聊聊分库分表
文章导读
背景介绍
随着互联网技术的发展,数据量呈爆炸性增长。大数据量的业务场景中,数据库成为系统性能瓶颈的一个主要因素。当单个数据库包含了太多数据或过高的访问量时,会出现查询缓慢、响应时间长等问题,严重影响用户体验。为了解决这一问题,分库分表技术应运而生。通过将数据分散到多个数据库或表中,从而有效提升系统的处理能力和稳定性。
场景分析
例如:在交易系统核心数据库设计大致包括:
产品数据库(Product/Asset Database):存储系统可交易的产品或资产的详细信息,比如在股票交易系统中,这里会包含股票代码、股票名称、当前价格等信息。
订单数据库(Order Database):存储用户提交的订单信息,包括订单ID、订单状态(如待处理、完成、取消)、订单创建时间等。
用户数据库(User Database):存储用户的基本信息,如用户ID、用户名、密码(通常进行加密存储)、联系信息等,以及用户的权限和角色定义。
交易数据库(Transaction Database):记录所有交易的详细信息,如交易ID、交易类型(买入、卖出等)、交易金额、交易时间、交易双方等。这个数据库是交易系统的核心,需要高效且可靠。
配置数据库(Configuration Database):存储系统配置信息,如交易规则、费用设置、系统参数等。
历史数据库(Historical Data Database):保存交易、订单和价格的历史记录。这对于数据分析、报告生成及监控非常重要。
账户数据库(Account Database):存储用户的账户信息,包括账户余额、账户类型、账户状态等。在交易系统中,账户信息是核心数据之一。
安全和审计数据库(Security and Audit Database):用于记录安全相关的事件,如登录尝试、权限变更等,以及审计记录,确保系统的安全性和可追踪性。
......
从上边的分析看,对应数据库表大致归纳为以下几种类型:
-
配置表:产品规格、数据字典、系统参数、费用项等
-
流水表:订单数据、交易流水等
-
日志表:应用日志、用户操作日志、异常日志、访问日志等
-
用户表:用户注册、用户登录等
......
思考
一般哪些表可能存在数据激增、性能问题?日志表、流水表、用户表等都可能。而系统配置则可能相对较少。
分库分表
什么是分库分表?
分库分表是一种数据库架构优化技术,说白了就是一种分治思想。通过分库分表将数据分散到多个数据库或表中,来提高系统的性能和稳定性。分库分表可以分为以下几种策略:水平分库、水平分表、垂直分库、垂直分表。
以订单库 db_order 和 订单表 tb_order 为例(db为库,tb为表):
水平分库:根据某些规则(例如订单ID的范围)将db_order数据库分成多个数据库(分片),如db_order_1, db_order_2, db_order_3等。每个数据库的表结构相同,但存储的订单数据不同。
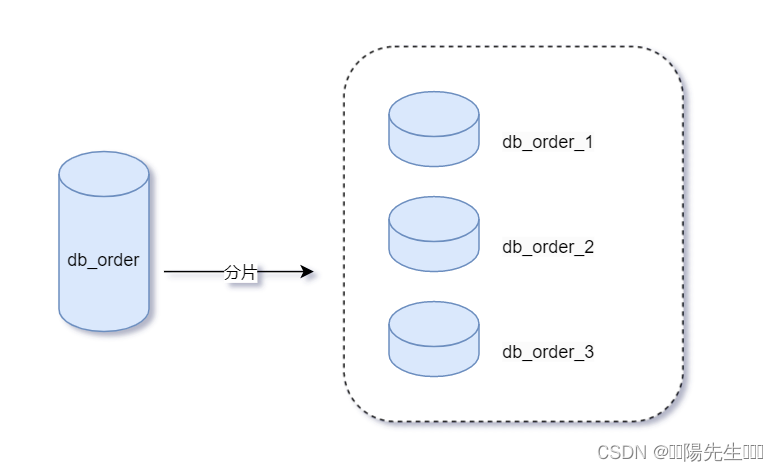
水平分表:根据订单的创建时间,将tb_order分成tb_order_2022, tb_order_2023, tb_order_2024等多个表,每个表存储各自时间段的订单数据。表结构保持一致,但每个表只存储一部分数据。

垂直分库:根据业务功能将数据垂直分割到不同的数据库中。例如,将订单相关的表保留在db_order中,将用户相关的表迁移到新的数据库db_user中,商品相关的表迁移到db_product中。
垂直分表:若tb_order表中的字段非常多,包含了订单的基本信息、订单属性信息、订单资费信息等多个方面。此时,可以将tb_order表垂直拆分为多个表,如tb_order_base存储订单的基本信息,tb_order_chars存储订单属性信息、tb_order_charges存储订单资费信息。
小结
有了以上这些了解,基本对分库分表概念有了大致了解。对于分库一般按照业务功能领域划分,这里我们主要重点介绍分表。
分库分表常见问题
什么情况下需要分表?
参考规则
根据《阿里巴巴Java开发手册》,给出如下建议:

