网页数据的解析提取(XPath的使用----lxml库详解)
在提取网页信息时,最基础的方法是使用正则表达式,但过程比较烦琐且容易出错。对于网页节点来说,可以定义id、class或其他属性,而且节点之间还有层次关系,在网页中可以通过XPath或CSS选择器来定位一个或多个节点。那么,在解析页面时,利用XPath或CSS选择器提取某个节点,然后调用相应方法获取该节点的正文内容或者属性,就可以提取我们想要的任意信息了。
在Python中,如何实现上述操作呢?不用担心,相关解析库有非常多,其中比较强大的有lxml、Beautiful Soup,parsel、pyquery等。此帖介绍使用lxml库来定位网页源代码所需部分。(哇哦,Python也太强大了!又对Python深爱了一份!!!)
目录
XPath的使用
1. XPath概览
2. XPath常用规则
3.准备工作
4.实例引入
5、所有节点
6.子节点
7.父节点
8、属性匹配
9、文本获取
10.属性获取
11.属性多值匹配
12.多属性匹配
13.按序选择
XPath的使用
XPath 的全称是 XML Path Language, 即XML 路径语言, 用来在 XML 文档中查找信息。它虽然最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。
所以在做爬虫时,我们完全可以使用XPath实现相应的信息抽取。本节我们就介绍一下 XPath的基本用法。
1. XPath概览
XPath的选择功能十分强大,它提供了非常简洁明了的路径选择表达式。另外,它还提供了 100多个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。几乎所有我们想要定位的节点, 都可以用XPath选择。
XPath于1999年11月16日成为 W3C标准,它被设计出来, 供XSLT、XPointer以及其他XML解析软件使用。
2. XPath常用规则
下表列举了 XPath的几个常用规则。
| 表 达 式 | 描 | 述 | |
| nodename | 选取此节点的所有子节点 | ||
| / | 从当前节点选取直接子节点 | ||
| // | 从当前节点选取子孙节点 | ||
| . | 选取当前节点 | ||
| . . | 选取当前节点的父节点 | ||
| @ | 选取属性 | ||
这里列出了 XPath 的一个常用匹配规则,如下:
//title[@lang='eng']它代表选择所有名称为 title,同时属性 lang 的值为 eng的节点。后面会通过 Python 的 lxml库, 利用XPath对HTML 进行解析。
3.准备工作
使用lxml库之前,首先要确保其已安装好。可以使用 pip3 来安装:
pip3 install 1xml更详细的安装说明可以参考:https://setup.scrape.center/lxml
安装完成后,就可以进入接下来的学习了。
4.实例引入
下面通过实例感受一下使用XPath对网页进行解析的过程,相关代码如下:
from lxml import etree
text = '''
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul>
</div>
'''
html =etree.HTML(text)
result = etree.tostring(html)
print(result.decode('utf-8'))这里首先导入 lxml库的etree模块,然后声明了一段HTML 文本,接着调用HTML 类进行初始化,这样就成功构造了一个 XPath 解析对象。此处需要注意一点,HTML 文本中的最后一个 li 节点是没有闭合的, 而 etree模块可以自动修正 HTML 文本。之后调用tostring方法即可输出修正后的 HTML 代码,但是结果是 bytes类型。于是利用 decode 方法将其转换成 str类型,结果如下:
text = '''
<div><ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></ul>
</div>
'''可以看到,经过处理之后的 li 节点标签得以补全,并且自动添加了 body、html节点。另外,也可以不声明,直接读取文本文件。 首先要将HTML文本新建一个html程序,然后采用调用的方式
test.html文件代码:(该html文本一定需要创建到与一下Python程序同一目录下,后面都是基于此html代码进行分析)
text = '''
<div><ul><li class="item-0"><a href="link1. html">first item</a></li><li class="item-1"><a href="link2. html">second item</a></li><li class="item-inactive"><a href="link3. html">third item</a></li><li class="item-1"><a href="link4. html">fourth item</a></li><li class="item-0"><a href="link5. html">fifth item</a></ul>
</div>
'''Python代码:
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('utf-8'))此次输出结果略有不同,多了一个DOCTYPE声明,不过对解析无任何影响,结果如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd">
<html><body><p>text = '''
</p><div> <ul> <li class="item-0"><a href="link1. html">first item</a></li> <li class="item-1"><a href="link2. html">second item</a></li> <li class="item-inactive"><a href="link3. html">third item</a></li> <li class="item-1"><a href="link4. html">fourth item</a></li> <li class="item-0"><a href="link5. html">fifth item</a> </li></ul>
</div>
'''</body></html>5、所有节点
一般以//开头的XPath规则,来选取所有符合要点的节点。这里还是以第一个实例中的HTML文本为例,选取其中所有节点。
Python代码:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//*')
pprint.pprint(result)结果如下:
[<Element html at 0x2a9cf235280>,<Element body at 0x2a9cf4ea780>,<Element p at 0x2a9cf4ea7c0>,<Element div at 0x2a9cf4ea040>,<Element ul at 0x2a9cf4ea200>,<Element li at 0x2a9cf4ea680>,<Element a at 0x2a9cf4ea700>,<Element li at 0x2a9cf4ea740>,<Element a at 0x2a9cf4ea8c0>,<Element li at 0x2a9cf4ea540>,<Element a at 0x2a9cf4eaa40>,<Element li at 0x2a9cf4eaa00>,<Element a at 0x2a9cf4ea840>,<Element li at 0x2a9cf4eab80>,<Element a at 0x2a9cf4eabc0>]这里使用*代表匹配所有节点,也就是获取整个HTML 文本中的所有节点。从运行结果可以看到返回形式是一个列表,其中每个元素是Element类型,类型后面跟着节点的名称,如html、body、div ul、li、a等,所有节点都包含在了列表中。当然,此处匹配也可以指定节点名称。例如想获取所有 li 节点,实例如下:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li')
