Windows下搭建EFK实例
资源下载
elasticSearch :下载最新版本的就行
kibana
filebeat:注意选择压缩包下载
更新elasticsearch.yml,默认端口9200:
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
#cluster.name: my-application
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
#node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
#
#network.host: 192.168.0.1
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
#
#http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.seed_hosts: ["host1", "host2"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
#cluster.initial_master_nodes: ["node-1", "node-2"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Allow wildcard deletion of indices:
#
#action.destructive_requires_name: false#----------------------- BEGIN SECURITY AUTO CONFIGURATION -----------------------
#
# The following settings, TLS certificates, and keys have been automatically
# generated to configure Elasticsearch security features on 20-02-2024 07:30:46
#
# --------------------------------------------------------------------------------# Enable security features
xpack.security.enabled: falsexpack.security.enrollment.enabled: true# Enable encryption for HTTP API client connections, such as Kibana, Logstash, and Agents
xpack.security.http.ssl:enabled: falsekeystore.path: certs/http.p12# Enable encryption and mutual authentication between cluster nodes
xpack.security.transport.ssl:enabled: trueverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
# Create a new cluster with the current node only
# Additional nodes can still join the cluster later
cluster.initial_master_nodes: ["RAYL"]# Allow HTTP API connections from anywhere
# Connections are encrypted and require user authentication
http.host: 0.0.0.0# Allow other nodes to join the cluster from anywhere
# Connections are encrypted and mutually authenticated
#transport.host: 0.0.0.0#----------------------- END SECURITY AUTO CONFIGURATION -------------------------更新kibana.yml配置,默认端口5601:
# For more configuration options see the configuration guide for Kibana in
# https://www.elastic.co/guide/index.html# =================== System: Kibana Server ===================
# Kibana is served by a back end server. This setting specifies the port to use.
#server.port: 5601# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
#server.host: "localhost"# Enables you to specify a path to mount Kibana at if you are running behind a proxy.
# Use the `server.rewriteBasePath` setting to tell Kibana if it should remove the basePath
# from requests it receives, and to prevent a deprecation warning at startup.
# This setting cannot end in a slash.
#server.basePath: ""# Specifies whether Kibana should rewrite requests that are prefixed with
# `server.basePath` or require that they are rewritten by your reverse proxy.
# Defaults to `false`.
#server.rewriteBasePath: false# Specifies the public URL at which Kibana is available for end users. If
# `server.basePath` is configured this URL should end with the same basePath.
#server.publicBaseUrl: ""# The maximum payload size in bytes for incoming server requests.
#server.maxPayload: 1048576# The Kibana server's name. This is used for display purposes.
#server.name: "your-hostname"# =================== System: Kibana Server (Optional) ===================
# Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively.
# These settings enable SSL for outgoing requests from the Kibana server to the browser.
#server.ssl.enabled: false
#server.ssl.certificate: /path/to/your/server.crt
#server.ssl.key: /path/to/your/server.key# =================== System: Elasticsearch ===================
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://localhost:9200"]# If your Elasticsearch is protected with basic authentication, these settings provide
# the username and password that the Kibana server uses to perform maintenance on the Kibana
# index at startup. Your Kibana users still need to authenticate with Elasticsearch, which
# is proxied through the Kibana server.
#elasticsearch.username: "kibana_system"
#elasticsearch.password: "pass"# Kibana can also authenticate to Elasticsearch via "service account tokens".
# Service account tokens are Bearer style tokens that replace the traditional username/password based configuration.
# Use this token instead of a username/password.
# elasticsearch.serviceAccountToken: "my_token"# Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of
# the elasticsearch.requestTimeout setting.
#elasticsearch.pingTimeout: 1500# Time in milliseconds to wait for responses from the back end or Elasticsearch. This value