工程经验
事实上,通常在实战中,一般按经验数据达到千万级,就需要分库分表。原因如下:
我们知道:InnoDB管理磁盘的最小单元:页,页大小16KB.
mysql> show global status like '%Innodb_page_size%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.00 sec)
在日常开发中,对于数据库性能优化,我们首先想到的是索引优化。索引的底层数据结构是B+树。其组织结构如图所示:
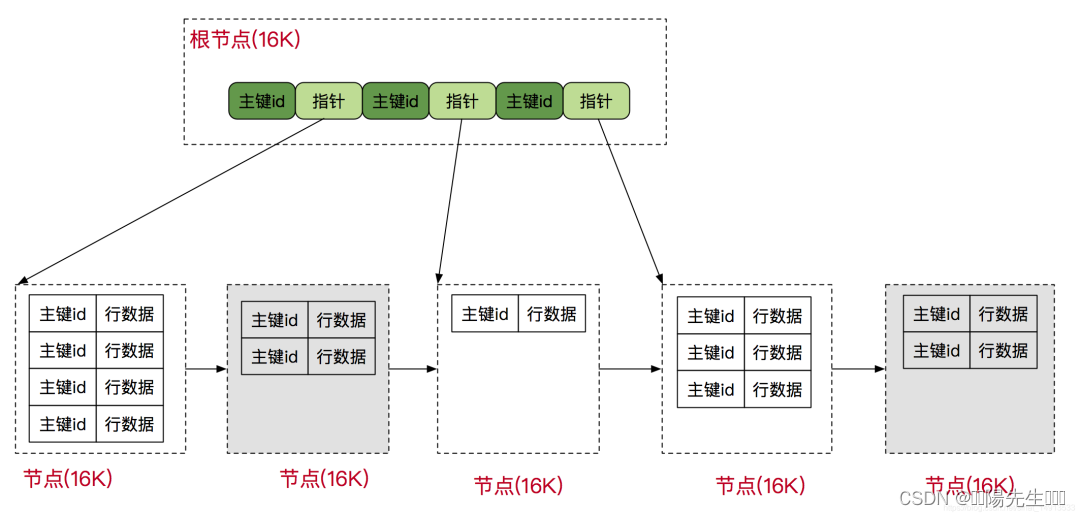
树高为3的B+树数据存储计算规则:
根节点计算:
假设数据类型是bigint,大小为8b。数据本身也需要一小块空间,用来存储下一层索引数据页的地址,大小为6b, 那么根节点是可以存储16*1024/(8+6) = 1170 个数据。
其它层节点计算:
第二层:因为每个节点数据结构和跟节点一样,而且在跟节点每个元素都会延伸出来一个节点,所以第二层的数据量是1170*1170=1368900
第三层:因为innodb的叶子节点,是直接包含整条mysql数据的,假设每条数据以1kb计算,那么第三层每个节点为16kb,那么每个节点是可以放16个数据的,所以最终mysql可以存储的总数据为
1170 * 1170 * 16 = 21902400 (千万级)
其实计算结果与我们平时的工作经验也是相符的,一般mysql一张表的数据超过了千万也是得进行分表操作了。
参考文章:
MySQL一张表到底能存多少数据?[1]
如何选择分片键?
例如,本节我们以订单表的分表为例,一般订单表中含有订单编号:order_id, 用户编号:user_id, 订单创建时间:order_date等。
对于订单表,通常我们可以考虑以下分片键选项:
订单编号
优点:订单编号通常是唯一的,可以确保每个订单都分散到不同的分片上。这对于保证数据均匀分布和避免热点数据非常有帮助。
用户编号
优点:用户编号通常也是唯一的,并且如果用户的订单量分布均匀,那么使用用户编号作为分片键可以确保每个用户的订单都在同一个分片上,这对于查询某个用户的所有订单非常高效。
缺点:如果用户的订单量差异很大,那么某些分片可能会存储大量的订单数据,而其他分片可能只有少量的数据。这会导致数据分布不均匀,进而影响查询性能。
订单创建时间
优点:适用于:按时间范围查询订单的场景。
缺点:可能出现热点数据倾斜问题(即在某个时段产生订单峰值)
如何选择数据库主键策略?
在选择主键策略时,需要注意以下几点:
-
唯一性:确保主键在
全局唯一,避免数据冲突。 -
性能:选择适合的主键类型和生成策略,以提高数据插入、查询和索引的性能。
-
扩展性:能够适应数据量和并发量增长。
-
兼容性:选择的主键策略要与使用的数据库兼容。
在 MySQL 中进行分库分表时,自增主键策略确实需要特别处理,因为传统的自增主键策略在分布式环境下会导致主键冲突。每个数据库实例或分片都会从相同的起始点开始自增,这会导致在不同的分片上生成相同的 ID,进而引发数据冲突。
几种常见的主键策略方案:
-
UUID:
UUID 是一个 128 位的值,具有全局唯一性,可以很好地解决分布式环境下的主键冲突问题。但是,UUID 字符串较长,存储和索引效率较低,而且是无序的,可能会影响查询性能。
-
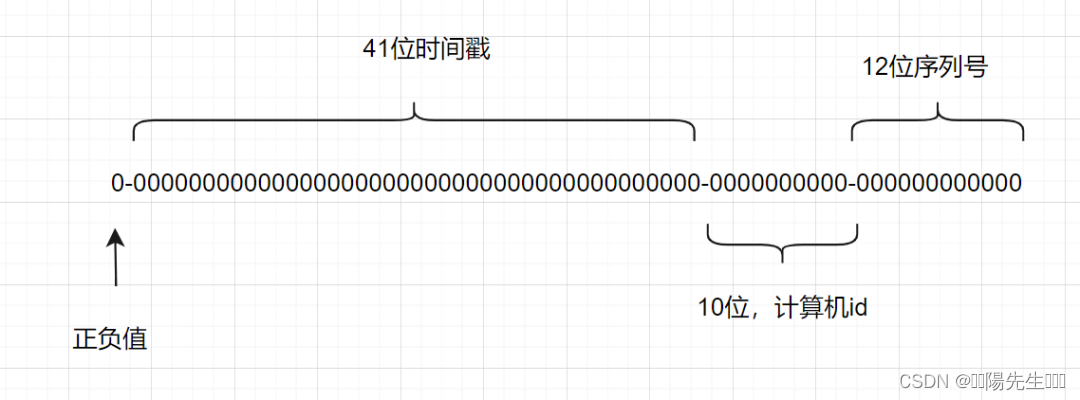
Snowflake 算法:雪花算法(SnowFlake)是一种分布式ID生成算法,由Twitter开源。其核心思想是使用64位long型数字作为全局唯一的ID,通过时间戳、工作机器ID和序列号等部分来确保ID的全局唯一性。
-
结构说明:
-
1位:未使用(因为二进制中最高位是符号位,正数是0,负数是1,一般生成的ID都是正数,所以这一位固定为0)。
-
41位:时间戳(毫秒级),用来记录时间截的差值(当前时间截 - 开始时间截)。
-
10位:工作机器ID,包括5位datacenterId(数据中心ID)和5位workerId(工作机器ID),用来表示工作机器的ID。
-
12位:序列号,用来记录同一毫秒内产生的不同ID,12位可以表示的最大整数为4095,用来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
-
通过这种结构,雪花算法可以保证生成的ID按时间递增,并且整个分布式系统中不会有重复的ID。
-
分布式自增 ID 生成器:使用像 Twitter 的 Snowflake、阿里巴巴的 Druid 等分布式 ID 生成器来生成全局唯一的自增 ID。这些生成器通过特定的算法和机制保证在不同实例间生成的 ID 是全局唯一的。
-
自增主键 + 分片策略:仍然使用自增主键,但是结合分片策略,确保每个分片上的主键值是唯一的。例如,可以预先为每个分片分配一个 ID 范围,确保在这个范围内的 ID 是唯一的。这种方法需要维护分片的 ID 范围,并在必要时进行调整。
-
使用数据库的自增 ID 特性:某些数据库支持在分表时自动处理自增 ID,避免冲突。例如,MySQL 8.0 引入了
AUTO_INCREMENT_INCREMENT和AUTO_INCREMENT_OFFSET这两个系统变量,用于在复制或分片环境中调整自增 ID 的步长和起始值,从而避免冲突。
总之,在分库分表时,自增主键策略需要进行特殊处理,以确保全局唯一性,并根据实际情况选择合适的方案。
如何选择分表策略?
选择分库分表的策略时,确实需要根据具体的业务场景和数据特性来决定。例如订单表,以订单ID (order_id) 作为分表键。
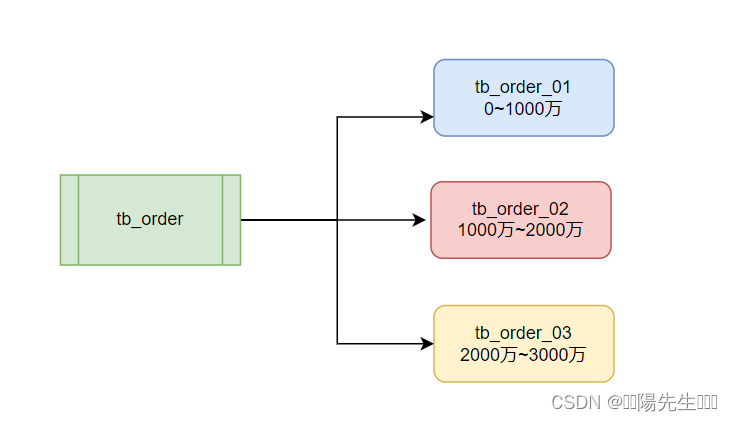
基于范围的策略
适用场景:当订单ID有明确的增长趋势,例如连续的自增ID,并且你知道未来可能的订单数量时,范围分表是一个好选择。