pprint.pprint(result)
pprint.pprint(result[0])这里选取所有li 节点,可以使用//,然后直接加上节点名称,调用时使用xpath方法即可。
运行结果如下:
[<Element li at 0x1c5211da700>,<Element li at 0x1c5211da740>,<Element li at 0x1c5211d9fc0>,<Element li at 0x1c5211da180>,<Element li at 0x1c5211da4c0>]
<Element li at 0x1c5211da700>可以看到,提取结果也是一个列表,其中每个元素都是 Element类型。要是想取出其中一个对象可以直接用中括号加索引获取,如[0]。
6.子节点
通过/ 或//即可查找元素的子节点或子孙节点。假如现在想选择 li 节点的所有直接子节点a,可以这样实现:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li/a')
pprint.pprint(result)
这里通过追加/a的方式,选择了li节点的所有直接子节点a。其中//li用于选中所有li节点,/a用于选中li节点的所有直接子节点a。
运行结果如下 :
[<Element a at 0x1c663e9a780>,<Element a at 0x1c663e9a7c0>,<Element a at 0x1c663e9a040>,<Element a at 0x1c663e9a200>,<Element a at 0x1c663e9a540>]上面的/用于选取节点的直接子节点,如果要获取节点的所有孙子节点,可以使用//。例如:要获取ul节点下的所有子孙节点a,可以这样实现:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//ul//a')
pprint.pprint(result)
运行结果与上面相同。如果这里用//ul/a,就无法获取结果了。因为/用于获取直接子节点,二ul节点下没有直接的a子节点,只有li子节点。因此要注意/和//的区别,前者用于获取直接子节点,后者用于获取子孙节点。
7.父节点
通过连续的 /或 //可以查找子节点或子孙节点,那么假如知道了子节点,怎样查找父节点呢?这可以用..实现。例如, 首先选中 href属性为 link4. html的a节点, 然后获取其父节点,再获取父节点的 class 属性,相关代码如下:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//a[@href="link4.html"]/../@class')
pprint.pprint(result)
运行结果如下:
['item-1']检查一下结果发现,这正是我们获取的目标li节点的 class 属性。
也可以通过 parent::获取父节点,代码如下:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//a[@href="link4.html"]/parent::*/@class')
pprint.pprint(result)
8、属性匹配
在选取节点的时候,还可以使用@符号实现属性过滤。例如,要选取class属性为item-0的li节点,可以这样实现:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]')
pprint.pprint(result)
结果如下:
[<Element li at 0x1cf3f68a7c0>, <Element li at 0x1cf3f68a040>]9、文本获取
用XPath中的text方法可以获取节点中的文本,接下来尝试获取前面li节点中的文本,代码如下:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]/text()')
pprint.pprint(result)
结果如下:
['\r\n ']奇怪的是,我们没有获取任何文本,只获取了一个换行符,这是为什么呢? 因为xpath中text方法的前面是/,而/的含义是选取直接子节点,很明显li的直接子节点都是 a 节点,文本都是在 a节点内部的,所以这里匹配到的结果就是被修正的 li 节点内部的换行符,因为自动修正的 li 节点的尾标签换行了。
即选中的是这两个节点:
<li class="item-0"><a href="link1.html">first item</a></li><li class="item-0"><a href="link5.html">fifth item</a>其中一个节点因为自动修正,li 节点的尾标签在添加的时候换行了,所以提取文本得到的唯一结果就是 li节点的尾标签和a节点的尾标签之间的换行符。因此,如果想获取 li 节点内部的文本,就有两种方式,一种是先选取 a 节点再获取文本,另一种是使用//。接下来,我们看下两种方式的区别。
先选取a节点,再获取文本的代码如下:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]/a/text()')
pprint.pprint(result)
结果如下:
['first item', 'fifth item']可以看到,这里有两个返回值,内容都是 class 属性为 item-0 的 1i 节点的文本,这也印证了前面属性匹配的结果是正确的。这种方式下,我们是逐层选取的,先选取li节点,然后利用/选取其直接子节点a,再选取节点a的文本,得到的两个结果恰好是符合我们预期的。这种方式下,我们是逐层选取的,先选li节点,然后利用/选取其直接子节点a,再选取节点a 的文本,得到的两个结果恰好是符合我们预期的。再来看一下使用//能够获取什么样的结果,代码如下:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li[@class="item-0"]//text()')
pprint.pprint(result)
运行结果如下:
['first item', 'fifth item', '\r\n ']不出所料,这里的返回结果是三个。可想而知,这里选取的是所有子孙节点的文本,其中前两个是 li 的子节点 a 内部的文本,另外一个是最后一个 li 节点内部的文本,即换行符。由此,要想获取子孙节点内部的所有文本,可以直接使用//加text 方法的方式,这样能够保证获取最全面的文本信息,但是可能会夹杂一些换行符等特殊字符。如果想获取某些特定子孙节点下的所有文本,则可以先选取特定的子孙节点,再调用 text方法获取其内部的文本,这样可以保证获取的结果是整洁的。
10.属性获取
我们已经可以用text方法获取节点内部文本,那么节点属性该怎样获取呢? 其实依然可以用@符号。例如,通过如下代码获取所有 li 节点下所有 a 节点的 href属性:
import pprint
from lxml import etree
html = etree.parse('./test.html', etree.HTMLParser())
result = html.xpath('//li/a/@href')
pprint.pprint(result)