# must be a positive integer.
#elasticsearch.requestTimeout: 30000# The maximum number of sockets that can be used for communications with elasticsearch.
# Defaults to `Infinity`.
#elasticsearch.maxSockets: 1024# Specifies whether Kibana should use compression for communications with elasticsearch
# Defaults to `false`.
#elasticsearch.compression: false# List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side
# headers, set this value to [] (an empty list).
#elasticsearch.requestHeadersWhitelist: [ authorization ]# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten
# by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration.
#elasticsearch.customHeaders: {}# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable.
#elasticsearch.shardTimeout: 30000# =================== System: Elasticsearch (Optional) ===================
# These files are used to verify the identity of Kibana to Elasticsearch and are required when
# xpack.security.http.ssl.client_authentication in Elasticsearch is set to required.
#elasticsearch.ssl.certificate: /path/to/your/client.crt
#elasticsearch.ssl.key: /path/to/your/client.key# Enables you to specify a path to the PEM file for the certificate
# authority for your Elasticsearch instance.
#elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ]# To disregard the validity of SSL certificates, change this setting's value to 'none'.
#elasticsearch.ssl.verificationMode: full# =================== System: Logging ===================
# Set the value of this setting to off to suppress all logging output, or to debug to log everything. Defaults to 'info'
#logging.root.level: debug# Enables you to specify a file where Kibana stores log output.
#logging.appenders.default:
# type: file
# fileName: /var/logs/kibana.log
# layout:
# type: json# Logs queries sent to Elasticsearch.
#logging.loggers:
# - name: elasticsearch.query
# level: debug# Logs http responses.
#logging.loggers:
# - name: http.server.response
# level: debug# Logs system usage information.
#logging.loggers:
# - name: metrics.ops
# level: debug# =================== System: Other ===================
# The path where Kibana stores persistent data not saved in Elasticsearch. Defaults to data
#path.data: data# Specifies the path where Kibana creates the process ID file.
#pid.file: /run/kibana/kibana.pid# Set the interval in milliseconds to sample system and process performance
# metrics. Minimum is 100ms. Defaults to 5000ms.
#ops.interval: 5000# Specifies locale to be used for all localizable strings, dates and number formats.
# Supported languages are the following: English (default) "en", Chinese "zh-CN", Japanese "ja-JP", French "fr-FR".
i18n.locale: "zh-CN"# =================== Frequently used (Optional)===================# =================== Saved Objects: Migrations ===================
# Saved object migrations run at startup. If you run into migration-related issues, you might need to adjust these settings.# The number of documents migrated at a time.
# If Kibana can't start up or upgrade due to an Elasticsearch `circuit_breaking_exception`,
# use a smaller batchSize value to reduce the memory pressure. Defaults to 1000 objects per batch.
#migrations.batchSize: 1000# The maximum payload size for indexing batches of upgraded saved objects.
# To avoid migrations failing due to a 413 Request Entity Too Large response from Elasticsearch.
# This value should be lower than or equal to your Elasticsearch cluster’s `http.max_content_length`
# configuration option. Default: 100mb
#migrations.maxBatchSizeBytes: 100mb# The number of times to retry temporary migration failures. Increase the setting
# if migrations fail frequently with a message such as `Unable to complete the [...] step after
# 15 attempts, terminating`. Defaults to 15
#migrations.retryAttempts: 15# =================== Search Autocomplete ===================
# Time in milliseconds to wait for autocomplete suggestions from Elasticsearch.
# This value must be a whole number greater than zero. Defaults to 1000ms
#unifiedSearch.autocomplete.valueSuggestions.timeout: 1000# Maximum number of documents loaded by each shard to generate autocomplete suggestions.
# This value must be a whole number greater than zero. Defaults to 100_000
#unifiedSearch.autocomplete.valueSuggestions.terminateAfter: 100000更新filebeat.yml: 命令行执行 install-service-filebeat.ps1 把filebeat安装为windows服务,在service中搜索