策略实现:可以将订单ID按照范围划分到不同的表中。例如,订单ID【1-1000万】 在表tb_order_01,【1000万-2000万】在表tb_order_02,以此类推。
优点:
-
查询效率较高,尤其是范围查询。
-
数据迁移和维护相对简单。
缺点:
-
订单ID的分布必须均匀.
-
如果订单ID不是连续或可预测的,这种策略可能不适用。
基于哈希的策略
适用场景:当订单ID没有明确的增长趋势,哈希分表是一个好选择。
策略实现:使用哈希函数对订单ID进行哈希运算,然后根据哈希值的结果决定存储在哪个表中。
table_index = hash(order_id) % tables_num
优点:
-
负载均衡,每个表的数据分布相对均匀。
缺点:
-
不利于二次扩容。
映射表策略
适用场景:当订单ID的分布不均,或者需要灵活控制数据分布时,映射表分表可能是一个好选择。
策略实现:使用一个映射表来记录每个订单ID应该存储在哪个表中。这个映射表可以是内存中的数据结构,也可以是数据库中的一个表。
优点:
-
灵活,可以根据需要调整数据分布。
缺点:
-
查询时需要先查询映射表,可能影响性能。
一致性哈希策略
适用场景:当系统需要高可用性,并且希望在添加或删除节点时尽量减少数据迁移时,一致性哈希可能是一个好选择。
策略实现:使用一致性哈希算法将订单ID映射到哈希环上,然后根据哈希环上的节点(或表)来存储数据。
一致性哈希算法的核心思想是将哈希值空间表示为一个闭合的圆环(哈希环),每个节点负责维护圆环上一段连续的哈希值范围。
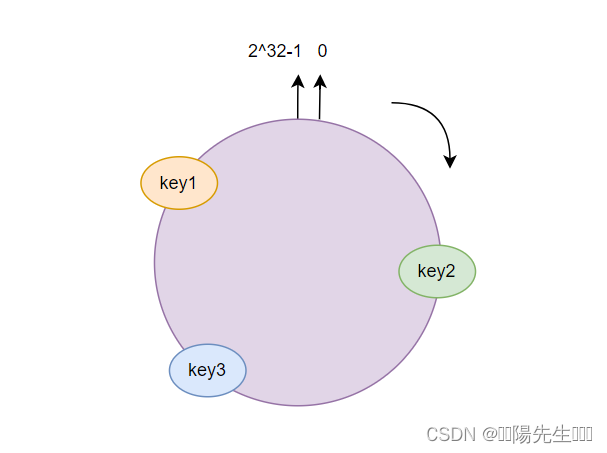
在分库分表的场景中,可以将每个数据库或表看作是一个节点,将这些节点均匀地分布在哈希环上。当插入或查询数据时,根据数据的哈希值将其映射到哈希环上,然后顺时针查找最近的节点(即负责该哈希值范围的数据库或表),将数据插入或查询该节点。
优点:
-
支持节点的动态扩容。
缺点:
-
当节点数量变化较大时,可能需要重新计算所有数据的哈希值并进行迁移,增加系统的开销
-
范围查询和顺序查询可能不如范围分表和哈希分表高效。
非分片键字段如何查询?
曾几何时,面试过程中遇到过这样一个问题:假设有一个用户表,你用ID做的分片键,那么有一个类似于name这样的字段如何查询?
这里提供几种常见的思路:
1.全局索引
全局索引是一个跨所有分片的索引,它包含了非分片键字段和对应的分片键信息。查询时,先通过全局索引找到相关的分片键,然后在相应的分片中查询详细数据。
适用场景:适用于查询频率高、数据量大的非分片键字段。
优点:查询效率高,可以快速定位到数据所在的分片。
缺点:全局索引维护成本较高,需要定期更新以保持与分片数据的一致性。
2. 数据冗余
在每个分片中存储部分非分片键字段的数据。这样,即使不直接查询分片键,也可以在分片内快速找到相关数据。
适用场景:适用于查询性能要求极高,且可以接受一定数据冗余的场景。
优点:查询性能高,无需跨分片查询。
缺点:数据冗余增加了存储成本和维护复杂性。
3. 应用层处理
在应用层实现复杂的查询逻辑,将多个分片中的查询结果汇总后进行处理。
适用场景:适用于查询频率不高,或者可以接受一定延迟的场景。
优点:灵活性高,可以根据业务需求定制查询逻辑。
缺点:查询性能可能受到网络延迟和分片数量的影响。
4. 使用Elasticsearch(ES)
将非分片键字段的数据同步到Elasticsearch中,利用Elasticsearch强大的搜索和查询能力进行查询。
适用场景:适用于非结构化数据、全文搜索、复杂查询等场景。
优点:支持复杂的查询操作,如全文搜索、模糊匹配等;查询性能高,支持分布式部署。
缺点:需要维护Elasticsearch集群,增加了系统的复杂性;数据同步可能引入一定的延迟。
5. 数据库中间件
使用数据库中间件(如ShardingSphere、MyCAT等)来管理分库分表,中间件可以自动处理非分片键字段的查询,将请求路由到正确的分片。
适用场景:适用于希望减少应用层复杂性的场景。
优点:简化了应用层的查询逻辑,减少了开发和维护的工作量。
缺点:需要配置和维护数据库中间件。
总结
在实际应用中,可能需要根据实际情况结合多种策略来满足不同的查询需求。同时,随着业务的发展和数据量的增长,可能需要不断调整和优化分库分表策略。
如何解决热点数据倾斜问题?
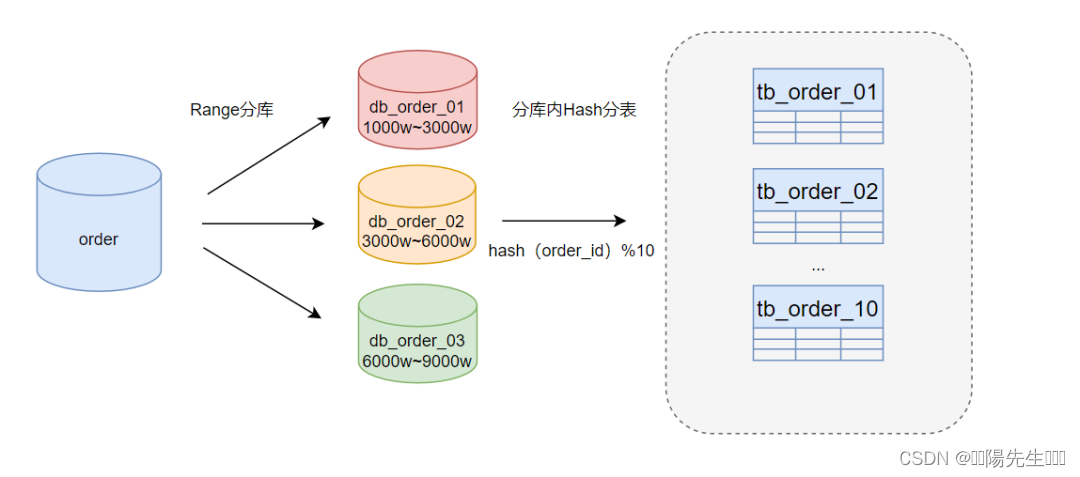
热点数据倾斜通常发生在某些特定的数据项(例如,用户激增、促销订单峰值等)等,导致这些数据的查询和更新操作集中在些某特定的数据库或表上,从而造成性能瓶颈。
解决方案:采用Range分库+Hash分表
如何解决跨库关联查询?
分库分表后,数据被分散到了不同的数据库或表中。跨库关联查询成为新的问题。为了解决这个问题,可以采取以下几种策略:
-
字段冗余:对于经常需要进行关联查询的字段,可以考虑将这些字段冗余到每个相关的表中。这样,在进行查询时就不需要跨库关联,可以直接在单个表内完成查询。例如,如果经常需要查询合同和客户的关联信息,可以在合同表中冗余一些客户的基础字段,这样查询时就不需要跨库关联客户表。
-
数据同步:如果某个系统经常需要查询另一个系统的数据,可以在当前系统中创建一张对应的表,并通过ETL或其他数据同步工具定时同步所需的数据。这样,查询时就可以直接在本地表中完成,避免了跨库关联查询。
-
全局表(广播表):对于某些基础数据,如行名行号信息等,如果它们被多个业务系统频繁使用,可以考虑在所有的数据库中都存储这些基础数据。这样,无论哪个系统需要这些数据,都不需要进行跨库关联查询。
-
ER表(绑定表):对于存在逻辑主外键关系的表,如订单表和订单明细表,可以考虑将它们的数据物理上存储在一起,形成一个绑定表。这样,查询时就可以在一个表中完成主表和明细表的关联查询,避免了跨库关联。