这里通过@href获取节点的 href属性。注意,此处和属性匹配的方法不同,属性匹配是用中括号加属性名和值来限定某个属性, 如[@href="link1.html"], 此处的@href是指获取节点的某个属性,二者需要做好区分。结果如下:
['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']可以看到,我们成功获取了所有 li 节点下 a 节点的 href 属性,并以列表形式返回了它们。
11.属性多值匹配
有时候,某些节点的某个属性可能有多个值,例如:
from lxml import etree
text= '''
<li class="li li-first"><a href="link. html">first item</a></li>
'''
html= etree. HTML(text)
result = html.xpath('//li[@class="li"]/a/text()')
print(result)这里 HTML 文本中 li 节点的 class 属性就有两个值: li 和li-first。此时如果还用之前的属性匹配获取节点, 就无法进行了, 运行结果如下:
[]这种情况需要用到 contains 方法, 于是代码可以改写如下:
from lxml import etree
text= '''
<li class="li li-first"><a href="link. html">first item</a></li>
'''
html= etree. HTML(text)
result = html.xpath('//li[contains(@class,"li")]/a/text()')
print(result)上面使用了contains方法,给其第一个参数传入属性名称,第二个参数传入属性值,只要传入的属性包含传入的属性值,就可以完成匹配。
运行结果为:
['first item']contains方法经常在某个节点的某个属性有多个值用到。
12.多属性匹配
我们还可能遇到一种情况, 就是根据多个属性确定一个节点, 这时需要同时匹配多个属性。运算符and用于连接多个属性, 实例如下:
from lxml import etreetext = '''
<li class="li li-first" name="item"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,"li") and @name="item"]/a/text()')
print(result)
这里的 li 节点又增加了一个属性name。因此要确定 li 节点, 需要同时考察 class 和 name 属性,一个条件是class 属性里面包含li字符串, 另一个条件是 name 属性为item字符串, 这二者同时得到满足, 才是 li 节点。class 和 name 属性需要用 and 运算符相连, 相连之后置于中括号内进行条件筛选。运行结果如下:
['first item']这里的 and其实是 XPath中的运算符。除了它,还有很多其他运算符,如or、mod等,在此总结为下表。
| 运 算 符 | 描述 | 实例 | 返 回 值 | ||
| or | 或 | age=19 or age=20 | 如果 age 是 19, 则返回true。 | ||
| and | 与 | age>19 and age<21 | 如果 age 是 20, 则返回true。如果age 是18, 则返回false | ||
| mod | 计算除法的余数 | 5 mod 2 | 1 | ||
| | | 计算两个节点集 | //book|//cd | 返回所有拥有 book 和cd元素的节点集 | ||
| + | 加法 | 6 + 4 | 10 | ||
| - | 减法 | 6 - 4 | 2 | ||
| * | 乘法 | 6 * 4 | 24 | ||
| div | 除法 | 8 div 4 | 2 | ||
| = | 等于 | age=19 | 如果 age 是 19, 则返回true。 | ||
| != | 不等于 | age!=19 | 如果 age 是 18, 则返回true。如果age 是 19, 则返回false | ||
| < | 小于 | age<19 | 如果 age 是 18, 则返回 true。如果age 是 19, 则返回 false | ||
| <= | 小于或等于 | <=19 | 如果 age 是 19, 则返回 true。如果age 是 20, 则返回false | ||
| > | 大于 | age>19 | 如果 age 是 20, 则返回true。如果age 是 19, 则返回 false | ||
| >= | 大于或等于 | age>=19 | 如果age 是 19, 则返回true。如果age 是18, 则返回false | ||
13.按序选择
在选择节点时, 某些属性可能同时匹配了多个节点, 但我们只想要其中的某一个,如第二个或者最后一个, 这时该怎么办呢?可以使用往中括号中传入索引的方法获取特定次序的节点, 实例如下:
from lxml import etree
text= '''
<div>
<ul><li class="item-0"><a href="link1.html">first item</a></li><li class="item-1">< a href="link2.html">second item</a></li><li class="item-inactive"><a href="link3.html">third item</a></li><li class="item-1">< a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html= etree. HTML(text)
result = html.xpath('//li[1]/a/text()')
print(result)
result = html.xpath('//li[last()]/a/text()')
print(result)
result = html.xpath('//li[position()<3]/a/text()')
print(result)
result = html.xpath('//li[last()-2]/a/text()')
print(result) 上述代码中, 第一次选择时选取了第一个 li 节点, 往中括号中传入数字1 即可实现。注意,这里和写代码不同, 序号以1开头, 而非0。第二次选择时, 选取了最后一个 li 节点, 在中括号中调用last 方法即可实现。第三次选择时, 选取了位置小于3 的 li 节点, 也就是位置序号为1 和2 的节点, 得到的结果就是前两个 li节点。第四次选择时, 选取了倒数第三个 li 节点, 在中括号中调用last 方法再减去2即可实现。因为last 方法代表最后一个, 在此基础上减2 得到的就是倒数第三个。
运行结果如下:
['first item']
['fifth item']
['first item', 'second item']
['third item']在这个实例中, 我们使用了 last、position等方法。XPath 提供了 100多个方法, 包括存取、数值、字符串、逻辑、节点、序列等处理功能。
XPath还有一个节点轴的选择方法,但由于很少使用,故在此不在介绍!!!
注:今天,又是深爱Python的一天!!!
相关文章:
)
网页数据的解析提取(XPath的使用----lxml库详解)
在提取网页信息时,最基础的方法是使用正则表达式,但过程比较烦琐且容易出错。对于网页节点来说,可以定义id、class或其他属性,而且节点之间还有层次关系,在网页中可以通过XPath或CSS选择器来定位一个或多个节点。那么&…...