注意如果显示执行脚本未签名,更新windows ExecutionPolicy为RemoteSigned,执行指令Set-ExecutionPolicy RemoteSigned
###################### Filebeat Configuration Example ########################## This file is an example configuration file highlighting only the most common
# options. The filebeat.reference.yml file from the same directory contains all the
# supported options with more comments. You can use it as a reference.
#
# You can find the full configuration reference here:
# https://www.elastic.co/guide/en/beats/filebeat/index.html# For more available modules and options, please see the filebeat.reference.yml sample
# configuration file.# ============================== Filebeat inputs ===============================filebeat.inputs:# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input-specific configurations.# filestream is an input for collecting log messages from files.
- type: log# Unique ID among all inputs, an ID is required.id: my-filestream-id# Change to true to enable this input configuration.enabled: true# Paths that should be crawled and fetched. Glob based paths.paths:#- /var/log/*.log- your log path(这里改成你的日志地址 * 是通配符匹配文件夹下所有文件例如:E:\Project\log\* )# Exclude lines. A list of regular expressions to match. It drops the lines that are# matching any regular expression from the list.# Line filtering happens after the parsers pipeline. If you would like to filter lines# before parsers, use include_message parser.#exclude_lines: ['^DBG']# Include lines. A list of regular expressions to match. It exports the lines that are# matching any regular expression from the list.# Line filtering happens after the parsers pipeline. If you would like to filter lines# before parsers, use include_message parser.#include_lines: ['^ERR', '^WARN']# Exclude files. A list of regular expressions to match. Filebeat drops the files that# are matching any regular expression from the list. By default, no files are dropped.#prospector.scanner.exclude_files: ['.gz$']# Optional additional fields. These fields can be freely picked# to add additional information to the crawled log files for filtering#fields:# level: debug# review: 1# ============================== Filebeat modules ==============================filebeat.config.modules:# Glob pattern for configuration loadingpath: ${path.config}/modules.d/*.yml# Set to true to enable config reloadingreload.enabled: false# Period on which files under path should be checked for changes#reload.period: 10s# ======================= Elasticsearch template setting =======================setup.template.settings:index.number_of_shards: 1#index.codec: best_compression#_source.enabled: false# ================================== General ===================================# The name of the shipper that publishes the network data. It can be used to group
# all the transactions sent by a single shipper in the web interface.
#name:# The tags of the shipper are included in their field with each
# transaction published.
#tags: ["service-X", "web-tier"]# Optional fields that you can specify to add additional information to the
# output.
#fields:
# env: staging# ================================= Dashboards =================================
# These settings control loading the sample dashboards to the Kibana index. Loading
# the dashboards is disabled by default and can be enabled either by setting the
# options here or by using the `setup` command.
#setup.dashboards.enabled: false# The URL from where to download the dashboard archive. By default, this URL
# has a value that is computed based on the Beat name and version. For released
# versions, this URL points to the dashboard archive on the artifacts.elastic.co
# website.
#setup.dashboards.url:# =================================== Kibana ===================================# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API.
# This requires a Kibana endpoint configuration.
setup.kibana:# Kibana Host# Scheme and port can be left out and will be set to the default (http and 5601)# In case you specify and additional path, the scheme is required: http://localhost:5601/path# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601host: "localhost:5601"# Kibana Space ID# ID of the Kibana Space into which the dashboards should be loaded. By default,# the Default Space will be used.#space.id:# =============================== Elastic Cloud ================================# These settings simplify using Filebeat with the Elastic Cloud (https://cloud.elastic.co/).# The cloud.id setting overwrites the `output.elasticsearch.hosts` and