-
使用分布式中间件:分布式中间件如Sharding-JDBC、MyCAT等,可以将多个物理数据库视为一个逻辑数据库。这些中间件能够处理复杂的联合查询、排序、聚合等SQL操作,并根据分片规则指导SQL语句的执行。它们能够解决分库分表后的通过程序聚合汇总结果,解决跨库关联查询问题。
-
应用层数据聚合:在应用层,可以编写逻辑来聚合来自不同数据库或表的数据。这通常涉及发起多个数据库查询,然后在应用层将结果集合并成所需的结构。
需要注意的是,虽然上述方法可以解决跨库关联查询的问题,但它们也会带来一些额外的复杂性。在设计分库分表方案时,需要综合考虑业务需求、数据量、查询频率等因素,选择合适的策略来平衡性能和可维护性。同时,随着业务的发展和数据量的增长,可能需要对分库分表方案进行调整和优化。
如何解决分库分表后排序、分页问题?
分库分表后,排序和分页问题变得相对复杂,因为数据不再集中在一个单一的数据库或表中。解决这些问题需要综合考虑多种因素,包括数据量、查询频率、业务需求等。以下是一些解决分库分表后排序和分页问题的策略:
排序问题
-
全局排序字段:在分库分表时,可以引入一个全局排序字段,所有分片都基于这个字段进行排序。这样,即使数据分布在不同的分片中,也可以保证整体排序的一致性。
-
数据同步与合并:在查询时,从各个分片中分别获取数据,然后在应用层将这些数据按照排序规则进行合并。这种方式需要处理大量的数据传输和合并逻辑,可能对性能有一定影响。
-
中间件支持:使用支持分库分表的中间件,如ShardingSphere、MyCAT等。这些中间件通常提供了强大的排序功能,能够处理分库分表后的排序问题。
-
预算与缓存:对于某些固定的排序需求,可以预先计算排序结果并缓存起来,减少实时计算的压力。
分页问题
-
分页参数调整:在分库分表的情况下,传统的
LIMIT OFFSET分页方式可能不再适用。可以考虑调整分页参数,比如使用基于游标(cursor)的分页方式,或者基于时间戳、ID等排序字段的范围查询来实现分页。 -
数据聚合:类似于排序问题的解决方式,从各个分片中分别获取数据,然后在应用层进行数据聚合,实现分页功能。
-
中间件支持:使用支持分库分表的中间件,这些中间件通常也提供了分页功能的支持,能够简化分页查询的处理。
-
限制分页:对于深度分页的需求,可以考虑限制分页的深度,避免查询大量的数据。例如,只支持查询前100页的数据。
-
预加载与缓存:对于经常访问的分页数据,可以考虑预加载并缓存起来,减少实时查询的开销。
分库分表如何扩容?
当数据量逐渐增加,需要进行分库分表的扩容时,可以从以下几个方面来考虑和制定策略:
1. 数据增长评估
首先,要对数据的增长趋势进行准确的评估。通过分析历史数据、业务发展趋势以及用户增长情况,可以预测未来的数据量增长情况。一般预估未来3~5年的数据增长。
2. 选择合适的分片键
选择一个合适的分片键是分库分表的关键。分片键应该能够均匀分布数据,避免某些数据库或表过载。同时,分片键的选择也要考虑到查询性能和数据一致性等因素。
3. 实施扩容
基于数据增长趋势和分片键的选择,制定详细的扩容计划。这包括确定扩容的时间点、扩容的目标规模、数据迁移和重新分配的策略等。确保扩容过程能够顺利进行,尽可能减少对业务的影响。
4. 数据迁移与重新分配
在扩容过程中,需要进行数据迁移和重新分配。这通常涉及到将现有数据从旧的数据库或表迁移到新的数据库或表中。可以使用数据迁移工具或自动化脚本来完成这个过程,确保数据的完整性和一致性。
5. 负载均衡
在扩容后,需要确保数据在新旧数据库或表之间均匀分布,以实现负载均衡。可以使用负载均衡器或支持分库分表的中间件来动态分配请求,确保系统的性能和稳定性。
6. 监控与调优
在扩容过程中和扩容后,需要对系统进行持续的监控和调优。通过监控数据库或表的负载情况、查询性能等指标,及时发现并解决性能瓶颈和故障。同时,根据实际需求进行调优,如调整索引、优化查询语句等,以提升系统的整体性能。
分库分表中间件技术对比
业界常用的分库分表中间有:Sharding和MyCat
-
ShardingSphere
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。ShardingSphere提供数据分片、读写分离、多数据源集成等功能。其中,Sharding-JDBC是一个轻量级的Java框架,以jar包形式提供服务,无需额外部署和依赖,适用于Java应用。Sharding-Proxy则是一个独立的数据库代理,支持MySQL和PostgreSQL协议,可以实现透明的数据库操作。
优点:
-
功能丰富,支持数据分片、读写分离、广播表、分布式事务等。
-
社区活跃,文档完善,有较多的成功案例。
-
支持多种数据库和SQL方言,具有较好的兼容性。
缺点:
-
对于非Java应用可能需要额外的适配工作。
-
在处理复杂SQL时可能存在一定的性能损耗。
-
Mycat
Mycat是一个开源的、跨平台的、基于MySQL协议的数据库中间件,支持SQL分析、SQL解析、SQL路由、SQL改写、SQL执行和结果归并等功能。Mycat可以实现透明的读写分离、自动故障切换、负载均衡等特性,同时支持多租户模式和全局序列号等功能。
优点:
-
支持MySQL协议,对于使用MySQL的应用无需修改代码即可接入。
-
支持多种路由策略,可以满足不同的业务需求。
-
提供丰富的监控和管理功能,方便运维和管理。
缺点:
-
主要针对MySQL数据库,对于其他类型的数据库支持有限。
-
在处理复杂SQL时可能存在一定的限制和性能问题。
总结
分库分表技术总结
一、分库分表策略
分库分表(Sharding)是一种将单一数据库拆分为多个数据库实例,以及将单一大表拆分为多个小表的技术策略。其目的是解决单一数据库在数据量、并发访问、性能等方面的瓶颈,提升系统的整体性能和可靠性。