dell r740服务器黄灯闪烁维修现场解决
1:首先看一下这款DELL非常主力的PowerEdge R740服务器长啥样,不得不说就外观来说自从IBM抛弃System X系列服务器后,也就戴尔这个外观看的比较顺眼。 图一:是DELL R740前视图(这款是8盘机型) 图二ÿ…...

202426读书笔记|《尼采诗精选》——高蹈于生活之上,提升自己向下观望
202426读书笔记|《尼采诗精选》——高蹈于生活之上,提升自己向下观望 第一辑 早期尼采诗歌选辑(1858—1869年)第二辑 前期尼采遗著中的诗歌选辑(1871—1882年)第五辑 戏谑、狡计与复仇——德语韵律短诗序曲(…...
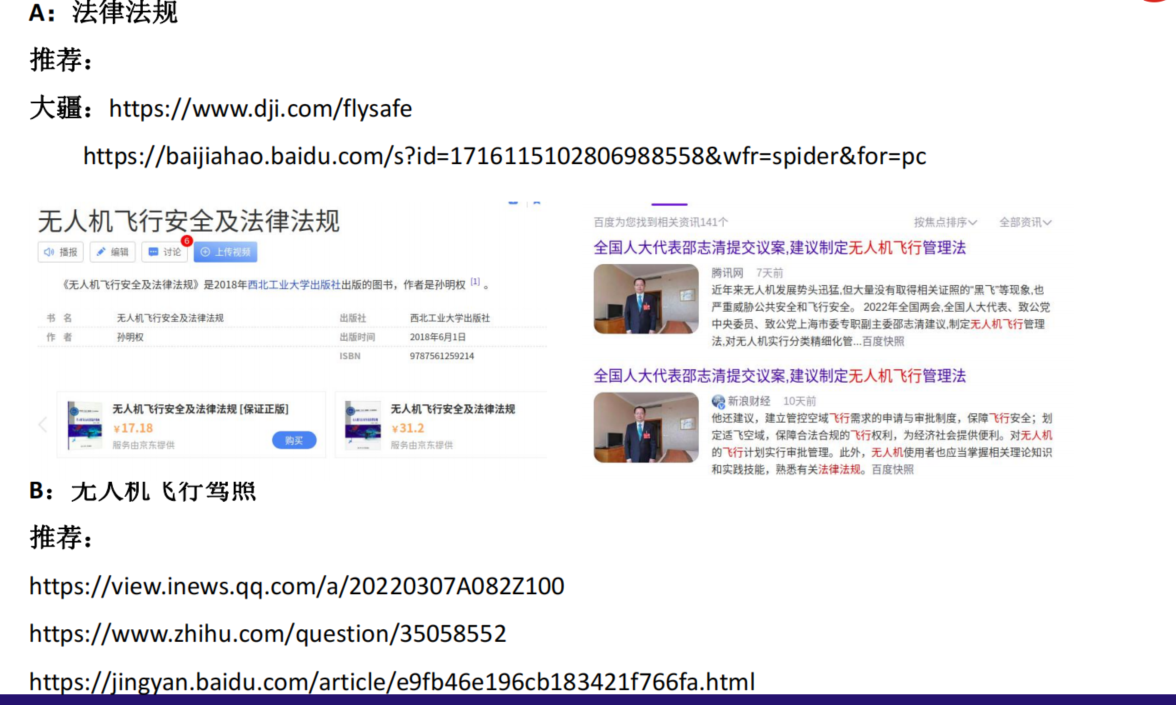