# `setup.kibana.host` options.
# You can find the `cloud.id` in the Elastic Cloud web UI.
#cloud.id:# The cloud.auth setting overwrites the `output.elasticsearch.username` and
# `output.elasticsearch.password` settings. The format is `<user>:<pass>`.
#cloud.auth:# ================================== Outputs ===================================# Configure what output to use when sending the data collected by the beat.# ---------------------------- Elasticsearch Output ----------------------------
output.elasticsearch:# Array of hosts to connect to.hosts: ["localhost:9200"]# Performance preset - one of "balanced", "throughput", "scale",# "latency", or "custom".preset: balanced# Protocol - either `http` (default) or `https`.#protocol: "https"# Authentication credentials - either API key or username/password.#api_key: "id:api_key"#username: "elastic"#password: "changeme"# ------------------------------ Logstash Output -------------------------------
#output.logstash:# The Logstash hosts#hosts: ["localhost:5044"]# Optional SSL. By default is off.# List of root certificates for HTTPS server verifications#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]# Certificate for SSL client authentication#ssl.certificate: "/etc/pki/client/cert.pem"# Client Certificate Key#ssl.key: "/etc/pki/client/cert.key"# ================================= Processors =================================
processors:- add_host_metadata:when.not.contains.tags: forwarded- add_cloud_metadata: ~- add_docker_metadata: ~- add_kubernetes_metadata: ~# ================================== Logging ===================================# Sets log level. The default log level is info.
# Available log levels are: error, warning, info, debug
#logging.level: debug# At debug level, you can selectively enable logging only for some components.
# To enable all selectors, use ["*"]. Examples of other selectors are "beat",
# "publisher", "service".
#logging.selectors: ["*"]# ============================= X-Pack Monitoring ==============================
# Filebeat can export internal metrics to a central Elasticsearch monitoring
# cluster. This requires xpack monitoring to be enabled in Elasticsearch. The
# reporting is disabled by default.# Set to true to enable the monitoring reporter.
#monitoring.enabled: false# Sets the UUID of the Elasticsearch cluster under which monitoring data for this
# Filebeat instance will appear in the Stack Monitoring UI. If output.elasticsearch
# is enabled, the UUID is derived from the Elasticsearch cluster referenced by output.elasticsearch.
#monitoring.cluster_uuid:# Uncomment to send the metrics to Elasticsearch. Most settings from the
# Elasticsearch outputs are accepted here as well.
# Note that the settings should point to your Elasticsearch *monitoring* cluster.
# Any setting that is not set is automatically inherited from the Elasticsearch
# output configuration, so if you have the Elasticsearch output configured such
# that it is pointing to your Elasticsearch monitoring cluster, you can simply
# uncomment the following line.
#monitoring.elasticsearch:# ============================== Instrumentation ===============================# Instrumentation support for the filebeat.
#instrumentation:# Set to true to enable instrumentation of filebeat.#enabled: false# Environment in which filebeat is running on (eg: staging, production, etc.)#environment: ""# APM Server hosts to report instrumentation results to.#hosts:# - http://localhost:8200# API Key for the APM Server(s).# If api_key is set then secret_token will be ignored.#api_key:# Secret token for the APM Server(s).#secret_token:# ================================= Migration ==================================# This allows to enable 6.7 migration aliases
#migration.6_to_7.enabled: trueelastic执行:命令行到解压后的bin文件夹 ./elasticsearch
启动后浏览器打开 http://localhost:9200
kibana: 命令行到解压后的bin文件夹 ./kibana.bat
浏览器打开 http://localhost:5601
filebeat: 直接从service启动
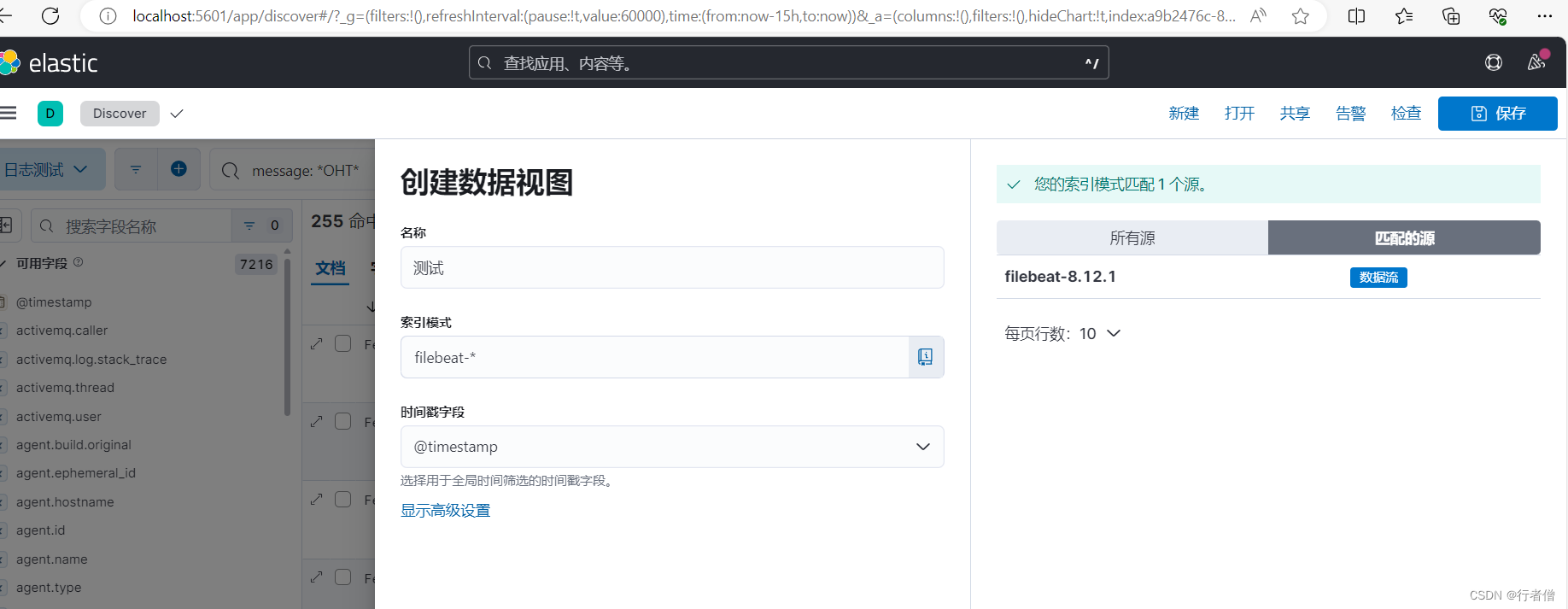
kibana创建数据视图,右边可以看到filebeat的源,索引模式匹配右边的数据源名称,这个名称可以在filebeat.yml配置:
对了,别忘了先安装java8及以上版本,ElasticSearch需要java环境
相关文章:
Windows下搭建EFK实例
资源下载 elasticSearch :下载最新版本的就行 kibana filebeat:注意选择压缩包下载 更新elasticsearch.yml,默认端口9200: # Elasticsearch Configuration # # NOTE: Elasticsearch comes with reasonable defaults for most …...
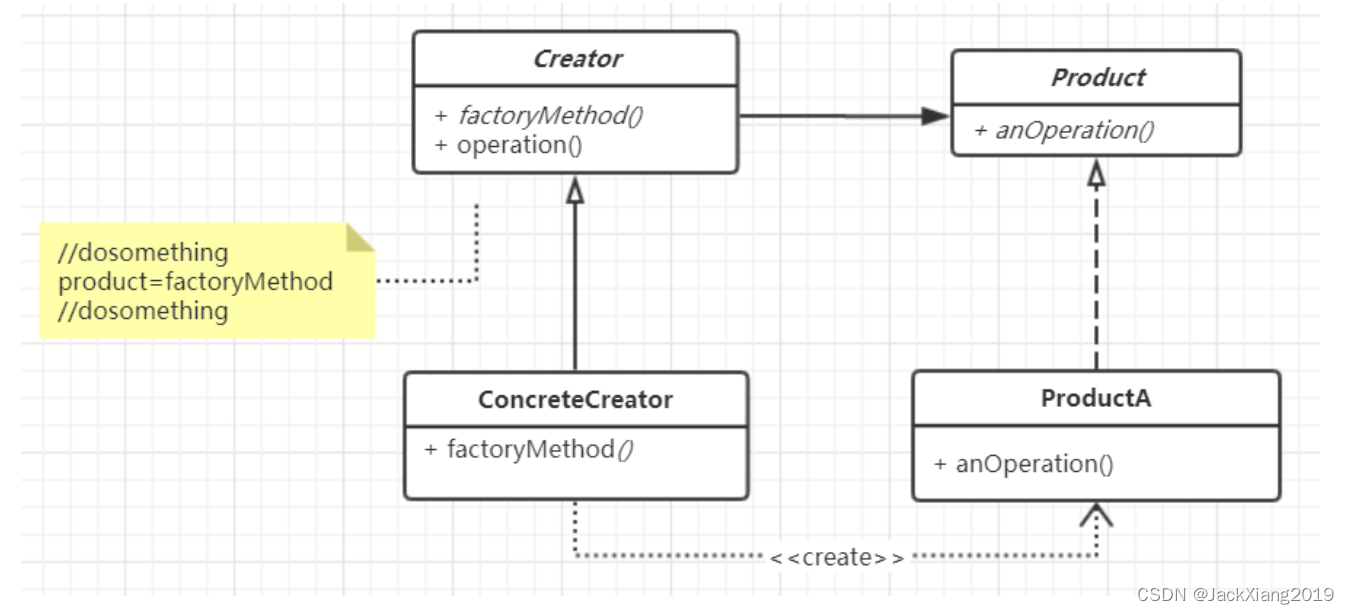
工厂方法模式Factory Method
1.模式定义 定义一个用于创建对象的接口,让子类决定实例化哪一个类。Factory Method 使得一个类的实例化延迟到子类 2.使用场景 1.当你不知道改使用对象的确切类型的时候 2.当你希望为库或框架提供扩展其内部组件的方法时 主要优点: 1.将具体产品和创建…...