常见的分库分表策略包括:
-
水平拆分(Sharding by Key):根据某个字段的值将表拆分为多个子表,每个子表只包含部分数据。这种策略适用于数据量巨大、访问频繁的表。
-
垂直拆分:将表按照列进行拆分,将不同列的数据分散到不同的表中。这种策略适用于某些列的数据量特别大或访问特别频繁的情况。
-
读写分离:将数据库的读操作和写操作分离到不同的数据库实例上,以提高系统的并发处理能力和性能。
二、分库分表常见问题
-
数据一致性问题:分库分表后,数据分布在不同的数据库和表中,需要确保跨库跨表操作的数据一致性。
-
跨库跨表查询问题:复杂的跨库跨表查询可能变得困难,需要考虑查询性能和数据整合。
-
事务处理问题:分布式事务的处理比单一数据库更复杂,需要确保不同数据库实例间的事务一致性。
-
中间件选择问题:选择合适的分库分表中间件是关键,需要考虑中间件的性能、稳定性、兼容性等因素。
相关文章:
聊聊分库分表
文章导读 背景介绍 随着互联网技术的发展,数据量呈爆炸性增长。大数据量的业务场景中,数据库成为系统性能瓶颈的一个主要因素。当单个数据库包含了太多数据或过高的访问量时,会出现查询缓慢、响应时间长等问题,严重影响用户体验。…...
小米标准模组+MCU 快速上手开发(二)——之模组串口调试
小米标准模组MCU 开发笔记之固件调试 背景技术名词简介● 小米IoT开发者平台● 小米IoT 模组● 固件● OTA● CRC32 固件双串口调试● MHCWB6S-IB 模组资料下载● MHCWB6S-IB 模组管脚图● 上电调试 背景 小米标准模组MCU的开发过程中,由于部分官方资料较为古早&am…...
Ubuntu22.04和Windows10双系统安装
概要 本篇演示Ubuntu22.04和Windows10双系统的安装。先安装Ubuntu22.04,再安装Windows10。 一、说明 1、电脑 笔者的电脑品牌是acer(宏碁/宏基) 电脑开机按F2进入BIOS 电脑开机按F12进入Boot Manager 2、U盘启动盘 需要用到两个U盘启动盘 (1&a…...
重新安装VSCode后,按住Ctrl(or Command) 点击鼠标左键不跳转问题
重新安装VSCode后,按住Ctrl(or Command) 点击鼠标左键不跳转问题 原因:重新安装一般是因为相应编程语言的插件被删除了或还没有下载。 本次是由于Python相关的插件被删除了,因此导致Python无法跳转。 解决办法 在vs…...
QPaint绘制自定义仪表盘组件01
网上抄别人的,只是放这里自己看一下,看完就删掉 ui Dashboard.pro QT core guigreaterThan(QT_MAJOR_VERSION, 4): QT widgetsCONFIG c11# You can make your code fail to compile if it uses deprecated APIs. # In order to do so, uncomm…...
华为笔记本原厂系统镜像恢复安装教程方法
1.安装方法有两种,一种是用PE安装,一种是华为工厂包安装(安装完成自带F10智能还原) 若没有原装系统文件,请在这里远程恢复安装:https://pan.baidu.com/s/166gtt2okmMmuPUL1Fo3Gpg?pwdm64f 提取码:m64f …...
互联网高科技公司领导AI工业化,MatrixGo加速人工智能落地
作者:吴宁川 AI(人工智能)工业化与AI工程化正在引领人工智能的大趋势。AI工程化主要从企业CIO角度,着眼于在企业生产环境中规模化落地AI应用的工程化举措;而AI工业化则从AI供应商的角度,着眼于以规模化方式…...
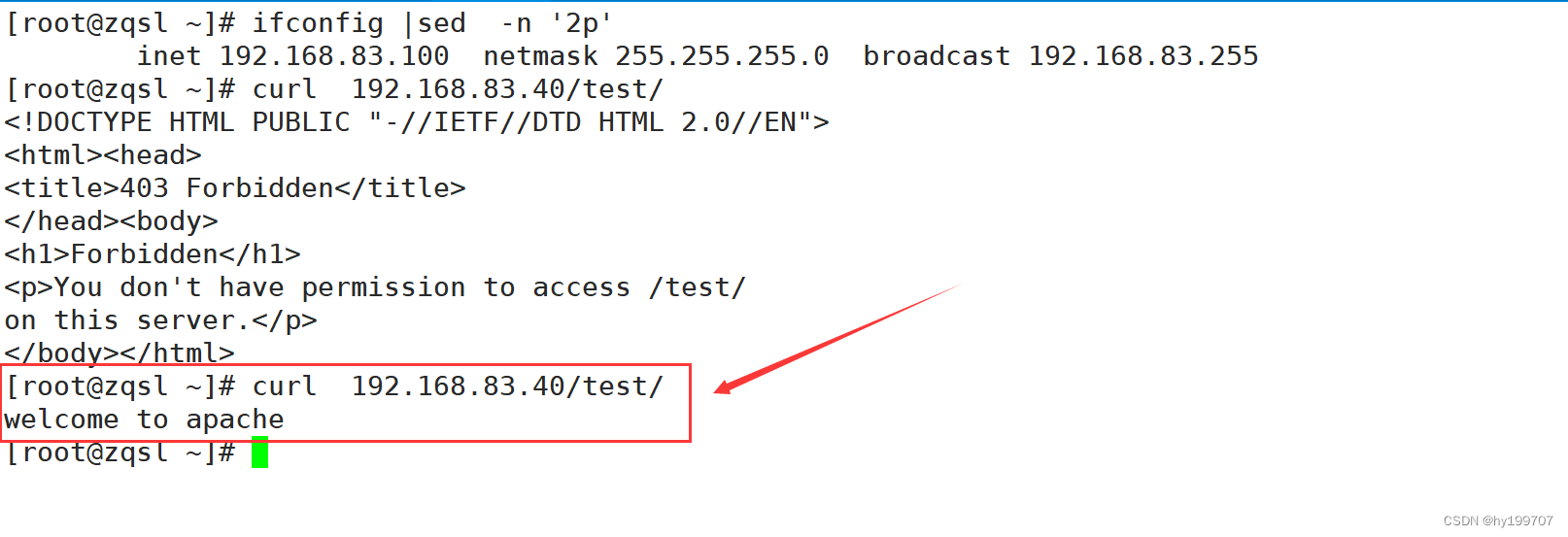
Apache服务
目录 引言 一、常见的http服务程序 (一)lls (二)nginx (三)Apache (四)Tomcat 二、Apache特点 三、Apache服务的安装 (一)yum安装及配置文件 1.配置…...
----Template API)
【Spring连载】使用Spring Data访问 MongoDB(二)----Template API
【Spring连载】使用Spring Data访问 MongoDB(二)----Template API 一、方便的方法二、执行回调函数Execute Callbacks三、Fluent API四、异常转换五、域类型映射六、配置6.1 默认读取首选项Read Preference6.2 WriteResultChecking策略6.3 默认写安全Wri…...
)
手写table表格(一表头多数据)
手写table表格(一表头多数据) <template><div class"table-info"><div class"info-list"><div class"header-wrapper"><div class"columns-title" v-for"(i, k) in columns&q…...
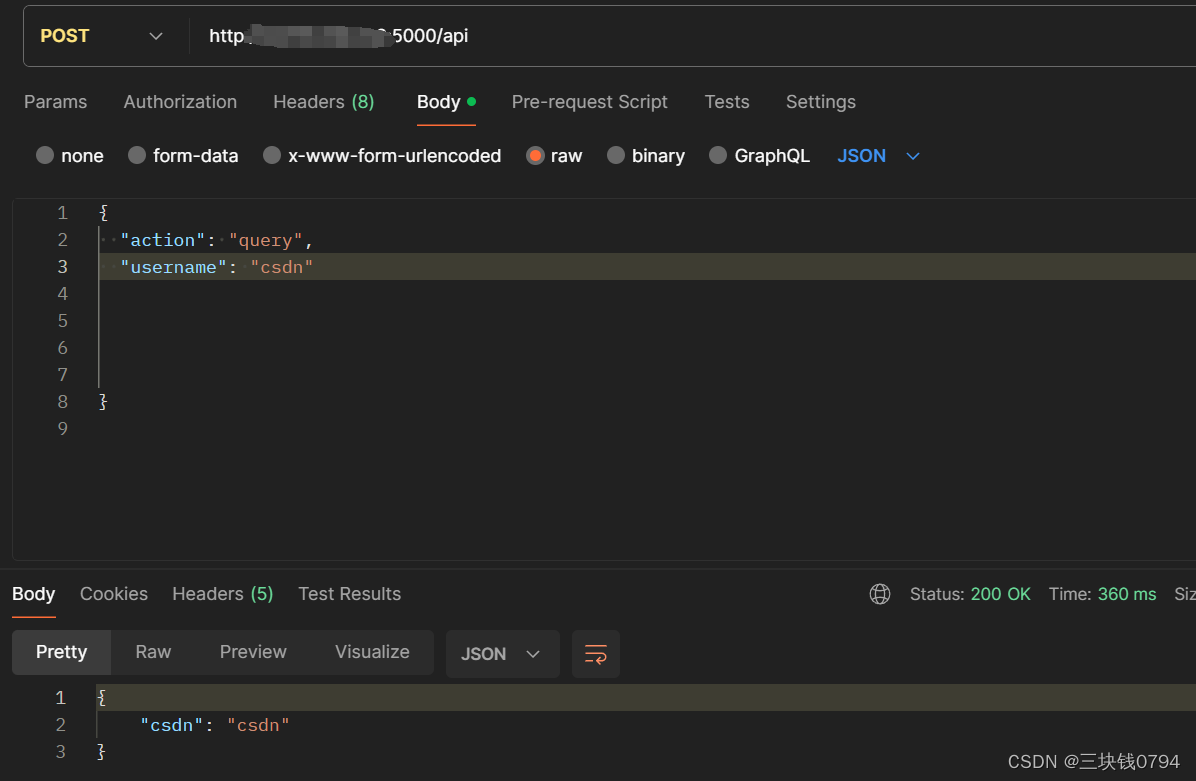
python3 flask 实现对config.yaml文件的内容的增删改查,并重启服务
config.yaml配置文件内容 功能就是userpass下的用户名和密码做增删改查,并重启hy2服务 auth:type: userpassuserpass:csdn: csdnlisten: :443 masquerade:proxy:rewriteHost: trueurl: https://www.bing.com/type: proxy tls:cert: /root/hyst*****马赛克******er…...