【PX4学习笔记】13.飞行安全与炸机处理
目录 文章目录 目录使用QGC地面站的安全设置、安全绳安全参数在具体参数中的体现安全绳 无人机炸机处理A:无人机异常时控操作B:无人机炸机现场处理C:无人机炸机后期维护和数据处理D:无人机再次正常飞行测试 无人机飞行法律宣传 使…...
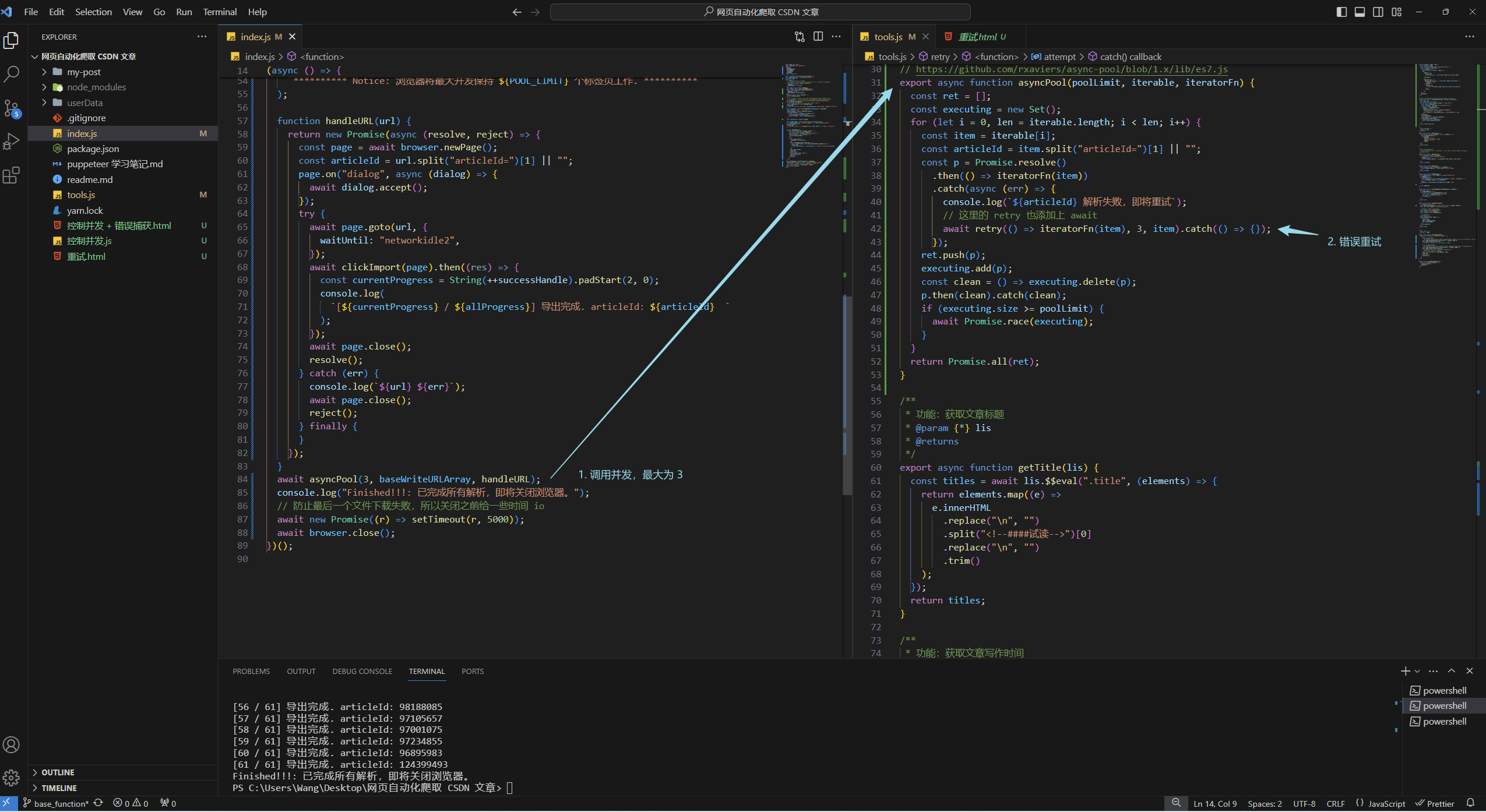
Puppeteer 使用实战:如何将自己的 CSDN 专栏文章导出并用于 Hexo 博客(二)
文章目录 上一篇效果演示Puppeteer 修改浏览器的默认下载位置控制并发数错误重试并发控制 错误重试源码 上一篇 Puppeteer 使用实战:如何将自己的 CSDN 专栏文章导出并用于 Hexo 博客(一) 效果演示 上一篇实现了一些基本功能,…...