Vue的个人笔记
Vue学习小tips ctrl s ----> 运行 alt b <scrip> 链接 <script src"https://cdn.jsdelivr.net/npm/vue2.7.16/dist/vue.js"></script> 插值表达式 指令...

linux platform架构下I2C接口驱动开发
目录 概述 1 认识I2C协议 1.1 初识I2C 1.2 I2C物理层 1.3 I2C协议分析 1.3.1 Start、Stop、ACK 信号 1.3.2 I2C协议的操作流程 1.3.3 操作I2C注意的问题 2 linux platform驱动开发 2.1 更新设备树 2.1.1 添加驱动节点 2.1.2 编译.dts 2.1.3 更新板卡中的.dtb 2.2 …...
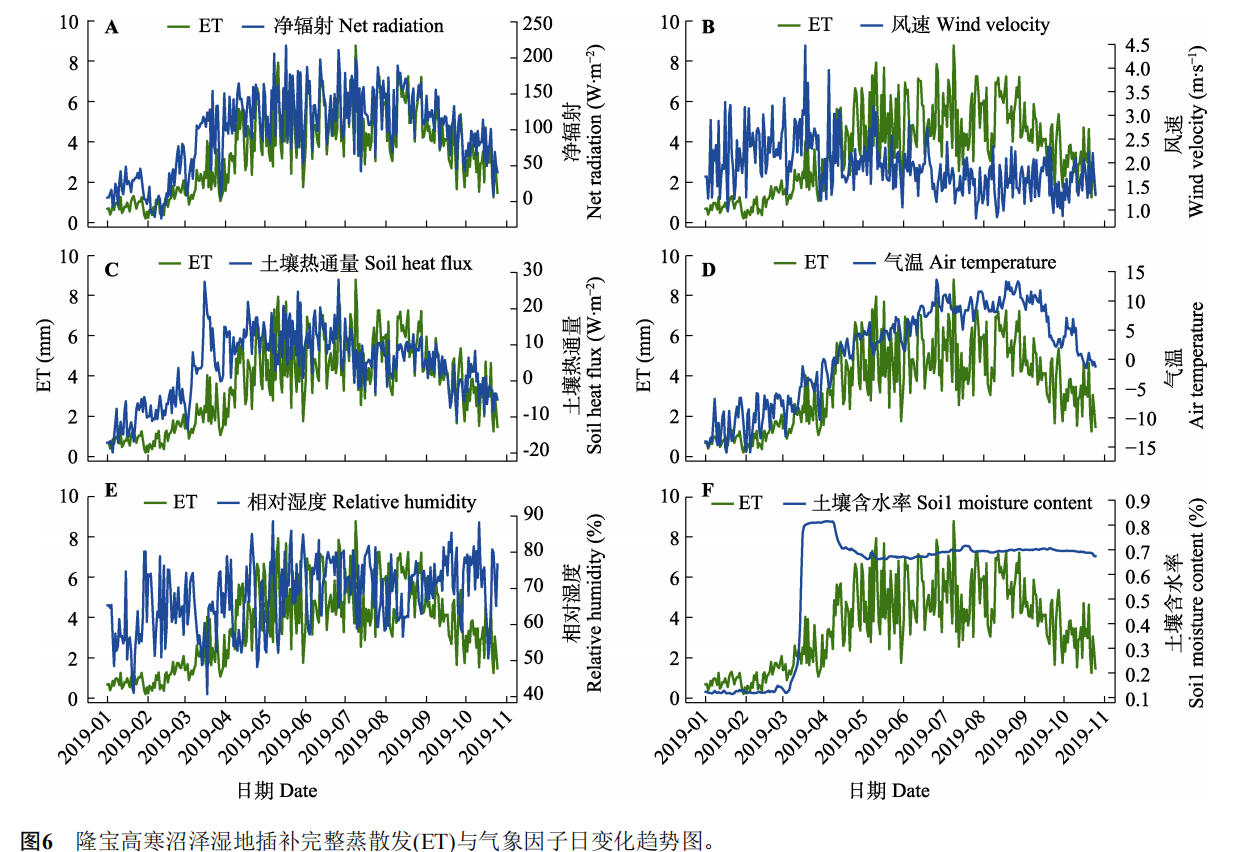
基于机器学习的青藏高原高寒沼泽湿地蒸散发插补研究_王秀英_2022
基于机器学习的青藏高原高寒沼泽湿地蒸散发插补研究_王秀英_2022 摘要关键词 1 材料和方法1.1 研究区概况与数据来源1.2 研究方法 2 结果和分析2.1 蒸散发通量观测数据缺省状况2.2 蒸散发与气象因子的相关性分析2.3 不同气象因子输入组合下各模型算法精度对比2.4 随机森林回归模…...