ADO世界之“对象”
目录 一、Command 对象 1.Command 对象 2.语法 3.属性 4.方法 5.集合 二、Connection 对象 1.Connection 对象 2.语法 3.属性 4.方法 5.事件 6.集合 三、Error 对象 1.Error 对象 2.语法 3.属性 四、Parameter 对象 1.Field 对象 2.语法 3.属性 4.方法 …...

LeetCode59-螺旋矩阵II
参考链接:代码随想录->螺旋矩阵II 关键是学视频链接里面的编码思想,然后背下来 class Solution { public:vector<vector<int>> generateMatrix(int n) {vector<vector<int>> resvector(n,vector<int>(n,0));int sx0,s…...
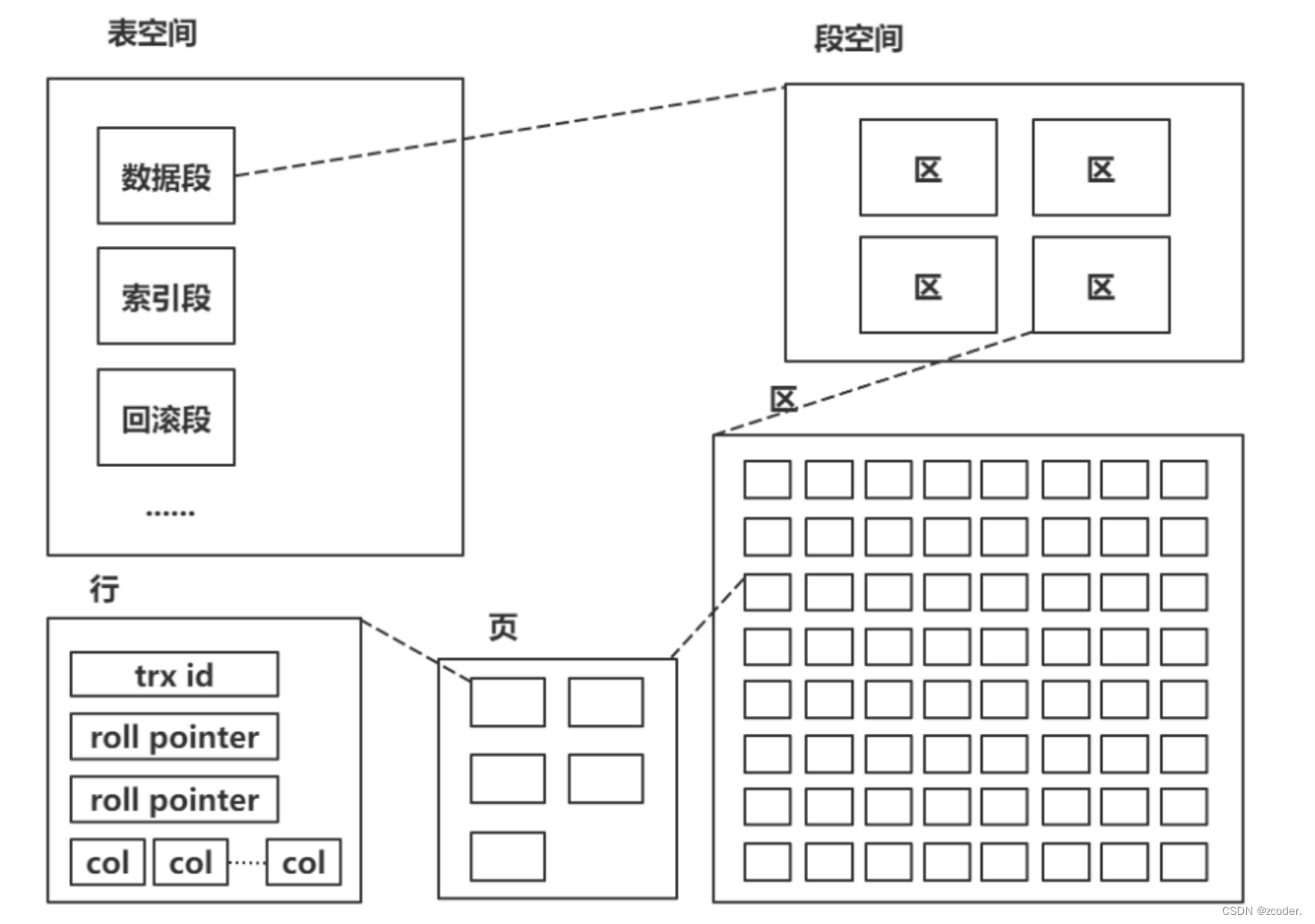
MySQL 索引原理以及 SQL 优化
索引 索引:一种有序的存储结构,按照单个或者多个列的值进行排序。索引的目的:提升搜索效率。索引分类: 数据结构 B 树索引(映射的是磁盘数据)hash 索引(快速锁定内存数据)全文索引 …...