[ 2024春节 Flink打卡 ] -- 优化(draft)
2024,游子未归乡。工作需要,flink coding。觉知此事要躬行,未休,特记 资源配置调优内存设置 TaskManager内存模型 https://nightlies.apache.org/flink/flink-docs-release-1.18/docs/deployment/config/ TaskManager 内存模型…...

电脑进水无法开机怎么办 电脑进水开不了机的解决方法
意外总是会不定时打破你的计划,电脑这类电器最怕遇到的除了火还有水,设备进水会导致数据丢失,那么我们遇到电脑进水怎么办?进水之后不正确处理也会引起很多不必要的麻烦. 解决办法 第一步:关机 如果您的电脑是在开…...

【Flutter】底部导航BottomNavigationBar的使用
常用基本属性 属性名含义是否必须items底部导航栏的子项List是currentIndex当前显示索引否onTap底部导航栏的点击事件, Function(int)否type底部导航栏类型,定义 [BottomNavigationBar] 的布局和行为否selectedItemColor选中项图标和label的颜色否unsel…...
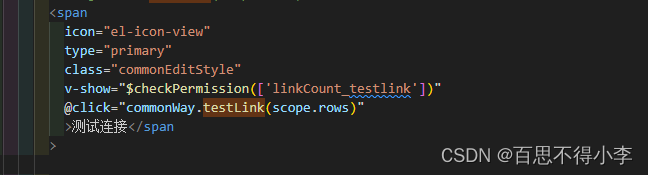
Vue封装全局公共方法
有的时候,我们需要在多个组件里调用一个公共方法,这样我们就能将这个方法封装成全局的公共方法。 我们先在src下的assets里新建一个js文件夹,然后建一个common.js的文件,如下图所示: 然后在common.js里写我们的公共方法,比如这里我们写了一个testLink的方法,然后在main…...

雪花算法生成分布式主键ID
直接上代码,复制即可使用 public class SnowflakeIdGenerator {private static final long START_TIMESTAMP 1624000000000L; // 设置起始时间戳,2021-06-18 00:00:00private static final long DATA_CENTER_ID_BITS 5L;private static final long WO…...