Failed at the node-sass@4.14.1 postinstall script.
问题描述 安装sass # "node-sass": "^4.9.0" npm i node-sass报错如下 npm ERR! code ELIFECYCLE npm ERR! errno 1 npm ERR! node-sass4.14.1 postinstall: node scripts/build.js npm ERR! Exit status 1 npm ERR! npm ERR! Failed at the node-sass4…...

【鸿蒙系统学习笔记】网络请求
一、介绍 资料来自官网:文档中心 网络管理模块主要提供以下功能: HTTP数据请求:通过HTTP发起一个数据请求。WebSocket连接:使用WebSocket建立服务器与客户端的双向连接。Socket连接:通过Socket进行数据传输。 日常…...

LabVIEW风力机智能叶片控制系统
LabVIEW风力机智能叶片控制系统 介绍了一种风力机智能叶片控制系统的开发。通过利用LabVIEW软件与CDS技术,该系统能够实时监测并调整风力机叶片的角度,优化风能转换效率。此项技术不仅提高了风力发电的稳定性和效率,而且为风力机的智能化管…...

HarmonyOS Stage模型 权限申请
配置声明权限 在module.json5配置文件中声明权限。不论是system_grant还是user_grant类型都需要声明权限,否则应用将无法获得授权。 {"module" : {// ..."requestPermissions":[{"name": "ohos.permission.DISCOVER_BLUETOOTH…...

标题:从预编译到链接:探索C/C++程序的翻译环境全貌
引言 在软件开发的世界里,我们通常会遇到两种不同的环境——翻译环境与运行环境。今天,我们将聚焦于前者,深入剖析C/C程序生命周期中至关重要的“翻译环境”,即从源代码到可执行文件这一过程中涉及的四个关键阶段:预编…...
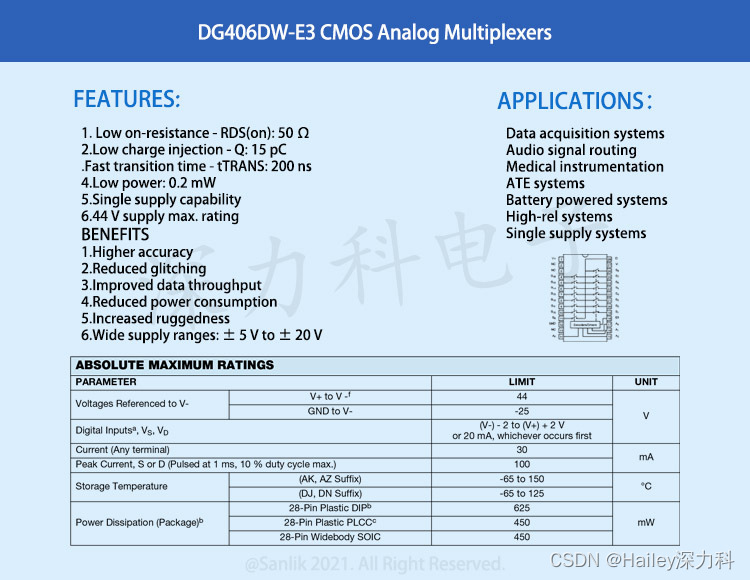
深入理解单端模拟多路复用器DG406DW-E3 应用于高速数据采集、ATE系统和航空电子设备解决方案
DG406DW-E3是一款16通道单端模拟多路复用器设计用于将16个输入中的一个连接到公共端口由4位二进制地址确定的输出。应用包括高速数据采集、音频信号切换和路由、ATE系统和航空电子设备。高性能低功耗损耗使其成为电池供电和电池供电的理想选择远程仪器应用。采用44V硅栅CMOS工艺…...

