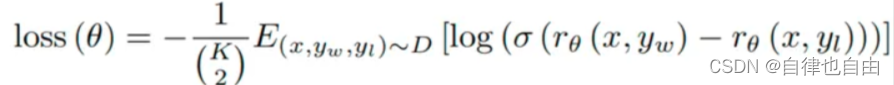
大模型训练流程(三)奖励模型
为什么需要奖励模型 因为指令微调后的模型输出可能不符合人类偏好,所以需要利用强化学习优化模型,而奖励模型是强化学习的关键一步,所以需要训练奖励模型。 1.模型输出可能不符合人类偏好 上一篇讲的SFT只是将预训练模型中的知识给引导出来…...

替换if...else的锦囊妙计
目录 前言 一、又臭又长的if...else 二、消除if...else的锦囊妙计 1、使用注解 2、动态拼接名称 3、模板方法判断 4.策略工厂模式 5.责任链模式 6、其他的消除if...else的方法 1.根据不同的数字返回不同的字符串 2.集合中的判断 3.简单的判断 4.spring中的判断 原文…...

新建一个flask项目
在Flask中创建一个新的项目,您可以遵循以下步骤: 确保您已经安装了Python环境。如果还未安装Flask,可以通过pip来安装: pip install flask创建一个新的文件夹作为您的项目文件夹,例如myflaskapp: mkdir …...

【Linux 内核源码分析】物理内存组织结构
多处理器系统两种体系结构: 非一致内存访问(Non-Uniform Memory Access,NUMA):这种体系结构下,内存被划分成多个内存节点,每个节点由不同的处理器访问。访问一个内存节点所需的时间取决于处理器…...

力扣日记2.21-【回溯算法篇】46. 全排列
力扣日记:【回溯算法篇】46. 全排列 日期:2023.2.21 参考:代码随想录、力扣 46. 全排列 题目描述 难度:中等 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1&…...

[AIGC] Kafka 消费者的实现原理
在 Kafka 中,消费者通过订阅主题来消费数据。每个消费者都属于一个消费者组,消费者组中的多个消费者可以共同消费一个主题,实现分布式消费。每个消费者都会维护自己的偏移量,用于记录已经读取到的消息位置。消费者可以选择手动提交…...
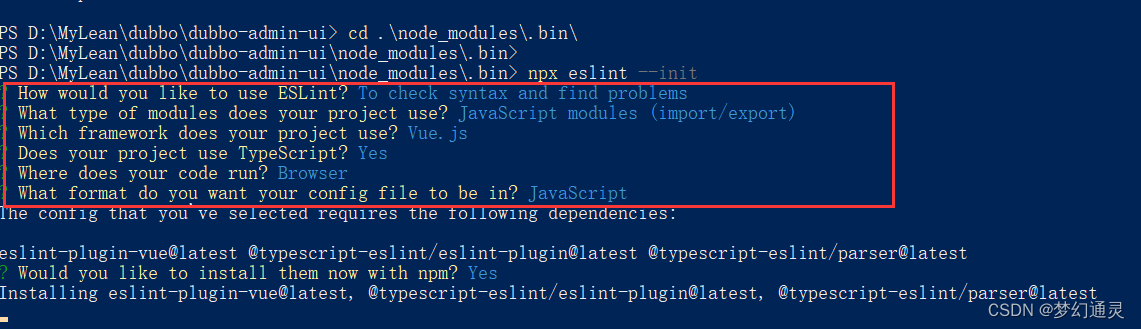
Dubbo框架admin搭建
Dubbo服务监控平台,dubbo-admin是图形化的服务管理界面,从服务注册中心获取所有的提供者和消费者的配置。 dubbo-admin是前后端分离的项目,前端使用Vue,后端使用springboot。因此,前端需要nodejs环境,后端需…...

Linux 内存top命令详解
通过top命令可以监控当前机器的内存实时使用情况,该命令的参数解释如下: 第一行 15:30:14 —— 当前系统时间 up 1167 days, 5:02 —— 系统已经运行的时长,格式为时:分 1 users ——当前有1个用户登录系统 load average: 0.00, 0.01, 0.05…...