第三百五十九回
文章目录 1. 概念介绍2. 使用方法3. 代码与效果3.1 示例代码3.2 运行效果 4. 内容总结 013pickers2.gif 我们在上一章回中介绍了"如何实现Numberpicker"相关的内容,本章回中将介绍wheelChoose组件.闲话休提,让我们一起Talk Flutter吧。 1. 概念…...
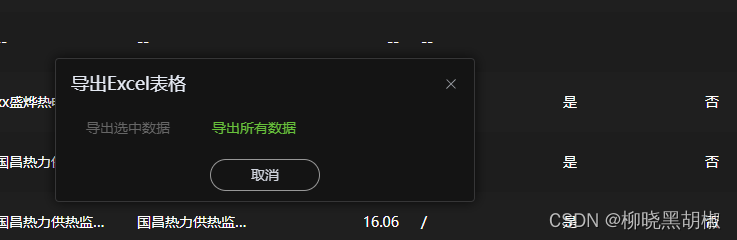
vue3 用xlsx 解决 excel 低版本office无法打开问题
需求背景解决思路解决效果将json导出为excel将table导为excel导出样式 需求背景 原使用 vue3-json-excel ,导致在笔记本office环境下,出现兼容性问题 <vue3-json-excel class"export-btn" :fetch"excelGetList" :fields"js…...
Java后端底座从无到有的搭建(随笔)
文章目录 开发模式的演变草创时期1.0时期(基座时期)1.1时期(低代码时期)2.0时期(无代码时期) 前言:本文是笔者在初创公司,一年多来Java后端服务底座搭建过程的总结,如有不…...

Rust介绍与开发环境搭建
Rust 是一种系统编程语言,它专注于内存安全、并发和性能。它是由 Mozilla 开发的,并得到了许多社区的广泛支持。Rust 的设计理念是“安全 by default”,这意味着你不需要特殊的工具或技巧来编写安全的代码。 Rust 的主要特点: 内…...
)
本地TCP通讯(C++)
概要 利用TCP技术,实现本地ROS1和ROS2的通讯。 服务端代码 头文件 #include <ros/ros.h> #include "std_msgs/String.h" #include "std_msgs/Bool.h" #include <iostream> #include <cstring> #include <unistd.h>…...

docker 安装jenkins
使用 Docker 安装 Jenkins 是一种快速、方便的方法,可以避免本地环境的复杂依赖。以下是通过 Docker 安装 Jenkins 的基本步骤: 安装 Docker: 如果你的系统尚未安装 Docker,请先安装 Docker。对于 Ubuntu 系统,可以通过…...

电脑黑屏什么都不显示怎么办 电脑开机黑屏不显示任何东西的4种解决办法
相信有很多网友都有经历电脑开机黑屏不显示任何东西,找了很多方法都没处理好,其实关于这个的问题,首先还是要了解清楚开机黑屏的原因,才能够对症下药,下面大家可以跟小编一起来看看怎么解决吧 电脑开机黑屏不显示任何…...

MT8781核心板_MTK8781安卓核心板规格参数
MT8781安卓核心板以其强大的性能和高效的能耐备受瞩目。其八核CPU架构包括(2x Cortex-A76 2.2GHz 6x Cortex-A55 2.0GHz),以及高性能的Arm Mali G57级GPU。同时,配备高达2,133MHz的LPDDR4X内存和快速的UFS 2.2级存储,大大加速了数据访问速…...