Redis篇----第六篇
系列文章目录 文章目录 系列文章目录前言一、Redis 的持久化机制是什么?各自的优缺点?二、Redis 常见性能问题和解决方案:三、redis 过期键的删除策略?前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章…...
——代码随想录算法训练营Day38)
【LeetCode】509. 斐波那契数(简单)——代码随想录算法训练营Day38
题目链接:509. 斐波那契数 题目描述 斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) 0,F(1) 1 F(n) F(n -…...
 函数对累积缓存设置)
[OpenGL教程05 ] glAccum() 函数对累积缓存设置
Accumulation Buffer:累积缓存 一、说明 openGL编程之所以困难,是因为它是三维图表示;简简单单加入一个Z轴,却使得几何遮挡、光线过度、运动随影等搞得尤其复杂。它的核心处理环节是像素缓存,本篇的积累缓存就是其一个…...

BeautifulSoup的使用与入门
1. 介绍 BeautifulSoup是用来从HTML、XML文档中提取数据的一个python库,安装如下: pip install beautifulsoup4 它支持多种解析器,包括python标准库、lxml HTML解析器、lxml XML解析器、html5lib等。结合稳定性和速度,这里推荐使用lxml HT…...
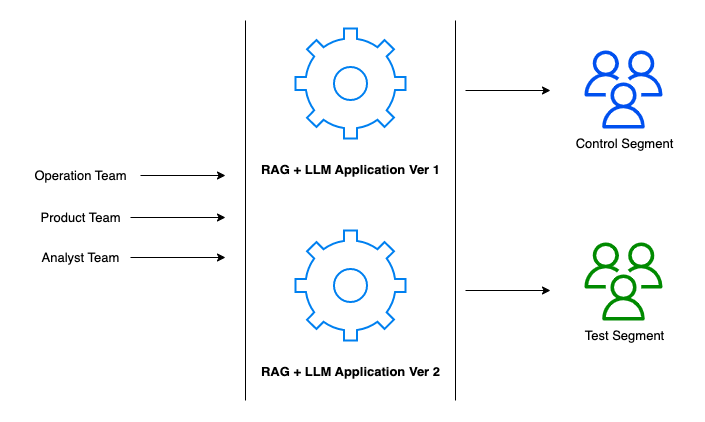
LLM之RAG实战(二十七)| 如何评估RAG系统
有没有想过今天的一些应用程序是如何看起来几乎神奇地智能的?这种魔力很大一部分来自于一种叫做RAG和LLM的东西。把RAG(Retrieval Augmented Generation)想象成人工智能世界里聪明的书呆子,它会挖掘大量信息,准确地找到…...

Linux Docker 关闭开机启动
说说自己为什么需要关闭自启动:Linux中安装Docker后,自启动会占用80和443端口,然后使用自己的SSL认证,导致自己Nginx配置的SSL认证失效,网站通过https打开显示不安全。 Docker是一个容器化平台,它可以让开…...
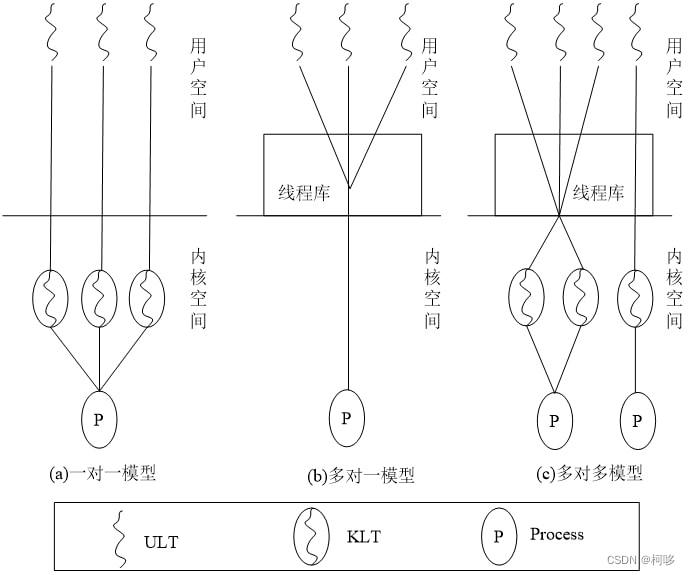
处理器管理补充——线程
传送门:操作系统——处理器管理http://t.csdnimg.cn/avaDO 1.1 线程的概念 回忆:[未引入线程前] 进程有两个基本属性:拥有资源的独立单位、处理器调度和分配的基本单位。 引入线程以后,线程将作为处理器调度和运行的基本单位&…...