C++学习Day08之函数模板和普通函数的区别以及调用规则
目录 一、程序及输出1.1 区别1.1.1 自动类型推导,不可以发生隐式类型转换的1.1.2 普通函数 可以发生隐式类型转换 1.2 调用规则 二、分析与总结 一、程序及输出 1.1 区别 1.1.1 自动类型推导,不可以发生隐式类型转换的 1.1.2 普通函数 可以发生隐式类型…...
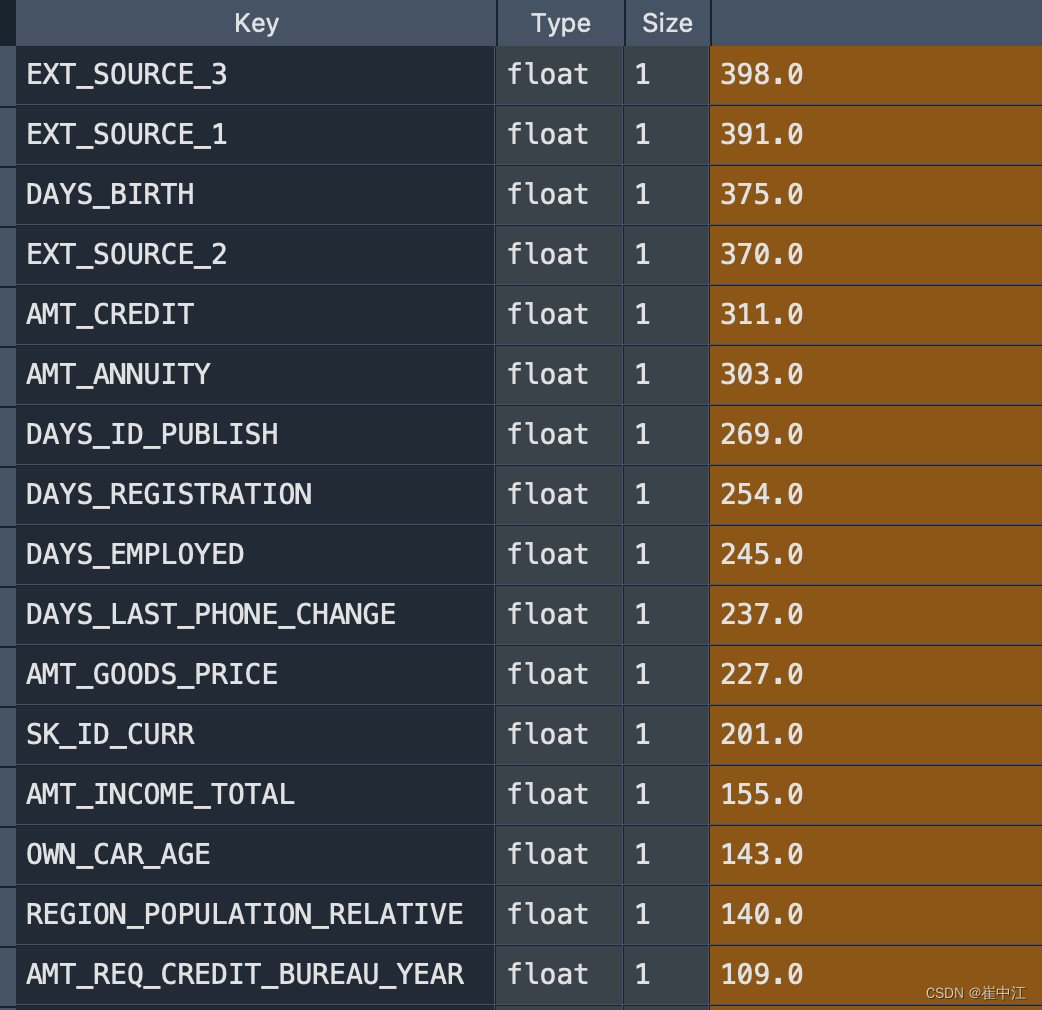
Kaggle实践之《Home Credit Default Risk》的逐步优化
记录下每一次的改进及其score。 1、只用训练集的特征简单处理 特征只用训练集的特征,把string型的特征全部进行one-hot转化,然后随机1:4分成测试集训练集,模型也调参直接出结果。 最终的score是训练集80.13%、验证集76.33%、线上74.28%。 …...
django rest framework 学习笔记-实战商城2
01收货地址模型类和视图定义_哔哩哔哩_bilibili 本博客借鉴至大佬的视频学习笔记 地址信息的管理:增删改查的实现 # 序列化器配置 class AddrSerializer(serializers.ModelSerializer):"""收货地址的模型序列化器"""class Meta:mo…...