OCP使用CLI创建和构建应用
文章目录 环境登录创建project赋予查看权限部署第一个image创建route检查pod扩展应用 部署一个Python应用连接数据库创建secret加载数据并显示国家公园地图 清理参考 环境 RHEL 9.3Red Hat OpenShift Local 2.32 登录 通过 crc console --credentials 可以查看登录信息&…...
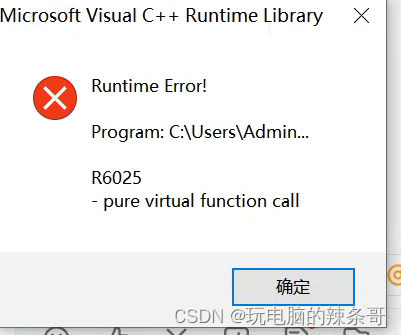
Chrome关闭时出现弹窗runtime error c++R6052,且无法关闭
环境: Chrome 版本121 Win10专业版 问题描述: Chrome关闭时出现弹窗runtime error cR6052,且无法关闭 解决方案: 1.任务管理器打开,强制结束进程 2.再次打开谷歌浏览器,打开设置关于Chrome࿰…...

多语言交易所源码/币币交易+期权交易+永续合约+Defi借贷+新币申购+矿机理财/前端uniapp纯源码+后端php
简介: 多语言交易所源码/币币交易期权交易永续合约Defi借贷新币申购矿机理财/前端uniapp纯源码后端php 语言:7种,看图 前端是uniapp纯源码,只有手机端,后端是php框架,清理了后门的,是最开始蓝…...

Continental CICP1800RB继电器扩展板
Continental CICP1800RB 是一款继电器扩展板,专为工业控制系统中的信号隔离与负载驱动而设计,可有效扩展主控单元的输出能力。产品特点(15条):CICP1800RB 提供 8 个继电器输出通道,满足多路负载控制需求每个…...

如何打破闭源代码智能模型的垄断?DeepSeek-Coder-V2的技术突围与实践指南
如何打破闭源代码智能模型的垄断?DeepSeek-Coder-V2的技术突围与实践指南 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSe…...

保姆级教程:在Ubuntu上拆解和重组RK356x的update.img固件包
深度解析:Ubuntu环境下RK356x固件逆向工程与定制化实践 引言 在嵌入式开发领域,瑞芯微RK356x系列芯片因其出色的性能和丰富的接口资源,已成为智能硬件开发的热门选择。然而,官方提供的固件包往往无法完全满足特定项目的需求&#…...

NVIDIA CUDA 在深度学习中的代码结构分析与性能优化
1. 深度学习场景下 CUDA 代码结构概述1.1 CUDA 在深度学习中的应用场景CUDA(Compute Unified Device Architecture)是 NVIDIA 推出的通用并行计算架构,通过利用 GPU 的大规模并行处理能力来加速深度学习工作负载。在深度学习领域,…...
)
Midjourney盐印相风格实战手册(附12组可复用Prompt模板+SDXL交叉验证数据)
更多请点击: https://kaifayun.com 第一章:Midjourney盐印相风格的视觉溯源与美学内核 盐印相(Salted Paper Print)是19世纪早期摄影术诞生之初的核心工艺,由亨利福克斯塔尔博特于1839年系统完善。其本质是将纸基浸入…...

ncmdumpGUI:3分钟解锁网易云音乐NCM加密文件,让音乐自由流动
ncmdumpGUI:3分钟解锁网易云音乐NCM加密文件,让音乐自由流动 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 当智能音箱对你说"不…...

利用Taotoken为Claude Code配置稳定后备API解决封号与Token不足问题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken为Claude Code配置稳定后备API解决封号与Token不足问题 对于依赖Claude Code进行日常开发的工程师而言,服…...

开放量子系统模拟:分治法混合态制备与Kraus算子优化
1. 开放量子系统模拟的挑战与机遇量子计算最令人期待的潜力之一,就是能够高效模拟传统计算机难以处理的量子系统动力学。然而在实际物理系统中,完全孤立的量子系统并不存在——环境噪声、退相干效应和测量干扰都会显著影响系统演化。这类与环境相互作用的…...
)
告别昂贵下载器!用20块的CH347芯片在Vivado里玩转FPGA调试(保姆级XVC配置)
20元打造专业级FPGA调试环境:CH347芯片Vivado全攻略 在电子设计领域,FPGA开发一直被视为硬件工程师的"高端玩具",但配套调试工具的高昂价格往往让个人开发者和学生望而却步。一块正版Xilinx下载器动辄数千元的价格,足以…...