RESTful 风格是指什么
RESTful(Representational State Transfer)是一种基于 HTTP 协议的软件架构风格,用于设计网络应用程序的接口。它的设计理念是利用 HTTP 协议中的方法(如 GET、POST、PUT、DELETE 等)来对资源进行 CRUD,使得…...

Python 二维矩阵加一个变量运算该如何避免 for 循环
Python 二维矩阵加一个变量运算该如何避免 for 循环 引言正文方法1------使用 for 循环方法2------不使用 for 循环引言 今天写代码的时候遇到了一个问题,比如我们需要做一个二维矩阵运算,其中一个矩阵是 2x2 的,另一个是 2x1 的。在这个二维矩阵中,其中各个参数会随着一个…...

B2B制造业如何利用GEO优化获得精准询盘:实战指南
B2B制造业如何利用GEO优化获得精准询盘:实战指南 摘要 :随着AI搜索渗透率超过85%,B2B制造业的获客逻辑正在被重塑。本文详细介绍GEO(Generative Engine Optimization)优化技术如何帮助工业品、机械配件企业获得精准询盘…...

酷安UWP桌面客户端完整指南:大屏幕高效刷酷安的终极方案
酷安UWP桌面客户端完整指南:大屏幕高效刷酷安的终极方案 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 还在为手机小屏幕刷酷安而感到眼睛酸痛吗?想在27寸大屏幕上…...

伯朗特机器人集成智能料库,为多台激光切割机提供24小时不间断的板材上下料服务
在现代钣金加工、机箱电柜及金属构件制造领域,激光切割已成为核心工序。然而,随着多台激光切割机集群化作业成为常态,传统的板材上下料模式——依赖叉车转运、行车吊运及人工操作——日益暴露出效率瓶颈、劳动力密集、安全隐患及设备利用率不…...

抖音批量下载终极指南:免费高效获取视频、图集、合集和音乐
抖音批量下载终极指南:免费高效获取视频、图集、合集和音乐 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

光电效应实验避坑指南:从汞灯预热到遏止电压判读,新手常犯的5个错误
光电效应实验避坑指南:从汞灯预热到遏止电压判读的5个关键误区 在大学的物理实验室里,光电效应实验就像一位性格古怪的教授——看似简单明了,实则暗藏玄机。许多同学满怀信心地走进实验室,却在数据采集阶段屡屡碰壁,最…...

深入解析TRC-20代币:从技术原理到生态布局,一篇文章讲透
深入解析TRC-20代币:从技术原理到生态布局,一篇文章讲透 引言 在波场(TRON)生态中,TRC-20 代币标准扮演着至关重要的角色,它不仅是承载如USDT等巨量稳定币的基石,更是连接DeFi、GameFi和NFT等…...

猫抓Cat-Catch:浏览器资源嗅探神器,轻松下载网页视频和流媒体资源
猫抓Cat-Catch:浏览器资源嗅探神器,轻松下载网页视频和流媒体资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾…...
)
Python 实现电脑垃圾自动清理工具(附完整源码)
最近很多朋友都在问:为什么电脑明明配置不差, 但用久了还是越来越卡?其实很多时候,并不是硬件问题。而是:临时文件过多缓存堆积回收站没清理系统垃圾越来越多于是我用 Python 写了一个:“电脑垃圾自动清理工…...

MASA全家桶汉化包终极指南:让Minecraft模组界面说中文的免费解决方案
MASA全家桶汉化包终极指南:让Minecraft模组界面说中文的免费解决方案 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为MASA模组复杂的英文界面而烦恼吗?MAS…...

B站SEO优化底层逻辑:以用户需求为核心,解锁低成本流量密码
在B站流量竞争日趋激烈的当下,很多创作者陷入“唯算法论”的误区,过度纠结于完播率、互动量等数据,却忽略了SEO优化的本质——匹配用户搜索需求。 一、认知重构:B站SEO的本质是“用户需求匹配”,而非“算法博弈”多数创…...