WEB 3D技术 three.js 3D贺卡(4) 添加鼠标滚轮移动屏幕 改变贺卡文字功能
好,上文 WEB 3D技术 three.js 3D贺卡(3) 点光源灯光动画效果 那么 我们来做一下 鼠标滚动相机和滚动时不同文字的切换 首先 我们要设置多个场景 其实也不能完全叫场景 也可以说多个位置 反正简单说就是多个位置 展现多个场景 我们先在代码的最下面 加上一个对象数…...
爬虫在网页抓取的过程中可能会遇到哪些问题?
在网页抓取(爬虫)过程中,开发者可能会遇到多种问题,以下是一些常见问题及其解决方案: 1. IP封锁: 问题:封IP是最常见的问题,抓取的目标网站会识别并封锁频繁请求的IP地址。 解决方案…...

Eclipse中Run As On Server和Run As Java Application
一、名词释义 run java application (作为Java应用程序运行)是运行 java main方法。 run on server是启动一个web 应用服务器。 二、两者的区别 Eclipse中可以创建java project 也可以创建java web poject 。java project是可以直接在命令行运行,或者…...

如何快速上手Meeko:分子对接参数化的完整指南
如何快速上手Meeko:分子对接参数化的完整指南 【免费下载链接】Meeko Interface for AutoDock, molecule parameterization 项目地址: https://gitcode.com/gh_mirrors/me/Meeko 想要在药物发现和分子相互作用研究中获得精准的对接结果吗?Meeko作…...

智能图像分层革命:5分钟将任何图片转换为可编辑PSD图层
智能图像分层革命:5分钟将任何图片转换为可编辑PSD图层 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 你是否曾面对一张精美的插画ÿ…...

UV-UI框架终极指南:如何快速构建跨平台应用
UV-UI框架终极指南:如何快速构建跨平台应用 【免费下载链接】uv-ui uv-ui 破釜沉舟之兼容vue32、app、h5、小程序等多端基于uni-app和uView2.x的生态框架,支持单独导入,开箱即用,利剑出击。 项目地址: https://gitcode.com/gh_m…...

零基础,能转行做网络安全架构师吗?一份写给“跨界者”的理性指南
零基础,能转行做网络安全架构师吗?一份写给“跨界者”的理性指南 拆解真实岗位需求,规划可达成的12个月学习路径 “我30岁了,学编程转行网络安全还来得及吗?”“非科班出身,能成为网络安全架构师吗&#…...

5分钟搞定专业网络拓扑图:easy-topo终极使用指南
5分钟搞定专业网络拓扑图:easy-topo终极使用指南 【免费下载链接】easy-topo vuesvgelement-ui 快捷画出网络拓扑图 项目地址: https://gitcode.com/gh_mirrors/ea/easy-topo 还在为绘制复杂的网络架构图而头疼吗?网络拓扑图是网络工程师、系统管…...

长鑫存储逆袭:从近10年亏损超366亿到盈利超预期,能否成“中国海力士”?
长鑫存储逆袭:从巨亏到盈利超预期,能否成为“中国海力士”?“韩国巨头布局存储,中国巨头热衷于外卖。”这一波存储涨价潮,很多人用戏谑的方式来表达对中国几家互联网公司的“恨铁不成钢”。但长鑫存储却凭借一份极度亮…...

从零到一:WPR机器人仿真平台实战指南,快速掌握ROS机器人开发精髓
从零到一:WPR机器人仿真平台实战指南,快速掌握ROS机器人开发精髓 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 你是否对机器人开发充满热情,却被高昂的硬件成本和复杂的调试过程吓退…...

ViGEmBus终极指南:如何在Windows上轻松实现游戏手柄兼容性
ViGEmBus终极指南:如何在Windows上轻松实现游戏手柄兼容性 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一个开源的Windows内核模式…...

从PubMed到VOSviewer:手把手教你用MeSH词表做更精准的医学文献关键词共现分析
从PubMed到VOSviewer:解锁MeSH词表在医学文献分析中的精准力量 医学研究者常面临海量文献的筛选难题——如何从数万篇论文中快速识别核心研究方向?传统的关键词共现分析往往被"aged"、"female"等高频但低区分度的词汇干扰࿰…...

智慧树刷课插件:如何用自动化工具解放你的学习时间
智慧树刷课插件:如何用自动化工具解放你的学习时间 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 你是否曾经花费大量时间在智慧树平台上手动点击视频、处…...