HTML知识点
HTML 【一】HTML简介 【1】什么是HTML HTML是一种用于创建网页结构和内容的超文本标记语言,它是构建网页的基础。为了让浏览器正确渲染页面,我们必须遵循HTML的语法规则。浏览器在解析网页时会将HTML代码转换为可视化的页面,所以我们在浏览…...
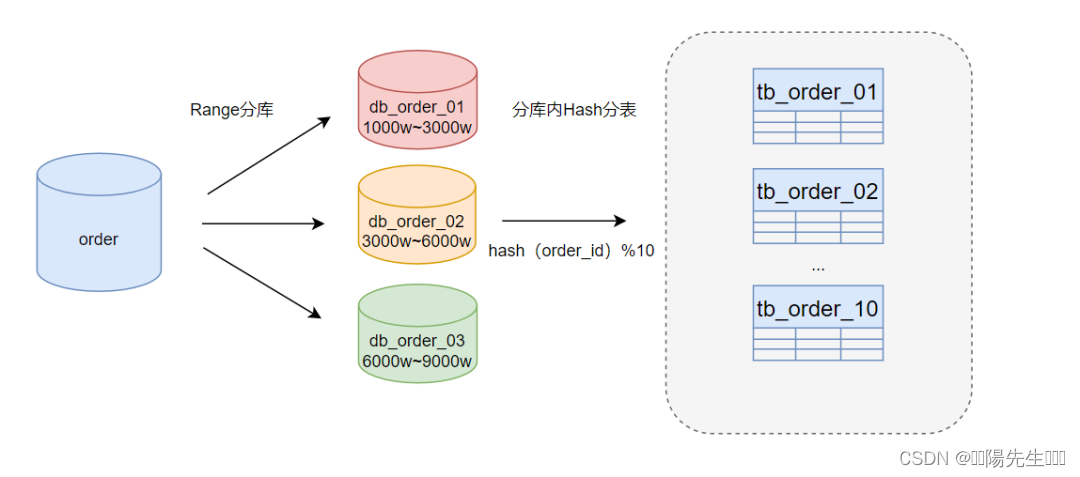
聊聊分库分表
文章导读 背景介绍 随着互联网技术的发展,数据量呈爆炸性增长。大数据量的业务场景中,数据库成为系统性能瓶颈的一个主要因素。当单个数据库包含了太多数据或过高的访问量时,会出现查询缓慢、响应时间长等问题,严重影响用户体验。…...

BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐
BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...

N_m3u8DL-RE终极指南:如何高效下载加密流媒体视频
N_m3u8DL-RE终极指南:如何高效下载加密流媒体视频 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE 还…...

抖音批量下载器终极指南:免费高效的视频采集解决方案
抖音批量下载器终极指南:免费高效的视频采集解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

如何用btcrecover快速找回丢失的比特币钱包密码与助记词:完整指南
如何用btcrecover快速找回丢失的比特币钱包密码与助记词:完整指南 【免费下载链接】btcrecover An open source Bitcoin wallet password and seed recovery tool designed for the case where you already know most of your password/seed, but need assistance i…...

从模型文件到孪生场景:一个Three.js三维模型管理系统的完整产品化思考
从技术原型到商业产品:构建Three.js数字孪生系统的全栈实践 在数字孪生技术快速渗透工业制造、智慧城市等领域的今天,如何将一个基于Three.js的模型展示Demo转化为真正具备商业价值的企业级管理系统?这个问题困扰着许多掌握前端3D技术的开发者…...

避坑指南:在Codesys V3.5中用ST处理XML,我踩过的那些‘坑’
Codesys实战:ST语言处理XML文件的7个关键陷阱与解决方案 在工业自动化领域,XML作为数据交换的标准格式,其重要性不言而喻。然而,当我们在Codesys V3.5环境下使用ST语言处理XML文件时,往往会遇到一系列令人头疼的问题。…...
)
告别丢包!手把手教你用Vivado/PLL调优RTL8211的RXC时钟相位(FPGA千兆以太网篇)
FPGA千兆以太网时序优化实战:用PLL驯服RTL8211的RXC时钟相位 当你在调试FPGA与RTL8211千兆以太网PHY芯片的RGMII接口时,是否遇到过这样的场景:硬件连接一切正常,链路也能正常建立,但就是会随机出现数据包丢失或CRC校验…...

AMD GPU本地AI模型部署终极指南:ollama-for-amd让你的Radeon显卡焕发新生
AMD GPU本地AI模型部署终极指南:ollama-for-amd让你的Radeon显卡焕发新生 【免费下载链接】ollama-for-amd Get up and running with Llama 3, Mistral, Gemma, and other large language models.by adding more amd gpu support. 项目地址: https://gitcode.com/…...
函数)
保姆级教程:STM32CubeMX配置ADC扫描模式,并封装一个灵活的Get_Adc()函数
STM32CubeMX实战:构建可动态配置的ADC多通道扫描系统 在嵌入式开发中,ADC(模数转换器)的灵活配置一直是硬件工程师面临的常见挑战。许多开发者在使用STM32CubeMX配置多通道ADC时,往往止步于基础扫描模式的应用…...

14.3 异步协程开发铁律示例 与 标准示例代码核心:事件循环内严禁编写同步逻辑,协程业务务必全程异步
Python异步协程从原理到实战完整总结 一、协程底层核心 asyncio 基于单线程事件循环驱动运行,通过 await 主动让出执行权完成任务切换,切换开销远低于多线程,天生适配IO密集型业务场景; 单线程特性决定它无法直接利用多核处理CPU密…...